郝斌–SQL Server2005学习笔记
数据库(Database)狭义上是指存储数据的仓库,广义上包含对数据进行存储和管理的软件(DBMS)和数据本身。数据库由表、关系和操作组成。
一、数据库简介
1、为什么需要数据库
数据库简化了对数据的操作,几乎所有的应用软件的后台都需要数据库;且数据库存储数据占用空间小、存储安全、容易持久保存 以及 数据库容易维护、升级和移植等。
2、数据结构与数据库的区别
数据库是在应用软件级别研究对硬盘数据的存储和操作,数据结构是在系统软件级别研究对内存数据的存储和操作。
3、如何学习数据库
(1)数据库是如何存储数据的
字段 记录 表 约束 (主键 外键 唯一键 非空 check default 触发器)
(2)数据库是如何操作数据的
insert update delete T-SQL 存储过程 函数 触发器
(3)数据库是如何显示数据的
Select (重点的重点
二、MS图形化操作
1、数据库的附加与分离
分离时,必须选择删除链接(保证数据分离后不可在更新)和更新统计(保证数据分离时的数据是最新的)。
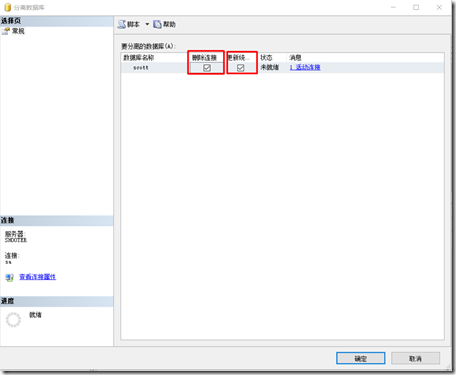
图 2-1-1 数据库分离
mdf文件是存储数据的文件、ldf是存储操作日志的文件,附加时只需选中mdf文件即可。

图2-1-2 数据库附加
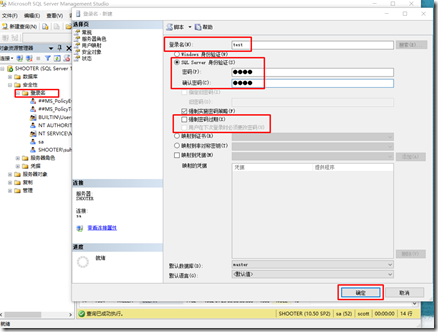
2、创建登录用户
在创建登录用户时必须去除勾选【强制密码过期】。
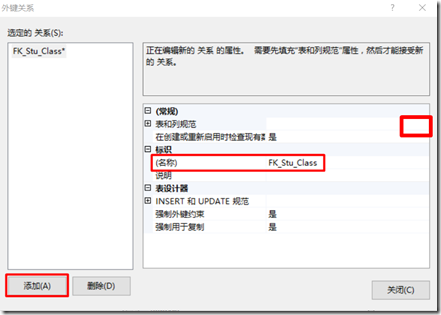
3、建立外键约束
在表结构的侧边栏右击【关系】,在弹出的窗口中设置完外键名称后,单击【表和列规范】的最右侧即可设置外键关系。
依据【外键字段所在的表是外键表,外键参照的字段所在的表称为主键表】设置表与列的关系。
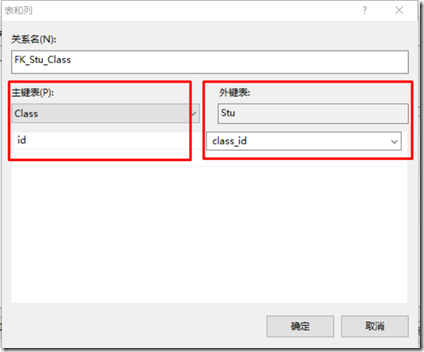
设置完成后,点击确定后,并在表设计界面上按【Ctrl+S】将设计的外键关系进行保存。
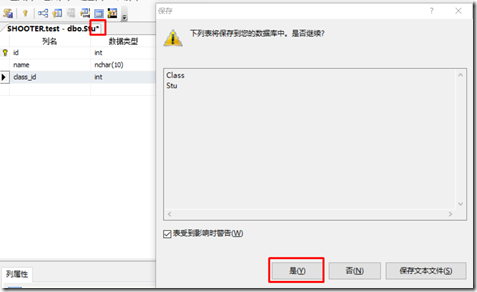
可以在表的【显示依赖关系】查看表与表的依赖关系
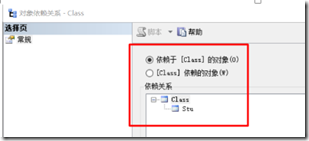
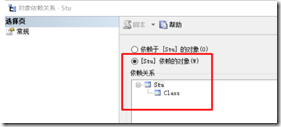
图 2-3-1 依赖于class表的对象 图 2-3-2 stu依赖的对象
也可以在外键表的【键】中查看表中的外键关系(黄色的是主键约束、灰色的是外键约束)。
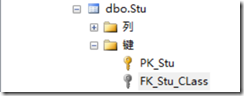
外键关系设置完成后,在外键表stu的class_id字段中只能插入属于主键表class中的id字段值。若插入范围外的值,则会弹出更新失败窗口。
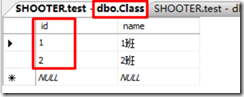
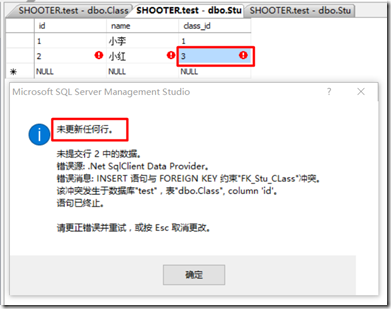
图 2-3-1 class的id字段只有1和2 图2-3-2 若在stu表的class_id字段中插入3则失败
4、表中插入数据
在表上右击,选择【编辑前200行】,插入多行数据时,要在数据输入完毕后,单击【 * –> 执行】方可。
三、数据库是如何存储数据的
数据库是通过表(字段)来解决事物的存储问题;通过约束来解决事物取值的有效性和合法性的问题以及表述表与表之间的关系;建表的过程就是指定事物属性及其各种约束的过程。
1、表的相关概念
字段是一个事物的某一特征,又称列或属性
记录是字段的组合,表示的是一个具体的事务,又称元组
表是记录的组合,表示的是同一类型事物的集合
2、字段的约束
约束是对一个表中属性操作的限制,分为主键约束、外键约束、唯一约束、default约束、check约束和非空约束。
(1)主键约束
主键是指能唯一标识一个事物的一个字段或者多个字段的组合。若表中没有主键,记录与记录之间可以完全相同,这样会造成数据冗余。设置主键约束,不允许字段重复,可以避免了数据冗余。
注:① 含有主键的表称为主键表,外键所在的表称为外键表
② 若主键不是用于集群式服务,建议使用整型,不建议使用字符串
③ 主键的值通常不建议修改,除非本条记录被删除
④ 主键不要定义为id,建议定义为表名id或表名_id
⑤ 不要使用有业务含义的字段充当主键(业务主键),建议使用代理主键
(2)外键约束
