Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py
Sikp gram方式的model思路
http://tensorflow.org/tutorials/word2vec/index.md
另外可以参考cs224d课程的课件。
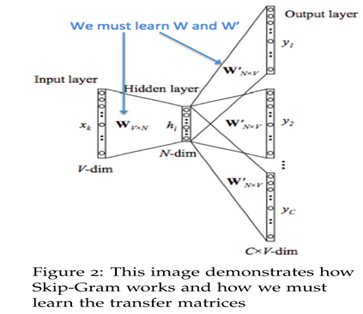

窗口设置为左右1个词
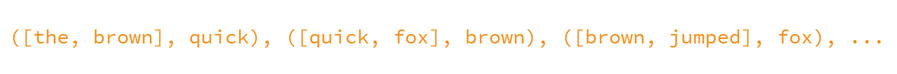
对应skip gram模型
就是一个单词预测其周围单词(cbow模型是
输入一系列context词,预测一个中心词)

Quick -> the quick -> brown
Skip gram的训练目标cost function是
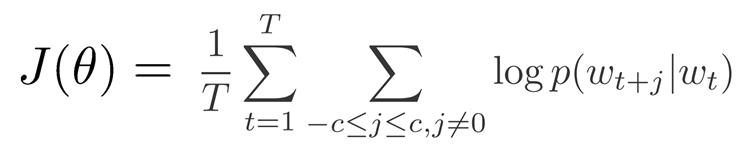
对应

但是这样太耗时了
每一步训练时间代价都是O(VocabularySize)
于是我们采用了 nce(noise-contrastive estimation)的方式,也就是负样本采样,采用某种方式随机生成词作为负样本,比如 quick -> sheep ,sheep作为负样本,假设我们就取一个负样本
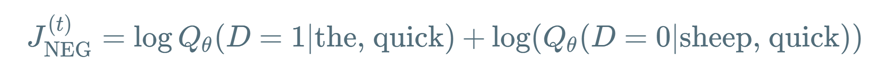
- 输入数据
这里是
分隔好的单词 - 读入单词存储到list中
- 统计词频 0号位置给 unknown, 其余按照频次由高到低排列,unknown的获取按照预设词典大小
比如50000,则频次排序靠后于50000的都视为unknown建立好 key->id id->key的双向索引map
4. 产生一组training batch
batch_size = 128
embedding_size = 128 # Dimension of the embedding vector.
skip_window = 1 # How many words to consider left and right.
num_skips = 2 # How many times to reuse an input to generate a label.
Batch_size每次sgd训练时候扫描的数据大小, embedding_size 词向量的大小,skip_window 窗口大小,
Num_skips = 2 表示input用了产生label的次数限制
demo中默认是2,
可以设置为1 对比下
默认2的时候
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], '->', labels[i, 0])
print(reverse_dictionary[batch[i]], '->', reverse_dictionary[labels[i, 0]])
Sample data [5239, 3084, 12, 6, 195, 2, 3137, 46, 59, 156]
-> 5239
originated -> anarchism
-> 12
originated -> as
12 -> 6
as -> a
12 -> 3084
as -> originated
6 -> 195
a -> term
6 -> 12
a -> as
195 -> 2
term -> of
195 -> 6
term -> a
3084左侧出现2次,对应窗口左右各1
设置1的时候
batch, labels = generate_batch(batch_size=8, num_skips=1, skip_window=1)
for i in range(8):
print(batch[i], '->', labels[i, 0])
print(reverse_dictionary[batch[i]], '->', reverse_dictionary[labels[i, 0]])
Sample data [5239, 3084, 12, 6, 195, 2, 3137, 46, 59, 156]
-> 12
originated -> as
12 -> 3084
as -> originated
6 -> 12
a -> as
195 -> 2
term -> of
2 -> 3137
of -> abuse
3137 -> 46
abuse -> first
46 -> 59
first -> used
59 -> 156
3084左侧只出现1次
# Step 4: Function to generate a training batch for the skip-gram model.
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ]
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window # target label at the center of the buffer
targets_to_avoid = [ skip_window ]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], '->', labels[i, 0])
print(reverse_dictionary[batch[i]], '->', reverse_dictionary[labels[i, 0]])
就是对于一个中心词
在window范围
随机选取 num_skips个词,产生一系列的
(input_id, output_id) 作为(batch_instance, label)
这些都是正样本
训练准备,
Input embedding W

