飞桨动态图PyLayer机制
一、主要用法
如下是官方文档上的使用样例:
import paddle
from paddle.autograd import PyLayer
# Inherit from PyLayer
class cus_tanh(PyLayer):
@staticmethod
def forward(ctx, x, func1, func2=paddle.square):
# ctx is a context object that store some objects for backward.
ctx.func = func2
y = func1(x)
# Pass tensors to backward.
ctx.save_for_backward(y)
return y
@staticmethod
# forward has only one output, so there is only one gradient in the input of backward.
def backward(ctx, dy):
# Get the tensors passed by forward.
y, = ctx.saved_tensor()
grad = dy * (1 - ctx.func(y))
# forward has only one input, so only one gradient tensor is returned.
return grad
data = paddle.randn([2, 3], dtype="float64")
data.stop_gradient = False
z = cus_tanh.apply(data, func1=paddle.tanh)
z.mean().backward()
print(data.grad)
PyLayer 在使用上需要遵循一定的规范,如:
- 子类必须包含静态的 forward 和 backward 函数,它们的第一个参数必须是
PyLayerContext - 如果 backward 的某个返回值在 forward 中对应的 Tensor 是需要梯度,这个返回值必须为 Tensor
- backward 输入的 Tensor 的数量必须等于 forward 输出 Tensor 的数量
- 如果你需在 backward 中使用 forward 的输入 Tensor ,你可以将这些 Tensor 输入到
PyLayerContext的save_for_backward方法,之后在 backward 中使用这些 Tensor 。 - backward 的输出 Tensor 的个数等于 forward 输入 Tensor 的个数
二、运行机制
2.1 端到端执行流程
以下图为例:
import paddle
from paddle.autograd import PyLayer
class Tanh(PyLayer):
@staticmethod
def forward(ctx, x):
print("in forward")
return x+x
@staticmethod
def backward(ctx, grad):
print("in backwarad")
return grad
x = paddle.ones([1], dtype="float64")
x.stop_gradient = False
out = Tanh.apply(x)[0]
print("after apply")
out.backward()
print("after backward")
print(x.grad)
执行如下命令可以看出执行的过程:GLOG_vmodule=eager_py_layer=6,py_layer_node=6 python test_pylayer.py,日志如下:
[eager_py_layer.cc:132] Begin run PyLayer apply...
[eager_py_layer.cc:144] PyLayer construct PyLayerContext finish...
[eager_py_layer.cc:247] PyLayer forward args is ready, begin call user's forward function...
in forward
[eager_py_layer.cc:376] PyLayer forward function finish...
[eager_py_layer.cc:442] PyLayer construct backward node finish...
after apply
[py_layer_node.cc:38] Running Eager Backward Node: GradNodePyLayer_Tanh_backward
[py_layer_node.cc:98] PyLayer backward args is ready, begin call user's backward function...
in backwarad
[py_layer_node.cc:116] PyLayer backward function finish...
[py_layer_node.h:46] Do nothing here now
after backward
Tensor(shape=[1], dtype=float64, place=Place(gpu:0), stop_gradient=False,
[1.])
