git database 数据库 平面文件 Git 同其他系统的重要区别 Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异 Git 的设计哲学
小结:
1、如果要浏览项目的历史更新摘要,Git 不用跑到外面的服务器上去取数据回来
2、注意 git clone 应指定版本,它复制的这个版本的全部历史信息;
各个分支 git init 数据库
master分支 git 数据库
“分布式 地位平等的 ” “git 区别与svn,没有 c/s 主从的概念”“”“c/s” 大家都往这个分支提交,这个分支就是“c/s”中的“s”?
master分支 非master分支地位平等
master只是第一个分支的默认名字而已,任意改。
git clone 时 clone 的是哪个分支,然后本地pull过来的就是哪个分支,push过去的目的地就是哪个分支?
https://git-scm.com/book/zh/v1/起步-Git-基础#近乎所有操作都是本地执行
直接记录快照,而非差异比较
Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。这类系统(CVS,Subversion,Perforce,Bazaar 等等)每次记录有哪些文件作了更新,以及都更新了哪些行的什么内容,请看图 1-4。
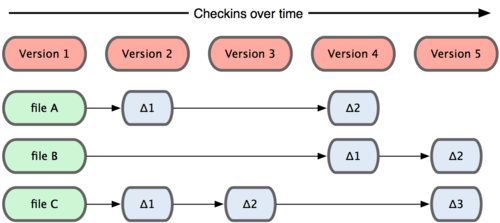
图 1-4. 其他系统在每个版本中记录着各个文件的具体差异
Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接。Git 的工作方式就像图 1-5 所示。
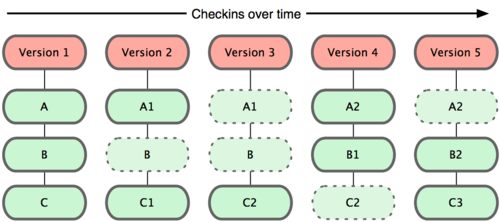
图 1-5. Git 保存每次更新时的文件快照
这是 Git 同其他系统的重要区别。它完全颠覆了传统版本控制的套路,并对各个环节的实现方式作了新的设计。Git 更像是个小型的文件系统,但它同时还提供了许多以此为基础的超强工具,而不只是一个简单的 VCS。稍后在第三章讨论 Git 分支管理的时候,我们会再看看这样的设计究竟会带来哪些好处。
近乎所有操作都是本地执行
在 Git 中的绝大多数操作都只需要访问本地文件和资源,不用连网。但如果用 CVCS 的话,差不多所有操作都需要连接网络。因为 Git 在本地磁盘上就保存着所有当前项目的历史更新,所以处理起来速度飞快。
举个例子,如果要浏览项目的历史更新摘要,Git 不用跑到外面的服务器上去取数据回来,而直接从本地数据库读取后展示给你看。所以任何时候你都可以马上翻阅,无需等待。如果想要看当前版本的文件和一个月前的版本之间有何差异,Git 会取出一个月前的快照和当前文件作一次差异运算,而不用请求远程服务器来做这件事,或是把老版本的文件拉到本地来作比较。
用 CVCS 的话,没有网络或者断开 VPN 你就无法做任何事情。但用 Git 的话,就算你在飞机或者火车上,都可以非常愉快地频繁提交更新,等到了有网络的时候再上传到远程仓库。同样,在回家的路上,不用连接 VPN 你也可以继续工作。换作其他版本控制系统,这么做几乎不可能,抑或非常麻烦。比如 Perforce,如果不连到服务器,几乎什么都做不了(译注:默认无法发出命令 p4 edit file 开始编辑文件,因为 Perforce 需要联网通知系统声明该文件正在被谁修订。但实际上手工修改文件权限可以绕过这个限制,只是完成后还是无法提交更新。);如果是 Subversion 或 CVS,虽然可以编辑文件,但无法提交更新,因为数据库在网络上。看上去好像这些都不是什么大问题,但实际体验过之后,你就会惊喜地发现,这其实是会带来很大不同的。
时刻保持数据完整性
