借助Numpy,优化Pandas的条件检索代码
Numpy其实是最早的处理数据的Python库,它的核心ndarray对象,是一个高效的n维数组结构。
通过这个库,可以高效的完成向量和矩阵运算,由于其出色的性能,很多其他的数据分析,科学计算或者机器学习相关的Python库都或多或少的依赖于它。
Pandas就是其中之一,Pandas充分利用了NumPy的数组运算功能,使得数据处理和分析更加高效。
比如,Pandas中最重要的两个数据结构Series和DataFrame在内部就使用了NumPy的ndarray来存储数据。
在使用Pandas进行数据分析的过程中,按条件检索和过滤数据是最频繁的操作。
本文介绍两种通过结合Numpy,一方面让Pandas的检索过滤代码更加简洁易懂,另一方面还能保障检索过滤的高性能。
1. 准备数据
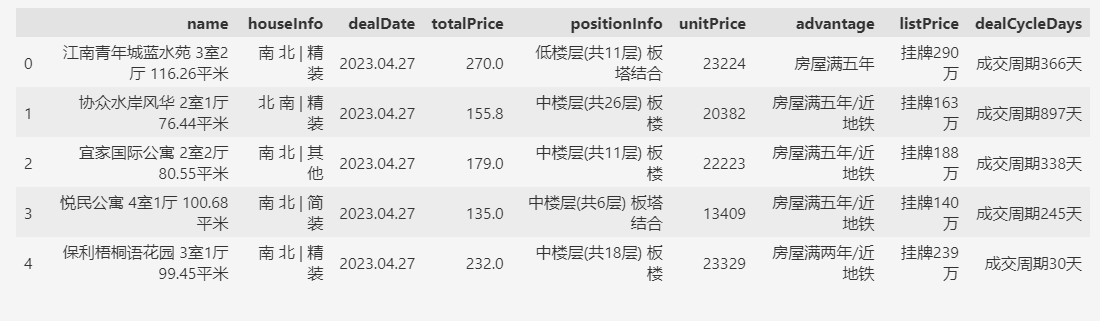
第一步,先准备数据,这次使用二手房交易数据,可从 https://databook.top/lianjia/nj 下载。
import pandas as pd
import numpy as np
# 这个路径替换成自己的路径
fp = r'D:\data\南京二手房交易\南京江宁区.csv'
df = pd.read_csv(fp)
df.head()
2. 一般条件判断(np.where)
比如,买房前我们想先分析下已有的成交信息,对于房价能有个大致的印象。
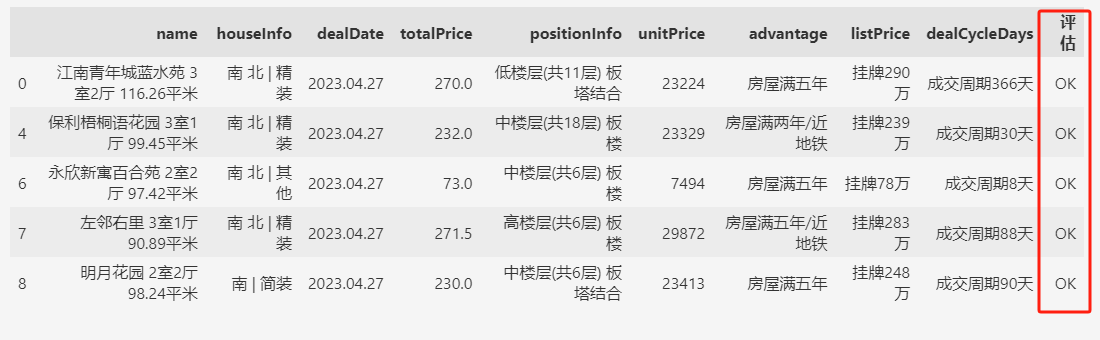
下面,按照总价和单价,先挑选总价200~300万之间,或者单价1万以下的成交信息。
符合条件返回“OK”,否则返回“NG”。
def filter_data(row):
if row["totalPrice"] > 200 and row["totalPrice"] < 300:
return "OK"
if row["unitPrice"] < 10000:
return "OK"
return "NG"
df["评估"] = df.apply(filter_data, axis=1)
df[df["评估"] == "OK"].head()
上面的过滤数据写法是使用Pandas时用的比较多的方式,也就是将过滤条件封装到一个自定义函数(filter_data)中,然后通过 apply 函数来完成数据过滤。
下面我们用Numpy的 np.where 接口来改造上面的代码。np.where类似Python编程语言中的if-else判断,基本语法:
import numpy as np
np.where(condition[, x, y])
其中:
- condition:条件表达式,返回布尔数组。
- x 和 y:可选参数,
condition为True,返回x,反之,返回y。
如果未提供x 和 y,则函数仅返回满足条件的元素的索引。
改造后的代码如下:
# 根据单价过滤
cond_unit_price = np.where(
df["unitPrice"] < 10000,
"OK",
"NG",
)
# 先根据总价过滤,不满足条件再用单价过滤
cond_total_price = np.where(
