Netty实战(五)
一、什么是ByteBuf
我们前面说过,网络数据的基本单位总是字节。Java NIO 提供了 ByteBuffer 作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。ByteBuffer 替代品是 ByteBuf,一个强大的实现,既解决了 JDK API 的局限性,又为网络应用程序的开发者提供了更好的 API。
下面我们将会说明和 JDK 的 ByteBuffer 相比,ByteBuf 的卓越功能性和灵活性
二、 ByteBuf 的 API
Netty 的数据处理 API 通过两个组件暴露——abstract class ByteBuf 和 interface ByteBufHolder。
下面是一些 ByteBuf API 的优点:
- 它可以被用户自定义的缓冲区类型扩展;
- 通过内置的复合缓冲区类型实现了透明的零拷贝;
- 容量可以按需增长(类似于 JDK 的 StringBuilder);
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法;
- 读和写使用了不同的索引;
- 支持方法的链式调用;
- 支持引用计数;
- 支持池化。
其他类可用于管理 ByteBuf 实例的分配,以及执行各种针对于数据容器本身和它所持有的数据的操作。
三、ByteBuf 类——Netty 的数据容器
因为所有的网络通信都涉及字节序列的移动,所以高效易用的数据结构明显是必不可少的。Netty 的 ByteBuf 实现满足并超越了这些需求。
3.1 ByteBuf如何工作?
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入。
当你从 ByteBuf 读取时,它的 readerIndex 将会被递增已经被读取的字节数。
当你写入 ByteBuf 时,它的writerIndex 也会被递增。
ByteBuf 的布局结构和状态如下:

那么这两个索引之间有什么关系?如果读取字节直到 readerIndex 达到和 writerIndex 同样的值时会发生什么?
在那时,我们将会到达“可以读取的”数据的末尾。就如同试图读取超出数组末尾的数据一样,试图读取超出该点的数据将会触发IndexOutOfBoundsException。
名称以 read 或者 write 开头的 ByteBuf 方法,将会推进其对应的索引,而名称以 set 或者 get 开头的操作则不会。
后面的这些方法将在作为一个参数传入的一个相对索引上执行操作。可以指定 ByteBuf 的最大容量。试图移动写索引(即 writerIndex)超过这个值将会触发一个异常。(默认的限制是Integer.MAX_VALUE。)
PS:也就是说用户直接或者间接使 capacity(int)或者 ensureWritable(int)方法来增加超过该最大容量时抛出异常。
3.2 ByteBuf 的使用模式
首先我们记住ByteBuf:一个由不同的索引分别控制读访问和写访问的字节数组。
3.2.1 堆缓冲区
最常用的 ByteBuf 模式是将数据存储在 JVM 的堆空间中。这种模式被称为支撑数组(backing array),它能在没有使用池化的情况下提供快速的分配和释放。这种方式,非常适合于有遗留的数据需要处理的情况。
代码展示:
ByteBuf heapBuf = ...;
//检查ByteBuf是否有一个支撑数组
if (heapBuf.hasArray()) {
//如果有,则获取对该数组的引用
byte[] array = heapBuf.array();
//计算第一个字节的偏移量
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
//获取可读字节数
int length = heapBuf.readableBytes();
//使用数组、偏移量和长度作为参数调用你的方法
handleArray(array, offset, length);
}
PS:当 hasArray()方法返回 false 时,尝试访问支撑数组将触发一个 UnsupportedOperationException。这个模式类似于 JDK 的 ByteBuffer 的用法。
3.2.2 直接缓冲区
直接缓冲区是另外一种 ByteBuf 模式。
我们都希望用于对象创建的内存分配永远都来自于堆中。但这并不是必须的,因为ByteBuffer 类允许 JVM 实现通过本地调用来分配内存。
这主要是为了避免在每次调用本地 I/O 操作之前(或者之后)将缓冲区的内容复制到一个中间缓冲区(或者从中间缓冲区把内容复制到缓冲区)。
直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外(它的内容可能不会被堆回收)。如果你的数据包含在一个在堆上分配的缓冲区中,那么在通过套接字发送它之前,JVM将会在内部把你的缓冲区复制到一个直接缓冲区中。
直接缓冲区的主要缺点是:
1、相对于基于堆的缓冲区,它们的分配和释放都较为昂贵。
2、因为数据不是在堆上,所以你不得不进行一次复制,如代码所示。
ByteBuf directBuf = ...;
//检查 ByteBuf 是否由数组支撑。如果不是,则这是一个直接缓冲区
if (!directBuf.hasArray()) {
//获取字节可读数
