文件系统(八):Linux JFFS2文件系统工作原理、优势与局限
liwen01 2024.06.23
前言
在嵌入式Linux设备中,经常使用jffs2文件系统来作为参数区的文件系统格式。至于为什么要使用jffs2来作为参数区的文件系统,我猜大部分人都没有做过多的思考。
jffs2在2021年被设计出来,距今已过二十多年,现在在嵌入式设备中它还在被大量使用、说明这套设计本身是没有问题。
但是,你是否有思考过,你的jffs2文件系统使用是否正确、合理?如果你存储文件某天突然不见了,你要怎么分析?是flash有坏块,还是被jffs2垃圾回收处理掉了?亦或是应用程序误删除了?又要怎样才能把它恢复回来?
先问几个问题:
- 如果jffs2系统中数据频繁更新会有什么影响?
- 如果jffs2系统分区比较大会有什么影响?
- 如果分区全部写满有什么影响?
- 如果出现文件或是数据丢失,可以恢复回来不?
(一)闪存文件系统分类
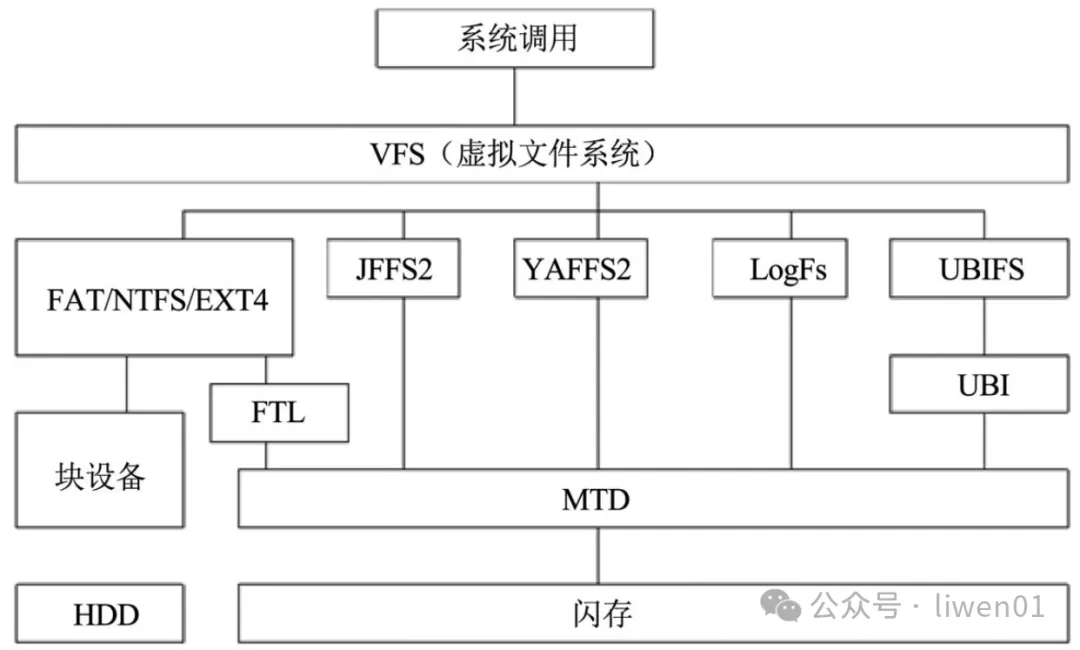 图1.1 闪存文件系统层次结构
图1.1 闪存文件系统层次结构
我们前面介绍的FAT32、exFAT、ext4文件系统,在闪存存储设备中,它们是通过FTL中间层使它们适用于闪存。
但是在嵌入式设备开发中,我们有时候是直接基于闪存来使用,比如上面提到的,在flash中划分为一个分区来用存储参数。
jffs 有三个版本,jffs1出来后一两年就被jffs2替代了,而jff3好像是有被定义,但是还未实现。
jffs1与jffs2 并不兼容,基本上属于重新实现,它们都是基于linux操作系统,flash存储介质的一种文件系统。虽然支持移植,但并未看到Linux系统之外的其它系统有在使用jffs文件系统。
关于存储介质、文件系统、分区、格式化等内容,可以查看前面的文章。
文件系统(一):存储介质、原理与架构 文件系统(二):分区、格式化数据结构 文件系统(三):嵌入式、计算机系统启动流程与步骤 文件系统(四):FAT32文件系统实现原理 文件系统(五):exFAT 文件系统原理详解 文件系统(六):一文看懂linux ext4文件系统工作原理 文件系统(七):文件系统崩溃一致性、方法、原理与局限
(二)JFFS1介绍
JFFS 文件系统是2000年由 Axis Communications针对nor flash 设计的一个日志文件系统(Log-structured File System)。
它是基于日志文件系统(LFS)原理设计的一款文件系统,关于LFS可以查看文章:《文件系统(七):文件系统崩溃一致性、方法、原理与局限》
