hadoop-MapReduce分布式计算框架
计算框架:
MapReduce:主要用于离线计算
Storm:流式计算框架,更适合做实时计算
stack:内存计算框架,快速计算
MapReduce设计理念:
--何为分布式计算
--移动计算,而不是移动数据
4个步骤:
1.Splitting
2.Mapping:Map步骤有可能有多个Map task线程并发同时执行
3.Shuffing:合并和排序
4.Reducing
Hadoop计算框架Shuffler
在mapper和reducer中间的一个步骤
可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去处理
可以简化reducer过程
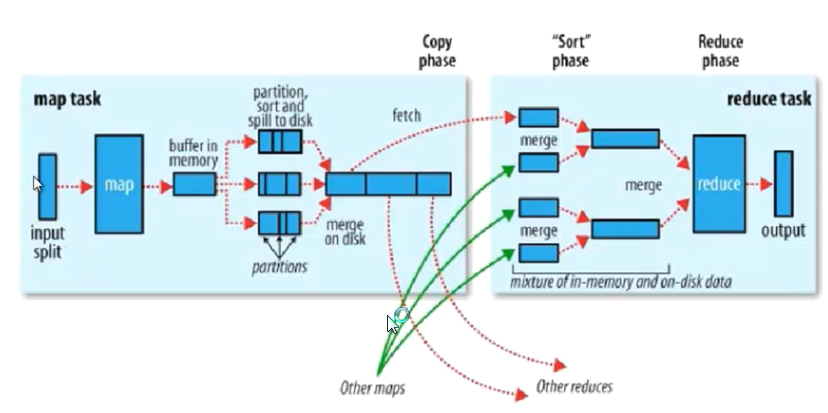
partition:分区
如果不进行分区,会有默认的分区 “哈希模运算”
1.获得 哈希值 -->得到一个整数(int) --> 模reduce的个数得到一个结果
分区 是为了把map的输出数据进行 负载均衡 或解决数据倾斜问题
map中不会出现数据倾斜问题,map的输入数据split(片段)事实上来源于dataNode的block块
默认的partition有可能产生数据倾斜问题
如果有 数据倾斜 问题,需要更改和优化partition
sort:排序
程序可以控制的地方
partition,sort(比较算法,默认按照字典排序(ASCII大小)),combiner
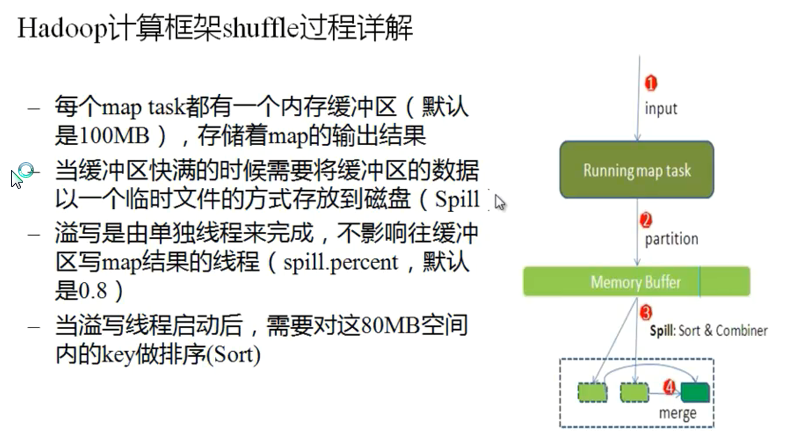
在spill to desk 时候出现 sort和combiner
Combiner 有可能不存在

MapReduce 的 Split 大小
-- max.split(100M)
-- min.split(10M)
-- block(64M)
-- max(min.split,min(max.split,block))
MapReduce 的架构
一主多从架构
主JobTracker:
负责调度分配每一个子任务task运行与TaskTracker上,如果发现有失败的task就重新分配其任务到其他节点.每一个hadoop集群中只有一个JobTracker.一般它运行在Master节点上
从TaskTracker:
TaskTracker主动与JobTracker通信,接受作业,并负责执行每一个任务,为了减少网络带宽TaskTracker最好运行咋HDFS的DataNode上
搭建:
1.指定JobTracker所在的机器
conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.201:</value>
</property>
</configuration>
2.如果TaskTracker配置在DataNode上,默认不需要配置
3.同步配置文件
[root@bogon conf]# scp ./mapred-site.xml root@192.168.1.202:~/hadoop-1.2./conf/
[root@bogon conf]# scp ./mapred-site.xml root@192.168.1.203:~/hadoop-1.2./conf/
4.启动
[root@bogon bin]# ./start-all.sh
5.使用 jps 查看启动
192.168.1.201
[root@bogon bin]# jps
Jps
JobTracker
NameNode
[root@bogon bin]#
192.168.1.202
[root@localhost ~]# jps
DataNode
SecondaryNameNode
Jps
TaskTracker
[root@localhost ~]#
192.168.1.203
[root@localhost ~]# jps
TaskTracker
Jps
DataNode
[root@localhost ~]#
使用 http://192.168.1.201:50030/ 查看
生成 eclipse 插件
hadoop-1.2.1\src\contrib\eclipse-plugin 在eclipse中编译成jar
将编译好的jar放入到eclipse的plugin中
eclipse版本不能太低也不能太高 使用4.4
hadoop-MapReduce分布式计算框架的更多相关文章
