cosbench使用方法
前言
cosbench的功能很强大,但是配置起来可能就有点不是太清楚怎么配置了,本篇将梳理一下这个测试的配置过程,以及一些测试注意项目,以免无法完成自己配置模型的情况
安装
cosbench模式是一个控制端控制几个driver向后端rgw发起请求
下载最新版本
https://github.com/intel-cloud/cosbench/releases/download/v0.4.2.c4/0.4.2.c4.zip
[root@lab102 cosbench]#unzip 0.4.2.zip
[root@lab102 cosbench]#yum install java-1.7.0-openjdk nmap-ncat
访问地址
同时可以执行的workloads的个数通过下面的control参数控制
concurrency=1
默认是一个,这个为了保证单机的硬件资源足够,保持单机启用一个workload
创建一个s3用户
[root@lab101 ~]# radosgw-admin user create --uid=test1 --display-name="test1" --access-key=test1 --secret-key=test1
{
"user_id": "test1",
"display_name": "test1",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "test1",
"access_key": "test1",
"secret_key": "test1"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"temp_url_keys": []
}
配置相关
cosbench的配置文件结构

- 一个workload 可以定义一个或者多个work stages
- 执行多个work stages是顺序的,执行同一个work stage里面的work是可以并行执行的
- 每个work里面,worker是来调整负载的
- 认证可以多个级别的定义,低级别的认证会覆盖高级别的配置
可以通过配置多个work的方式来实现并发,而在work内通过增加worker的方式增加并发,从而实现多对多的访问,worker的分摊是分到了driver上面,注意多work的时候的containers不要重名,划分好bucker的空间
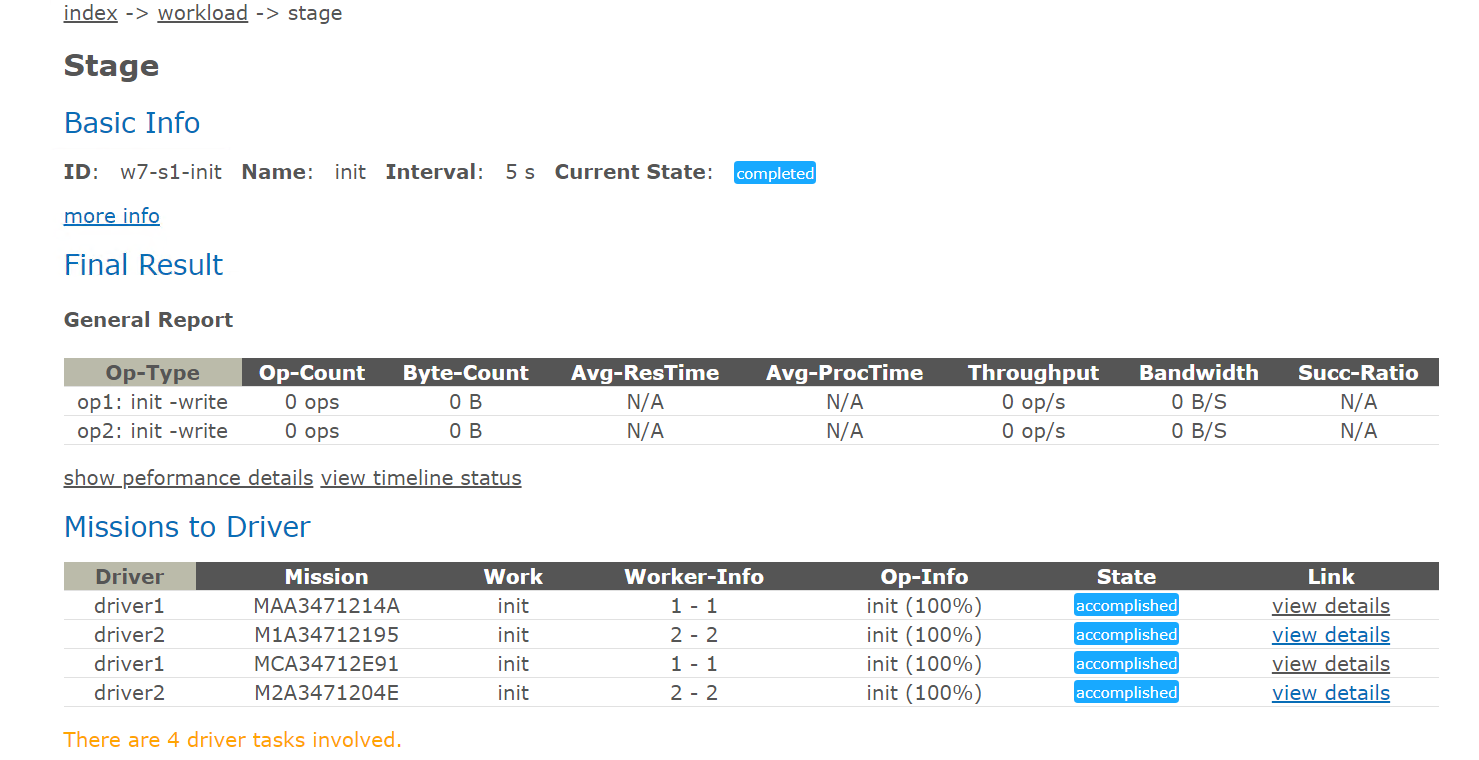
work相关的说明
- 可以通过写入时间,写入容量,写入iops来控制什么时候结束
- interval默认是5s是用来对性能快照的间隔,可以理解为采样点
- division 控制workers之间的分配工作的方式是bucket还是对象还是none
- 默认全部的driver参与工作,也可以通过参数控制部分driver参与
- 时间会控制执行,如果时间没到,但是指定的对象已经写完了的话就会去进行复写的操作,这里要注意是进行对象的控制还是时间的控制进行的测试
如果读取测试的时候,如果没有那个对象,会中断的提示,所以测试读之前需要把测试的对象都填充完毕(最好检查下先)
单项的配置文件
通过单网关创建bucket
<?xml version="1.0" encoding="UTF-8"?>
<workload name="create-bucket" description="create s3 bucket" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="create bucket" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1" type="init" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,8)">
<auth type="none" config=""/>
