CUDA学习(四)之使用全局内存进行归约求和(一个包含N个线程的线程块)
问题:使用CUDA进行数组元素归约求和,归约求和的思想是每次循环取半。
详细过程如下:
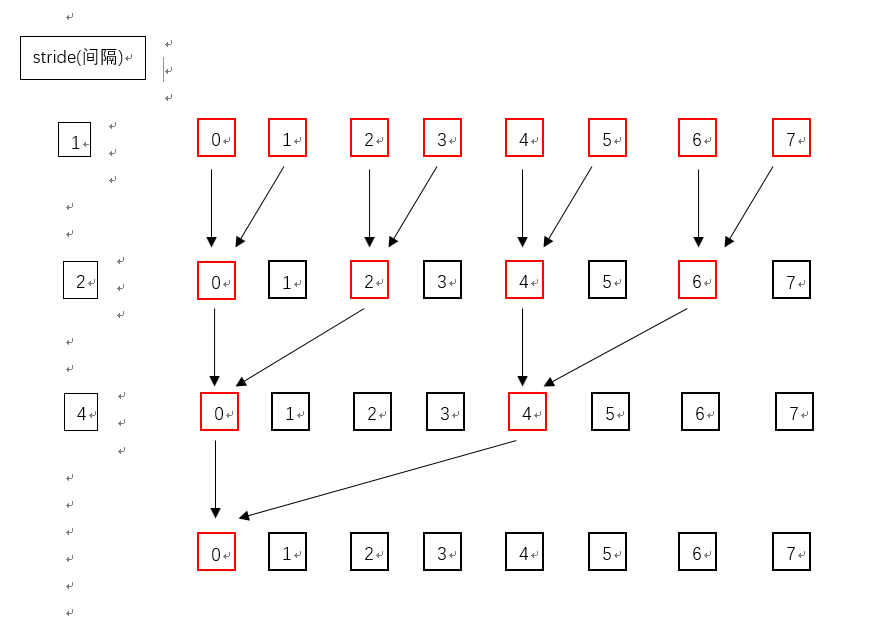
假设有一个包含8个元素的数组,索引下标从0到7,现通过3次循环相加得到这8个元素的和,使用一个间隔变量,该间隔变量随循环次数改变(累乘)。
第一次循环,间隔变量stride等于1,将0与1号元素、2与3号元素、4与5号元素、6与7号元素相加并将结果分别保存在0、2、4、6号元素中(图中红色框所示)。
第二次循环,间隔变量stride等于2,将0与2号元素、4与6号元素相加并将结果分别保存在0、4号元素中(图中红色框所示)。
第三次循环,间隔变量stride等于4,将0与4号元素相加并将结果保存在0号元素中(图中红色框所示)。
三次循环过后,整个数组元素相加之和就保存在数组0号元素中。
代码如下:
#pragma once
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h" #include <iostream> using namespace std; const int N = 128; //数组长度 __global__ void d_ParallelTest(double *Para)
{
int tid = threadIdx.x;
//----随循环次数的增加,stride逐次翻倍(乘以2)-----------------------------------------------------
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if (tid % (2 * stride) == 0)
{
Para[tid] += Para[tid + stride]; //对应上图中红色框的元素
}
__syncthreads();
} } void ParallelTest()
{
double *Para;
cudaMallocManaged((void **)&Para, sizeof(double) * N); //统一内存寻址,CPU和GPU都可以使用的数组 double ParaSum = 0;
for (int i = 0; i<N; i++)
{
Para[i] = (i + 1) * 0.1; //数组赋值
ParaSum += Para[i]; //CPU端数组累加
} cout << " CPU result = " << ParaSum << endl; //显示CPU端结果
double d_ParaSum; d_ParallelTest << < 1, N >> > (Para); //调用核函数(一个包含N个线程的线程块) cudaDeviceSynchronize(); //同步
d_ParaSum = Para[0]; //从累加过后数组的0号元素得出结果
cout << " GPU result = " << d_ParaSum << endl; //显示GPU端结果 } int main() {
//并行归约
ParallelTest(); //调用归约函数 system("pause");
return 0;
}
结果如下所示(CPU和GPU计算结果一致):

CUDA学习(四)之使用全局内存进行归约求和(一个包含N个线程的线程块)的更多相关文章
- 【CUDA 基础】4.0 全局内存
title: [CUDA 基础]4.0 全局内存 categories: - CUDA - Freshman tags: - 全局内存 - CUDA内存模型 - CUDA内存管理 - 全局内存编程 - ...
