构建RAG应用-day05: 如何评估 LLM 应用 评估并优化生成部分 评估并优化检索部分
评估 LLM 应用
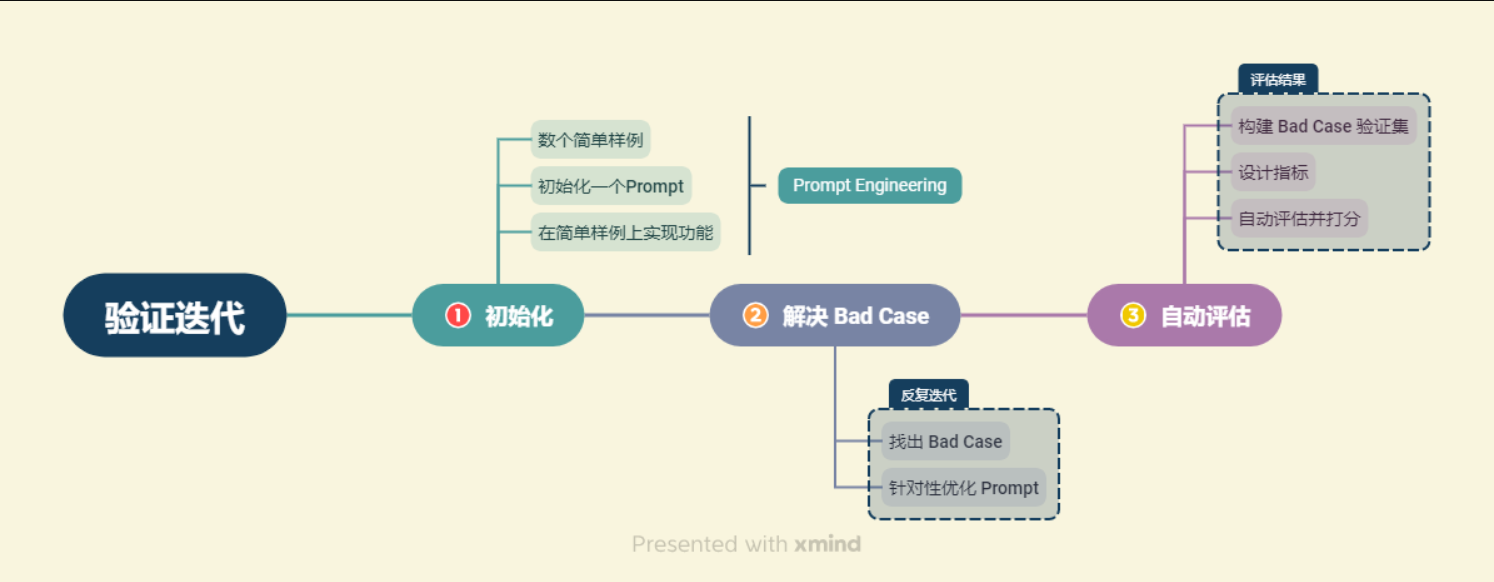
1.一般评估思路
首先,你会在一到三个样本的小样本中调整 Prompt ,尝试使其在这些样本上起效。
随后,当你对系统进行进一步测试时,可能会遇到一些棘手的例子,这些例子无法通过 Prompt 或者算法解决。
最终,你会将足够多的这些例子添加到你逐步扩大的开发集中,以至于手动运行每一个例子以测试 Prompt 变得有些不便。
然后,你开始开发一些用于衡量这些小样本集性能的指标,例如平均准确度。
也就是说总结一下大模型应用的开发过程,可以得出测试用例随着时间发展的变化:
基于一两个小测试用例构建应用 --> 解决棘手的测试用例(bad case) --> 足够多的测试用例集 --> 针对测试用例集合设置指标(自动评估)
2. 大模型评估方法
在具体的大模型应用开发中,我们可以找到 Bad Cases,并不断针对性优化 Prompt 或检索架构来解决 Bad Cases,从而优化系统的表现。
我们会将找到的每一个 Bad Case 都加入到我们的验证集中,每一次优化之后,我们会重新对验证集中所有验证案例进行验证,从而保证优化后的系统不会在原有 Good Case 上失去能力或表现降级。
核心:找到棘手的情况(大模型解决不了、效果不佳的情况),将其加入验证集。利用这个验证集,每次优化都进行验证,保证是在正确的方向。
import sys
sys.path.append("../C3 搭建知识库") # 将父目录放入系统路径中
# 使用智谱 Embedding API,注意,需要将上一章实现的封装代码下载到本地
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../../data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
# 使用 OpenAI GPT-3.5 模型
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0)
2.1 人工评估的一般思路
应用开发的初期,可以采用人工评估,也就是人来观察大模型的输出是否达到好的效果。
但是人工评估也需要有一些准则。
准则一 量化评估
方法1:打分。对llm的输出进行打分,比如1-5分,1-100分。
方法2:评估规范。 在不同评估员中达成共识,例如在幻觉的情况下,直接打0分。
方法3:平均值。对于单个prompt,使用多个测试用例进行测试,最后去评分的平均值。选择平均值高的prompt。
如下是使用两个测试用例(query),对两个prompt进行测试,然后人工观察输出结果进行打分,最终取平均值,然后决定选择哪个prompt。
import openai
from embed import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
import os
openai.base_url = 'https://api.chatanywhere.tech/v1'
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