<storage type="s3" config="accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
</workstage>
</workflow>
</workload>
执行完建议检查下是不是创建了这么多的bucket,之前测试的时候发现即使没有创建成功bucket,在put的时候也不会报错,bucket并没有创建成功,读取的时候才抛出的错,总之每做一步确认下上一步的结果
执行检查
[root@lab101 ~]# radosgw-admin bucket list
[
"zp2",
"zp8",
"zp7",
"zp3",
"zp4",
"zp6",
"zp5",
"zp1"
]
如上配置的时候,如果设置的是workers=1,那么就会从当前的driver中挑选一个driver出来,然后选择配置storage进行bucket的创建,如果设置的是workers=2,那么就会挑选两个driver出来进行创建,一个driver负责一半的工作,相当于两个客户端同时向一个网关发起创建的操作,cprefix参数是控制创建的bucket的前缀的
rgw的网关是对等的关系,那么这里肯定就有另外一种配置,我想通过不只一个网关进行创建的操作,那么这个地方是通过增加work的配置来实现的,我们看下配置
通过多网关创建bucket
<?xml version="1.0" encoding="UTF-8"?>
<workload name="create-bucket" description="create s3 bucket" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="create bucket" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1" type="init" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,4)">
<auth type="none" config=""/>
<storage type="s3" config="accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="rgw2" type="init" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(4,8)">
<auth type="none" config=""/>
<storage type="s3" config="accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
</workflow>
</workload>
以上配置就实现了通过两个网关进行创建bucket的配置了,下面是做prepare的相关配置,在cosbench里面有两个部分可以进行写操作,在prepare stage里面和 main stage里面
这个地方这样设置的理由是:
如果有读和写混合测试的时候,那么就需要提前进行读数据的准备,然后再开始进行读写并发的测试,所以会有一个prepare的阶段,这个在配置文件里面只是type设置的不同,其他没区别,我们可以看下这里web界面里面提供的配置项目,下面其他项目默认都是采取双并发的模式
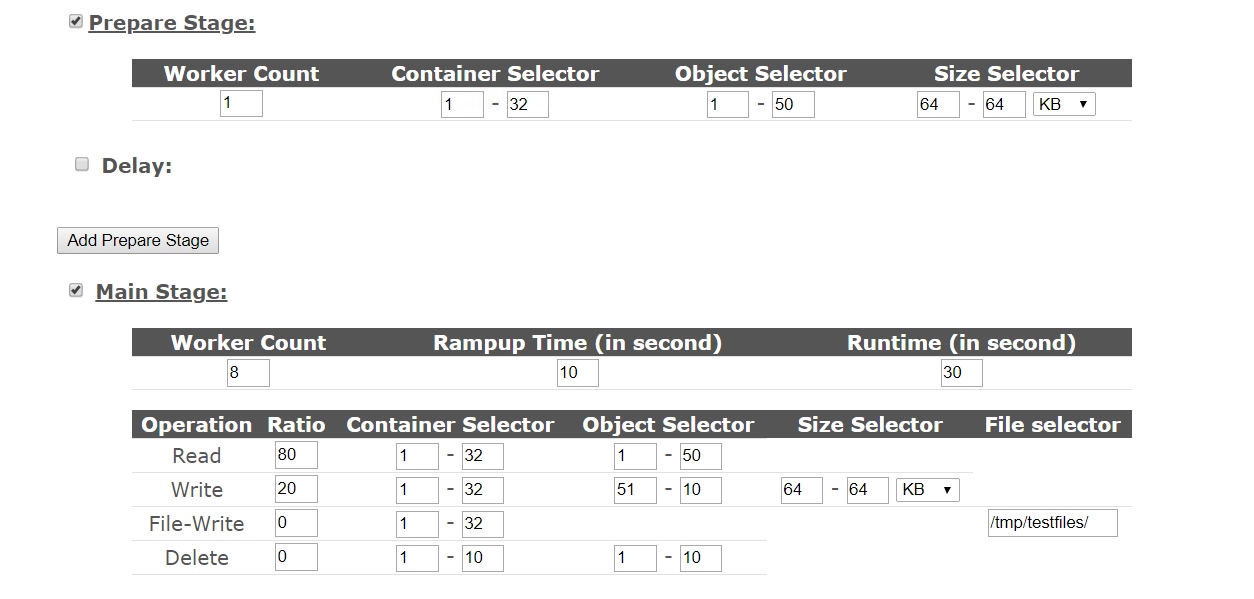
在写的部分是一样的
通过多网关写数据
<?xml version="1.0" encoding="UTF-8"?>
<workload name="create-object" description="create object" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="putobject" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-put-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
