回文自动机(PAM) 详解
PAM 是一种高效存储字符串中所有回文子串的自动机,用于解决回文串相关问题。
虽然代码稍微长一点,但写起来比 manacher 容易很多,毕竟没有加了一堆字符再转回原串的若干上取整下取整问题。
前置知识
无。或许需要一些自动机相关的理论基础。
结构 & 定义
状态
我们用 PAM 上的一个节点来表示一个回文子串,作为 PAM 的一个状态。但回文串分奇偶两种,像 manacher 一样在每两个字符之间加分隔符是很麻烦的。因此,我们把 PAM 的状态分成两个部分,一部分存奇回文串,另一部分存偶回文串。
同理,我们把根也分为奇根和偶根。它们不表示任何字符串,只作为初始状态而存在。
因为存的是回文串,我们其实只需要对一个串记录其中一半位置的字符是什么,所以定义 PAM 上的一个点到根的路径上的字符串表示它所代表的回文串的其中一半,这一点上 PAM 与以前学过的自动机状态的定义都不同。
换句话说,对于一个点它实际表示的回文串,在 PAM 上的读法是从它开始沿着 PAM 读到根,再原路读回该点形成的字符串。这里注意如果是奇回文串,与根相连的那个字符边只读一次。
令奇根为 \(1\),偶根为 \(0\)。那么对于 \(s=\texttt{"abaabc"}\),建出的 PAM 如下图(省略 Fail 指针):
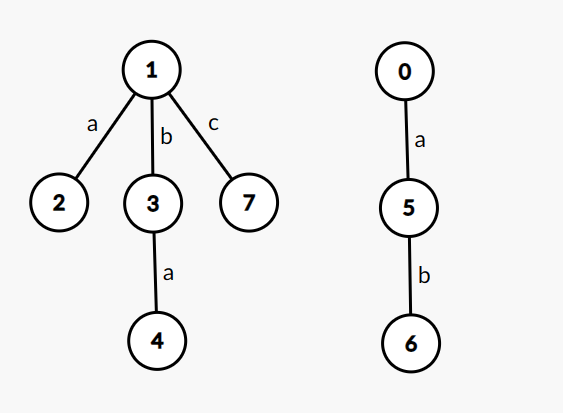
每个点表示的回文串根据上文所述即可读出,例如点 \(7\) 表示 \(\texttt{c}\),点 \(4\) 表示串 \(\texttt{aba}\),点 \(6\) 表示串 \(\texttt{baab}\)。
Fail 指针
在 PAM 中,每个节点同样有一个 Fail 指针。这里 \(\text{Fail}(x)\) 的定义是 \(x\) 表示的回文串的最长回文后缀的状态。(也同时是最长回文前缀,因为 \(x\) 是回文串)
对于初始状态,我们定义偶根的 Fail 指向奇根。而我们并不关心奇根的 Fail,因为任意一个长度为 \(1\) 的字符串都是回文串,奇根不可能失配。
同时,对于每个节点我们记录 \(\text{len}(x)\) 表示它实际代表的回文串长度,用于在下文 PAM 的构造中判断每个点在原串中的位置。那么对于点 \(x\),设它在 PAM 上的父亲是 \(fa(x)\),则有 \(\text{len}(x)=\text{len}(fa(x))+2\)。
为保证奇回文串也满足这个性质,令 \(\text{len}(1)=-1\)。
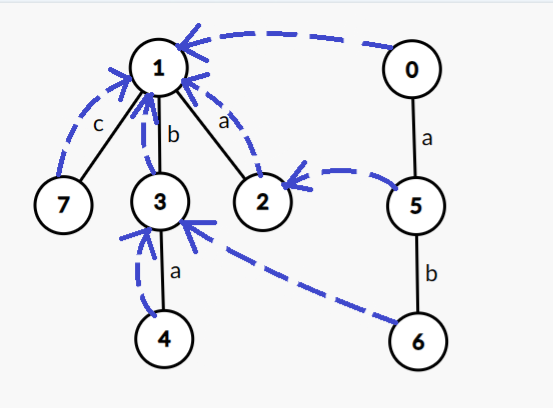
对于之前的例子,建出它的 Fail 指针就是这样的(为了减少交叉,把 \(2\) 和 \(7\) 号点换了位置):
PAM 的构造
PAM 的构造方式是在线的,即每次添加一个字符 \(c\) 时,在原来的 PAM 基础上添加与新增字符相关的状态和转移。
假设对于一个长度为 \(n\) 的字符串 \(s\),我们已经构造完了前 \(n-1\) 个字符,现在要加入第 \(n\) 个字符。设这个字符为 \(c\),前 \(n-1\) 个字符最长回文后缀对应的状态是 \(now\)。
要新增的状态就是以第 \(n\) 个字符结尾,且在以前没有出现过的回文串。考虑到一个回文串前后各去掉一位还是回文串,新增的回文串前后去掉一位,一定是某个以 \(n-1\) 为结尾的回文串。
我们要找的就是以 \(n-1\) 为结尾的回文串中,前一位恰好是 \(c\) 的最长的串。发现上一次构造到的节点 \(now\) 就表示以 \(n-1\) 为结尾的最长回文串,因此我们不断令 \(now\gets \text{Fail}(now)\),直至满足条件。设使条件满足的状态为 \(pos\)。那么以 \(n\) 为结尾的最长回文后缀就是在 \(x\) 前后各加一个 \(c\)。根据 PAM 的定义,这个状态就是 \(pos\) 通过字符 \(c\) 的边连向的儿子。
如果 \(pos\) 没有对应的儿子,代表这个回文串是新增的,我们添加一个新的状态。否则既然已经存在就不用管了。
