Hadoop集群模式安装笔记
前言
Hadoop集群=HDFS集群+YARN集群
特点:两个集群逻辑上分离,通常物理上在一起;并且都是标准的主从架构集群
Hadoop安装
方式一源码编译安装
方式二官方编译安装包 ()
环境
Centos +虚拟机
集群规划
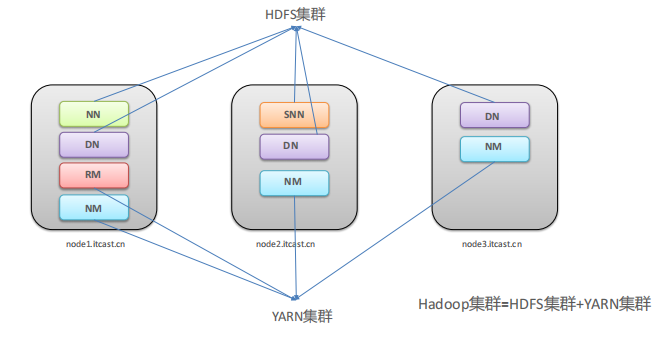
| 服务器 | 运行角色 |
|---|---|
| node1.itcast.cn | namenode datanode resourcemanager nodemanager |
| node2.itcast.cn | secondarynamenode datanode nodemanager |
| node3.itcast.cn | datanode nodemanager |
服务器环境准备
1、主机名-allservers
/* 建立服务器的主机名*/
vim /etc/hostname
添加主机名
/*验证:*/
hostname或cat /etc/hostname、
2、Hosts映射-allservers
/*建立服务器主机名和IP地址映射*/
vim /etc/hosts
添加IP地址 主机名1 主机名2..
/*验证:*/
cat /etc/hosts
3、集群时间同步-allservers
/*安装ntpdate命令*/
yum -y install ntpdate (若有可跳过)
/*同步时间*/
ntpdate ntp4.aliyun.com
4、关闭防火墙-allservers
systemctl stop firewalld.service #停止firewalld服务
systemctl disable firewalld.service #开机禁用firewalld服务
5、SSH免密登录-node1
Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程可用通过SSH登录实现。
#只需要配置node1至node1、node2、node3即可
#node1生成公钥私钥--一直确认
ssh-keygen
#node1配置免密登录到node1 node2 node3
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
#验证,进行登录
ssh node1
ssh node2
ssh node3
4、创建存放路径
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/sofrware/ #安装包存放路径
5、安装JDK-allservers
JDK安装包上传至/export/server/
#解压
tar -zxvf jdk-8u241-linux-x64.tar.gz
#解压文件:jdk1.8.0_241
#解压后的文件分发同步到node2、node3,路径保持一致
scp -r /export/server/jdk1.8.0_241 root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241 root@node3:/export/server/
-------------------------------------------------------------
#配置环境变量
vim /etc/profile
#追加
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#同步分发到node2,node3
scp /etc/profile root@node2:/etc/profile
scp /etc/profile root@node3:/etc/profile
#重新加载环境变量文件
source /etc/profile
#验证
java -version
6、安装Hadoop-allservers
#上传Hadoop安装包到node1 /export/server
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
#解压
tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
------------------------------------------------------
#修改配置文件:/hadoop-3.3.0/etc/hadoop
hadoop-env.sh
core-site.xml #核心模块配置
hdfs-site.xml #hdfs文件系统模块配置
mapred-site.xml #MapReduce模块配置
yarn-site.xml #yarn模块配置
workers
#分发同步hadoop安装包
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
------------------------------------------------------
#配置环境变量
vim /etc/profile
#追加
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#重载配置文件
source /etc/profile
#分发同步
...
#验证
hadoop
7、Hadoop集群启动
1、 首次启动HDFS之前需要format操作;format本质上是初始化工作,进行HDFS清理和准备工作
2. format只能进行一次 后续不再需要;
3. 如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别。通过删除所有机器hadoop.tmp.dir目录重新format解决
命令:hdfs namenode -format #node1,namenode进程在node1 下
验证:

Hadoop集群的启停
1、手个逐个进程启停
每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停。
HDFS集群:
#hadoop2.x版本命令