(1)数据存储
 图2.1 jffs1数据分布
图2.1 jffs1数据分布
第一版本的JFFS是一个纯日志结构文件系统,包含数据和元数据的节点,按顺序存储在闪存芯片上,严格线性地遍历可用的存储空间。
挂载时系统会扫描整个存储介质,读取并解释每个节点。原始节点中存储的数据提供了足够的信息来重建整个目录层次结构和每个inode在介质上的数据范围的物理位置的完整映射。
(2)垃圾回收
采用日志文件系统,随着数据的增、删、改操作,jffs文件系统的空间会被慢慢使用完,这个时候就需要启动垃圾回收机制了。
 图2.2 jffs1数据回收
图2.2 jffs1数据回收
在jffs1系统中,垃圾回收也是完全按照线性规则来回收,大致步骤如图2.2 jffs1数据回收:
状态1:数据按序存储。这个时候并未开始垃圾回收
状态2:开始垃圾回收,将最早节点中的有效数据移动到后面,标记原来数据为无效数据(脏数据)
状态3:重复状态2操作,直到脏数据空间达到可擦除的最小单位。
状态4:将脏数据擦除,标记为空。
(3)缺点
从上面的数据分布和垃圾回收机制,我们可以看出jffs v1版本的实现存在一些严重缺陷:
- 垃圾回收线性进行,通过写入新节点以允许它擦除日志中最旧的块,即使被垃圾回收的块仅包含干净的节点。
- 如果文件系统中存在大量的静态数据、垃圾回收的时候也会移动所有的静态数据,虽然每个块被擦除的次数完全相同、但这也意味着块被擦除的次数比实际需要的要多。
- JFFS 不支持压缩,在资源紧张的嵌入式系统中,这是一个比较重要的需求
针对jffs1中的缺陷,就有了jffs的第二个版本,也就是jffs2。
(三)JFFS2 数据布局
(1)制作jff2镜像文件
- 创建测试目录和文件,在file1-4中随意输入一些数据
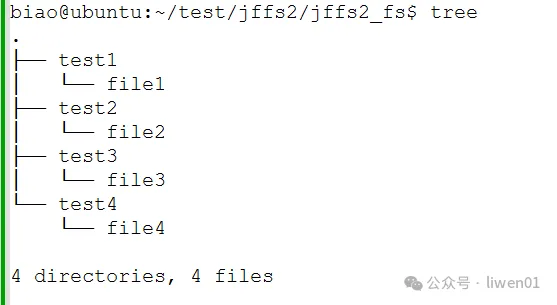
- 制作镜像文件
mkfs.jffs2 -s 0x100 -e 0x10000 -p 0x100000 -d jffs2_fs -o jffs2.img- s表示页大小,一般页大小为256Byte,即0x100
- e表示擦除块大小,一般块大小为64KB,即0x10000
- p表示分区大小,在生成时会擦除分区大小的flash,x100000表示1MB
(2)加载jffs2镜像文件到PC机上
- 加载MTD块设备模块,使得MTD设备能够通过块设备接口进行访问
sudo modprobe mtdblock- 加载内存设备模块,并配置虚拟的内存技术设备