<operation type="write" ratio="100" division="none"
config="cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
<work name="rgw2-put-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
<operation type="write" ratio="100" division="none"
config="cprefix=zp;containers=r(5,8);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
</workstage>
</workflow>
</workload>
这里有几个参数可以注意一下:
cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"
控制写入的bucket的名称的,是全部散列还是把负载均分可以自己去控制,objects是指定写入bucke里面的对象的名称的,sizes是指定大小的,如果两个值不同,就是设置的范围,相同就是设置的指定大小的
runtime="0" rampup="0" rampdown="0" afr="200000" totalOps="240" totalBytes="0"
这个是控制写入什么时候中止的,可以通过时间,也可以通过总的ops,或者总的大小来控制,这个需求可以自己定,afr是控制允许的失效率的,单位为1百万分之
interval="5"
这个是控制抓取性能数据的周期的
写的部分还可以通过prepare控制,因为读和写需要对应上,不然读取会报错,所以这里还有一种方法写数据
我们在测试的时候,有时候有两种需求,一种是我只关注读取,那么就需要准备好测试数据,不用关心写入的性能,一种是我想看下复写的性能,那么也是需要把数据先填充完,那么这种情况的填充就不用iops控制,也不用时间控制了,我需要填充满,那么cosbench里面就提供了这种写法,就是prepare这个写类型做了的,我们看下配置文件
<?xml version="1.0" encoding="UTF-8"?>
<workload name="create-object" description="create object" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="prepare-rgw1" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="prepare" type="prepare" workers="2" interval="5"
division="object" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;oprefix=hj;containers=r(1,4);objects=r(1,240);sizes=u(64,64)KB">
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="prepare-rgw2" type="prepare" workers="2" interval="5"
division="object" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;oprefix=hj;containers=r(5,8);objects=r(1,240);sizes=u(64,64)KB">