2.2 代码拆解
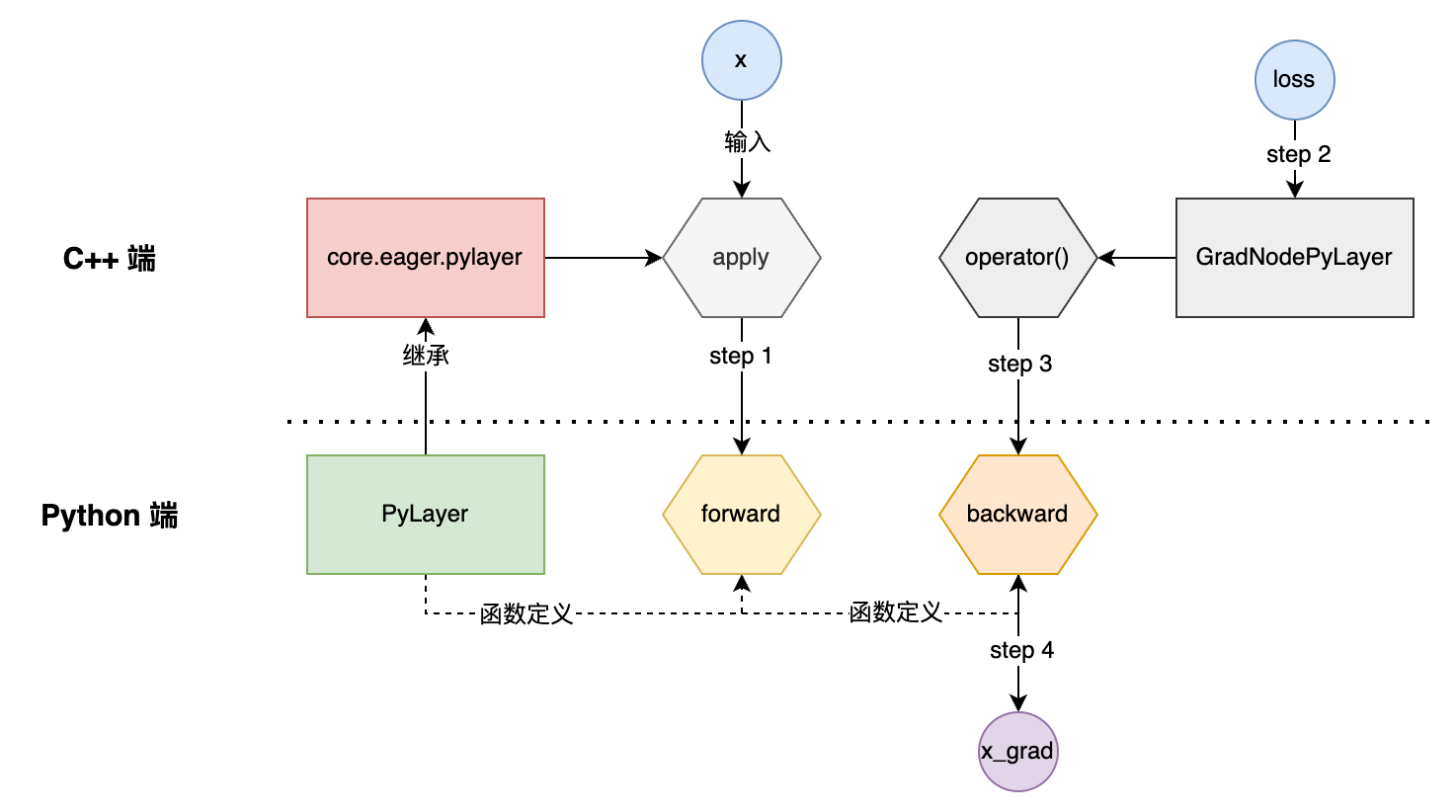
2.2.1 PyLayer 类
PyLayer 继承自 core.eager.PyLayer,提供了两个需要重写的接口:
class EagerPyLayer(
with_mateclass(EagerPyLayerMeta, core.eager.PyLayer,
EagerPyLayerContext)):
@staticmethod
def forward(ctx, *args, **kwargs):
raise NotImplementedError(
"You must implement the forward function for PyLayer.")
@staticmethod
def backward(ctx, *args):
raise NotImplementedError(
"You must implement the backward function for PyLayer.")
