基于飞桨paddlespeech训练中文唤醒词模型
飞桨Paddlespeech中的语音唤醒是基于hey_snips数据集做的。Hey_snips数据集是英文唤醒词,对于中国人来说,最好是中文唤醒词。经过一番尝试,我发现它也能训练中文唤醒词,于是我决定训练一个中文唤醒词模型。
要训练中文唤醒词模型,主要有如下工作要做:找数据集,做数据增强(augmentation),做标注,训练和评估等。关于数据集,调研下来发现“你好米雅”这个数据集不错。它不仅可以做声纹识别,也可以做唤醒词识别。它录制人数较多,既近场拾音(44.1KHZ),又用了麦克风阵列远场拾音(16kHZ),还有快速、正常语速、慢速等,极大地丰富了语料。难能可贵的是出品方希尔贝壳还出了一个补充数据集,全是“你好米雅”的相似发音,比如“你好呀”、“你好米”等。把这些作为负样本加入训练,会大大地降低说“你好米雅”相似词的误唤醒率。经过评估后我决定用“你好米雅”这个唤醒词。因为“你好米雅”数据集只有唤醒词语料,为了降低误唤醒,我又把AIDataTang数据集中两三秒左右的语料提取出来作为负样本加入训练。这样整个数据集包括三部分:“你好米雅”的原始数据集,相似发音的补充数据集(作为负样本)和AIDataTang数据集(作为负样本)。先把“你好米雅”数据集中44.1k采样的语料变成16K采样的,再分别将三个数据集分成训练集、验证集、测试集三部分。数据集分好后,还需要做数据增强,目前主要用的是加噪。从NOISEX-92中选取10种典型噪声,再结合各种SNR叠加到干净语音中形成带噪语音。数据增强做好后又把数据集增大了好多,形成一个近300万个wav的数据集。最后写python代码按照paddlespeech里规定的格式做了数据标注,得到了train.json/dev.json/test.json三个文件。在json文件中对于一个wav文件的标注格式如下图:

包括文件的时长、文件的路径、id以及是否是唤醒词等。
以上这些工作做好后就开始训练和评估了,验证集和测试集下的结果都不错。又想试试真实录音的wav的准确率如何,请了几个人在办公室环境下用手机录了“你好米雅”的音频,在得到的模型下去测试,结果让我大失所望,识别率特别低。为什么呢?测试集上的结果可挺好的呀。输入模型的特征是频域的fbank,于是我就从频谱上找差异。对比测试集里能识别的和自己录的不能识别的wav的频谱,发现能识别的在7K HZ附近处做了低通滤波,而不能识别的却没有,具体见下图:
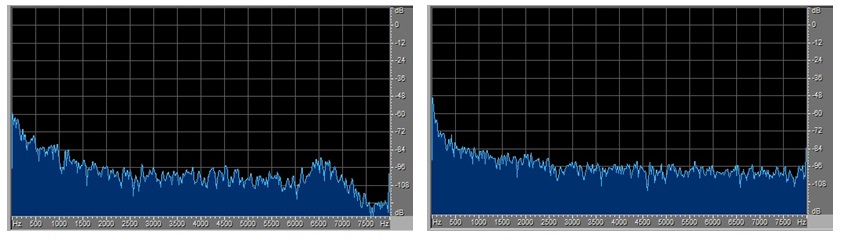
做了7k HZ低通滤波的能识别 没做7k HZ低通滤波的不能识别
我试着将不能识别的也在7K HZ附近处做了低通滤波,再去做测试就能识别了。这样自己录的不能识别的原因就找到了:没去做7K HZ附近的低通滤波。整个数据集是由3个子数据集(“你好米雅”数据集,“你好米雅”相似词数据集,AIDATATANG数据集)组成的,前两个是同一出品方且用相同的设备录的。我看了这三个子数据集的频域特性,前两个都在7K HZ附近处做了低通滤波,而AIDATATANG的没有。这暴露了我在数据集准备上的一个错误:没有做到训练集/验证集/测试集频域特性上的一致。
原因找到了,对应的措施就是对原先的数据集做7k HZ处的低通滤波处理。为了再降低误唤醒率,我又找来了cn-celeb数据集,因为这个里面包含的场景更丰富,有singing/vlog/movie/entertainment等。把里面几秒左右的音频都提取出来,先做7k HZ处的低通滤波处理,再把它们作为负样本加入到数据集中。数据处理好后就又开始训练了。一边训练模型,一边请更多的人用手机录“你好米雅”的唤醒词音频,还要对这些录好的做7k HZ处的低通滤波处理。模型训练好后在验证集和测试集上的评估效果(唤醒率和误唤醒率)都很好,再把自己录的音频在模型上跑,唤醒率跟在测试集上保持一致。同时还做了另外一个实验,把测试集里有唤醒词且有噪声的音频提取出来组成一个新的测试集。先在这个集上看唤醒率,再对这个集上的音频做降噪处理,再看唤醒率,发现唤醒率有一定程度的降低。这是模型没有学习降噪算法的结果,模型不像人耳,降噪后听起来更清晰未必能识别。通过这些实验说明:要想在嵌入式设备上语音唤醒效果好,得搞清楚特征提权前有哪些前处理算法(降噪等)。语料最好是在这款嵌入式设备上录,如果没有条件就要把语料过一下这些前处理算法后再拿去训练和评估,也就是要让模型学一下这些前处理算法。
现在的模型输入特征是80维的fbank,我又评估了一下维度改到40维后对唤醒效果的影响。评估下来发现唤醒率有0.2%左右的下降,误唤醒率有0.3%左右的提升,在可接受的范围内。好处是模型参数减少了1.6k(见下图),推理时的运算量也有一定程度的减少。

目前用的是公开数据集里的中文唤醒词,通过实践找到一些能提高唤醒率和降低误唤醒率的方法。等做产品时用的数据集是私有的,把找到的方法用到模型训练上,就能出一个性能不错的语音唤醒方案。
基于飞桨paddlespeech训练中文唤醒词模型的更多相关文章
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- 使用 DL4J 训练中文词向量
目录 使用 DL4J 训练中文词向量 1 预处理 2 训练 3 调用 附录 - maven 依赖 使用 DL4J 训练中文词向量 1 预处理 对中文语料的预处理,主要包括:分词.去停用词以及一些根据实 ...