# 使用 OpenAI GPT-3.5 模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, base_url=openai.base_url)
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
template_v1 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],
template=template_v1)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
print("问题一:")
question = "南瓜书和西瓜书有什么关系?"
result = qa_chain({"query": question})
print(result["result"])
print("问题二:")
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
print(result["result"])
template_v2 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],
template=template_v2)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
print("问题一:")
question = "南瓜书和西瓜书有什么关系?"
result = qa_chain({"query": question})
print(result["result"])
print("问题二:")
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
print(result["result"])
准则二 多维评估
什么是多维评估?有哪些维度?
知识、回答的正确性
① 知识查找正确性。该维度需要查看系统从向量数据库查找相关知识片段的中间结果,评估系统查找到的知识片段是否能够对问题做出回答。该维度为0-1评估,即打分为0指查找到的知识片段不能做出回答,打分为1指查找到的知识片段可以做出回答。
② 回答一致性。该维度评估系统的回答是否针对用户问题展开,是否有偏题、错误理解题意的情况,该维度量纲同样设计为0~1,0为完全偏题,1为完全切题,中间结果可以任取。
③ 回答幻觉比例。该维度需要综合系统回答与查找到的知识片段,评估系统的回答是否出现幻觉,幻觉比例有多高。该维度同样设计为0~1,0为全部是模型幻觉,1为没有任何幻觉。
④ 回答正确性。该维度评估系统回答是否正确,是否充分解答了用户问题,是系统最核心的评估指标之一。该维度可以在0~1之间任意打分。
拟人性、语法正确性
⑤ 逻辑性。该维度评估系统回答是否逻辑连贯,是否出现前后冲突、逻辑混乱的情况。该维度为0-1评估。
⑥ 通顺性。该维度评估系统回答是否通顺、合乎语法,可以在0~1之间任意打分。
⑦ 智能性。该维度评估系统回答是否拟人化、智能化,是否能充分让用户混淆人工回答与智能回答。该维度可以在0~1之间任意打分。
所以基本上就是按照评分标准,人工逐个去确认核实,最终得出分数。
# 问题:
应该如何使用南瓜书?
