python之Web服务器案例
HTTP协议简介
1. 使用谷歌/火狐浏览器分析
在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来。而浏览器和服务器之间的传输协议是HTTP,所以:
HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信。
Chrome浏览器提供了一套完整地调试工具,非常适合Web开发。
安装好Chrome浏览器后,打开Chrome,在菜单中选择“视图”,“开发者”,“开发者工具”,就可以显示开发者工具:
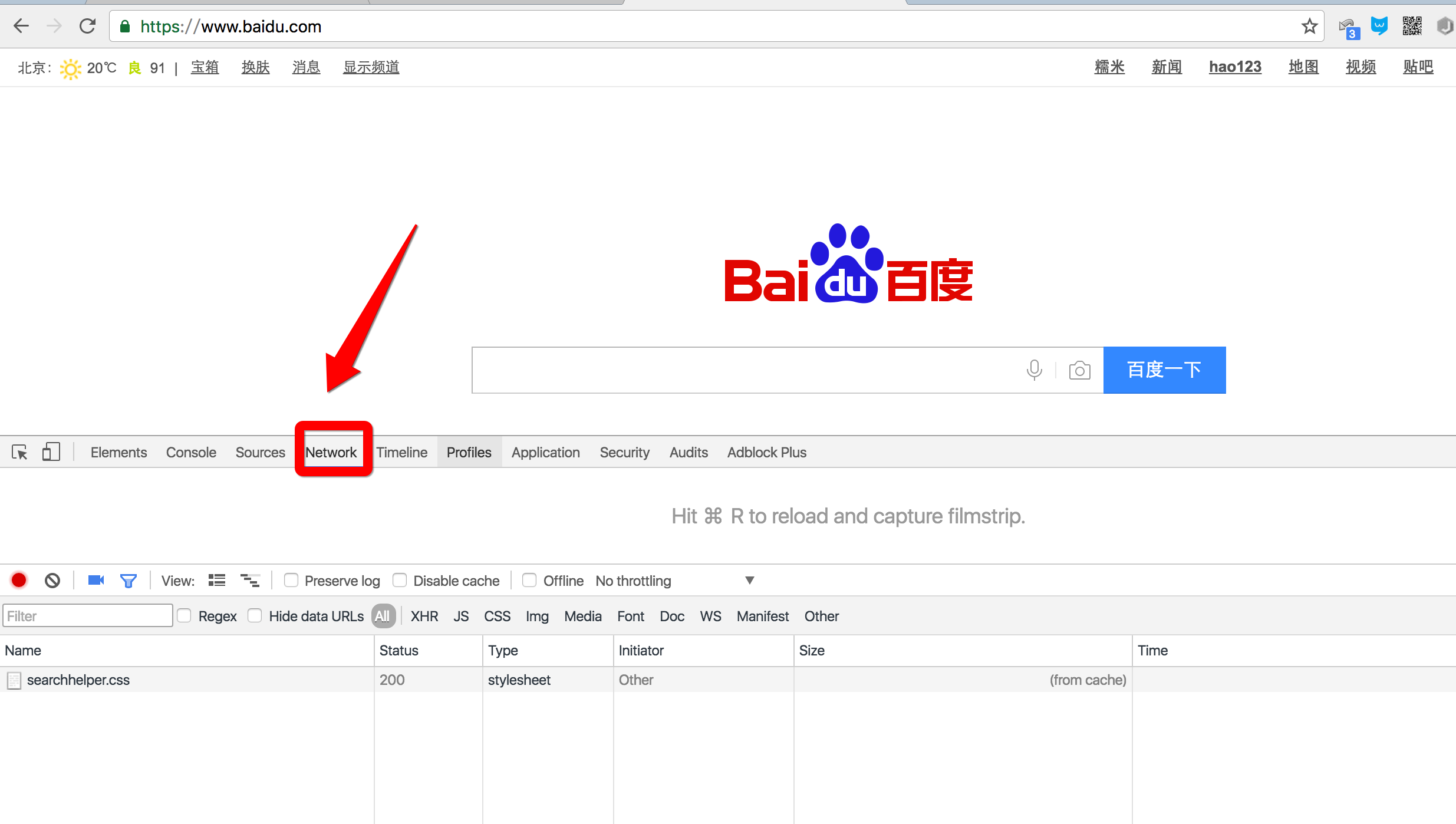
说明
- Elements显示网页的结构
- Network显示浏览器和服务器的通信
我们点Network,确保第一个小红灯亮着,Chrome就会记录所有浏览器和服务器之间的通信:
2. http协议的分析
当我们在地址栏输入www.sina.com时,浏览器将显示新浪的首页。在这个过程中,浏览器都干了哪些事情呢?通过Network的记录,我们就可以知道。在Network中,找到www.sina.com那条记录,点击,右侧将显示Request Headers,点击右侧的view source,我们就可以看到浏览器发给新浪服务器的请求:
2.1 浏览器请求

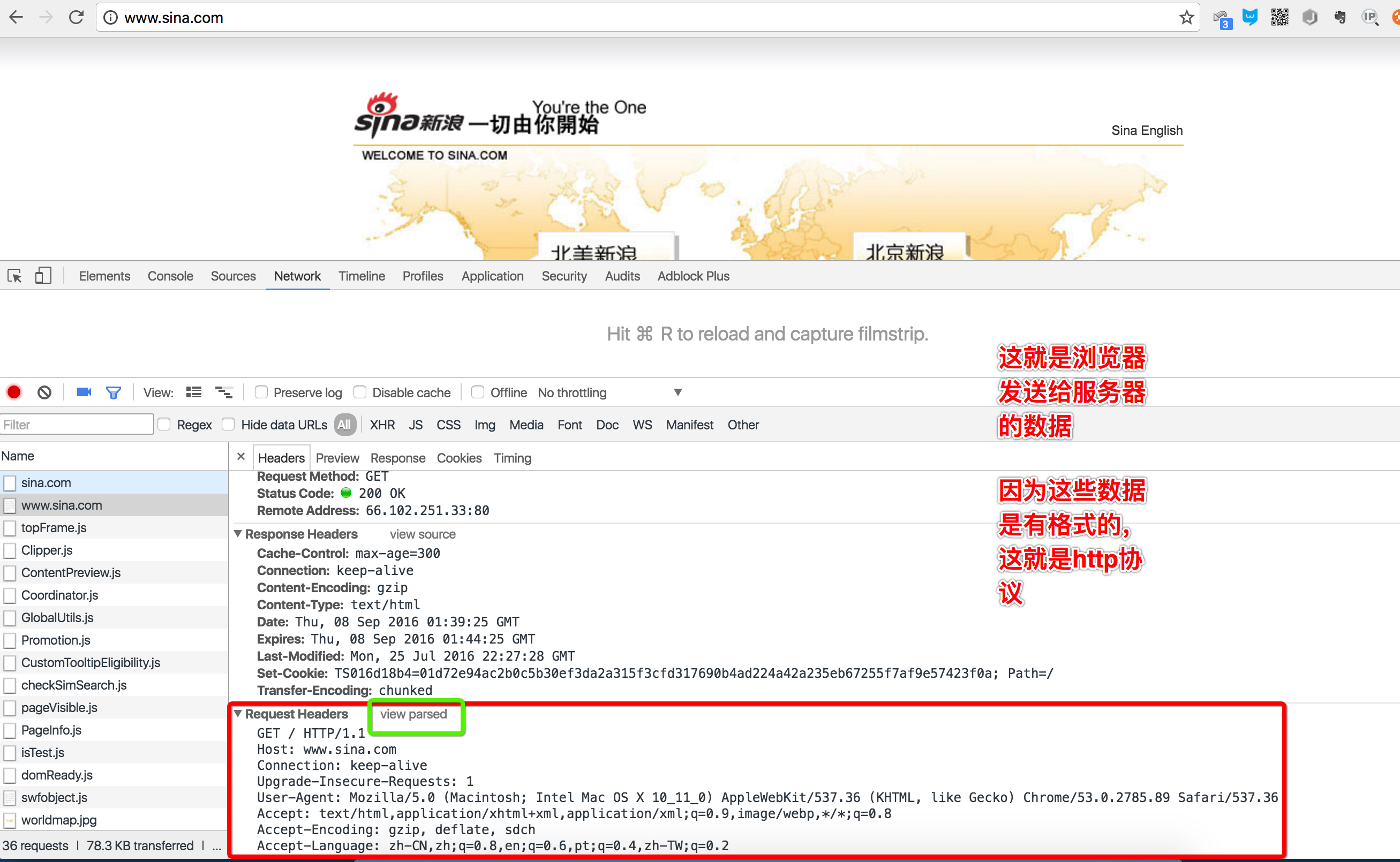
说明
最主要的头两行分析如下,第一行:
GET / HTTP/1.1
GET表示一个读取请求,将从服务器获得网页数据,/表示URL的路径,URL总是以/开头,/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1。目前HTTP协议的版本就是1.1,但是大部分服务器也支持1.0版本,主要区别在于1.1版本允许多个HTTP请求复用一个TCP连接,以加快传输速度。
从第二行开始,每一行都类似于Xxx: abcdefg:
Host: www.sina.com
表示请求的域名是www.sina.com。如果一台服务器有多个网站,服务器就需要通过Host来区分浏览器请求的是哪个网站。