- CUDA学习(五)之使用共享内存(shared memory)进行归约求和(一个包含N个线程的线程块)
共享内存(shared memory)是位于SM上的on-chip(片上)一块内存,每个SM都有,就是内存比较小,早期的GPU只有16K(16384),现在生产的GPU一般都是48K(49152). ...
- 【CUDA 基础】5.3 减少全局内存访问
title: [CUDA 基础]5.3 减少全局内存访问 categories: - CUDA - Freshman tags: - 共享内存 - 归约 toc: true date: 2018-06 ...
- CUDA学习(七)之使用CUDA内置API计时
问题:对于使用GPU计算时,都想知道kernel函数运行所耗费的时间,使用CUDA内置的API可以方便准确的获得kernel运行时间. 在CPU上,可以使用clock()函数和GetTickCount ...
- CUDA学习笔记(四)——CUDA性能
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5h.html 四.CUDA性能 CUDA中的block被划分成一个个的warp,在GeForce880 ...
- CUDA学习笔记(三)——CUDA内存
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5f.html 结合lec07_intro_cuda.pptx学习 内存类型 CGMA: Compute ...
- cuda学习3-共享内存和同步
为什么要使用共享内存呢,因为共享内存的访问速度快.这是首先要明确的,下面详细研究. cuda程序中的内存使用分为主机内存(host memory) 和 设备内存(device memory),我们在这 ...
- 【CUDA 基础】5.4 合并的全局内存访问
title: [CUDA 基础]5.4 合并的全局内存访问 categories: - CUDA - Freshman tags: - 合并 - 转置 toc: true date: 2018-06- ...
- CUDA学习(六)之使用共享内存(shared memory)进行归约求和(M个包含N个线程的线程块)
在https://www.cnblogs.com/xiaoxiaoyibu/p/11402607.html中介绍了使用一个包含N个线程的线程块和共享内存进行数组归约求和, 基本思路: 定义M个包含N个 ...
随机推荐
- MyBatis学习与使用(一)
写在前面—— 用 MyBatis 也做过几个项目了,但是一直没有很深入的去理解这个框架,最近决定从头开始学习和整理MyBatis. 之前开发的项目并不是我先创建的,等我介入的时候发现他们已经稍稍封装了 ...
- Spring Boot (5) 整合 RabbitMQ
一.前言 RabbitMQ是实现了AMQP(高级消息队列协议)的开源消息中间件,RabbitMQ服务器是用Erlang(面向并发的编程语言)编写的. RabbitMQ官网下载地址:https://ww ...
- 1026 程序运行时间 (15 分)C语言
题目描述 要获得一个C语言程序的运行时间,常用的方法是调用头文件time.h,其中提供了clock()函数,可以捕捉从程序开始运行到clock()被调用时所耗费的时间.这个时间单位是clock tic ...
- Dockerfile文件记录(用于后端项目部署)
Dockerfile文件记录(用于后端项目部署) 本教程依据个人理解并经过实际验证为正确,特此记录下来,权当笔记. 注:基于linux操作系统(敏感信息都进行了处理) 此文结合另一篇博客共同构成后端服 ...
- Qt5学习(2)
1.学习了qt quick application 这是一种跟application不同的设计方式.主要就是靠“拖拖拽拽”,然后设置属性(颜色,大小),布局(margins等),然后要注意控件的从属关 ...
- 关于Itext 报错-java.lang.NoClassDefFoundError: org/bouncycastle/asn1/ASN1Encodable
如果我们在用iText 做为java 为PDF 文档加水印的时候 报如下异常 java.lang.NoClassDefFoundError: org/bouncycastle/asn1/ASN1Enc ...
- AES中ECB模式的加密与解密(Python3.7)
本文主要解决的问题 本文主要是讲解AES加密算法中的ECB模式的加密解密的Python3.7实现.具体AES加密算法的原理这里不做过多介绍,想了解的可以参考文末的参考链接. 主要解决了两个问题: 在P ...
- 关于Element对话框组件Dialog在使用时的一些问题及解决办法
Element对话框组件Dialog在我们的实际项目开发中可以说是一个使用频率较高的组件,它能为我们展示提示的功能,如:业务模块提交前展示我们曾经输入或选择过的业务信息,或者展示列表信息中某项业务的具 ...
- navicate远程连接mysql8.0失败
已经给了远程连接权限(update mysql.user set host = "%" where user = 'root'; flush privileges;) 连接错误提示 ...
- js中排序方法sort() 和 reverse()
reverse() 作用:反转原数组. 用法: array.reverse(); 图解: sort() 作用:对原数组进行排序.默认将每个数组项 先 转换为字符串 再 进行字符串对比后升序排序. 用法 ...