最大堆(MaxHeap)
性质
- 二叉堆是一颗完全二叉树,而完全二叉树是把元素排列成树的形状。
- 堆中某个节点的值总不大于其父节点的值最大堆(相应的可以定于最小堆)
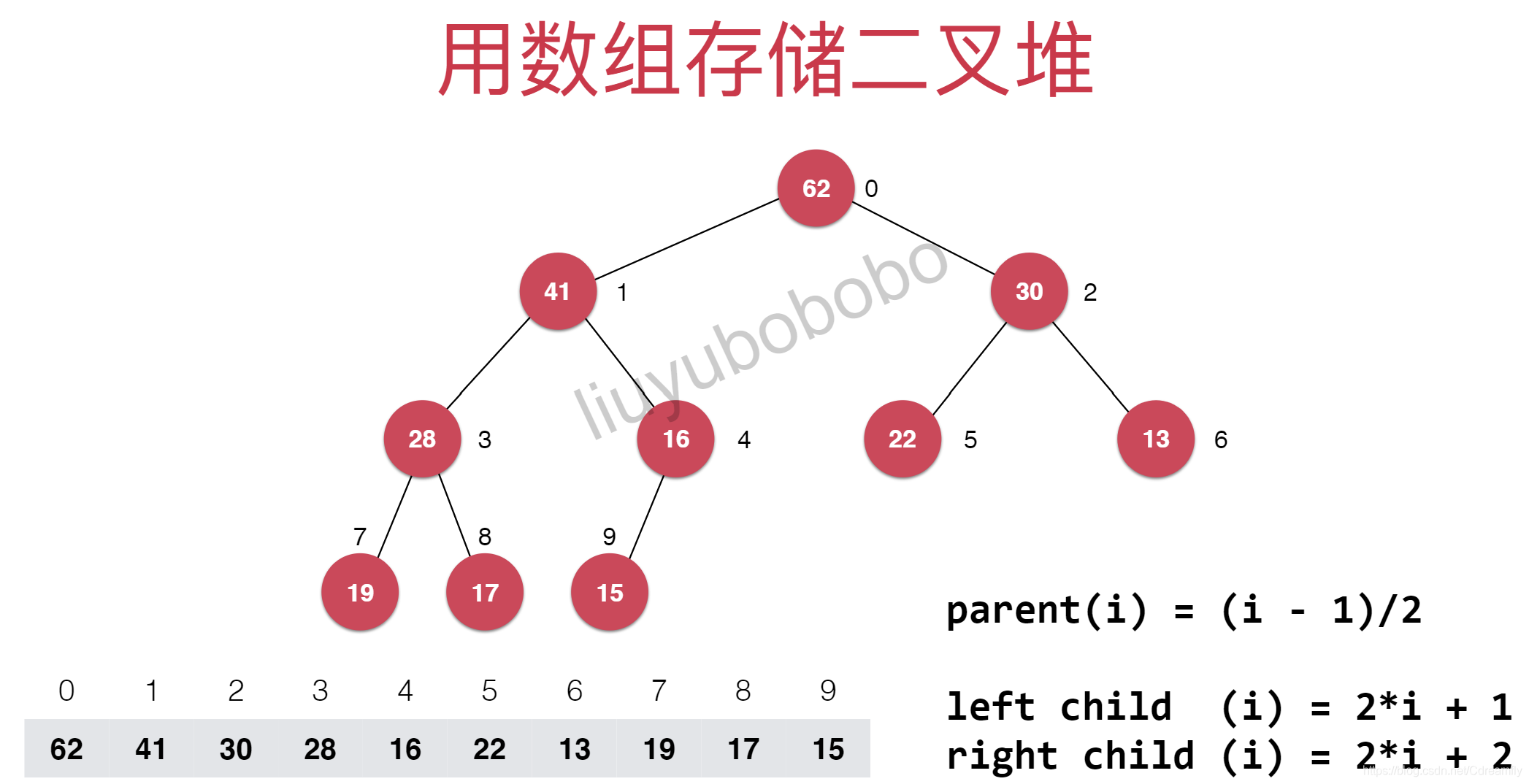
// 返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引
constexpr int parent(const int index) const {
if (index == 0) {
throw new NoParent();
}
return (index - 1) / 2;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引
constexpr int leftChild(const int index) const {
return (index * 2) + 1;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引
constexpr int rightChild(const int index) const {
return (index * 2) + 2;
}
可以先阅读底层动态数组Array
添加
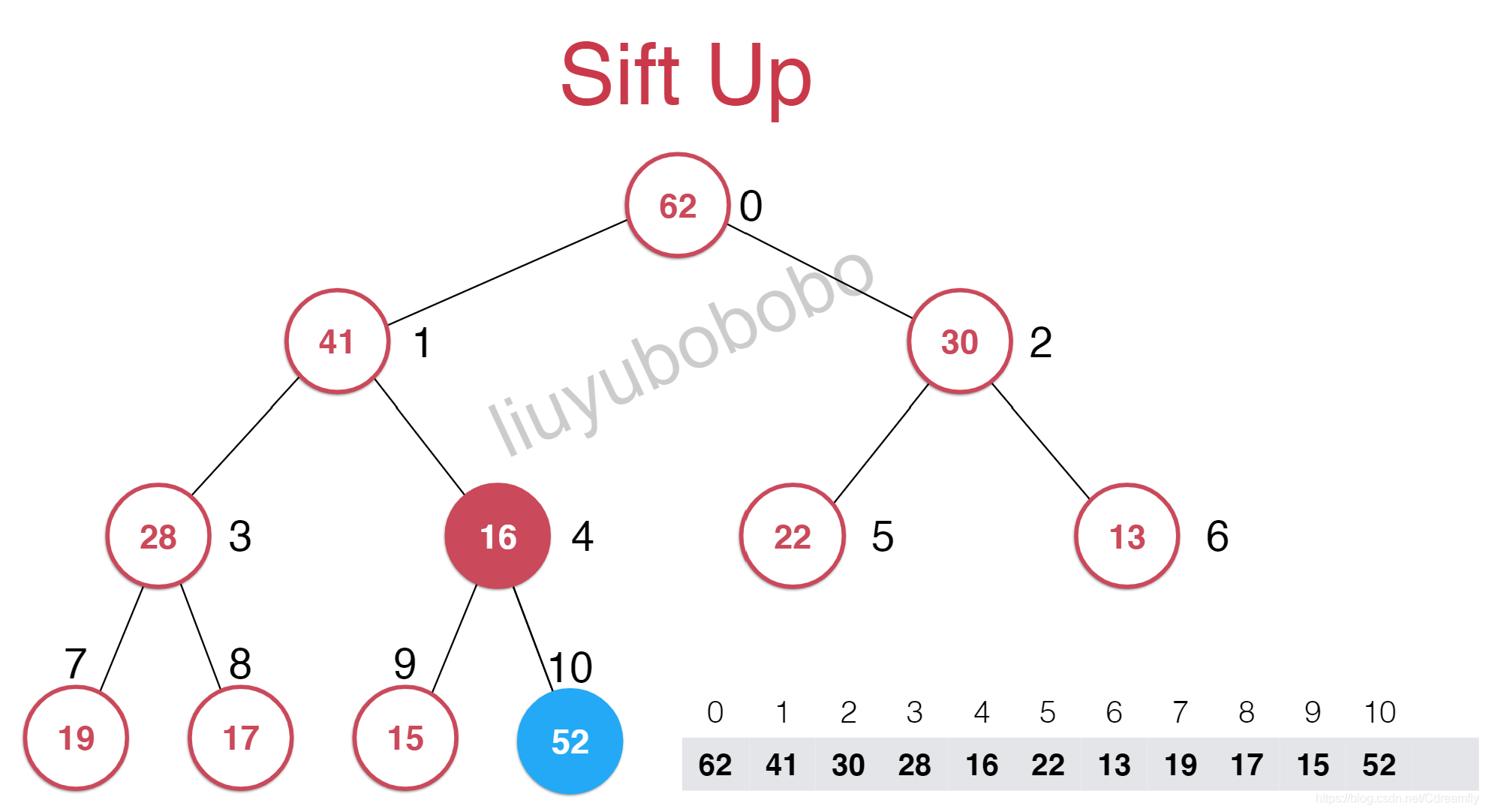
首先我们堆中的数据使用数组排列的,所以添加一个元素就是在层序遍历的最右端,也就是最下面一层的最后添加一个元素。但是以数组来看就是在索引为10的地方添加一个元素。
void add(const T &e) {
data->addLast(e); //在数组的末尾添加元素
