并发-CopyOnWrite源码分析
CopyOnWrite源码分析
参考:
https://blog.csdn.net/linsongbin1/article/details/54581787
http://ifeve.com/java-copy-on-write/
https://www.cnblogs.com/leesf456/p/5547853.html
CopyOnWriteArrayList可以用于什么应用场景?
先写一段代码证明CopyOnWriteArrayList确实是线程安全的。
ReadThread.Java
import java.util.List;
public class ReadThread implements Runnable {
private List<Integer> list;
public ReadThread(List<Integer> list) {
this.list = list;
}
@Override
public void run() {
for (Integer ele : list) {
System.out.println("ReadThread:"+ele);
}
}
}
WriteThread.java
import java.util.List;
public class WriteThread implements Runnable {
private List<Integer> list;
public WriteThread(List<Integer> list) {
this.list = list;
}
@Override
public void run() {
this.list.add(9);
}
}
TestCopyOnWriteArrayList.java
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestCopyOnWriteArrayList {
private void test() {
//1、初始化CopyOnWriteArrayList
List<Integer> tempList = Arrays.asList(new Integer [] {1,2});
CopyOnWriteArrayList<Integer> copyList = new CopyOnWriteArrayList<>(tempList);
//2、模拟多线程对list进行读和写
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.execute(new ReadThread(copyList));
executorService.execute(new WriteThread(copyList));
executorService.execute(new WriteThread(copyList));
executorService.execute(new WriteThread(copyList));
executorService.execute(new ReadThread(copyList));
executorService.execute(new WriteThread(copyList));
executorService.execute(new ReadThread(copyList));
executorService.execute(new WriteThread(copyList));
System.out.println("copyList size:"+copyList.size());
}
public static void main(String[] args) {
new TestCopyOnWriteArrayList().test();
}
}
运行上面的代码,没有报出
java.util.ConcurrentModificationException
1
1
说明了CopyOnWriteArrayList并发多线程的环境下,仍然能很好的工作。
CopyOnWriteArrayList如何做到线程安全的
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
当有新元素加入的时候,如下图,创建新数组,并往新数组中加入一个新元素,这个时候,array这个引用仍然是指向原数组的。
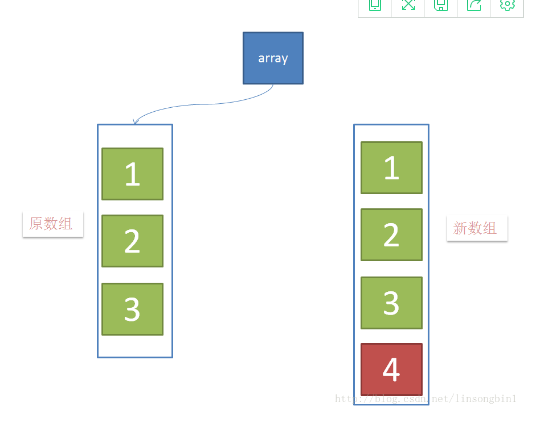
当元素在新数组添加成功后,将array这个引用指向新数组。
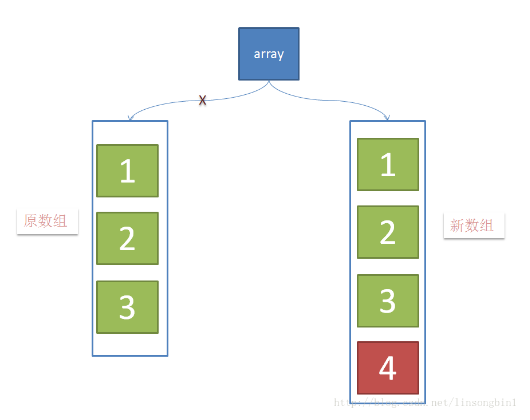
CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。
CopyOnWriteArrayList的add操作的源代码如下:
public boolean add(E e) {
//1、先加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements
= getArray();
int len =
elements.length;
//2、拷贝数组
Object[]
newElements = Arrays.copyOf(elements, len + 1);
//3、将元素加入到新数组中
newElements[len] =
e;
//4、将array引用指向到新数组
setArray(newElements);
return true;
} finally {
//5、解锁
lock.unlock();
}
}
由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制,如果有线程并发的读,则分几种情况:
1、如果写操作未完成,那么直接读取原数组的数据;
2、如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
3、如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
可见,CopyOnWriteArrayList的读操作是可以不用加锁的。
CopyOnWriteArrayList的使用场景
通过上面的分析,CopyOnWriteArrayList 有几个缺点:
1、由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
2、不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
网上的文章都说到,CopyOnWriteArrayList 合适读多写少的场景,比如说缓存。
但是我个人认为CopyOnWriteArrayList 无用武之地,那怕读远远大于写也不能使用CopyOnWriteArrayList,因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
CopyOnWriteArrayList透露的思想
如上面的分析CopyOnWriteArrayList表达的一些思想:
1、读写分离,读和写分开
2、最终一致性
3、使用另外开辟空间的思路,来解决并发冲突
