cmu15545笔记-查询执行(Query Excution)
执行模型
执行模型(Processing Model)定义了数据库系统如何执行一个查询计划。
Iterator Model
基本思想:采用树形结构组织操作符,然后中序遍历执行整棵树,最终根结点的输出就是整个查询计划的结果。
每个操作符(Operator)实现如下函数:
Next()- 返回值:一个tuple或者EOF。
- 执行流程:循环调用孩子结点的
Next()函数。
Open()和Close():类似于构造和析构函数。
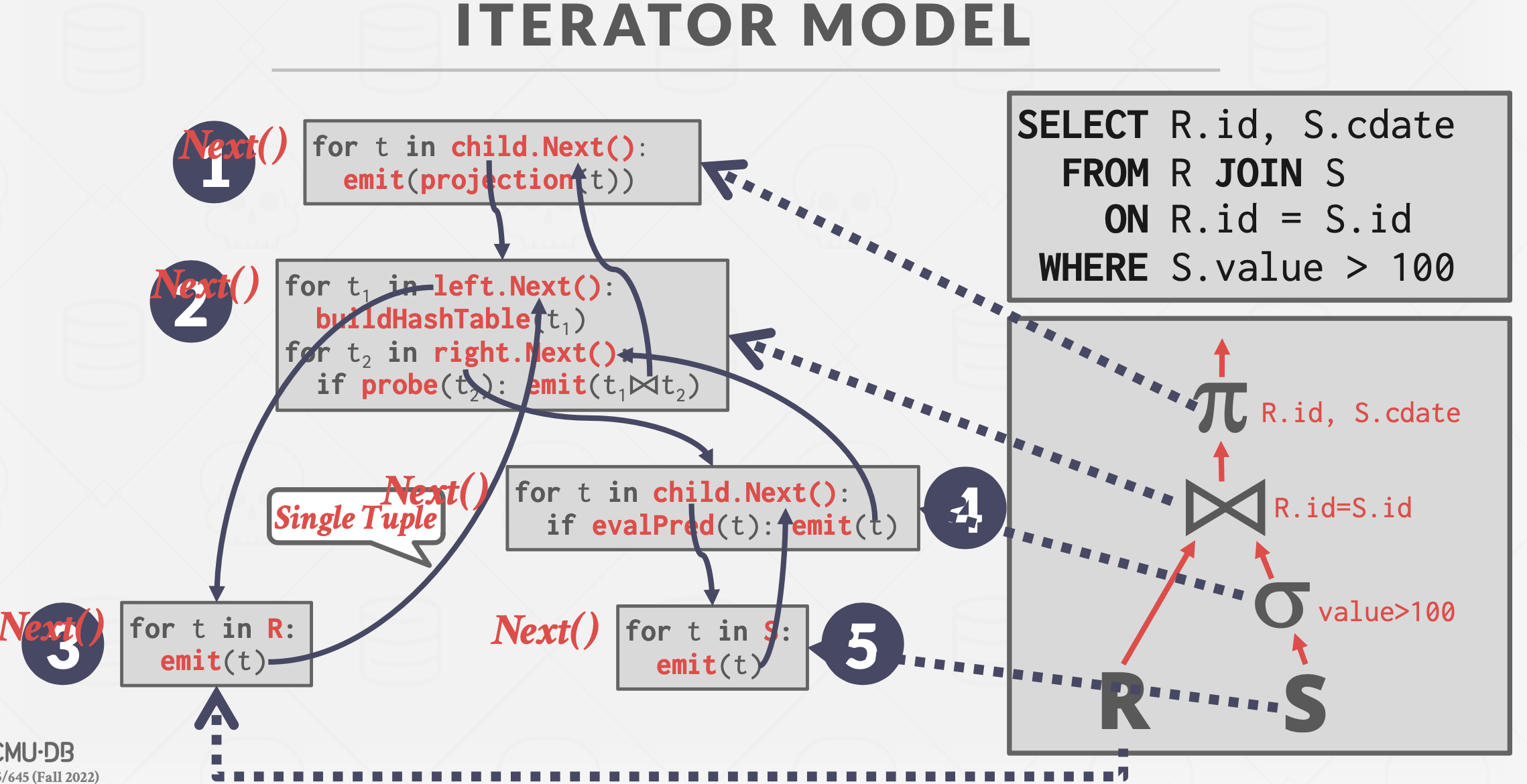
输出从底部向顶部(Bottom-To-Top)汇聚,且支持流式操作,所以又称为Valcano Model,Pipeline Model。
