lasso-ridge
L1与L2正则化的区别与联系
L1正则化和L2正则化的说明如下:
L1正则化:\(\min _{w} \frac{1}{2 n_{\text {samples}}}\|X w-y\|_{2}^{2}+\alpha\|w\|_{1}\) 绝对值之和
L2正则化:\(\min _{w}\|X w-y\|_{2}^{2}+\alpha\|w\|_{2}^{2}\) 平方和
L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
L1 L2 区别:
相同点:都用于避免过拟合
不同点:L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
- L2 regularizer :使得模型的解偏向于 norm 较小的 W,通过限制 W 的 norm 的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 ridge regression 并不具有产生稀疏解的能力,得到的系数 仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。会选择更多的特征,这些特征都会接近于0。 最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0
- L1 regularizer :** 它的优良性质是能产生稀疏性,因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵, 导致 W 中许多项变成零。** 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”csdn
L1稀疏性的原因
解空间形状直观理解
带正则项,相当于为目标函数的解空间进行了约束。当参数为2维时,为对于L2正则项,解空间为原型,L1正则项解空间为菱形。最优解必定是有且仅有一个交点。除非目标函数具有特殊的形状,否则和菱形的唯一交点大概率出现在截距处(即对应某一维度参数为0)。而对于圆形的解空间,总存在一个切点,且仅当某些特殊情况下,切点才会位于坐标轴上csdn

而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:
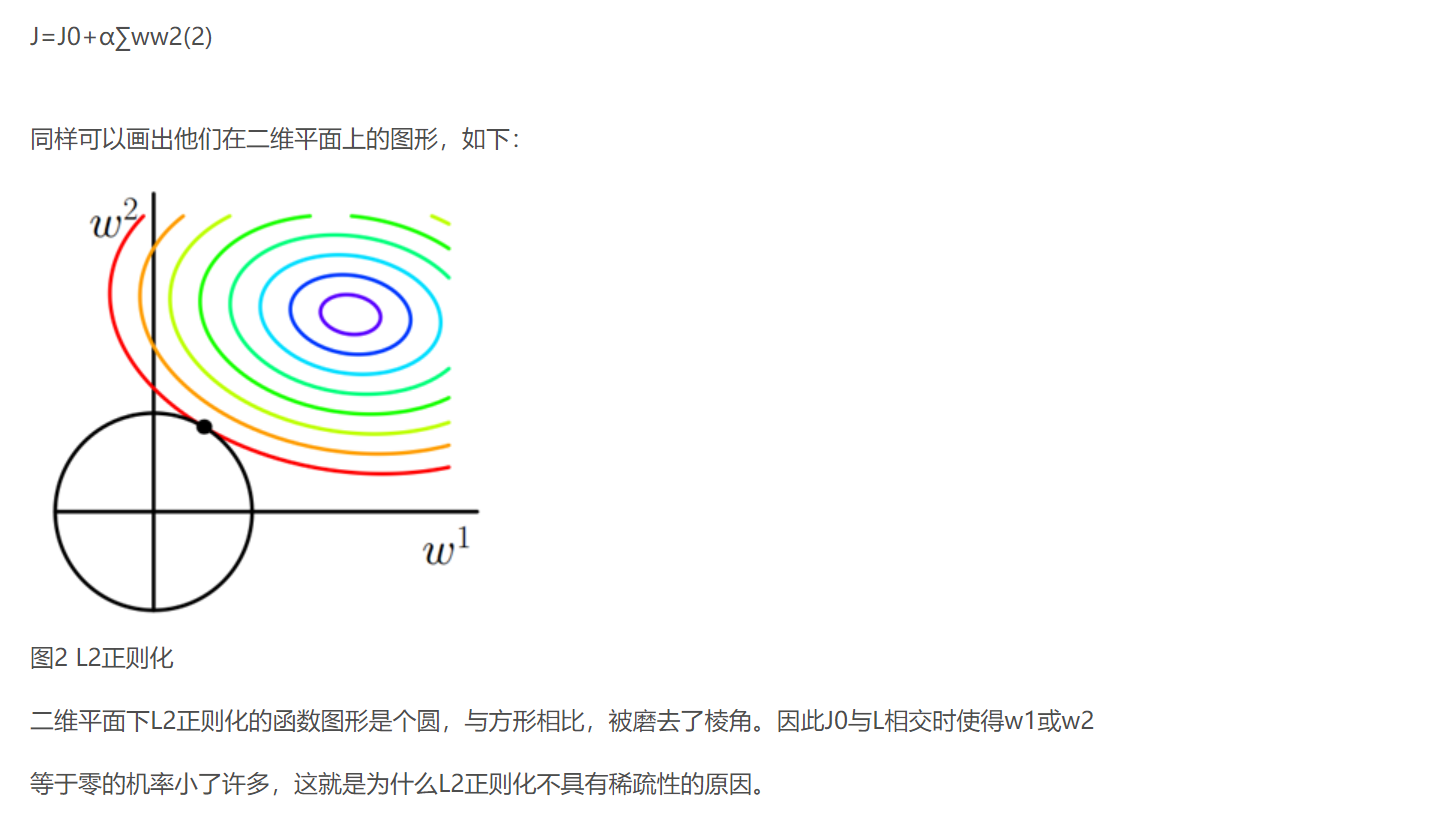

lasso 回归和岭回归(ridge regression)其实就是在标准线性回归的基础上分别加入 L1 和 L2 正则化(regularization)。
正则化
岭回归-Ridge
Loss function = OLS loss function +\(\alpha * \sum_{i=1}^{n} a_{i}^{2}\)
Lasso is great for feature selection, but when building regression models, Ridge regression should be your first choice.
datacamp
# Import necessary modules
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# Setup the array of alphas and lists to store scores
alpha_space = np.logspace(-4, 0, 50)
ridge_scores = []
ridge_scores_std = []
# Create a ridge regressor: ridge
ridge = Ridge(normalize=True)