shiftUp(data->getSize() - 1); //上浮添加元素的索引
}
- 时间复杂度O(logn)
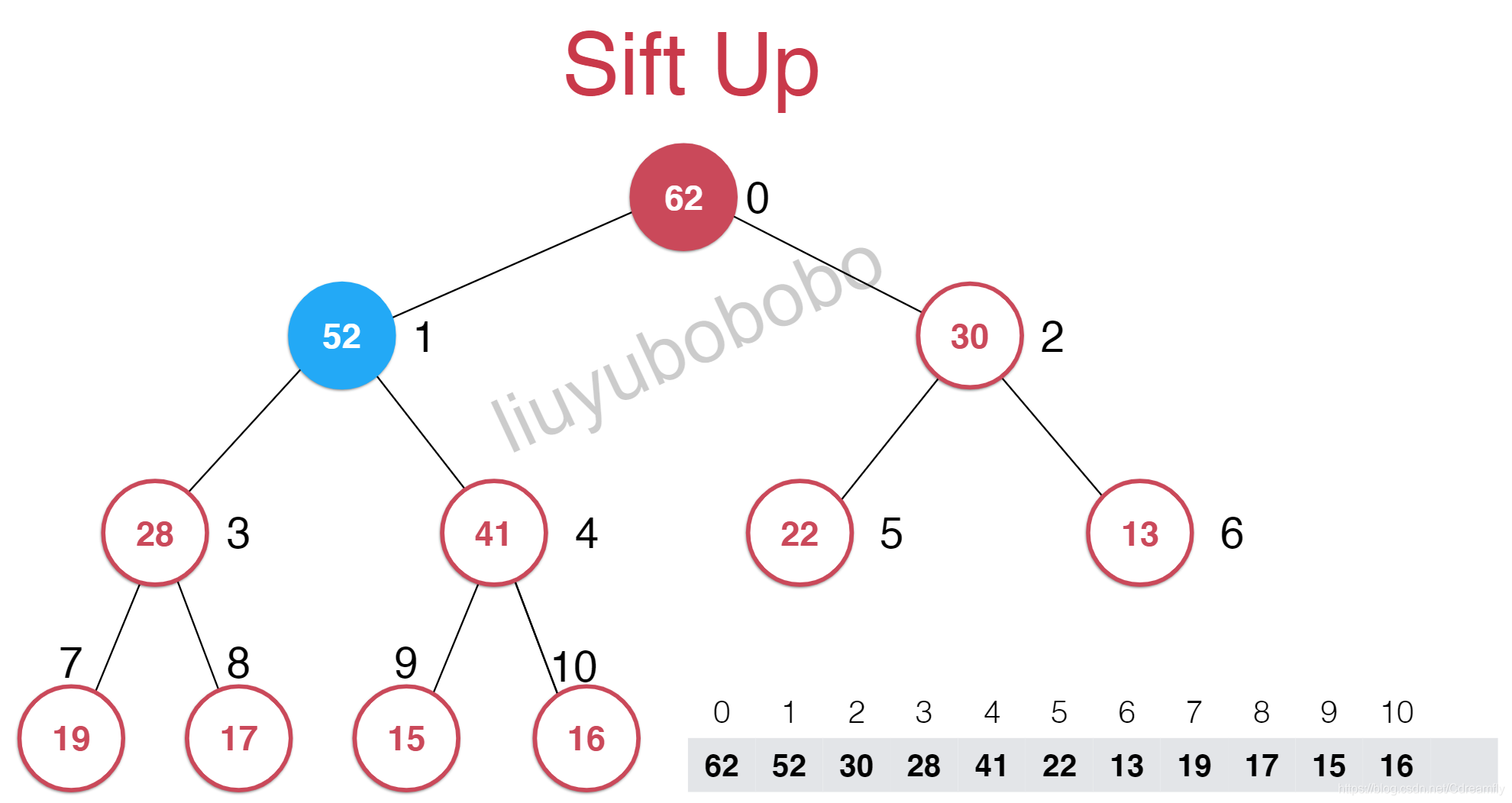
但是添加的元素不符最大堆的性质,索引我需要一些调整,而这个调整就是一个上浮的过程。
void shiftUp(int index) {
//如果传入索引小于等于0并且父元素大于等于子元素则停止循环
while (index > 0 && data->get(index) > data->get(parent(index))) {
data->swap(index, parent(index)); //位置交换
index = parent(index); //把父节点的索引给子节的
}
}
取出最大元素
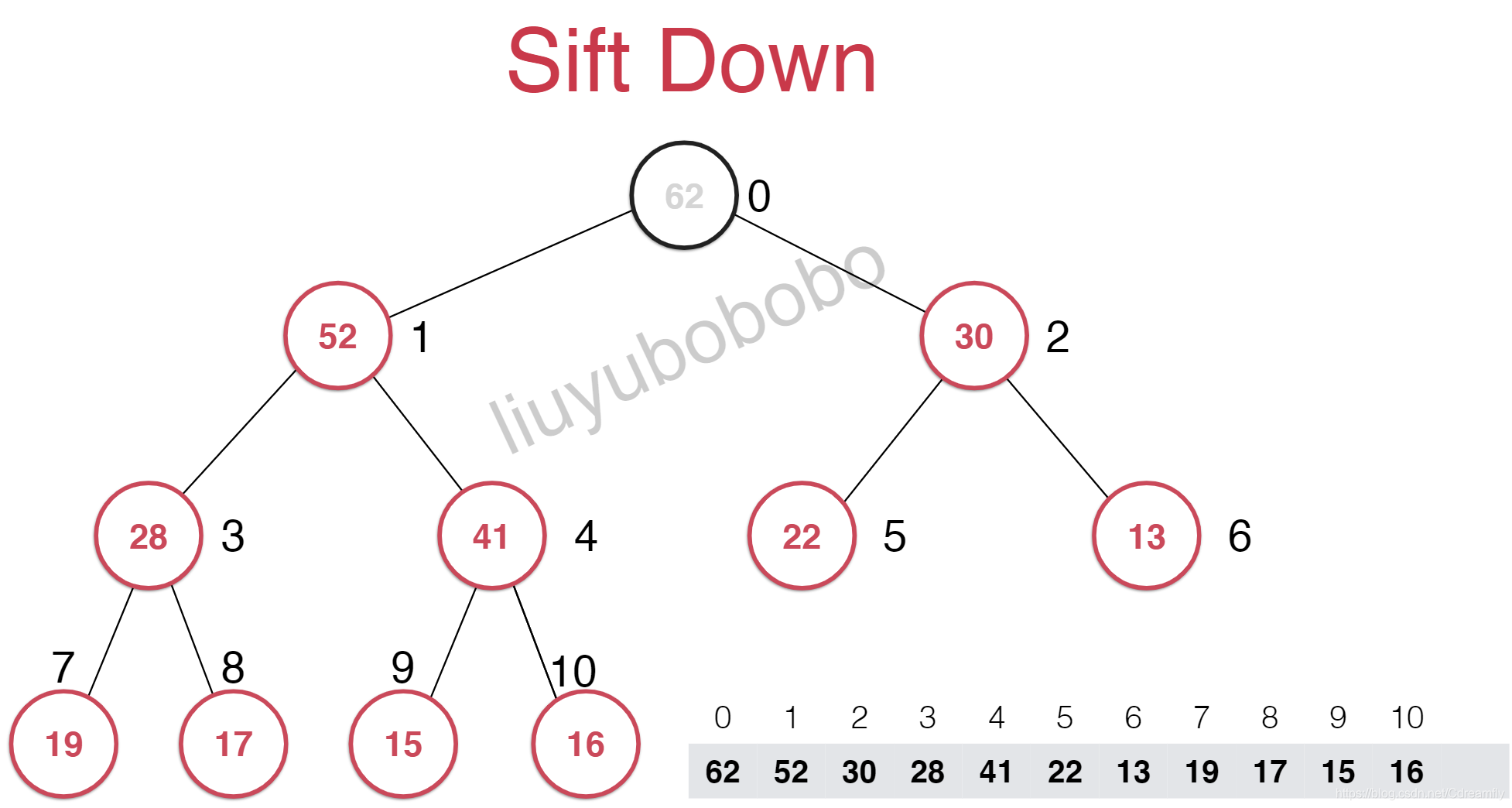
最大堆的最大元素就是其根节点元素,取出的操作只能取出这个元素,对于数组来说,根结点就是索引为0的元素。
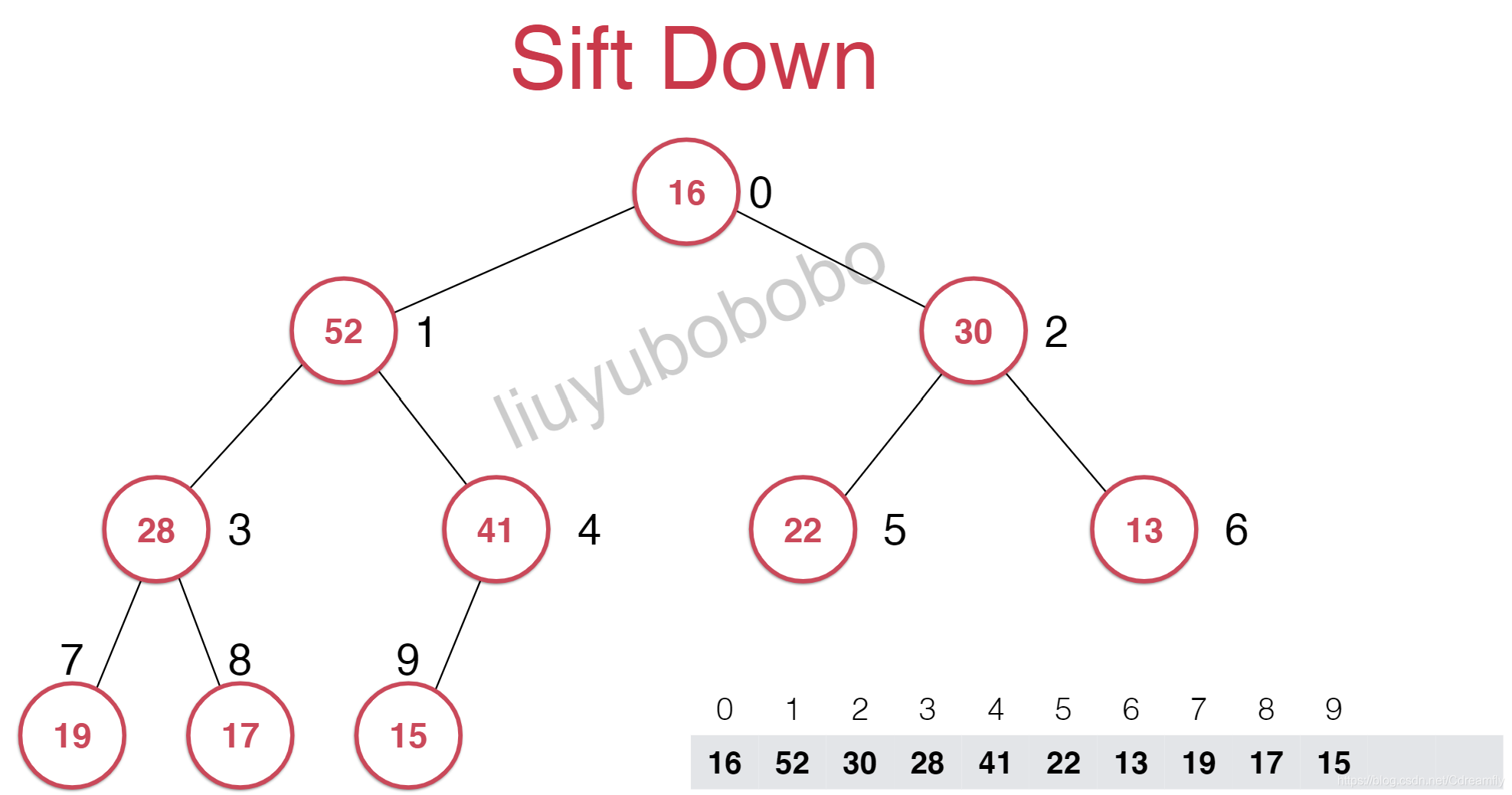
我们把堆中最后一个元素顶到堆顶去,然后再把最后一个元素删除。然而这样就又不符合最大堆的性质。
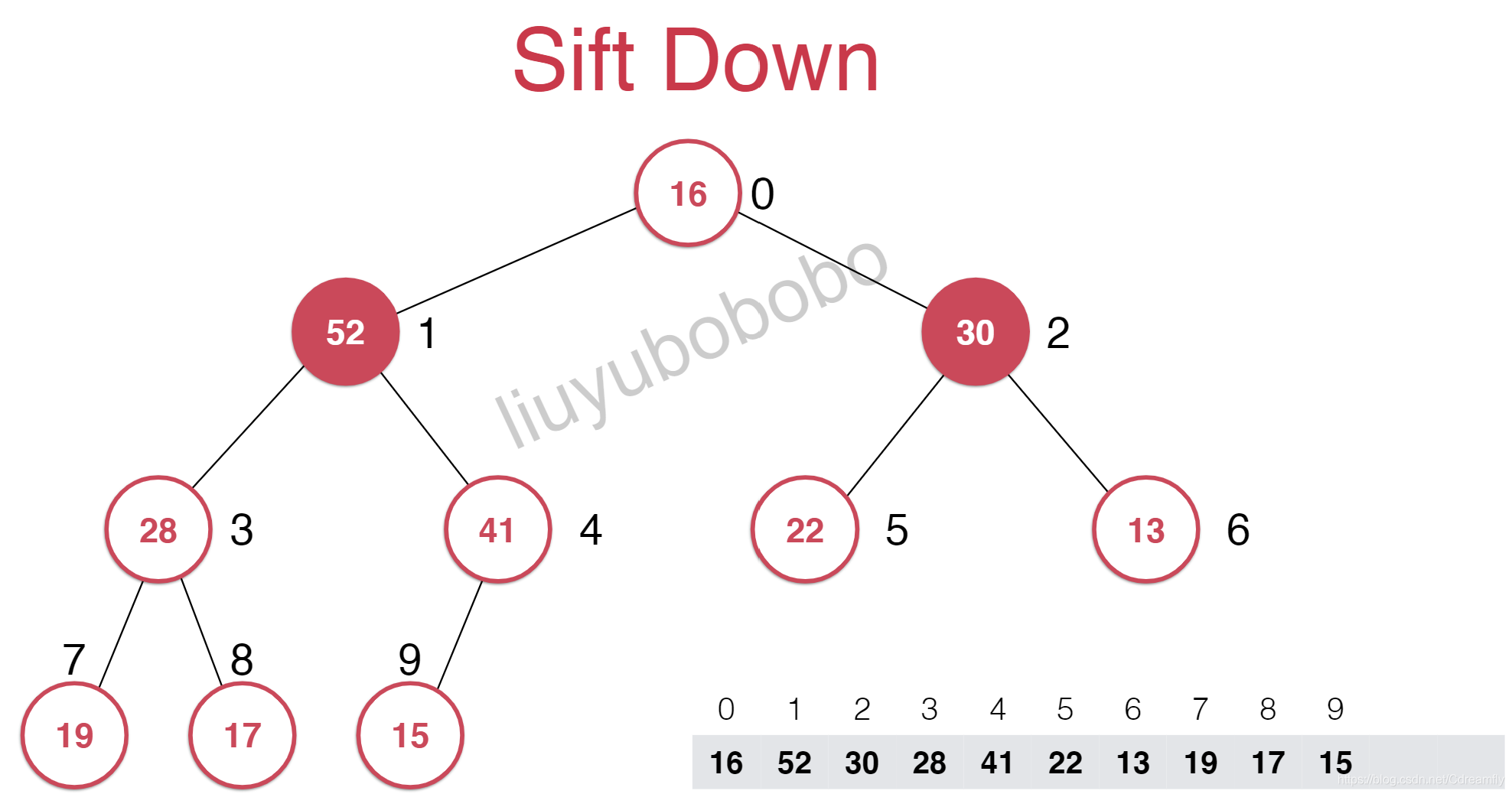
这样的话,其不大于它的子节点,此时又要进行调整,这个调整的过程叫做下沉。在这个过程中每次需要下沉的时候都要和它的两个孩子进行比较,选择其中较大的进行交换位置。
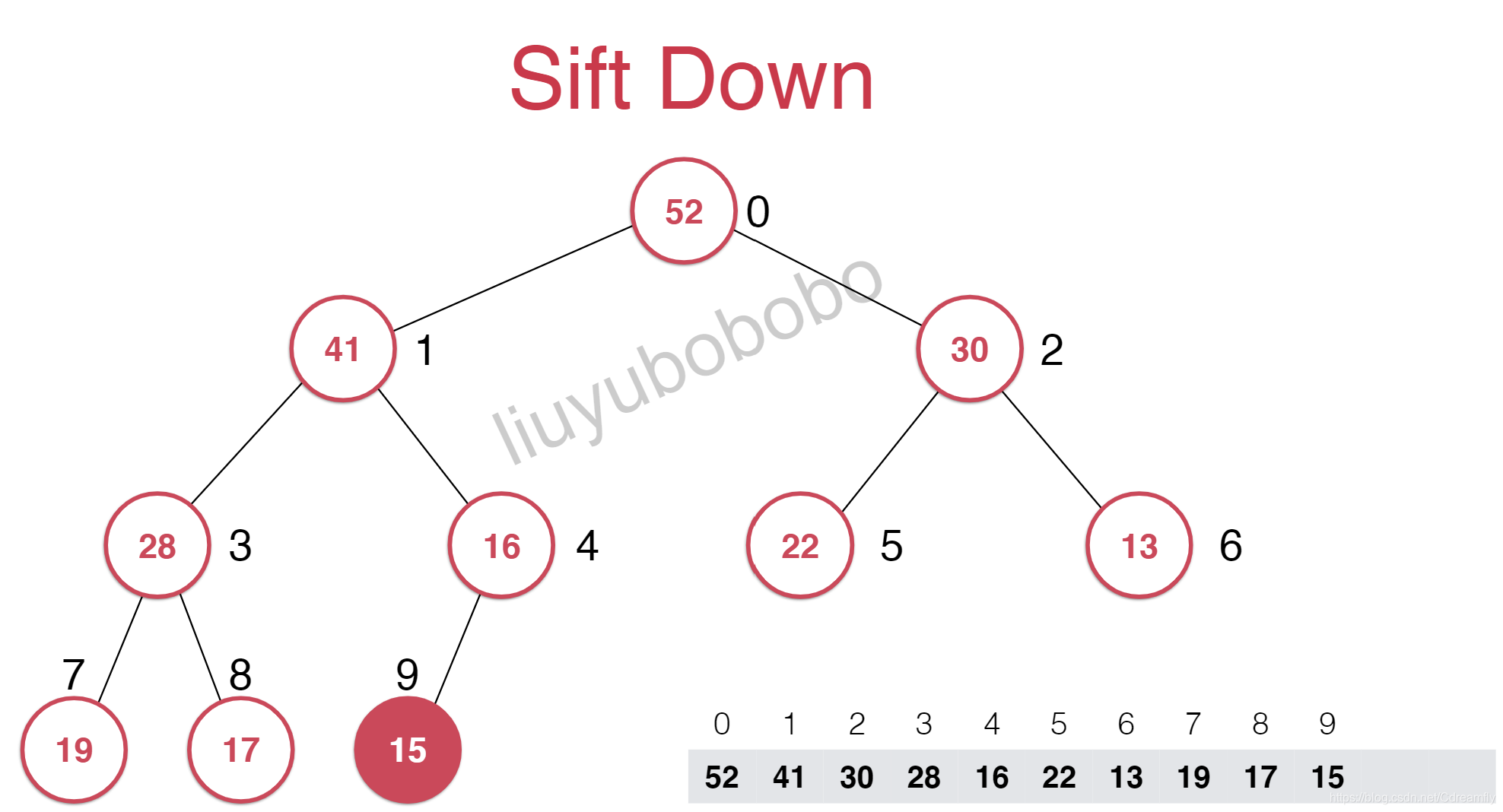
- 时间复杂度O(logn)
//返回最大的元素
T findMax() const {
if (data->isEmpty()) {