# 模型回答:
应该将南瓜书作为西瓜书的补充,主要在遇到自己无法推导或理解的公式时进行查阅。对于初学机器学习的小白来说,建议先简单过一下南瓜书的第1章和第2章,等学得更深入后再回来深究。每个公式的解析和推导都以本科数学基础的视角进行讲解,超纲的数学知识会在附录和参考文献中给出,感兴趣的同学可以继续深入学习。如果南瓜书中没有你想要查阅的公式,或者发现有错误,可以在GitHub的Issues中提交反馈,通常会在24小时内得到回复。最终目的是帮助读者更好地理解和应用机器学习知识,成为合格的理工科学生。
# 我们做出相应评估:
① 知识查找正确性—— 1
② 回答一致性—— 0.8(解答了问题,但是类似于“反馈”的话题偏题了)
③ 回答幻觉比例—— 1
④ 回答正确性—— 0.8(理由同上)
⑤ 逻辑性—— 0.7(后续内容与前面逻辑连贯性不强)
⑥ 通顺性—— 0.6(最后总结啰嗦且无效)
⑦ 智能性—— 0.5(具有 AI 回答的显著风格)
我们也可以针对不同维度的不同重要性赋予权值,再计算所有维度的加权平均来代表系统得分。
对系统每一个版本的每一个案例,我们都需要进行七次评估。如果我们有两个版本的系统,验证集中有10个验证案例,那么我们每一次评估就需要 140 次;但当我们的系统不断改进迭代,验证集会迅速扩大,一般来说,一个成熟的系统验证集应该至少在几百的体量,迭代改进版本至少有数十个,那么我们评估的总次数会达到上万次,带来的人力成本与时间成本就很高了。因此,我们需要一种自动评估模型回答的方法。
3.2 简单自动评估
核心思想:将复杂的没有标准答案的主观题进行转化,从而变成有标准答案的问题,进而通过简单的自动评估来实现。
方法一 构造客观题
主观题的评估是非常困难的,但是客观题可以直接对比系统答案与标准答案是否一致,从而实现简单评估。
简单来说,就是直接让llm输出ABCD,做选择题,根据llm的选择来进行打分。而不是让llm回复一大串文字。
例如,对于问题:
【问答题】南瓜书的作者是谁?
我们可以将该主观题构造为如下客观题(也是我们的测试用例,看看llm回答的如何):
【多项选择题】南瓜书的作者是谁? A 周志明 B 谢文睿 C 秦州 D 贾彬彬
然后构造一个函数,来根据llm的回答进行打分:
def multi_select_score_v2(true_answer : str, generate_answer : str) -> float:
# true_anser : 正确答案,str 类型,例如 'BCD'
# generate_answer : 模型生成答案,str 类型
true_answers = list(true_answer)
'''为便于计算,我们假设每道题都只有 A B C D 四个选项'''
# 先找出错误答案集合
false_answers = [item for item in ['A', 'B', 'C', 'D'] if item not in true_answers]
# 如果生成答案出现了错误答案
for one_answer in false_answers:
if one_answer in generate_answer:
return -1
# 再判断是否全选了正确答案
if_correct = 0
for one_answer in true_answers:
if one_answer in generate_answer:
if_correct += 1
continue
if if_correct == 0:
# 不选
return 0
elif if_correct == len(true_answers):
# 全选
return 1
else:
# 漏选
return 0.5
方法二:计算答案相似度
这个方法,需要你首先自己写一个问题和一个正确答案,然后使用一些ai算法来比较,llm的输出和你准备好的答案的文本相似度。(类似embedding计算余弦距离?)
例如,对问题:
南瓜书的目标是什么?