那么对于这个新的状态,可以证明只有最长的这个回文后缀是新增的。考虑一个比它短的回文后缀,可以在最长的里面对称到一个不包括 \(n\) 的字符串,这一定是以前出现过的状态。

(如果黑的是最长回文后缀,蓝的是次长回文后缀,那显然红的和蓝的相同,也是回文串,在前面出现过。)
那么我们令新点为 \(new\),容易得出 \(fa(new)=pos\),\(\text{len}(new)=\text{len}(pos)+2\)。
只剩下它的 Fail 还没有求了。
发现求 Fail 指针和求最长以 \(n\) 结尾的回文后缀的本质是一样的。这次我们从 \(\text{Fail}(pos)\) 开始跳,找到第一个能在前后各加一个 \(c\) 的回文串即可。
如果到最后都没匹配到,令 \(\text{Fail}(new)=0\) 就好了。
你可能会奇怪为什么不指向奇根呢,这两个都是啥也没有。考虑这样的情况:原来字符串只有一个字符 \(\texttt{a}\),现在变成了 \(\texttt{aa}\)。那么这个新回文串是从偶根同时也是之前的 Fail 转移过来的。如果一开始把 \(a\) 的 Fail 指向奇根就会转移不到这种情况。
看起来构建完了。
实现
结构体定义是平凡的:
struct node{int len,fa,s[26];} d[N];
设函数 getfail(u,i) 表示从状态 \(u\) 开始查找首个前一位与 \(s_i\) 相同的回文后缀状态。
il int getfail(int u,int i)
{
while(i-d[u].len-1<=0||s[i-d[u].len-1]!=s[i]) u=d[u].fa;
return u;
}
具体的构造根据上文也不难写出。
d[0].fa=1,d[1].len=-1;
for(int i=1,now=0;i<=n;i++)
{
int pos=getfail(now,i),c=s[i]-'a';
if(!d[pos].s[c])
{
d[++tot].fa=d[getfail(d[pos].fa,i)].s[c];
d[pos].s[c]=tot,d[tot].len=d[pos].len+2;
}
now=d[pos].s[c];
}
注意一定要先对新点求 Fail,再连新的转移边。
考虑颠倒顺序会出什么问题,上文说过“最后匹配不到,要令 Fail=0”,正常情况下匹配不到,\(pos\) 就没有 \(c\) 的转移边,Fail 确实是 \(0\);而如果先给 \(pos\) 连了新节点的边,最后匹配不到,新节点就会把 \(Fail\) 连到自己,喜提死循环。
看起来也实现完了。
正确性证明
接下来对 PAM 的时空复杂度均为线性给出证明。(因为这个还比较好证,那就写一下。
状态数证明
PAM 的状态数即为字符串本质不同的回文子串个数。
考虑每次新增一个字符,上文已经证明过只有以它结尾的最长回文后缀可能是新增的。也就是说,每次新增字符,本质不同的回文子串数至多增加 \(1\)。
因此任意字符串本质不同回文子串数不多于 \(n\),上界可以在形如 \(s=\texttt{"aaaa}\dots\texttt{aaaa"}\) 的字符串中取到。
时间复杂度证明
看起来除了我们每次匹配都在循环跳 Fail 指针以外,线性复杂度都很显然。
考虑 \(now\) 在 Fail 树上的深度,每次新增一个字符至多使它的深度增加 \(1\)。那么 \(n\) 个字符至多增加了 \(n\) 次,\(now\) 至多跳了 \(2n\) 次 Fail。
而求 Fail 指针时的那个循环也是同理的。因此 PAM 的时间复杂度是线性。
例题
P5496【模板】回文自动机(PAM)
根据 Fail 的定义,发现对于 PAM 上的一个状态,以它结尾的回文后缀个数就是它在 Fail 树上的深度。
那么我们只需要在构建过程中记录每个状态在 Fail 树上的深度即可。
点击查看代码
const int N=5e5+5;
int n,tot=1;
struct node {int len,fa,dep,s[26];}d[N];
char s[N];
il int getfail(int u,int i)
{
while(i-d[u].len-1<=0||s[i-d[u].len-1]!=s[i]) u=d[u].fa;