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
#hadoop3.x版本命令
hdfs --daemon start|stop namenode|datanode|secondarynamenode
YARN集群
#hadoop2.x版本命令
yarn-daemon.sh start|stop resourcemanager|nodemanager
#hadoop3.x版本命令
yarn --daemon start|stop resourcemanager|nodemanager
2、shell脚本一键启停
一台机器上操作,集群内所有机器都会做配置
在node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和workers文件
#HDFS集群
start-dfs.sh
stop-dfs.sh
#YARN集群
start-yarn.sh
stop-yarn.sh
#Hadoop集群
start-all.sh
stop-all.sh
#验证集群启动正常
jps #显示java相关进程,查看进程是否启动
/export/server/hadoop-3.3.0/logs/*.log #查看hadoop启动日志
------------------------------------------
闪退则是配置文件出错
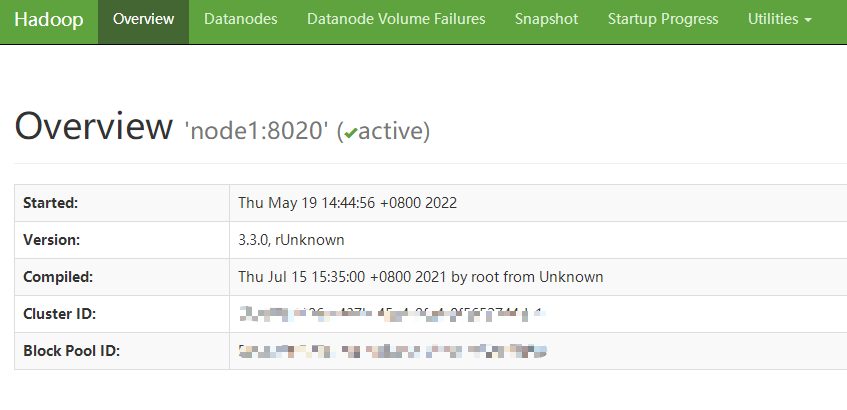
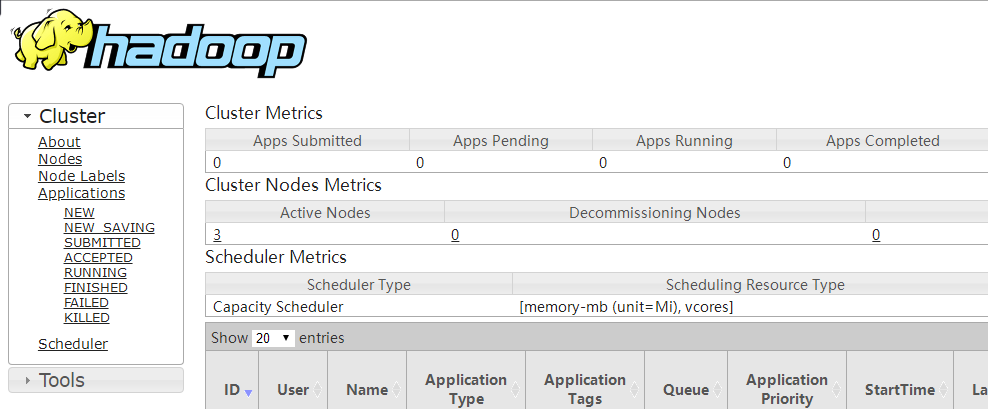
Hadoop WebUI
HDFS集群:http://namenode_host:9870
其中namenode_host是namenode运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
YARN集群:http://resourcemanager_host:8088
其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
备注:
单机安装是本机作为集群
伪分布式安装是指在一台机器上模拟一个小的集群,但是集群只有一个节点。
完全分布式安装可用通过安装多个Linux虚拟机来实现。
Hadoop集群模式安装笔记的更多相关文章
- Presto单机/集群模式安装笔记
Presto单机/集群模式安装笔记 一.安装环境 二.安装步骤 三.集群模式安装: 3.1 集群模式修改配置部分 3.1.1 coordinator 节点配置. Node172配置 3.1.2 nod ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- Hadoop集群模式安装出现的若干问题
一.域名解析问题 域名解析暂时失败问题 vim /etc/sysconfig/network 查看主机名 vim etc/hosts 配置IP地址与主机名 192.168.60.132 centos ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
随机推荐
- 【AGC】云监控日志服务查询不到Logger日志相关问题2
[关键字] AGC.云监控.日志服务 [问题描述] 之前有开发者反馈在使用AGC云监控,填写了Logger日志,但是在云监控的日志服务查不到的问题.具体如下所述: 云函数按要求写了Logger日志, ...
- CHAT-GPT初使用
拿chatgpt去试验了一下,一个挺小的需求,但是前后还是更改了三次,体验就是它可以不断改进之前实现的代码,但需要提需求的人比较清楚需求内的细节,差不多类似于,我有想法,它来实现,还是可以提高不少效率 ...
- WakaTime Readme Stats-开源项目翻译
寻找不同语言和地区的翻译 #23 Readme中添加了功能标志的开发指标 眼前一亮的Readme统计数据 你是早起的还是夜间的? 你一天中什么时候工作效率最高? 你用什么语言编写代码? 让我们在你的个 ...
- Spring Boot 整合组件套路
自动配置类 Spring Boot 在整合任何一个组件的时候都会先添加一个依赖 starter,比如整合 MybatisPlus 有一个 mybatis-plus-boot-starter,如下: & ...
- 反向代理后 location 被替换成本机域名。
反向代理后 location 被替换成本机域名. 和上次写博客系统遇到的问题一样. 反向代理后,系统header中的location参数 域名自动被替换成本机域名了,本地测试没有问题,服务器反向代理就 ...
- MySQL存储之为什么要使用B+树做为储存结构?
导言: 在使用MySQL数据库的时候,我们知道了它有两种物理存储结构,hash存储和B+树存储,由于hash存储使用的少,而B+树存储使用的范围就多些,如 InnoDB和MYISAM引擎都是使用的B+ ...
- 基于.Net Core实现的飞书文档一键导出服务(支持多系统)
feishu-doc-export 一个支持Windows.Mac.Linux系统的飞书文档一键导出服务,仅需一行命令即可将飞书知识库的全部文档同步到本地电脑.导出速度嘎嘎快,实测700多个文档导出只 ...
- BitLocker加密过程中断断电,能否恢复数据?
BitLocker是Windows系统提供的磁盘加密功能,用户自己可以手动开启.在访问受BitLocker保护的磁盘分区时,需要先提供正确的密码.秘钥或是BEK文件.如果使用BitLocker将系统盘 ...
- 在VS Code 中调试远程服务器的PHP代码
背景 对于PHP的调试,一般来说我们用 echo 和 var_dump 就够用了. 有时会碰到要解决复杂的逻辑或需要确认代码的运行顺序,这里用var_dump效率就比较低了,这时建议用断点的方式进行代 ...
- 【转载】Linux虚拟化KVM-Qemu分析(二)之ARMv8虚拟化
原文链接: 作者:LoyenWang 出处:https://www.cnblogs.com/LoyenWang/ 公众号:LoyenWang 版权:本文版权归作者和博客园共有 转载:欢迎转载,但未经作 ...