int length = directBuf.readableBytes();
//分配一个新的数组来保存具有该长度的字节数据
byte[] array = new byte[length];
//将字节复制到该数组
directBuf.getBytes(directBuf.readerIndex(), array);
//开始调用
handleArray(array, 0, length);
}
显然,与使用支撑数组相比,这涉及的工作更多。因此,如果事先知道容器中的数据将会被作为数组来访问,你可能更愿意使用堆内存。
3.2.3 复合缓冲区
第三种也是最后一种模式使用的是复合缓冲区,它为多个 ByteBuf 提供一个聚合视图。
在这里你可以根据需要添加或者删除 ByteBuf 实例,这是一个 JDK 的 ByteBuffer 实现完全缺失的特性。Netty 通过一个 ByteBuf 子类——CompositeByteBuf——实现了这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。
注意:CompositeByteBuf 中的 ByteBuf 实例可能同时包含直接内存分配和非直接内存分配。如果其中只有一个实例,那么对 CompositeByteBuf 上的 hasArray()方法的调用将返回该组件上的 hasArray()方法的值;否则它将返回 false
举个粒子:
假设我们有一条由头部和主体两部分组成并通过 HTTP 协议传输的消息。且这两部分分别由应用程序的不同模块产生,然后在消息被发送的时候组装。该应用程序可以选择为多个消息重用相同的消息主体。当这种情况发生时,对于每个消息都将会创建一个新的头部。
如果我们不想为每个消息都重新分配这两个缓冲区,那么使用 CompositeByteBuf 是一个完美的选择。
如图为持有一个头部和主体的 CompositeByteBuf:

JDK 的 ByteBuffer针对我们这个需求实现代码会像下面这样:
// 使用数组保存消息部分
ByteBuffer[] message = new ByteBuffer[] { header, body };
// 创建一个新的ByteBuffer,并使用copy合并头和正文
ByteBuffer message2 =ByteBuffer.allocate(header.remaining() + body.remaining());
message2.put(header);
message2.put(body);
message2.flip();
使用 CompositeByteBuf 的复合缓冲区模式则是这样:
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = ...; // 可以是堆缓冲或直接缓冲
ByteBuf bodyBuf = ...; // 可以是堆缓冲或直接缓冲
//将 ByteBuf 实例追加到 CompositeByteBuf
messageBuf.addComponents(headerBuf, bodyBuf);
.....
//删除位于索引位置为 0(第一个组件)的 ByteBuf
messageBuf.removeComponent(0); // 移除头部
//循环遍历所有的 ByteBuf 实例
for (ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}
CompositeByteBuf 不支持访问其支撑数组,因此访问 CompositeByteBuf 中的数据类似于(访问)直接缓冲区的模式,像下面这样:
CompositeByteBuf compBuf = Unpooled.compositeBuffer();
//获得可读字节数
int length = compBuf.readableBytes();
//分配一个具有可读字节数长度的新数组
byte[] array = new byte[length];
//将数组读到该数组中
compBuf.getBytes(compBuf.readerIndex(), array);
//调用使用
handleArray(array, 0, array.length);
Netty使用了CompositeByteBuf来优化套接字的I/O操作,尽可能地消除了由JDK的缓冲区实现所导致的性能以及内存使用率的惩罚。
这种优化发生在Netty的核心代码中,因此不会被暴露出来,但是我们应该知道它所带来的影响。
四、字节级操作
ByteBuf 提供了许多超出基本读、写操作的方法用于修改它的数据。
4.1 随机访问索引
如同在普通的 Java 字节数组中一样,ByteBuf 的索引是从零开始的:第一个字节的索引是0,最后一个字节的索引总是 capacity() - 1。对存储机制的封装使得遍历 ByteBuf 的内容非常简单。
像这样的:
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char)b);
}
需要注意的是,使用那些需要一个索引值参数的方法(的其中)之一来访问数据既不会改变readerIndex 也不会改变 writerIndex。如果有需要,也可以通过调用 readerIndex(index)或者 writerIndex(index)来手动移动这两者。
4.2 顺序访问索引