3.2.2 core.eager.PyLayer
C++ 端定义了一个 PyLayerObject 的结构体:
typedef struct {
PyObject_HEAD PyObject* container;
bool container_be_packed;
std::shared_ptr<egr::UnPackHookBase> unpack_hook;
PyObject* non_differentiable;
PyObject* not_inplace_tensors;
bool materialize_grads;
std::vector<bool> forward_input_tensor_is_duplicable;
std::vector<bool> forward_output_tensor_is_duplicable;
std::weak_ptr<egr::GradNodePyLayer> grad_node;
} PyLayerObject;
借助 BindEagerPyLayer() 函数实现了关键属性、方法的bind:
void BindEagerPyLayer(PyObject* module) {
auto heap_type = reinterpret_cast<PyHeapTypeObject*>(
PyType_Type.tp_alloc(&PyType_Type, 0));
heap_type->ht_name = ToPyObject("PyLayer");
heap_type->ht_qualname = ToPyObject("PyLayer");
auto type = &heap_type->ht_type;
type->tp_name = "PyLayer";
type->tp_basicsize = sizeof(PyLayerObject);
type->tp_dealloc = (destructor)PyLayerDealloc;
type->tp_methods = pylayer_methods; // <----- 核心方法
type->tp_getset = pylayer_properties; // <----- 核心属性
type->tp_new = (newfunc)PyLayerNew;
// 省略
}
后端绑定的只有两个method,一个是 name() ,另一个是apply(self, *args, **kwargs) ,后者是PyLayer核心逻辑:
- 首先会解析用户传入的args和kwargs参数
- 然后调用用户的forward函数:
outputs = PyObject_Call(forward_fn, forward_args, kwargs); - 创建反向grad_node节点:GradNodePyLayer
- 当用户调用
loss.backward()时,最终会执行GradNodePyLayer::operator()- 在C++端调用用户的backward函数:
auto outputs = PyObject_CallObject(backward_fn, backward_args);
- 在C++端调用用户的backward函数:
对于反向GradNodePyLayer,其继承自GradNodeBase,核心成员如下:
class GradNodePyLayer : public GradNodeBase {
public:
GradNodePyLayer(PyObject* ctx,
size_t bwd_in_slot_num,
size_t bwd_out_slot_num)
: GradNodeBase(bwd_in_slot_num, bwd_out_slot_num) {
ctx_ = ctx;
Py_INCREF(ctx_);
}
private:
PyObject* ctx_{nullptr}; //<----- 记录了Pythond端的PyLayer对象,用于获取backward函数指针
std::vector<std::vector<phi::DenseTensorMeta>> forward_outputs_meta_;
std::vector<std::vector<paddle::platform::Place>> forward_outputs_place_;
};
三、静态图
在静态图下,已知的是4年前实现的 py_func_op算子(框架中还有一个PyLayerOp,将在下文中阐述),OpMaker定义如下:
class PyFuncOpMaker : public framework::OpProtoAndCheckerMaker {
public:
void Make() override {
AddInput("X", "Inputs of py_func op.").AsDuplicable();
AddOutput("Out", "Outputs of py_func op").AsDuplicable();
AddAttr<int>(kForwardPythonCallableId,
"Index of registered forward Python function.")
.SetDefault(0);
AddAttr<int>(kBackwardPythonCallableId,
"Index of registered backward Python function.")
.SetDefault(-1);
AddAttr<std::vector<std::string>>(kPyFuncBackwardSkipVars,
"Unused forward in/out in backward op")
.SetDefault(std::vector<std::string>());
AddComment(R"DOC("PyFunc Op")DOC");
}
};
3.1 主要用法
如下是单测里的用法样例:
def simple_fc_net(img, label, use_py_func_op):
hidden = img
for idx in range(4):
hidden = fluid.layers.fc(
hidden,
size=200,
bias_attr=fluid.ParamAttr(initializer=fluid.initializer.Constant(
value=1.0)))
if not use_py_func_op:
hidden = fluid.layers.tanh(hidden)
else:
new_hidden = fluid.default_main_program().current_block(
).create_var(name='hidden_{}'.format(idx),
dtype='float32',
shape=hidden.shape)
hidden = fluid.layers.py_func(func=tanh, #<------ 前向函数
x=hidden,
out=new_hidden,
backward_func=tanh_grad, #<------ 反向函数
skip_vars_in_backward_input=hidden)
prediction = fluid.layers.fc(hidden, size=10, act='softmax')
if not use_py_func_op:
loss = fluid.layers.cross_entropy(input=prediction, label=label)
else:
loss = fluid.default_main_program().current_block().create_var(
name='loss', dtype='float32', shape=[-1, 1])
loss = fluid.layers.py_func(func=cross_entropy, #<------ 前向函数
x=[prediction, label],
out=loss,
backward_func=cross_entropy_grad, #<------ 反向函数
skip_vars_in_backward_input=loss)
dummy_var = fluid.default_main_program().current_block().create_var(
name='test_tmp_var', dtype='float32', shape=[1])
fluid.layers.py_func(func=dummy_func_with_no_input,
x=None,
out=dummy_var)
loss += dummy_var
fluid.layers.py_func(func=dummy_func_with_no_output, x=loss, out=None)
loss_out = fluid.default_main_program().current_block().create_var(
dtype='float32', shape=[-1, 1])
dummy_var_out = fluid.default_main_program().current_block().create_var(
dtype='float32', shape=[1])
fluid.layers.py_func(func=dummy_func_with_multi_input_output,
x=(loss, dummy_var),
out=(loss_out, dummy_var_out))
assert loss == loss_out and dummy_var == dummy_var_out, \
"py_func failed with multi input and output"
fluid.layers.py_func(func=dummy_func_with_multi_input_output,
x=[loss, dummy_var],
out=[loss_out, dummy_var_out])
assert loss == loss_out and dummy_var == dummy_var_out, \
"py_func failed with multi input and output"
loss = paddle.mean(loss)
return loss
经过单测测试,静态图下基于py_func_op 训练是支持的,也可以导出model文件。但加载时,会报错。提示找不到函数的定义。
InvalidArgumentError: Invalid python callable id 0, which should be less than 0.