我们可以首先人工构造一个标准回答:
周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充具体的推导细节。
计算相似度的方法有很多,我们一般可以使用 BLEU 来计算相似度,其原理详见:知乎|BLEU详解,对于不想深究算法原理的同学,可以简单理解为主题相似度。
我们可以调用 nltk 库中的 bleu 打分函数来计算:
from nltk.translate.bleu_score import sentence_bleu
import jieba
def bleu_score(true_answer : str, generate_answer : str) -> float:
# true_anser : 标准答案,str 类型
# generate_answer : 模型生成答案,str 类型
true_answers = list(jieba.cut(true_answer))
# print(true_answers)
generate_answers = list(jieba.cut(generate_answer))
# print(generate_answers)
bleu_score = sentence_bleu(true_answers, generate_answers)
return bleu_score
问题:
- 需要人工构造标准答案。对于一些垂直领域而言,构造标准答案可能是一件困难的事情;
- 通过相似度来评估,可能存在问题。例如,如果生成回答与标准答案高度一致但在核心的几个地方恰恰相反导致答案完全错误,bleu 得分仍然会很高;
- 通过计算与标准答案一致性灵活性很差,如果模型生成了比标准答案更好的回答,但评估得分反而会降低;
- 无法评估回答的智能性、流畅性。如果回答是各个标准答案中的关键词拼接出来的,我们认为这样的回答是不可用无法理解的,但 bleu 得分会较高。
2.3 使用大模型进行评估
就是让llm扮演评估员打分,就这么简单:
prompt = '''
你是一个模型回答评估员。
接下来,我将给你一个问题、对应的知识片段以及模型根据知识片段对问题的回答。
请你依次评估以下维度模型回答的表现,分别给出打分:
① 知识查找正确性。评估系统给定的知识片段是否能够对问题做出回答。如果知识片段不能做出回答,打分为0;如果知识片段可以做出回答,打分为1。
② 回答一致性。评估系统的回答是否针对用户问题展开,是否有偏题、错误理解题意的情况,打分分值在0~1之间,0为完全偏题,1为完全切题。
③ 回答幻觉比例。该维度需要综合系统回答与查找到的知识片段,评估系统的回答是否出现幻觉,打分分值在0~1之间,0为全部是模型幻觉,1为没有任何幻觉。
④ 回答正确性。该维度评估系统回答是否正确,是否充分解答了用户问题,打分分值在0~1之间,0为完全不正确,1为完全正确。
⑤ 逻辑性。该维度评估系统回答是否逻辑连贯,是否出现前后冲突、逻辑混乱的情况。打分分值在0~1之间,0为逻辑完全混乱,1为完全没有逻辑问题。
⑥ 通顺性。该维度评估系统回答是否通顺、合乎语法。打分分值在0~1之间,0为语句完全不通顺,1为语句完全通顺没有任何语法问题。
⑦ 智能性。该维度评估系统回答是否拟人化、智能化,是否能充分让用户混淆人工回答与智能回答。打分分值在0~1之间,0为非常明显的模型回答,1为与人工回答高度一致。
你应该是比较严苛的评估员,很少给出满分的高评估。
用户问题:
```
{}
```
待评估的回答:
```
{}
```
