一种使用 Redis 深度驱动的,为构建轻量级分布式应用程序(Microservices)的工程方案

Hydra 是一个轻量级的 NodeJS 库,用于构建分布式计算应用程序,比如微服务。我们对轻量级的定义是:轻处理外部复杂性和基础设施依赖 —— 而不是有限的轻处理。
Hydra 声称对基础设施的依赖很轻,这是因为它唯一的外部依赖是 Redis。
Hydra 利用 Redis 丰富的数据结构来实现重要的微服务所需的功能。
如 presence(在线状态)、service discovery (服务发现)、load balancing (负载平衡)、messaging(消息传递)、queuing(队列)等。
Hydra 到底是什么?
Hydra 是一个 NodeJS 模块,可以将其导入到 JavaScript Node 应用程序中,以使其具有微服务功能。 Hydra 通过利用 Redis 做到这一点。
在这里,我们看到三个微服务 - 每个微服务都带有一个连接到 Redis 的 Hydra 模块。 在这种模式下,大多数服务不会直接与 Redis 通信。而是底层的 Hydra 模块代理 Redis。
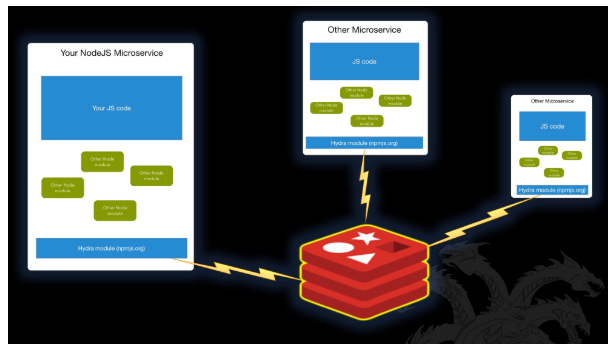
关于此图的另一点是,Hydra 只是另一个导入的模块 - 如绿色所示。 Hydra 在底部仅以蓝色显示,以说明其存在和与 Redis 的关系。
Hydra 模块公开一个 JS 类接口,该接口共有36个成员函数。
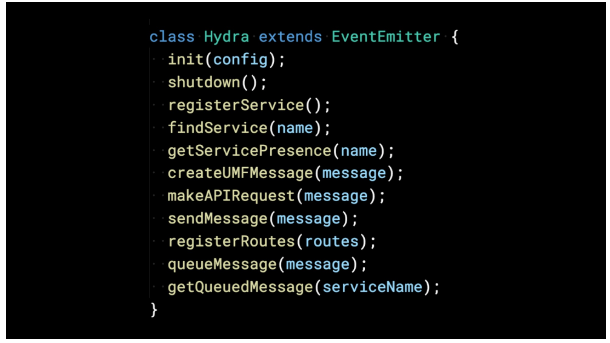
该快照提供了简化抽象的感觉。成员函数(例如 findService 和 sendMessage)非常简单。
Hydra 如何利用 Redis
这张幻灯片显示了许多重要的微服务问题。每个都是 non-trivial(非平凡的) 微服务所必需的。我们将详细研究 Hydra 如何使用 Redis 来实现所有这些功能。

请记住,这里的目标是展示如何做到这一点 —— 而不是说每种方法都是您应该如何在自己的服务中实现该特性。一个恰当的例子是,虽然你可以在 Redis 中存储你的微服务配置数据,或者使用 Redis 作为一个 logger —— 但这并不意味着你应该这样做。至少,除非你确切地知道你在做什么,以及需要做哪些权衡。
另外,请记住,您也许不需要Hydra。这些功能都是由 Redis 实现的,您当然可以在自己的应用程序中做到这一点。(如:Golang 来一版)
我将向您展示的一个关键点是,其中一些特性只有在组合时才能实现。例如,请求(request)和消息路由(message routing)依赖于状态(presence)、运行状况(health)、服务发现(service discovery)和负载平衡(load balancing)。
如您所知,这些特性中的每一个都可以使用各种基础设施工具来解决。然而,Hydra 的一个关键目标是简化构建微服务,同时最小化外部基础设施需求。在构建可用于生产的服务时,您需要决定需要哪些 Hydra 特性,以及哪些特性将从其他工具获得。这不是一个非此即彼的命题,而是一个你想要达到的目标和你能多快开始的问题。
就是说,很有趣的是,仅使用 Redis 和您喜欢的编程语言就可以实现所有这些功能。
Key 空间组织
了解 Hydra 如何利用 Redis 的第一步是查看它如何组织对 Redis key 空间的使用。
Hydra 使用的键 —— 由 2 到 4 段标签组成,标签之间用冒号分隔。段标签被命名为:前缀(Prefix)、服务名称(Service name)、实例 ID(Instance ID)和类型(type)。

