使用 LinkedBlockingQueue 实现简易版线程池
一、线程池设计

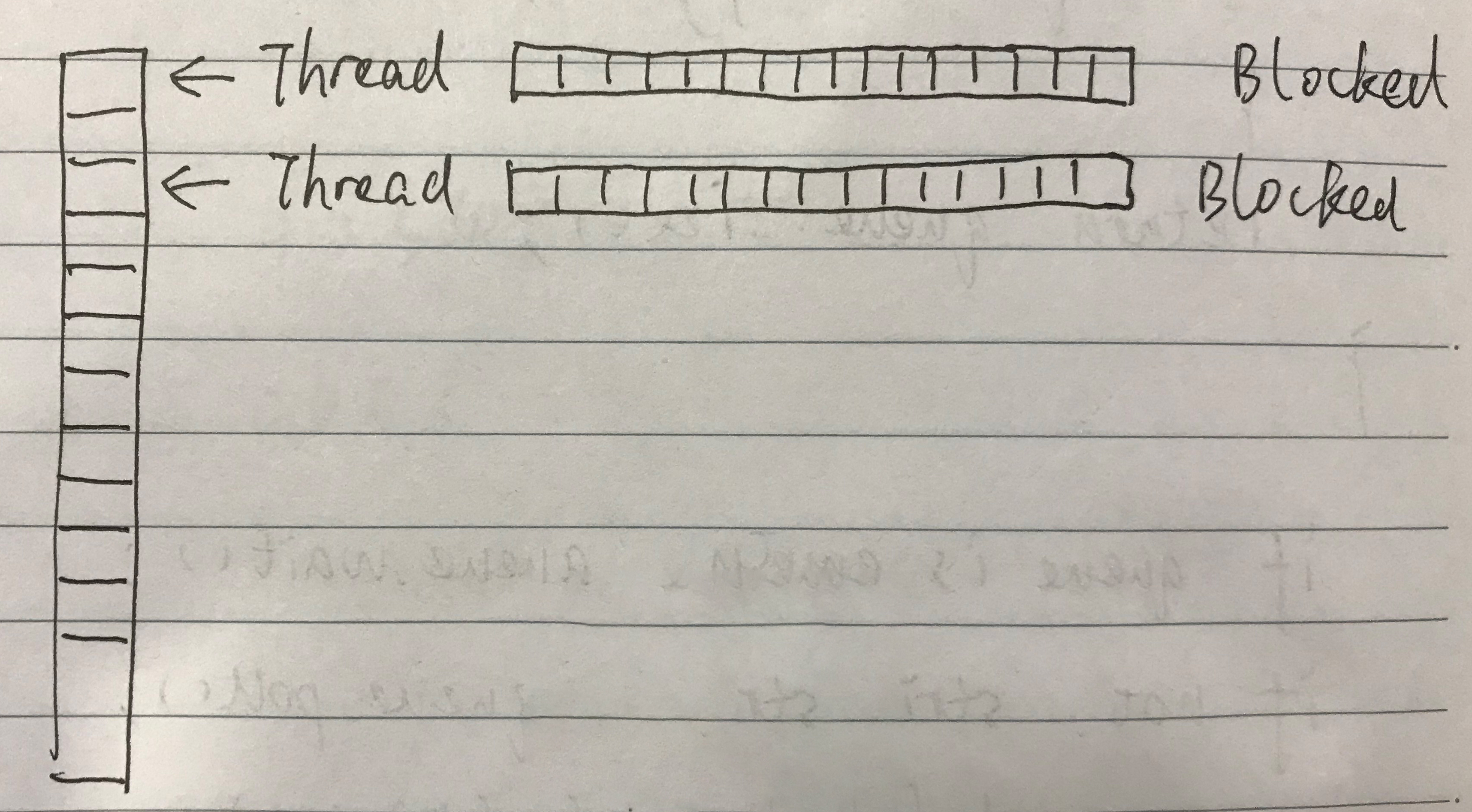
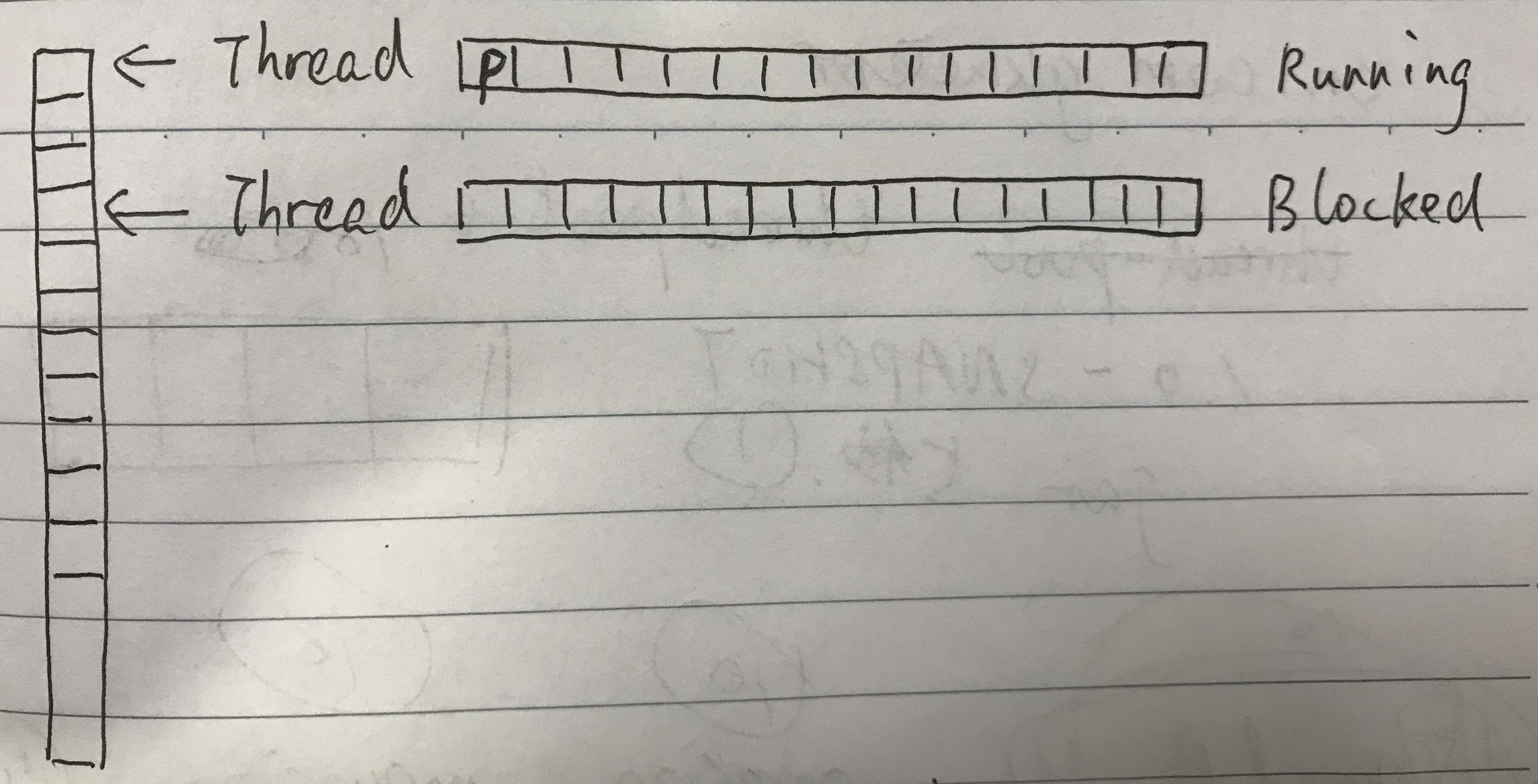

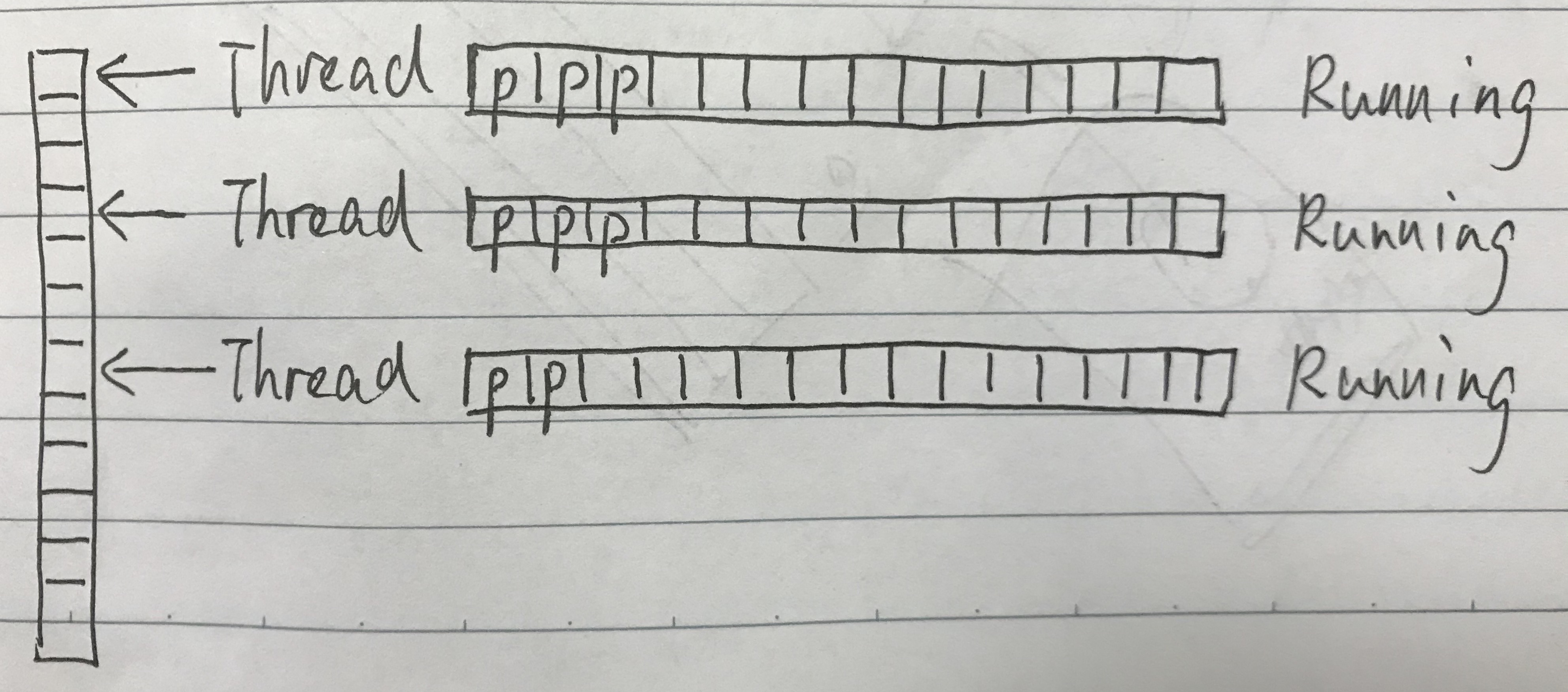
二、为什么使用 LinkedBlockingQueue
1. BlockingQueue
2. ArrayBlockingQueue
3. DelayQueue
4. LinkedBlockingQueue
5. PriorityBlockingQueue
6. SynchronousQueue
package java.util.concurrent; /**
* 带有缓存的线程池
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
7. 阻塞队列选择
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE)。对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReentrantLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
三、LinkedBlockingQueue 底层方法
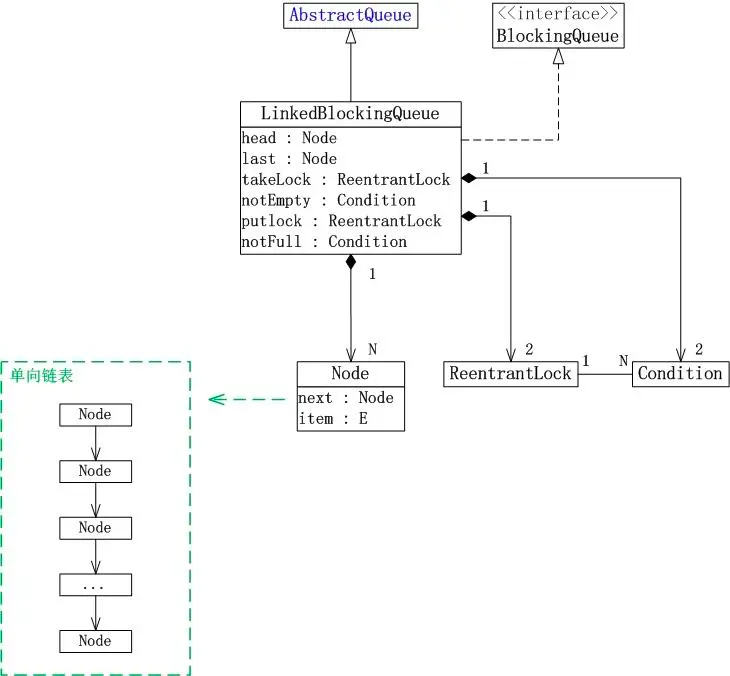
- LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。
- LinkedBlockingQueue实现了BlockingQueue接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
- LinkedBlockingQueue是通过单链表实现的。
- head是链表的表头。取出数据时,都是从表头head处获取。
- last是链表的表尾。新增数据时,都是从表尾last处插入。
- count是链表的实际大小,即当前链表中包含的节点个数。
- capacity是列表的容量,它是在创建链表时指定的。
- putLock是插入锁,takeLock是取出锁;notEmpty是“非空条件”,notFull是“未满条件”。通过它们对链表进行并发控制。
// 容量
private final int capacity; // 当前数量
private final AtomicInteger count = new AtomicInteger(0); // 链表的表头
transient Node<E> head; // 链表的表尾
private transient Node<E> last; // 用于控制删除元素的【取出锁】和锁对应的【非空条件】
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition(); // 用于控制添加元素的【插入锁】和锁对应的【非满条件】