return u;
}
int main()
{
scanf("%s",s+1); n=strlen(s+1);
d[0].fa=1,d[1].len=-1;
int now=0,lst=0;
for(int i=1;i<=n;i++)
{
s[i]=(s[i]-'a'+lst)%26+'a';
int pos=getfail(now,i); int c=s[i]-'a';
if(!d[pos].s[c])
{
d[++tot].fa=d[getfail(d[pos].fa,i)].s[c];
d[pos].s[c]=tot,d[tot].len=d[pos].len+2;
d[tot].dep=d[d[tot].fa].dep+1;
}
now=d[pos].s[c];
printf("%d ",lst=d[now].dep);
}
return 0;
}
这题要记录每个回文串出现的次数。在 Fail 树的角度考虑,每加入一个字符,最长回文后缀所在的状态在 Fail 树上的所有祖先出现次数都 \(+1\)。
显然每次都跳 Fail 暴力修改是不可行的,因此只在最长回文后缀处打一个标记,最后统计答案时,状态的出现次数就是 Fail 树的子树和。
点击查看代码
const int N=3e5+5;
int n,tot=1;
long long f[N];
char s[N];
struct node{int len,fa,s[26];} d[N];
il int getfail(int u,int i)
{
while(i-d[u].len-1<=0||s[i-d[u].len-1]!=s[i]) u=d[u].fa;
return u;
}
int main()
{
scanf("%s",s+1); n=strlen(s+1);
d[0].fa=1,d[1].len=-1;
for(int i=1,now=0;i<=n;i++)
{
int pos=getfail(now,i),c=s[i]-'a';
if(!d[pos].s[c])
{
d[++tot].fa=d[getfail(d[pos].fa,i)].s[c];
d[pos].s[c]=tot,d[tot].len=d[pos].len+2;
}
now=d[pos].s[c],f[now]++;
}
long long ans=0;
for(int i=tot;i;i--)
{
f[d[i].fa]+=f[i];
ans=max(ans,1ll*f[i]*d[i].len);
}
printf("%lld\n",ans);
return 0;
}
P4199 万径人踪灭
ybtoj 翻到的。其实这题重点不在 PAM/manacher,倒不如说是 FFT 练习题(
答案可以转化成所有合法子序列减掉连续的。
对于不保证连续的,发现本质是求下标和等于某个数(即关于某个点对称)且相同的点对数。这个东西形如多项式卷积,对两种字符分别 FFT。
而连续回文子串的总数可以用 PAM 来求,代码不放了。
回文自动机(PAM) 详解的更多相关文章
- 回文自动机pam
目的:类似回文Trie树+ac自动机,可以用来统计一些其他的回文串相关的量 复杂度:O(nlogn) https://blog.csdn.net/Lolierl/article/details/999 ...
- 回文树(回文自动机PAM)小结
回文树学习博客:lwfcgz poursoul 边写边更新,大概会把回文树总结在一个博客里吧... 回文树的功能 假设我们有一个串S,S下标从0开始,则回文树能做到如下几点: 1.求串S前缀0~ ...
- 回文树/回文自动机(PAM)学习笔记
回文树(也就是回文自动机)实际上是奇偶两棵树,每一个节点代表一个本质不同的回文子串(一棵树上的串长度全部是奇数,另一棵全部是偶数),原串中每一个本质不同的回文子串都在树上出现一次且仅一次. 一个节点的 ...
- 回文自动机(PAM) 入门讲解
处理回文串,Manacher算法也是很不错,但在有些问题的处理上比较麻烦,比如求本质不同的子串的数量还需要结合后缀数组才能解决.今天的们介绍一种能够方便的解决关于回文串的问题的算法--PAM. 一些功 ...