前缀段允许过滤 Hydra key 和非 Hydra key。因此,如果你大量使用 Redis,那么能够过滤特定的 key 是至关重要的。
服务名称段帮助过滤特定服务类型的 key。例如授权(authorization)、用户(user)或图像处理(image processing)服务类型。
实例ID(Instance ID)段允许过滤唯一服务实例的 key。运行微服务时,通常需要运行一个服务类型的多个实例。每个服务实例都分配有唯一的 ID,并且能够区分它们是有用的。
最后,还有“类型(Type)”部分,用于对 key 的用途进行分类。并非每个 key 中都存在所有段。例如,某些 key 中不需要服务名称(Service name)和实例ID(instance ID)。
这是用户服务(user service) key 的示例。我们看到前缀 hydra:service 后跟服务名称,在本例中为 “user-svcs”。接下来,我们看到唯一的实例ID(unique instance ID)。最后,我们看到此 key 的类型为 presence(presence)。 因此,我们说 presence 信息存储(presence information)在此 key 地址中。

在前面的描述中,一个令人困惑的地方是,key 由名称组成,名称中有2到4个段标签,用冒号分隔。然而,在这里我们看到 hydra:service 也用冒号分隔。当时的想法是,可能还有另一种 hydra:other 类型,service 只是其中之一。
关于消息传递还有另一个不一致的地方,稍后我们将对此进行讨论。
我们可以输入 redis-cli 和输入 Redis 命令来查看各种键。在接下来的演示中我们会看到一些例子。

一个关于我们将使用的 redis-cli 示例的快速说明:你将看到 keys 命令的使用 —— 这是为了方便 —— Hydra 内部使用 Redis scan 命令。
所以重述一下 —— Hydra 使用的 key 是按段组织的,这使它们更容易查询。此外,一致的组织使它们更容易扩展和维护。随着我们继续,我们将看到 key 在每个微服务特性的组织中所扮演的角色。让我们从检查 presence(examining presence)开始。
Presence(呈现 type)
在微服务领域中,发现服务、了解服务是否正常以及是否可以路由到该服务的能力至关重要。
这些特性依赖于知道某个特定的服务实例确实存在并可供使用。
对于服务发现(service discovery)、路由(routing)和负载平衡(load balancing)等特性,这也是必需的。
每隔一秒钟,Hydra 就会更新它的服务 key 的生存时间(TTL)。
在三秒钟的时间内这样做失败将导致 key 过期,主机应用程序被视为不可用。

在这里我们可以看到使用的 Redis 命令是 “get” 和 “setex”,它们设置了一个 key 和一个到期时间。
我们可以使用带有模式匹配项的 “keys” 命令来查询 presence key。 注意,存在三个 key。这告诉我们存在 “ asset-svcs” 运行的三个实例。
如果我们尝试检索其中一个 key 的内容,我们会看到它包含实例ID(instance ID)。
并对键使用 TTL 命令可以向我们显示,它还有 2 秒钟的剩余时间。

所以回顾一下。可以使用自动过期的 key 来管理微服务的存在。Hydra 代表主机服务自动更新密钥。这意味着这不是开发人员做的事情。在3秒内更新 key 失败将导致服务被视为不可用。这可能意味着服务不健康。
这将我们带入下一个主题…
Health(健康 type)
能够监视微服务的运行状况是另一个重要功能。Hydra 每 5 秒钟收集并写入一个健康信息快照。
您可以检查快照以快速查看单个服务实例的运行状况。并且,快照可以由监控工具(例如 HydraRouter 仪表板)使用。
这就是健康 key 的样子。请注意,唯一的新位是标识 key 为关于 health 的 “type” 段。