throw Empty();
}
return data->get(0);
}
//取出最大的元素
T extractMax() {
T ret = findMax();
data->swap(0, data->getSize() - 1);
data->removeLast();
shiftDown(0);
return ret;
}
//下沉
void shiftDown(int k) {
while (leftChild(k) < data->getSize()) {
int j = leftChild(k);
//j保存的是左右孩子中较大的元素索引
if (j + 1 < data->getSize() && data->get(j + 1) > data->get(j)) {
j = rightChild(k);
}
//如果子节点小于等于父节点了,就结束
if (data->get(k) > data->get(j)) {
break;
}
data->swap(k, j);
k = j;
}
}
取出堆中最大的元素,并替换成元素e
- 时间复杂度O(logn)
T replace(T e) {
T ret = findMax();
data->set(0, e);
shiftDown(0);
return ret;
}
Heapify
将n个元素逐个插入到一个空堆中,算法复杂度是O(nlogn),Heapify的过程,算法复杂度是O(n)。
MaxHeap(T arr[], const int n) {
data = new Array<T>(arr, n);
for (int i = parent(n - 1); i >= 0; --i) {
shiftDown(i);
}
}
对比使用与不适用Heapify代码
#include <iostream>
#include "MaxHeap.h"
#include <cassert>
template<typename T>
double testHeap(T testData[], int n, bool isHeapify) {
clock_t startTime = clock();
MaxHeap<T> *maxHeap;
if (isHeapify) {
maxHeap = new MaxHeap<T>(testData, n);
} else {
maxHeap = new MaxHeap<T>();
for (int i = 0; i < n; ++i) {
maxHeap->add(testData[i]);
}
}
T *arr = new T[n];
for (int j = 0; j < n; ++j) {
arr[j] = maxHeap->extractMax();
}
for (int k = 1; k < n; ++k) {
assert(arr[k - 1] >= arr[k]);
}
std::cout << "Test MaxHeap completed." << std::endl;
clock_t endTime = clock();
return double(endTime - startTime) / CLOCKS_PER_SEC;
}
int main() {
int n = 5000000;
int *testData = new int[n];
for (int i = 0; i < n; ++i) {
testData[i] = rand() % INT32_MAX;