2.2 服务器响应
继续往下找到Response Headers,点击view source,显示服务器返回的原始响应数据:
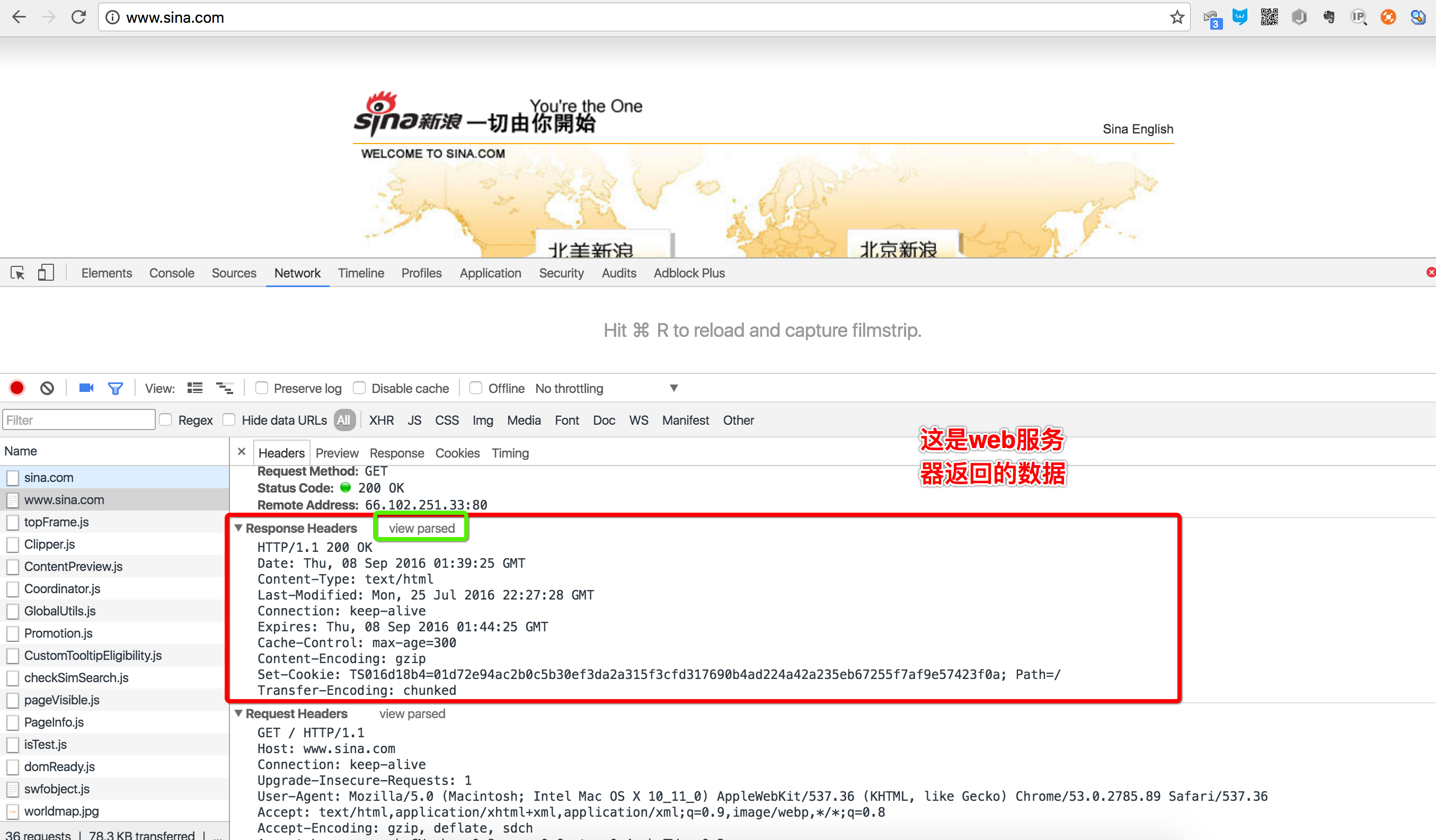
HTTP响应分为Header和Body两部分(Body是可选项),我们在Network中看到的Header最重要的几行如下:
HTTP/1.1 200 OK
200表示一个成功的响应,后面的OK是说明。
如果返回的不是200,那么往往有其他的功能,例如
- 失败的响应有404 Not Found:网页不存在
- 500 Internal Server Error:服务器内部出错
...等等...
Content-Type: text/html
Content-Type指示响应的内容,这里是text/html表示HTML网页。
请注意,浏览器就是依靠Content-Type来判断响应的内容是网页还是图片,是视频还是音乐。浏览器并不靠URL来判断响应的内容,所以,即使URL是
http://www.baidu.com/meimei.jpg,它也不一定就是图片。
HTTP响应的Body就是HTML源码,我们在菜单栏选择“视图”,“开发者”,“查看网页源码”就可以在浏览器中直接查看HTML源码:
浏览器解析过程
当浏览器读取到新浪首页的HTML源码后,它会解析HTML,显示页面,然后,根据HTML里面的各种链接,再发送HTTP请求给新浪服务器,拿到相应的图片、视频、Flash、JavaScript脚本、CSS等各种资源,最终显示出一个完整的页面。所以我们在Network下面能看到很多额外的HTTP请求。

3. 总结
3.1 HTTP请求
跟踪了新浪的首页,我们来总结一下HTTP请求的流程:
3.1.1 步骤1:浏览器首先向服务器发送HTTP请求,请求包括:
方法:GET还是POST,GET仅请求资源,POST会附带用户数据;
路径:/full/url/path;
域名:由Host头指定:Host: www.sina.com
以及其他相关的Header;
如果是POST,那么请求还包括一个Body,包含用户数据