若表中的若干个字段是来自另外若干个表的主键或唯一键,则这个若干个字段就是外键。事物与事物之间的关系是通过外键来体现的,通过外键约束从语法上保证了事务所关联的其他事物是存在的。
注:① 外键通常是来自另外表的主键而不是唯一键,因为唯一键可能为null。
② 外键不一定来自另外的表,也可能来自本表的主键。
③ 删除具有外键约束的表,要先删除外键表再删除主键表,否则会导致外键表中的数据引用失败
(3)check约束
保证了事物属性的取值在合法的范围之内。
(4)default约束
保证事物的属性一定会有一个值。
(5)唯一约束
保证了事物属性的取值不允许重复。SQL Server中允许其中有一列且只能有一列为空,Oracle允许多个unique列为空。
(6)非空约束
要求用户在使用insert语句时必须为该属性赋予一个值,否则语法出错。字段默认可以为空。
3、表与表的关系
通过设置不同形式的外键来体现表与表的不同关系。
(1)一对一
既可以把表A的主键作为表B的外键,也可把表B的主键作为表A的外键。
(2)一对多
将表A的主键添加到表B作为表B表的外键,要在“多”的一方添加外键。
(3)多对多
多对多必须通过单独的一张表来表示。
例如:班级和教师 –> 班级是一张表,教师是一张表,班级与教师的关系也是一张表。
四、数据库是如何操作数据的
1、create语句
1 1 create table 表名(
2 2 字段名1 数据类型 字段约束,
3 3 字段名2 数据类型 字段约束
4 4 );
注:create table最后一个字段的后面建议不要写逗号(SQL server可以识别,但在Mysql和Oracle中会报做错)。
identity:主键自动增长,用户不需要为identity修饰的主键斌值
2、insert语句
insert into Table values(值列表);
insert into Table (字段列表) values(值列表);
3、update语句
update Table set 字段 = 值 where 过滤条件;
4、delete语句
Delete from Table where 过滤条件;
5、Drop语句
Drop Table 表名
五、数据库是如何显示数据的
1、单表查询
select 关键字 字段列表/计算列 from 表名 as 别名
join 表名 on where 过滤条件;
group by分组 having 过滤
order by 排序
(1)显示字段
① select变量字段
1 1 select * from emp; -- 显示emp表中的所有字段
2 2 select ename,sal from emp; --仅显示emp表中的ename和sal字段
3 3 select ename,sal,* from emp; -- 显示emp表中的ename、sal和所有字段
② select 计算列
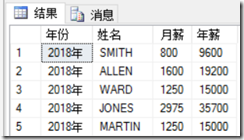
1 select '2018年' as "年份",
2 ename as "姓名",
3 sal as" 月薪",
4 sal * 12 as "年薪" -- 多行函数,计算年薪
5 from emp;
1 select 5; -- 输出一行,显示5
2 select 5 from emp; -- 输出行数是emp行数,每列值是5
① * 是指表中的全部字段,在多表查询时,要指明表名。如:表名.*
② SQL Server允许别名使用单引号括起来,但Oracle不允许,因此为了兼容性,建议使用双引号表示
别名,单引号表示字符串常量。
③ 建议引用表中的字段时,使用表的别名,而非表名
(2)distinct【不允许重复】
distinct可以过滤字段或字段列表重复的值,对于多个null值最终也只会输出一个null。
1 select distinct deptno from emp;--会过滤重复的deptno
2 select distinct comm from emp;--会过滤掉重复的null,或者所:有多个null,最终也只会输出一个
3 select distinct deptno, comm from emp;--对deptno和comm组合进行过滤
4
5 select deptno, distinct comm from emp;--error 逻辑上有冲突
(3)between【在某个范围】
1 --查找工资在1500到3000之间(包括和)的所有员工信息
2 select * from emp where sal >=1500 and sal <=3000