}
double time1 = testHeap(testData, n, false);
std::cout << "Without heapify :" << time1 << " s " << std::endl;
double time2 = testHeap(testData, n, true);
std::cout << "With heapify :" << time2 << " s " << std::endl;
return 0;
}
代码清单
//
// Created by cheng on 2021/7/10.
//
#ifndef MAXHEAP_MAXHEAP_H
#define MAXHEAP_MAXHEAP_H
#include "Array.h"
template<typename T>
class MaxHeap {
public:
class NoParent {
};
class Empty {
};
MaxHeap() {
data = new Array<T>();
}
~MaxHeap() {
delete data;
data = nullptr;
}
MaxHeap(const int capacity) {
data = new Array<T>(capacity);
}
MaxHeap(T arr[], const int n) {
data = new Array<T>(arr, n);
for (int i = parent(n - 1); i >= 0; --i) {
shiftDown(i);
}
}
constexpr int getSize() const {
return data->getSize();
}
constexpr bool isEmpty() const {
return data->isEmpty();
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引
constexpr int parent(const int index) const {
if (index == 0) {
throw new NoParent();
}
return (index - 1) / 2;
}
void add(const T &e) {
data->addLast(e);
shiftUp(data->getSize() - 1);
}
//返回最大元素
T findMax() const {
if (data->isEmpty()) {
throw Empty();
}
return data->get(0);
}
//取出最大的元素
T extractMax() {
T ret = findMax();
data->swap(0, data->getSize() - 1);
data->removeLast();
shiftDown(0);
return ret;
}
//取出堆中最大的元素,并替换成元素e
T replace(T e) {
T ret = findMax();
data->set(0, e);
shiftDown(0);
return ret;
}
void print() {
data->print();
}
private:
void shiftDown(int k) {
while (leftChild(k) < data->getSize()) {
int j = leftChild(k);
if (j + 1 < data->getSize() && data->get(j + 1) > data->get(j)) {
j = rightChild(k);
}
if (data->get(k) > data->get(j)) {
break;
}
data->swap(k, j);
k = j;
}
}
void shiftUp(int index) {
while (index > 0 && data->get(index) > data->get(parent(index))) {
data->swap(index, parent(index));
index = parent(index);
}
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引
constexpr int leftChild(const int index) const {
return (index * 2) + 1;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引
constexpr int rightChild(const int index) const {
return (index * 2) + 2;
}
private:
Array<T> *data;
};
#endif //MAXHEAP_MAXHEAP_H
最大堆(MaxHeap)的更多相关文章
- java——最大堆 MaxHeap
使用数组来实现最大堆 堆是平衡二叉树 import Date_pacage.Array; public class MaxHeap<E extends Comparable <E>& ...