3.1.1 步骤2:服务器向浏览器返回HTTP响应,响应包括:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中。
3.1.1 步骤3:如果浏览器还需要继续向服务器请求其他资源,比如图片,就再次发出HTTP请求,重复步骤1、2。
Web采用的HTTP协议采用了非常简单的请求-响应模式,从而大大简化了开发。当我们编写一个页面时,我们只需要在HTTP请求中把HTML发送出去,不需要考虑如何附带图片、视频等,浏览器如果需要请求图片和视频,它会发送另一个HTTP请求,因此,一个HTTP请求只处理一个资源(此时就可以理解为TCP协议中的短连接,每个链接只获取一个资源,如需要多个就需要建立多个链接)
HTTP协议同时具备极强的扩展性,虽然浏览器请求的是http://www.sina.com的首页,但是新浪在HTML中可以链入其他服务器的资源,比如<img src="http://i1.sinaimg.cn/home/2013/1008/U8455P30DT20131008135420.png">,从而将请求压力分散到各个服务器上,并且,一个站点可以链接到其他站点,无数个站点互相链接起来,就形成了World Wide Web,简称WWW。
3.2 HTTP格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。
HTTP协议是一种文本协议,所以,它的格式也非常简单。
3.2.1 HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
每个Header一行一个,换行符是\r\n。
3.2.2 HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3 body data goes here...
当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。
3.2.3 HTTP响应的格式:
200 OK
Header1: Value1
Header2: Value2
Header3: Value3 body data goes here...
