Hive 实战(2)--hive分区分桶实战
前言:
互联网应用, 当Mysql单机遇到性能瓶颈时, 往往采用的优化策略是分库分表. 由于互联网应用普遍的弱事务性, 这种优化效果非常的显著.而Hive作为数据仓库, 当数据量达到一定数量时, 查询性能会有所下降, 那如何利用数据的特点进行优化? 分区分桶作为Hive的优化的一个有力武器.
*). 分区(静态、动态)
Hive没有索引, 查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。倘若只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。分区表指的是在创建表时指定的partition的分区空间。
1). 静态分区
hive默认采用静态分区, 数据的导入需至少指定一个分区字段
1.1). 创建分区表
CREATE TABLE tb_part_shop (
shop_id int,
shop_name string,
shopkeeper string
) PARTITIONED BY (province_id int, city_id int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
1.2). 描述分区表(describe extended <table_name>)
DESCRIBE EXTENDED tb_part_shop;
> DESCRIBE EXTENDED tb_part_shop;
OK
shop_id int None
shop_name string None
shopkeeper string None
province_id int None
city_id int None # Partition Information
# col_name data_type comment province_id int None
city_id int None
1.3). 导入分区和数据
ALTER TABLE tb_part_shop ADD PARTITION (province_id = 1001, city_id = 10001);
数据内容
33068201 Wal-Mart wal-mart
33068202 Carrefour carrefour
LOAD DATA LOCAL INPATH '/path/to/data.txt' INTO TABLE tb_part_shop PARTITION(province_id = 1001, city_id = 10001);
对于小数据量导入, 可采用如下的语句来实现
INSERT INTO VALUES() 等价实现 INSERT INTO TABLE <table_name> SELECT ... FORM <table_name> LIMIT 1;
1.4). 分区表的目录结构
分区表, 在hdfs中的目录结构如图所示:
2). 动态分区表
2.1). 设置开启动态分区开关
set hive.exec.dynamic.partition=true;
2.2). 严格模式
set hive.exec.dynamic.partition.mode=strict; # strict/nonstrict
默认为strict, 对于分区表, 若插入语句没有指定至少一个静态分区字段, 则执行失败
如下例子:
set hive.exec.dynamic.partition.mode=strict;
hive> insert into table tb_part_shop select 1, "2haodian", "shopper", 1001, 20012 from tb_user limit 1;
FAILED: SemanticException 1:18 Need to specify partition columns because the destination table is partitioned. Error encountered near token 'tb_part_shop'
2.3). 其他限制条件
set hive.exec.max.dynamic.partitions=3000; # 具体的数值, 表示总共能创建的动态分区数
set hive.exec.max.dynamic.partitions.pernode=1000; # 在mapper/reducer节点中, 允许创建的分区数
SHOW PARTITIONS tb_part_shop;
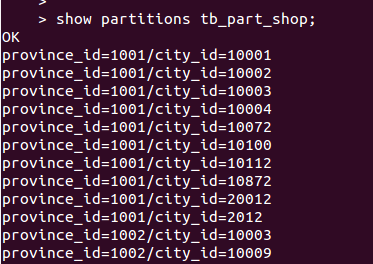
分区适合于字段值可枚举, 离散有限个数值, 比如按时间年/月/日, 省份/市区号编码, 而不适合取值特别多的应用场景, 因为一个值就对应一个目录, 目录无休止的增加对查询的性能, 反而是有害的.
*). 分桶
Hive采用对列值哈希来组织数据的方式, 称之为分桶, 适合采样和map-join.
看看分桶表如何建立
1). 创建分桶表
CREATE TABLE tb_bucket_shop (
shop_id int,
shop_name string,
shopkeeper string
) CLUSTERED BY (shop_id) INTO 4 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
2). 数据导入
set hive.enforce.bucketing=true;
INSERT OVERWRITE TABLE tb_bucket_shop SELECT shop_id, shop_name, shopkeeper FROM tb_part_shop CLUSTER BY shop_id;
若没有使用hive.enforce.bucketing属性, 则需要设置和分桶个数相匹配的reducer个数, 同时SELECT后添加CLUSTER BY
set mapred.reduce.tasks=4;
INSERT OVERWRITE TABLE tb_bucket_shop SELECT shop_id, shop_name, shopkeeper FROM tb_part_shop CLUSTER BY shop_id;
分桶适合于sampling, 不过其数据正确的导入到hive表中, 需要用户自己来保证, 因为table中信息仅仅是元数据, 而不影响实际填充表的命令.