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWriteArrayList的实现原理
在使用CopyOnWriteArrayList之前,我们先阅读其源码了解下它是如何实现的。以下代码是向ArrayList里添加元素,可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
01 |
public boolean add(T e) { |
02 |
final ReentrantLock lock = this.lock; |
03 |
lock.lock(); |
04 |
try { |
05 |
06 |
Object[] elements = getArray(); |
07 |
08 |
int len = elements.length; |
09 |
// 复制出新数组 |
10 |
11 |
Object[] newElements = Arrays.copyOf(elements, len + 1); |
12 |
// 把新元素添加到新数组里 |
13 |
14 |
newElements[len] = e; |
15 |
// 把原数组引用指向新数组 |
16 |
17 |
setArray(newElements); |
18 |
19 |
return true; |
20 |
21 |
} finally { |
22 |
23 |
lock.unlock(); |
24 |
25 |
} |
26 |
27 |
} |
28 |
29 |
final void setArray(Object[] a) { |
30 |
array = a; |
31 |
} |
读的时候不需要加锁,如果读的时候有多个线程正在向ArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的ArrayList。
1 |
public E get(int index) { |
2 |
return get(getArray(), index); |
3 |
} |
JDK中并没有提供CopyOnWriteMap,我们可以参考CopyOnWriteArrayList来实现一个,基本代码如下:
01 |
import java.util.Collection; |
02 |
import java.util.Map; |
03 |
import java.util.Set; |
04 |
05 |
public class CopyOnWriteMap<K, V> implements Map<K, V>, Cloneable { |
06 |
private volatile Map<K, V> internalMap; |
07 |
08 |
public CopyOnWriteMap() { |
09 |
internalMap = new HashMap<K, V>(); |
10 |
} |
11 |
12 |
public V put(K key, V value) { |
13 |
14 |
synchronized (this) { |
15 |
Map<K, V> newMap = new HashMap<K, V>(internalMap); |
16 |
V val = newMap.put(key, value); |
17 |
internalMap = newMap; |
18 |
return val; |
19 |
} |
20 |
} |
21 |
22 |
public V get(Object key) { |
23 |
return internalMap.get(key); |
24 |
} |
25 |
26 |
public void putAll(Map<? extends K, ? extends V> newData) { |
27 |
synchronized (this) { |
28 |
Map<K, V> newMap = new HashMap<K, V>(internalMap); |
29 |
newMap.putAll(newData); |
30 |
internalMap = newMap; |
31 |
} |
32 |
} |
33 |
} |
实现很简单,只要了解了CopyOnWrite机制,我们可以实现各种CopyOnWrite容器,并且在不同的应用场景中使用。
CopyOnWrite的应用场景
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。实现代码如下:
01 |
package com.ifeve.book; |
02 |
03 |
import java.util.Map; |
04 |
05 |
import com.ifeve.book.forkjoin.CopyOnWriteMap; |
06 |
07 |
/** |
08 |
* 黑名单服务 |
09 |
* |
10 |
* @author fangtengfei |
11 |
* |
12 |
*/ |
13 |
public class BlackListServiceImpl { |
14 |
15 |
private static CopyOnWriteMap<String, Boolean> blackListMap = newCopyOnWriteMap<String, Boolean>( |
16 |
1000); |
17 |
18 |
public static boolean isBlackList(String id) { |
19 |
return blackListMap.get(id) == null ? false : true; |
20 |
} |
21 |
22 |
public static void addBlackList(String id) { |
23 |
blackListMap.put(id, Boolean.TRUE); |
24 |
} |
25 |
26 |
/** |
27 |
* 批量添加黑名单 |
28 |
* |
29 |
* @param ids |
30 |
*/ |
31 |
public static void addBlackList(Map<String,Boolean> ids) { |
32 |
blackListMap.putAll(ids); |
33 |
} |
34 |
35 |
} |
代码很简单,但是使用CopyOnWriteMap需要注意两件事情:
1. 减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
2. 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用上面代码里的addBlackList方法。
CopyOnWrite的缺点
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
一、前言
由于Deque与Queue有很大的相似性,Deque为双端队列,队列头部和尾部都可以进行入队列和出队列的操作,所以不再介绍Deque,感兴趣的读者可以自行阅读源码,相信偶了Queue源码的分析经验,Deque的分析也会水到渠成,下面介绍List在JUC下的CopyOnWriteArrayList类,CopyOnWriteArrayList是ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