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFull = putLock.newCondition();
- 对于插入操作,通过 putLock(插入锁)进行同步
- 对于取出操作,通过 takeLock(取出锁)进行同步
LinkedBlockingQueue 常用函数
// 创建一个容量为 Integer.MAX_VALUE 的 LinkedBlockingQueue
LinkedBlockingQueue() // 创建一个容量是 Integer.MAX_VALUE 的 LinkedBlockingQueue,最初包含给定 collection 的元素,元素按该 collection 迭代器的遍历顺序添加
LinkedBlockingQueue(Collection<? extends E> c) // 创建一个具有给定(固定)容量的 LinkedBlockingQueue
LinkedBlockingQueue(int capacity) // 从队列彻底移除所有元素
void clear() // 将指定元素插入到此队列的尾部(如果立即可行且不会超出此队列的容量),在成功时返回 true,如果此队列已满,则返回 false
boolean offer(E e) // 将指定元素插入到此队列的尾部,如有必要,则等待指定的时间以使空间变得可用
boolean offer(E e, long timeout, TimeUnit unit) // 获取但不移除此队列的头;如果此队列为空,则返回 null
E peek() // 获取并移除此队列的头,如果此队列为空,则返回 null
E poll() // 获取并移除此队列的头部,在指定的等待时间前等待可用的元素(如果有必要)
E poll(long timeout, TimeUnit unit) // 将指定元素插入到此队列的尾部,如有队列满,则等待空间变得可用
void put(E e) // 返回理想情况下(没有内存和资源约束)此队列可接受并且不会被阻塞的附加元素数量
int remainingCapacity() // 从此队列移除指定元素的单个实例(如果存在)
boolean remove(Object o) // 返回队列中的元素个数
int size() // 获取并移除此队列的头部,在元素变得可用之前一直等待(如果有必要)
E take()
/**
* 将指定元素插入到此队列的尾部(如果立即可行且不会超出此队列的容量)
* 在成功时返回 true,如果此队列已满,则返回 false
* 如果使用了有容量限制的队列,推荐使用add方法,add方法在失败的时候只是抛出异常
*/
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity)
// 如果队列已满,则返回false,表示插入失败
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// 获取 putLock
putLock.lock();
try {
// 再次对【队列是不是满】的进行判断,如果不是满的,则插入节点
if (count.get() < capacity) {