给定的知识片段:
```
{}
```
你应该返回给我一个可直接解析的 Python 字典,字典的键是如上维度,值是每一个维度对应的评估打分。
不要输出任何其他内容。
'''
代码:
from openai import OpenAI
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ.get("OPENAI_API_KEY"),
)
def gen_gpt_messages(prompt):
'''
构造 GPT 模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
def get_completion(prompt, model="gpt-3.5-turbo", temperature = 0):
'''
获取 GPT 模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 gpt-3.5-turbo,也可以按需选择 gpt-4 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~2。温度系数越低,输出内容越一致。
'''
response = client.chat.completions.create(
model=model,
messages=gen_gpt_messages(prompt),
temperature=temperature,
)
if len(response.choices) > 0:
return response.choices[0].message.content
return "generate answer error"
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
answer = result["result"]
knowledge = result["source_documents"]
response = get_completion(prompt.format(question, answer, knowledge))
response
2.4 混合评估
将上述方法综合起来使用
例如,针对本项目个人知识库助手,我们可以设计以下混合评估方法:
- 客观正确性。客观正确性指对于一些有固定正确答案的问题,模型可以给出正确的回答。我们可以选取部分案例,使用构造客观题的方式来进行模型评估,评估其客观正确性。
- 主观正确性。主观正确性指对于没有固定正确答案的主观问题,模型可以给出正确的、全面的回答。我们可以选取部分案例,使用大模型评估的方式来评估模型回答是否正确。
- 智能性。智能性指模型的回答是否足够拟人化。由于智能性与问题本身弱相关,与模型、Prompt 强相关,且模型判断智能性能力较弱,我们可以少量抽样进行人工评估其智能性。
- 知识查找正确性。知识查找正确性指对于特定问题,从知识库检索到的知识片段是否正确、是否足够回答问题。知识查找正确性推荐使用大模型进行评估,即要求模型判别给定的知识片段是否足够回答问题。同时,该维度评估结果结合主观正确性可以计算幻觉情况,即如果主观回答正确但知识查找不正确,则说明产生了模型幻觉。
使用上述评估方法,基于已得到的验证集示例,可以对项目做出合理评估。限于时间与人力,此处就不具体展示了。
3.评估并优化生成部分
1. 提升直观回答质量
这部分是教学如何调prompt。
首先给出一个例子:
问题:什么是南瓜书