(df["totalPrice"] > 200) & (df["totalPrice"] < 300),
"OK",
cond_unit_price,
)
df["评估"] = cond_total_price
df[df["评估"] == "OK"].head()
运行之后返回的结果是一样的,但是性能提升很多。
如果数据量是几十万量级的话,你会发现改造之后的代码运行效率提高了几百倍。
3. 复杂多条件判断(np.select)
上面的示例中,判断还比较简单,属于if-else,也就是是与否的判断。
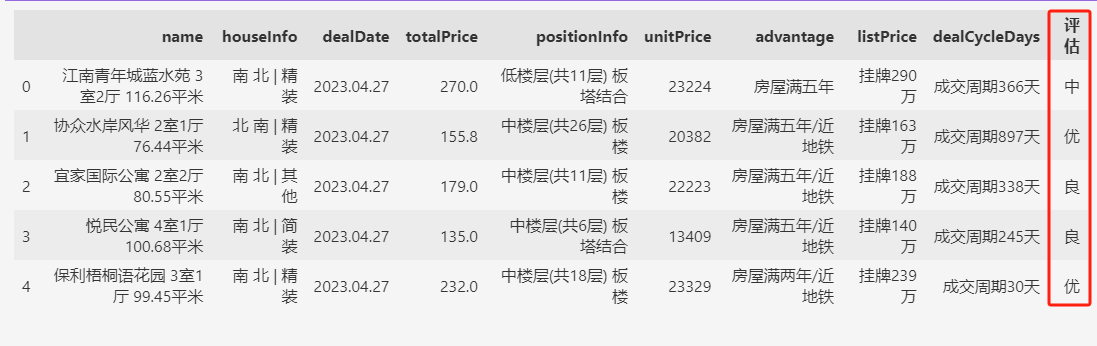
下面设计一种更复杂的判断,将成交信息评估为“优良中差”4个等级,而不仅仅是“OK”和“NG”。
我们假设:
- 优:房屋精装,且位于中楼层,且近地铁
- 良:总价<300,且近地铁
- 中:总价<400
- 差:其他情况
用传统的方式,同样是封装一个类似filter_data的函数来判断“优良中差”4个等级,然后用 apply 函数来完成数据过滤。
这里就不演示了,直接看结合Numpy的np.select接口,高效的完成“优良中差”4个等级的过滤。
np.select类似Python编程语言中的match匹配,基本语法:
numpy.select(condlist, choicelist, default=0)
其中:
- condlist:条件列表,每个条件都是一个布尔数组。
- choicelist:与 condlist 对应的数组列表,当某个条件为真时,返回该位置对应的数组中的元素。
- default:可选参数,当没有条件为真时返回的默认值。
# 设置 “优,良,中” 的判断条件
conditions = [
df["houseInfo"].str.contains("精装")
& df["positionInfo"].str.contains("中楼层")
& df["advantage"].str.contains("近地铁"),
(df["totalPrice"] < 300) & df["advantage"].str.contains("近地铁"),
df["totalPrice"] < 400,
]
choices = ["优", "良", "中"]
# 默认为 “差”
df["评估"] = np.select(conditions, choices, default="差")
df.head()
这样,就实现了一个对成交信息的分类。
4. 总结
np.where 和 np.select的底层都是向量化的方式来操作数据,执行效率非常高。
所以,我们在使用Pandas分析数据时,应尽量使用np.where 和 np.select来帮助我们过滤数据,这样不仅能够让代码更加简洁专业,而且能够极大的提高分析性能。
借助Numpy,优化Pandas的条件检索代码的更多相关文章
- numpy、pandas
numpy: 仨属性:ndim-维度个数:shape-维度大小:dtype-数据类型. numpy和pandas各def的axis缺省为0,作用于列,除DataFrame的.sort_index()和 ...