HTTP响应如果包含body,也是通过\r\n\r\n来分隔的。
请再次注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
Web静态服务器-1-显示固定的页面
#coding=utf-8
import socket
from multiprocessing import Process def handleClient(clientSocket):
'用一个新的进程,为一个客户端进行服务'
recvData = clientSocket.recv(2014)
requestHeaderLines = recvData.splitlines()
for line in requestHeaderLines:
print(line) responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "\r\n"
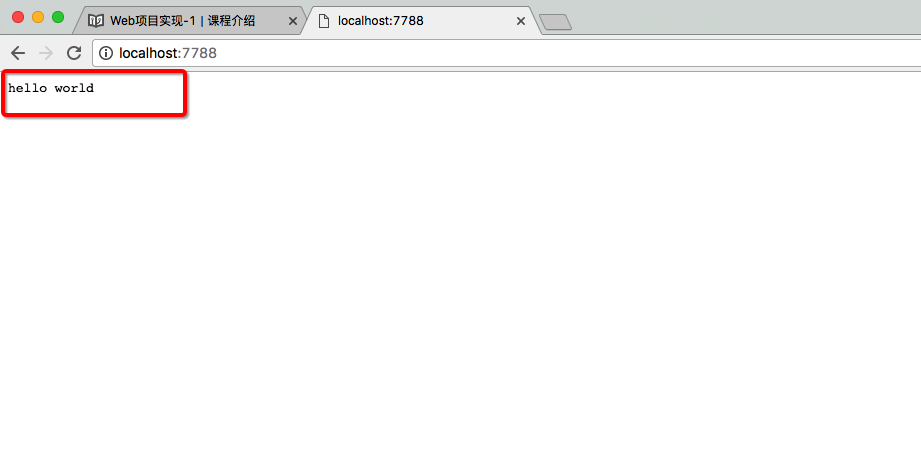
responseBody = "hello world" response = responseHeaderLines + responseBody
clientSocket.send(response)
clientSocket.close() def main():
'作为程序的主控制入口' serverSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serverSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serverSocket.bind(("", 7788))
serverSocket.listen(10)
while True:
clientSocket,clientAddr = serverSocket.accept()
clientP = Process(target = handleClient, args = (clientSocket,))
clientP.start()
clientSocket.close() if __name__ == '__main__':
main()
服务器端
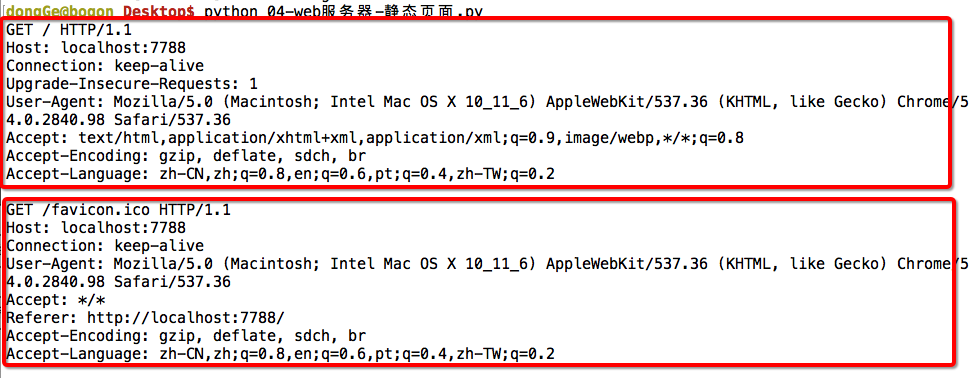
客户端
Web静态服务器-2-显示需要的页面
#coding=utf-8
import socket
from multiprocessing import Process
import re def handleClient(clientSocket):
'用一个新的进程,为一个客户端进行服务'
recvData = clientSocket.recv(2014)
requestHeaderLines = recvData.splitlines()
for line in requestHeaderLines:
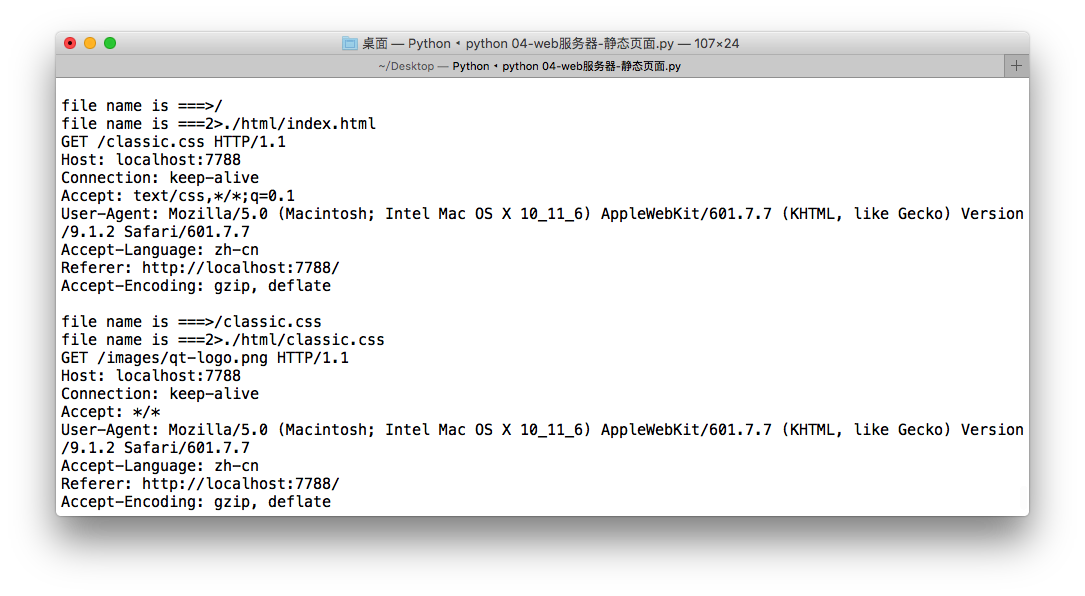
print(line) httpRequestMethodLine = requestHeaderLines[0]
getFileName = re.match("[^/]+(/[^ ]*)", httpRequestMethodLine).group(1)
print("file name is ===>%s"%getFileName) #for test if getFileName == '/':
getFileName = documentRoot + "/index.html"
else:
getFileName = documentRoot + getFileName print("file name is ===2>%s"%getFileName) #for test try:
f = open(getFileName)
except IOError:
responseHeaderLines = "HTTP/1.1 404 not found\r\n"
responseHeaderLines += "\r\n"
responseBody = "====sorry ,file not found===="
else:
responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "\r\n"
responseBody = f.read()
f.close()
finally:
response = responseHeaderLines + responseBody
clientSocket.send(response)
clientSocket.close() def main():
'作为程序的主控制入口' serverSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serverSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serverSocket.bind(("", 7788))
serverSocket.listen(10)
while True:
clientSocket,clientAddr = serverSocket.accept()