虽然 ByteBuf 同时具有读索引和写索引,但是 JDK 的 ByteBuffer 却只有一个索引,这也就是为什么必须调用 flip()方法来在读模式和写模式之间进行切换的原因。
以下展示了ByteBuf 是如何被它的两个索引划分成 3 个区域的:
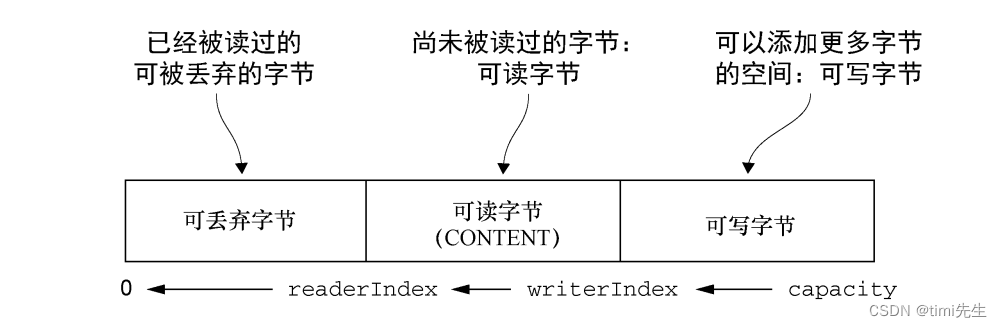
4.3 可丢弃字节
可丢弃字节的分段包含了已经被读过的字节。通过调用 discardReadBytes()方法,可以丢弃它们并回收空间。这个分段的初始大小为 0,存储在 readerIndex 中,会随着 read 操作的执行而增加(get*操作不会移动 readerIndex)。
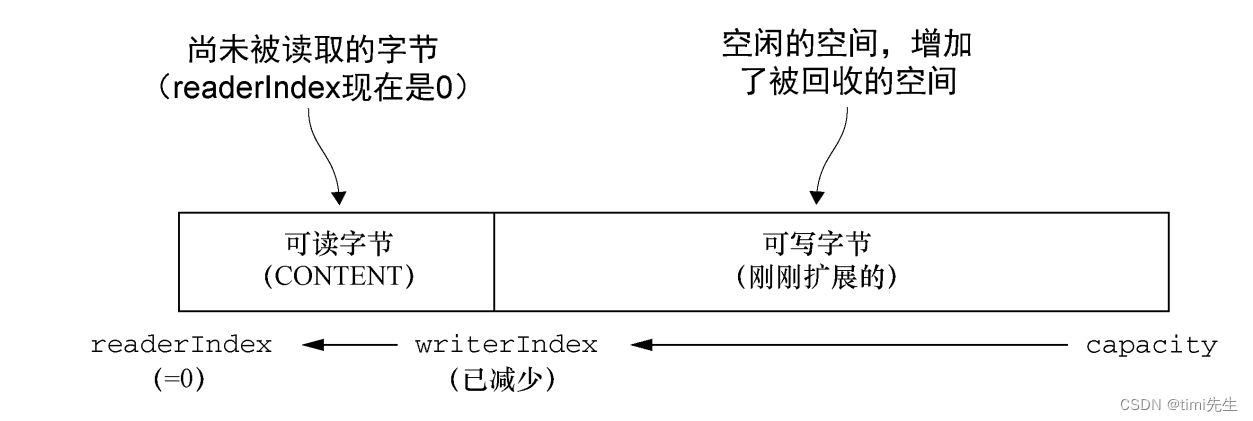
像图中所展示的缓冲区上调用discardReadBytes()方法后的结果。可以看到,可丢弃字节分段中的空间已经变为可写的了。注意,在调用discardReadBytes()之后,对可写分段的内容并没有任何的保证 (因为只是移动了可以读取的字节以及 writerIndex,而没有对所有可写入的字节进行擦除写)。
有的同学可能会倾向于频繁地调用 discardReadBytes()方法以确保可写分段的最大化,但是请注意,这将极有可能会导致内存复制,因为可读字节(图中标记为 CONTENT 的部分)必须被移动到缓冲区的开始位置。建议只在有真正需要的时候才这样做,例如,当内存非常宝贵的时候。
4.4 可读字节
ByteBuf 的可读字节分段存储了实际数据。新分配的、包装的或者复制的缓冲区的默认的readerIndex 值为 0。任何名称以 read 或者 skip 开头的操作都将检索或者跳过位于当前readerIndex 的数据,并且将它增加已读字节数。
如果被调用的方法需要一个 ByteBuf 参数作为写入的目标,并且没有指定目标索引参数,那么该目标缓冲区的 writerIndex 也将被增加。例如:
readBytes(ByteBuf dest);
如果尝试在缓冲区的可读字节数已经耗尽时从中读取数据,那么将会引发一个 IndexOutOfBoundsException。
下面是一个读取所有数据的代码示例:
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
4.5 可写字节
可写字节分段是指一个拥有未定义内容的、写入就绪的内存区域。新分配的缓冲区的writerIndex 的默认值为 0。任何名称以 write 开头的操作都将从当前的 writerIndex 处开始写数据,并将它增加已经写入的字节数。
如果写操作的目标也是 ByteBuf,并且没有指定源索引的值,则源缓冲区的 readerIndex 也同样会被增加相同的大小。这个调用如下所示:
writeBytes(ByteBuf dest);
如果尝试往目标写入超过目标容量的数据,将会引发一个IndexOutOfBoundException(PS:在往 ByteBuf 中写入数据时,其将首先确保目标 ByteBuf 具有足够的可写入空间来容纳当前要写入的数据,如果没有,则将检查当前的写索引以及最大容量是否可以在扩展后容纳该数据,可以则会分配并调整容量,否则就会抛出该异常。)
下面代码是一个用随机整数值填充缓冲区,直到它空间不足为止的例子。writeableBytes()方法在这里被用来确定该缓冲区中是否还有足够的空间。
// 用随机整数填充缓冲区的可写字节。
ByteBuf buffer = ...;
while (buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
4.6 索引管理
JDK 的 InputStream 定义了 mark(int readlimit)和 reset()方法,这些方法分别被用来将流中的当前位置标记为指定的值,以及将流重置到该位置。(说白了就是给指定位置写值,比如有四个位置可以指定第一个位置写 “作”,第二个位置写“者”,第三个位置写“很”,第四个位置写“帅”)。
也可以通过调用 readerIndex(int)或者 writerIndex(int)来将索引移动到指定位置。试图将任何一个索引设置到一个无效的位置都将导致一个 IndexOutOfBoundsException。
可以通过调用 clear()方法来将 readerIndex 和 writerIndex 都设置为 0。注意,这并不会清除内存中的内容。
clear()未被调用:

clear()调用之后:
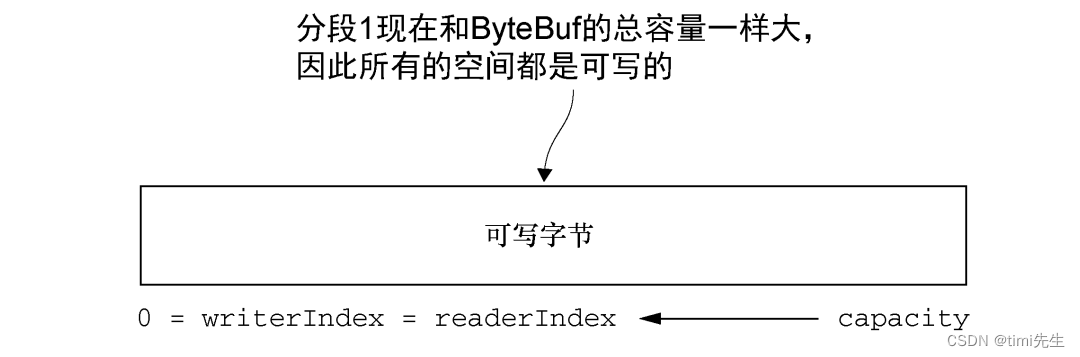
调用 clear()比调用 discardReadBytes()轻量得多,因为它将只是重置索引而不会复制任何的内存。
4.7 查找操作
在ByteBuf中有多种可以用来确定指定值的索引的方法。最简单的是使用indexOf()方法。
较复杂的查找可以通过那些需要一个io.netty.util.ByteProcessor,这个接口只定义了一个方法:
boolean process(byte value)
ByteProcessor针对一些常见的值定义了许多便利的方法。假设你的应用程序需要和所谓的包含有以NULL结尾的内容的Flash套接字作为参数的方法达成。可以调用它将检查输入值是否是正在查找的值。
forEachByte(ByteBufProcessor.FIND_NUL)
展示一个查找回车符(\r)的例子:
ByteBuf buffer = ...;