在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git 一无所知。这项特性作为 Git 的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
Git 使用 SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个 SHA-1 哈希值,作为指纹字符串。该字串由 40 个十六进制字符(0-9 及 a-f)组成,看起来就像是:
24b9da6552252987aa493b52f8696cd6d3b00373
Git 的工作完全依赖于这类指纹字串,所以你会经常看到这样的哈希值。实际上,所有保存在 Git 数据库中的东西都是用此哈希值来作索引的,而不是靠文件名。
多数操作仅添加数据
常用的 Git 操作大多仅仅是把数据添加到数据库。因为任何一种不可逆的操作,比如删除数据,都会使回退或重现历史版本变得困难重重。在别的 VCS 中,若还未提交更新,就有可能丢失或者混淆一些修改的内容,但在 Git 里,一旦提交快照之后就完全不用担心丢失数据,特别是养成定期推送到其他仓库的习惯的话。
这种高可靠性令我们的开发工作安心不少,尽管去做各种试验性的尝试好了,再怎样也不会弄丢数据。至于 Git 内部究竟是如何保存和恢复数据的,我们会在第九章讨论 Git 内部原理时再作详述。
文件的三种状态
好,现在请注意,接下来要讲的概念非常重要。对于任何一个文件,在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地数据库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
由此我们看到 Git 管理项目时,文件流转的三个工作区域:Git 的工作目录,暂存区域,以及本地仓库。
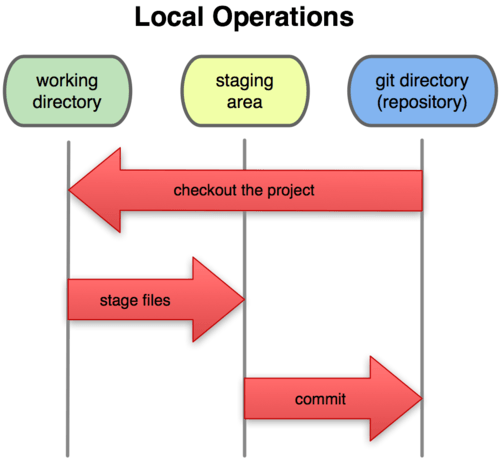
图 1-6. 工作目录,暂存区域,以及本地仓库
每个项目都有一个 Git 目录(译注:如果 git clone 出来的话,就是其中 .git 的目录;如果 git clone --bare 的话,新建的目录本身就是 Git 目录。),它是 Git 用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。
从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从 Git 目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。
所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
基本的 Git 工作流程如下:
- 在工作目录中修改某些文件。
- 对修改后的文件进行快照,然后保存到暂存区域。
- 提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中。
所以,我们可以从文件所处的位置来判断状态:如果是 Git 目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。到第二章的时候,我们会进一步了解其中细节,并学会如何根据文件状态实施后续操作,以及怎样跳过暂存直接提交。
(克隆指定分支)
git clone -b dev git@192.68.11.123:root/autocloudservices.git
git clone -b master git@192.68.11.123:root/autocloudservices.git
git+ssh://git@gitlab-test.d5.com:182/python/e.logging_sdk.git@fxl requirement
[xiaole@localhost .git]$ tree -sf
.