clientP = Process(target = handleClient, args = (clientSocket,))
clientP.start()
clientSocket.close() #这里配置服务器
documentRoot = './html' if __name__ == '__main__':
main()
服务器端
客户端
Web静态服务器-3-使用类
#coding=utf-8
import socket
import sys
from multiprocessing import Process
import re class WSGIServer(object): addressFamily = socket.AF_INET
socketType = socket.SOCK_STREAM
requestQueueSize = 5 def __init__(self, server_address):
#创建一个tcp套接字
self.listenSocket = socket.socket(self.addressFamily,self.socketType)
#允许重复使用上次的套接字绑定的port
self.listenSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#绑定
self.listenSocket.bind(server_address)
#变为被动,并制定队列的长度
self.listenSocket.listen(self.requestQueueSize) def serveForever(self):
'循环运行web服务器,等待客户端的链接并为客户端服务'
while True:
#等待新客户端到来
self.clientSocket, client_address = self.listenSocket.accept() #方法2,多进程服务器,并发服务器于多个客户端
newClientProcess = Process(target = self.handleRequest)
newClientProcess.start() #因为创建的新进程中,会对这个套接字+1,所以需要在主进程中减去依次,即调用一次close
self.clientSocket.close() def handleRequest(self):
'用一个新的进程,为一个客户端进行服务'
recvData = self.clientSocket.recv(2014)
requestHeaderLines = recvData.splitlines()
for line in requestHeaderLines:
print(line) httpRequestMethodLine = requestHeaderLines[0]
getFileName = re.match("[^/]+(/[^ ]*)", httpRequestMethodLine).group(1)
print("file name is ===>%s"%getFileName) #for test if getFileName == '/':
getFileName = documentRoot + "/index.html"
else:
getFileName = documentRoot + getFileName print("file name is ===2>%s"%getFileName) #for test try:
f = open(getFileName)
except IOError:
responseHeaderLines = "HTTP/1.1 404 not found\r\n"
responseHeaderLines += "\r\n"
responseBody = "====sorry ,file not found===="
else:
responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "\r\n"
responseBody = f.read()
f.close()
finally:
response = responseHeaderLines + responseBody
self.clientSocket.send(response)
self.clientSocket.close() #设定服务器的端口
serverAddr = (HOST, PORT) = '', 8888
#设置服务器服务静态资源时的路径
documentRoot = './html' def makeServer(serverAddr):
server = WSGIServer(serverAddr)
return server def main():
httpd = makeServer(serverAddr)
print('web Server: Serving HTTP on port %d ...\n'%PORT)
httpd.serveForever() if __name__ == '__main__':
main()v
服务器动态资源请求
1. 浏览器请求动态页面过程
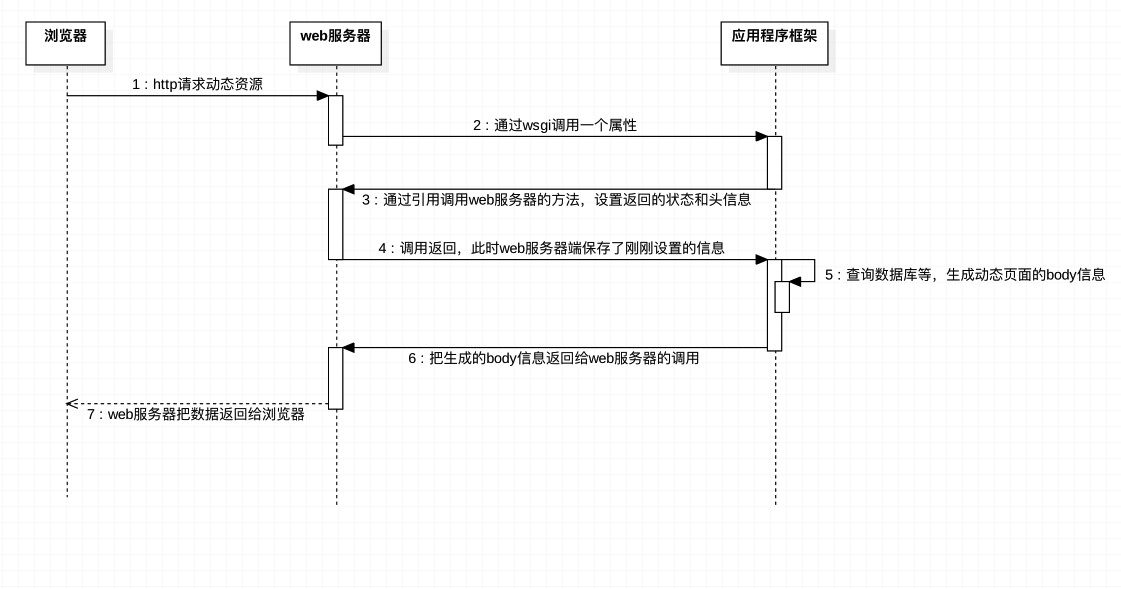
2. WSGI
怎么在你刚建立的Web服务器上运行一个Django应用和Flask应用,如何不做任何改变而适应不同的web架构呢?