当我们查看密钥的内容时,我们看到它包含一个字符串化的 JSON 对象。 在这种情况下,它用于 “project-svcs”。

将 JSON 解串可以更容易地查看存储的内容。它包含了很多有用的信息。
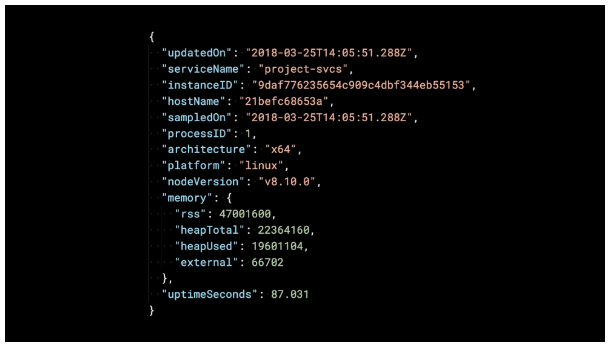
因此,可以按服务实例存储运行状况(health)信息。使用包含字符串化的JSON文本的字符串 key 进行管理。 而且这些信息可以通过监视应用程序来使用。
Service Discovery(服务发现)
接下来,让我们考虑服务发现,这是任何微服务架构的另一个必备功能。
通过名称发现服务的 IP 和 PORT 位置的能力极大地简化了通信。其他好处包括不必管理 DNS 条目或创建固定的路由规则。
服务发现信息以一种 “nodes” 的形式存储在 Redis Hash 中。使用 Hash 可以实现快速的查找。我们使用 Redis 的“hget”,“hset” 和 “hgetall” 命令来处理 nodes hash。