enqueue(node); // 在队尾插入节点
c = count.getAndIncrement(); // 当前节点数量+1,并返回插入之前节点数量
if (c + 1 < capacity)
// 如果在插入元素之后,队列仍然未满,则唤醒notFull上的等待线程
notFull.signal();
}
} finally {
// 释放 putLock
putLock.unlock();
}
if (c == 0)
// 如果在插入节点前,队列为空,那么插入节点后,唤醒notEmpty上的等待线程
signalNotEmpty();
return c >= 0;
}
下面来看看 put(E e) 的源码:
/**
* 将指定元素插入到此队列的尾部,如有队列满,则等待空间变得可用
*
* @throws InterruptedException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException(); int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly(); // 可中断地获取 putLock
try {
// count 变量是被 putLock 和 takeLock 保护起来的,所以可以真实反映队列当前的容量情况
while (count.get() == capacity) {
notFull.await();
}
enqueue(node); // 在队尾插入节点
c = count.getAndIncrement(); // 当前节点数量+1,并返回插入之前节点数量
if (c + 1 < capacity)
// 如果在插入元素之后,队列仍然未满,则唤醒notFull上的等待线程
notFull.signal();
} finally {
putLock.unlock(); // 释放 putLock
}
if (c == 0)
// 如果在插入节点前,队列为空,那么插入节点后,唤醒notEmpty上的等待线程
signalNotEmpty();
}
/**
* 通知一个等待的take。该方法应该仅仅从put/offer调用,否则一般很难锁住takeLock
*/
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock(); // 获取 takeLock
try {
notEmpty.signal(); // 唤醒notEmpty上的等待线程,意味着现在可以获取元素了
} finally {
takeLock.unlock(); // 释放 takeLock
}
}
/**
* 获取并移除此队列的头,如果此队列为空,则返回 null
*/
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0)
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock(); // 获取 takeLock
try {
if (count.get() > 0) {
x = dequeue(); // 获取队头元素,并移除
