在Hadoop集群中添加机器和删除机器
本文转自:http://www.cnblogs.com/gpcuster/archive/2011/04/12/2013411.html
无论是在Hadoop集群中添加机器和删除机器,都无需停机,整个服务不中断。
本次操作之前,Hadoop的集群情况如下:
HDFS的机器情况如下:
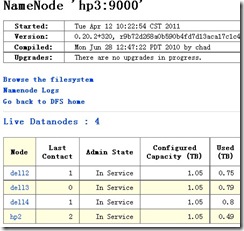
MR的机器情况如下:
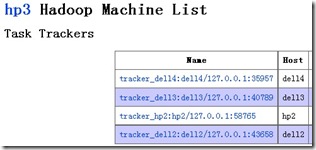
添加机器
在集群的Master机器中,修改$HADOOP_HOME/conf/slaves文件,在其中添加需要加入集群的新机器(hp3)的主机名:
hp3
hp2
dell1
dell2
dell3
dell4
然后在Master机器中执行如下命令:
$HADOOP_HOME/bin/start-all.sh
这样操作完成之后,新的机器就添加到集群中来了。
HDFS集群增加了一台新的机器:
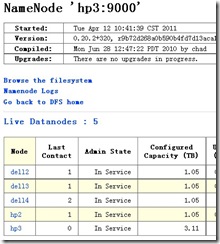
MR集群中也新增了一台机器:
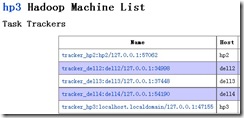
删除机器
不安全的方式
由于Hadoop集群自身具备良好的容错性,可以直接关闭相应的机器,从而达到将该机器撤除的目的。但是如果一次性操作3台以上的机器,就有可能造成部分数据丢失,所以不推荐使用这种方式进行操作。
安全的方式
在集群的Master机器中,新建一个文件:$HADOOP_HOME/conf/nn-excluded-list,在这个文件中指定需要删除的机器主机名(hp3):
hp3
然后,修改Master机器的配置文件:$HADOOP_HOME/conf/hdfs-site.xml,添加如下内容:
<property>
<name>dfs.hosts.exclude</name>
<value>conf/nn-excluded-list</value>
</property>
最后,在Master机器中执行如下命令:
$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes
这样操作完成之后,可以在HDFS集群中看到,hp3机器已经处于Decommission In Progress状态:
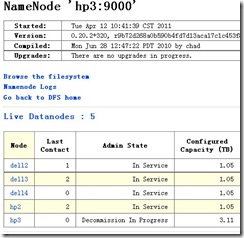
但是MR机器中hp3机器依旧在运行中:
我们需要等待一定的时间,等待hp3中datanode的Decommission操作完成以后,再到hp3机器中关闭所有的Hadoop进程即可。
这样就完成了整个从集群中删除机器的操作。
更多关于Hadoop的文章,可以参考:http://www.cnblogs.com/gpcuster/tag/Hadoop/
在Hadoop集群中添加机器和删除机器的更多相关文章
- Hadoop集群中添加硬盘
Hadoop工作节点扩展硬盘空间 接到老板任务,Hadoop集群中硬盘空间不够用,要求加一台机器到Hadoop集群,并且每台机器在原有基础上加一块2T硬盘,老板给力啊,哈哈. 这些我把完成这项任务的步 ...
- hadoop集群中客户端修改、删除文件失败
这是因为hadoop集群在启动时自动进入安全模式 查看安全模式状态:hadoop fs –safemode get 进入安全模式状态:hadoop fs –safemode enter 退出安全模式状 ...
- 向CDH5集群中添加新的主机节点
向CDH5集群中添加新的主机节点 步骤一:首先得在新的主机环境中安装JDK,关闭防火墙.修改selinux.NTP时钟与主机同步.修改hosts.与主机配置ssh免密码登录.保证安装好了perl和py ...
- hadoop集群中动态添加新的DataNode节点
集群中现有的计算能力不足,须要另外加入新的节点时,使用例如以下方法就能动态添加新的节点: 1.在新的节点上安装hadoop程序,一定要控制好版本号,能够从集群上其它机器cp一份改动也行 2.把name ...
- hadoop集群中动态添加节点
集群的性能问题需要增加服务器节点以提高整体性能 https://www.cnblogs.com/fefjay/p/6048269.html hadoop集群之间hdfs文件复制 https://www ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置(三台机器跑集群)
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- hadoop 集群配置--增加减少新的机器不重启
增加机器不重启操作如下: 首先,把新节点的 IP或主机名 加入主节点(master)的 conf/slaves 文件. 然后登录新的从节点,执行以下命令: $ cd path/to/hadoop $ ...
- Hadoop集群(第3期)机器信息分布表
1.分布式环境搭建 采用4台安装Linux环境的机器来构建一个小规模的分布式集群. 图1 集群的架构 其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点.这四台机器彼 ...
- hadoop 集群中数据块的副本存放策略
HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性.可用性和网络带宽的利用率.目前实现的副本存放策略只是在这个方向上的第一步.实现这个策略的短期目标是验证它在生产环境下的有效 ...
随机推荐
- Python项目实战
编程只有不断练习才能掌握其精髓,多练练网上的习题和项目,才能掌握python的精髓. Python的模块和包是出了名的多,因此你不必自己从底层开始写起,只需要看懂模块和包的使用文档就可以了,因此掌握一 ...
- java 导入包
导入包 问题:类名冲突时,要如何解决. 解决:sun提供导入包语句让我们解决该问题. 导入包语句的作用:简化书写. 导入包语句的格式:import 包名.类名;(导入xxx包的XX类) 导入包语句的细 ...
- Jquery如何获得<iframe>嵌套页面中的元素
DOM方法:父窗口操作IFRAME:window.frames["iframeSon"].documentIFRAME操作父窗口: window.parent.documentjq ...
- STL中vector的用法
vector是标准模板库的一种容器,是可存放各种类型的动态数组. #include<iostream> #include<vector> using namespace std ...
- hdu-----(4857)逃生(拓扑排序)
逃生 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submissi ...
- 5月18日 HTML 个人简历
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- MySql查找几个字段的值一样的记录
),name,class,charge_start,charge_end ) ; 注意:having在这里起到很大的作用,只有在having中,才可以对类似sum(),count()等等复合函数的结果 ...
- ArangoDB介绍——未知架构和底层原理
ArangoDB介绍 ArangoDB是一个开源NoSQL数据库,官网:https://www.ArangoDB.org/ArangoDB支持灵活的数据模型,比如文档Document.图Graph以及 ...
- java入门第二步之helloworld【转】
前一篇博客已经介绍了jdk的安装:接下来我们就乘热打铁,完成第一个程序:helloworld(每学一样程序的新东西都是从实现helloworld开始的) 1.不是用开发工具IDE,只是使用记事本来实现 ...
- 面向对象编程(OOP)基础之UML基础
在我们学习OOP过程中,难免会见到一些结构图~各种小框框.各种箭头.今天小猪就来简单介绍一下这些框框箭头的意思——UML. UML定义的关系主要有:泛化(继承).实现.依赖.关联.聚合.组合,这六种关 ...