一篇文章带你掌握Web自动化测试工具——Selenium
一篇文章带你掌握Web自动化测试工具——Selenium
在这篇文章中我们将会介绍Web自动化测试工具Selenium
如果我们需要学习相关内容,我们需要掌握Python,PyTest以及部分前端知识即可
下面我们将会从以下角度进行介绍:
- Web自动化入门
- Selenium-API介绍
Web自动化入门
首先我们先来介绍Web自动化的一些相关知识
自动化测试介绍
首先我们需要了解什么是自动化:
- 由机器设备代替人工自动完成指定目标的过程被称为自动化
那么自动化测试的概念也很清晰:
- 让程序代替人工去验证系统功能的过程
自动化测试在我们的项目测试中主要为了完成以下功能:
解决-回归测试
解决-压力测试
解决-兼容性测试
提高测试效率,保证产品质量
下面我们分别给出自动化测试的分类以及优缺点:
# 自动化分类
1. 接口-自动化测试:Requests类的学习,我们在之前的文章已经学习
2. 单元-自动化测试:Pytest工具的学习,我们之前的文章中已经学习
3. Web-自动化测试:Selenium工具的学习,也就是我们目前所需要学习的技术
4. 移动-自动化测试:Appium工具的学习,我们将在下篇文章中介绍
# 自动化优点
1. 较少的时间内运行更多的测试用例;
2. 自动化脚本可重复运行;
3. 减少人为的错误;
4. 克服手工测试的局限性;
# 自动化缺点
1. 自动化测试无法完全替代手工测试,手工测试可以专门去测试各种特殊情况
2. 自动化测试无法适用于所有功能,当系统出现各种情况时,自动化测试会受到严重影响
最后我们来介绍Web自动化测试的相关内容:
# 我们的测试类型通常划分为以下三种
# Web自动化属于黑盒测试+功能测试模块
1. 黑盒测试(功能测试)
2. 白盒测试(单元测试)
3. 灰盒测试(接口测试)
# Web自动化测试时机
1. Web自动化测试代码的书写一般在手动测试之后,我们后续为了回归当前版本问题而去书写的自动化测试
2. Web自动化测试代码可以帮助我们在后续版本进行大规模的简易测试,来判断当前版本更新是否影响到之前的功能模块
自动化工具介绍
我们首先介绍一下目前比较流行的自动化测试工具:
# QTP
QTP是一个商业化的功能测试工具,收费,支持web,桌面自动化测试
# Selenium
Selenium是一个开源的web自动化测试工具,免费,主要做功能测试
# Robot framework
Robot Framework是一个基于Python可扩展地关键字驱动的测试自动化框架
那么我们就要介绍一下为什么我们需要学习Selenium:
# Selenium是一个用于Web应用程序的自动化测试工具
# 开源软件
Selenium的源代码开放可以根据需要来增加工具的某些功能
# 跨平台
Selenium支持多个平台的使用,其中包括linux、windows、mac等主流平台
# 支持多种浏览器:Firefox、Chrome、IE、Edge、Opera、Safari等
Selenium支持多个浏览器的使用,其中包括Firefox、Chrome、IE、Edge、Opera、Safari等主流浏览器
# 支持多种语言
Selenium支持多个语言的使用,其中包括Python、Java、CPP、JavaScript、Ruby、PHP等
# 成熟稳定
目前已经被google、百度、腾讯等公司广泛使用
# 功能强大
能够实现类似商业工具的大部分功能,因为开源性,可实现定制化功能
自动化初始准备
我们如果需要学习Selenium,那么我们就需要进行一些初始准备:
- Python 开发环境
- 安装selenium包
- 安装浏览器
- 安装浏览器驱动
我们在这里主要介绍Selenium包的安装以及安装浏览器驱动的知识,其它部分我们在之前文章已经介绍
安装selenium包
我们的开发一般在Pycharm上,我们只需要采用pip工具即可安装:
# 在Terminal控制台采用Pip工具进行下载
pip install selenium
# 当然我们也可以卸载
pip uninstall selenium
# 我们在下载后可以采用show进行查看是否下载成功以及信息版本
pip show selenium
安装浏览器驱动
首先我们介绍一下为什么需要安装浏览器驱动:
- Selenium是一套web自动化的软件底层库,框架只暴露接口
- 它基于浏览器的原生的API接口,通过浏览器驱动来对web进行页面元素的查找以及操作
然后我们首先需要查看我们的浏览器是属于什么版本,一般我们可以从设置中查看版本信息:
然后我们可以到对应的驱动下载网站进行下载
我们这里给出Chrome的网站:chromedriver.storage.googleapis.com/index.html
我们简单给出一个界面,点击对应的版本,然后下载解压即可:
但是我们需要注意,我们需要将对应的解压出来的chromedriver.exe保存到环境变量
最后我们给出一个简单快速下载驱动的代码方法:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 自动安装需要用到第三方库webdriver_manager,先安装这个库,然后调用对应的方法即可
from webdriver_manager.chrome import ChromeDriverManager
# ChromeDriverManager().install()方法就是自动安装驱动的操作,它会自动获取当前浏览器的版本并去下载对应的驱动到本地
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
Selenium-API介绍
下面我们正式开始介绍Selenium的API
入门代码示例
我们在正式开始语法介绍之前,给出一段简单的代码来进行介绍:
# 下面是我们Selenium所使用的最简单的代码
# 导包
# 我们的Selenium属于第三方包,所以我们需要导包使用
# 这里导入的是Selenium的webdriver,主要就是为了获取浏览器驱动,后续我们主要使用这个驱动进行操作
from selenium import webdriver
import time
# 创建浏览器驱动对象
# 这里我们只需要打出webdriver. 后续Pycharm会为我们自动展示所有Selenium所支持的浏览器类型,我们只需要选择即可
driver1 = webdriver.Firefox()
driver2 = webdriver.Chrome()
driver3 = webdriver.Edge()
# 加载web页面
# 这里使用的是Firefox界面,get方法的第一个参数是url,意味着根据url打开网页
driver1.get("http://www.baidu.com/")
# 暂停3秒
time.sleep(3)
# 关闭驱动对象
driver.quit()
元素定位方法
我们的Selenium进行网页操作主要是针对元素进行操作
而元素这个概念在我们的前端学习时已经学习过,我们前端所展示的都是元素
我们将会介绍八大元素定位方法来实现我们Selenium的元素定位并进行对应的操作
元素检索
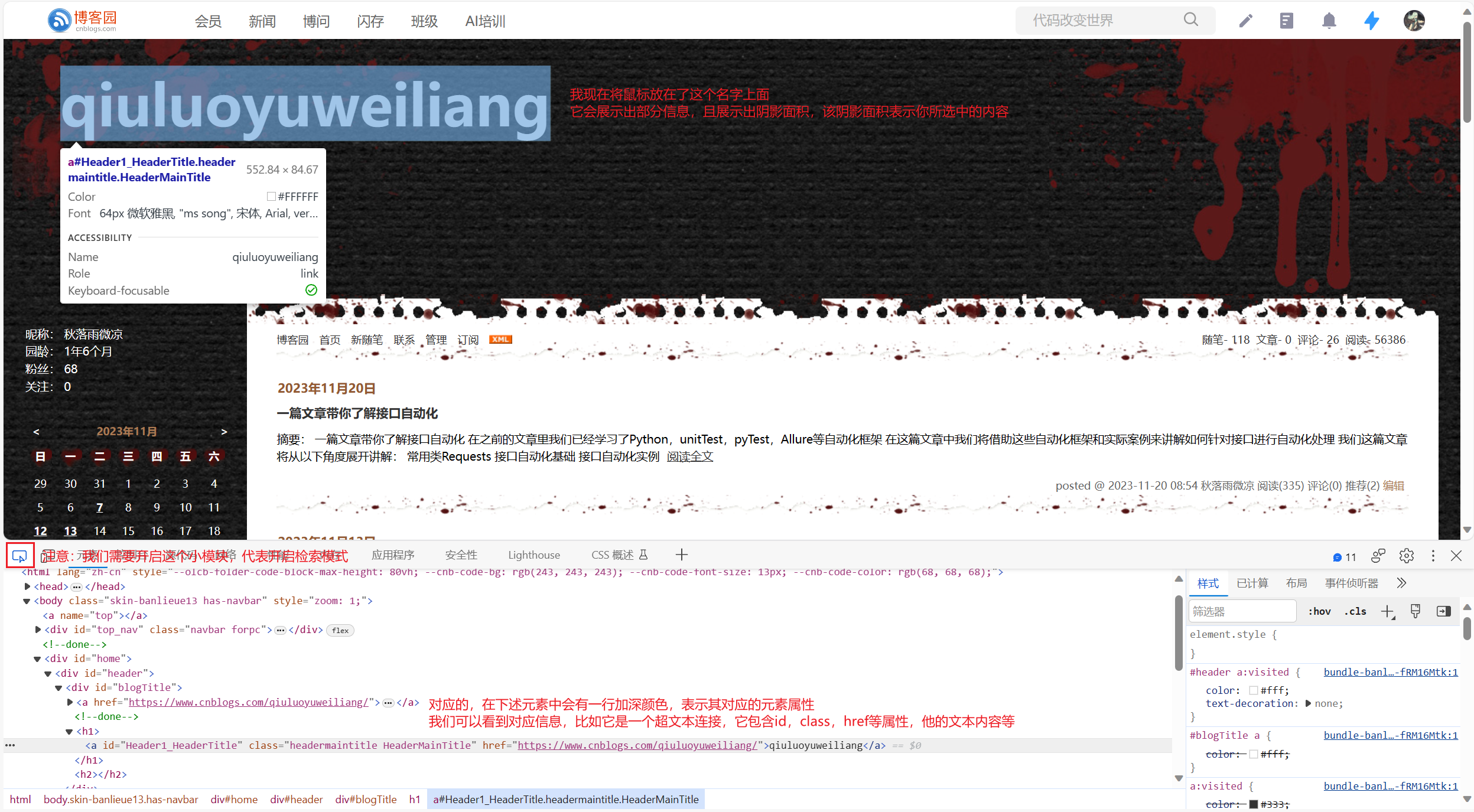
如果我们希望使用网页中的元素,并获取其对应信息,那么我们还是需要一些简单技巧的
例如我们在网页中可以使用F12开发者模式直接查看某个元素的对应信息
我们只需要打开元素检索模式,并且点击我们所需要检索的元素,网页就会帮助我们自动定位获取对应的元素信息
我们给出一个简单的网页展示:
id定位
我们首先需要了解id定位方法:
- id定位就是通过元素的id属性来定位元素
- HTML规定id属性在整个HTML文档中必须是唯一的
我们给出一个简单示例:
# 我们需要注意:并不是所有元素都有id,在实际使用中,大多数元素都不会有id,所以这个方法的泛用性较差
# 方法解析
# 在Selenium的目前更新中,所有的元素定位方法都被集中到了driver.find_element方法中
# 后面的第一个参数是使用By类的内置属性,包括我们所使用的八大定位方法,而第二个参数就是我们对应的名称值
element = driver.find_element(By.ID,id)
""""
需求:打开注册A.html页面,完成以下操作
1).使用id定位,输入用户名:admin
2).使用id定位,输入密码:123456
3).3秒后关闭浏览器窗口
""""
# 导包
from selenium import webdriver
from time import sleep
# 我们还需要导入By包,当我们使用By类的时候,我们需要提前导包
from selenium.webdriver.common.by import By
# 获取 浏览器对象
driver = webdriver.Firefox()
# 这里我们介绍url的四种书写方法,这里我们比较推荐第一种本地打开方法,相对比较简单
# 打开url
# 注意:\反斜杠在python是转义字符 r:修饰的字符串,如果字符串中有转义字符,不进行转义使用
url = r"E:\StudyResource\注册A.html"
