集成学习与随机森林(四)Boosting与Stacking
Boosting
Boosting(原先称为hypothesis boosting),指的是能够将多个弱学习器结合在一起的任何集成方法。对于大部分boosting方法来说,它们常规的做法是:按顺序训练模型,每个模型都会尝试修正它的前一个模型。Booting 方法有很多种,不过到现在为止最热门的是AdaBoost(Adaptive Boosting的简称)和Gradient Boosting。我们首先看一下AdaBoost。
AdaBoost
其中一个让一个新模型修正它前一个模型的方法是:放更多的精力在前任模型欠拟合的训练数据实例上。结果就是接下来的模型们会放越来越多的精力在那些难处理的条目上。这个就是AdaBoost所用的技巧。
例如,在训练一个AdaBoost 分类器时,算法首先训练一个基分类器(例如决策树),然后使用它在训练集上做预测。算法然后增加那些分类错误的训练数据条目的相对权重。接着它开始训练第二个分类器,使用更新后的权重值,并在训练结束后再次在训练集上做预测,更新数据实例的权重,诸如此类。如下图所示:

下图展示的是5个连续的模型 ,使用的训练集是moons 数据集(在这个例子中,每个模型都是一个高度正则后的SVM分类器,使用RBF核)。第一个分类器有很多实例都分类错误,所以这些实例的权重得到增强。第二个分类器因此在这些实例上获得了更好的表现;依次类推。右边的图是同样一个5连续的模型,除了它的learning_rate 进行了减半(也就是说,被错误分类的实例的权重在每轮的增强都减半)。我们可以看到,这个顺序学习技术与梯度下降有些类似,不过梯度下降调整的是单个模型的参数,以最小化损失函数;而AdaBoost是在集成中增加模型,逐渐的让集成更优秀。

对于连续学习技术来说,有一个非常重要的缺点:它无法并行(或者仅能部分并行),因为每个模型只能在前一个模型训练完并评估后才能开始训练。所以导致它的扩展不如bagging或pasting好。
我们进一步看一下AdaBoost算法,每个实例的权重w(i) 在初始设置为 1/m。在第一个模型训练后,会在训练集上计算它的带权错误率,如下所示:

然后使用以下公式计算出模型权重αj :

这里η是超参数学习率(默认为1)。模型的准确度越高,则它的权重也会更高。如果它仅是一个随机猜测的模型,则它的权重会接近于0。不过,如果它的预测错误率非常高的话(例如比随机猜的正确率还要低),则它的权重会是负值。
然后,AdaBoost算法会更新实例的权重,使用以下公式,增加错误分类实例的权重:
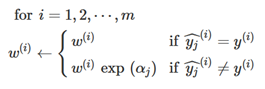
然后所有的实例权重会被标准化(也就是说除以∑w(i))
最后,一个新的模型会使用权重更新后的训练集进行训练,并且整个过程迭代(新模型的权重被计算,实例权重更新,然后下一个模型开始训练,依次类推)。在达到了指定的模型数量,或是一个非常完美的模型被发现后,算法终止。
在做预测时,AdaBoost会计算所有模型的预测,然后使用模型的权重αj给预测结果加权。最终输出的预测类是获取最多带权票数的那一类,如下公式所示:
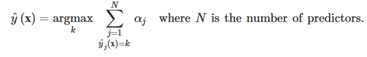
Sk-learn使用了AdaBoost的一个多类别分类版本,称为SAMME(Stagewise Additive Modeling using a Multiclass Exponential loss function)。如果目标类别仅有2类,则SAMME等同于AdaBoost。如果模型可以预测类别的概率(例如它们有predict_proba() 方法),则sk-learn可以使用一个SAMME的变种,称为SAMME.R(这里R代表Real),它基于的是预测类别的概率,而不是直接预测类别,一般这种表现会更好。
下面的代码训练一个AdaBoost分类器,基于的是200个决策桩(Decision Stumps,也就是只有一层的决策树),使用sk-learn的AdaBoostClassifier 类(同理,也有AdaBoostRegressor类)。决策桩就是单决策节点带两个叶子节点,它是AdaBoostClassifier类默认的基模型:
from sklearn.ensemble import AdaBoostClassifier ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5)
ada_clf.fit(X_train, y_train)
如果AdaBoost 集成在训练集上过拟合,则我们可以尝试减少模型的数量,或是对基模型使用更强的正则。
Gradient Boosting
另一个非常人们的boosting 算法是Gradient Boosting。与AdaBoost 类似,Gradient Boosting也是将模型按顺序增加到集成中,每个模型都会修正它的前一个模型。但是,与AdaBoost在每轮调整实例的权重不一样,Gradient Boosting方法会尝试将新的模型与前一个模型的残差(residual errors)进行拟合。
我们先看一个简单的回归例子,使用决策树作为基模型,这个称谓Gradient Tree Boosting,或Gradient Boosted Regression Trees(GBRT)。首先,我们用一个DecistionTreeRegressor拟合训练数据(例如,带噪声的二次方训练集):
from sklearn.tree import DecisionTreeRegressor tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X, y)
然后,我们训练第二个DecisionTreeRegressor,基于第一个模型产生的残差进行训练:
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X, y2)
接下来训练第三个回归器,基于第二个模型产生的残差进行训练:
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X, y3)
现在我们有了一个集成,包含3棵树。它在对一个新实例做预测时,会简单地将所有树的输出进行相加:
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
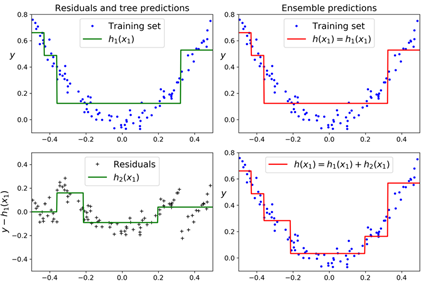
下图中的左图展示的是这3棵树的预测,右图代表的是集成器的预测。在第一行,集成仅有一棵树,所以它的预测与左边的树的预测完全一样。在第二行,一颗新树基于第一棵树的残差进行了训练。在第二行右边,我们可以看到集成器的预测等同于前两颗树的和。类似,第三行训练的第三棵树基于的是第二颗树的残差进行训练。我们可以看到集成器的预测表现随着加入的数越多而表现的越好。