3 select * from emp where sal between 1500 and 3000;
4
5 --查找工资不在1500到3000之间(包括和)的所有员工信息
6 select * from emp where sal <1500 or sal >3000;
7 select * from emp where sal not between 1500 and 3000;
8 select * from emp where not sal between 1500 and 3000;
9
10 --error,求的是不大于1500且小于3000的工资
11 select * from emp where not sal >=1500 and sal <=3000;
注: SQL Server中可用于判断大小的符号【 = <> != > < >= <= between+and in not】
(4)in
1 --把sal是1500 或是 3000 或是 5000 的记录输出
2 select * from emp where sal in (1500, 3000, 5000)
3 select * from emp where sal=1500 or sal=3000 or sal=5000
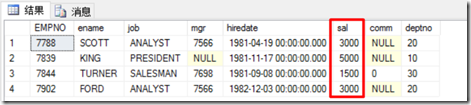
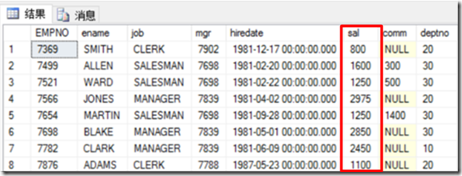
1 --把sal不是1500 也不是3000 也不是5000 的记录输出
2 select * from emp where sal not in (1500, 3000,5000)
3 select*from emp where sal<>1500 and sal<>3000 and sal<>5000
注:① 数据库中不等于有两种表示 ! 和 <> ,建议使用第二种。
② 对 或 取反是 并且 对 并且 取反是 或。
(5)top
关键字top可以显示最前面的若干条记录,专属于Sql语法,不可移植。
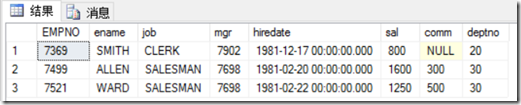
1 select top 3 * from emp;
2 select top 15 percent * from emp;--进位取整,emp记录为14条,输出的是3个,不是2个
3 select top 3 from emp;--error
分页查询:
1 --假设每页显示n条记录,当前要显示的是第m页
2
3 --表名是A 主键是A_id
4
5 Select top n * From A
6 where A_id not in (select top (m-1)*n A_id from emp)
(6)null【空值】
① null的判断方式
零和null是不一样的,null表示空值,没有值,而零是一个确定的值。
null不能参加如下运算:<> != =
null可以参加如下运算:is 和 not is
1 select * from emp where comm is null; --输出奖金为空的员工的信息
2 select * from emp where comm is not null; --输出奖金不为空的信息
3
4 select * from emp where comm < > null;--输出为空error
5 select * from emp where comm != null; --偏出为空error
6 select * from emp where comm = null; --输出为空error
② 任何数据与null进行运算的结果永远是null值
1 --输出每个员工的姓名年薪(包含了奖金) comm假设是一年的奖金
2 -- 错误写法,计算结果存在null值
3 Select empno, ename, sal*12 + comm "年薪" from emp;
4
5 --正确写法:使用isnull (comm, 0)表示 如果comm是null 就返回零 否则返回comm的值
6 select ename, sal*12+isnull(comm, 0)"年薪" from emp;
7
(7)order by
1 --先按照deptno升序排序,如果deptno相同,再按照sal升序排序
2 select * from emp order by deptno, sal;
3