# 使用双反斜杠 进行转义操作
# url = "E:\\StudyResource\\注册A.html"
# 使用本地浏览模式 前缀必须添加 file:///
# url = "file:///E:/StudyResource/注册A.html"
# 复制浏览器地址
# url = "file:///E:/%E8%AF%BE%E5%A0%82/%E5%8C%97%E4%BA%AC/%E5%8C%97%E4%BA%AC%E5%8D%81%E6%9C%9F/Day01/02_%E5%85%B6%E4%BB%96%E8%B5%84%E6%96%99/%E6%B5%8F%E8%A7%88%E5%99%A8/%E8%AF%BE%E5%A0%82%E7%B4%A0%E6%9D%90/%E6%B3%A8%E5%86%8CA.html"
# 打开浏览器
driver.get(url)
# 查找 用户名元素
username = driver.find_element(By.ID,"userA")
# 查找 密码元素
password = driver.find_element(By.ID,"passwordA")
# 用户名输入 admin send_keys("内容")
username.send_keys("admin")
# 密码 输入 123456
password.send_keys("123456")
# 暂停3秒
sleep(3)
# 退出浏览器驱动
driver.quit()
name定位
下面我们来介绍name定位方法:
- name定位就是根据元素name属性来定位
- HTML文档中name的属性值是可以重复的,当存在多个时默认获取第一个元素
我们给出一个简单示例:
# Name是前端书写时常用的元素信息,但Name通常含有多个,如果我们使用find_element我们只能默认获取第一个元素
# 方法解析
element = driver.find_element(By.NAME,name)
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器对象
driver = webdriver.Firefox()
# 打开url
url = r"E:\StudyResource\注册A.html"
driver.get(url)
# 查找用户名 输入admin
driver.find_element(By.NAME,"userA").send_keys("admin")
# 查找密码 输入123456
driver.find_element(By.NAME,"passwordA").send_keys("123456")
# 暂停3秒
sleep(3)
# 关闭浏览器
driver.quit()
class_name定位
下面我们来介绍class_name定位方法:
- class_name定位就是根据元素class属性值来定位元素
- 注意一个元素可能含有多个class,如果class有多个属性值,只能使用其中的一个
我们给出一个简单示例:
# 方法解析
element = driver.find_element(By.CLASS_NAME,class_name)
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器对象
driver = webdriver.Firefox()
# 打开url
url = r"E:\StudyResource\注册A.html"
driver.get(url)
# 查找电话 输入 18611111111
driver.find_element_by(By.CLASS_NAME,"telA").send_keys("18611111111")
# 暂停3秒
sleep(3)
# 关闭浏览器
driver.quit()
tag_name定位
下面我们来介绍tag_name定位方法:
- tag_name定位就是通过标签名来定位
- HTML本质就是由不同的tag组成,每一种标签一般在页面中会存在多个,所以不方便进行精确定位
我们给出一个简单示例:
# 方法解析
element = driver.find_element(By.TAG_NAME,tag_name)
"""""
需求:
1. 使用tag_name定位方式,使用注册A.html页面,用户名输入admin
方法:
1. driver.find_element("") # 定位元素方法
2. send_keys() # 输入方法
3. driver.quit() # 退出方法
"""
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取 浏览器驱动对象
driver = webdriver.Firefox()
# 打开 注册A.html
url = r"D:\StudyResource\注册A.html"
driver.get(url)
# 使用tag_name定位用户名 并 输入admin
# 注意:页面中如果存在多个相同的标签名,默认返回第一个标签
driver.find_element(By.TAG_NAME,"input").send_keys("admin")
# 暂停 3秒
sleep(3)
# 退出浏览器驱动
driver.quit()
link_text定位
下面我们来介绍link_text定位方法:
- link_text定位是专门用来定位超链接元素
- link_text主要通过超链接的文本内容来定位元素,需要注意是完整文本信息,包括空格等
我们给出一个简单示例:
# 方法解析
element = driver.find_element(By.LINK_TEXT,link_text)
"""
需求:
1. 使用link_text定位方式,使用注册A.html页面,点击 访问 新浪 网站 连接地址
方法:
1. driver.find_element("") # 定位元素方法
2. click() # 点击方法
注意:
link_text:
1. 只能定位a标签
2. link_text定位元素的内容必须为全部匹配
"""
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取 浏览器驱动对象
driver = webdriver.Firefox()
# 打开 注册A.html
url = r"D:\StudyResource\注册A.html"
driver.get(url)
# 使用 link_text定位 访问 新浪 网站 <全部匹配>
driver.find_element(By.LINK_TEXT,"访问 新浪 网站").click()
# 错误写法,没有全部匹配文本
# driver.find_element_by_link_text("访问").click()
# 暂停 3秒
sleep(3)
# 退出浏览器驱动
driver.quit()
partial_link_text定位
下面我们来介绍partial_link_text定位方法:
- partial_link_text定位是对link_text定位的补充
- partial_link_text可以使用完全文本进行定位,也可以使用部分文本信息匹配进行定位
我们给出一个简单示例:
# 方法解析
element = driver.find_element(By.PARTIAL_LINK_TEXT,link_text)
"""
需求:
1. 使用partial_link_text定位方式,使用注册A.html页面,点击 访问 新浪 网站 连接地址
方法:
1. driver.find_element_by_partial_link_text("") # 定位元素方法
2. click() # 点击方法
注意:
partial_link_text:
1. 只能定位a标签
2. partial_link_text定位元素的内容可以模糊部分值,但是必须能代表唯一性
"""
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取 浏览器驱动对象
driver = webdriver.Firefox()
# 打开 注册A.html
url = r"D:\StudyResource\注册A.html"
driver.get(url)
# 使用partial_link_text定位 使用模糊 唯一代表关键词
# driver.find_element(By.PARTIAL_LINK_TEXT,"访问").click()
# 没有使用唯一代表词 默认操作符合条件的第一个元素
# driver.find_element(By.PARTIAL_LINK_TEXT,"新浪").click()
# 使用全部匹配
driver.find_element(By.PARTIAL_LINK_TEXT,"访问 新浪 网站").click()
# 暂停 3秒
sleep(3)
# 退出浏览器驱动
driver.quit()
XPath定位
首先我们需要了解XPath定位为什么被研发出来:
- 如果要定位的元素没有id、name、class属性,我们就只能使用Xpath或CSS定位方法
- 如果通过name、class、tag_name无法定位到唯一的元素,我们就只能使用Xpath或CSS定位方法
我们来简单介绍一下XPath定位方法:
- XPath即为XML Path的简称,它是一门在 XML 文档中查找元素信息的语言
- HTML可以看做是XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中定位元素