c = count.getAndDecrement(); // 当前节点数量-1,并返回移除之前节点数量
if (c > 1)
// 如果在移除元素之后,队列中仍然有元素,则唤醒notEmpty上的等待线程
notEmpty.signal();
}
} finally {
takeLock.unlock(); // 释放 takeLock
}
if (c == capacity)
// 如果在移除节点前,队列是满的,那么移除节点后,唤醒notFull上的等待线程
signalNotFull();
return x;
}
/**
* 取出并返回队列的头。若队列为空,则一直等待
*/
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
// 获取 takeLock,若当前线程是中断状态,则抛出InterruptedException异常
takeLock.lockInterruptibly();
try {
// 若队列为空,则一直等待
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue(); // 从队头取出元素
c = count.getAndDecrement(); // 取出元素之后,节点数量-1;并返回移除之前的节点数量
if (c > 1)
// 如果在移除元素之后,队列中仍然有元素,则唤醒notEmpty上的等待线程
notEmpty.signal();
} finally {
takeLock.unlock(); // 释放 takeLock
} if (c == capacity)
// 如果在取出元素之前,队列是满的,就在取出元素之后,唤醒notFull上的等待线程
signalNotFull();
return x;
}
/**
* 唤醒notFull上的等待线程,只能从 poll 或 take 调用
*/
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock(); // putLock 上锁
try {
notFull.signal(); // 唤醒notFull上的等待线程,意味着可以插入元素了
} finally {
putLock.unlock(); // putLock 解锁
}
}
四、简易版线程池代码实现
1. 注册成为 Spring Bean
package cn.com.gkmeteor.threadpool.utils; @Component
public class ThreadPoolUtil implements InitializingBean { public static int POOL_SIZE = 10; @Autowired
private ThreadExecutorService threadExecutorService; // 具体的线程处理类 private List<ThreadWithQueue> threadpool = new ArrayList<>(); /**
* 在所有基础属性初始化完成后,初始化当前类
*
* @throws Exception