初始回答:南瓜书是对《机器学习》(西瓜书)中难以理解的公式进行解析和补充推导细节的一本书。谢谢你的提问!
存在不足:回答太简略,需要回答更具体;谢谢你的提问感觉比较死板,可以去掉
我们需要找到回复中存在的问题,这也就是优化的方向,然后依据问题修改prompt。
核心:围绕具体业务展开思考,找出初始回答中不足以让人满意的点,并针对性进行提升改进
2. 标明知识来源,提高可信度
示例:
强化学习是一种机器学习方法,旨在让智能体通过与环境的交互学习如何做出一系列好的决策。在这个过程中,智能体会根据环境的反馈(奖励)来调整自己的行为,以最大化长期奖励的总和。强化学习的目标是在不确定的情况下做出最优的决策,类似于让一个小孩通过不断尝试来学会走路的过程。强化学习的交互过程由智能体和环境两部分组成,智能体根据环境的状态选择动作,环境根据智能体的动作输出下一个状态和奖励。强化学习的应用非常广泛,包括游戏玩法、机器人控制、交通管理等领域。【来源:蘑菇书一语二语二强化学习教程】。
但是,附上原文来源往往会导致上下文的增加以及回复速度的降低,我们需要根据业务场景酌情考虑是否要求附上原文。可以在数据库层面就对于原文进行标注,只要检索匹配到,就能获取原文的位置,不过这也有很多工作要做。
3. 构造思维链
问题:我们应该如何去构造一个 LLM 项目
初始回答:略
存在不足:事实上,知识库中中关于如何构造LLM项目的内容是使用 LLM API 去搭建一个应用,模型的回答看似有道理,实则是大模型的幻觉,将部分相关的文本拼接得到,存在问题
构建思维链的示例:也就是告诉llm怎么做,怎么思考。如下是个两部的思维,1根据上下文回答问题,2进行反思
template_v4 = """
请你依次执行以下步骤:
① 使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。
你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
如果答案有几点,你应该分点标号回答,让答案清晰具体。
上下文:
{context}
问题:
{question}
有用的回答:
② 基于提供的上下文,反思回答中有没有不正确或不是基于上下文得到的内容,如果有,回答你不知道
确保你执行了每一个步骤,不要跳过任意一个步骤。
"""
4. 增加一个指令解析
即我们需要模型以我们指定的格式进行输出。但是,由于我们使用了 Prompt Template 来填充用户问题,用户问题中存在的格式要求往往会被忽略,例如:
question = "LLM的分类是什么?给我返回一个 Python List"
模型没有返回list,而是在答案中包含list:
根据上下文提供的信息,LLM(Large Language Model)的分类可以分为两种类型,即基础LLM和指令微调LLM。基础LLM是基于文本训练数据,训练出预测下一个单词能力的模型,通常通过在大量数据上训练来确定最可能的词。指令微调LLM则是对基础LLM进行微调,以更好地适应特定任务或场景,类似于向另一个人提供指令来完成任务。
根据上下文,可以返回一个Python List,其中包含LLM的两种分类:["基础LLM", "指令微调LLM"]。
解决这个问题的方案是:再加上一次llm调用
用户问题 --> 指令解析llm --> 知识库llm --> 输出格式解析llm
指令解析前:
question = "LLM的分类是什么?给我返回一个 Python List"
指令解析后(也就是调用一个指令解析llm,让其生成一个list):