我们来简述一下XPath定位元素的几种通用格式:
# 首先我们还是给出XPath的使用格式
element = driver.find_element(By.XPATH,xpath)
# XPath一般分为四种定位方法,我们会在下面一一展示
# 1. 路径-定位
# 路径定位一般划分为绝对路径定位和相对路径定位
# 绝对路径定位:以 /html根节点 开始,使用/来分隔元素层级
# 例如/html/body/div/fieldset/p[1]/input,表示html层级下的body层级下的....的第一个p下的input元素
# 需要注意我们的html元素是以1开头,并不是以0开头,这里的1就是指一组p标签的第一个元素
driver.find_element(By.XPATH,"/html/body/form/div/fieldset/p[1]/input").send_keys("admin")
# 相对路径定位:以 //确定元素 开始,后续使用/来分隔元素层级
# 例如//p[@id='p1']/input,表示id为p1的p标签元素下的input元素
# 我们通常使用//来表示第一个可以确认的相对路径的元素,而这个元素通常采用标签名开头,我们可以使用[]来加上其对应的属性来确定元素
# 我们通常在[]里添加单个属性或多个属性来确定元素,我们通常使用@属性名=属性值的格式来表示,例如@id='p1'
driver.find_element(By.XPATH,"//p[@id='p1']/input").send_keys("123")
# 2. 利用元素属性-定位
# 一个元素通常会有多个属性,包括id,name以及自定义属性等
# 例如//input[@id='passwordA'],表示该id为passwordA的input元素
driver.find_element(By.XPATH,"//input[@id='passwordA']").send_keys("123")
# 3. 属性与逻辑结合-定位
# 如果我们出现元素内含有多个属性,且每个属性都有多个元素共享,我们就不能使用单个属性进行元素定位
# 所以我们需要使用逻辑方法来进行多属性判定,例如and,or等方法
driver.find_element(By.XPATH,"//input[@id='passwordA' and @placeholder='密码A']").send_keys("123")
# 4. 层级与属性结合-定位
# 如果通过元素自身的信息不方便直接定位到该元素,则可以先定位到其父级元素,然后再找到该元素
# 例如我们所需要定位的input上没有任何独立的属性,但是它的父类有独立属性,那么我们就可以根据父元素去定位子元素
driver.find_element(By.XPATH,"//*[@id='p1']/input").send_keys("123")
# 最后我们介绍几个XPATH的常用的延申内置属性方法
# 下面的*表示任意元素,这个是HTML中所定义的内容
# 文本内容是xxx的元素
driver.find_element(By.XPATH,"//*[text()="xxx"]")
# 属性中含有xxx的元素
driver.find_element(By.XPATH,"//*[contains(@attribute,'xxx')]")
# 属性以xxx开头的元素
driver.find_element(By.XPATH,"//*[starts-with(@attribute,'xxx')]")
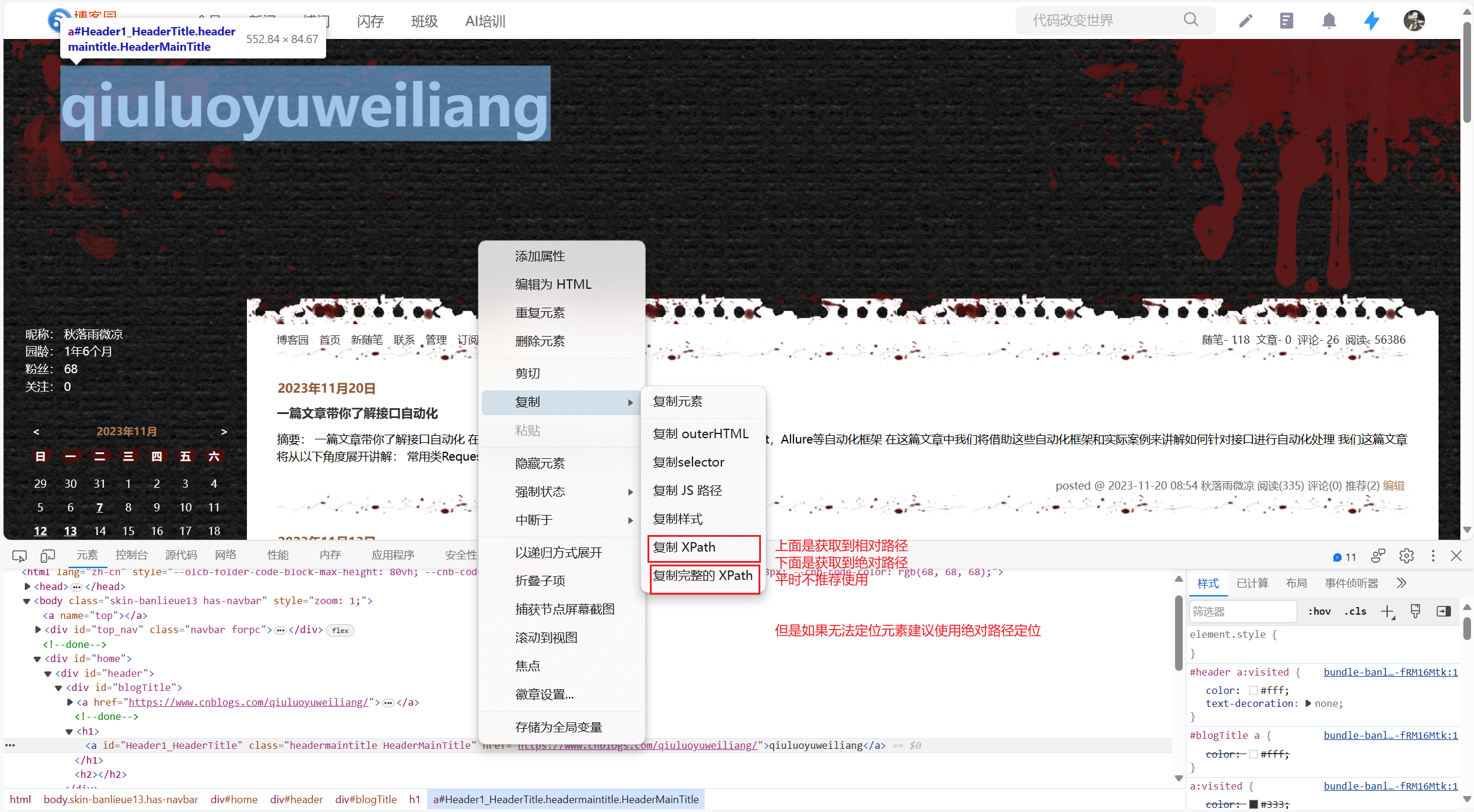
最后我们还需要简单介绍一下,我们的浏览器目前基本都可以直接点击元素右键获取绝对路径和相对路径
但使用绝对路径的速度相对而言比较缓慢且相对路径获取的数据并非是唯一数据,所以可以使用但是不推荐
这里简单给出一张获取元素路径的图片:
CSS定位
最后我们介绍一下CSS定位方法:
- 这里的CSS指的就是前端三件套里的CSS渲染工具
- 在CSS中,选择器是一种模式,用于选择需要添加样式的元素
- 在selenium中推荐使用CSS定位,因为它比XPath定位速度要快
下面我们就来介绍我们常用的几种CSS定位方法:
# 方法展示
element = driver.find_element(By.CSS_SELECTOR,css_selector)
# 1.id选择器
# 根据元素的ID获取其元素,由于ID具有唯一性,当元素存在ID时推荐使用
# CSS定位对ID做了单独的优化,我们可以直接使用#+id来定位元素,例如#usernameA就代表ID为usernameA
# 2.class选择器
# 根据元素class属性来选择元素
# CSS定位对class做了单独的优化,我们可以直接使用.+class_name来定位元素,例如.telA就代表class_name为telA
# 3.元素选择器
# 直接根据元素类型来选择元素
# 我们常见的元素包括有div,p,input等,我们直接使用即可
# 4.属性选择器
# 格式包括有:[attribute=value] element[attribute=value]
# 例如[type="password"] <选择type属性值为password的元素>,属于常用方法
# 5.层级选择器
# 层级选择器格式主要分为两种:element1>element2 和 element1 element2
# element1>element2: 通过element1来定位element2,并且element2必须为element1的直接子元素
# element1 element2: 通过element1来定位element2,并且element2为element1的后代元素
# 最后我们同样给出CSS定位的几种常用格式
# type属性以p字母开头的元素
input[type^='p']
# type属性以d字母结束的元素
input[type$='d']
# type属性包含w字母的元素
input[type*='w']
下面我们直接给出一个例子来展示上述五种定位方法:
# CSS定位是我们Selenium最常用的方法,注意掌握
"""
需求:
1. 使用css id选择器 定位用户名 输入admin
2. 使用css 属性选择 定位密码框 输入123456
3. 使用 css class 选择器 定位电话号码: 18611112222
4. 使用css 元素选择器 定位span标签获取文本值
5. 使用层级选择器 定位email 输入 123@qq.com
方法:
driver.find_element_by_css_selector()
获取文本的方法 元素.text
"""
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取 浏览器驱动对象
driver = webdriver.Firefox()
# 打开 注册A.html
url = r"D:\StudyResource\注册A.html"
driver.get(url)
# 1. 使用css id选择器 定位用户名 输入admin
driver.find_element(By.CSS_SELECTOR,"#userA").send_keys("admin")
# 2. 使用css 属性选择 定位密码框 输入123456
driver.find_element(By.CSS_SELECTOR,"[name='passwordA']").send_keys("123456")
# 3. 使用 css class 选择器 定位电话号码: 18611112222
driver.find_element(By.CSS_SELECTOR,".telA").send_keys("18611112222")
# 4. 使用css 元素选择器 定位span标签获取文本值
span = driver.find_element(By.CSS_SELECTOR,"span").text
# 5.1 使用层级选择器 定位email 输入 123@qq.com
driver.find_element(By.CSS_SELECTOR,"p>input[placeholder='电子邮箱A']").send_keys("123@qq.com")
# 5.2 使用层级选择器 定位email 输入 123@qq.com
driver.find_element(By.CSS_SELECTOR,"div input[placeholder='电子邮箱A']").send_keys("123@qq.com")
# 暂停 3秒
sleep(3)
# 退出浏览器驱动
driver.quit()
find_elements方法
最后我们来介绍一下find_elements方法:
- 查找定位所有符合条件的元素
- 返回的定位元素格式为数组(列表)格式
- 列表数据格式的读取需要指定下标(下标从0开始)
我们给出一个简单的案例:
# 我们之前所使用的都是find_element方法
# 该方法只能获得一个元素,即使我们定位到多个元素,我们也只能获取这组元素中的第一个元素
# 但是find_elements方法可以获取到一组元素并将其封装为列表
# 我们可以使用列表的获取方法来获取到这组元素中的任意元素并对其进行操作
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取 浏览器驱动对象
