python 数据清洗之数据合并、转换、过滤、排序
前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作,
数据清洗一直是数据分析中极为重要的一个环节。
数据合并
在pandas中可以通过merge对数据进行合并操作。
import numpy as np
import pandas as pd
data1 = pd.DataFrame({'level':['a','b','c','d'],
'numeber':[1,3,5,7]})
data2=pd.DataFrame({'level':['a','b','c','e'],
'numeber':[2,3,6,10]})
print(data1)
结果为:

print(data2)
结果为:
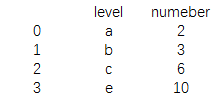
print(pd.merge(data1,data2))
结果为:
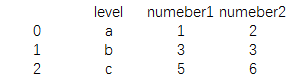
可以看到data1和data2中用于相同标签的字段显示,而其他字段则被舍弃,这相当于SQL中做inner join连接操作。
此外还有outer,ringt,left等连接方式,用关键词how的进行表示。
data3 = pd.DataFrame({'level1':['a','b','c','d'],
'numeber1':[1,3,5,7]})
data4=pd.DataFrame({'level2':['a','b','c','e'],
'numeber2':[2,3,6,10]})
print(pd.merge(data3,data4,left_on='level1',right_on='level2'))
结果为:
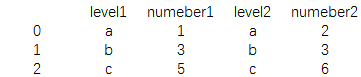
两个数据框中如果列名不同的情况下,我们可以通过指定letf_on 和right_on两个参数把数据连接在一起
print(pd.merge(data3,data4,left_on='level1',right_on='level2',how='left'))
结果为:
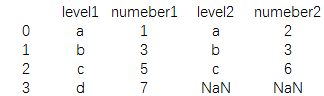
其他详细参数说明
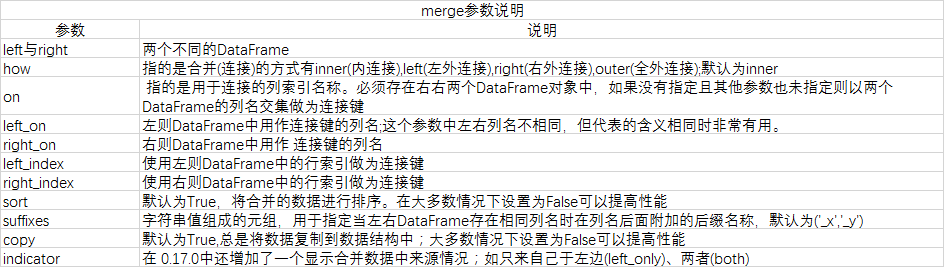
重叠数据合并
有时候我们会遇到重叠数据需要进行合并处理,此时可以用comebine_first函数。
data3 = pd.DataFrame({'level':['a','b','c','d'],
'numeber1':[1,3,5,np.nan]})
data4=pd.DataFrame({'level':['a','b','c','e'],
'numeber2':[2,np.nan,6,10]})
print(data3.combine_first(data4))
结果为:

可以看到相同标签下的内容优先显示data3的内容,如果一个数据框中的某一个数据是缺失的,此时另外一个数据框中的元素就会补上
这里的用法类似于np.where(isnull(a),b,a)
数据重塑和轴向旋转
这个内容我们在上一篇pandas文章有提到过。数据重塑主要使用reshape函数,旋转主要使用unstack和stack两个函数。
data=pd.DataFrame(np.arange(12).reshape(3,4),
columns=['a','b','c','d'],
index=['wang','li','zhang'])
print(data)
结果为:
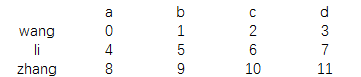
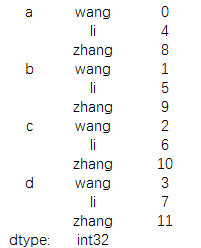
print(data.unstack())
结果为:
数据转换
删除重复行数据
data=pd.DataFrame({'a':[1,3,3,4],
'b':[1,3,3,5]})
print(data)
结果为:
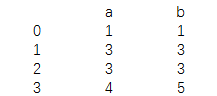
print(data.duplicated())
结果为:

可以看出第三行是重复第二行的数据所以,显示结果为True
另外用drop_duplicates方法可以去除重复行
print(data.drop_duplicates())
结果为:
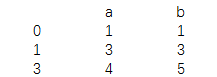
替换值
除了使用我们上一篇文章中提到的fillna的方法外,还可以用replace方法,而且更简单快捷
data=pd.DataFrame({'a':[1,3,3,4],
'b':[1,3,3,5]})
print(data.replace(1,2))
结果为:
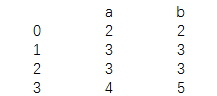
多个数据一起换
print(data.replace([1,4],np.nan))
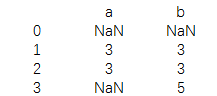
数据分段
data=[11,15,18,20,25,26,27,24]
bins=[15,20,25]
print(data)
print(pd.cut(data,bins))
结果为:
[11, 15, 18, 20, 25, 26, 27, 24]
[NaN, NaN, (15, 20], (15, 20], (20, 25], NaN, NaN, (20, 25]]
Categories (2, object): [(15, 20] < (20, 25]]
可以看出分段后的结果,不在分段内的数据显示为na值,其他则显示数据所在的分段。
print(pd.cut(data,bins).labels)
结果为:
[-1 -1 0 0 1 -1 -1 1]
显示所在分段排序标签
print(pd.cut(data,bins).levels)
结果为:
Index(['(15, 20]', '(20, 25]'], dtype='object')
显示所以分段标签
print(value_counts(pd.cut(data,bins)))
结果为:

显示每个分段值得个数
此外还有一个qcut的函数可以对数据进行4分位切割,用法和cut类似。
排列和采样
我们知道排序的方法有好几个,比如sort,order,rank等函数都能对数据进行排序
现在要说的这个是对数据进行随机排序(permutation)
data=np.random.permutation(5)
print(data)
结果为:
[1 0 4 2 3]
这里的peemutation函数对0-4的数据进行随机排序的结果。
也可以对数据进行采样
df=pd.DataFrame(np.arange(12).reshape(4,3))
samp=np.random.permutation(3)
print(df)
结果为:
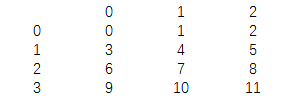
print(samp)
结果为:
[1 0 2]
print(df.take(samp))
结果为:

这里使用take的结果是,按照samp的顺序从df中提取样本。
python 数据清洗之数据合并、转换、过滤、排序的更多相关文章
- 吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库.安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html 其中操作Mysql使 ...
- vue遍历数据是对数据进行筛选 过滤 排序
使用computed 方法来过滤筛选数据;或者使用methods 方式来筛选过滤数据 <body> <div id="app"> <ul> &l ...
- Java Swing实现展示数据,以及过滤排序
public class RelationCostctrTable extends DefaultTableModel { public RelationCostctrTable(Vector< ...
- python剑指offer 合并两个排序的链表
题目描述 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. # -*- coding:utf-8 -*- # class ListNode: # def _ ...
- python 数据合并
1. 数据合并 前言 一.横向合并 1. 基本合并语句 2. 键值名不一样的合并 3. “两个数据列名字重复了”的合并 二.纵向堆叠 统计师的Python日记[第6天:数据合并] 前言 根据我的Pyt ...
- 【python cookbook】【数据结构与算法】19.同时对数据做转换和换算
问题:我们需要调用一个换算函数(例如sum().min().max()),但是首先需对数据做转换或者筛选处理 解决方案:非常优雅的方法---在函数参数中使用生成器表达式 例如: # 计算平方和 num ...
- Python中xml、字典、json、类四种数据的转换
最近学python,觉得python很强很大很强大,写一个学习随笔,当作留念注:xml.字典.json.类四种数据的转换,从左到右依次转换,即xml要转换为类时,先将xml转换为字典,再将字典转换为j ...
- 【剑指Offer】合并两个排序的链表 解题报告(Python)
[剑指Offer]合并两个排序的链表 解题报告(Python) 标签(空格分隔): LeetCode 题目地址:https://www.nowcoder.com/ta/coding-interview ...
- Python 实现把两个排好序的的列表合并成一个排序列表
列表是升序的 # -*- coding: utf-8 -*- # 合并两个排序的数组 def merge_list(a, b): if not a: return b if not b: return ...
随机推荐
- .NET重构—单元测试重构
.NET重构—单元测试重构 阅读目录: 1.开篇介绍 2.单元测试.测试用例代码重复问题(大量使用重复的Mock对象及测试数据) 2.1.单元测试的继承体系(利用超类来减少Mock对象的使用) 2.1 ...
- General Structure of Quartz.NET and How To Implement It
General Structure of Quartz.NET and How To Implement It General Structure of Quartz.NET and How To ...
- 企业架构研究总结(33)——TOGAF架构内容框架之架构制品(上)
4. 架构制品(Architectural Artifacts) 架构制品是针对某个系统或解决方案的模型描述,与架构交付物和构建块相比,架构制品既不是架构开发方法过程各阶段的合约性产物,亦不是企业中客 ...
- 简明CSS属性:定位
简明CSS属性:定位 第一话 定位 (Positioning) 关键词:position/z-index/top/bottom/right/left/clip POSITION 该属性用来决定元素在页 ...
- C#执行cmd命令
public class Console : IRun { public Console(){ ; } public string Result { get; set; } public string ...
- ASP.NET MVC页面UI之多级数据选择UI(行业信息、专业信息、职位信息的选择)
多级数据选择操作在开发中是常见的操作,比如选择行业信息时,一般有个大类,每个大类下边又包含很多小类,本文简单实现了弹出窗口一级一级选择功能. 本文博客出处:http://www.kwstu.com/A ...
- GC算法精解(五分钟教你终极算法---分代搜集算法)
GC算法精解(五分钟教你终极算法---分代搜集算法) 引言 何为终极算法? 其实就是现在的JVM采用的算法,并非真正的终极.说不定若干年以后,还会有新的终极算法,而且几乎是一定会有,因为LZ相信高人们 ...
- 使用upstream和subrequest访问第三方服务
本文是对陶辉<深入理解Nginx>第5章内容的梳理以及实现,代码和注释基本出自此书. 一.upstream:以向nginx服务器的请求转化为向google服务器的搜索请求为例 (一)模块框 ...
- 使用 Spring 2.5 TestContext 测试DAO层
资源准备: mysql5.0 spring-2.5 hibernate-3.2 junit-4.jar 创建表 DROP TABLE IF EXISTS `myproject`.`boys`; ...
- JAXP进行DOM和SAX解析
1.常用XML的解析方式:DOM和SAX 1)DOM思想:将整个XML加载内存中,形成文档对象,所以对XML操作都对内存中文档对象进行. 2)SAX思想:一边解析,一边处理,一边释放内存资源---不允 ...