'```\n["给我返回一个 Python List", "LLM的分类是什么?"]\n```'
然后根据拆分得到的问题部分,进行检索。最后根据拆分得到的输出格式要求,按照输出格式再次调用llm进行输出。
评估并优化检索部分(了解)
检索部分的检索精确率和召回率其实更大程度影响了应用的整体性能。
回顾整个 RAG:
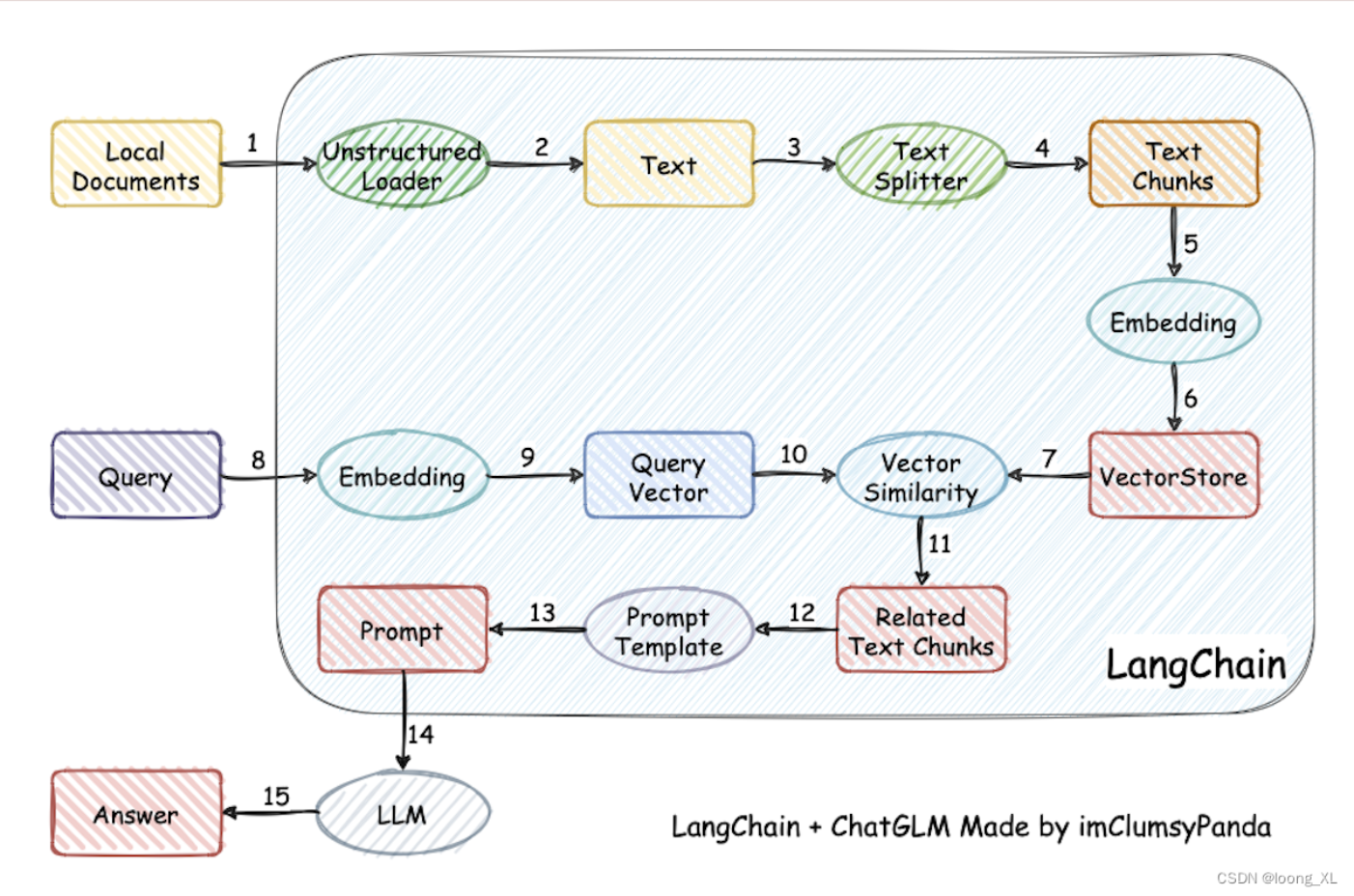
如何评估检索效果?
检索部分的核心功能是找到存在于知识库中、能够正确回答用户 query 中的提问的文本段落。
两个标准:
- query的答案确实存在于知识库。
如果正确答案本就不存在,那我们应该将 Bad Case 归因到知识库构建部分,说明知识库构建的广度和处理精度还有待提升。 - 该答案能被成功检索到。
什么叫成功检索?假设对于每一个 query,系统找到了 K 个文本片段,如果正确答案在 K 个文本片段之一,那么我们认为检索成功;
问题:
- 有的 query 可能需要联合多个知识片段才能做出回答,对于这种 query,我们如何评估?
- 检索到的知识片段彼此之间的顺序其实会对大模型的生成带来影响,我们是否应该将检索片段的排序纳入考虑?
- 除去检索到正确的知识片段之外,我们的系统还应尽量避免检索到错误的、误导性知识片段,否则大模型的生成结果很可能被错误片段误导。我们是否应当将检索到的错误片段纳入指标计算?
构建RAG应用-day05: 如何评估 LLM 应用 评估并优化生成部分 评估并优化检索部分的更多相关文章
- [转]MySQL源码:Range和Ref优化的成本评估
MySQL源码:Range和Ref优化的成本评估 原文链接:http://www.orczhou.com/index.php/2012/12/mysql-source-code-optimizer-r ...
- 伪Textatea的构建(div+table),以及相应的滚动条问题与safari上的优化
在页面中创建一个不可编辑的文本块,并且文本块的篇幅较大,第一反应是创建一个textarea,并将它的disabled="disabled",并设置相应的scroll属性,就可以构建 ...
- 模型构建<1>:模型评估-分类问题
对模型的评估是指对模型泛化能力的评估,主要通过具体的性能度量指标来完成.在对比不同模型的能力时,使用不同的性能度量指标可能会导致不同的评判结果,因此也就意味着,模型的好坏只是相对的,什么样的模型是较好 ...
- 入门系列之Scikit-learn在Python中构建机器学习分类器
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由信姜缘 发表于云+社区专栏 介绍 机器学习是计算机科学.人工智能和统计学的研究领域.机器学习的重点是训练算法以学习模式并根据数据进行预 ...
- scikit-learn 中常用的评估模型
一,scikit-learn中常用的评估模型 1.评估分类模型: 2.评估回归模型: 二.常见模型评估解析: •对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为:(T,F表示预测的 ...
- 使用 Estimator 构建卷积神经网络
来源于:https://tensorflow.google.cn/tutorials/estimators/cnn 强烈建议前往学习 tf.layers 模块提供一个可用于轻松构建神经网络的高级 AP ...