driver = webdriver.Firefox()
# 打开 注册A.html
url = r"D:\StudyResource\注册A.html"
driver.get(url)
# 获取所有的input元素
elements = driver.find_elements(By.TAG_NAME,"input")
# 通过遍历来输入
for el in elements:
el.send_keys("admin")
# 我们也可以通过index来获取某一个input元素进行操作
elements[0].clear()
# 暂停 3秒
sleep(3)
# 退出浏览器驱动
driver.quit()
元素操作方法
我们针对于单个元素主要有三种操作方式:
# 1.单击元素
element.click()
# 2.模拟输入
element.send_keys(value)
# 3.清除内容
element.clear()
我们给出上述操作的基本操作代码以及一段示例:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 下面我们找到对应的元素后,直接使用send_keys进行元素写入
# 输入 admin
driver.find_element(By.CSS_SELECTOR,"#userA").send_keys("admin")
# 输入 密码 123456
driver.find_element(By.CSS_SELECTOR,"#passwordA").send_keys("123456")
# 输入 电话 18611112222
driver.find_element(By.CSS_SELECTOR,".telA").send_keys("18611112222")
# 输入 邮箱 123@qq.com
driver.find_element(By.CSS_SELECTOR,"#emailA").send_keys("123@qq.com")
# 暂停2秒
sleep(2)
# 如果我们希望重新书写一个信息,我们就需要先进行清除,否则我们就是追加书写
# 修改电话号码 18622223333 -->清空操作
driver.find_element(By.CSS_SELECTOR,".telA").clear()
driver.find_element(By.CSS_SELECTOR,".telA").send_keys("18622223333")
# 暂停2秒
sleep(2)
# 然后我们点击注册按钮,进行整体页面提交
# 点击注册按钮
driver.find_element(By.CSS_SELECTOR,"button").click()
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
页面操作方法
下面我们来介绍浏览器的一些操作方法:
# 1.最大化浏览器窗口 --> 模拟浏览器最大化按钮
driver.maximize_window()
# 2.设置浏览器窗口大小 --> 设置浏览器宽、高(像素点)
driver.set_window_size(width, height)
# 3.设置浏览器窗口位置 --> 设置浏览器位置
driver.set_window_position(x, y)
# 4.后退 --> 模拟浏览器后退按钮
driver.back()
# 5.前进 --> 模拟浏览器前进按钮
driver.forward()
# 6.刷新 --> 模拟浏览器F5刷新
driver.refresh()
# 7.关闭当前窗口 --> 模拟点击浏览器关闭按钮
driver.close()
# 8.关闭浏览器驱动对象 --> 关闭所有程序启动的窗口
driver.quit()
# 9.获取页面title
driver.title
# 10.获取当前页面URL
driver.current_url
我们同样给出一段代码展示上述方法:
# 首先我们展示一下前五个方法的执行代码
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 将浏览器 最大化
driver.maximize_window()
# 暂停2秒
sleep(2)
# 设置固定大小 300,200
driver.set_window_size(300, 200)
# 暂停2秒
sleep(2)
# 移动浏览器窗口位置 x:320,y:150
driver.set_window_position(320, 150)
# 暂停2秒
sleep(2)
# 点击 访问新浪网站
# 注意:要演示后退功能,必须先执行打开新的网站
# 进入第二个界面
driver.find_element_by_partial_link_text("访问").click()
# 暂停2秒
sleep(2)
# 执行后退 ---> 注册A.html
driver.back()
# 暂停2秒
sleep(2)
# 执行前进 -->新浪 注意:前进必须放到后退操后执行
driver.forward()
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
然后我们再来展示后续操作代码:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 浏览器最大化通常是我们的默认配置,方便我们进行测试查看效果
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 将浏览器 最大化
driver.maximize_window()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册实例.html"
driver.get(url)
# 我们可以通过刷新得到一些我们书写的结果,我们也可以通过刷新刷掉目前页面我们所填写的数据信息
# 用户名输入 admin
driver.find_element_by_css_selector("#user").send_keys("admin")
# 暂停2秒
sleep(2)
# 刷新
driver.refresh()
# 获取title
title = driver.title
print("当前页面title为:", title)
# 获取当前url
current_rul = driver.current_url
print("当前页面url地址为:", current_rul)
# 点击 注册A网页 打开新窗口
driver.find_element_by_partial_link_text("注册A网页").click()
# 暂停 3秒
sleep(3)
# 关闭主窗口
driver.close()
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
元素获取方法
下面我们来介绍元素信息获取的相关方法:
# 1.返回元素大小
element.size
# 2.获取元素的文本
element.text
# 3.获取属性值,传递的参数为元素的属性名
element.get_attribute("xxx")
# 4.判断元素是否可见
element.is_displayed()
# 5.判断元素是否可用
element.is_enabled()
# 6.判断元素是否选中,用来检查复选框或单选按钮是否被选中
element.is_selected()
我们同样给出一个简单的例子展示上述方法的操作:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 将浏览器 最大化
driver.maximize_window()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册实例.html"
driver.get(url)
# 获取用户名文本框大小
size = driver.find_element(By.CSS_SELECTOR,"#user").size
print("用户名大小为:", size)
# 获取页面上第一个超文本连接内容
text = driver.find_element(By.CSS_SELECTOR,"a").text
print("页面中第一个a标签为:", text)
# 获取页面上第一个超文本链接地址 get_attribute("href")
att = driver.find_element(By.CSS_SELECTOR,"a").get_attribute("href")
print("页面中第一个a标签为href属性值为:", att)
# 判断 span元素是否可见
display = driver.find_element(By.CSS_SELECTOR,"span").is_displayed()
print("span元素是否可见:", display)
# 判断 取消按钮是否可用
enabled = driver.find_element(By.CSS_SELECTOR,"#cancel").is_enabled()
print("取消按钮是否可用:", enabled)
# 选中旅游按钮
driver.find_element(By.CSS_SELECTOR,"#ly").click()