以下 Redis 操作可用于实现服务发现。
首先是对特定服务类型的查找。
第二个是查找可用实例。第三次查找,允许Hydra检索有关特定服务实例的信息。
我们可以看到有用的信息,例如服务的版本,instanceID,IP地址和端口,最后还有主机名。在此示例中,主机名也恰好是Docker 容器 ID。
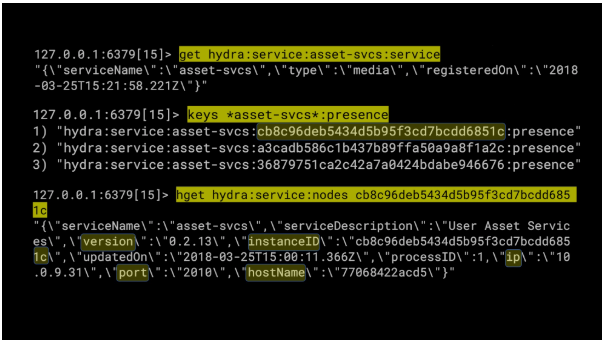
我们可以使用 Redis “hgetall” 命令检索有关所有可用实例的信息。这就是 Hydra Router 如何检索要显示在其仪表板上的服务列表。
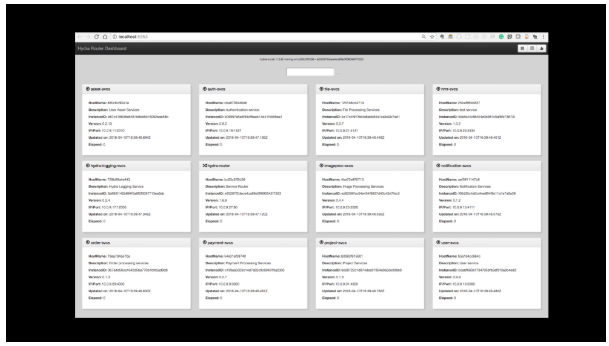
让我们回顾一下。Hydra 使用 servicename key 段进行查询,以发现有关服务的各种信息。可以使用 Redis Hash 管理服务详细信息,该服务可提供快速的服务发现
接下来,让我们考虑路由。
Routes(路由)
同时路由 HTTP 和消息(例如 Web Socket 或 PubSub )- 要求对 routes 进行验证。微服务可以发布其 routes 到 Redis。举个例子,HydraRouter 使用发布的 routes 来实现动态的服务感知路由。
每个服务以 “service:routes” 类型的 key 发布其路由。在这里,我们看到 “asset-svcs” 路由的 key
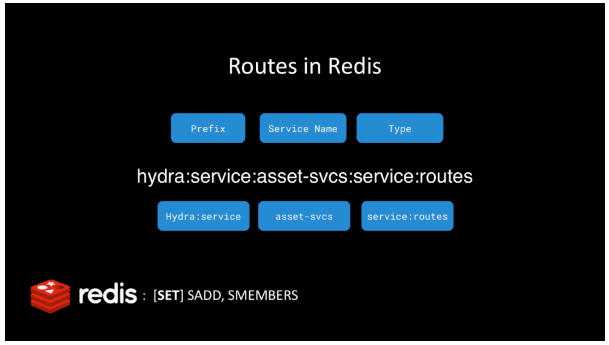
服务路由存储在 Set 结构中。非常适合,因为您不想重复输入路由条目。使用 SADD 和 SMEMBERS 命令。
回到我们的 routes 上。我们可以使用 key 模式拉出路由列表。在这里我们可以看到许多服务的路由。
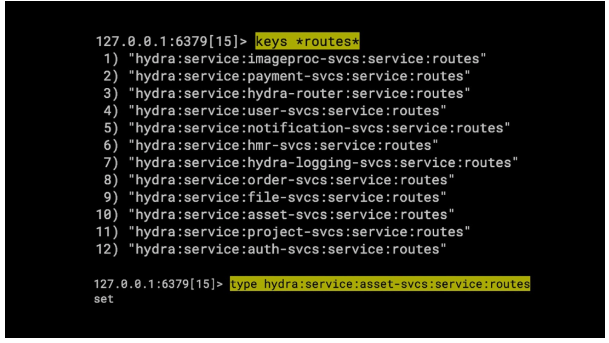
我们可以使用 “smembers” 命令查看特定路由集的内容。顺便说一下,括号中的 [get]、[post] 和 [put] 位表示 HTTP REST 端点。对于其他消息传递传输,可以省略括号方法的使用。
让我们回顾一下。每个服务都会向一个 Redis Set 发布它的路由。访问一个单独的路由会显示该服务的路由条目集合。
路由使用 Set 数据结构存储在 Redis 中,这避免了重复的路由。发布的路由可用于实现动态的服务感知路由。接下来,让我们考虑负载平衡。
Load Balancing(负载平衡)
随着应用程序的增长,您将需要在可用的服务实例之间平衡请求。这是通过使用我们看到的服务呈现(service presence)和路由(routing)功能完成的。在应用程序级别,使用 Hydra,这与使用 “makeAPIRequest” 或 “sendMessage” 调用一样简单。当 Hydra 使用路由和 presence 信息在可用的目标实例中进行选择时,就会在这些调用中进行负载平衡。
一个很好的好处是,在路由过程中,如果某个请求在某个特定实例上失败,Hydra 可以在出现 HTTP 503 服务器不可用错误之前重试其他可用实例。
如您所见,负载平衡依赖于其他功能,例如 presence,服务发现和路由。
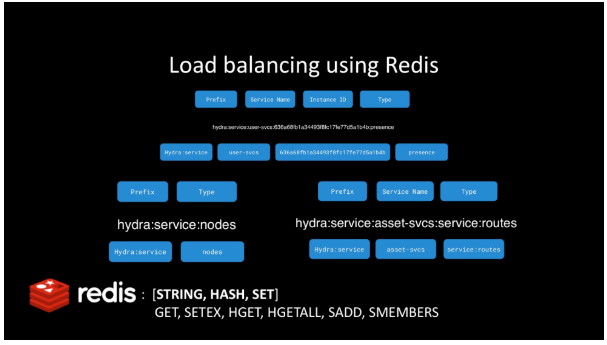
回顾一下,可以使用我们已经看到的 Presence、服务发现(Service Discovery)和路由(Routing)特性来完成服务之间的负载平衡请求。Redis Strings,Hashes 和 Sets 使这成为可能。整体大于部分之和。
Messaging(消息)
分布式服务强制通过底层网络彼此通信。
HTTP Rest 调用可能是最常见的,但是 socket 消息传递可能更有效。
Hydra 中的消息传递是通过 Redis 的 Pub/Sub 通道完成的,而 Redis 通过 socket 连接实现了 Pub/Sub。
这里有一个例子。Hydra 使用 Redis 的 “subscribe”、“unsubscribe” 和 “publish” 命令。