在以前,选择 Python web 架构会受制于可用的web服务器,反之亦然。如果架构和服务器可以协同工作,那就好了:
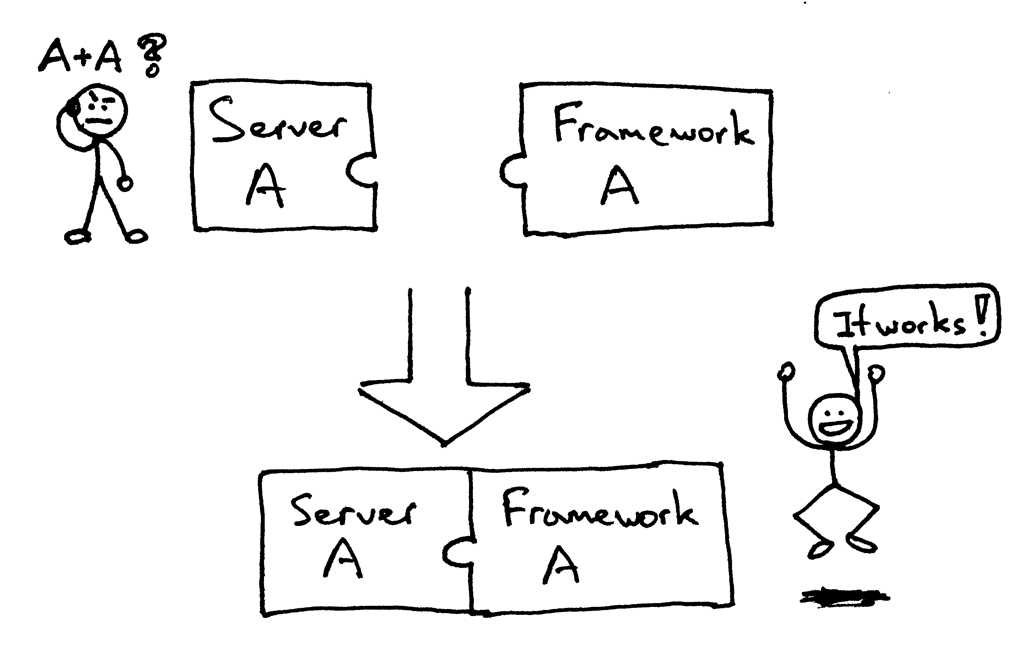
但有可能面对(或者曾有过)下面的问题,当要把一个服务器和一个架构结合起来时,却发现他们不是被设计成协同工作的:
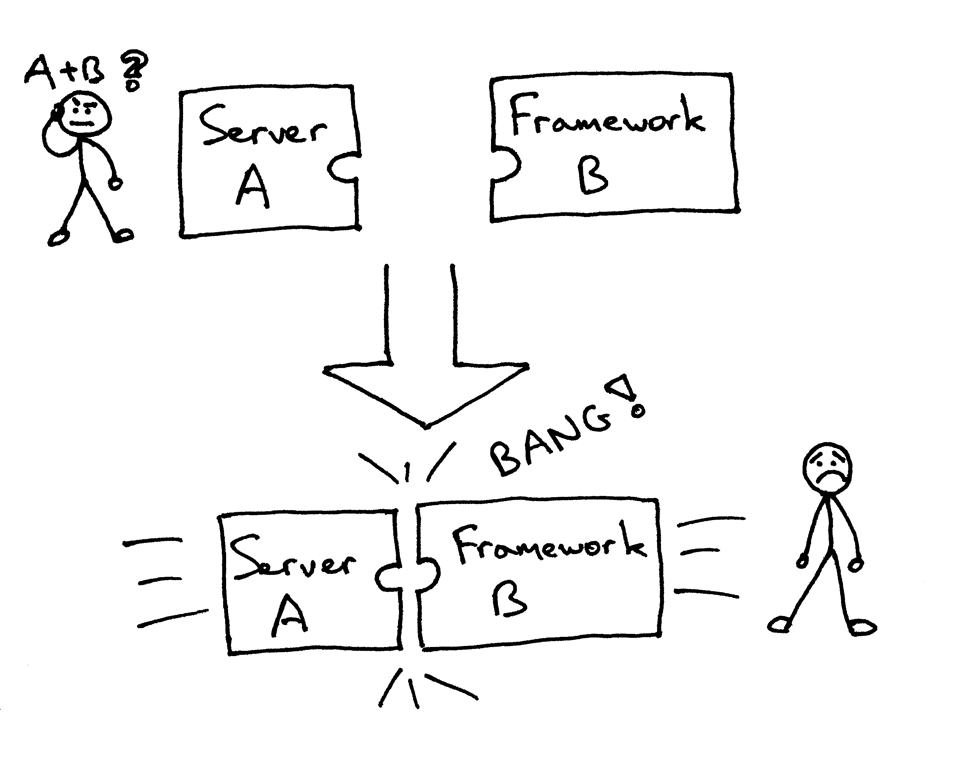
那么,怎么可以不修改服务器和架构代码而确保可以在多个架构下运行web服务器呢?答案就是 Python Web Server Gateway Interface (或简称 WSGI,读作“wizgy”)。

WSGI允许开发者将选择web框架和web服务器分开。可以混合匹配web服务器和web框架,选择一个适合的配对。比如,可以在Gunicorn 或者 Nginx/uWSGI 或者 Waitress上运行 Django, Flask, 或 Pyramid。真正的混合匹配,得益于WSGI同时支持服务器和架构:
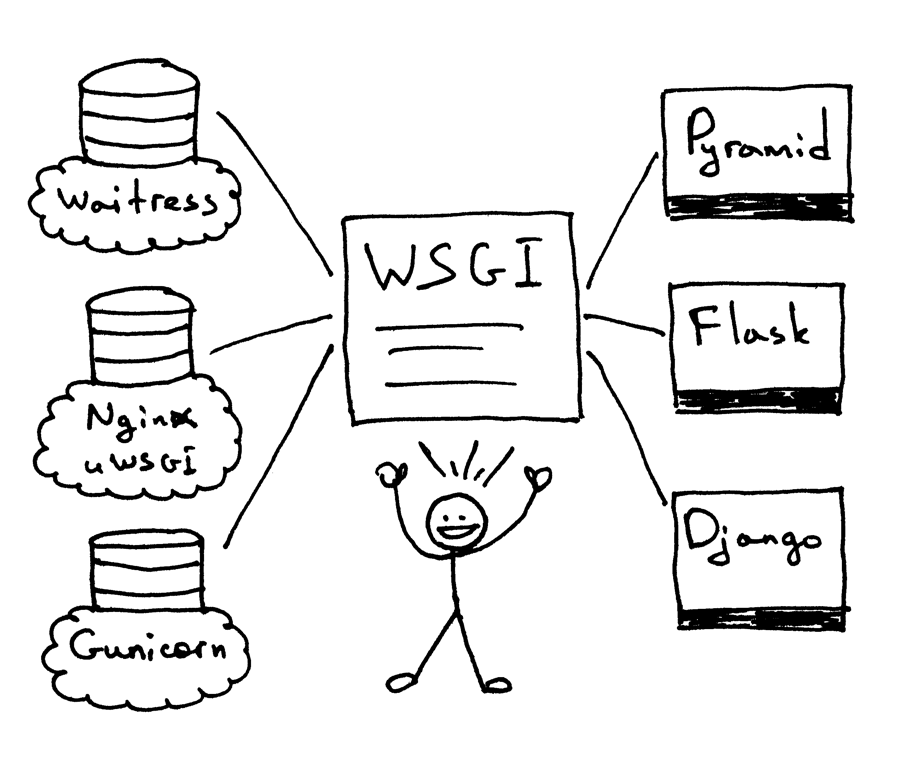
web服务器必须具备WSGI接口,所有的现代Python Web框架都已具备WSGI接口,它让你不对代码作修改就能使服务器和特点的web框架协同工作。
WSGI由web服务器支持,而web框架允许你选择适合自己的配对,但它同样对于服务器和框架开发者提供便利使他们可以专注于自己偏爱的领域和专长而不至于相互牵制。其他语言也有类似接口:java有Servlet API,Ruby 有 Rack。
3.定义WSGI接口
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello World!”:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return 'Hello World!'
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
- environ:一个包含所有HTTP请求信息的dict对象;
- start_response:一个发送HTTP响应的函数。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,把底层web服务器解析部分和应用程序逻辑部分进行了分离,这样开发者就可以专心做一个领域了
不过,等等,这个application()函数怎么调用?如果我们自己调用,两个参数environ和start_response我们没法提供,返回的str也没法发给浏览器。
所以application()函数必须由WSGI服务器来调用。有很多符合WSGI规范的服务器。而我们此时的web服务器项目的目的就是做一个极可能解析静态网页还可以解析动态网页的服务器
Web动态服务器-1
#coding=utf-8
import socket
import sys
from multiprocessing import Process
import re class WSGIServer(object): addressFamily = socket.AF_INET
socketType = socket.SOCK_STREAM
requestQueueSize = 5 def __init__(self, serverAddress):
#创建一个tcp套接字
self.listenSocket = socket.socket(self.addressFamily,self.socketType)
#允许重复使用上次的套接字绑定的port
self.listenSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#绑定
self.listenSocket.bind(serverAddress)
#变为被动,并制定队列的长度
self.listenSocket.listen(self.requestQueueSize) self.servrName = "localhost"
self.serverPort = serverAddress[1] def serveForever(self):