# 判断旅游是否被选中
selected = driver.find_element(By.CSS_SELECTOR,"#ly").is_selected()
print("旅游是否被选中:", selected)
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
鼠标操作方法
下面我们同样给出鼠标操作方法:
# 首先我们需要知道鼠标的操作需要一个第三方类ActionChains
# 我们可以使用匿名类也可以直接创建一个实例对象
# 实例对象
action = ActionChains(driver)
action.操作
# 匿名使用
ActionChains(driver).操作
# 下面我们给出鼠标的相关操作方法
# 1.右击 --> 模拟鼠标右键点击效果
action.context_click(element)
# 2.双击 --> 模拟鼠标双击效果
action.double_click(element)
# 3.拖动 --> 模拟鼠标拖动效果
action.drag_and_drop(source, target)
# 4.悬停 --> 模拟鼠标悬停效果
action.move_to_element(element)
# 5.执行 --> 此方法用来执行以上所有鼠标操作
# 我们需要着重讲解一下这里,我们执行每一个鼠标操作之后都需要使用perform方法,表示执行了我们所书写的方法
action.perform()
我们给出对应的网页实操代码:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 实例化并获取 ActionChains类
action = ActionChains(driver)
# 定位用户名 在用户名上 右击鼠标 预期:粘贴
# 获取用户名元素
username = driver.find_element(By.CSS_SELECTOR,"#userA")
# 调用右击方法
ActionChains(driver).context_click(username).perform()
username.send_keys(Keys.ALT)
sleep(2)
# 发送用户名 admin 并进行双击 预期:选中admin
pwd = driver.find_element(By.CSS_SELECTOR,"#passwordA")
pwd.send_keys("admin")
ActionChains(driver).double_click(pwd).perform()
sleep(2)
# 移动到注册按钮上 预期:按钮变色 出现 加入会员A
ActionChains(driver).move_to_element(driver.find_element(By.CSS_SELECTOR,"button")).perform()
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
这里我们介绍一个有关鼠标右键操作的小技巧:
# 我们通常使用鼠标右键其实是为了某些网页的特定要求,比如某些按钮需要右键点击等
# 但有时我们也是为了像正常网页呢样去使用我们的复制粘贴等右键框里的操作,但我们无法直接使用,但是我们可以借助快捷键来实现
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
# 谷歌浏览器不支持 --> 粘贴快捷键
# driver = webdriver.Chrome()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 实例化并获取 ActionChains类
action = ActionChains(driver)
# 定位用户名 在用户名上 右击鼠标 预期:粘贴
# 获取用户名元素 admin123
username = driver.find_element(By.CSS_SELECTOR,"#userA")
# 点击右键
action.context_click(username).perform()
# 发送p
username.send_keys("p")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
键盘操作方法
下面我们来介绍键盘操作方法:
# 使用键盘操作同样需要一个第三方类 Keys,但是我们不需要创建实体对象,只需要导入该包即可
# 1.删除键(BackSpace)
element.send_keys(Keys.BACK_SPACE)
# 2.空格键(Space)
element.send_keys(Keys.SPACE)
# 3.制表键(Tab)
element.send_keys(Keys.TAB)
# 4.回退键(Esc)
element.send_keys(Keys.ESCAPE)
# 5.回车键(Enter)
element.send_keys(Keys.ENTER)
# 6.CTRL+任意键
element.send_keys(Keys.CONTROL,'任意键')
# 7.全选(Ctrl+A)
element.send_keys(Keys.CONTROL,'a')
# 8.复制(Ctrl+C)
element.send_keys(Keys.CONTROL,'c')
我们同样给出代码示例:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver.common.keys import Keys
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 定位 用户名
username = driver.find_element(By.CSS_SELECTOR,"#userA")
# 输入 admin1
username.send_keys("admin1")
sleep(2)
# 删除1
username.send_keys(Keys.BACK_SPACE)
sleep(2)
# 全选 admin Ctrl+a
username.send_keys(Keys.CONTROL, "a")
sleep(2)
# 复制 Ctrl+c
username.send_keys(Keys.CONTROL, "c")
sleep(2)
# 定位密码框 并执行 Ctrl+v
driver.find_element(By.CSS_SELECTOR,"#passwordA").send_keys(Keys.CONTROL, "v")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
元素等待方法
我们首先需要明白为什么需要元素等待:
- 在Selenium执行脚本定位时,若该元素还没加载成功,则脚本获取该元素失败,从而导致报错
那么我们就应该很容易理解元素等待:
- WebDriver定位页面元素时如果未找到,会在指定时间内一直等待的过程
元素等待被划分为两种:
- 隐式等待:针对所有元素进行设置,若定位失败待一定时间后重新定位,规定时间内定位失败直接报错
- 显式等待:针对单个元素进行设置,若定位失败待一定时间后重新定位,规定时间内定位失败直接报错
我们首先来讲解隐式等待:
# 隐式等待方法(timeout:为等待最大时长,单位:秒)
# 说明:隐式等待为全局设置(只需要设置一次,就会作用于所有元素)
driver.implicitly_wait(timeout)
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 设置元素等待
# 设置隐式等待10秒。
driver.implicitly_wait(10)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 给一个错误的id,不能知道,如果直接抛出异常,说明等待失效。如果在设置指定时长以外抛出说明等待生效。
driver.find_element(By.CSS_SELECTOR,"#user").send_keys("admin")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
下面我们再来介绍显式等待:
# 其实我们大多数高级代码中都是使用显示等待,因为显式等待可以设置的参数较多,更容易我们控制响应
# 我们首先需要导包
from selenium.webdriver.support.wait import WebDriverWait
# 然后我们需要创建一个WebDriverWait用于进行显式等待操作
wait = WebDriverWait(driver, timeout, poll_frequency=0.5)
# 最后我们使用wait对需要等待的元素进行操作
# method:函数名称,该函数用来实现对元素的定位
# 一般使用匿名函数来实现:lambda x: x.find_element_by_id("userA")
wait.until(method)
wait.until(lambda x: x.find_element_by_id("userA"))
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Firefox()
driver.maximize_window()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 写法1
