kmeans算法
KMeans算法
基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
k-means 算法基本步骤
算法分析和评价
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt def dis(x, y): #计算距离
return np.sum(np.power(y - x, 2)) def dataN(length,k):#生成数据
z=range(k)
c=[5]*length
a1= [np.sin(i*2*np.pi/k) for i in range(k)]
a2= [np.cos(i*2*np.pi/k) for i in range(k)]
x=[[[i*j + np.random.uniform(0,5)]for i in c]for j in a1]
y=[[[i*j + np.random.uniform(0,5)]for i in c]for j in a2]
return x,y,z def showP(x,y,z):#原始点作图
plt.figure(1)
color=['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
for j in z:
for i in xrange(length):
plt.plot(x[j][i], y[j][i],color[j]) def initCentroids(dataSet, k):#初始化中心点
n, d = dataSet.shape
centroids = np.zeros((k, d))
for i in range(k):
index = int(np.random.uniform(0, n))
centroids[i] = dataSet[index]
return centroids def kmeans(dataSet, k): #kmeans算法
n = dataSet.shape[0]
clusterAssment = np.mat(np.zeros((n, 2)))
clusterChanged = True
centroids = initCentroids(dataSet, k)
while clusterChanged:
clusterChanged = False
for i in xrange(n):
distance=[[dis(centroids[j], dataSet[i])] for j in range(k)]
minDist= min(distance)
minIndex=distance.index(minDist)
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i] = minIndex, minDist[0]
for j in range(k):
pointsInCluster = dataSet[np.nonzero(clusterAssment[:, 0]== j)[0]]
centroids[j] = np.mean(pointsInCluster, axis = 0)
return centroids, clusterAssment def showCluster(dataSet, k, centroids, clusterAssment):#结果作图
plt.figure(2)
n=len(dataSet)
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
for i in xrange(n):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize =8)
plt.show() length=200
k=8 #k<=8
x,y,z=dataN(length,k)
showP(x,y,z) dataSet=np.mat(zip(np.reshape(x,(1,length*k))[0],np.reshape(y,(1,length*k))[0]))
centroids, clusterAssment = kmeans(dataSet, k)
showCluster(dataSet, k, centroids, clusterAssment)
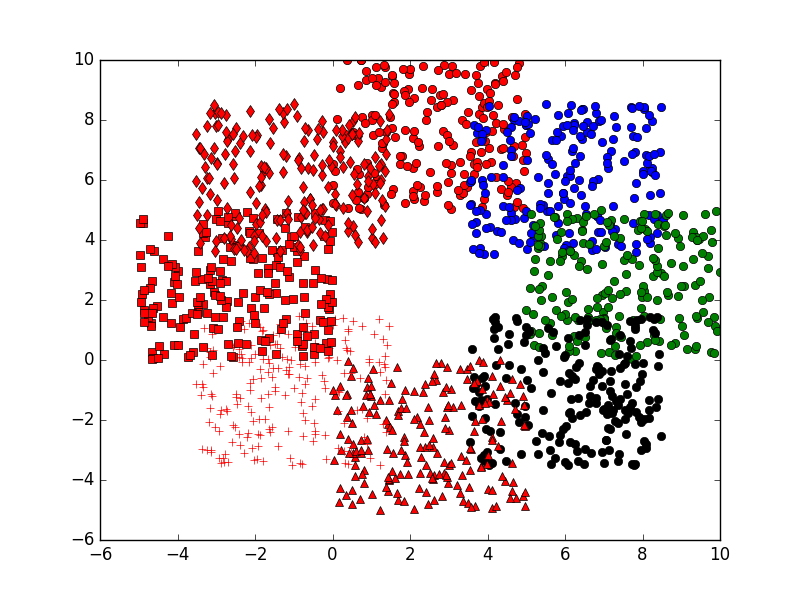
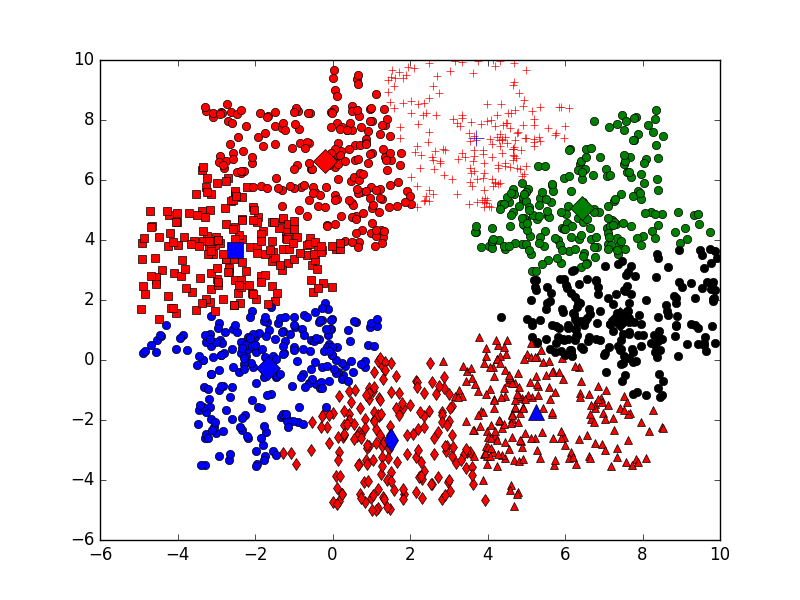
kmeans算法的更多相关文章
- kmeans算法并行化的mpi程序
用c语言写了kmeans算法的串行程序,再用mpi来写并行版的,貌似参照着串行版来写并行版,效果不是很赏心悦目~ 并行化思路: 使用主从模式.由一个节点充当主节点负责数据的划分与分配,其他节点完成本地 ...