二、CopyOnWriteArrayList数据结构
通过源码分析可知,CopyOnWriteArrayList使用的数据结构是数组。结构如下
说明:CopyOnWriteArrayList底层使用数组来存放元素。
三、CopyOnWriteArrayList源码分析
3.1 类的继承关系
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {}
说明:CopyOnWriteArrayList实现了List接口,List接口定义了对列表的基本操作;同时实现了RandomAccess接口,表示可以随机访问(数组具有随机访问的特性);同时实现了Cloneable接口,表示可克隆;同时也实现了Serializable接口,表示可被序列化。
3.2 类的内部类
1. COWIterator类
复制代码
static final class COWIterator<E> implements ListIterator<E> {
/** Snapshot of the array */
// 快照
private final Object[] snapshot;
/** Index of element to be returned by subsequent call to next. */
// 游标
private int cursor;
// 构造函数
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
// 是否还有下一项
public boolean hasNext() {
return cursor < snapshot.length;
}
// 是否有上一项
public boolean hasPrevious() {
return cursor > 0;
}
// next项
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext()) // 不存在下一项,抛出异常
throw new NoSuchElementException();
// 返回下一项
return (E) snapshot[cursor++];
}
@SuppressWarnings("unchecked")
public E previous() {
if (! hasPrevious())
throw new NoSuchElementException();
return (E) snapshot[--cursor];
}
// 下一项索引
public int nextIndex() {
return cursor;
}
// 上一项索引
public int previousIndex() {
return cursor-1;
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code remove}
* is not supported by this iterator.
*/
// 不支持remove操作
public void remove() {
throw new UnsupportedOperationException();
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code set}
* is not supported by this iterator.
*/
// 不支持set操作
public void set(E e) {
throw new UnsupportedOperationException();
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code add}
* is not supported by this iterator.
*/
// 不支持add操作
public void add(E e) {
throw new UnsupportedOperationException();
}
@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
Object[] elements = snapshot;
final int size = elements.length;
for (int i = cursor; i < size; i++) {
@SuppressWarnings("unchecked") E e = (E) elements[i];
action.accept(e);
}
cursor = size;
}
}
复制代码
说明:COWIterator表示迭代器,其也有一个Object类型的数组作为CopyOnWriteArrayList数组的快照,这种快照风格的迭代器方法在创建迭代器时使用了对当时数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出 ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作(remove、set 和 add)不受支持。这些方法将抛出 UnsupportedOperationException。
3.3 类的属性
复制代码
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 8673264195747942595L;
// 可重入锁
final transient ReentrantLock lock = new ReentrantLock();
// 对象数组,用于存放元素
private transient volatile Object[] array;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// lock域的内存偏移量
private static final long lockOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = CopyOnWriteArrayList.class;
lockOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("lock"));
} catch (Exception e) {
throw new Error(e);
}
}
}
复制代码
说明:属性中有一个可重入锁,用来保证线程安全访问,还有一个Object类型的数组,用来存放具体的元素。当然,也使用到了反射机制和CAS来保证原子性的修改lock域。
3.4 类的构造函数
1. CopyOnWriteArrayList()型构造函数
public CopyOnWriteArrayList() {
// 设置数组
setArray(new Object[0]);
}
说明:该构造函数用于创建一个空列表。
2. CopyOnWriteArrayList(Collection<? extends E>)型构造函数
复制代码