'循环运行web服务器,等待客户端的链接并为客户端服务'
while True:
#等待新客户端到来
self.clientSocket, client_address = self.listenSocket.accept() #方法2,多进程服务器,并发服务器于多个客户端
newClientProcess = Process(target = self.handleRequest)
newClientProcess.start() #因为创建的新进程中,会对这个套接字+1,所以需要在主进程中减去依次,即调用一次close
self.clientSocket.close() def setApp(self, application):
'设置此WSGI服务器调用的应用程序入口函数'
self.application = application def handleRequest(self):
'用一个新的进程,为一个客户端进行服务'
self.recvData = self.clientSocket.recv(2014)
requestHeaderLines = self.recvData.splitlines()
for line in requestHeaderLines:
print(line) httpRequestMethodLine = requestHeaderLines[0]
getFileName = re.match("[^/]+(/[^ ]*)", httpRequestMethodLine).group(1)
print("file name is ===>%s"%getFileName) #for test if getFileName[-3:] != ".py": if getFileName == '/':
getFileName = documentRoot + "/index.html"
else:
getFileName = documentRoot + getFileName print("file name is ===2>%s"%getFileName) #for test try:
f = open(getFileName)
except IOError:
responseHeaderLines = "HTTP/1.1 404 not found\r\n"
responseHeaderLines += "\r\n"
responseBody = "====sorry ,file not found===="
else:
responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "\r\n"
responseBody = f.read()
f.close()
finally:
response = responseHeaderLines + responseBody
self.clientSocket.send(response)
self.clientSocket.close()
else: #根据接收到的请求头构造环境变量字典
env = {} #调用应用的相应方法,完成动态数据的获取
bodyContent = self.application(env, self.startResponse) #组织数据发送给客户端
self.finishResponse(bodyContent) def startResponse(self, status, response_headers):
serverHeaders = [
('Date', 'Tue, 31 Mar 2016 10:11:12 GMT'),
('Server', 'WSGIServer 0.2'),
]
self.headers_set = [status, response_headers + serverHeaders] def finishResponse(self, bodyContent):
try:
status, response_headers = self.headers_set
#response的第一行