4 --先按deptno降序排序 如果deptno相同,再按照sal升序排序
5 Select * from emp order by deptno desc, sal;
6
7 --先按deptno升序,如果deptno相同,再按sal降序
8 select * from emp order by deptno, sal desc
注:① 使用关键字desc降序排列,如果不指定排序的标准,则默认是升序 (asc)
② 为一个字段指定的排序标准并不会对另一个字段产生影响,强烈建议为每一个字段都指定排序的标准
(8)模糊查询
(1)格式
select 字段列表 from 表名
where 字段 like 匹配条件
注:① 匹配的条件必须的用单引号括起来 不能省略 也不能改用双引号
② 匹配的条件通常含有通配符;匹配结果不区分大小写
(2)通配符
1 -- %:表示任意0个或多个字符
2 select * from emp where ename like '%A%' --ename只要含有字母A就输出
3 select * from emp where ename like 'A%' --ename只要首字母是A的就输出
4 select * from emp where ename like '%A' --ename只要尾字母是A的就输出
5
6 -- _ [这是下划线 不是减号]:表示任意单个字符
7 select *from emp where ename like '_A%' --ename只要第二个字母是A的就输出
8
9 --[a-f]:a到f中的任意单个字符 只能是a b c d e f中的任意一个字符
10 select * from emp where ename like '_[A-F]%';--把ename中第二个字符是A或B或C或D或E或F的记录输出
11
12 --[a, f]:a或f
13 select * from emp where ename like '_[a,F]%';
14
15 --[^a-c]:不是a也不是b也不是c的任意单个字符
16 select * from emp where ename like '_[^A-F]%';
17
(3)通配符作为普通字符使用
1 select * from student where name like '%\%%' escape '\'; --把name中含有%的输出
2 select * from student where name like '%\_%' escape '\'; --把name中含有_的输出;
2、分组查询
(1)、聚合函数
聚合函数:多行记录返回至一个值,通常用于统计分组的信息,默认把所有的信息当做一组
单行函数:每一行返回一个值
多行函数:多行返回一个值,聚合函数是多行函数
1 --单行函数
2 select lower(ename) from emp; --返回各行的小写形式
3
4 --多行函数
5 select avg(sal) from emp;--返回sal的平均值,默认把所有的信息当做一组
6 select min(sal) from emp;--返回sal的最小值
7 select max(sal) from emp;--返回sal的最大值
8
9 select count(*) from emp;--返回表中所有的记录的个数
10 select count(comm) from emp;--返回sal字段非空记录个数,重复的记录也会被当做有效的记录
11 select count(distinct deptno) from emp; --返回字段不重复并且非空的记录的个数
12
13 select max(sal), lower(ename) from emp; --error单行函数和多行函数不能混用
(2)、group by
格式: group by 字段的集合
功能: 把表中的记录按照字段分成不同的组,最终统计的是最小分组的信息
举例: group by a, b,c的用法 –> 先按a分组,如果a相同,再按b分组,如果b相同,再按c分组, 最终统计的是最小分组的信息。
1 -- 查询不同部门的平均工资
2 select deptno, avg(sal) as "部门平均工资" from emp group by deptno;
3
4 -- 使用了group by 之后select中只能出现分组后的整体信息,不能出现组内的详细信息
5 select deptno, avg(sal) as"部门平均工资", ename from emp group by deptno;