int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
4.8 派生缓冲区
派生缓冲区为 ByteBuf 提供了以专门的方式来呈现其内容的视图。这类视图是通过以下方法被创建的:
- duplicate();
- slice();
- slice(int, int);
- Unpooled.unmodifiableBuffer(…);
- order(ByteOrder);
- readSlice(int)。
每个这些方法都将返回一个新的 ByteBuf 实例,它具有自己的读索引、写索引和标记索引。其内部存储和 JDK 的 ByteBuffer 一样也是共享的。这使得派生缓冲区的创建成本是很低廉的,但是这也意味着,如果你修改了它的内容,也同时修改了其对应的源实例,所以要小心。
ByteBuf 复制:
如果需要一个现有缓冲区的真实副本,请使用 copy()或者 copy(int, int)方法。不同于派生缓冲区,由这个调用所返回的 ByteBuf 拥有独立的数据副本。
看段代码:
1、使用 slice(int, int)方法来操作 ByteBuf 的一个分段
Charset utf8 = Charset.forName("UTF-8");
//创建一个用于保存给定字符串的字节的 ByteBuf
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//创建该 ByteBuf 从索引 0 开始到索引 15结束的一个新切片
ByteBuf sliced = buf.slice(0, 15);
//将打印“Netty in Action”
System.out.println(sliced.toString(utf8));
//更新索引 0 处的字节
buf.setByte(0, (byte)'J');
//将会成功,因为数据是共享的,对其中一个所做的更改对另外一个也是可见的
assert buf.getByte(0) == sliced.getByte(0);
2、利用副本切片来操作 ByteBuf 的一个分段
Charset utf8 = Charset.forName("UTF-8");
//创建 ByteBuf 以保存所提供的字符串的字节
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//创建该 ByteBuf 从索引 0 开始到索引 15结束的分段的副本
ByteBuf copy = buf.copy(0, 15);
//将打印“Netty in Action”
System.out.println(copy.toString(utf8));
////更新索引 0 处的字节
buf.setByte(0, (byte) 'J');
//将会失败,因为数据不是共享的
assert buf.getByte(0) != copy.getByte(0);
4.9 读/写操作
正如我们所提到过的,有两种类别的读/写操作:
- get()和 set()操作,从给定的索引开始,并且保持索引不变;
- read()和 write()操作,从给定的索引开始,并且会根据已经访问过的字节数对索引进行调整。
下面是部分常用的get()方法:
| 名 称 | 描 述 |
|---|---|
| getBoolean(int) | 返回给定索引处的 Boolean 值 |
| getByte(int) | 返回给定索引处的字节 |
| getUnsignedByte(int) | 将给定索引处的无符号字节值作为 short 返回 |
| getMedium(int) | 返回给定索引处的 24 位的中等 int 值 |
| getUnsignedMedium(int) | 返回给定索引处的无符号的 24 位的中等 int 值 |
| getInt(int) | 返回给定索引处的 int 值 |
| getUnsignedInt(int) | 将给定索引处的无符号 int 值作为 long 返回 |
| getLong(int) | 返回给定索引处的 long 值 |
| getShort(int) | 返回给定索引处的 short 值 |
| getUnsignedShort(int) | 将给定索引处的无符号 short 值作为 int 返回 |
| getBytes(int, ...) | 将该缓冲区中从给定索引开始的数据传送到指定的目的地 |
下面是部分常用的set()方法:
| 名 称 | 描 述 |
|---|---|
| setBoolean(int, boolean) | 设定给定索引处的 Boolean 值 |
| setByte(int index, int value) | 设定给定索引处的字节值 |
| setMedium(int index, int value) | 设定给定索引处的 24 位的中等 int 值 |
| setInt(int index, int value) | 设定给定索引处的 int 值 |
| setLong(int index, long value) | 设定给定索引处的 long 值 |
| setShort(int index, int value) | 设定给定索引处的 short 值 |
get()和 set()方法的用法大家可以参照下面的例子:
Charset utf8 = Charset.forName("UTF-8");