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class) // 类型相同
// 获取c集合的数组
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else { // 类型不相同
// 将c集合转化为数组并赋值给elements
elements = c.toArray();
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elements.getClass() != Object[].class) // elements类型不为Object[]类型
// 将elements数组转化为Object[]类型的数组
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
// 设置数组
setArray(elements);
}
复制代码
说明:该构造函数用于创建一个按 collection 的迭代器返回元素的顺序包含指定 collection 元素的列表。该构造函数的处理流程如下
① 判断传入的集合c的类型是否为CopyOnWriteArrayList类型,若是,则获取该集合类型的底层数组(Object[]),并且设置当前CopyOnWriteArrayList的数组(Object[]数组),进入步骤③;否则,进入步骤②
② 将传入的集合转化为数组elements,判断elements的类型是否为Object[]类型(toArray方法可能不会返回Object类型的数组),若不是,则将elements转化为Object类型的数组。进入步骤③
③ 设置当前CopyOnWriteArrayList的Object[]为elements。
3. CopyOnWriteArrayList(E[])型构造函数
public CopyOnWriteArrayList(E[] toCopyIn) {
// 将toCopyIn转化为Object[]类型数组,然后设置当前数组
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
说明:该构造函数用于创建一个保存给定数组的副本的列表。
3.5 核心函数分析
对于CopyOnWriteArrayList的函数分析,主要明白Arrays.copyOf方法即可理解CopyOnWriteArrayList其他函数的意义。
1. copyOf函数
复制代码
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
// 确定copy的类型(将newType转化为Object类型,将Object[].class转化为Object类型,判断两者是否相等,若相等,则生成指定长度的Object数组
// 否则,生成指定长度的新类型的数组)
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
// 将original数组从下标0开始,复制长度为(original.length和newLength的较小者),复制到copy数组中(也从下标0开始)
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
复制代码
说明:该函数用于复制指定的数组,截取或用 null 填充(如有必要),以使副本具有指定的长度。
2. add函数
复制代码
public boolean add(E e) {
// 可重入锁
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
try {
// 元素数组
Object[] elements = getArray();
// 数组长度
int len = elements.length;
// 复制数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 存放元素e
newElements[len] = e;
// 设置数组
setArray(newElements);
return true;
} finally {
// 释放锁
lock.unlock();
}
}
复制代码
说明:此函数用于将指定元素添加到此列表的尾部,处理流程如下
① 获取锁(保证多线程的安全访问),获取当前的Object数组,获取Object数组的长度为length,进入步骤②。
② 根据Object数组复制一个长度为length+1的Object数组为newElements(此时,newElements[length]为null),进入步骤③。
③ 将下标为length的数组元素newElements[length]设置为元素e,再设置当前Object[]为newElements,释放锁,返回。这样就完成了元素的添加。
3. addIfAbsent
复制代码
private boolean addIfAbsent(E e, Object[] snapshot) {
// 重入锁
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
try {
// 获取数组
Object[] current = getArray();
// 数组长度
int len = current.length;
if (snapshot != current) { // 快照不等于当前数组,对数组进行了修改
// Optimize for lost race to another addXXX operation
// 取较小者
int common = Math.min(snapshot.length, len);
for (int i = 0; i < common; i++) // 遍历
if (current[i] != snapshot[i] && eq(e, current[i])) // 当前数组的元素与快照的元素不相等并且e与当前元素相等
// 表示在snapshot与current之间修改了数组,并且设置了数组某一元素为e,已经存在
// 返回
return false;
if (indexOf(e, current, common, len) >= 0) // 在当前数组中找到e元素
// 返回
return false;
}
// 复制数组
Object[] newElements = Arrays.copyOf(current, len + 1);
// 对数组len索引的元素赋值为e
newElements[len] = e;
// 设置数组
setArray(newElements);
return true;
} finally {
// 释放锁
lock.unlock();
}
}
复制代码
说明:该函数用于添加元素(如果数组中不存在,则添加;否则,不添加,直接返回)。可以保证多线程环境下不会重复添加元素,该函数的流程如下
① 获取锁,获取当前数组为current,current长度为len,判断数组之前的快照snapshot是否等于当前数组current,若不相等,则进入步骤②;否则,进入步骤④
