Lucene之查询索引
Query子类
TermQuery:根据域和关键词进行搜索
/**
* termQuery根据域和关键词进行搜索
*/
@Test
public void termQuery() throws IOException {
//1.创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\\Luene资料\\Index").toPath());
//2.创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//3.创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//4.创建Query查询对象
Query query=new TermQuery(new Term("fieldContent","spring"));
//5.执行查询,获取到文档对象
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("共获取:"+topDocs.totalHits+"个文档~~~~~~~~~~~~~~~~~~~~~");
//6.获取文档列表
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc item:scoreDocs) {
//获取文档ID
int docId=item.doc;
//取出文档
Document doc = indexSearcher.doc(docId);
//获取到文档域中数据
System.out.println("fieldName:"+doc.get("fieldName"));
System.out.println("fieldPath:"+doc.get("fieldPath"));
System.out.println("fieldSize:"+doc.get("fieldSize"));
System.out.println("fieldContent:"+doc.get("fieldContent"));
System.out.println("==============================================================");
}
//7.关闭资源
indexReader.close();
}
结果
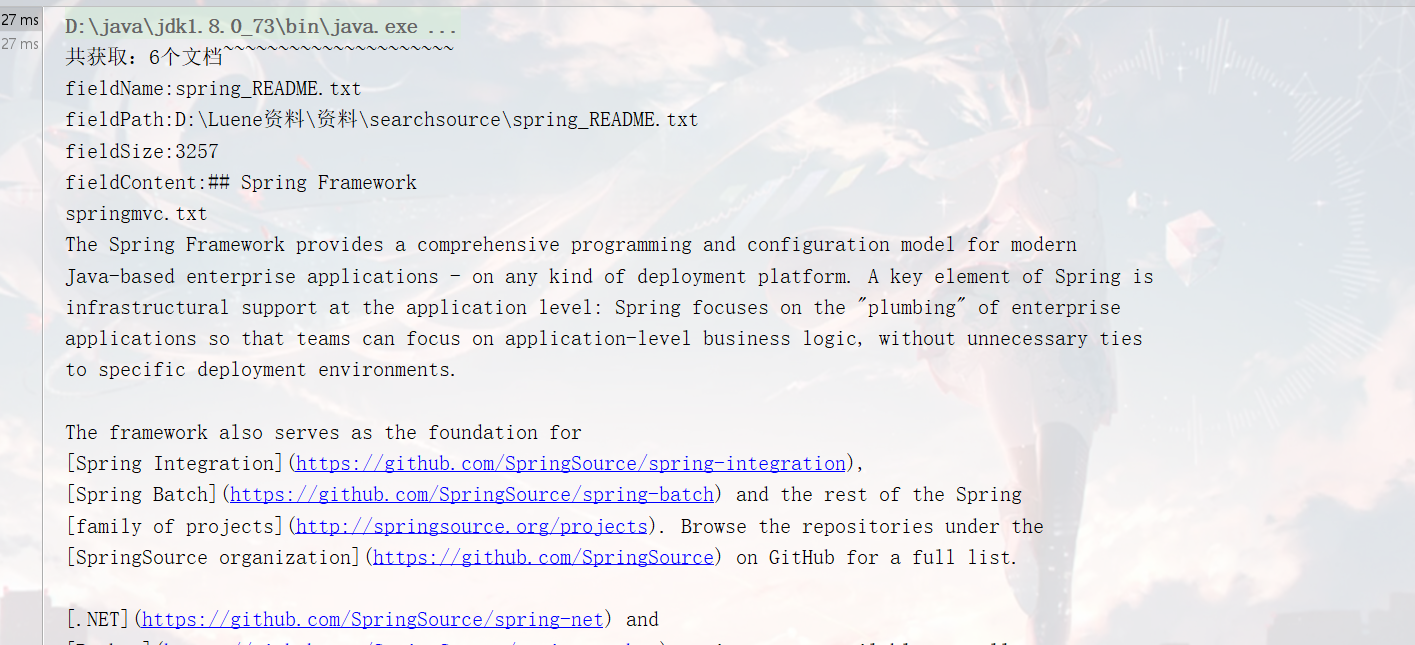
RangeQuery:范围搜索
/**
* RangeQuery范围搜素
*/
@Test
public void RangeQuery() throws IOException {
//创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\\Luene资料\\Index").toPath());
//创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//设置范围搜索的条件 参数一范围所在的域
Query query= LongPoint.newRangeQuery("fieldSize",0,50);
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
} //关闭
indexReader.close();
}
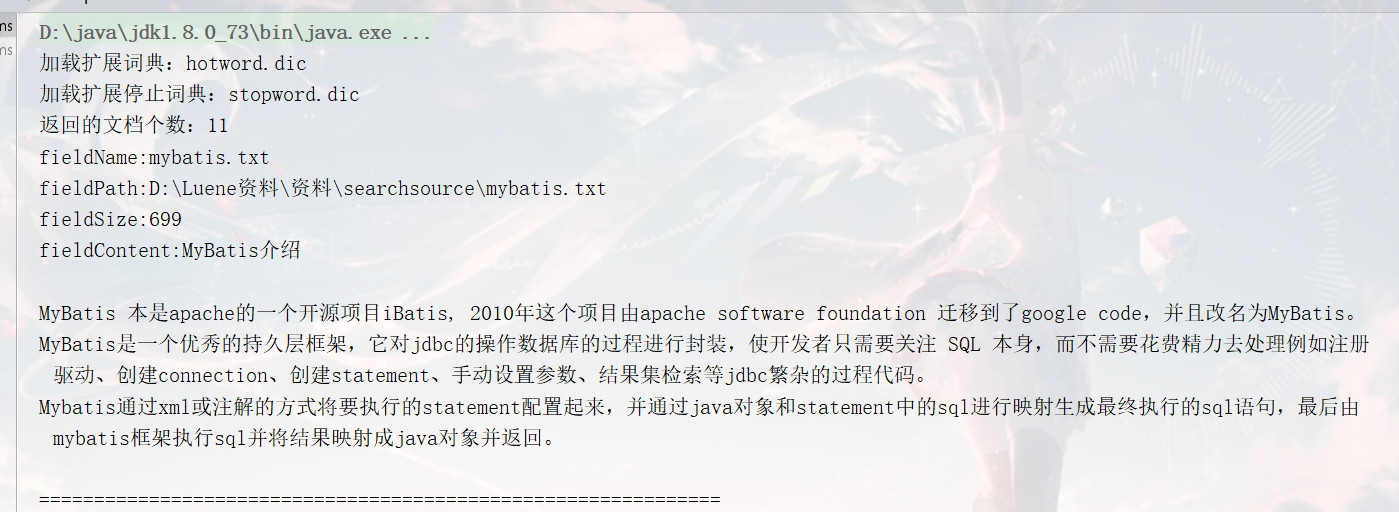
结果

QueryParser:匹配一行数据,这一行数据会自动进行分词
/**
* queryparser搜素,会将搜索条件分词
*/
@Test
public void queryparser() throws IOException, ParseException {
//创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\\Luene资料\\Index").toPath());
//创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建一个QueryParser对象 参数一:查询的域 参数二:使用哪种分析器
QueryParser parser=new QueryParser("fieldContent",new IKAnalyzer());
//设置匹配的数据条件
Query query = parser.parse("Lucene是一个开源的基于Java的搜索库");
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
}
//关闭
indexReader.close();