# 实例化WebDriverWait()并调用until方法
# 注意:调用until方法返回的一定是一个元素
username = WebDriverWait(driver, timeout=10, poll_frequency=0.5).until(lambda x:x.find_element_by_id("#user")).send_keys("admin")
# 写法2
# 获取 WebDriverWait示例对象
wait= WebDriverWait(driver,timeout=10, poll_frequency=0.5)
# 获取元素
username = wait.until(lambda x:x.find_element_by_id("#user"))
# 发送内容
username.send_keys("admin")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
特殊元素方法
下面我们分别来介绍四种特殊元素操作方法:
文件上传
下拉选择框
弹出框
滚动条
文件上传
我们在进行Web页面操作时,有时会让我们进行文件内容上传
其实处理方法非常简单,我们直接给出一个小案例来展示文件上传效果:
# 文件上传
# 我们只需要对文件上传的元素输入我们本地目录的绝对地址或相对地址即可
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 错误的实现
# driver.find_element_by_css_selector("[name='upfilea']").click()
# 正确实现,使用 send_keys("文件路径及文件名")
driver.find_element(By.CSS_SELECTOR,"[name='upfilea']").send_keys("D:\hello123.txt")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
下拉选择框
首先我们需要知道什么是下拉选择框:
- 下拉框就是HTML中<select>元素
那么我们首先需要了解我们在未学习该方法前,我们通常都是采用什么方法来选择下拉选择框:
# 因为我们的下拉选择框都是<select>元素,那么对应的选择框都是option元素
# 所以我们只需要选择对应的option元素,然后采用click方法进行该元素点击就可以选中该元素
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 下方的三行代码基本成为我们所有Selenium的标配
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
sleep(2)
# 使用css定位来操作 A上海
driver.find_element_by_css_selector("[value='sh']").click()
sleep(2)
# 使用css定位 A广州
driver.find_element_by_css_selector("[value='gz']").click()
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
但是我们还有另外一种方法进行元素选择,该元素选择方法相较之前那种更加清楚明了:
# Selenium为我们提供了一种专门用于选择框的第三方类Select
# 我们可以采用Select类来封装其<select>选择框,然后采用各种方法来更换内部元素
# 1.封装下拉选择框父元素
select = Select(element)
# 2. 执行方法
# 2-1. 根据option索引来定位,从0开始
select_by_index(index)
# 2-2. 根据option属性 value值来定位
select_by_value(value)
# 2-3. 根据option显示文本来定位
select_by_visible_text(text)
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
from selenium.webdriver.support.select import Select
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 我们可以直接获取其父元素,也就是我们的<select>元素
el = driver.find_element(By.CSS_SELECTOR,"#selectA")
sleep(2)
# 2-1.采用索引定位
# 切换 上海
Select(el).select_by_index(1)
# sleep(2)
Select(el).select_by_index(2)
# 2-2.采用属性定位
# 切换 上海
el.select_by_value("sh")
# sleep(2)
# 切换 广州
el.select_by_value("gz")
# 2-3. 采用完整文本定位
# 切换 上海
Select(el).select_by_visible_text("A上海")
# 切换广州
Select(el).select_by_visible_text("A广州")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
弹出框
我们在网页操作时通常会遇到三种弹出框:
- 警告框:alert
- 确认框:confirm
- 提示框:prompt
而如果我们遇到了这些弹出框,通常会出现一种问题:
- 如果出现了弹出框,就会导致弹出框覆盖在我们页面之上,从而导致我们无法定位元素而报错
所以我们需要对弹出框进行处理:
# Selenium中对处理弹出框的操作,有专用的处理方法;并且处理的方法都一样
# 1.获取弹出框对象
alert = driver.switch_to.alert
# 2-1.返回alert/confirm/prompt中的文字信息(无法使该弹出框消失,需要继续调用下面两个方法)
alert.text
# 2-2.接受对话框选项
alert.accept()
# 2-3.取消对话框选项
alert.dismiss()
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 定位 alert按钮 并 点击
driver.find_element(By,CSS_SELECTOR,"#alerta").click()
# 这时会存在弹出框,我们需要对其进行处理
# 默认返回的alert对话框对象
at = driver.switch_to.alert
# 处理 对话框
# 同意
at.accept()
# 获取文本
# print("警告信息:", at.text)
# 取消
# at.dismiss()
# 定位 用户名 输入admin(处理弹框之后我们才可以继续这一步)
driver.find_element(By,CSS_SELECTOR,"#userA").send_keys("admin")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
滚动条
首先我们需要了解什么是滚动条以及我们为什么需要处理它:
- 在HTML页面中,由于前端技术框架的原因,页面元素为动态显示,元素根据滚动条的下拉而被加载
- 页面注册同意条款,需要滚动条到最底层,才能点击同意
那么我们就来介绍滚动条的操作方法:
# selenium中并没有直接提供操作滚动条的方法,
# selenium提供了可执行JavaScript脚本的方法,所以我们可以通过JavaScript脚本来达到操作滚动条的目的
# 1.设置JavaScript脚本控制滚动条(0:左边距;1000:上边距;单位像素)
js = "window.scrollTo(0,1000)"
# 2.selenium调用执行JavaScript脚本的方法
driver.execute_script(js)
# 导包
from selenium import webdriver
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
sleep(2)
# 第一步 设置js控制滚动条语句
js = "window.scrollTo(0, 10000)"
# 第二步 调用执行js语句方法
driver.execute_script(js)
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
窗口切换方法
下面我们来介绍窗口的切换,但是窗口其实是分为两种的:
- frame窗口:HTML页面中的一种框架,主要作用是在当前页面中指定区域显示另一页面元素
- 浏览器窗口:在HTML页面中,当点击超链接或者按钮时,有的会在新的窗口打开页面
frame窗口切换
首先我们需要了解什么是frame窗口:
- frame窗口和主窗口都是在同一个页面下,在主窗口下存在一个<frame>或<iframe>进行存放
- 但是frame窗口的内容其实是存放在另一个html下的,所以我们在该界面下直接获取是获取不到的
所以我们就需要进行frame窗口切换:
# Selenium中封装了如何切换frame框架的方法
# 切换到指定frame的方法
# frame_reference:可以为frame框架的name、id或者定位到的frame元素
driver.switch_to.frame(frame_reference)
# 恢复默认页面方法
driver.switch_to.default_content()
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册实例.html"
driver.get(url)
# 用户名
driver.find_element(By.CSS_SELECTOR,"#user").send_keys("admin")
# 密码
driver.find_element(By.CSS_SELECTOR,"#password").send_keys("admin")
# 电话
driver.find_element(By.CSS_SELECTOR,".tel").send_keys("18611112222")
# 邮件
driver.find_element(By.CSS_SELECTOR,"#email").send_keys("123@qq.com")
# 切换到注册A 使用name
# driver.switch_to.frame("myframe1")
# 使用id
driver.switch_to.frame("idframe1")
"""填写注册A"""
# 用户名
driver.find_element(By.CSS_SELECTOR,"#userA").send_keys("admin")
# 密码
driver.find_element(By.CSS_SELECTOR,"#passwordA").send_keys("admin")
# 电话
driver.find_element(By.CSS_SELECTOR,".telA").send_keys("18611112222")
# 邮件
driver.find_element(By.CSS_SELECTOR,"#emailA").send_keys("123@qq.com")
# 切换到默认目录
# 因为只有默认目录下采用frame2
driver.switch_to.default_content()
# 切换到注册B 使用name
# driver.switch_to.frame("myframe2")
# 使用元素切换
driver.switch_to.frame(driver.find_element(By.CSS_SELECTOR,"[name='myframe2']"))
"""填写注册B"""
# 用户名
driver.find_element(By.CSS_SELECTOR,"#userB").send_keys("admin")
# 密码
driver.find_element(By.CSS_SELECTOR,"#passwordB").send_keys("admin")
# 电话
driver.find_element(By.CSS_SELECTOR,".telB").send_keys("18611112222")
# 邮件
driver.find_element(By.CSS_SELECTOR,"#emailB").send_keys("123@qq.com")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
浏览器窗口切换
那么浏览器窗口切换我们就不需要过多介绍:
- 在HTML页面中,当点击超链接或者按钮时,有的会在新的窗口打开页面
那么我们就来介绍浏览器窗口切换:
# 在Selenium中封装了获取当前窗口句柄、获取所有窗口句柄和切换到指定句柄窗口的方法
# 句柄:英文handle,窗口的唯一识别码
# 1.获取当前窗口句柄
driver.current_window_handle
# 2.获取所有窗口句柄
driver.window_handles
# 3.切换指定句柄窗口
# 提示:我们新打开的窗口往往都是最后一个窗口,所以我们只需要获得所有窗口句柄然后采用[-1]获取最后一个即可
# 提示:当然我们也可以依次遍历所有句柄,然后我们去判断和我们当前页面句柄不同的句柄,我们就可以切换到该句柄往往也是我们需要的界面
driver.switch_to.window(handle)
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册实例.html"
driver.get(url)
# 获取当前窗口句柄 -->目的:判断只要不是当前主窗口句柄,就一定时新开的窗口句柄
current_handle = driver.current_window_handle
print("当前窗口句柄为:", current_handle)
# 点击注册A网页
driver.find_element_by_partial_link_text("A网页").click()
# 获取所有窗口句柄
handles = driver.window_handles
print("所有窗口句柄:", handles)
# 判断 不是 当前窗口句柄
for h in handles:
if h != current_handle:
# 切换
driver.switch_to.window(h)
"""填写注册A"""
# 用户名
driver.find_element(By.CSS_SELECTOR,"#userA").send_keys("admin")
# 密码
driver.find_element(By.CSS_SELECTOR,"#passwordA").send_keys("admin")
# 电话
driver.find_element(By.CSS_SELECTOR,".telA").send_keys("18611112222")
# 邮件
driver.find_element(By.CSS_SELECTOR,"#emailA").send_keys("123@qq.com")
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
窗口截图方法
我们在测试过程中通常会出现各种各样的问题,如果我们只有测试信息提示我们很难定位到问题:
- 所以我们可以将出现问题的界面截图下来,方便我们后续进行判断错误原因
我们直接给出窗口截图的相关方法:
# Selenium中,提供了截图方法,我们只需要调用即可
# 方法
# imgpath:图片保存路径
driver.get_screenshot_as_file(imgpath)
# 导包
import time
from time import strftime
from selenium import webdriver
from time import sleep
# 获取浏览器驱动对象
driver = webdriver.Firefox()
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
url = r"D:\web自动化素材\课堂素材\注册A.html"
driver.get(url)
# 输入 admin
driver.find_element(By.CSS_SELECTOR,"#userA").send_keys("admin")
# 调用截图方法
# driver.get_screenshot_as_file("./admin.png")
# 存放指定目录
# driver.get_screenshot_as_file("../scripts/admin02.png")
# driver.get_screenshot_as_file("../image/admin.png")
# 动态获取文件名称 使用时间戳
# driver.get_screenshot_as_file("../image/%s.png"%(time.strftime("%Y_%m_%d %H_%M_%S")))
# driver.get_screenshot_as_file("../image/%s.jpg"%(time.strftime("%Y_%m_%d %H_%M_%S")))
driver.get_screenshot_as_file("../image/%s.jpg"%(strftime("%Y_%m_%d %H_%M_%S")))
# 暂停 2
sleep(2)
# 关闭驱动对象
driver.quit()
结束语
这篇文章中详细介绍了Web自动化工具Selenium的相关知识,希望能为你带来帮助
下面给出我学习和书写该篇文章的一些参考文章,大家也可以去查阅:
- 黑马课程:软件测试web自动化测试,Web自动化流程精讲和移动自动化测试环境_哔哩哔哩_bilibili
- 知乎文章:selenium用法详解【从入门到实战】【Python爬虫】【4万字】 - 知乎 (zhihu.com)
- 知乎文章:2 万字带你了解 Selenium 全攻略 - 知乎 (zhihu.com)
一篇文章带你掌握Web自动化测试工具——Selenium的更多相关文章
- 开源Web自动化测试工具Selenium IDE
Selenium IDE(也有简写SIDE的)是一款开源的Web自动化测试工具,它实现了测试用例的录制与回放. Selenium IDE目前版本为 3.6 系列,支持跨浏览器运行,所以IDE的UI从原 ...