sudo modprobe mtdram total_size=1024 erase_size=64modprobe: 加载指定的内核模块,并自动处理模块之间的依赖关系。mtdram: 需要加载的内核模块名称,表示内存设备的模拟。total_size=1024: 指定虚拟MTD设备的总大小,单位KB,这里总大小为1MB。erase_size=64: 指定虚拟MTD设备的擦除块大小,单位KB,这里擦除块大小为64KB。
- 将镜像文件复制到mtdblock0节点上
sudo dd if=jffs2.img of=/dev/mtdblock0- 将镜像文件以jffs2类型挂载到指定目录
sudo mount -t jffs2 /dev/mtdblock0 /home/biao/test/jffs2/jffs2_simulator/(3)查看分区信息
- 使用jffs2dump查看jffs镜像信息
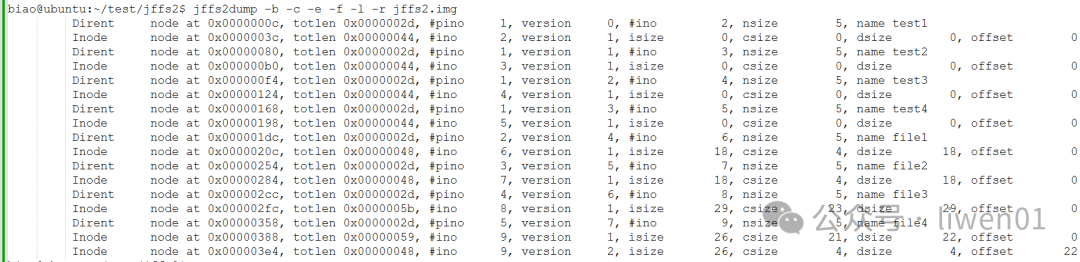
- 查看mtdblock0设备节点上的信息
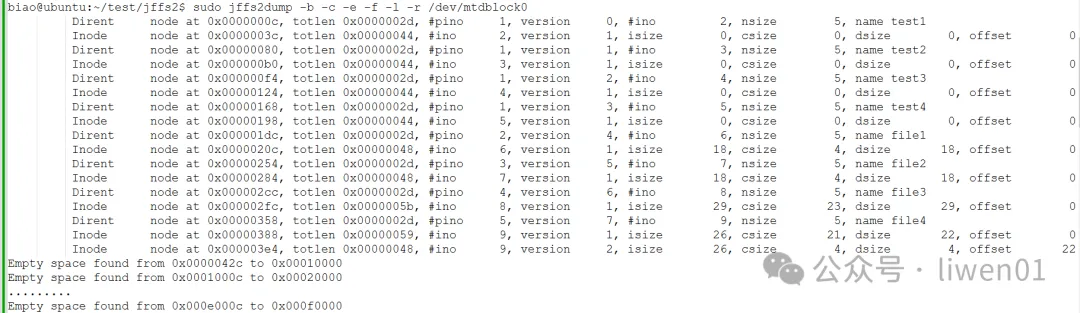
可以看到/dev/mtdblock0设备节点上的数据与jffs2.img镜像文件上的数据信息是一致的。
不同的是,mtdblock0是实际分配的1M空间,除了有效数据空间外,其它都是空闲地址(Empty space)
(四)JFFS2数据解析
(1)查看block数据
- 使用hexdump查看mtdblock0节点前面2KB的数据,数据如下(...中为省略部分)

(2)数据结构定义
magic: 魔术数字,用来标识是一个有效的JFFS2项
nodetype: 节点类型,在jffs2.h中有定义7种类型
nodetype对应的值如下:
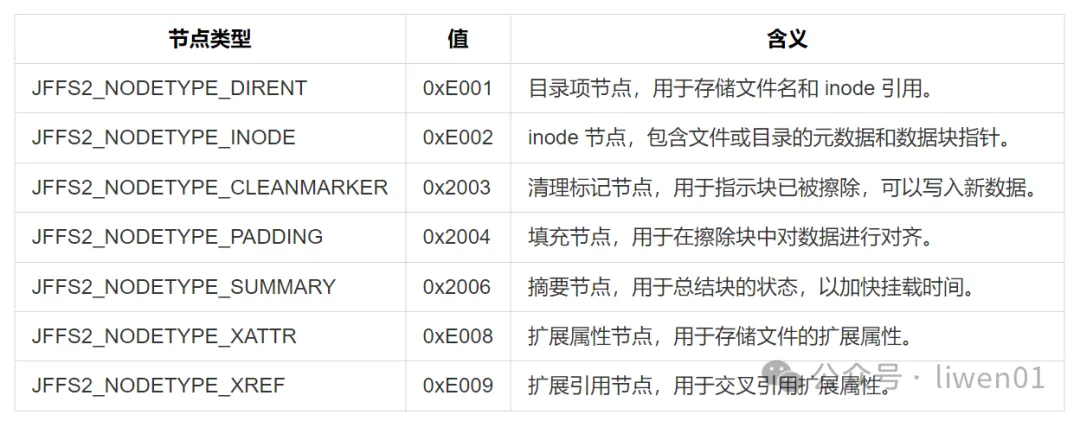
详细的定义可以查看mtd-utils/include/linux/jffs2.h
数据结构
所有的节点,都是以jffs2_unknown_node数据结构开始:幻数、类型、长度、CRC校验,定义如下:
struct jffs2_unknown_node
{
/* All start like this */
jint16_t magic;
jint16_t nodetype;
jint32_t totlen; /* So we can skip over nodes we don't grok */
jint32_t hdr_crc;
} __attribute__((packed));另外:
- 目录信息存储在