6 select deptno,ename from emp group by deptno;
7 select deptno,job, sal from emp group by deptno, job;
(3)、having
having子句是用来对分组之后的数据进行过滤,因此使用having时通常都会先使用group by, 如果没使用group by但使用了having,则意味着having把所有的记录当做一组来进行过滤。
having子句出现的字段必须的是分组之后的组的整体信息,having子句不允许出现组内的详细信息。另外,尽管select字段中可以出现别名,但是having子句中不能出现字段的别名,只能使用字段最原始的名字。
having和where的异同
相同的:
① 都是对数据过滤,只保留有效的数据
② where和having一样,都不允许出现字段的别名,
③ 只允许出现最原始的字段的名字,此结论在SQL和Oracle都成立
不同:
① where是对原始的记录过滤having是对分组之后的记录过滤
② where必须的写在having的前面,顺序不可顺倒 否则运行出错
1 select count(*) from emp having avg(sal)>1000 --直接使用having语句
2
3 ----统计 输出部门平均工资大的部门的部门编号和部门的平均工资
4 select deptno, avg(sal) "平均工资",count (*)"部门人数",
5 max(sal) as "部门的最高工资"
6 from emp
7 where sal>2000 --where是对原始的记录过滤
8 group by deptno
9 having avg(sal)>3000 --一对分组之后的记录过
10
11 --判断入选语句是否正确
12 select deptno, avg(sal)"平均工资",count (*)"部门人数",
13 max(sal)"部门的最高工资"
14 from emp
15 group by deptno
16 having avg(sal)>300 --对分组之后的记录过滤
17 where sal>2000 --where写在Thaving的后面 error
3、连接查询
连接查询是将两个表或者两个以上的表以一定的连接条件连接起来,从中检索出满足条件的数据。
(1)内连接
4、View视图
视图从代码上看是一个select语句,从逻辑上看被当做一个虚拟表看待。视图可以简化查询、避免了代码的冗余、避免了书写大盆重复的sql语句。
视图不是物理表,是虚拟表,不建议通过视图更新视图所依附的原始表的数据或结构。
(1)如何创建视图
1 create view 视图的名字 as
2 select语句 --select的前后都不能添加begin
(2)注意的问题
1 --创建视图的select语句必须为所有的计算列指定别名
2 create view v$_a as select avg(sal) as "avg_sal" from emp;
3
4 create view v$_a as select avg(sal) from emp; --error
(3)视图的优缺点
视图的优点:简化查询、增加数据的保密性
视图的缺点:增加了数据库维护的成本、视图只是简化了查询,但是并不能加快查询的速度
5、事物管理
(1)事务是用来研究什么的
① 避免数据处于不合理的中间状态,举例:转账
② 怎样保证多用户同时访问同一个数据时呈现给用户的数据是合理的
(2)事务和线程的关系
事务是通过锁来解决并发访问的,线程同步也是通过锁来解决并发访问的 synchronized,所谓并发访问是指多用户同时访问同一个数据
(3)事务和第三方插件的关系
直接使用事务库技术难度很大很多人是借助第三放插件来实现,因此我们一般人不需要细细的研究数据库中事务的语法细节。
第三方插件要想完成预期的功能,一般必须的借助数据库中的事物机制来实现
附录:
索引、存储过程、游标、TL-SQL
郝斌–SQL Server2005学习笔记的更多相关文章
- SQL server2005学习笔记(一)数据库的基本知识、基本操作(分离、脱机、收缩、备份、还原、附加)和基本语法
在软件测试中,数据库是必备知识,假期闲里偷忙,整理了一点学习笔记,共同探讨. 阅读目录 基本知识 数据库发展史 数据库名词 SQL组成 基本操作 登录数据库操作 数据库远程连接操作 数据库分离操作 数 ...