//创建一个新的 ByteBuf以保存给定字符串的字节
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//打印第一个字符'N'
System.out.println((char)buf.getByte(0));
//存储当前的 readerIndex和 writerIndex
int readerIndex = buf.readerIndex();
int writerIndex = buf.writerIndex();
//将索引 0 处的字节更新为字符'B'
buf.setByte(0, (byte)'B');
////打印第一个字符'B'
System.out.println((char)buf.getByte(0));
//将会成功,因为这些操作并不会修改相应的索引
assert readerIndex == buf.readerIndex();
assert writerIndex == buf.writerIndex();
然后我们看一下read()操作,其作用于当前的 readerIndex 或 writerIndex。这些方法将用于从 ByteBuf 中读取数据,如同它是一个流。
常用的read()方法:
| 名 称 | 描 述 |
|---|---|
| readBoolean() | 返回当前 readerIndex 处的 Boolean,并将 readerIndex 增加 1 |
| readByte() | 返回当前 readerIndex 处的字节,并将 readerIndex 增加 1 |
| readUnsignedByte() | 将当前 readerIndex 处的无符号字节值作为 short 返回,并将readerIndex 增加 1 |
| readMedium() | 返回当前 readerIndex 处的 24 位的中等 int 值,并将 readerIndex增加 3 |
| readUnsignedMedium() 返回当前 readerIndex 处的 24 位的无符号的中等 int 值,并将readerIndex 增加 3 | |
| readInt() | 返回当前 readerIndex 的 int 值,并将 readerIndex 增加 4 |
| readUnsignedInt() | 将当前 readerIndex 处的无符号的 int 值作为 long 值返回,并将readerIndex 增加 4 |
| readLong() | 返回当前 readerIndex 处的 long 值,并将 readerIndex 增加 8 |
| readShort() | 返回当前 readerIndex 处的 short 值,并将 readerIndex 增加 2 |
| readUnsignedShort() | 将当前 readerIndex 处的无符号 short 值作为 int 值返回,并将readerIndex 增加 2 |
| readBytes(ByteBuf byte[] destination,int dstIndex [,intlength]) | 将当前 ByteBuf 中从当前 readerIndex 处开始的(如果设置了,length 长度的字节)数据传送到一个目标 ByteBuf 或者 byte[],从目标的 dstIndex 开始的位置。本地的 readerIndex 将被增加已经传输的字节数 |
常见的writer()方法(PS:几乎每个 read()方法都有对应的 write()方法,用于将数据追加到 ByteBuf 中。注意:下列所列出的这些方法的参数是需要写入的值,而不是索引值。)
| 名 称 | 描 述 |
|---|---|
| writeBoolean(boolean) | 在当前 writerIndex 处写入一个 Boolean,并将 writerIndex 增加 1 |
| writeByte(int) | 在当前 writerIndex 处写入一个字节值,并将 writerIndex 增加 1 |
| writeMedium(int) | 在当前 writerIndex 处写入一个中等的 int 值,并将 writerIndex增加 3 |
| writeInt(int) | 在当前 writerIndex 处写入一个 int 值,并将 writerIndex 增加 4 |
| writeLong(long) | 在当前 writerIndex 处写入一个 long 值,并将 writerIndex 增加 8 |
| writeShort(int) | 在当前 writerIndex 处写入一个 short 值,并将 writerIndex 增加 2 |
| writeBytes(sourceByteBuf byte[][,int srcIndex,int length]) | 从当前 writerIndex 开始,传输来自于指定源(ByteBuf 或者 byte[])的数据。如果提供了 srcIndex 和 length,则从 srcIndex 开始读取,并且处理长度为 length 的字节。当前 writerIndex 将会被增加所写入的字节数 |
ByteBuf 上的 read()和 write()操作大家可以参照下列的代码:
Charset utf8 = Charset.forName("UTF-8");
//创建一个新的ByteBuf 以保存给定字符串的字节