jffs2_raw_dirent结构体中 - 文件中的实际数据信息存储在
jffs2_raw_inode结构体中
结构体的详细定义,可以在mtd-utils中的源码中找到
(3)目录、文件解析
按上面hexdump查看的mtdblock0 RAW数据进行解析,可以发现,解析的数据与jffs2dump中查看的信息是一致的。
下面分析的这个test1目录,是在我们最开始制作镜像文件的时候创建的目录。
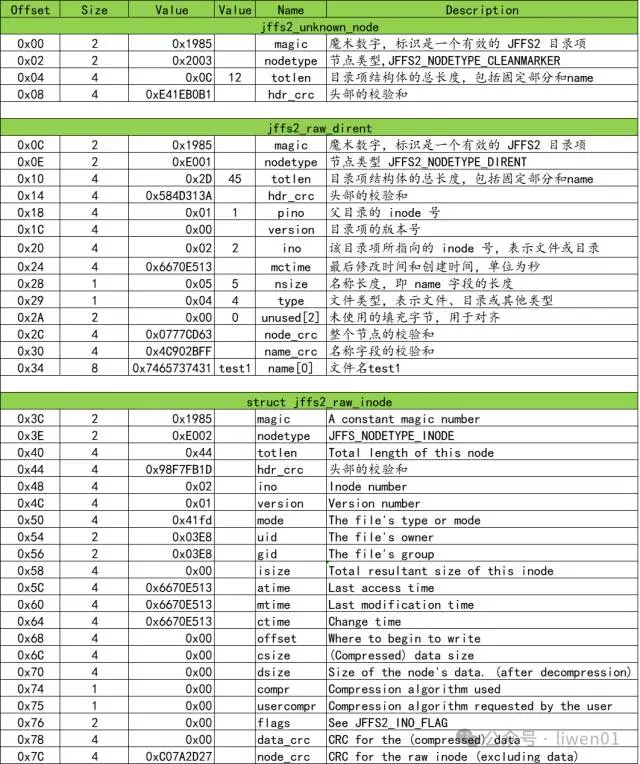
这里需要注意的一点是,在分区的最开始,是一个jffs2_unknown_node数据结构头,它的节点类型是JFFS2_NODETYPE_CLEANMARKER,表示清理标记节点,用于指示块已被擦除,可以写入新数据。
接下来的是test1目录的目录项节点和它的inode节点。它的inode节点里面据段的数值是空,并没有携带数据块。
其它的几个目录test2、test3、test4数据结构也是类似。
文件解析
下面分析的这个文件,是制作镜像文件时创建的file1文件,里面存有18个字节的a字符串,文件信息如下:

下面根据hexdump中查看的mtdblock0 RAW数据对file1文件进行解析,如下表
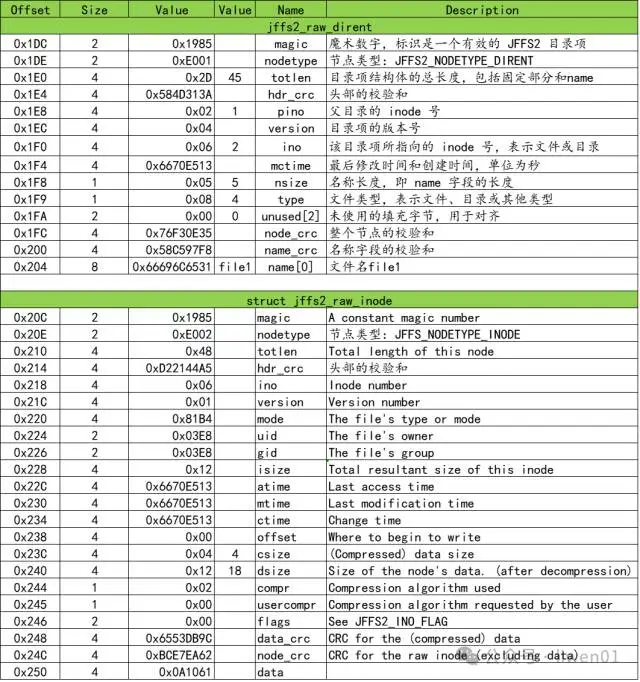
与test1目录不同,file1 有携带数据。上面表格中compr 字段表示数据的压缩类型。
数据压缩类型定义如下:
#define JFFS2_COMPR_NONE 0x00
#define JFFS2_COMPR_ZERO 0x01
#define JFFS2_COMPR_RTIME 0x02
#define JFFS2_COMPR_RUBINMIPS 0x03
#define JFFS2_COMPR_COPY 0x04
#define JFFS2_COMPR_DYNRUBIN 0x05
#define JFFS2_COMPR_ZLIB 0x06
#define JFFS2_COMPR_LZO 0x07与文件中实际数据对比可以看到,这里记录的数据,是将18Byte字节的18个a压缩成了4个字节。
(4)追加数据
使用echo添加数据到file1
echo"bbbbbbbbbbbbbbbbbbb" >> file1查看数据变化:

我们看到inode 6 新增加了一个版本记录version2:
Inode node at 0x0000042c, totlen 0x0000004e, #ino 6, version 2, isize 38, csize 10, dsize 22, offset 16而inode 6 表示的就是file1文件。实际追加的数据是记录在version2 节点中,而原来的18个字节a数据,还是存在原来version1中的节点。
(5)修改数据
使用echo写数据到文件file1
echo"cccc" > file1数据变化:

从上面我们可以看到:
- file1 的目录项是没有变的
- file1 的数据项是有3个修改记录,也就是version1 - version4
为什么会有3个修改记录?实际上是执行上面一个操作它是两个步骤完成的,也就是一个操作中有了两个记录。
version 1 :原始数据,未进行修改
version 2 :是上面执行echo "bbbbbbbbbbbbbbbbbbb" >> file1 命令在file1文件末尾追加的数据
version 3 :执行echo "cccc" > file1 命令时,是先把file1文件数据全部清空
version 4 :执行echo "cccc" > file1 命令时,把cccc字符写入到file1文件中的记录
标记数据无效上面我们看到执行4个记录之后,最后文件中的数据是"cccc",但是之前的数据要怎么处理呢?是直接删除回收还是怎么处理呢?
我们看到version 1 - version 3 的前面,有标记为 Obsolete Inode,它表示为一个过时的节点,也就是一个未知的节点,这个节点是不能够被挂载解析的。
它在flash中实际的数据又有哪些变化呢?
使用hexdump查看version 1 中的RAW数据
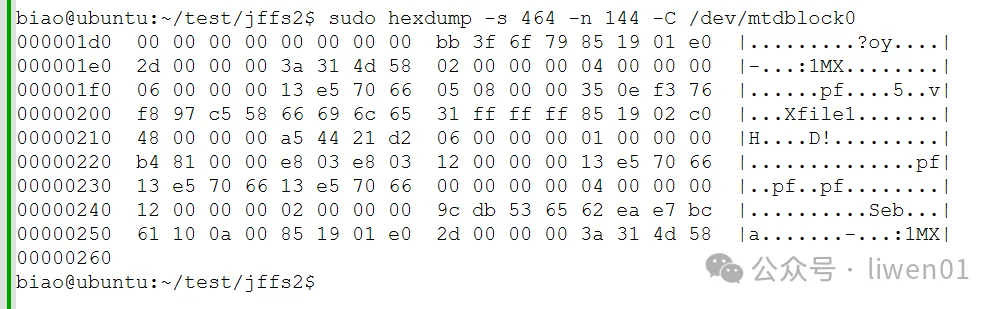
对比原始数据,只有一个字节改变,nodetype 由原来的0xE002 改为了0xC002
 图4.5.3数据对比
图4.5.3数据对比
0xC000的定义如下:
/* Compatibility flags. */
#define JFFS2_COMPAT_MASK 0xc000 /* What do to if an unknown nodetype is found */(6)数据压缩
下面我们往file1中一次写入256K的0数据,看数据分布会怎么变化
dd if=/dev/zero of=file1 bs=256K count=1执行第一遍结果如下:

执行到第二十遍结果如下:

实际写入数据有256K*20 = 5120KB = 5M
为什么实际写入数据5M,但是MTD的空间只使用到0x0005ff64,也就是383K的空间呢?