# Compute scores over range of alphas
# 给出很多a值,调参,就是超参数调参
for alpha in alpha_space:
# Specify the alpha value to use: ridge.alpha
ridge.alpha = alpha
# Perform 10-fold CV: ridge_cv_scores
# 用到了10折交叉验证进行的调参
ridge_cv_scores = cross_val_score(ridge, X, y, cv=10)
# Append the mean of ridge_cv_scores to ridge_scores
ridge_scores.append(np.mean(ridge_cv_scores))
# Append the std of ridge_cv_scores to ridge_scores_std
ridge_scores_std.append(np.std(ridge_cv_scores))
# Display the plot
display_plot(ridge_scores, ridge_scores_std)

Lasso_套索回归(最小绝对值收敛)
Loss function = OLS loss function +\(\alpha * \sum_{i=1}^{n}\left|a_{i}\right|\)
lasso一般用来进行特征选择
- hrinks the coefcients of less important features to exactly 0
# Import Lasso
from sklearn.linear_model import Lasso
# Instantiate a lasso regressor: lasso
lasso = Lasso(alpha=0.4, normalize=True)
# Fit the regressor to the data
lasso.fit(X, y)
# Compute and print the coefficients
lasso_coef = lasso.coef_
print(lasso_coef)
# Plot the coefficients
plt.plot(range(len(df_columns)), lasso_coef)
plt.xticks(range(len(df_columns)), df_columns.values, rotation=60)
plt.margins(0.02)
plt.show()

lasso-ridge的更多相关文章
- 【机器学习】Linear least squares, Lasso,ridge regression有何本质区别?
Linear least squares, Lasso,ridge regression有何本质区别? Linear least squares, Lasso,ridge regression有何本质 ...
- 《机器学习_01_线性模型_线性回归_正则化(Lasso,Ridge,ElasticNet)》
一.过拟合 建模的目的是让模型学习到数据的一般性规律,但有时候可能会学过头,学到一些噪声数据的特性,虽然模型可以在训练集上取得好的表现,但在测试集上结果往往会变差,这时称模型陷入了过拟合,接下来造一些 ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- 变量的选择——Lasso&Ridge&ElasticNet
对模型参数进行限制或者规范化能将一些参数朝着0收缩(shrink).使用收缩的方法的效果提升是相当好的,岭回归(ridge regression,后续以ridge代称),lasso和弹性网络(elas ...