顺便说一句,Hydra router 能够通过 HTTP 和 WebSocket 接受消息并将其转换为 pub/sub 消息。
要了解其工作原理,请考虑两个服务,即 “asset-svcs” 和 “project-svcs”。
每个服务创建两个 key,一个使用服务名(service name),另一个使用服务名(service name)和实例ID(instance ID)。
每个服务都监听两个 channel。
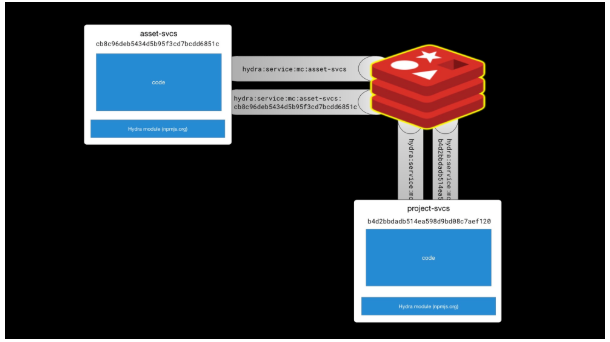
在大多数情况下,您并不关心哪个服务实例处理请求。在这些情况下,将使用没有特定实例ID的通道。
现在,当您需要向特定实例发送消息时,可以使用具有实例ID的通道。 需要特别注意的是,hydra 在负载均衡时会将请求转换为具有特定实例ID的服务名称。 这样可以确保只有一个实例可以处理给定的消息或请求。
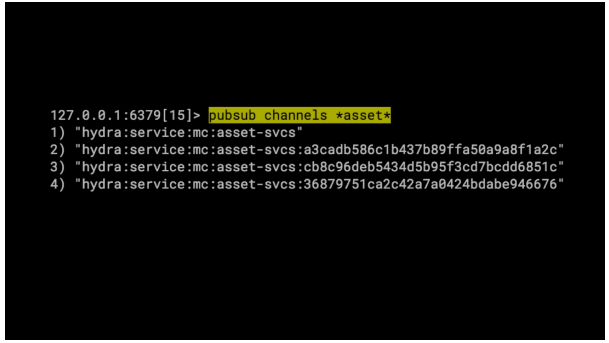
我们可以使用 Redis pub/sub channels 命令查看 channel key 列表。注意这里有四个 key。
第一个 key 是 “asset-svcs” 的名称 —— 由 asset service 的所有实例共享。
接下来,我们将看到三个具有惟一实例id的附加 key。三个服务实例各有一个。
继续关注消息传递。为了确保微服务之间的互操作性,必须标准化共享的通信格式。
通用消息格式是已记录的基于JSON的格式,其中包括对消息传递,路由和排队的支持。
这些消息作为JSON字符串文本存储在Redis中。
继续关注消息传递。
为了确保微服务之间的互操作性,必须对共享的通信格式进行标准化。
通用消息格式是一种文档化的 JSON-based 的格式,包括对消息传递(messaging)、路由(routing)和队列(queuing)的支持。
这些消息作为 JSON 字符串文本存储在 Redis 中。
下面是一个示例 UMF 消息。
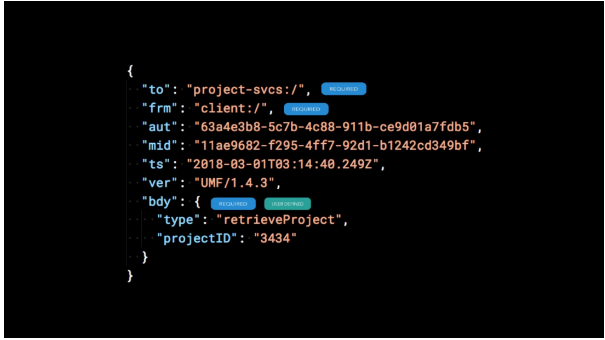
“to”,“frm” 和 “bdy” 字段是必填字段,服务可以自由地在 “body” 对象中包含自己的自定义字段。
让我们看看如何在实践中使用它。
在左边,“client-svcs” 向 “project-svcs” 发送消息。
注意,这只需要一个 UMF 创建调用和一个发送消息调用,这里用黄色显示。
在右边 —— “project-svcs” 侦听消息并根据需要进行处理。这是使用事件消息侦听器完成的。