因为我们使用的是dd if=/dev/zero of=file1 bs=256K count=1 命令写入的数据都是0,全是0的数据是很容易压缩的,这338K空间实际是压缩后的使用空间。
看数据:
csize 32, dsize 4096,实际数据4096字节,压缩后变成了32字节。
(7)垃圾回收
在最前面制作镜像文件挂载虚拟MTD设备的时候,我们分配的大小是1M空间,理论上我们操作的数据记录超过1M就一定会进行垃圾回收,实际是不是这样呢?
上面我们写的全0数据是很容易压缩,所以实际保存的数据要比文件小很多。这里我们写入随机数,让数据记录快速写满整个分区空间,看jffs2是如何进行垃圾回收的。
dd if=/dev/urandom of=file1 bs=1K count=20执行第一次,数据是按序分布
 数据4.7.1 第一次执行
数据4.7.1 第一次执行
执行第二次,数据开始跳跃分布,数据分配到0x0000fa00地址就直接跳到0x000d000c位置开始存储,中间间隔了0xc060c 个地址,也就是769K地址,实际是直接跳到了分区的后半段去分配。
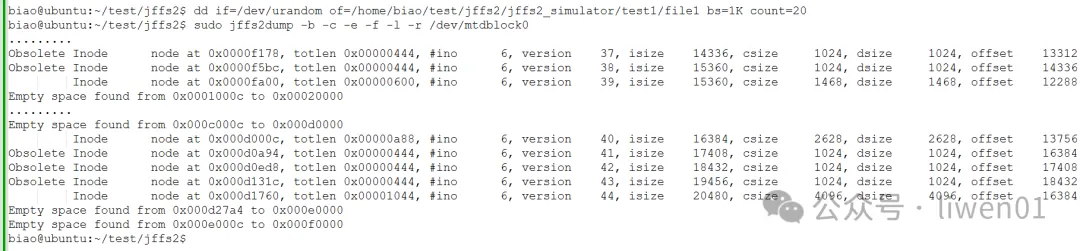 数据4.7.2 第二次执行
数据4.7.2 第二次执行
第5遍写入20K数据的时候,记录数据分布在0x000c000c-0x000dfc24的地址空间
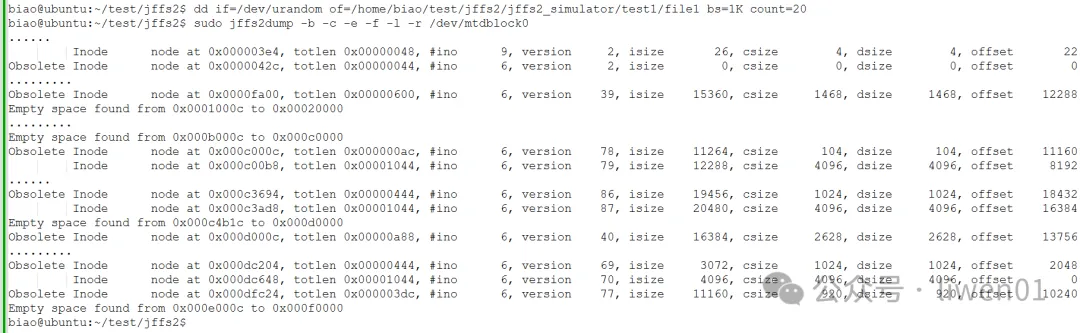 数据4.7.3 第五次执行
数据4.7.3 第五次执行
执行第6次写入20K随机数据之后,数据空间分布在0x000c000c-0x000ccc6c 的地址
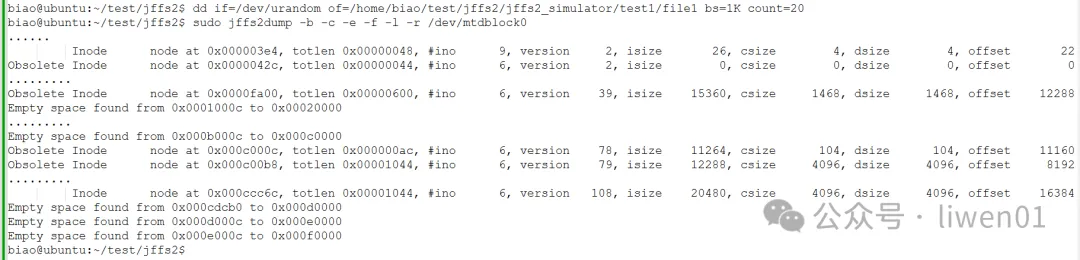 数据4.7.4 第六次执行
数据4.7.4 第六次执行
从第5次到第6次数据写入的时候,我们看到,第6次数据写入的时候,已经对第5次写入数据的空间进行了回收,所以在第6次写完数据之后,可以看到实际剩余的空闲块比第5次写完数据还多。
(8)数据结论
从上面的几个简单测试中我们可以看出下面几点:
- 存储的数据是可以被压缩的
- 数据记录不是线性存储
- 垃圾回收时静态数据(没有被修改的文件数据)不会被移动
- 垃圾回收有可能发生在空余空间还有很多的情况
实际官方的说法是:
- 100次中有99次是从脏列表中选择一个块进行垃圾回收,以获得最佳性能
- 剩下的1次是从干净块中选择一个块,以确保数据在介质上移动并实现磨损均衡
具体详细的实现逻辑,可以去jffs2的源码中查找。
(五)JFFS2数据恢复
如果在开发或是在设备使用过程中发现jffs2中的文件丢失了,或者是里面的数据丢失了,首先进行的第一步操作就是:停止往文件系统中写入任何数据