- 再谈Lasso回归 | elastic net | Ridge Regression
前文:Lasso linear model实例 | Proliferation index | 评估单细胞的增殖指数 参考:LASSO回歸在生物醫學資料中的簡單實例 - 生信技能树 Linear le ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- 7 Types of Regression Techniques you should know!
翻译来自:http://news.csdn.net/article_preview.html?preview=1&reload=1&arcid=2825492 摘要:本文解释了回归分析 ...
- 机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho
机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho 总述 本书是 2014 ...
- 深入理解:Linear Regression及其正则方法
这是最近看到的一个平时一直忽略但深入研究后发现这里面的门道还是很多,Linear Regression及其正则方法(主要是Lasso,Ridge, Elastic Net)这一套理论的建立花了很长一段 ...
- Kaggle竞赛 —— 房价预测 (House Prices)
完整代码见kaggle kernel 或 Github 比赛页面:https://www.kaggle.com/c/house-prices-advanced-regression-technique ...
随机推荐
- 5G为人工智能与工业互联网赋能 高清79页PPT
人工智能和5G是时下最热门的科技领域之一,两者都是能改变社会,推进下一代工业革命的颠覆性技术. 工业互联网是利用基础科学.工业.信息技术.互联网等领域的综合优势,从大数据应用等软服务切入,注重软件.网 ...
- 威联通(NAS)搭建个人图床
名词解释: 图床:一般是指储存图片的服务器,有国内和国外之分.国外的图床由于有空间距离等因素决定访问速度很慢影响图片显示速度.国内也分为单线空间.多线空间和cdn加速三种. 更详细的内容,请左转查看百 ...
- 【题解】删数问题(Noip1994)
题目 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 11506 通过数: 3852 [题目描述] 输入一个高精度的正整数n,去掉其中任意s个数字后剩下的数字按原左右次序组成一个新 ...
- javascript 动态加载javascript文件
/* loadFile(data, callback): 动态加载js文件 data: 存放需要加载的js文件的url("url" || ["url", &qu ...
- gitlab CICD/schedules无法按照分钟执行
多条Scheduling Pipelines 设置之后发现执行时间都是某个时间,分钟设置的无效不管用 修改/etc/gitlab/gitlab.rb gitlab_rails['pipeline_sc ...
- 杭电1007-----C语言实现
这道题花了好久的时间才做出来,刚开始没有思路,最后看了网上的解答,好难得样子,每次都没有看完,但是掌握了大概思想,今天试着做了一下,已ac 主要思想:先将点对按照x排序,再在x排好序的基础上按照y来排 ...
- 函数式编程/lambda表达式入门
函数式编程/lambda表达式入门 本篇主要讲解 lambda表达式的入门,涉及为什么使用函数式编程,以及jdk8提供的函数式接口 和 接口的默认方法 等等 1.什么是命令式编程 命令式编程就是我们去 ...
- React之拆分组件与组件之间的传值
父子组件传值: 父组件向子组件传值通过向子组件TodoItem进行属性绑定(content={item}.index={index}),代码如下 getTodoItem () { return thi ...
- 【题解】 2月19日 厦门双十中学NOIP2014模拟D2 T2 采药人接水果
[问题描述] 采药人虽然 AFO(SU),但他在闲暇的时候还是可以玩一玩接水果(cat)的.但他渐渐发现 cat 好像有点太弱智.于是他不想浪费他的智商,于是决定写一个程序帮他玩. cat 是这样玩的 ...
- SAP SD 销售中的借贷项凭证
SAP SD 销售中的借贷项凭证 SAP系统中,正常与客户的应收款都能通过销售订单来实现. 但实际操作中,常有收款后发现价格有误或其他原因需退款客户或补收客户货款的情况,或者客户需要少量的材料,但不能 ...