- 一篇文章带你了解轻量级Web服务器——Nginx简单入门
一篇文章带你了解轻量级Web服务器--Nginx简单入门 Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件代理服务器 在本篇中我们会简单介绍Nginx的特点,安装,相关指令使用以及配置信 ...
- 一篇文章带你掌握主流服务层框架——SpringMVC
一篇文章带你掌握主流服务层框架--SpringMVC 在之前的文章中我们已经学习了Spring的基本内容,SpringMVC隶属于Spring的一部分内容 但由于SpringMVC完全针对于服务层使用 ...
- 一篇文章带你掌握主流基础框架——Spring
一篇文章带你掌握主流基础框架--Spring 这篇文章中我们将会介绍Spring的框架以及本体内容,包括核心容器,注解开发,AOP以及事务等内容 那么简单说明一下Spring的必要性: Spring技 ...
- 一篇文章带你掌握主流办公框架——SpringBoot
一篇文章带你掌握主流办公框架--SpringBoot 在之前的文章中我们已经学习了SSM的全部内容以及相关整合 SSM是Spring的产品,主要用来简化开发,但我们现在所介绍的这款框架--Spring ...
- MYSQL(基本篇)——一篇文章带你走进MYSQL的奇妙世界
MYSQL(基本篇)--一篇文章带你走进MYSQL的奇妙世界 MYSQL算是我们程序员必不可少的一份求职工具了 无论在什么岗位,我们都可以看到应聘要求上所书写的"精通MYSQL等数据库及优化 ...
- MYSQL(进阶篇)——一篇文章带你深入掌握MYSQL
MYSQL(进阶篇)--一篇文章带你深入掌握MYSQL 我们在上篇文章中已经学习了MYSQL的基本语法和概念 在这篇文章中我们将讲解底层结构和一些新的语法帮助你更好的运用MYSQL 温馨提醒:该文章大 ...
- 一篇文章带你掌握MyBatis简化框架——MyBatisPlus
一篇文章带你掌握MyBatis简化框架--MyBatisPlus 我们在前面的文章中已经学习了目前开发所需的主流框架 类似于我们所学习的SpringBoot框架用于简化Spring开发,我们的国人大大 ...
- 一篇文章带你了解网页框架——Vue简单入门
一篇文章带你了解网页框架--Vue简单入门 这篇文章将会介绍我们前端入门级别的框架--Vue的简单使用 如果你以后想从事后端程序员,又想要稍微了解前端框架知识,那么这篇文章或许可以给你带来帮助 温馨提 ...
- 一篇文章带你了解热门版本控制系统——Git
一篇文章带你了解热门版本控制系统--Git 这篇文章会介绍到关于版本控制的相关知识以及版本控制神器Git 我们可能在生活中经常会使用GitHub网页去查询一些开源的资源或者项目,GitHub就是基于G ...
随机推荐
- MySQL面试题全解析:准备面试所需的关键知识点和实战经验
MySQL有哪几种数据存储引擎?有什么区别? MySQL支持多种数据存储引擎,其中最常见的是MyISAM和InnoDB引擎.可以通过使用"show engines"命令查看MySQ ...
- 每日一库:gosec
gosec 是一个用于在 Go 代码中查找安全问题的开源工具,它可以帮助发现可能的漏洞和潜在的安全风险.以下是关于 gosec 的详细介绍: 1. 工具概述: gosec 是一个静态分析工具,用于扫描 ...
- 【NestJS系列】核心概念:Module模块
theme: fancy highlight: atelier-dune-dark 前言 模块指的是使用@Module装饰器修饰的类,每个应用程序至少有一个模块,即根模块.根模块是Nest用于构建应用 ...
- 聊聊HuggingFace如何处理大模型下海量数据集
翻译自: Big data? Datasets to the rescue! 如今,使用大GB的数据集并不罕见,特别是从头开始预训练像BERT或GPT-2这样的Tranformer模型.在这样的情况下 ...
- QA|workon env后没有进入虚拟环境,但也没有报错,但cmd可以|Python虚拟环境
问题:pycharm的terminal执行workon env后没有进入虚拟环境,但也没有报错 但cmd可以 原因:因为pycharm的terminal用的是powershell,更改为cmd,重新打 ...
- 2.14 PE结构:地址之间的转换
在可执行文件PE文件结构中,通常我们需要用到地址转换相关知识,PE文件针对地址的规范有三种,其中就包括了VA,RVA,FOA三种,这三种该地址之间的灵活转换也是非常有用的,本节将介绍这些地址范围如何通 ...
- 在阿里云上部署Solid服务器
1.Solid是什么? Solid(中文文档)是一个令人兴奋的新项目,由万维网发明者 Tim Berners-Lee 爵士在麻省理工学院启动. 该项目旨在从根本上改变 Web 应用程序的中心化趋势, ...
- java类序列化和反序列化
参考:https://zhuanlan.zhihu.com/p/144535172?utm_id=0 https://blog.csdn.net/qq_42617455/article/details ...
- Springboot优雅参数校验,统一响应,异常处理
1.统一响应 (1)统一状态码 首先定义一个状态码接口,所有状态码都需要实现它 public interface StatusCode { public int getCode(); public S ...
- u-boot启动流程
U-Boot(Universal Bootloader)是一个通用的开源引导加载程序,通常用于嵌入式系统中,负责引导操作系统或加载 Linux 内核等任务.U-Boot的启动流程可以概括为以下几个关键 ...