假设丢失的文件是上面测试file1文件
一般的操作流程为:
- 停止往jffs2系统中写入任何数据
- 将jffs2文件系统所在的分区全部备份一份
- 分析备份jffs2中的数据,看是否能找到file1的目录节点
- 查看file1文件inode的操作版本,按最大版本号开始分析
- 看最后版本的操作时间,分析设备在该时间段有做什么操作
- 分析倒数第二版本与最后版本,看最后版本是什么操作
通过上面方法,可以分析出数据丢失的大概原因,只有最后没办法的时候才去怀疑是否flash的扇区损坏了,因为分析flash是否损坏会破坏掉问题现场
如果数据丢失后想恢复回来,在数据还没有被覆盖的前提下,理论上是可以被恢复回来,恢复的难度就需要看丢失文件的具体数据和大小以及被修改的次数了。
(六)JFFS2使用注意事项
通过上面分析,我们大概的了解了jffs2文件系统的工作机制和原理,有几个使用注意事项需要留意:
- jffs2有磨损平衡,但磨损平衡比较随机。
- 因为数据是通过节点串起来的,所以它并不适合做大容量的文件系统,一般不建议超过32M的文件系统使用jff2
- 尽量避免频繁地更新jffs2文件系统里的数据,一是磨损平衡问题、二是每次修改都会产生新数据记录(version),不管修改的数据是多是少。少量数据的修改还会存在写放大的问题。
- 对于低功耗设备,关机前最好先正确卸载jffs2文件系统,提高文件系统一致性的保障
- 虽然jffs2是日志文件系统,数据丢失或是文件系统异常有可能被修复,但是对于嵌入式设备,一般没有足够的资源去做修复动作,所以对于关键数据的备份显得尤为重要。
结尾
这里介绍了嵌入式Linux系统中非常常用的jffs2文件系统,jffs2文件系统经过二十多年的验证是没有问题的,只是大家在使用的时候需要留意一下它的特性和局限性,避免造成关键数据的丢失。
---------------------------End---------------------------如需获取更多内容请关注 liwen01 公众号
文件系统(八):Linux JFFS2文件系统工作原理、优势与局限的更多相关文章
- STM32F3 GPIO的八种模式及工作原理
一.GPIO简介 GPIO(英语:General-purpose input/output),通用型之输入输出的简称,简单来说就是STM32可控制的引脚,STM32芯片的GPIO引脚与外部设备连接起来 ...
- 【翻译】TCP backlog在Linux中的工作原理
原文How TCP backlog works in Linux水平有限,难免有错,欢迎指出!以下为翻译: 当应用程序通过系统调用listen将一个套接字(socket)置为LISTEN状态时,需要为 ...