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//打印第一个字符'N'
System.out.println((char)buf.readByte());
//存储当前的存储当前的 readerIndex
int readerIndex = buf.readerIndex();
////存储当前的存储当前的 writerIndex
int writerIndex = buf.writerIndex();
//将字符'?'追加到缓冲区
buf.writeByte((byte)'?');
assert readerIndex == buf.readerIndex();
//将会成功,因为 writeByte()方法移动了 writerIndex
assert writerIndex != buf.writerIndex();
4.10 更多的操作
ByteBuf 还为我们提供了其他有用操作:
| 名 称 | 描 述 |
|---|---|
| readableBytes() | 返回可被读取的字节数 |
| writableBytes() | 返回可被写入的字节数 |
| capacity() | 返回 ByteBuf 可容纳的字节数。在此之后,它会尝试再次扩展直到达到 maxCapacity() |
| maxCapacity() | 返回 ByteBuf 可以容纳的最大字节数 |
| hasArray() | 如果 ByteBuf 由一个字节数组支撑,则返回 true |
| array() | 如果 ByteBuf 由一个字节数组支撑则返回该数组;否则,它将抛出一个UnsupportedOperationException 异常 |
五、ByteBufHolder 接口
为了处理我们除了数据负载之外,还需要存储各种属性值的需求,Netty 提供了 ByteBufHolder。
ByteBufHolder 也为 Netty 的高级特性提供了支持,如缓冲区池化,其中可以从池中借用 ByteBuf,并且在需要时自动释放。ByteBufHolder 只有几种用于访问底层数据和引用计数的方法。
ByteBufHolder 的常见操作如下:
| 名 称 | 描 述 |
|---|---|
| content() | 返回由这个 ByteBufHolder 所持有的 ByteBuf |
| copy() | 返回这个 ByteBufHolder 的一个深拷贝,包括一个其所包含的 ByteBuf 的非共享拷贝 |
| duplicate() | 返回这个 ByteBufHolder 的一个浅拷贝,包括一个其所包含的 ByteBuf 的共享拷贝 |
如果想要实现一个将其有效负载存储在 ByteBuf 中的消息对象,那么 ByteBufHolder 将是个不错的选择。
六、ByteBuf 分配
6.1 按需分配:ByteBufAllocator 接口
为了降低分配和释放内存的开销,Netty 通过 interface ByteBufAllocator 实现了(ByteBuf 的)池化,它可以用来分配我们所描述过的任意类型的 ByteBuf 实例。
使用池化是特定于应用程序的决定,其并不会以任何方式改变 ByteBuf API。
下面列出了 ByteBufAllocator 常见的一些操作:
| 名 称 | 描 述 |
|---|---|
| buffer()、buffer(int initialCapacity)、buffer(int initialCapacity, int maxCapacity) | 返回一个基于堆或者直接内存存储的 ByteBuf |
| heapBuffer()、heapBuffer(int initialCapacity)、heapBuffer(int initialCapacity, int maxCapacity) | 返回一个基于堆内存存储的ByteBuf |
| directBuffer()、directBuffer(int initialCapacity)、directBuffer(int initialCapacity, int maxCapacity) | 返回一个基于直接内存存储的ByteBuf |
| compositeBuffer()、compositeBuffer(int maxNumComponents)、compositeDirectBuffer()、compositeDirectBuffer(int maxNumComponents)、compositeHeapBuffer()、compositeHeapBuffer(int maxNumComponents) | 返回一个可以通过添加最大到指定数目的基于堆的或者直接内存存储的缓冲区来扩展的CompositeByteBuf |
| ioBuffer() | 返回一个用于套接字的 I/O 操作的 ByteBuf |
可以通过 Channel(每个都可以有一个不同的 ByteBufAllocator 实例)或者绑定到ChannelHandler 的 ChannelHandlerContext 获取一个到 ByteBufAllocator 的引用。
大家可以参考下面的代码:
Channel channel = ...;
//从 Channel 获取一个到ByteBufAllocator 的引用
ByteBufAllocator allocator = channel.alloc();
....