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一.MapReduce概述 二.MapReduce编程模型简述 三.combiner & partitioner 四.MapReduce词频统计案例 4.1 项目简介 ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop 系列(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集. MapReduce ...
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 下一代Apache Hadoop MapReduce框架的架构
背景 随着集群规模和负载增加,MapReduce JobTracker在内存消耗,线程模型和扩展性/可靠性/性能方面暴露出了缺点,为此需要对它进行大整修. 需求 当我们对Hadoop MapReduc ...
- 2_分布式计算框架MapReduce
一.mr介绍 1.MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据. 2.计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr ...
随机推荐
- shell 删除某个目录下的重复文件
#!/bin/bash ls -lS | awk 'BEGIN{ getline; getline; name1=$;size=$; } { name2=$; sizeTmp=$; ){ ; ; if ...
- IIS 应用程序池.NET40 重新注册
32位的Windows:---------------------------------------------------------------------------1. 运行->cmd ...
- Codevs 1506 传话(floyd大法好)。
1506 传话 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 白银 Silver 题解 题目描述 Description 一个朋友网络,如果a认识b,那么如果a第 ...
- BZOJ 4241 历史研究
Description IOI国历史研究的第一人——JOI教授,最近获得了一份被认为是古代IOI国的住民写下的日记.JOI教授为了通过这份日记来研究古代IOI国的生活,开始着手调查日记中记载的事件. ...
- ASP.NET MVC铵钮Click后下载文件
本篇Insus.NET练习的是FilePathResult和FileStreamResult操作.本篇也算是<如何把Json格式字符写进text文件中>http://www.cnblogs ...
- 通过js动态生成页面表格
var redlineTemplateP = $(".redlineDataList"); for (var index in detailArraryLists.rows){ v ...
- QT5 动态链接库的创建和使用
记录一下QT5 动态链接库的创建和使用 在文章的最后有完成的代码供下载 1.创建动态链接库 先新建一个库项目 选择chose进入下一下页面,类型选择共享库,输入一个名称:我输入的是sld 再点击下一步 ...
- 为什么我们的web前端变的越来越复杂
前端发展了也有些年头了,曾记得很多年前,聊起前端,都觉得是很简单,那个时候都没有前端工程师这个职位.可现在,前端已经逆袭了,已经不是原来的样子了,各种技术层出不穷,显的越来越高深莫测了.前端真的变得那 ...
- SQL Server 2012新特性(1)T-SQL操作FileTable目录实例
在SQL Server 2008提供FileStream,以借助Windows系统本身的API来强化SQL Server对于非结构化数据的支持后,SQL Server 2012更是推出了像Contai ...
- Android开发之SlidingMenu开源项目的使用和问题
一.关于如何导入lib 第一步:New Module 点击+: 第二步:选择Import Eclipse ADT Project: 第三步:选择你想引入的lib文件,选择完成后,会开始编译你添加的项 ...