Materialization Model
基本思想:操作符不是一次返回一个数据,暂存下所有数据,一次返回给父结点。
相比于Iterator Model,减少了函数调用开销,但是中间结果可能要暂存磁盘,IO开销大。
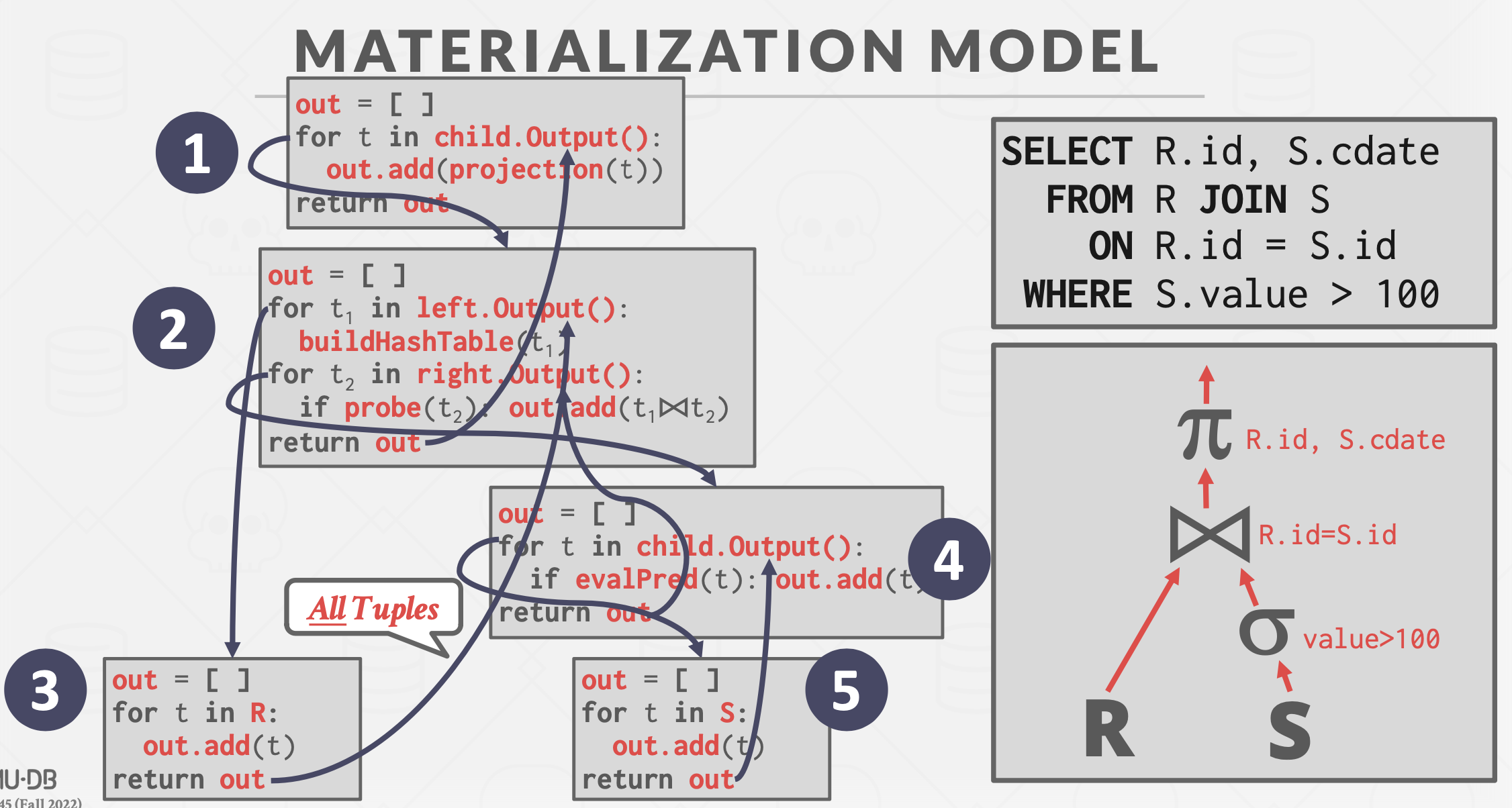
可以向下传递一些暗示(hint),如Limit,避免扫描过多的数据。
更适用于OLTP而不是OLAP。
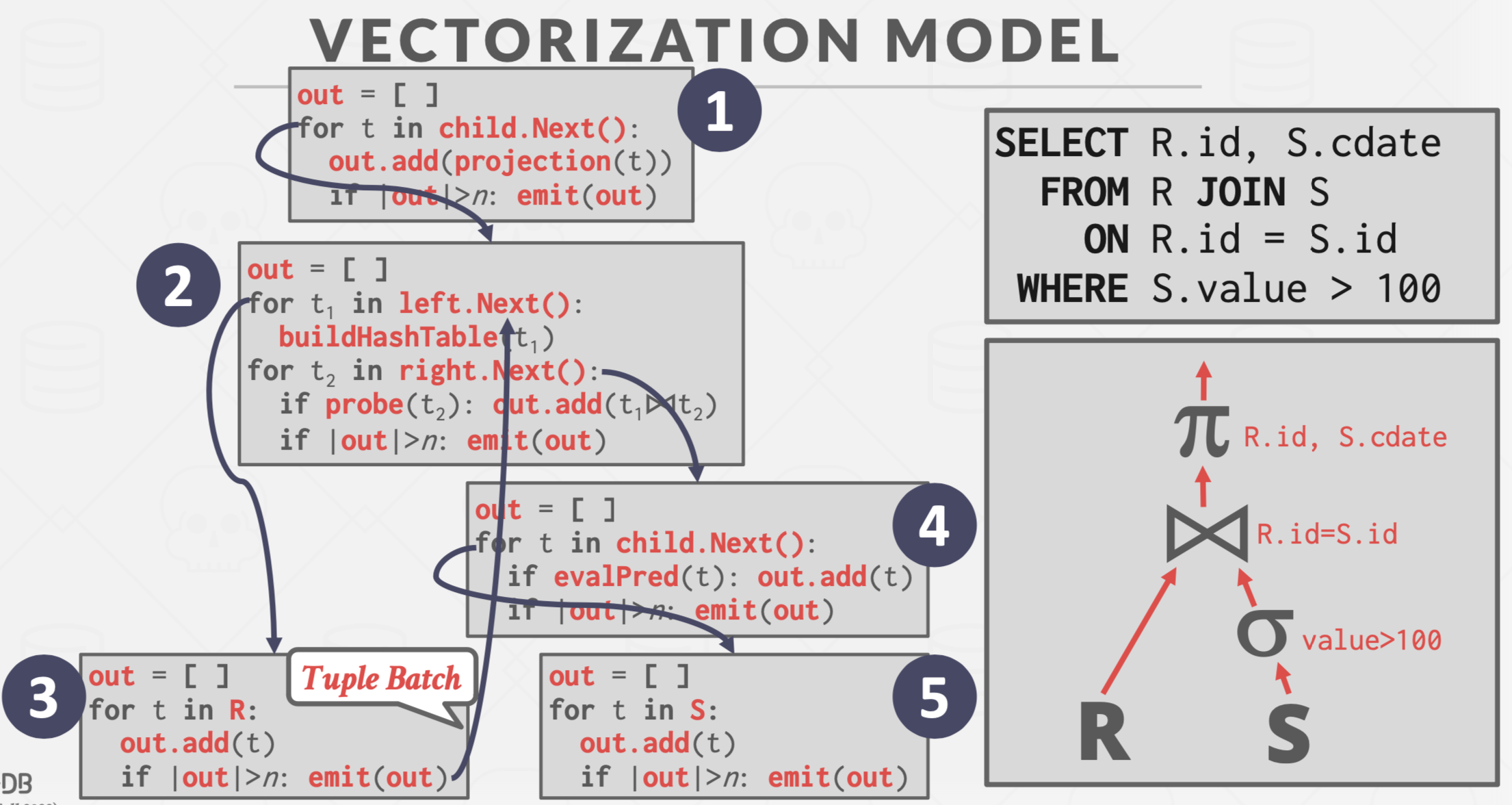
Vectoriazation Model
基本思想:操作符返回一批数据。
结合了Iterator Model和Materialization Model的优势,既减少了函数调用,中间结果又不至于过大。
可以采用SIMD指令加速批数据的处理。