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
</workflow>
</workload>
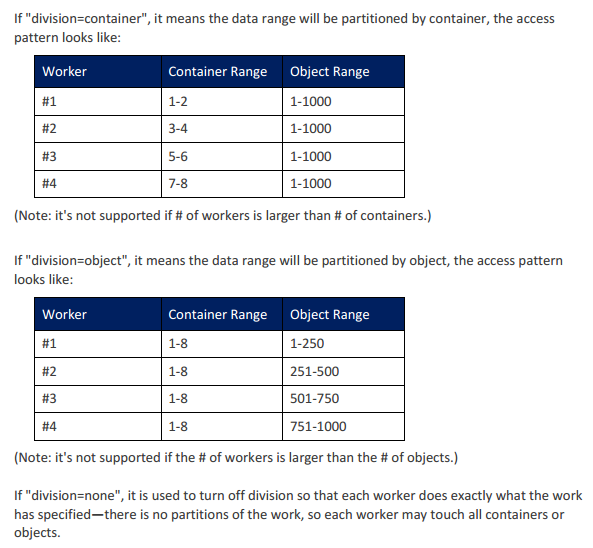
division这个参数用下面的这张图比较好解释
写入的配置就完了
并发读取的配置
<?xml version="1.0" encoding="UTF-8"?>
<workload name="read-object" description="create object" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="readobject" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-put-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
<operation type="read" ratio="100" division="none"
config="cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
<work name="rgw2-read-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
<operation type="read" ratio="100" division="none"
config="cprefix=zp;containers=r(5,8);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
</workstage>
</workflow>
</workload>
删除对象的配置
<?xml version="1.0" encoding="UTF-8"?>
<workload name="read-object" description="create object" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="rgw1-cleanup" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-cleanup" type="cleanup" workers="2" interval="5"
division="object" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);deleteContainer=false;">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="rgw2-cleanup" type="cleanup" workers="2" interval="5"
division="object" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(5,8);oprefix=hj;objects=r(1,240);deleteContainer=false;">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
</workflow>
</workload>
删除bucket的配置
<?xml version="1.0" encoding="UTF-8"?>