ChannelHandlerContext ctx = ...;
//从 ChannelHandlerContext 获取一个到 ByteBufAllocator 的引用
ByteBufAllocator allocator2 = ctx.alloc();
...
Netty提供了两种ByteBufAllocator的实现:PooledByteBufAllocator和UnpooledByteBufAllocator。
前者池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。
后者的实现不池化ByteBuf实例,并且在每次它被调用时都会返回一个新的实例。
虽然Netty默认使用了PooledByteBufAllocator,但这可以很容易地通过ChannelConfig API或者在引导你的应用程序时指定一个不同的分配器来更改。
6.2 Unpooled 缓冲区
可能某些情况下,未能获取一个到 ByteBufAllocator 的引用。对于这种情况,Netty 提供了一个简单的称为 Unpooled 的工具类,它提供了静态的辅助方法来创建未池化的 ByteBuf实例。
下面是写常用的Unpooled方法:
| 名 称 | 描 述 |
|---|---|
| buffer()、buffer(int initialCapacity)、buffer(int initialCapacity, int maxCapacity) | 返回一个未池化的基于堆内存存储的ByteBuf |
| directBuffer()、directBuffer(int initialCapacity)、directBuffer(int initialCapacity, int maxCapacity) | 返回一个未池化的基于直接内存存储的 ByteBuf |
| wrappedBuffer() | 返回一个包装了给定数据的 ByteBuf |
| copiedBuffer() | 返回一个复制了给定数据的 ByteBuf |
Unpooled 类还使得 ByteBuf 同样可用于那些并不需要 Netty 的其他组件的非网络项目,使得其能得益于高性能的可扩展的缓冲区 API。
6.3 ByteBufUtil 类
ByteBufUtil 提供了用于操作 ByteBuf 的静态的辅助方法。因为这个 API 是通用的,并且和池化无关,所以这些方法已然在分配类的外部实现。
这些静态方法中最有价值方法:
- hexdump()方法:它以十六进制的表示形式打印ByteBuf 的内容。这在各种情况下都很有用,例如,出于调试的目的记录 ByteBuf 的内容。十六进制的表示通常会提供一个比字节值的直接表示形式更加有用的日志条目,此外,十六进制的版本还可以很容易地转换回实际的字节表示。
- boolean equals(ByteBuf, ByteBuf):它被用来判断两个 ByteBuf实例的相等性。如果你实现自己的 ByteBuf 子类,你可能会发现 ByteBufUtil 的其他有用方法。
七、引用计数
引用计数是一种通过在某个对象所持有的资源不再被其他对象引用时释放该对象所持有的资源来优化内存使用和性能的技术。
引用计数背后的想法并不是特别的复杂;它主要涉及跟踪到某个特定对象的活动引用的数量。一个 ReferenceCounted 实现的实例将通常以活动的引用计数为 1 作为开始。只要引用计数大于 0,就能保证对象不会被释放。当活动引用的数量减少到 0 时,该实例就会被释放。
PS,虽然释放的确切语义可能是特定于实现的,但是至少已经释放的对象应该不可再用了。
引用计数对于池化实现(如 PooledByteBufAllocator)来说是至关重要的,它降低了内存分配的开销。
引用计数演示代码:
Channel channel = ...;
//从 Channel 获取ByteBufAllocator
ByteBufAllocator allocator = channel.alloc();
....
//从 ByteBufAllocator分配一个 ByteBuf
ByteBuf buffer = allocator.directBuffer();
//检查引用计数是否为预期的 1
assert buffer.refCnt() == 1;
...
释放引用计数:
ByteBuf buffer = ...;
//减少到该对象的活动引用。当减少到 0 时,该对象被释放,并且该方法返回 true
boolean released = buffer.release();
..
试图访问一个已经被释放的引用计数的对象,将会导致一个 IllegalReferenceCountException。注意,一个特定的(ReferenceCounted 的实现)类,可以用它自己的独特方式来定义它的引用计数规则。例如,我们可以设想一个类,其 release()方法的实现总是将引用计数设为
零,而不用关心它的当前值,从而一次性地使所有的活动引用都失效
Netty实战(五)的更多相关文章
- Netty实战五之ByteBuf
网络数据的基本单位总是字节,Java NIO 提供了ByteBuffer作为它的字节容器,但是其过于复杂且繁琐. Netty的ByteBuffer替代品是ByteBuf,一个强大的实现,即解决了JDK ...
