巨杉学习笔记 | SequoiaDB MySQL导入导出工具使用实战
本文来自社区用户投稿,感谢这位小伙伴的技术分享
巨杉数据库架构简介
巨杉数据库作为分布式数据库是计算和存储分离架构,由数据库实例层和存储引擎层组成的。存储引擎层负责数据库核心功能比如数据读写存储以及分布式事务管理。数据库实例层也就是这里的的SQL层负责把应用SQL请求处理后发存储引擎层处理,并且把存储引擎层响应结果反馈给应用层。支持结构化实例比如MySQL实例/PG实例/spark实例,也支持非结构化实例比如 Json实例/S3对象存储实例/PosixFs实例等等。这种架构支持的实例类型比较多,方便从传统数据库无缝迁移到巨杉数据库,减小了开发学习成本,之前也跟数据库圈同行交流,他们对架构也是十分认可。

这里的SQL层采用的是MySQL实例,存储引擎层是有三个数据节点和协调节点编目节点组成。其中数据节点就是用来存储数据的,协调节点不存储数据,是用来把MySQL的请求进行路由分发到数据库节点。编目节点用来存储集群的系统信息比如用户信息/分区信息等等。这里用一个容器来模拟一个物理机或云虚拟机,这里设置的是MySQL实例在一个容器里,编目和节点和协调节点放在了一个容器,三个数据节点分别放在一个容器,三个数据节点构成了三个数据组,每个数据组三个副本。Web应用的海量数据是通过分片切分的方式分散给不同的数据节点,像这里的数据ABC通过分片打散到三台机器。
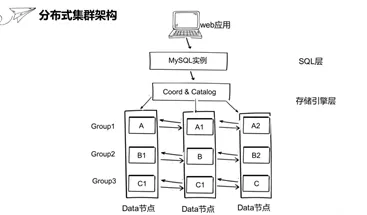
这里的数据分片是通过分布式Hash算法DHT机制实现,DHT是distribute Hashing table 缩写。当写入数据时,首先通过MySQL实例把记录下发到协调节点,协调节点会通过分布式Hash算法根据每条记录的分区键进行散列,散列完之后协调节点根据分区键判断到底发送到哪一个分区,所以每个分区之间的数据是完全隔离互相独立的。采用这种方法,我们就可以把一个很大的表拆散到下面不同的子分区里面小表,实现数据拆分。
mysqldump和 mydumper/myloader 导入导出工具实战
SequoiaDB实现了对MySQL的完整兼容,那么有的用户会问了:
“既然是完整兼容,MySQL相关的工具是否能使用?”
“数据从MySQL迁移到SequoiaDB如何操作?”
下面我们就介绍SequoiaDB如何使用 mysqldump和 mydumper/myloader 进行数据的导入导出。
1. mysqldump
1)通过存储过程制造测试数据
#mysql -h 127.0.0.1 -P -u root
mysql>create database news;
mysql>use news;
mysql>create table user_info(id int(),unickname varchar());
delimiter //
create procedure `news`.`user_info_PROC`()
begin
declare iloop smallint default ;
declare iNum mediumint default ;
declare uid int default ;
declare unickname varchar() default 'test';
while iNum <= do
start transaction;
while iloop<= do
set uid=uid+;
set unickname=CONCAT('test',uid);
insert into `news`.`user_info`(id,unickname)
values(uid,unickname);
set iloop=iloop+;
end while;
set iloop=;
set iNum=iNum+;
commit;
end while;
end//
delimiter ;
call news.user_info_PROC();
2)查看制造测试数据状况
mysql> use news;
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
row in set (0.00 sec)
mysql> select count(*) from user_info;
+----------+
| count(*) |
+----------+
| |
+----------+
row in set (0.01 sec)
3)执行下面mysqldump备份指令
#/opt/sequoiasql/mysql/bin/mysqldump -h 127.0.0.1 -P -u
root -B news > news.sql
查看到对应的文件为news.sql
然后登陆到数据库删除原来的数据库数据
mysql> drop database news;
Query OK, row affected (0.10 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
rows in set (0.00 sec)
4)用source导入新的数据
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P -u root
使用mysqldump导出的完整sql语句,直接登陆数据库执行导入即可:
#/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P -u root
mysql>source news.sql
mysql> use news;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with-A
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
row in set (0.00 sec)
可以看到返回结果,的确支持mysqldump数据导出工具和source导入工具。
2. mydumper和myloader使用
这一章节将介绍有关mydumper和myloader工具的使用。
有的同学对于mysqldump与mydumper有点混淆:mysqldump是MySQL原厂自带的。mydumper/myloader是由MySQL /Facebook等公司开发维护的一套逻辑备份恢复工具,DBA较常使用,需要单独安装,具体安装方式可以在网络上进行查询。
针对SequoiaDB使用mydumper/myloader的情况,
我们首先查看mydumper版本号
# mydumper --version
mydumper 0.9., built against MySQL 5.7.