├── [ 6] ./branches
├── [ 264] ./config
├── [ 73] ./description
├── [ 20] ./HEAD
├── [ 242] ./hooks
│ ├── [ 452] ./hooks/applypatch-msg.sample
│ ├── [ 896] ./hooks/commit-msg.sample
│ ├── [ 189] ./hooks/post-update.sample
│ ├── [ 398] ./hooks/pre-applypatch.sample
│ ├── [ 1704] ./hooks/pre-commit.sample
│ ├── [ 1239] ./hooks/prepare-commit-msg.sample
│ ├── [ 1348] ./hooks/pre-push.sample
│ ├── [ 4951] ./hooks/pre-rebase.sample
│ └── [ 3611] ./hooks/update.sample
├── [ 10448] ./index
├── [ 21] ./info
│ └── [ 240] ./info/exclude
├── [ 30] ./logs
│ ├── [ 195] ./logs/HEAD
│ └── [ 34] ./logs/refs
│ ├── [ 17] ./logs/refs/heads
│ │ └── [ 195] ./logs/refs/heads/dev
│ └── [ 20] ./logs/refs/remotes
│ └── [ 18] ./logs/refs/remotes/origin
│ └── [ 195] ./logs/refs/remotes/origin/HEAD
├── [ 30] ./objects
│ ├── [ 6] ./objects/info
│ └── [ 121] ./objects/pack
│ ├── [ 10312] ./objects/pack/pack-0428e2c92ad659916d4f1dcf0548dbb152dd0720.idx
│ └── [ 384838] ./objects/pack/pack-0428e2c92ad659916d4f1dcf0548dbb152dd0720.pack
├── [ 172] ./packed-refs
└── [ 46] ./refs
├── [ 17] ./refs/heads
│ └── [ 41] ./refs/heads/dev
├── [ 20] ./refs/remotes
│ └── [ 18] ./refs/remotes/origin
│ └── [ 32] ./refs/remotes/origin/HEAD
└── [ 6] ./refs/tags 16 directories, 22 files
更新时前缀英文字母A C D M G U R I的含义
A:add,新增
C:conflict,冲突
D:delete,删除
M:modify,本地已经修改
G:modify and merGed,本地文件修改并且和服务器的进行合并
U:update,从服务器更新
R:replace,从服务器替换
I:ignored,忽略
http://wuchong.me/blog/2019/02/12/how-to-become-apache-committer/
- 提Bug和提需求:Flink 使用 JIRA 来管理issue。打开 Flink JIRA 并登录,点击菜单栏中的红色 “Create“ 按钮,创建一个issue。
- 贡献代码:可以在 Flink JIRA 中寻找自己感兴趣的 issue,并提交一个 Pull Request(下文会介绍提交一个 PR 的全过程)。如果是新手,建议从 “starter” 标记的 issue 入手。笔者在 Flink 项目的第一个 issue 就是修复了打印日志中的错别字,非常适合于熟悉贡献流程,而且当天就 merge 了,成就感满满。当熟悉了流程之后,建议专注贡献某个模块(如 SQL, DataStream, Runtime),有利于积累影响力。
- 贡献文档:文档是一个项目很重要的部分,可以在 JIRA 中寻找并解决文档类的 issue。熟悉中英文的同学可以参与贡献中文翻译,可以搜索 “chinese-translation” 的 issue。
- 代码审查:Flink 每天都会在 GitHub 上收到很多 Pull Request 。帮助 review 代码也是对社区很重要的贡献。
- 还有很多参与贡献的方式,比如帮助测试RC版本,写Flink相关的博客等等。
如何提交第一个 Pull Request
1. 订阅 dev 邮件列表
1.用自己的邮箱给 dev-subscribe@flink.apache.org 发送任意邮件。
2.收到官方确认邮件。
3.回复该邮件,内容随意,表示确认即可。
4.确认后,会收到一封欢迎邮件,表示订阅成功。
注:自2019年7月开始,经过社区讨论,将开始执行新的 JIRA workflow,不再需要去 dev 邮件列表申请 contributor 权限。
2. 在 JIRA 中挑选 issue