另外一个跟简单的训练GBRT集成器的方法是使用sk-learn的GradientBoostingRegressor类。它与RandomForestRegressor类类似,有超参数用于控制如何构造决策树(例如max_depth, min_samples_leaf),以及超参数控制集成器的训练,例如树的个数(n_estimators)。下面的代码训练了与上述模型同样的一个集成器:
from sklearn.ensemble import GradientBoostingRegressor gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
gbrt.fit(X, y)
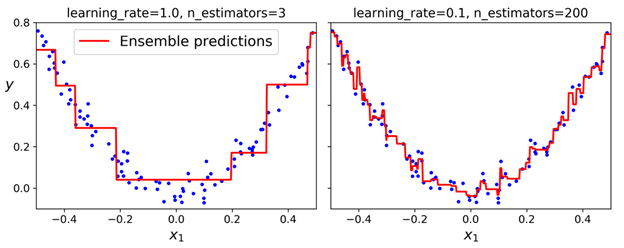
learning_rate 超参数控制的是每棵树的贡献。如果将它设置一个很小的值,例如0.1,则我们的集成器需要更多的树来拟合训练集,不过预测的泛化性能一般会更好。这是一个正则技巧,称为收缩(shrinkage)。下图展示的是两个使用了低学习率的GBRT集成器,左边的集成器没有足够的树来拟合数据,而右边的集成器包含的树太多,导致了在训练集上的过拟合。
为了找到最佳数目的树,我们可以使用early stopping。一个简单的实现办法是使用staged_predict() 方法:它返回一个迭代器,包含的是集成器在每个阶段训练(例如使用一棵树,两棵树,等等)后做的预测。下面的代码训练了一个GBRT集成器,使用120棵树,然后在每个训练阶段衡量它的交叉错误(validation error),以找到最优数目的树,并最终训练另一个GBRT集成器,使用最优数目的树:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error X_train, X_val, y_train, y_val = train_test_split(X, y) gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gbrt.fit(X_train, y_train) errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors) + 1 gbrt_best = GradientBoostingRegressor(max_depth=2, n_estimators=bst_n_estimators)
gbrt_best.fit(X_train, y_train)
交叉错误(validation errors)如下图左图所示,最佳模型的预测结果如右图所示:

上面实现early stopping 的办法是先训练大量数目的数模型,然后再回看去找最优。不过我们也有其他的方式实现真正意义上的提前结束(early stopping)。我们可以通过设置warm_start=True 参数,这样sk-learn会在调用fit() 方法后保留已存在的树,允许增量训练。下面的代码会在5轮迭代后交叉错误仍未提升时停止训练:
gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if val_error < min_val_error:
error_going_up = 0
else:
error_going_up += 1
if error_going_up == 5:
break # early stopping
GradientBoostingRegresoor类也支持一个subsample的超参数,它可以指定使用训练集的多少比例去训练每颗树。例如,如果设置subsample=0.25,则每棵树会在25%的训练实例上进行训练,选择的方式是随机选择。同样,这里也是为了得到更低的variance而牺牲了低bias(bias会更高,更欠拟合)。它也可以极大的提升训练的速度,称为随机梯度增强(Stochastic Gradient Boosting)。
其实我们也可以为Gradient Boosting 指定其他损失函数,这个由loss 超参数控制。具体可以参考sk-learn 的文档。
这里有必要提示的是,Gradient Boosting 其中的一个优化后的实现是XGBoost,非常热门的一个python库。XGBoost在ML比赛中是非常常用的一个组件,并且它的使用方法也类似于sk-learn:
import xgboost xgb_reg = xgboost.XGBRegressor()
xgb_reg.fit(X_train, y_train)
y_pred = xgb_reg.predict(X_val) XGBoost也提供了一些非常好的功能,例如自动控制提前结束(early stopping):
xgb_reg.fit(X_train, y_train,
eval_set=[(X_val, y_val)], early_stopping_rounds=2)
y_pred = xgb_reg.predict(X_val)
请务必要尝试XGBoost!
Stacking
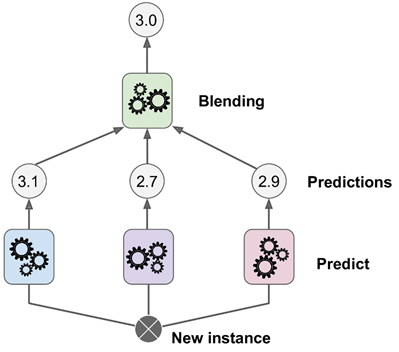
最后要提的一个集成方法是stacking(stacked generalization的简称),它基于的原理很简单:与其使用一个简单的方法(例如硬投票)来聚合集成器中所有模型的预测结果,为什么不直接训练一个模型来执行这个聚合呢?下图展示的就是这样一个集成器,它在一个新的实例上执行一个回归任务。最底层的3个模型都预测了一个不同的值(3.1,2.7和2.9),然后最后的一个模型(称为 blender,搅拌器,或是meta learner,元学习器)接收这些预测值并作出最终的预测。
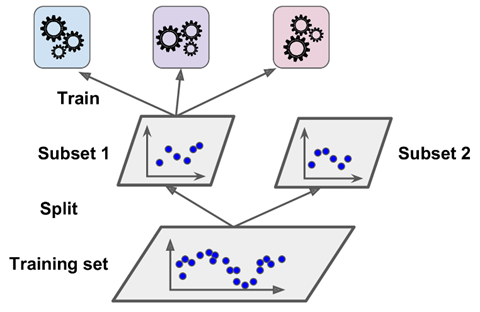
在训练一个blender时,一个常见的办法是使用 hold-out 集,它的工作原理为:首先,训练集被分类成2个子集。第一个子集用于在第一层训练模型,如下图所示:
然后,第一层的模型会在第二个子集(held-out 集)上做预测(如下图所示)。这样可以确保预测值是干净、不受影响的,因为模型在训练过程中不会看到这些实例。对于每个在hold-out集中的实例,它都有3个预测值。我们可以使用这些预测值创建一个新的训练集作为输入特征(会让这个新训练集变为3维),并保留目标值(target或label)。blender在这个新训练集上进行训练,所以它会根据第一层的预测,学习如何预测目标值。