- NumPy和Pandas常用库
NumPy和Pandas常用库 1.NumPy NumPy是高性能科学计算和数据分析的基础包.部分功能如下: ndarray, 具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组. 用于对整组数 ...
- python安装numpy和pandas
最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,不过使用python安装numpy和pandas因为linux环境没有外网遇到了很多问题就记下来了.首要条件,python版本必须 ...
- 如何快速地从mongo中提取数据到numpy以及pandas中去
mongo数据通常过于庞大,很难一下子放进内存里进行分析,如果直接在python里使用字典来存贮每一个文档,使用list来存储数据的话,将很快是内存沾满.型号拥有numpy和pandas import ...
- [转] python安装numpy和pandas
最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,不过使用python安装numpy和pandas因为linux环境没有外网遇到了很多问题就记下来了.首要条件,python版本必须 ...
- Python 工匠:编写条件分支代码的技巧
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 作者:朱雷 | 腾讯IEG高级工程师 『Python 工匠』是什么? 我一直觉得编程某种意义是一门『手艺』 ...
- numpy和pandas简单使用
numpy和pandas简单使用 import numpy as np import pandas as pd 一维数据分析 numpy中使用array, pandas中使用series numpy一 ...
- Python入门之安装numpy和pandas
最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,不过使用python安装numpy和pandas因为linux环境没有外网遇到了很多问题就记下来了. 首要条件,python版本必 ...
- asp.net用三层实现多条件检索
众所周知,三层将项目分为界面层,业务逻辑层和数据訪问层(以最主要的三层为例) 相同都知道,多条件检索事实上就是依据用户选择的条件项,然后来拼sql语句 那么.既然要依据用户选择的条件项来拼sql语句, ...
- 【转载】python安装numpy和pandas
转载:原文地址 http://www.cnblogs.com/lxmhhy/p/6029465.html 最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,不过使用python安装 ...
随机推荐
- gif 制作
gif 制作 博文中使用 gif 有时比纯粹的图片更明了.比如展示"墨刀"中的动画效果: 录制视频 首先利用录制视频,例如使用在线录制工具 vizard. Tip:需要花费2分钟手 ...
- ultraISO方式制作win10安装U盘
说明 最近帮朋友安装下win10,用了2种制作U盘启动盘的方式.记录一下也方便大家少走弯路. 准备的工具: 1.utralISO(软通牒) 2.win10镜像 3.16GB U盘,U盘容量 > ...
- Java I/O 教程(十 一) BufferedWriter和BufferedReader
Java BufferedWriter 类 Java BufferedWriter class 继承了Writer类,为Writer实例提供缓冲. 提升了写字符和字符串性能. 类定义: public ...
- Maven如何打包可执行jar包
假设我有一个maven项目叫:hello-world 新建一个HelloWorld类: package com.dylan.mvnbook.helloworld; public class Hello ...
- C++ 多线程的错误和如何避免(4)
对共享的资源或者数据做加锁处理 在多线程的环境下,有时需要多个线程对同一个资源或者数据进行操作,如果没有加锁,容易出现未定义的行为. 比如: #include <iostream> #in ...
- 突破Windows的极限
偶然碰到这类技术博客,甚感欣慰,但奈何技术水平达不到,很多都难以理解,故记录在此,用作日后学习. 国内有类似的中文翻译,比如:突破Windows极限:物理内存 但是外文链接已经失效,看不到原汁原味的英 ...
- ubuntu18.04下安装MySQL5.7
更新源 sudo apt update 安装mysql sudo apt install mysql-server 使用sudo mysql进入数据设置root账户的密码和权限 sudo mysql ...
- 基于java的学生信息管理系统
开发说明:使用数组集合存储临时数据,实现学生信息管理系统,实现的功能有管理员的注册.登陆.增加学生信息.删除学生信息.查询学生信息.修改学生信息.学生信息列表 登陆注册界面 系统首页界面 增加 删除 ...
- JVM-对象实例化
JVM-对象实例化 1.创建对象的方式 new:最常见的方式.Xxx的静态方法,XxxBuilder/XxxFactory的静态方法 Class的newInstance方法:反射的方式,只能调用空参的 ...
- iOS的Runtime知识点繁杂难啃,真的理解它的思想,你就豁然开朗了
一.Runtime 1.概念: 概念:Runtime是Objective-c语言动态的核心,即运行时.在面向对象的基础上增加了动态运行,达到很多在编译时确定方法推迟到了运行时,从而达到动态修改.确定. ...