如果有感兴趣的 JIRA,可以直接在 JIRA 下面留言,对于复杂的 issue,需要先阐明实现方案。然后会有 Committer/PMC assign issue 给你。
推荐从简单的开始做起。例如中文翻译的issue。
3. 本地开发代码
认领了 issue 后建议尽快开始开发,本地的开发环境建议使用 IntelliJ IDEA。在开发过程中有几个注意点:
- 分支开发。 从最新的 master 分支切出一个开发分支用于 issue 开发。
- 单 PR 单改动。 不要在 PR 中混入不相关的改动,不做无关的代码优化,不做无关的代码格式化。如果真有必要,可以另开 JIRA 解决。
- 保证新代码能被单元测试覆盖到。如果原本的测试用例,无法覆盖到,则需要自己编写对应的单元测试。
4. 创建 pull request
在提交之前,先更新 master 分支,并通过 git rebase -i master
命令,将自己的提交置顶(也可以通过 IDEA > VCS > Git > Rebase 可视化界面来做
rebase)。同时保证自己的提交信息中只有一个 commit,commit message 遵循规范格式。Commit 格式是
“[FLINK-XXX] [YYY] ZZZ”,其中 XXX 是 JIRA ID,YYY 是 component 名字,ZZZ 是 JIRA
title。例如 [FLINK-5385] [core] Add a helper method to create Row object。
5. 解决 code review 反馈的问题和建议
提交 PR 后会收到修改建议,只需要为这些修改 追加commit 就行,commit message 随意。注意不要 rebase/squash commits。追加 commit 能方便地看出距离上次的改动,而 rebase/squash 会导致 reviewer 不得不从头到尾重新看一遍 diff。
6. Committer merge PR
当 PR 获得 Committer 的 +1 认可后,就可以等待被 merge 到主干分支了。merge 的工作会由 Committer 来完成,Committer 会将你的分支再次 rebase 到最新的master 之上,并将多个 commits 合并成一个,完善 commit 信息,做最后的测试检查,最后会 merge 到 master 。
比较指定的2次提交的差异,注意方向
git diff
git diff ba13a9e4688312dbce247ff6489459a53a46bd57
git diff ba13a9e4688312dbce247ff6489459a53a46bd57 eda70705953ce2e57eb7501333dc73f49a39469e
- this.$router.push({ path: "/account/index" });
+ this.$router.push({ path: "/selfinfo/info" });
git diff eda70705953ce2e57eb7501333dc73f49a39469e ba13a9e4688312dbce247ff6489459a53a46bd57
- this.$router.push({ path: "/selfinfo/info" });
+ this.$router.push({ path: "/account/index" });
git database 数据库 平面文件 Git 同其他系统的重要区别 Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异 Git 的设计哲学的更多相关文章
- git database 数据库 平面文件
w 各个分支 git init 数据库 master分支 git 数据库 “分布式 地位平等的 ” “git 区别与svn,没有 c/s 主从的概念”“”“c/s” 大家都往这个分支提交,这个分支 ...
- git设计哲学
刚开始使用git的时候,总想拿git来和cvs或者svn来作对比,但不久后发现这个想法本身就是错的,git完全就是另外一种物种,一种本属于未来的物种.它的对象存储方式,快照,分支等,都是完全不同的. ...
- 基于Git的数据库sql文件的管理——完美解决团队sql操作协同问题
目录 基于Git的数据库sql文件的管理--完美解决团队sql操作协同问题 1.产生背景 2.之前没用Git管理数据库出现的问题 2.1 用同一个库调试带来的问题 3.解决方案 3.1 Sql文件的创 ...
- Git使用总结 Asp.net生命周期与Http协议 托管代码与非托管代码的区别 通过IEnumerable接口遍历数据 依赖注入与控制反转 C#多线程——优先级 AutoFac容器初步 C#特性详解 C#特性详解 WPF 可触摸移动的ScrollViewer控件 .NET(C#)能开发出什么样的APP?盘点那些通过Smobiler开发的移动应用
一,原理 首先,我们要明白Git是什么,它是一个管理工具或软件,用来管理什么的呢?当然是在软件开发过程中管理软件或者文件的不同版本的工具,一些作家也可以用这个管理自己创作的文本文件,由Linus开发的 ...