[Hint: Expected i < g_py_callables.size(), but received i:0 >= g_py_callables.size():0.] (at /workspace/paddle-fork/paddle/fluid/operators/py_func_op.cc:52)
[operator < py_func > error]
从打印的program里来看,是添加的py_func算子:
{Out=['hidden_0']} = py_func(inputs={X=['fc_0.tmp_1']}, backward_callable_id = 1, backward_skip_vars = ['fc_0.tmp_1'], forward_callable_id = 0, op_device = , op_namescope = /, op_role = 0, op_role_var = [], with_quant_attr = False)
{Out=['hidden_1']} = py_func(inputs={X=['fc_1.tmp_1']}, backward_callable_id = 3, backward_skip_vars = ['fc_1.tmp_1'], forward_callable_id = 2, op_device = , op_namescope = /, op_role = 0, op_role_var = [], with_quant_attr = False)
{Out=['test_tmp_var']} = py_func(inputs={X=[]}, backward_callable_id = -1, backward_skip_vars = [], forward_callable_id = 10, op_device = , op_namescope = /, op_role = 0, op_role_var = [], with_quant_attr = False)
3.2 运行机制
在 fluid.layers.nn.py_func 定义如下:
def py_func(func, x, out, backward_func=None, skip_vars_in_backward_input=None):
# 注册前向函数
fwd_func_id = PyFuncRegistry(func).id
# 注册反向函数,如有必要
bwd_func_id = PyFuncRegistry(backward_func).id if backward_func is not None else -1
helper.append_op(type='py_func',
inputs={'X': x},
outputs={'Out': out_list},
attrs={
'forward_callable_id': fwd_func_id,
'backward_callable_id': bwd_func_id,
'backward_skip_vars': list(backward_skip_vars)
})
return out
可以看出前端API通过PyFuncRegistry来管理注册前向、反向函数,生成唯一的id,然后传递给py_func 算子,如下是其实现:
class PyFuncRegistry(object):
_register_funcs = [] # <--- 记录所有的注册函数
def __init__(self, func):
self._func = func
self._id = core._append_python_callable_object_and_return_id(self) # <--- 与C++端交互
PyFuncRegistry._register_funcs.append(self)
其中core._append_python_callable_object_and_return_id是通过pybind绑定到AppendPythonCallableObjectAndReturnId函数,它唯一的作用就是记录一个PyFuncRegistry对象(内部关联对应的前向或反向函数)
static std::vector<py::object> g_py_callables; // <---- 全局静态变量
size_t AppendPythonCallableObjectAndReturnId(const py::object &py_obj) {
g_py_callables.emplace_back(py_obj);
return g_py_callables.size() - 1;
}
前述我们在加载离线导出的model时会报”找不到对应的函数“,本质上是因为g_py_callables并没有被序列化保存下来,因为在执行py_func 算子时,会先去获取对应的PyObject:
// Return py::object* instead of py::object
// Returning py::object would cause reference count increasing
// but without GIL, reference count in Python may not be safe
static py::object *GetPythonCallableObject(size_t i) {
PADDLE_ENFORCE_LT(
i,
g_py_callables.size(),
platform::errors::InvalidArgument(
"Invalid python callable id %d, which should be less than %d.",
i,
g_py_callables.size()));
return &g_py_callables[i];
}
从框架中py_func的实现来看,其具有如下几个特点:
- 属于无Kernel算子。因为其直接继承 OperatorBase,类似控制流算子。
- 需要额外的管理注册函数的工具类,且目前不支持序列化。
四、PyLayer算子
除了上述静态图的py_func,一年之前框架中新增过一个py_layer_op,用户支持动态图Python端自定义OP的功能,相关背景描述见PR。
其算子描述为:
class PyLayerOpMaker : public framework::OpProtoAndCheckerMaker {