- 飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节.因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推 ...
- word2vec训练好的词向量
虽然早就对NLP有一丢丢接触,但是最近真正对中文文本进行处理才深深感觉到自然语言处理的难度,主要是机器与人还是有很大差异的,毕竟人和人之间都是有差异的,要不然不会讲最难研究的人嘞 ~~~~~~~~~~ ...
- word2vec中文类似词计算和聚类的使用说明及c语言源代码
word2vec相关基础知识.下载安装參考前文:word2vec词向量中文文本相似度计算 文件夹: word2vec使用说明及源代码介绍 1.下载地址 2.中文语料 3.參数介绍 4.计算相似词语 5 ...
- 树莓派上搭建唤醒词检测引擎 Snowboy
Snowboy 是一款高度可定制的唤醒词检测引擎,可以用于实时嵌入式系统,并且始终监听(即使离线).当前,它可以运行在 Raspberry Pi.(Ubuntu)Linux 和 Mac OS X 系统 ...
- 自然语言9_NLTK计算中文高频词
以下代码仅限于python2 NLTK计算中文高频词 >>> sinica_fd=nltk.FreqDist(sinica_treebank.words()) >>> ...
- Tesseract训练中文字体识别
注:目前仅说明windows下的情况 前言 网上已经有大量的tesseract的识别教程,但是主要有两个缺点: 大多数比较老,有部分内容已经不适用. 大部分只是就英文的训练进行探索,很少针对中文的训练 ...
- LUSE: 无监督数据预训练短文本编码模型
LUSE: 无监督数据预训练短文本编码模型 1 前言 本博文本应写之前立的Flag:基于加密技术编译一个自己的Python解释器,经过半个多月尝试已经成功,但考虑到安全性问题就不公开了,有兴趣的朋友私 ...
- 斯坦福NLP课程 | 第12讲 - NLP子词模型
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- 命令行启动kate||cmd启动kate|| 一行命令用kate编辑文件
命令行启动kate||cmd启动kate|| 一行命令用kate编辑文件 先看: 在得知可以在命令行中输入code以启用vscode编辑器后 例 code D:\dLevel\Lenovo\Deskt ...
- Web 开发的常规流程
Web 开发的常规流程 What is the Web? 简单地说,网络是一个遍布全球的网络,它连接大量设备并允许它们相互通信 Internet 上的网站托管在称为服务器的设备上,当您与 Intern ...
- Django笔记九之model查询filter、exclude、annotate、order_by
在接下来四五篇笔记中,将介绍 model 查询方法的各个细节,为我们的查询操作提供各种便利. 本篇笔记将介绍惰性查找.filter.exclude.annotate等方法,目录如下: 惰性查找 fil ...
- SpringBoot的EnableCaching简述
Spring Boot中的EnableCaching简述 spring boot中自带有数据缓存机制,主要通过其org.springframework.cache包下的各种类来实现. EnableCa ...
- [原创][luogu]P1217 回文质数 真·生成回文的方法
不多说,直接看代码,都在注释里 // 中心思想: // * 1. 代入数据只想回文的一半和位数的变化 // * 例. 1001 和 101 都存的是10, 但是位数一个是4, 一个是3 // * 2. ...
- 学习docker看此文足以
什么是 Docker Docker 最初是 dotCloud 公司创始人 在法国期间发起的一个公司内部项目,它是基于 dotCloud 公司多年云服务技术的一次革新,并于 ,主要项目代码在 上进行 ...
- [Java SE]Unicode解码
文由 将ASCII等其他非Unicode字符与Unicode混合的"脏的.不规范的"编码文本转为正常文本. 源码 unicodetoString(String unicodeTex ...
- Nvidia Tensor Core-WMMA API编程入门
1 WMMA (Warp-level Matrix Multiply Accumulate) API 对于计算能力在7.0及以上的CUDA设备,可以使用CUDA C++ API调用Tensor Cor ...
- node使用react项目启动错误TSError: ⨯ Unable to compile TypeScript:
1.错误内容 return new TSError(diagnosticText, diagnosticCodes) ^ TSError: ⨯ Unable to compile TypeScript ...
- 揭开神秘面纱,会stream流就会大数据
目录 准备工作 1.map类 1.1 java stream map 1.2 spark map 1.2.1 MapFunction 1.2.2 MapPartitionsFunction 2.fla ...