}
结果
Lucene之查询索引的更多相关文章
- 全文检索Lucene框架---查询索引
一. Lucene索引库查询 对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name ...
- lucene入门查询索引——(三)
1.用户接口(lucene不提供)
- 搜索引擎学习(三)Lucene查询索引
一.查询理论 创建查询:构建一个包含了文档域和语汇单元的文档查询对象.(例:fileName:lucene) 查询过程:根据查询对象的条件,在索引中找出相应的term,然后根据term找到对应的文档i ...
- Lucene查询索引(分页)
分页查询只需传入每页显示记录数和当前页就可以实现分页查询功能 Lucene分页查询是对搜索返回的结果进行分页,而不是对搜索结果的总数量进行分页,因此我们搜索的时候都是返回前n条记录 package c ...
- Lucene查询索引
索引创建 以新闻文档为例,每条新闻是一个document,新闻有news_id.news_title.news_source.news_url.news_abstract.news_keywords这 ...
- lucene查询索引库、分页、过滤、排序、高亮
2.查询索引库 插入测试数据 xx.xx. index. ArticleIndex @Test public void testCreateIndexBatch() throws Exception{ ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
- lucene查询索引之QueryParser解析查询——(八)
0.语法介绍:
- lucene查询索引之Query子类查询——(七)
0.文档名字:(根据名字索引查询文档)
随机推荐
- epel-release的卸载重装
1.yum remove epel-release 2.清空epel目录:rm -rf /var/cache/yum/x86_64/6/epel/ 3.安装,yum install epel-rel ...
- ios--->帧动画
帧动画 NSMutableArray<UIImage *> *imageArr=[NSMutableArray array]; for(int i=0;i<20;i++){ NSSt ...
- V8垃圾回收?看这篇就够了!
什么是内存管理 内存管理是控制和协调应用程序访问电脑内存的过程.这个过程是复杂的,对于我们来说,可以说相当于一个黑匣子. 当咱们的应用程序运行在某个操作系统中的时候,它访问电脑内存(RAM)来达成下列 ...
- SMB信息泄露
开门见山 1. 用netdiscover -r 扫描与攻击机同一网段的靶机,发现PCS 2. 扫描靶场开放信息 3. 挖掘靶场全部信息 4. 针对SMB协议,使用空口令,若口令尝试登录,并查看敏感文件 ...
- PyCharm安装和使用教程(Windows系统)
说明: PyCharm 是一款功能强大的 Python 编辑器, 本文简单的介绍下PyCharm 在 Windows下是如何安装的. PyCharm 的下载地址:http://www.jetbrain ...
- .net core控制台使用log4net
第一步,Nuget log4net包 第二步,在项目中添加一个新xml文件,我这里是直接从.net framework的项目里复制过来的config文件,不过效果是一样的 内容如下: ?xml ver ...
- sockaddr与sockaddr_in的关系
WIN7+VS2013 sockaddr // // Structure used to store most addresses. // typedef struct sockaddr { #if ...
- C++ STL IO流 与 Unicode (UTF-16 UTF-8) 的协同工作
09年研究技术的大神真的好多,本文测试有很多错误,更正后发布下(可能与编辑器相关). file.imbue(locale(file.getloc(), new codecvt_utf8<wcha ...
- 【WPF学习】第四十章 画刷
画刷填充区域,不管是元素的背景色.前景色以及边框,还是形状的内部填充和笔画(Stroke).最简单的画刷类型是SolidColorBrush,这种画刷填充一种固定.连续的颜色.在XAML中设置形状的S ...
- Zabbix监控实现跨区域跨网络监控数据
Zabbix监控实现跨区域跨网络监控数据 环境: 公司现有服务器10台,其中5台服务器有一台安装了zabbix,并且这5台服务器处于一个网络,只有一台服务器有公网ip, 另外的5台处于另一个网络,仅有 ...