public:
void Make() override {
AddInput("X", "Inputs of PyLayer op.").AsDuplicable();
AddOutput("Out", "Outputs of PyLayer op").AsDuplicable();
AddComment(R"DOC("PyLayer Op")DOC");
}
};
void PyLayerGradOpMaker<paddle::imperative::OpBase>::Apply(
GradOpPtr<paddle::imperative::OpBase> grad_op) const {
grad_op->SetType("py_layer");
auto &inner_op = grad_op->InnerOp();
auto py_layer_op_const = dynamic_cast<const PyLayerOp *>(&inner_op);
if (py_layer_op_const) {
auto py_layer_op = const_cast<PyLayerOp *>(py_layer_op_const);
py_layer_op->SetPyLayerContext(py_context_);
} else {
PADDLE_THROW(platform::errors::Fatal(
"PyLayerGradOpMaker can't cast %s to PyLayerOp*.",
typeid(&inner_op).name()));
}
auto fwd_out_grads = this->OutputGrad("Out");
using return_type = decltype(fwd_out_grads);
return_type bwd_ins;
bwd_ins.insert(bwd_ins.begin(), fwd_out_grads.begin(), fwd_out_grads.end());
auto bwd_outs = this->InputGrad("X", false);
grad_op->SetInput("X", bwd_ins);
grad_op->SetOutput("Out", bwd_outs);
}
其kerenl实现:
template <typename DeviceContext, typename T>
class PyLayerOpKernel : public framework::OpKernel<T> {
public:
void Compute(const framework::ExecutionContext &ctx) const override {
auto &op_ = ctx.GetOp();
auto const_pylayer_op = dynamic_cast<const PyLayerOp *>(&op_);
if (const_pylayer_op) {
auto pylayer_op = const_cast<PyLayerOp *>(const_pylayer_op);
// Release contex after executing the compute
auto py_layer_context = pylayer_op->ReleasePyLayerContext();
py::object bk_ctx(py::handle(py_layer_context->GetMutableCtx()), true);
auto &input_vars = ctx.MultiInputVar("X");
auto output_vars = ctx.MultiOutputVar("Out");
RunPyObject(&bk_ctx, input_vars, &output_vars);
} else {
PADDLE_THROW(platform::errors::Fatal(
"PyLayerOpKernel can't cast %s to PyLayer*.", typeid(&op_).name()));
}
}
};
需要特别注意的是,此处的PyLayerOpKernel其实只负责执行反向,并不负责执行前向:
- 动态图下,前向是通过Apply()函数触发的,这个是通过pybind来实现的,见py_layer_fwd.h中的定义
- 在执行完反向之后,会调用一个
CreateGradOpNode函数,创建一个py_layer算子,负责执行反向- RunPyObject函数中始终是获取
auto py_function = py_object->attr("backward");这也是为什么PyLayerOpKernel只负责执行反向的原因。
- RunPyObject函数中始终是获取
飞桨动态图PyLayer机制的更多相关文章
- [PyTorch 学习笔记] 1.4 计算图与动态图机制
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson1/computational_graph.py 计算图 深 ...
- 【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?
参考文章: 深度剖析知识增强语义表示模型--ERNIE_财神Childe的博客-CSDN博客_ernie模型 ERNIE_ERNIE开源开发套件_飞桨 https://github.com/Pad ...
- Keil C动态内存管理机制分析及改进(转)
源:Keil C动态内存管理机制分析及改进 Keil C是常用的嵌入式系统编程工具,它通过init_mempool.mallloe.free等函数,提供了动态存储管理等功能.本文通过对init_mem ...
- php实现动态随机验证码机制(CAPTCHA)
php实现动态随机验证码机制 验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Ap ...
- Deeplearning——动态图 vs. 静态图
动态图 vs. 静态图 在 fast.ai,我们在选择框架时优先考虑程序员编程的便捷性(能更方便地进行调试和更直观地设计),而不是框架所能带来的模型加速能力.这也正是我们选择 PyTorch 的理由, ...