对比
| 特性 | Iterator Model | Materialization Model | Vectorization Model |
|---|---|---|---|
| 数据处理单位 | 单条记录(tuple-at-a-time) | 整个中间结果(table-at-a-time) | 批量记录(vector/batch-at-a-time) |
| 性能 | 函数调用开销高,效率低 | 延迟高,内存/I/O 开销大 | 函数调用开销低,SIMD 加速性能优异 |
| 内存使用 | 内存需求低 | 内存需求高 | 中等 |
| I/O 开销 | 低 | 高 | 中等 |
| 缓存利用率 | 差 | 差 | 高 |
| 复杂性 | 实现简单 | 中等 | 实现复杂 |
| 适用场景 | 小型数据集,流式处理 | 中间结果复用的复杂查询 | 大型数据集,需高性能计算的场景 |
数据访问方式
主要有三种数据访问方式:
- 全表扫描(Sequential Scan)
- 索引扫描(Index Scan)
- 多索引扫描(Multi-Index Scan)
Sequential Scan
全表扫描的优化手段:

Data Skipping方法:
- 只需要大致结果:采样估计。
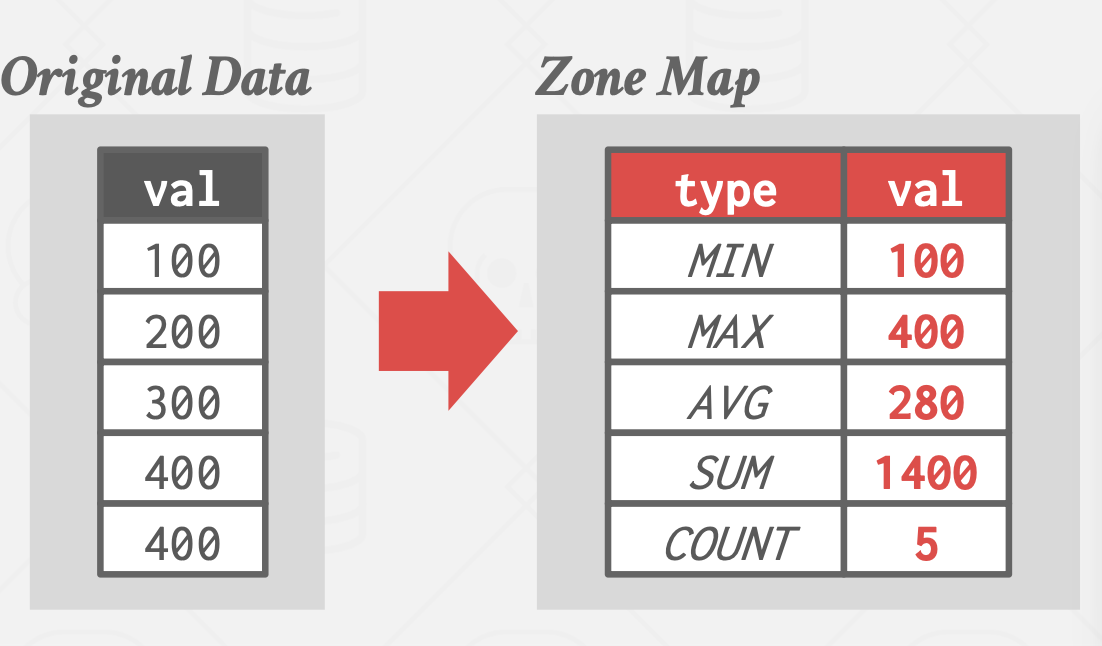
- 精确结果:Zone Map

Zone Map基本思想:化整为零,提前对数据页进行聚合。
执行 Select * From table Where val > 600时,下面的页可以直接跳过。
Index Scan
如何确定使用哪个索引:数据分布。