- linux命令管道工作原理与使用方法
一.管道定义 管道是一种两个进程间进行单向通信的机制.因为管道传递数据的单向性,管道又称为半双工管道.管道的这一特点决定了器使用的局限性.管道是Linux支持的最初Unix IPC形式之一,具有以下特 ...
- 已有 JFFs2文件系统的修改
项目应用中,对于前人留下的JFFS2的文件,有时候我们需要修改,但是苦于没有源文件,实际操作很多时候无所适从.每次支持生产之后再进行人为的升级.这样费时费力,也给生产人员增加了负担. 为了解决这个问题 ...
- 【转】完美解读Linux中文件系统的目录结构
一.前 言 接触Linux也有一段时间了,不过这几天在编译开源程序时,才发现自己对linux文件系统的目录结构了解的不够透彻,很多重要目录都说不清楚是用来干嘛的,于是在网上百度了一下这方面的介绍,根据 ...
- linux 文件系统的管理 (硬盘) 工作原理
一.系统在初始化时如何识别硬盘 1.系统初始时根据MBR的信息来识别硬盘,其中包括了一些执行文件就来载入系统,这些执行文件就是MBR里前面446bytes里的boot loader 程式,而后面的16 ...
- linux 文件系统工作原理
转:<http://linuxperf.com/?p=153> 一.概述 文件系统要解决的一个关键问题是怎样防止掉电或系统崩溃造成数据损坏,在此类意外事件中,导致文件系统损坏的根本原因在于 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
随机推荐
- SQL server 自定义工资公式设计
目的: 工资系统中,在计算各工资项目的时候,用户能自定义公式.这里的讲述是从数据库方设计方面考虑,做简要的数据模拟和实体.存储过程的设计. 收集数据: 1.Employee员工信息数据(Employe ...
- VGA显示文字
VGA显示文字 VGA字符显示的原理 把要显示的字符转换成字符点阵,然后编码存储,着色的部分为1,其它为0.然后在VGA上输出显示. 字符点阵生成软件: https://www.zhetao.com/ ...
- 2021年5.21NCU第四届校赛
比赛地址:http://222.204.50.106/contest/39 A 树上祖先 链接:http://222.204.50.106/contest/39/problem/A B 莎士比亚 链接 ...
- 一图明白ACHI,SATA之间的关系
从上图中可以看到,SATA与PCI-E不仅可以指代物理的接口,还可以指代物理接口使用的传输协议. M.2物理接口可以使用SATA.PCI-E传输协议. U.2可以使用PCI-E传输协议.在网上搜了一下 ...
- WEB服务与NGINX(20)- nginx 实现HTTP反向代理功能
目录 1. nginx实现反向代理功能 1.1 nginx代理功能概述 1.2 NGINX实现HTTP反向代理 1.2.1 HTTP反向代理基本功能 1.2.1.1 反向代理配置参数 1.2.1.2 ...
- WEB服务与NGINX(17)- https协议及使用nginx实现https功能
目录 1. https协议及使用nginx实现https功能 1.1 https协议概述 1.2 TLS/SSL协议原理 1.3 https的实现原理 1.4 使用openssl申请证书 1.5 ng ...
- JS实现跟随鼠标移动的div,和一串跟随鼠标的div,鼠标移入移出实现图片的颜色淡入淡出
1.一直跟着鼠标移动的div:原理是div的left和top值有oEvent.clientX+scrollLeft鼠标指针向对于浏览器页面(或客户区)的水平坐标+元素中滚动条的水平偏移 <!DO ...
- 删除字符串A中与字符串B相同的字符
/** * file name:DelDestChar.c * author : liaojx2016@126.com * date : 2024-05-06 * function : Delete ...
- iceoryx源码阅读(三)——共享内存通信(一)
目录 0 导引 1 整体通信结构 2 RelativePointer 2.1 原理 2.2 PointerRepository 2.3 构造函数 2.4 get函数 3 ShmSafeUnmanage ...
- Redis 的安装与配置详解【Redis系列一】
〇.前言 关于 Redis 在日常开发中还是用的比较多的,特别是在秒杀.消息队列.排行榜等数据交互时效要求较高的场景,Redis 都可以轻松应对. 本文将针对 Redis 进行简单介绍,以及如何安装, ...