<workload name="read-object" description="create object" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="dispose" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-dispose" type="dispose" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,4);">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="rgw2-dispose" type="dispose" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(5,8);">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
</workflow>
</workload>
上面的workstage一共包括下面几种
- init 创建bucket
- normal write 写入对象
- normal read 读取对象
- cleanup 清理对象
- dispose 清理bucket
division是控制多个worker之间的操作怎么去分的控制,最好在operation那层进行控制
测试前自我提问
- 单机用了几个workload(默认一般一个,保证单个测试资源的独占)
- 采用了几个driver(决定了客户端的发起是有几个客户端,单机一个就可以)
- 测试了哪几个项目(init,prepare or normal,remove),单独测试还是混合测试
- 单个项目的workstage里面启动了几个work(work可以控制请求发向哪里)
- 单个work里面采用了几个workers(这个是控制几个driver进行并发的)
- 测试的ceph集群有多少个rgw网关,创建了多少个bucket测试
- 设置的写入每个bucket的对象为多少?对象大小为多少?测试时间为多久?
测试很多文件的时候,可以用ops控制,并且将ops设置大于想测试的文件数目,保证能写入那么多的数据,或者比较确定性能,也可以通过时间控制
那么我来根据自己的需求来进行一个测试模型说明,然后根据说明进行配置
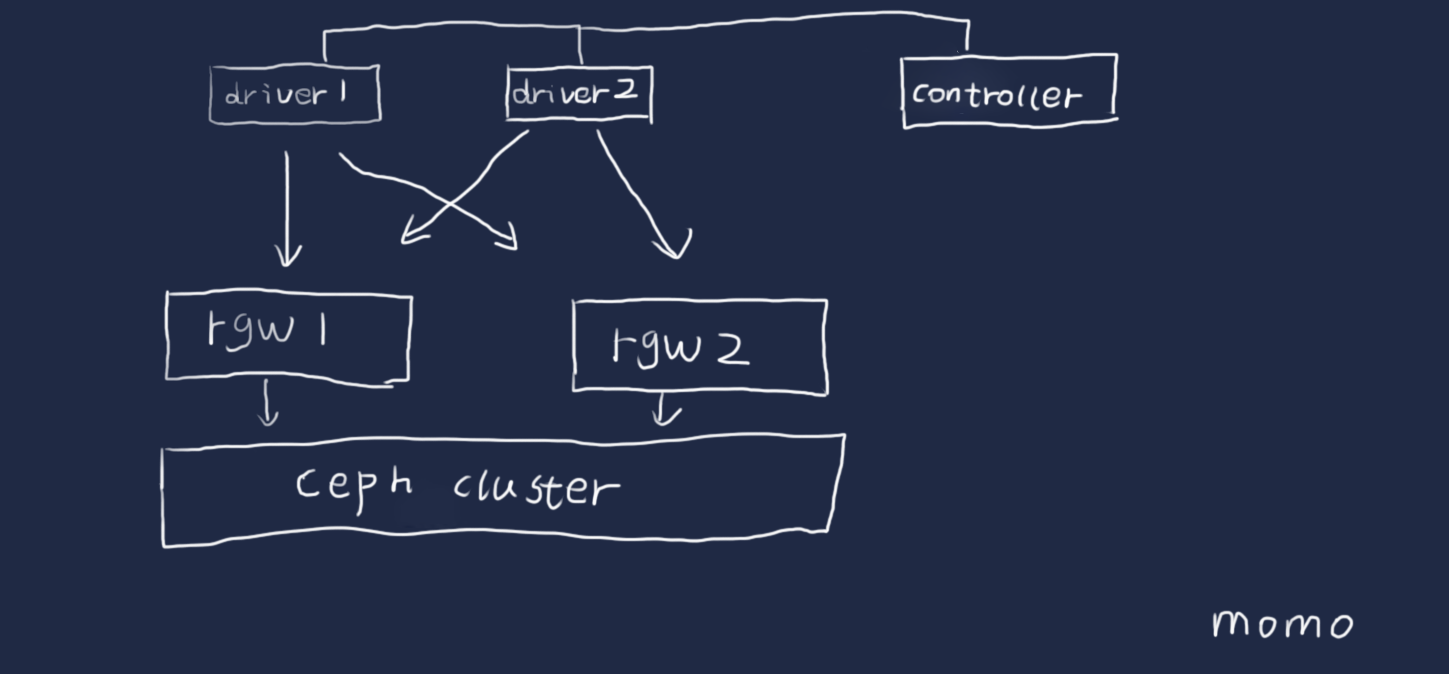
- 采用两个客户端测试,那么准备两个driver
- 准备配置两个rgw的网关,那么在配置workstage的时候配置两个work对应到两个storage
- 测试创建,写入,读取,删除对象,删除bucket一套完整测试
- wokers设置为2的倍数,初始值为2,让每个driver分得一半的负载,在进行一轮测试后,成倍的增加driver的数目,来增大并发,在性能基本不增加,时延在增加的时候,记录性能值和参数值,这个为本环境的最大性能
- 创建8个bucket,每个bucket写入30个64K的对象,测试文件数目为240个
简单框架图
配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<workload name="create-bucket" description="create s3 bucket" config="">
<auth type="none" config=""/>
<workflow config="">
<workstage name="create bucket" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1" type="init" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,4)">
<auth type="none" config=""/>
<storage type="s3" config="accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="rgw2" type="init" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(4,8)">
<auth type="none" config=""/>