请注意,Hydra 抽象了服务发现(service discovery)、负载平衡(load balancing)、路由和发布/订阅(pub/sub)等细节。
发送和接收消息只涉及三个成员函数。
在这里稍作停留是值得的。
花几秒钟考虑一下使用您最喜欢的堆栈时这个示例会是什么样子。
让我们仔细看看。Send message 通过解析消息中的 “to” 字段来确定目标服务名称。
有了服务名,下一步是检查可用的实例。
有了目标实例,消息就会被字符串序列化,并通过 Redis 的 “publish” 命令发送。

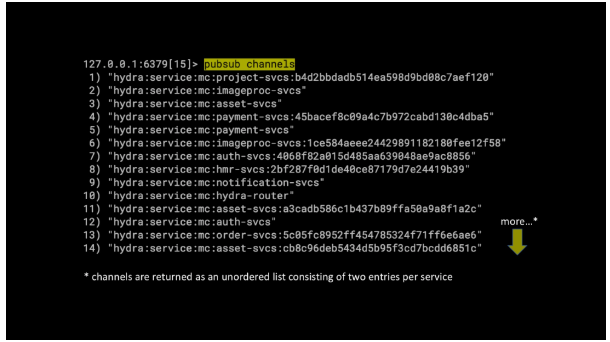
同样,我们可以列出Redis中的所有发布/订阅通道(Pub/Sub Channnel)。
消息可以通过这些通道发送,并由侦听器(listeners)检索。
因此,只需编写一些编程代码,我们就可以使用 Redis 通过组织良好的通道集合(collection of channels)来路由消息。
总而言之,值得注意的是,由于服务是物理分布的,因此最终需要进行消息传递。
Redis 使用其发布/订阅(pub/sub)功能启用消息传递。
标准化通信可以实现服务之间的互操作性。
我们还看到,当我们抽象出底层服务发现(service discover)、负载平衡(load balancing)、
路由(routing)和发布/订阅(pub/sub)细节时,
在应用程序级别上的通信是多么容易。
接下来,让我们考虑消息队列。
Queuing(队列)
作业(Job)和消息队列(message queues)是许多重要应用程序的另一个重要部分。
Hydra 使用 Redis 为每种服务类型维护动态队列(dynamic queues)。
然后,服务实例可以读取其队列和处理项目。
队列消息的内容是UMF消息,遵循用于消息传递的相同格式。
同样,互操作性为王!
Hydra 会为每种服务类型自动创建三个队列。
- “已接收(
received)”队列 - “进行中(
inprogress)”队列 - 还有一个“不完整(
incomplete)”队列。
因为这些是列表,我们使用 Redis 的 “lpush”、“rpush”、“rpoplpush” 和 “lrem” 命令。
下面的图表显示了队列之间的消息流。
在 Redis 中,在队列之间移动项目是一个原子操作。
所以不管你有多少微服务,它都是安全的。
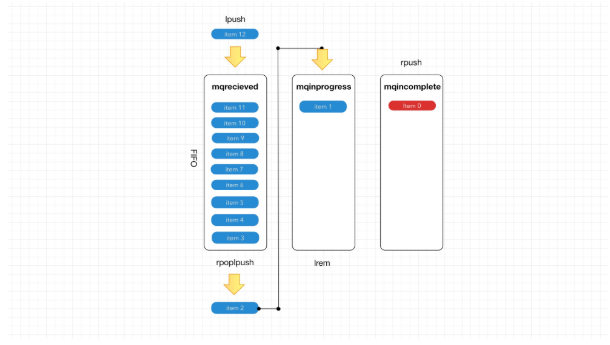
在下一个左边的示例中,
对消息进行排队就像创建一个 UMF 消息并调用 “queueMessage” 来发送它一样简单。
右下角的代码显示了图像处理服务通过调用 “getQueuedMessage”,
然后在处理完消息后调用 “markQueueMessage”,使消息脱离队列。很简单吧?