- 【原创】数据挖掘案例——ReliefF和K-means算法的医学应用
数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的.事先未知 ...
- kmeans算法c语言实现,能对不同维度的数据进行聚类
最近在苦于思考kmeans算法的MPI并行化,花了两天的时间把该算法看懂和实现了串行版. 聚类问题就是给定一个元素集合V,其中每个元素具有d个可观察属性,使用某种算法将V划分成k个子集,要求每个子集内 ...
- kmeans算法实践
这几天学习了无监督学习聚类算法Kmeans,这是聚类中非常简单的一个算法,它的算法思想与监督学习算法KNN(K近邻算法)的理论基础一样都是利用了节点之间的距离度量,不同之处在于KNN是利用了有标签的数 ...
- 二分K-means算法
二分K-means聚类(bisecting K-means) 算法优缺点: 由于这个是K-means的改进算法,所以优缺点与之相同. 算法思想: 1.要了解这个首先应该了解K-means算法,可以看这 ...
- 视觉机器学习------K-means算法
K-means(K均值)是基于数据划分的无监督聚类算法. 一.基本原理 聚类算法可以理解为无监督的分类方法,即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类.聚 ...
- EM算法(1):K-means 算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(1) : K-means算法 1. 简介 K-mean ...
- K-means算法及文本聚类实践
K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错,这里简单介绍一下k-means算法,下图是一个手写体数据集聚类的结果. 基本思想 k-means算法需要事先指定 ...
- K-means算法和矢量量化
语音信号的数字处理课程作业——矢量量化.这里采用了K-means算法,即假设量化种类是已知的,当然也可以采用LBG算法等,不过K-means比较简单.矢量是二维的,可以在平面上清楚的表示出来. 1. ...
- [聚类算法] K-means 算法
聚类 和 k-means简单概括. 聚类是一种 无监督学习 问题,它的目标就是基于 相似度 将相似的子集聚合在一起. k-means算法是聚类分析中使用最广泛的算法之一.它把n个对象根据它们的属性分为 ...
随机推荐
- Core Animation系列之CADisplayLink
一直以来都想好好学习下CoreAnimation,奈何涉及的东西太多,想要一次性全部搞定时间上不允许,以后会断断续续的补全.最近项目里用到了CADisplayLink,就顺便花点时间看了看. 一.简介 ...
- 基于HTML5+CSS3的图片旋转、无限滚动、文字跳动特效
本文分享几种基于HTML5+CSS3实现的一些动画特效:图片旋转.无限滚动.文字跳动;实现起来均比较容易,动手来试试! 一.图片旋转 效果图如下: 这个效果实现起来其实并不困难.代码清单如下: < ...
- 算法(第4版)-1.1.7 API
总结:本小姐讲述了API的定义.作用以及一些Java库的举例. 重点: 1.API的目的是将调用和实现分离:除了API中给出的信息,调用者不需要知道实现的其他细节,而实现也不应考虑特殊的应用场景.
- 初次使用百度地图API
因为项目需要,不得不使用百度地图的API,以前从未了解过API,这不是唬人,真的,所以对百度地图API充满了恐惧,但是到后面,已经麻木了.期间遇到过很多错误,每一个都弄得头大,借博客的名义把平时遇到的 ...
- GIT之二 基础篇(2)
远程仓库的使用 要参与任何一个 Git 项目的协作,必须要了解该如何管理远程仓库.远程仓库是指托管在网络上的项目仓库,可能会有好多个,其中有些你只能读,另外有些可以写.同他人协作开发某个项目时,需要管 ...
- HDU 2829 Lawrence (斜率DP)
斜率DP 设dp[i][j]表示前i点,炸掉j条边的最小值.j<i dp[i][j]=min{dp[k][j-1]+cost[k+1][i]} 又由得出cost[1][i]=cost[1][k] ...
- mysql主从同步报slave_sql_running:no的解决方案
1.没有正确设置server_id(如没有正确设置从配置项) ps:可手动设置server_id 2.slave stop;set global sql_slave_skip_counter=1;sl ...
- XML HttpRequest
XMLHttpRequest对象提供了在网页加载后与服务器进行通信的方法. 使用XMLHttpRequest对象,能够: 在不重新加载页面的情况下更新网页 在页面已加载后从服务器请求数据,接受数据 在 ...
- Magento删除产品同时删除图片
在Magento后台删除产品时,默认不会删除产品的图片,如果长期不清理这些废弃的图片,会导致Media目录下的文件越来越多,浪费服务器空间,为了实现删除产品的同时删除图片,网络上常见的方法是修改Mag ...
- Event Logging
编号:1001 时间:2016年3月29日16:24:33 功能:Event Logging 技术简介 URL:http://blog.csdn.net/colorknight/article/det ...