*/
@Override
public void afterPropertiesSet() throws Exception {
for (int i = 0; i < POOL_SIZE; i++) {
ThreadWithQueue threadWithQueue = new ThreadWithQueue(i, threadExecutorService);
this.threadpool.add(threadWithQueue);
}
}
}
2. 轮询获取一个线程
public static int POOL_SIZE = 10; // 线程池容量
index = (++index) % POOL_SIZE; // index 是当前选中的线程下标
3. 参数入队和出队,线程运行和阻塞
package cn.com.gkmeteor.threadpool.utils; import cn.com.gkmeteor.threadpool.service.ThreadExecutorService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import java.util.concurrent.BlockingQueue; /**
* 带有【参数阻塞队列】的线程
*/
public class ThreadWithQueue extends Thread { public static int CAPACITY = 10; private Logger logger = LoggerFactory.getLogger(ThreadWithQueue.class); private BlockingQueue<String> queue; private ThreadExecutorService threadExecutorService; // 线程运行后的业务逻辑处理 private String threadName; public String getThreadName() {
return threadName;
} public void setThreadName(String threadName) {
this.threadName = threadName;
} /**
* 构造方法
*
* @param i 第几个线程
* @param threadExecutorService 线程运行后的业务逻辑处理
*/
public ThreadWithQueue(int i, ThreadExecutorService threadExecutorService) {
queue = new java.util.concurrent.LinkedBlockingQueue<>(CAPACITY);
threadName = "Thread(" + i + ")"; this.threadExecutorService = threadExecutorService; this.start();
} /**
* 将参数放到线程的参数队列中
*
* @param param 参数
* @return
*/