因此,回顾一下,有时无法期望立即做出回应。
在这种情况下,我们只需要排队等待后续处理。
Redis List 数据结构可以用作消息队列。
使用原子操作的 “lpush” 和 “rpoplpush” 之类的命令使此操作可行。
再次在这里,我们看到了使用高级抽象进行基本排队有多么容易。
Logging(日志记录)
分布式日志记录(Distributed logging)是任何微服务体系结构的另一个重要特征。
但是,如果您知道 Redis,可能会对将其用作分布式记录器(distributed logger)感到震惊。
您可能会理所当然地担心。但是,您可以将其用作飞行记录器(flight recorder)。
仅存储最严重的错误,并使用 “lpush” 和 “ltrim” 限制条目的数量。
然后,至少您将有一种快速的方法来检查微服务可能出了什么问题。
这是 key 的样子。注意,key 类型为 health:log。

在这里,我们可以看到 health:log key 类型实际上是一个 “List” 数据结构。
所以我们可以使用 Redis 的 “lrange” 命令来查看 “imageproc-svcs” 的飞行记录器(flight recorder)日志。
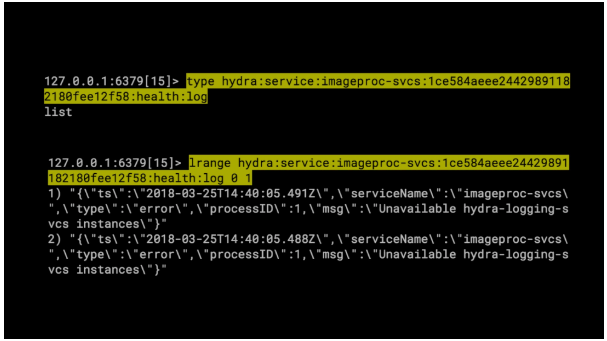
总结:使用微服务无法登录数十台或更糟的数百台计算机。
分布式日志记录绝对是必经之路。
使用 Redis,您可以构建一个轻量级的记录器(light-weight logger)以用作飞行记录器(flight recorder)。
使用 Redis List 数据结构以及方便的 “lpush” 和 “ltrim” 命令可以实现此目的。
最后,让我们考虑配置管理。
Configuration management(配置管理)
管理分布式微服务的配置文件可能具有挑战性。然而,你甚至可以使用 Redis 来存储你服务的配置文件。
但这并不理想,得远离,核心缺点是在 Redis 中存储配置会使 Redis 有状态。但这是可以做的。
让我们看看它是如何工作的。
configs key 类型是一个 hash。
该 hash 的 key 由服务版本和设置为该版本配置数据的值组成。

下面是一个配置示例。
在我们的示例中,我们使用名为 “hydra-cli” 的命令行工具,
它允许我们将配置文件推到特定的服务版本。
所做的一切就是创建一个 hash 条目,其键由服务名称和版本组成,
并将文件内容字符串序列化后(stringified)作为其值。
记住,你也可以使用 shell 脚本来驱动 redis cli。
我们可以使用 “hget” 命令和配置的版本提取一个特定的版本。