<storage type="s3" config="accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
<workstage name="putobject" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-put-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
<operation type="write" ratio="100" division="none"
config="cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
<work name="rgw2-put-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
<operation type="write" ratio="100" division="none"
config="cprefix=zp;containers=r(5,8);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
</workstage>
<workstage name="readobject" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-put-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
<operation type="read" ratio="100" division="none"
config="cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
<work name="rgw2-read-4M" type="normal" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="200000" totalOps="240" totalBytes="0" config="">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
<operation type="read" ratio="100" division="none"
config="cprefix=zp;containers=r(5,8);oprefix=hj;objects=r(1,240);sizes=c(64)KB" id="op1"/>
</work>
</workstage>
<workstage name="rgw1-cleanup" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-cleanup" type="cleanup" workers="2" interval="5"
division="object" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,4);oprefix=hj;objects=r(1,240);deleteContainer=false;">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="rgw2-cleanup" type="cleanup" workers="2" interval="5"
division="object" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(5,8);oprefix=hj;objects=r(1,240);deleteContainer=false;">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
<workstage name="dispose" closuredelay="0" config="">
<auth type="none" config=""/>
<work name="rgw1-dispose" type="dispose" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(1,4);">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7481;path_style_access=true"/>
</work>
<work name="rgw2-dispose" type="dispose" workers="2" interval="5"
division="container" runtime="0" rampup="0" rampdown="0"
afr="0" totalOps="1" totalBytes="0" config="cprefix=zp;containers=r(5,8);">
<auth type="none" config=""/>
<storage type="s3" config="timeout=300000;accesskey=test1;secretkey=test1;endpoint=http://66.66.66.63:7482;path_style_access=true"/>
</work>
</workstage>
</workflow>
</workload>
上面的测试是为了做测试模板,所以采用了比较小的对象数目和比较小的测试时间
可以根据自己的硬件环境或者客户的要求来设计测试模型,环境够大的时候,提供足够的rgw和足够的客户端才能测出比较大的性能值
测试的时候,尽量把写入和读取的测试分开,也就是分两次测试,避免第一次的写入没写足够对象,读取的时候读不到中断了,对于长达数小时的测试的时候,中断是很令人头疼的,分段可以减少这种中断后的继续测试的时间
写入的测试在允许的范围内,尽量写入多点对象,尽量避免复写,也能够在读取的时候尽量能够足够散列
测试时间能够长尽量长
测试结果
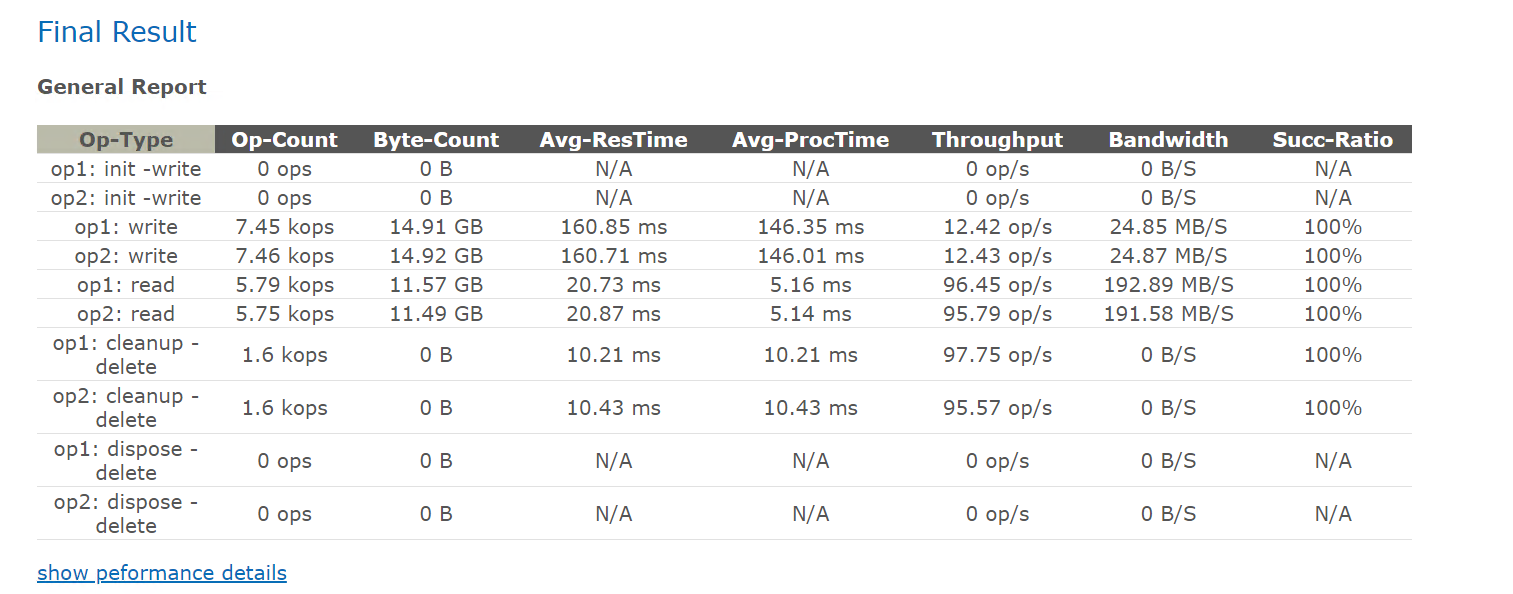
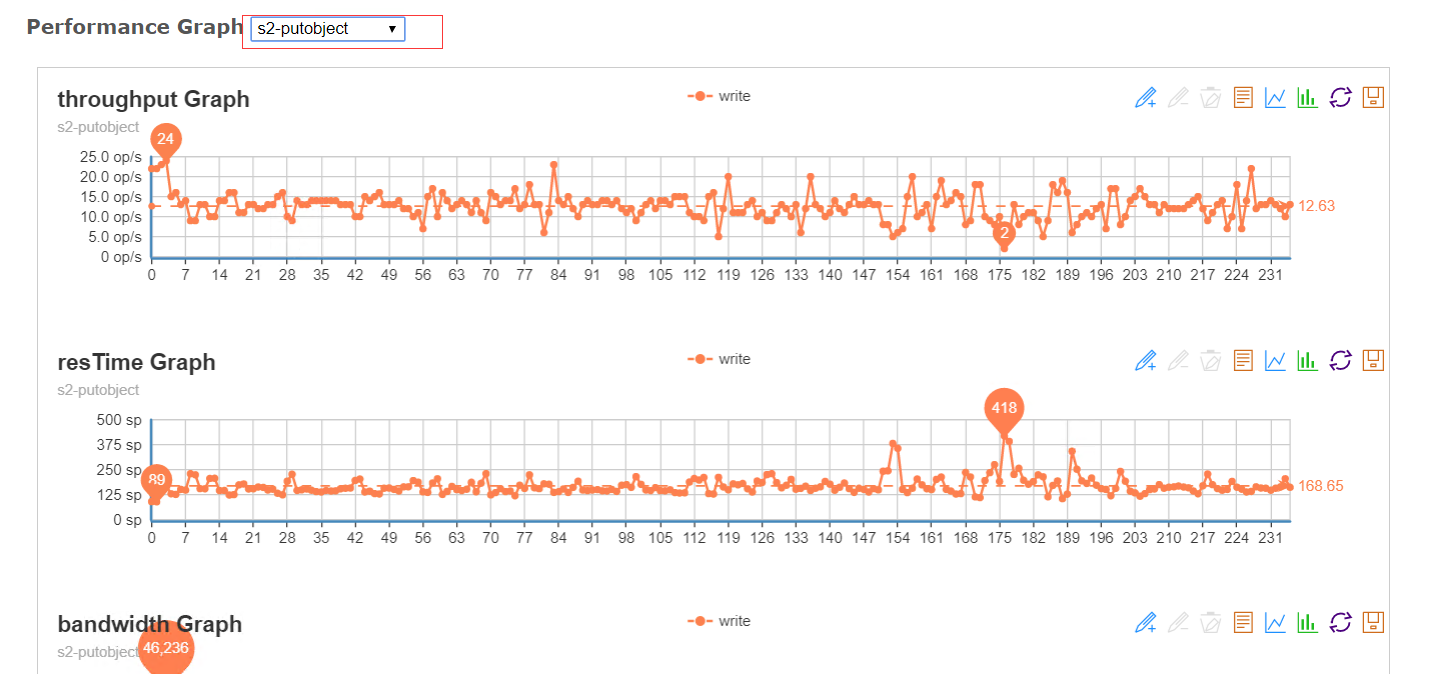
可以通过线图来看指定测试项目的中间情况,一般是去关注是否出现比较大的抖动 ,相同性能下,抖动越小越好
其他调优
在硬件环境一定的情况下,可以通过增加nginx负载均衡,或者lvs负载均衡来尝试增加性能值,这个不在本篇的讨论范围内
补充一个BUG
如果读取的时候,写入的文件数目是正确的,还是get失败,或者前面成功后面失败,那么可能是软件的bug
about setting the property:
stop all cosbench processes (controller, drivers)
edit cosbench-start.sh, locate the java launching line, and add "-Dcom.amazonaws.services.s3.disableGetObjectMD5Validation=true"
restart cosbench processes
来源:
https://github.com/intel-cloud/cosbench/issues/320
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2018-04-12 |
| 修改测试模式时间为文件数目控制 | 武汉-运维-磨渣 | 2019-03-15 |
cosbench使用方法的更多相关文章
- javaSE27天复习总结
JAVA学习总结 2 第一天 2 1:计算机概述(了解) 2 (1)计算机 2 (2)计算机硬件 2 (3)计算机软件 2 (4)软件开发(理解) 2 (5) ...