public String paramAdded(String param) {
String result = "";
if(queue.offer(param)) {
logger.info("参数已入队,{} 目前参数个数 {}", this.getThreadName(), queue.size());
result = "参数已加入线程池,等待处理";
} else {
logger.info("队列已达最大容量,请稍后重试");
result = "线程池已满,请稍后重试";
}
return result;
} public synchronized int getQueueSize() {
return queue.size();
} @Override
public void run() {
while (true) {
try {
String param = queue.take();
logger.info("{} 开始运行,参数队列中还有 {} 个在等待", this.getThreadName(), this.getQueueSize());
if (param.startsWith("contact")) {
threadExecutorService.doContact(param);
} else if (param.startsWith("user")) {
threadExecutorService.doUser(param);
} else {
logger.info("参数无效,不做处理");
}
logger.info("{} 本次处理完成", this.getThreadName());
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
了解了链接阻塞队列的底层方法后,使用起来就底气十足。具体来说:
五、总结
六、参考资料
- 阻塞队列,https://blog.csdn.net/f641385712/article/details/83691365
- 数组阻塞队列和链接阻塞队列,同事博客,https://blog.csdn.net/a314368439/article/details/82789367
- 链接阻塞队列,https://www.jianshu.com/p/9394b257fdde
- 延迟队列,https://blog.csdn.net/z69183787/article/details/80520851
- 优先级阻塞队列,https://blog.csdn.net/java_jsp_ssh/article/details/78515866
- 同步队列,https://segmentfault.com/a/1190000011207824
使用 LinkedBlockingQueue 实现简易版线程池的更多相关文章
- Java多线程之Executor框架和手写简易的线程池
目录 Java多线程之一线程及其基本使用 Java多线程之二(Synchronized) Java多线程之三volatile与等待通知机制示例 线程池 什么是线程池 线程池一种线程使用模式,线程池会维 ...