总结:
分区分桶是hive性能优化的一个手段, 不同的字段, 其数值属性不同, 其对应的优化方式也不同. 也不能简单的认为分区分桶对应传统关系型数据库的分库分表, 完全不一样.
Hive 实战(2)--hive分区分桶实战的更多相关文章
- 大数据入门第十一天——hive详解(二)基本操作与分区分桶
一.基本操作 1.DDL 官网的DDL语法教程:点击查看 建表语句 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data ...
- hive分区分桶
目录 1.分区 1.1.静态分区 1.1.1.一个分区 1.1.2.多个分区 1.2.动态分区 2.分桶 1.分区 如果一个表中数据很多,我们查询时就很慢,耗费大量时间,如果要查询其中部分数据该怎么办 ...
- 深入浅出Hadoop实战开发(HDFS实战图片、MapReduce、HBase实战微博、Hive应用)
Hadoop是什么,为什么要学习Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运 ...
- 【Hive学习之五】Hive 参数&动态分区&分桶
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive动态分区和分桶(八)
Hive动态分区和分桶 1.Hive动态分区 1.hive的动态分区介绍 hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在 ...
- 《OD大数据实战》Hive入门实例
官方参考文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual 一.命令行和客户端 1. 命令窗口 1)进入命令窗口 hi ...
- webpack4 中的最新 React全家桶实战使用配置指南!
最新React全家桶实战使用配置指南 这篇文档 是吕小明老师结合以往的项目经验 加上自己本身对react webpack redux理解写下的总结文档,总共耗时一周总结下来的,希望能对读者能够有收获, ...
随机推荐
- EVA资料
[史上最全EVA资料+原画+画集+设定集][共2266P=3.56GB] <ignore_js_op> <ignore_js_op> <ignore_js_op> ...
- 用excel做差异表达
首先准备数据:表达矩阵 ACC.uncv2.mRNAseq_RSEM_normalized_log2.txt(以下载的TCGA的数据,log之后的) 上面数据中01为tumor,11为normal 我 ...
- \boot 空间不足解决方法
ubuntu系统总是更新,有时是内核,有时是软件,最近的一次更新download中,提示\boot目录空间不足,我是将\boot单独划分在一个分区中的,当该目录空间不足时,可以利用命令删除没有用的镜像 ...
- cygwin配置git
对于windows用户来说,使用git bash经常会出现乱码情况,那么一款优质高尚的软件,值得推荐一下了,那就是cygwin 下载cygwin后,在安装过程中,安装git,安装vim编辑器 然后会在 ...
- Android SDK Manager 更新不了文件 提示https://dl-ssl.google.com refused
sdk manager无法自动更新,总在提示超时!!!SDK更新时的“https://dl-ssl.google.com refused”错误 解决方法: 在Android SDK Manager-& ...
- html/CSS基础知识回顾
html部分 块级元素: 一般用来搭建网站架构,布局,装载内容...像这些大体力的活都属于块级元素.它包括以下标签: address,blockquote,center,dir, div, dl, d ...
- 基础笔记5(file)
file 可以是目录和文件(只是是java程序与系统的文件进行一种关联) File file1 = new File("f:/mytest", "test5.txt&qu ...
- nodejs 访问mysql
安装 $ npm install mysql 简介 这个一个mysql的nodejs版本的驱动,是用JavaScript来编写的.不需要编译 这儿有个例子来示范如何使用: var mysql = re ...
- 编程之美--2. Trie树 (Trie图)
#1014 : Trie树 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和小Ho是一对好朋友,出生在信息化社会的他们对编程产生了莫大的兴趣,他们约定好互相帮助, ...
- Mysql 5.7.10以上版本安装大坑
mysql解压缩版的配置已经方便无比了,但是也正是由于官方的不断优化,导致传统的套路一次次被修改.也让像我这样的萌新撞了个大墙. [注:本篇博客适用mysql5.7.10~5.7.15,如果版本已太过 ...