- [原创].NET 分布式架构开发实战五 Framework改进篇
原文:[原创].NET 分布式架构开发实战五 Framework改进篇 .NET 分布式架构开发实战五 Framework改进篇 前言:本来打算这篇文章来写DAL的重构的,现在计划有点改变.之前的文章 ...
- SpringCloud---熔断降级理解、Hystrix实战(五)
SpringCloud---熔断降级理解.Hystrix实战(五) https://www.cnblogs.com/qdhxhz/p/9581440.html https://blog.csdn.ne ...
- Netty 系列五(单元测试).
一.概述和原理 Netty 的单元测试,主要是对业务逻辑的 ChannelHandler 做测试(毕竟对 Bootstrap.EventLoop 这些做测试着实没有多大意义),模拟一次入站数据或者出站 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- 《Netty实战》源码运行及本地环境搭建
1.源码路径: GitHub - zzzvvvxxxd/netty-in-action-cn: Netty In Action 中文版 ,中文唯一正版<Netty实战>的代码清单 下载后 ...
- 1.Netty 实战前言
1.参考文档:Netty实战精髓篇 2.Netty介绍: Netty是基于Java NIO的网络应用框架. Netty是一个NIO client-server(客户端服务器)框架,使用Nett ...
- 重磅!阿里P8费心整理Netty实战+指南+项目白皮书PDF,总计1.08G
前言 Netty是一款用于快速开发高性能的网络应用程序的Java框架.它封装了网络编程的复杂性,使网络编程和Web技术的最新进展能够被比以往更广泛的开发人员接触到. Netty不只是一个接口和类的集合 ...
- miniFTP项目实战五
项目简介: 在Linux环境下用C语言开发的Vsftpd的简化版本,拥有部分Vsftpd功能和相同的FTP协议,系统的主要架构采用多进程模型,每当有一个新的客户连接到达,主进程就会派生出一个ftp服务 ...
- 恶意代码分析实战五:OllyDebug动态结合
目录 恶意代码分析实战五:OllyDebug动态结合 OllyDebug界面介绍 OllyDebug载入程序方法 OllyDebug地址跳转 OllyDebug下断点 OllyDebug单步执行 Ol ...
随机推荐
- Jmeter——性能测试的认知以及思考bug(一)
前言 性能测试是一个全栈工程师/架构师必会的技能之一,只有学会性能测试,才能根据得到的测试报告进行分析,找到系统性能的瓶颈所在,而这也是优化架构设计中重要的依据. 测试流程: 需求分析→环境搭建→测试 ...
- Python——基础知识(一)
1. 那么多编程语言,为什么学python 易于学习,是所有编程语言当中最容易学习的 没有最好的语言,只有最合适的语言 2. 反复执行的用例如何提升效率 测试流程回归(回顾) 很多测试用例在不同的测试 ...
- Redis 线程模型
一.概述 [1]Redis 是基于 Reactor 模式开发的网络事件处理器:这个处理器被称为文件事件处理器(file event handler),这个文件事件处理器是单线程的,所以 Redis 才 ...
- MySQL 更新执行的过程
更多内容,前往 IT-BLOG Select语句的执行过程会经过连接器.分析器.优化器.执行器.存储引擎,同样的 Update语句也会同样走一遍 Select语句的执行过程. 但是和 Select ...
- 递推求解DAG最长路径长度及最长路径条数
说明 在一般图中,求解最长路或最短路只能通过最短路算法解决 但是在DAG中,由于不存在环,因此可以通过递推,以线性复杂度计算处最长路或最短路.当然需要首先对有向图进行Tarjan缩点转化为DAG 例题 ...
- Django笔记六之外键ForeignKey介绍
这一篇笔记介绍 Django 系统 model 的外键处理,ForeignKey 以及相应的处理方法. 这是一种一对多的字段类型,表示两张表之间的关联关系. 本篇笔记的目录如下: on_delete ...
- ACM-NEFUOJ-P209湖南修路
思路 prim的最小生成树,套上肝就完事了 代码 #include<iostream> #include<cstdio> #include<string.h> #d ...
- 浅学git工具
1.git工具介绍及使用 git工具直接安装: 直接运行exe文件进行安装,按默认的操作点击下一步就行了 校验: 在DOS命令行中输入:git --version 如果能正常显示出对应的版本就是ok ...
- 来自jackson的灵魂一击:@ControllerAdvice就能保证万无一失吗?
前几天写了篇关于fastjson的文章,<fastjson很好,但不适合我>.里面探讨到关于对象循环引用的序列化问题.作为spring序列化的最大竞品,在讨论fastjson的时候肯定要对 ...
- CentOS8 搭建zabbix监控系统
哈喽,有些时间没有更新公众号.今日更新一下. 安装MySQL数据库 # 安装wget [root@cby ~]# dnf install wget -y # 下载MySQL源 [root@cby ~] ...