1)mydumper导出数据
# mydumper -h 127.0.0.1 -P -u root -B news -o /home/sequoiadb
删除原来的数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| news |
| performance_schema |
| sys |
+--------------------+
rows in set (0.00 sec)
mysql> drop database news;
Query OK, row affected (0.13 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
rows in set (0.00 sec)
2)myloader 导入数据
可以看到数据已经被删除,利用myloader导入数据
#myloader -h 127.0.0.1 -P -u root -B news -d /home/sequoiadb
登陆到数据库中查看
# /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P -u root mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| news |
| performance_schema |
| sys |
+--------------------+
rows in set (0.00 sec)
mysql> use news;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_news |
+----------------+
| user_info |
+----------------+
row in set (0.00 sec)
mysql> select count(*) from user_info;
+----------+
| count(*) |
+----------+
| |
+----------+
row in set (0.00 sec)
mydumper 及 myloader 导入数据没问题,看来巨杉数据库 Sequoiadb 的确支持 MySQL 的兼容工具 mydumper 及 myloader。
迁移 MySQL 数据库数据只需要把 MySQL 数据利用 mydumper 导出之后,在巨杉数据库利用 myloader 导入到巨杉数据库即可。
总结
巨杉数据库采用计算-存储分离的架构,实现了MySQL的100%完整兼容。通过本文,我们也可以看到,巨杉数据库可以支持所有标准MySQL的周边工具,同时分布式可扩展性将大大提升已有应用的扩展性以及整体数据管理能力。因此,巨杉数据库SequoiaDB可以说是传统单点MySQL方案的一种有力替换。
巨杉学习笔记 | SequoiaDB MySQL导入导出工具使用实战的更多相关文章
- Mysql导入导出工具Mysqldump和Source命令用法详解
Mysql本身提供了命令行导出工具Mysqldump和Mysql Source导入命令进行SQL数据导入导出工作,通过Mysql命令行导出工具Mysqldump命令能够将Mysql数据导出为文本格式( ...
- [转]Mysql导入导出工具Mysqldump和Source命令用法详解
Mysql本身提供了命令行导出工具Mysqldump和Mysql Source导入命令进行SQL数据导入导出工作,通过Mysql命令行导出工具Mysqldump命令能够将Mysql数据导出为文本格式( ...
- Java基础学习总结(49)——Excel导入导出工具类
在项目的pom文件中引入 <dependency> <groupId>net.sourceforge.jexcelapi</groupId> <artifac ...
- MongoDB 学习笔记之 MongoDB导入导出
MongoDB数据导入导出: mongoexport: -host 机器 -port 端口 -u 用户名 -p 密码 -d 库名 -c 表名 -f 列名 -o 导出的文件名 -q 查询条件 --csv ...
- 好记性不如烂笔头-linux学习笔记3mysql数据库导入导出
1 数据库文件导出 mysqldump -uroot -p123456 test > 1.sql 2数据库文件导入 mysql -uroot -p123456 test <1.sql 3 ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL 导入数据
1.mysql 命令导入 使用 mysql 命令导入语法格式为: mysql -u用户名 -p密码 < 要导入的数据库数据(runoob.sql) 实例: # mysql -uroot -p12 ...
- sqlserver自带的导入导出工具,分别导入大批量mysql和oracle数据时的感受
sqlserver自带的导入导出工具,分别导入大批量mysql和oracle数据时,mysql经常出现格式转换出错,不好导入 导入的数据量比较大时,还不如自己写个工具导入 今天在导oracle时,想 ...
- MySQL多线程数据导入导出工具Mydumper
http://afei2.sinaapp.com/?p=456 今天在线上使用mysqldump将数据表从一个库导入到另外一个库,结果速度特别慢,印象中有个多线程的数据导入导出工具Mydumper,于 ...
- ArcGIS案例学习笔记_3_2_CAD数据导入建库
ArcGIS案例学习笔记_3_2_CAD数据导入建库 计划时间:第3天下午 内容:CAD数据导入,建库和管理 目的:生成地块多边形,连接属性,管理 问题:CAD存在拓扑错误,标注位置偏移 教程:pdf ...
随机推荐
- Mybaits(9)MyBatis级联-2
一.鉴别器和一对多级联 1.完善体检表,分为男雇员体检和女雇员体检表 (1)持久层dao编写 package com.xhbjava.dao; import com.xhbjava.domain.Ma ...
- JUnit套件测试(共通类测试)
@RunWith(Suite.class)@Suite.SuiteClasses({ TestClass1.class, TestClass2.class })public class SuiteTe ...
- docker - 如何清理硬盘中无关占用
背景 在使用docker进行容器化管理后会发现本次硬盘文件占用量在不断上升,并且即使是删除掉容器或者镜像也并不能释放掉对应的硬盘空间.本文将提供对应的docker命令用于真正释放掉该部分应被删除释放的 ...
- 纪中21日c组T2 2117. 【2016-12-30普及组模拟】台风
2117. 台风 (File IO): input:storm.in output:storm.out 时间限制: 1000 ms 空间限制: 262144 KB 具体限制 Goto Proble ...
- 三维偏序[cdq分治学习笔记]
三维偏序 就是让第一维有序 然后归并+树状数组求两维 cdq+cdq不会 告辞 #include <bits/stdc++.h> // #define int long long #def ...
- 使用mysql8.+版本,使用mybatis的代码生成工具:mybatis-generator连接数据库时Unknown initial character set index '255' received from server. Initial client character set can be forced via the 'characterEncoding' property.
Error connecting to database: (using class org.gjt.mm.mysql.Driver)Unknown initial character set ind ...
- ASP.NET常用内置对象(三)Server
Server对象是HttpServerUtility的一个实例,也是上下文对象HttpContext的一个属性,提供用于处理Web请求的Helper方法. Server.MapPath("& ...
- 使用git将本地项目上传至git仓库
个人博客 地址:https://www.wenhaofan.com/article/20190508220440 介绍 一般来说开发过程中都是先在git创建远程仓库,然后fetch到本地仓库,再进行c ...
- .NetCore学习笔记:三、基于AspectCore的AOP事务管理
AOP(面向切面编程),通过预编译方式和运行期间动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是函数式编程的一种衍生范型.利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑 ...
- 【E20200102-1】centos 7 下vsftp的安装和配置
一.准备工作 1.1.服务器准备 操作系统:centos 7.x 关闭防火墙(firewall/iptables)和SELinux 参见笔记<[E20200101-1]Centos 7.x 关闭 ...