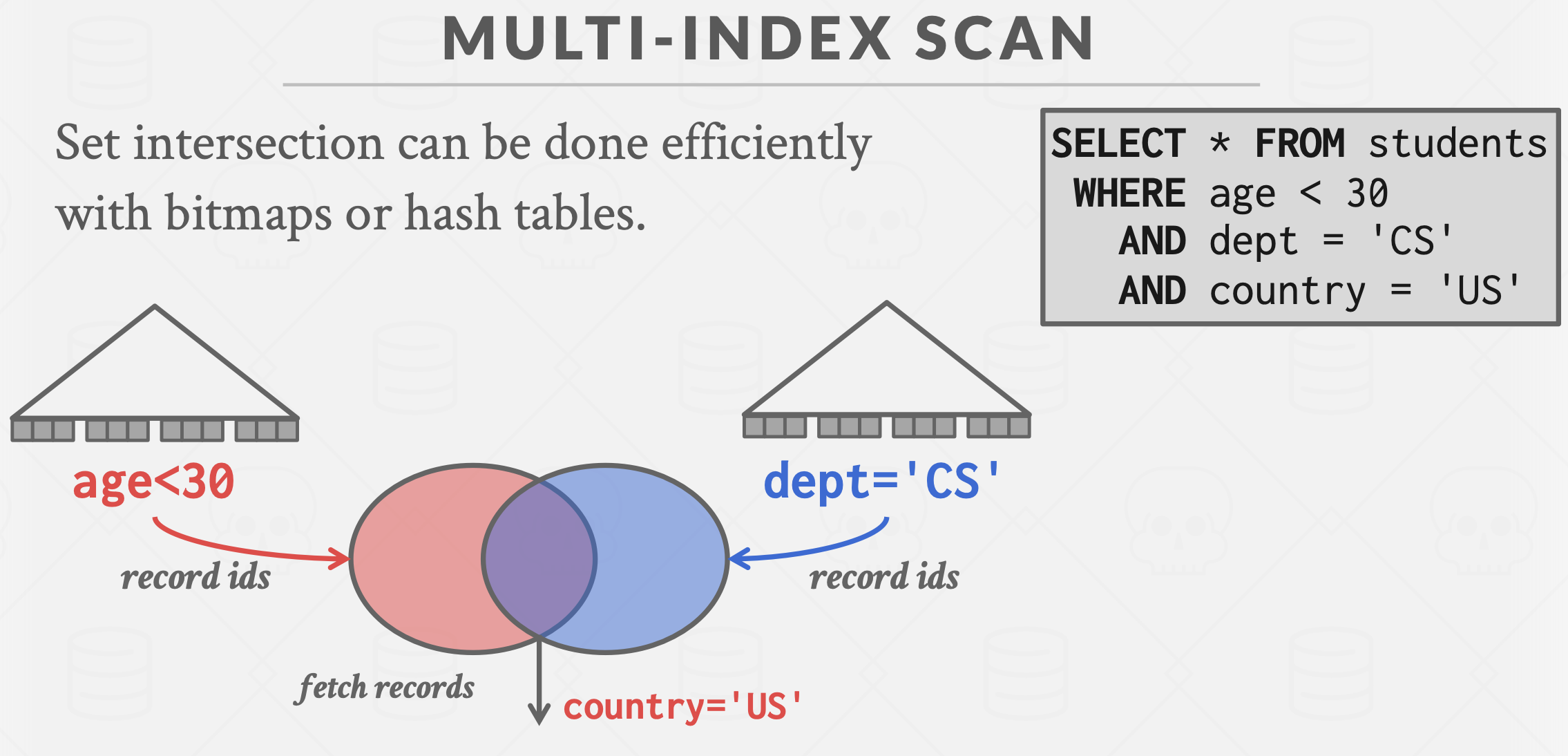
Multi-Index Scan
基本思想:根据每个索引上的谓词,独立找到满足条件的数据记录(Record),然后根据连接谓词进行操作(并集,交集,差集等)。
Halloween Problem
对于UPDATE语句,需要追踪更新过的语句,否则会出现级联更新的问题。

<999, Andy>执行更新,走索引扫描:
- 移除索引
- 更新Tuple,<1099, Andy>
- 插入索引
- (约束检查)
此时,如果不对<1099, Andy>进行标记,他满足Where子句,会被重新更新一次。
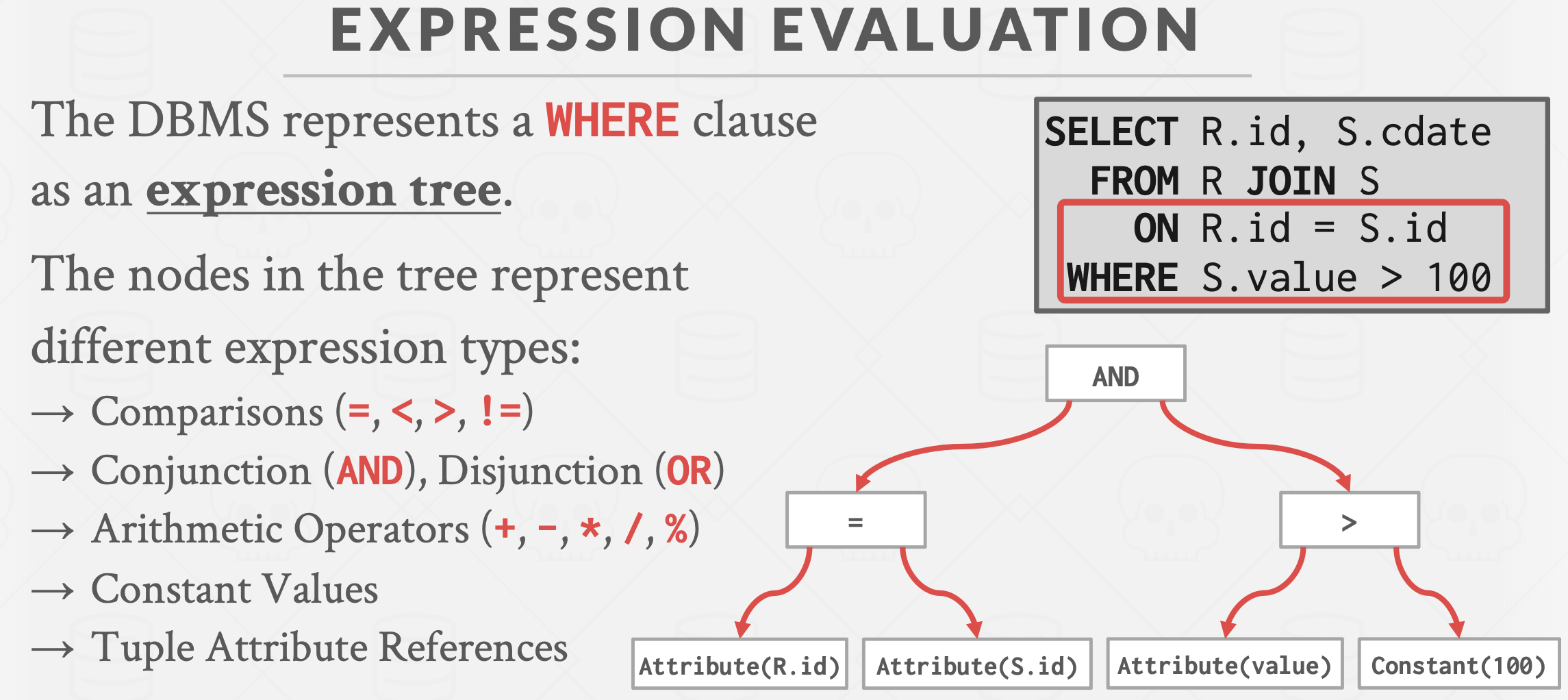
表达式求值
基本思想:采用树形结构,构建表达式树,用中序遍历方式执行所有求值动作,根结点的求值结果就是最终值。
数据库中哪些地方采用了树结构:
- B+树:存储。
- 树形结构+中序遍历求值:查询计划,表达式求值。
优化手段:JIT Compilatoin。将热点表达式计算结点视为函数,编译为内联机器码,而不是每次都遍历结点。

cmu15545笔记-查询执行(Query Excution)的更多相关文章
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- sql 查询执行的详细时间profile
1.查看profile的设置 SHOW VARIABLES LIKE '%profil%' 结果如下:profiling OFF 为关闭状态 2.开启profile 结果: 3.执行需要执行的sql ...