- 数据结构-详解优先队列的二叉堆(最大堆)原理、实现和应用-C和Python
一.堆的基础 1.1 优先队列和堆 优先队列(Priority Queue):特殊的"队列",取出元素顺序是按元素优先权(关键字)大小,而非元素进入队列的先后顺序. 若采用数组或链 ...
- MyCat源码分析系列之——结果合并
更多MyCat源码分析,请戳MyCat源码分析系列 结果合并 在SQL下发流程和前后端验证流程中介绍过,通过用户验证的后端连接绑定的NIOHandler是MySQLConnectionHandler实 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 面试题目——《CC150》高等难题
面试题18.1:编写一个函数,将两个数字相加.不得使用+或其他算数运算符. package cc150.high; public class Add { public static void main ...
- 二叉堆(二)之 C++的实现
概要 上一章介绍了堆和二叉堆的基本概念,并通过C语言实现了二叉堆.本章是二叉堆的C++实现. 目录1. 二叉堆的介绍2. 二叉堆的图文解析3. 二叉堆的C++实现(完整源码)4. 二叉堆的C++测试程 ...
- 二叉堆(三)之 Java的实现
概要 前面分别通过C和C++实现了二叉堆,本章给出二叉堆的Java版本.还是那句话,它们的原理一样,择其一了解即可. 目录1. 二叉堆的介绍2. 二叉堆的图文解析3. 二叉堆的Java实现(完整源码) ...
- 3.Python3标准库--数据结构
(一)enum:枚举类型 import enum ''' enum模块定义了一个提供迭代和比较功能的枚举类型.可以用这个为值创建明确定义的符号,而不是使用字面量整数或字符串 ''' 1.创建枚举 im ...
- pat04-树9. Path in a Heap (25)
04-树9. Path in a Heap (25) 时间限制 150 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue Insert ...
- 萌新笔记之堆(heap)
前言(萌新感想): 以前用STL的queue啊stack啊priority_queue啊,一直很想懂原理,现在终于课上到了priority_queue,还有就是下周期中考,哈哈,所以写几篇blog总结 ...
随机推荐
- 《系列二》-- 2、bean 的作用域: Scope 有哪些
目录 作用域 Scope 特性概述 常规作用域 web 场景作用域 经典问题 模拟场景 解决办法 方法一 方法二 实现接口 BeanFactoryAware 阅读之前要注意的东西:本文就是主打流水账式 ...
- 【LeetCode二叉树#18】修剪二叉搜索树(涉及重构二叉树与递归回溯)
修剪二叉搜索树 力扣题目链接(opens new window) 给定一个二叉搜索树,同时给定最小边界L 和最大边界 R.通过修剪二叉搜索树,使得所有节点的值在[L, R]中 (R>=L) .你 ...
- 在ABP的模块解决方案中使用BootstrapBlazor
1.为Study.Trade.Blazor.Server.Host引入两个包 成功后效果如下: 2.修改Study.Trade.Blazor.Server.Host的Pages目录下的_Host.cs ...
- 无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14B
目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被"玩"坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt)来操纵L ...
- 【Azure 存储服务】多设备并发往 Azure Storage Blob 的 Container 存数据是否可以
问题描述 多设备并发往 Azure Storage Blob 的 Container 存数据是否可以? 问题解答 可以! Azure Storage 是支持的并发存储数据的,Blob 可以使用乐观并发 ...
- 【Azure 应用服务】如何查看App Service中的私网IP地址?
问题描述 在使用App Service服务时,可以通过Azure 门户中的属性功能查看出站IP列表. 如果把App Service与虚拟网络(VNET)集成后,它就可以直接访问虚拟网络内部资源,那么如 ...
- Netty笔记(7) - 使用Netty 模仿 Dubbo 实现简单的 远程调用
使用Netty 模仿 Dubbo 实现简单的 远程调用 使用 java的反射 动态代理 加 Netty的远程访问 实现根据接口的RPC 远程调用 定义两个公共接口: public interface ...
- 9、mysql的并发参数调整
从实现上来说,MySQL Server 是多线程结构,包括后台线程和客户服务线程.多线程可以有效利用服务器资源,提高数据库的并发性能.在Mysql中,控制并发连接和线程的主要参数包括 max_conn ...
- 1. zookeeper简介与应用场景
1.1 zookeeper介绍 zookeeper是一个高可用的分布式管理与协调框架,基于ZAB算法(原子消息广播协议)的实现. 能够很好保证分布式环境中数据的一致性.正是基于这样的特性,使得zo ...
- Spring与微服务
Spring与微服务 微服务论文 Melvyn Conway 的意识是,像下图所展示的,设计一个系统时,将人员划分为 UI 团队,中间件团队,DBA 团队,那么相应地,软件系统也就会自然地被划分为 U ...