- Java面向接口编程,低耦合高内聚的设计哲学
接口体现的是一种规范和实现分离的设计哲学,充分利用接口可以极大的降低程序中各个模块之间的耦合,提高系统的可维护性以及可扩展性. 因此,很多的软件架构设计理念都倡导"面向接口编程"而 ...
- React的设计哲学 - 简单之美
React最初来自Facebook内部的广告系统项目,项目实施过程中前端开发遇到了巨大挑战,代码变得越来越臃肿且混乱不堪,难以维护.于是痛定思痛,他们决定抛开很多所谓的“最佳实践”,重新思考前端界面的 ...
- 【转载】Unix设计哲学 & 回车换行八卦 & EOF八卦 & UNIX目录结构八卦
昨天看了这篇文章 <关于Unix哲学> 首先用了两个例子,用风扇吹出空肥皂盒 和 太空铅笔,来说明简单设计也能派上作用吧. Unix哲学,Wikipedia上列出了好几个版本,不同的人有不 ...
- Spring History和spring设计哲学
1.spring history spring起点 2002年10月,Rod Johnson 写了一本名为Expert One-on-One J2EE设计和开发的书.本书由Wrox发布,涵盖了当时Ja ...
- 跟vczh看实例学编译原理——一:Tinymoe的设计哲学
自从<序>胡扯了快一个月之后,终于迎来了正片.之所以系列文章叫<看实例学编译原理>,是因为整个系列会通过带大家一步一步实现Tinymoe的过程,来介绍编译原理的一些知识点. 但 ...
随机推荐
- Backdrop Filter
CSS 滤镜 : backdrop-filter backdrop filter属性允许我们使用css对元素后面的内容应用过滤效果. 滤镜: 名称: 方法案例: 效果: blur() 模糊 filte ...
- 在 ASP.NET Core和Worker Service中使用Quartz.Net
现在有了一个官方包Quartz.Extensions.Hosting实现使用Quartz.Net运行后台任务,所以把Quartz.Net添加到ASP.NET Core或Worker Service要简 ...
- Spring IOC 笔记
什么是IOC与DI IOC(inversion of control) 它描述的其实是一种面向对象编程中的设计原则,用来降低代码之间的耦合度, 而DI(dependency Injection)依赖注 ...
- redis系列:分布式锁
redis系列:分布式锁 1 介绍 这篇博文讲介绍如何一步步构建一个基于Redis的分布式锁.会从最原始的版本开始,然后根据问题进行调整,最后完成一个较为合理的分布式锁. 本篇文章会将分布式锁的实现分 ...
- 关于char是否能表示一个中文
char是可以表示中文的 这个问题点有3个考核点 1 char是多少位的 2 java用的是什么方式表示字符 3 Unicode是用多少位表示的 1的答案是16位的,2的答案是Unicode,3的答案 ...
- 洛谷P4848 崂山白花蛇草水 权值线段树+KDtree
题目描述 神犇 \(Aleph\) 在 \(SDOI\ Round2\) 前立了一个 \(flag\):如果进了省队,就现场直播喝崂山白花蛇草水.凭借着神犇 \(Aleph\) 的实力,他轻松地进了山 ...
- Beta冲刺——汇总随笔
一.代码规范与计划随笔 Beta冲刺--代码规范与计划 二.凡事预则立随笔 Beta冲刺--凡事预则立 三.10篇冲刺随笔 Beta冲刺--第一天 Beta冲刺--第二天 Beta冲刺--第三天 Be ...
- 在.NET Core中使用Channel(三)
到目前为止,我们一直在使用所谓的"Unbounded"通道.你会注意到,当我们创建通道时,我们这样做: var myChannel = Channel.CreateUnbounde ...
- CSS卡片旋转
html{ perspective: 800px; } body{ display:flex; flex-wrap: wrap; } .card{ transform-style: preserve- ...
- Linux学习笔记 | 配置nginx
目录 一.Nginx概述 二.why Nginx? 三.Linux安装Nginx APT源安装 官网源码安装 四.nginx相关文件的配置 html文件:/var/www/html/index.htm ...