Output embedding W^

后面code都比较容易理解,tf定义了nce_loss来自动处理,每次会自动添加随机负样本
num_sampled = 64 # Number of negative examples to sample.
graph = tf.Graph()
with graph.as_default():
# Input data.
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Construct the variables.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Look up embeddings for inputs.
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Compute the average NCE loss for the batch.
# tf.nce_loss automatically draws a new sample of the negative labels each
# time we evaluate the loss.
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels,
num_sampled, vocabulary_size))
# Construct the SGD optimizer using a learning rate of 1.0.
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
训练过程利用embedding矩阵的乘法计算了不同词向量的欧式距离
并计算了高频几个词对应的距离最近的词展示
最后调用 skitlearn的TSNE模块
进行降维到2元,绘图展示。
Tensorflow 的Word2vec demo解析的更多相关文章
- IOS CoreData 多表查询demo解析
在IOS CoreData中,多表查询上相对来说,没有SQL直观,但CoreData的功能还是可以完成相关操作的. 下面使用CoreData进行关系数据库的表与表之间的关系演示.生成CoreData和 ...
- Ionic Demo 解析
Ionic Demo 解析 index.html 解析 1.引入所需要的类库 <link rel="manifest" href="manifest.json&qu ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- word2vec源代码解析之word2vec.c
word2vec源代码解析之word2vec.c 近期研究了一下google的开源项目word2vector,http://code.google.com/p/word2vec/. 事实上这玩意算是神 ...
- 利用 TensorFlow 入门 Word2Vec
利用 TensorFlow 入门 Word2Vec 原创 2017-10-14 chen_h coderpai 博客地址:http://www.jianshu.com/p/4e16ae0aad25 或 ...
- 转:RealThinClient LinkedObjects Demo解析
这个Demo源码实现比较怪,有点拗脑,原因估是作者想把控件的使用做得简单,而封装太多. 这里说是解析,其实是粗析,俺没有耐心每个实现点都查实清楚,看源码一般也就连读带猜的. 这个Demo表达出的意义, ...
- android报表图形引擎(AChartEngine)demo解析与源码
AchartEngine支持多种图表样式,本文介绍两种:线状表和柱状表. AchartEngine有两种启动的方式:一种是通过ChartFactory.get***View()方式来直接获取到view ...
- Tensorflow的CNN教程解析
之前的博客我们已经对RNN模型有了个粗略的了解.作为一个时序性模型,RNN的强大不需要我在这里重复了.今天,让我们来看看除了RNN外另一个特殊的,同时也是广为人知的强大的神经网络模型,即CNN模型.今 ...
- tensorflow lite的demo在android studio上环境搭建
由于很久没有接触过Android开发,而且最早用的是eclipse,所以这个demo在android studio上的搭建过程,真的是踩了不少坑.记录这篇文章,纯粹是给自己一点收获. 环境搭建的过程, ...
随机推荐
- leetcode 153. Find Minimum in Rotated Sorted Array
Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 migh ...
- Android学习笔记(八)——四种基本布局
//此系列博文是<第一行Android代码>的学习笔记,如有错漏,欢迎指正! 布局是一种可用于放置很多控件的容器,它可以按照一定的规律调整内部控件的位置,或是嵌套子布局,从而编写出精美的界 ...
- 技术博客(初用markdown)。
技术博客 菜鸟教程在这个网站我学到许多有趣的东西,并且弥补了我之前的一些不足之处. 以下为我学习到的内容 输出不同的三位数 以下为代码和输出结果 *** #include<stdio.h> ...
- r-cnn学习系列(三):从r-cnn到faster r-cnn
把r-cnn系列总结下,让整个流程更清晰. 整个系列是从r-cnn至spp-net到fast r-cnn再到faster r-cnn. RCNN 输入图像,使用selective search来构造 ...
- Ubuntu 中安装 NetBeans IDE
NetBeans 8.2 刚刚发布,如果你还没有安装的话,这篇简短的教程将会演示如何在 Ubuntu 系统上快速的安装.对安装 NetBeans 需要帮助的开发者来说,这往篇文章会是不错的指导. 给那 ...
- 14 BasicHashTable基本哈希表类(一)——Live555源码阅读(一)基本组件类
这是Live555源码阅读的第一部分,包括了时间类,延时队列类,处理程序描述类,哈希表类这四个大类. 本文由乌合之众 lym瞎编,欢迎转载 http://www.cnblogs.com/oloroso ...
- func_num_args, func_get_arg, func_get-args 的区别与用法
func_num_args 返回传递给函数的参数个数 <?php header("Content-Type: text/html; charset=UTF-8"); func ...
- 11.2---字符串数组排序,删除变位词(CC150)
这道题主义的就是,要利用数组自带的sort函数. 此外,注意,利用hash来判断是否出现了. public static ArrayList<String> sortStrings(Str ...
- Navicat for MySQL的使用
一. 在Navicat for MySQL软件中,如何打开MySQL命令行界面: 图 (1) 如何调出MySQL命令行界面 如图(1)所示,在左侧空白处,右键单击即可调出“命令列介面” 注意,输入My ...
- linux系统性能调优第一步——性能分析(vmstat)
linux系统性能调优第一步--性能分析(vmstat) 分类: LINUX 性能调优的第一步是性能分析,下面从性能分析着手进行一些介绍,尤其对linux性能分析工具vmstat的用法和实践进行详细介 ...