- 洛谷P5496 回文自动机【PAM】模板
回文自动机模板 1.一个串的本质不同的回文串数量是\(O(n)\)级别的 2.回文自动机的状态数不超过串长,且状态数等于本质不同的回文串数量,除了奇偶两个根节点 3.如何统计所有回文串的数量,类似后缀 ...
- HDU6599 (字符串哈希+回文自动机)
题意: 求有多少个回文串的前⌈len/2⌉个字符也是回文串.(两组解可重复)将这些回文串按长度分类,分别输出长度为1,2,...,n的合法串的数量. 题解:https://www.cnblogs.co ...
- 【XSY2715】回文串 树链剖分 回文自动机
题目描述 有一个字符串\(s\),长度为\(n\).有\(m\)个操作: \(addl ~c\):在\(s\)左边加上一个字符\(c\) \(addr~c\):在\(s\)右边加上一个字符 \(tra ...
- 字符串数据结构模板/题单(后缀数组,后缀自动机,LCP,后缀平衡树,回文自动机)
模板 后缀数组 #include<bits/stdc++.h> #define R register int using namespace std; const int N=1e6+9; ...
- bzoj千题计划306:bzoj2342: [Shoi2011]双倍回文 (回文自动机)
https://www.lydsy.com/JudgeOnline/problem.php?id=2342 解法一: 对原串构建回文自动机 抽离fail树,从根开始dfs 设len[x]表示节点x表示 ...
- 【回文自动机】bzoj3676 [Apio2014]回文串
回文自动机讲解!http://blog.csdn.net/u013368721/article/details/42100363 pam上每个点代表本质不同的回文子串.len(i)代表长度,cnt(i ...
随机推荐
- SaaS软件工程师成长路径
背景 SaaS软件工程师的成长需要循序渐进,和SaaS业务一样有耐心.SaaS工程师需要在"业务"."技术"."管理"三个维度做好知识储备. ...
- TCP的Keep-Alive机制:链接存在但是没有数据传输,内核怎么处理
服务端/客户端会定期发送探测报文来检测客户端的存活状态. 由三个内核参数控制: 首次发送探测报文时间:net.ipv4.tcp_keepalive_time有报文传输时重置 探测报文的发送间隔:net ...
- 记一次Android项目升级Kotlin版本(1.5 -> 1.7)
原文地址: 记一次Android项目升级Kotlin版本(1.5 -> 1.7) - Stars-One的杂货小窝 由于自己的历史项目Kotlin版本比较老了,之前已经升级过一次了(1.4-&g ...
- SimpleDateFormat 线程安全问题修复方案
问题介绍 在日常的开发过程中,我们不可避免地会使用到 JDK8 之前的 Date 类,在格式化日期或解析日期时就需要用到 SimpleDateFormat 类,但由于该类并不是线程安全的,所以我们常发 ...
- 基于Supabase开发公众号接口
在<开源BaaS平台Supabase介绍>一文中我们对什么是BaaS以及一个优秀的BaaS平台--Supabase做了一些介绍.在这之后,出于探究的目的,我利用一些空闲时间基于Micros ...
- Callback Function Essence
Include Example Input: I am a. route execute finish. I am b. route execute finish. What is Callback ...
- SQL Server 2022新功能概览
开始之前 本篇文章仅仅是针对SQL Server 2022新推出功能的概览,以及我个人作为用户视角对于每个功能的理解,有些功能会结合一些我的经验进行描述,实际上,SQL Server 2022在引 ...
- 定义一个函数,传入一个字典和一个元组,将字典的值(key不变)和元组的值交换,返回交换后的字典和元组
知识点:zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表. li=[3,4,5] t=(7,8,9) print(list(zip(li,t ...
- 浅析 GlusterFS 与 JuiceFS 的架构异同
在进行分布式文件存储解决方案的选型时,GlusterFS 无疑是一个不可忽视的考虑对象.作为一款开源的软件定义分布式存储解决方案,GlusterFS 能够在单个集群中支持高达 PiB 级别的数据存储. ...
- Robot 框架学习笔记
Robot 框架学习笔记 为了更好地让读者理解快速学习新框架的思路,笔者接下来会继续介绍另一个名为 Robot 的自动化测试框架,希望读者能参考笔者从零开始讲解一个开发/测试框架的流程,从中总结出适合 ...