② 不相等,表示在snapshot与current之间,对数组进行了修改(如进行了add、set、remove等操作),获取长度(snapshot与current之间的较小者),对current进行遍历操作,若遍历过程发现snapshot与current的元素不相等并且current的元素与指定元素相等(可能进行了set操作),进入步骤⑤,否则,进入步骤③
③ 在当前数组中索引指定元素,若能够找到,进入步骤⑤,否则,进入步骤④
④ 复制当前数组current为newElements,长度为len+1,此时newElements[len]为null。再设置newElements[len]为指定元素e,再设置数组,进入步骤⑤
⑤ 释放锁,返回。
4. set函数
复制代码
public E set(int index, E element) {
// 可重入锁
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
try {
// 获取数组
Object[] elements = getArray();
// 获取index索引的元素
E oldValue = get(elements, index);
if (oldValue != element) { // 旧值等于element
// 数组长度
int len = elements.length;
// 复制数组
Object[] newElements = Arrays.copyOf(elements, len);
// 重新赋值index索引的值
newElements[index] = element;
// 设置数组
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
// 设置数组
setArray(elements);
}
// 返回旧值
return oldValue;
} finally {
// 释放锁
lock.unlock();
}
}
复制代码
说明:此函数用于用指定的元素替代此列表指定位置上的元素,也是基于数组的复制来实现的。
5. remove函数
复制代码
public E remove(int index) {
// 可重入锁
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
try {
// 获取数组
Object[] elements = getArray();
// 数组长度
int len = elements.length;
// 获取旧值
E oldValue = get(elements, index);
// 需要移动的元素个数
int numMoved = len - index - 1;
if (numMoved == 0) // 移动个数为0
// 复制后设置数组
setArray(Arrays.copyOf(elements, len - 1));
else { // 移动个数不为0
// 新生数组
Object[] newElements = new Object[len - 1];
// 复制index索引之前的元素
System.arraycopy(elements, 0, newElements, 0, index);
// 复制index索引之后的元素
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
// 设置索引
setArray(newElements);
}
// 返回旧值
return oldValue;
} finally {
// 释放锁
lock.unlock();
}
}
复制代码
说明:此函数用于移除此列表指定位置上的元素。处理流程如下
① 获取锁,获取数组elements,数组长度为length,获取索引的值elements[index],计算需要移动的元素个数(length - index - 1),若个数为0,则表示移除的是数组的最后一个元素,复制elements数组,复制长度为length-1,然后设置数组,进入步骤③;否则,进入步骤②
② 先复制index索引前的元素,再复制index索引后的元素,然后设置数组。
③ 释放锁,返回旧值。
四、示例
下面通过一个示例来了解CopyOnWriteArrayList的使用
复制代码
package com.hust.grid.leesf.collections;
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
class PutThread extends Thread {
private CopyOnWriteArrayList<Integer> cowal;
public PutThread(CopyOnWriteArrayList<Integer> cowal) {
this.cowal = cowal;
}
public void run() {
try {
for (int i = 100; i < 110; i++) {
cowal.add(i);
Thread.sleep(50);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class CopyOnWriteArrayListDemo {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> cowal = new CopyOnWriteArrayList<Integer>();
for (int i = 0; i < 10; i++) {
cowal.add(i);
}
PutThread p1 = new PutThread(cowal);
p1.start();
Iterator<Integer> iterator = cowal.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
System.out.println();
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
iterator = cowal.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
}
}
复制代码
运行结果(某一次)
0 1 2 3 4 5 6 7 8 9 100
0 1 2 3 4 5 6 7 8 9 100 101 102 103
说明:在程序中,有一个PutThread线程会每隔50ms就向CopyOnWriteArrayList中添加一个元素,并且两次使用了迭代器,迭代器输出的内容都是生成迭代器时,CopyOnWriteArrayList的Object数组的快照的内容,在迭代的过程中,往CopyOnWriteArrayList中添加元素也不会抛出异常。
五、总结
CopyOnWriteArrayList的源码很简单,其主要用到的快照的思路,使得在迭代的过程中,只是Object数组之前的某个快照,而不是最新的Object,这样可以保证在迭代的过程中不会抛出ConcurrentModificationException异常。
一、前言