- SQLServer查询执行计划分析 - 案例
SQLServer查询执行计划分析 - 案例 http://pan.baidu.com/s/1pJ0gLjP 包括学习笔记.书.样例库
- MySQL查询执行过程
MySQL查询执行路径 1. 客户端发送一条查询给服务器: 2. 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果.否则进入下一阶段: 3. 服务器端进行SQL解析.预处理,再由优 ...
- [转载]MongoDB学习 (五):查询操作符(Query Operators).1st
本文地址:http://www.cnblogs.com/egger/archive/2013/05/04/3059374.html 欢迎转载 ,请保留此链接๑•́ ₃•̀๑! 查询操作符(Quer ...
- mysql 存储过程:提供查询语句并返回查询执行影响的行数
mysql 存储过程:提供查询语句并返回查询执行影响的行数DELIMITER $$ DROP PROCEDURE IF EXISTS `p_get_select_row_number`$$ CREAT ...
- 跟我一起读postgresql源码(六)——Executor(查询执行模块之——查询执行策略)
时光荏苒,岁月如梭.楼主已经很久没有更新了.之前说好的一周一更的没有做到.实在是事出有因,没能静下心来好好看代码.当然这不能作为我不更新的理由,时间挤挤还是有的,拖了这么久,该再写点东西了,不然人就怠 ...
- 跟我一起读postgresql源码(十)——Executor(查询执行模块之——Scan节点(下))
接前文跟我一起读postgresql源码(九)--Executor(查询执行模块之--Scan节点(上)) ,本篇把剩下的七个Scan节点结束掉. T_SubqueryScanState, T_Fun ...
- MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html 前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后 ...
- 步步深入MySQL:架构->查询执行流程->SQL解析顺序!
一.前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序 ...
随机推荐
- C#ListView类的继承
ListView控件类新加方法 新建一个类myListView class myListView : System.Windows.Forms.ListView { //添加自定义的方法 -- //设 ...
- c++学习笔记(二):引用
c++中的引用 引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字.一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量. C++ 引用 vs 指针 引用很容易与指针混淆,它 ...
- 游戏AI行为决策——HTN(分层任务网络)
游戏AI行为决策--HTN 前言 Hierarchical Task Network(分层任务网络),简称HTN,与行为树.GOAP一样,也是一种行为决策方法.在<地平线:零之曙光>.&l ...
- Asp.net core 学习笔记 dotnet & azure 常用 command
更新: 2021-08-26 最近试了一下 vs 2022 结果 .net cli 也自动升级到 .net 6 preview 版本, 害我 dotnet new 的时候出来一个 .net 6 tem ...
- 项目发布后项目时间和linux时间不一致
查阅了很多资料,本来总以为是项目的问题,启动前端,连接不同的后台,本地项目时间是正确的,部署到linux Docker容器就不行.很纳闷...... 基于以上,还是决定记下来,以便后来的人查阅,解决问 ...
- Mybatis整合多数据源
背景 有时候我们需要查询来自多个库表的数据内容,但是又不想起多个服务,可以业务需要这些数据那该怎么办呢?那么其实Mybatis 是支持整合多数据源,并随时进行切换. 解决 引入依赖 首先引入dyn ...
- 神经网络之卷积篇:详解为什么使用卷积?(Why convolutions?)
详解为什么使用卷积? 来分析一下卷积在神经网络中如此受用的原因,然后对如何整合这些卷积,如何通过一个标注过的训练集训练卷积神经网络做个简单概括.和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀 ...
- 高强度学习训练第七天总结:JVM分配内存机制
理解JVM内存分配策略 三大原则+担保机制 JVM分配内存机制有三大原则和担保机制 具体如下所示: 优先分配到eden区 大对象,直接进入到老年代 长期存活的对象分配到老年代 空间分配担保 对象优先在 ...
- map&unordered_map<key,value>key使用自定义类的要求
std::unordered_map 的键要求: std::unordered_map 是基于哈希表的数据结构. 它要求键类型必须支持哈希计算,也就是必须有对应的 std::hash 函数. 另外,键 ...
- ARMv8中non-shareable inner-shareable outer-shareable属性
如果将block的内存属性配置成Non-cacheable,那么数据就不会被缓存到cache,那么所有observer看到的内存是一致的,也就说此时也相当于Outer Shareable. 其实官方文 ...