- 【AI】【计算机】【中国人工智能学会通讯】【学会通讯2019年第01期】中国人工智能学会重磅发布 《2018 人工智能产业创新评估白皮书》
封面: 中国人工智能学会重磅发布 <2018 人工智能产业创新评估白皮书> < 2018 人工智能产业创新评估白皮书>由中国人工智能学会.国家工信安全中心.华夏幸福产业研究院. ...
- COMET —— 常识Transformer用于自动知识图构建
<COMET:Commonsense Transformers for Automatic Knowledge Graph Construction> 论文地址 论文源码 任务 目的层面 ...
- 英特尔® 至强® 平台集成 AI 加速构建数据中心智慧网络
英特尔 至强 平台集成 AI 加速构建数据中心智慧网络 SNA 通过 AI 方法来实时感知网络状态,基于网络数据分析来实现自动化部署和风险预测,从而让企业网络能更智能.更高效地为最终用户业务提供支撑. ...
- 如何评估 Serverless 服务能力?这份报告给出了 40 条标准
编者按:两年前,我们还在讨论什么是 Serverless,Serverless 如何落地.如今,已经有评测机构给出了 40 条标准来对 Serverless 的服务能力进行评估,这些评估细则既是技术生 ...
随机推荐
- OpenCvSharp+Yolov5Net+Onnx 完整Demo
效果 工程 代码 using Microsoft.ML.OnnxRuntime; using OpenCvSharp; using System; using System.Collections.G ...
- exist和left join 性能对比
今天遇到一个性能问题,再调优过程中发现耗时最久的计划是exist 部分涉及的三个表. 然后计划用left join 来替换exist,然后查询了很多资料,大部分都说exist和left join 性能 ...
- KingbaseES V8R6 集群运维案例 -- 禁止普通用户su到root
案例说明: 在集群管理中,会使用到root权限(如ip.aring命令等),为安全需要,有的生产环境禁止普通用户su切换到root,本案例测试了禁止普通用户su切换到root对集群管理带来的影响. 集 ...
- 一个可以让你有更多时间摸鱼的WPF控件(二)
前言 上文介绍了如何通过一个Form自定义控件来简化数据的录入,并自动实现数据校验,自动布局排列等功能.本文继续介绍如何优化表格控件的使用,缩减代码量,实现工作效率的提升. 一.功能实现 上文中分析了 ...
- Linux服务器定时器
网络程序需要处理的第三类事件是定时事件,比如定期检测一个客户连接的活动状态.服务器程序通常管理着众多定时事件,因此有效地组织这些定时事件,使之能在预期的时间点被触发且不影响服务器的主要逻辑,对于服务器 ...
- #插头dp#洛谷 5074 HDU 1693 Eat the Trees
题目 给出 \(n*m\) 的方格,有些格子不能铺线, 其它格子必须铺,可以形成多个闭合回路. 问有多少种铺法? \(n,m\leq 12\) 分析 设 \(dp[n][m][S][0/1]\) 表示 ...
- 新零售SaaS架构:客户管理系统架构设计(万字图文总结)
什么是客户管理系统? 客户管理系统,也称为CRM(Customer Relationship Management),主要目标是建立.发展和维护好客户关系. CRM系统围绕客户全生命周期的管理,吸引和 ...
- 拥抱开源更省钱「GitHub 热点速览」
免费.低成本.自托管.开源替代品...这些词就是本周的热门开源项目的关键字.常见的 AI 提升图片分辨率的工具,大多是在线服务或者调用接口的客户端,而「Upscaler」是一款下载即用的免费 AI 图 ...
- jemter做参数化的几种方法
第一种:使用用户参数:添加--前置处理器--用户参数
- springBoot集成RPC
需求 : 项目开发到尾期,仓库系统需要对接我们这边的制造系统, 为的是制造系统所使用物料时,需向仓库系统发送请求物料信息,所以需要调用 仓库接口. 使用技术: RPC 数据传输格式: json 开发环 ...