分析完了CopyOnWriteArrayList后,下面接着分析CopyOnWriteArraySet,CopyOnWriteArraySet与CopyOnWriteArrayList有莫大的联系,因为CopyOnWriteArraySet的底层是由CopyOnWriteArrayList提供支持,并且将对其的操作转发至对CopyOnWriteArrayList的操作。但是,CopyOnWriteArraySet的元素不允许重复,这是和CopyOnWriteArrayList不相同的地方,下面开始分析。
二、CopyOnWriteArraySet数据结构
由于CopyOnWriteArraySet底层是使用CopyOnWriteArrayList,所以其数据结构与CopyOnWriteArrayList相同,采用数组结构。其结构如下
说明:CopyOnWriteArraySet由于是基于CopyOnWriteArrayList的,所以对其操作都是基于CopyOnWriteArrayList的,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
三、CopyOnWriteArraySet源码分析
3.1 类的继承关系
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable {}
说明:CopyOnWriteArraySet继承了AbstractSet抽象类,AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作;同时实现了Serializable接口,表示可以序列化。
3.2 类的属性
复制代码
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 5457747651344034263L;
// 由其对CopyOnWriteArraySet提供支持
private final CopyOnWriteArrayList<E> al;
}
复制代码
说明:其属性中包含了一个CopyOnWriteArrayList类型的变量al,对CopyOnWriteArraySet的操作会转发至al上执行。
3.3 类的构造函数
1. CopyOnWriteArraySet()型构造函数
public CopyOnWriteArraySet() {
// 初始化al
al = new CopyOnWriteArrayList<E>();
}
说明:此构造函数用于创建一个空 set。
2. CopyOnWriteArraySet(Collection<? extends E>)型构造函数
复制代码
public CopyOnWriteArraySet(Collection<? extends E> c) {
if (c.getClass() == CopyOnWriteArraySet.class) { // c集合为CopyOnWriteArraySet类型
// 初始化al
@SuppressWarnings("unchecked") CopyOnWriteArraySet<E> cc =
(CopyOnWriteArraySet<E>)c;
al = new CopyOnWriteArrayList<E>(cc.al);
}
else { // c集合不为CopyOnWriteArraySet类型
// 初始化al
al = new CopyOnWriteArrayList<E>();
// 添加c集合(c集合的元素在al中部存在时,才会添加)
al.addAllAbsent(c);
}
}
复制代码
说明:此构造函数用于创建一个包含指定 collection 所有元素的 set。处理流程如下
① 判断集合c的类型是否为CopyOnWriteArraySet类型,若是,则获取c的al,并且初始当前CopyOnWriteArraySet的al域(调用CopyOnWriteArrayList的构造函数),否则,进入步骤②
② 新生CopyOnWriteArrayList,并赋值给al,之后调用addAllIfAbsent函数(al中不存在的元素,才添加)。
3.4 核心函数分析
由于对CopyOnWriteArraySet的操作(如add、remove、clear等)都转化为对CopyOnWriteArrayList的操作,所以在此不再进行讲解,有疑惑的读者可以参考CopyOnWriteArrayList的源码分析。
四、示例
下面通过一个示例来了解CopyOnWriteArraySet的使用。
复制代码
package com.hust.grid.leesf.collections;
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArraySet;
class PutThread extends Thread {
private CopyOnWriteArraySet<Integer> cowas;
public PutThread(CopyOnWriteArraySet<Integer> cowas) {
this.cowas = cowas;
}
public void run() {
for (int i = 0; i < 10; i++) {
cowas.add(i);
}
}
}
public class CopyOnWriteArraySetDemo {
public static void main(String[] args) {
CopyOnWriteArraySet<Integer> cowas = new CopyOnWriteArraySet<Integer>();
for (int i = 0; i < 10; i++) {
cowas.add(i);
}
PutThread p1 = new PutThread(cowas);
p1.start();
Iterator<Integer> iterator = cowas.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
System.out.println();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
iterator = cowas.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
}
}
复制代码
运行结果(某一次)
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
说明:首先,主线程向CopyWriteArraySet也添加了元素,然后,PutThread线程向CopyOnWriteArraySet中添加元素(与之前添加了元素重复),两次迭代,遍历集合,发现结果相同,即CopyWriteArraySet中没有重复的元素。
五、总结
CopyOnWriteArraySet的源码比较简单,是依托CopyOnWriteArrayList而言,所以当分析完了CopyOnWriteArrayList后,CopyOnWriteArraySet的分析就非常简单
并发-CopyOnWrite源码分析的更多相关文章
- 并发-AQS源码分析
AQS源码分析 参考: http://www.cnblogs.com/waterystone/p/4920797.html https://blog.csdn.net/fjse51/article/d ...