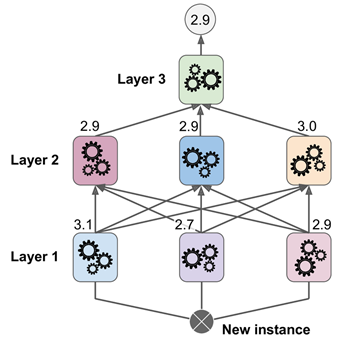
实际上也可以通过这种方式训练多个不同的blenders(例如,一个使用线性回归,另一个使用随机森林回归),来得到一整个blenders层。办法是将训练集分割为3个子集(第一个用于训练第一层,第二个用于创建新训练集给第二层模型训练(使用第一层的预测值作为第二层的训练数据),然后第3个子集用于给第3层模型训练创建训练数据(使用第二层的预测数据作为训练数据)。在这个过程完成后,在做预测时,新实例会按顺序经过每一层后,输出预测值,如下图所示:
可惜的是,sk-learn并未直接支持stacking,不过实现它也不是特别困难。或者我们也可以使用开源的实现例如DESlib。
集成学习与随机森林(四)Boosting与Stacking的更多相关文章
- bagging与boosting集成学习、随机森林
主要内容: 一.bagging.boosting集成学习 二.随机森林 一.bagging.boosting集成学习 1.bagging: 从原始样本集中独立地进行k轮抽取,生成训练集.每轮从原始样本 ...
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 决策树--------------------------------------------- ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 集成学习的不二法门bagging、boosting和三大法宝<结合策略>平均法,投票法和学习法(stacking)
单个学习器要么容易欠拟合要么容易过拟合,为了获得泛化性能优良的学习器,可以训练多个个体学习器,通过一定的结合策略,最终形成一个强学习器.这种集成多个个体学习器的方法称为集成学习(ensemble le ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 常用的模型集成方法介绍:bagging、boosting 、stacking
本文介绍了集成学习的各种概念,并给出了一些必要的关键信息,以便读者能很好地理解和使用相关方法,并且能够在有需要的时候设计出合适的解决方案. 本文将讨论一些众所周知的概念,如自助法.自助聚合(baggi ...
随机推荐
- MacBook M1 虚拟机安装Windows for ARM使用体验
前言 大家好,我是 刚进入春天还没来得及踏青又开始从早忙到晚的 蛮三刀.去年给大家带来了一篇比较详尽的MacBook M1评测.评测经历了全网的热情转载,成为了我唯一的一篇爆款文章(我该哭还是该笑!) ...
- ES_CCS/R(一):建立集群之间的安全互信
为了能够实现 CCR(跨集群复制 Cross-cluster replication) 及 CCS(跨集群搜索 Cross-cluster search ),我们必须让集群之间能够互信,这样才可以建立 ...
- JDK源码阅读-------自学笔记(十六)(java.util.Random随机数类)
Random类简介 如果使用Math.random()计算过于复杂的话,我们可以使用例外一种方式得到随机数,即Random类,这个类是专门用来生成随机数的,并且Math.random()底层调用的就是 ...
- pageoffice 6版本隐藏office工具栏和自定义按钮,并修改标题栏内容
在实际项目集成调用PageOffice的过程中: (1)有时需要把Office的工具栏隐藏,比如只读模式打开文件的时候,Office工具栏上的按钮几乎都是灰掉的,此时显示Office工具栏没有任何意义 ...
- 基于AIRIOT平台构建低成本、更聪明的智能环卫系统,让管理更加高效智能
环卫工程作为城市基础设施保障,是城市建设管理中不可或缺的重要组成部分.随着城市进程的加快及技术的进步,环卫工程管理也在逐渐向精细化.智能化.绿色化等趋势发展. 智能环卫依托物联网.AI.大数据等技术, ...
- Axure和墨刀——两款原型设计工具介绍
Axure与墨刀是两款在原型设计领域广受欢迎的工具,各具特点和优势: Axure: Axure RP是一款功能强大的原型设计工具,广泛应用于交互设计和用户体验设计领域.它提供了丰富的交互元素库.高保真 ...
- 关于EF Core 更新速度随时间越来越慢的解决办法
关于EF Core更新速度随时间越来越慢的解决办法 概要 本篇主要介绍使用 context.ChangeTracker.Clear() 方法,在通过循环进行批量更新时,通过手动清除跟踪实体以提高性能的 ...
- 「Python实用秘技17」快速获取国内节假日安排
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第17 ...
- CSS操作——列表属性
CSS中提供了一些列表属性可以用来: (1).设置不同的列表项标记为有序列表 (2).设置不同的列表项标记为无序列表 (3).设置列表项标记为图像 list-style-type(系统提供 ...
- Ubuntu20.04安装MySQL5.7
ubuntu 20.04系统自带源直接安装的是MySQL 8.0,要安装MySQL 5.7的话,需要先换源. 1.换源 sudo cp /etc/apt/sources.list /etc/apt/s ...