- 【SQL Server学习笔记】Delete 语句、Output 子句、Merge语句
原文:[SQL Server学习笔记]Delete 语句.Output 子句.Merge语句 DELETE语句 --建表 select * into distribution from sys.obj ...
- sql注入学习笔记,什么是sql注入,如何预防sql注入,如何寻找sql注入漏洞,如何注入sql攻击 (原)
(整篇文章废话很多,但其实是为了新手能更好的了解这个sql注入是什么,需要学习的是文章最后关于如何预防sql注入) (整篇文章废话很多,但其实是为了新手能更好的了解这个sql注入是什么,需要学习的是文 ...
- sql注入学习笔记 详解篇
sql注入的原理以及怎么预防sql注入(请参考上一篇文章) https://www.cnblogs.com/KHZ521/p/12128364.html (本章主要针对MySQL数据库进行注入) sq ...
- SQl语句学习笔记(二)
merge into when matched then... when not mached then... merge into t_road_pre_parameter a fr ...
- SQL语句学习笔记
从外部EXCEl文件导入sqlserver数据库操作命令 reconfigure reconfigure go select * into abc1_1 from OPENROWSET('MICROS ...
- SQL server 学习笔记1
1.查询安装的排序规则选项喝当前的排序规则服务器属性 select * from fn_helpcollations(); 2.查看当前服务器的排序规则 select serverproperty(' ...
- sql视图学习笔记--视图
视图是为用户对数据多种显示需求而创建的,其主要用在一下几种情况: (1)限制用户只能访问特定表特定条件的内容,提高系统的安全性. (2)隐藏表结构.创建多种形式的数透视,满足不同用户需求. (3)将复 ...
- sql 嵌套事务学习笔记
以下内容根据此官方文档修改:http://technet.microsoft.com/zh-cn/library/ms189336(v=sql.105).aspx 嵌套事务的使用场景或者说目的主要是为 ...
随机推荐
- spark 变量使用 broadcast、accumulator
broadcast 官方文档描述: Broadcast a read-only variable to the cluster, returning a [[org.apache.spark.broa ...
- iOS开发系列-Shell脚本生成IPA
概述 在公司开发到了测试阶段需要频繁打包交付给测试,看似简单的工作,重复的流程总是感觉不是那么好,我们可以借助苹果提供的编译指令编译项目. 自动化脚本编译打包IPA 常见的iOS项目就是基于xcode ...
- windows使用cmd查看、杀死进程
查看某个进程: netstat -ano | findstr 端口号 杀死某个进程: taskkill /f /pid 进程号
- Sublime Text自定制代码片段(Code Snippets)
在编写代码的整个过程中,开发人员经常会一次又一次的改写或者重用相同的代码段,消除这种重复过程的方法之一是把我们经常用到的代码保存成代码片段(snippets),这使得我们可以方便的检索和使用它们. 为 ...
- Python自学:第五章 对数字列表执行简单的统计计算
>>>digits = [1,2,3,4,5,6,7,8,9,0] >>>mid(digits) 0 >>>max(digits) 9 >& ...
- DELPHI实现类似仿360桌面的程序界面
1.窗体半透明: Alphablend属性为true;Alphablendvalue的值为100 2.窗体透明: formCreate: Self.TransparentColor := True;S ...
- try-catch 捕捉不到异常
code: int _tmain(int argc, _TCHAR* argv[]) { cout << "In main." << endl; //定义 ...
- JAVA入门各种API参考
java sdk: https://docs.oracle.com/javase/8/docs/api/ servlet api: http://tomcat.apache.org/tomcat-8. ...
- day 68 Django基础四之模板系统
Django基础四之模板系统 本节目录 一 语法 二 变量 三 过滤器 四 标签Tags 五 模板继承 六 组件 七 自定义标签和过滤器 八 静态文件相关 一 语法 模板渲染的官方文档 关 ...
- PHP面向对象编程题(方法的实践)
<?php header('content-type:text/html;charset=utf-8'); /*设计一个peron类(有名字,年龄和蛋糕三个属性) 蛋糕一共1000块,是所有人共 ...