让我们快速回顾一下,我们了解了 Redis 如何用于存储应用程序配置文件。
Redis Hash 数据结构允许我们存储每种服务类型的配置。
每个配置条目均由服务版本标签索引,并且内容仅指向字符串化的 JSON 配置。
总结
这里分享的是一种大量地使用 JavaScript 和 NodeJS 来利用 Redis 构建分布式应用程序的工程方案。
但是,你完全可以用其他你爱的语言(如:Golang)对 Redis 做同样的事情。
互相交流
我是为少。微信:uuhells123。公众号:黑客下午茶。
谢谢点赞支持!
一种使用 Redis 深度驱动的,为构建轻量级分布式应用程序(Microservices)的工程方案的更多相关文章
- 分布式Redis深度历险-Cluster
本文为分布式Redis深度历险系列的第三篇,主要内容为Redis的Cluster,也就是Redis集群功能. Redis集群是Redis官方提供的分布式方案,整个集群通过将所有数据分成16384个槽来 ...
- 分布式Redis深度历险-复制
Redis深度历险分为两个部分,单机Redis和分布式Redis. 本文为分布式Redis深度历险系列的第一篇,主要内容为Redis的复制功能. Redis的复制功能的作用和大多数分布式存储系统一样, ...
- java基础-jdbc——三种方式加载驱动建立连接
String url = "jdbc:mysql://localhost:3306/student?Unicode=true&characterEncoding=utf-8" ...
- Redis深度历险——核心原理与应用实践
高可用架构」的各位老铁们,你们好!你是否还记得上个月发布的文章中,有两篇深入讲解Redis的文章,分别是和,广大粉丝读者们对这两篇文章整体评价颇高.而我就是这两篇文章的原创作者「老钱」(钱文品),我是 ...
- 全程精髓无废话,腾讯强推Redis深度笔记我粉了
作为目前主流的NoSQL技术,redis在Java互联网中得到了非常广泛的使用,个时代码代码的秃头人员,对Redis肯定是不陌生的,如果连Redis都没用过,还真不好意思出去面试,指不定被面试官吊打多 ...
- 深度学习之TensorFlow构建神经网络层
深度学习之TensorFlow构建神经网络层 基本法 深度神经网络是一个多层次的网络模型,包含了:输入层,隐藏层和输出层,其中隐藏层是最重要也是深度最多的,通过TensorFlow,python代码可 ...
- 从0开发3D引擎(十):使用领域驱动设计,从最小3D程序中提炼引擎(上)
目录 上一篇博文 下一篇博文 前置知识 回顾上文 最小3D程序完整代码地址 通用语言 将会在本文解决的不足之处 本文流程 解释本文使用的领域驱动设计的一些概念 本文的领域驱动设计选型 设计 引擎名 识 ...
- Azure Redis Cache作为ASP.NET 缓存输出提供程序
前一篇文章<Azure Redis Cache作为ASP.NET Session状态提供程序 >我们已经知道如何将ASP.NET应用程序Session存储在Redis Cache中,这里我 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
随机推荐
- linux: c语言 关闭标准输出STDOUT_FILENO对父子进程的影响
简介标准 I/O 库(stdio)及其头文件 stdio.h 为底层 I/O 系统调用提供了一个通用的接口.这个库现在已经成为 ANSI 标准 C 的一部分.标准 I/O 库提供了许多复杂的函数用于格 ...
- 运维告警排班太复杂?试试Cloud Alert智能告警排班
前言: 之前的几篇文章有说过,通过智能告警平台Cloud Alert,将指定条件的告警以多样化的通知方式,通知到指定的人,其中的通知的方式包含电话.短信.邮件.微信.APP.钉钉等. 本篇文章就来说下 ...
- 聊一聊sockmap 以及ebpf 实例演示
eBPF实质上是一个内核注入技术 用户态可以用C来写运行的代码,再通过一个Clang&LLVM的编译器将C代码编译成BPF目标码: 用户态通过系统调用bpf()将BPF目标码注入到内核当中,并 ...
- linux nf_conntrack 连接跟踪机制 3-hook
conntrack hook函数分析 enum nf_ip_hook_priorities { NF_IP_PRI_FIRST = INT_MIN, NF_IP_PRI_CONNTRACK_DEFRA ...
- 1. 线性DP 120. 三角形最小路径和
经典问题: 120. 三角形最小路径和 https://leetcode-cn.com/problems/triangle/ func minimumTotal(triangle [][]int) ...
- 查看ceph集群被哪些客户端连接
前言 我们在使用集群的时候,一般来说比较关注的是后台的集群的状态,但是在做一些更人性化的管理功能的时候,就需要考虑到更多的细节 本篇就是其中的一个点,查询ceph被哪些客户端连接了 实践 从接口上来说 ...
- Python网络编程_抓取百度首页代码(注释详细)
1 #coding=utf-8 2 #网络编程 3 4 #客户端建立socket套接字 5 #引入socket模块 6 import socket 7 #实例化一个套接字,2个参数分别是: IPV4. ...
- JavaScrip_12.23
笔记系列,零散的知识点,准备以后复习整理使用 JavaScrip - 事件DOM绑定[将函数添加到一个元素对象的属性中] 1.事件 鼠标.键盘.操作等:所有的GUI都有 onclick(单击事件) 例 ...
- JetCache 源码分析
一.简介 JetCache是一个基于Java的缓存系统封装,提供统一的API和注解来简化缓存的使用. JetCache提供了比SpringCache更加强大的注解,可以原生的支持TTL.两级缓存.分布 ...
- [LeetCode题解]86. 分隔链表 | 三指针 + 虚拟头节点
解题思路 三指针,一个指向前半部分待插入位置,一个指向后半部分待插入位置,最后一个从前往后遍历 代码 /** * Definition for singly-linked list. * public ...