- 并发-AtomicInteger源码分析—基于CAS的乐观锁实现
AtomicInteger源码分析—基于CAS的乐观锁实现 参考: http://www.importnew.com/22078.html https://www.cnblogs.com/mantu/ ...
- 并发-ConcurrentHashMap源码分析
ConcurrentHashMap 参考: http://www.cnblogs.com/chengxiao/p/6842045.html https://my.oschina.net/hosee/b ...
- 并发-ThreadLocal源码分析
ThreadLocal源码分析 参考: http://www.cnblogs.com/dolphin0520/p/3920407.html https://www.cnblogs.com/coshah ...
- java并发:join源码分析
join join join是Thread方法,它的作用是A线程中子线程B在运行之后调用了B.join(),A线程会阻塞直至B线程执行结束 join源码(只有继承Thread类才能使用) 基于open ...
- JUC源码分析-集合篇:并发类容器介绍
JUC源码分析-集合篇:并发类容器介绍 同步类容器是 线程安全 的,如 Vector.HashTable 等容器的同步功能都是由 Collections.synchronizedMap 等工厂方法去创 ...
- 并发编程(四):ThreadLocal从源码分析总结到内存泄漏
一.目录 1.ThreadLocal是什么?有什么用? 2.ThreadLocal源码简要总结? 3.ThreadLocal为什么会导致内存泄漏? 二.ThreadLoc ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- Java并发系列[3]----AbstractQueuedSynchronizer源码分析之共享模式
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快 ...
随机推荐
- spring boot 整合kafka 报错 Exception thrown when sending a message with key='null' and payload=JSON to topic proccess_trading_end: TimeoutException: Failed to update metadata after 60000 ms.
org.springframework.kafka.support.LoggingProducerListener- Exception thrown when sending a message w ...
- noip2006 金明的预算
题目链接:传送门 题目大意:略.. 题目思路:其实单就这道题来说,一个主件最多两个附件,且附件不再包含附件,所以很简单,但是如果主件的附件无限制,附件也可包含无限制的附件,应该怎么做? 首先推荐一篇论 ...
- 【BZOJ4571】[Scoi2016]美味 主席树
[BZOJ4571][Scoi2016]美味 Description 一家餐厅有 n 道菜,编号 1...n ,大家对第 i 道菜的评价值为 ai(1≤i≤n).有 m 位顾客,第 i 位顾客的期望值 ...
- delphi ---ttoolbar,ttoolbutton
1.button style:tbsButton,tbsCheck,tbsDivider,tbsDropDown,tbsSeparator,tbsTextButton tbsButton:普通的控件 ...
- 巨蟒python全栈开发数据库攻略2:基础攻略2
1.存储引擎表类型 2.整数类型和sql_mode 3.浮点类&字符串类型&日期类型&集合类型&枚举类型 4.数值类型补充 5.完整性约束
- Java Concurrency In Practice
线程安全 定义 A class is thread-safe if it behaves correctly when accessed from multiple threads, regardle ...
- 常用的SQLalchemy 字段类型
https://blog.csdn.net/weixin_41896508/article/details/80772238 常用的SQLAlchemy字段类型 类型名 python中类型 说明 In ...
- json.dumps 和 json.dump的区别,load和loads的区别
json.dumps 和 json.dump的区别,load和loads的区别
- Java集合的遍历方式
Map的遍历 1.通过map.entrySet遍历Key和Value Map<Integer,Integer> map = new HashMap<>(); map.put(1 ...
- SPL(Standard PHP Library 标准PHP类库)
SplFileObject 读取大文件从第N行开始读: $line = 10; $splFileObj = new SplFileObject(__FILE__,'r'); $splFileObj-& ...