- 公网访问COSBench controller页面实现方法
总体实现思路:公网域名+nginx代理功能 条件: COSBench部署完毕,修改cosbench配置文件并启动,将127.0.0.1修改为本机IP,如:192.168.63.190 部署对外公网可以 ...
- cosbench 异常 FreeMarker template error: The following has evaluated to null or missing
问题现象: 使用Cosbench 0.4.2.c4 版本测试Ceph RGW read test失败,遇到异常如下: FreeMarker template error: The following ...
- 几个 Ceph 性能优化的新方法和思路(2015 SH Ceph Day 参后感)
一周前,由 Intel 与 Redhat 在10月18日联合举办了 Shanghai Ceph Day.在这次会议上,多位专家做了十几场非常精彩的演讲.本文就这些演讲中提到的 Ceph性能优化方面的知 ...
- 修改Cosbench源码 支持s3的 http range request 测试场景
在视频点播的业务应用场景中,用户使用了ffmpeg工具做视频实时转码用. 而ffmpeg使用range 请求.而Cosbench不支持这种测试场景,所以需要修改源码支持这种测试场景. HTTP 协议介 ...
- Cosbench测试 RGW S3 path_style_access=true模式支持
使用Ceph RGW Cosbench 测试时,文档中没有写如何使用 path_style_access 模式的方法. 查看了一下cosbench源码发现已经支持,只是文档没有写. 提交了一个iss ...
- cosbench 安装
cosbench是什么 COSBench是Intel团队基于java开发,衡量云对象存储服务性能的基准测试工具,全称是Cloud object Storage Bench,同所有的性能测试工具一样,C ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- 【.net 深呼吸】细说CodeDom(6):方法参数
本文老周就给大伙伴们介绍一下方法参数代码的生成. 在开始之前,先补充一下上一篇烂文的内容.在上一篇文章中,老周检讨了 MemberAttributes 枚举的用法,老周此前误以为该枚举不能进行按位操作 ...
随机推荐
- PHP SPL标准库-接口
PHP SPL标准库有一下接口: Countable OuterIterator RecursiveIterator SeekableIterator SplObserver SplSubject A ...
- js后台提交成功后 关闭当前页 并刷新父窗体
后台提交成功后 关闭当前页 并刷新父窗体 this.ClientScript.RegisterStartupScript(this.GetType(), "message", &q ...
- 500G Python从入门到进阶的视频资料
第一部分:Python资源500G百度网盘学习视频300+本电子书需要的小伙伴可以叫小编的Q群867067945 点击展开,查看完整图片 回复关键字:学习第二部分:Python就业指导 更多更详细的就 ...
- 如何使用dos,以及一些简单的dos命令
一. 如何打开dos窗口 1. 按下 windos键 alt ctrl 之间的键 或者打开开始 菜单 输入 cmd 名令 2. win + r 键 输入 cmd 打开 d ...
- 实战二:nacos服务注册与发现,openfeign服务调用
一,参照上一篇创建好微服务结构后,按业务需求编写各微服务逻辑 二,服务注册 1,安装nacos:下载,解压,运行startup.cmd 2,访问 http://localhost:8848/nacos ...
- 入门 第一个python可视化程序 基于pyqt5
不得不说 py的GUI实在是太难上手了 我现在突然很怀念MFC VB c#这些东西了 因为控件的代码你只要一点就能进入查看 而pyqt5 pyside2 都不可以 你要看就看全部的代码 你要改你也只能 ...
- 使用Socket通信(二)
这个socket有梗,主要是服务器端有梗,可能大家会碰到同样的问题,网上查了好久,这里分享一下解决办法.首先在第一个module建一个类SimpleServer,这个类就是服务端,建好之后在代码左边有 ...
- promise解决微信小程序中的request回调地狱
//使用 request(url,methods ,data).then(res => { //服务器返回数据 console.log(res ); return request(url,met ...
- JavaScript实现基于对象的队列
class Queue { constructor() { this.count = 0; this.lowestCount = 0; this.items = {}; } enqueue(eleme ...
- 世界碰撞算法原理和总结(sat gjk)
序言 此文出于作者的想法,从各处文章和论文中,总结和设计项目中碰撞结构处理方法.如有其它见解,可以跟作者商讨.(杨子剑,zijian_yang@yeah.net). 在一个世界中,有多个物体,物体可以 ...