- python low版线程池
1.low版线程池设计思路:运用队列queue 将线程类名放入队列中,执行一个就拿一个出来import queueimport threading class ThreadPool(object): ...
- Java与Scala的两种简易版连接池
Java版简易版连接池: import java.sql.Connection; import java.sql.DriverManager; import java.util.LinkedList; ...
- 用java自制简易线程池(不依赖concurrent包)
很久之前人们为了继续享用并行化带来的好处而不想使用进程,于是创造出了比进程更轻量级的线程.以linux为例,创建一个进程需要申请新的自己的内存空间,从父进程拷贝一些数据,所以开销是比较大的,线程(或称 ...
- 简易线程池Thread Pool
1. 基本思路 写了个简易的线程池,基本的思路是: 有1个调度线程,负责维护WorkItem队列.管理线程(是否要增加工作线程).调度(把工作项赋给工作线程)等 线程数量随WorkItem的量动态调整 ...
- 基于Win32 SDK实现的一个简易线程池
利用C++实现了一个简易的线程池模型(基于Win32 SDK),方便使用多线程处理任务.共包含Thread.h.Thread.cpp.ThreadPool.h.ThreadPool.cpp四个源文件. ...
- Java线程池实现原理与技术(ThreadPoolExecutor、Executors)
本文将通过实现一个简易的线程池理解线程池的原理,以及介绍JDK中自带的线程池ThreadPoolExecutor和Executor框架. 1.无限制线程的缺陷 多线程的软件设计方法确实可以最大限度地发 ...
- Java中的线程池用过吧?来说说你是怎么理解线程池吧?
前言 Java中的线程池用过吧?来说说你是怎么使用线程池的?这句话在面试过程中遇到过好几次了.我甚至这次标题都想写成[Java八股文之线程池],但是有点太俗套了.虽然,线程池是一个已经被说烂的知识点了 ...
- Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
随机推荐
- Linux 旗标实现
Linux 内核提供了一个遵守上面语义的旗标实现, 尽管术语有些不同. 为使用旗标, 内核 代码必须包含 <asm/semaphore.h>. 相关的类型是 struct semaphor ...
- Linux 内核存取 I/O 和内存空间
一个 PCI 设备实现直至 6 个 I/O 地址区. 每个区由要么内存要么 I/O 区组成. 大部分 设备实现它们的 I/O 寄存器在内存区中, 因为通常它是一个完善的方法(如同在" I/O ...
- 阿里云 CentOS8 Repo
# CentOS-Base.repo # # The mirror system uses the connecting IP address of the client and the # upda ...
- ZOJ3537 Cake
ZOJ3537 Cake 传送门:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3537 题意: 给你几何形状的蛋糕,你需要 ...
- js获取url参数值的方式
定义方法: function getParam(paramName) { paramValue = ""; isFound = false; paramName = paramNa ...
- 关于启动php-fpm失败的解决办法
当我执行 sudo lnmp php-fpm restart会出现如下错误 Starting php-fpm /usr/local/php/sbin/php-fpm: error while load ...
- JMeter FTP测试计划
为了演示测试目的,我们将使用公共可用的FTP位置,可以使用它来测试文件的下载. 您可以使用市场上现有的任何可用的演示FTP位置.我们使用URL下的FTP位置: https://dlptest.com/ ...
- 基于python的二分搜索和例题
二分搜索 二分概念 二分搜索是一种在有序数组中查找某一特定元素的搜索算法. 搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束: 如果某一特定元素大于或者小于中间元素,则在数 ...
- Java8 Date API
一 .Clock 时钟 Clock类提供了访问当前日期和时间的方法,Clock是时区敏感的,可以用来取代 System.currentTimeMillis() 来获取当前的微秒数.某一个特定的时间点也 ...
- OpenVINO 入门
关于OpenVINO 入门,今天给大家分享一个好东西和好消息! 现如今,说人工智能(AI)正在重塑我们的各行各业绝不虚假,深度学习神经网络的研究可谓如火如荼, 但这一流程却相当复杂,但对于初学者来说也 ...