- Qt编写自定义控件59-直方动态图
一.前言 直方动态图类似于音乐播放时候的柱状图展示,顶部提供一个横线条,当柱状上升的时候,该线条类似于帽子的形式冲到顶端,相当于柱状顶上去的感觉,给人一种动态的感觉,听音乐的同时更加赏心悦目,原理比较 ...
- 小白学PyTorch 动态图与静态图的浅显理解
文章来自公众号[机器学习炼丹术],回复"炼丹"即可获得海量学习资料哦! 目录 1 动态图的初步推导 2 动态图的叶子节点 3. grad_fn 4 静态图 本章节缕一缕PyTorc ...
- 树莓派4B安装 百度飞桨paddlelite 做视频检测 (一、环境安装)
前言: 当前准备重新在树莓派4B8G 上面搭载训练模型进行识别检测,训练采用了百度飞桨的PaddleX再也不用为训练部署环境各种报错发愁了,推荐大家使用. 关于在树莓派4B上面paddlelite的文 ...
- 飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节.因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推 ...
- Wpf 中使用gif格式的动态图
第一种方法:使用winform插件 <WindowsFormsHost xmlns:wf="clr-namespace:System.Windows.Forms;assembly=S ...
随机推荐
- CH395的FTP Server(主动模式)简单应用参考
FTP(File Transfer Protocol,文件传输协议) 是 TCP/IP 协议组中的协议之一.FTP协议包括两个组成部分,其一为FTP服务器,其二为FTP客户端.本篇文章将基于FTP协议 ...
- #特征方程,dp,快速幂#洛谷 4451 [国家集训队]整数的lqp拆分
题目 分析 设\(dp[n]\)表示答案,因为\(dp[n]=\sum\prod_{i=1}^mF_{a_i}\) \(dp[n]=\sum_{i=1}^{n-1}dp[i]*F_{n-i-1}\) ...
- Python 学习路线:介绍、基础语法、数据结构、算法、高级主题、框架及异步编程详解
Python 介绍 Python 是一种 高级 的.解释型 的.通用 的编程语言.其设计哲学强调代码的可读性,使用显著的缩进.Python 是 动态类型 和 垃圾收集 的. 基本语法 设置 Pytho ...
- R语言学习3:数据框处理(1)
本系列是一个新的系列,在此系列中,我将和大家共同学习R语言.由于我对R语言的了解也甚少,所以本系列更多以一个学习者的视角来完成. 参考教材:<R语言实战>第二版(Robert I.Kaba ...
- 高并发报错too many clients already或无法创建线程
高并发报错 too many clients already 或无法创建线程 本文出处:https://www.modb.pro/db/432236 问题现象 高并发执行 SQL,报错"so ...
- Prometheus 性能调优-水平分片
简介 之前笔者有连续 2 篇文章: Prometheus 性能调优 - 什么是高基数问题以及如何解决? 如何精简 Prometheus 的指标和存储占用 陆续介绍了一些 Prometheus 的性能调 ...
- 抓包整理————tcp 三次握手性能优化[十]
前言 tcp 三次握手性能优化. 正文 服务器三次握手流程示例: 下面就是3次握手的过程: 知道这个有什么用呢? 我举一个我使用到的例子哈. 比如有很多 tcp 连接到一台机器上机器上,那么tcp_m ...
- nginx重新整理——————nginx 模块[十]
前言 简单介绍一下nginx的模块. 正文 https://nginx.org/en/docs/ 这里面可以看到官方模块. 比如打开这个模块: https://nginx.org/en/docs/ht ...
- 重新点亮shell————函数[七]
前言 简单整理一下函数. 正文 自定义函数: function fname(){ 命令 } 函数的执行: fname 函数作用范围的变量: local 变量名 函数的参数 $1 $2 $3 .... ...
- 重新整理.net core 计1400篇[三] (.net core 如何源代码调试和查看源码 )
前言 本来这里是写源代码的,因为vs没有那么容易调试查看到源代码,所以先把调试源代码和查看源代码弄完. 正文 需要修改一些vs配置,这个vs也是有要求的,要vs2017. 那么你还需要加载远程符号. ...