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
#response的其他头信息
for header in response_headers:
response += '{0}: {1}\r\n'.format(*header)
#添加一个换行,用来和body进行分开
response += '\r\n'
#添加发送的数据
for data in bodyContent:
response += data self.clientSocket.send(response)
finally:
self.clientSocket.close() #设定服务器的端口
serverAddr = (HOST, PORT) = '', 8888
#设置服务器静态资源的路径
documentRoot = './html'
#设置服务器动态资源的路径
pythonRoot = './wsgiPy' def makeServer(serverAddr, application):
server = WSGIServer(serverAddr)
server.setApp(application)
return server def main(): if len(sys.argv) < 2:
sys.exit('请按照要求,指定模块名称:应用名称,例如 module:callable') #获取module:callable
appPath = sys.argv[1]
#根据冒号切割为module和callable
module, application = appPath.split(':')
#添加路径套sys.path
sys.path.insert(0, pythonRoot)
#动态导入module变量中指定的模块
module = __import__(module)
#获取module变量中指定的模块的,application变量指定的属性
application = getattr(module, application)
httpd = makeServer(serverAddr, application)
print('WSGIServer: Serving HTTP on port %d ...\n'%PORT)
httpd.serveForever() if __name__ == '__main__':
main()
应用程序示例
import time def app(environ, start_response):
status = '200 OK'
response_headers = [('Content-Type', 'text/plain')]
start_response(status, response_headers)
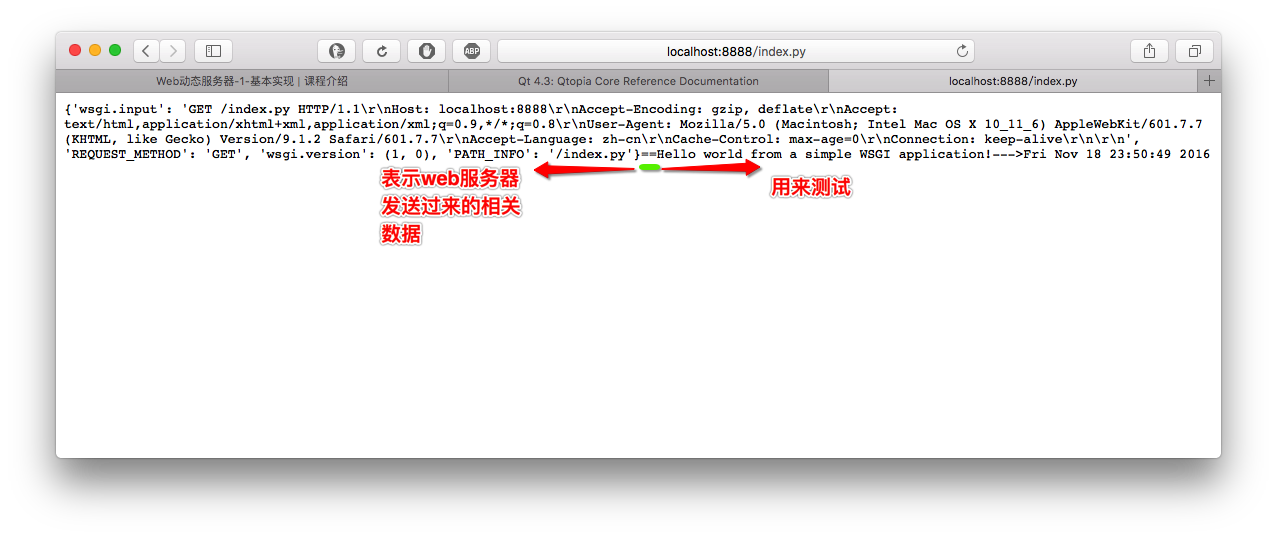
return [str(environ)+'==Hello world from a simple WSGI application!--->%s\n'%time.ctime()]
Web动态服务器-2-传递数据给应用
#coding=utf-8
import socket
import sys
from multiprocessing import Process
import re class WSGIServer(object): addressFamily = socket.AF_INET
socketType = socket.SOCK_STREAM
requestQueueSize = 5 def __init__(self, serverAddress):
#创建一个tcp套接字
self.listenSocket = socket.socket(self.addressFamily,self.socketType)
#允许重复使用上次的套接字绑定的port
self.listenSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
#绑定
self.listenSocket.bind(serverAddress)
#变为被动,并制定队列的长度
self.listenSocket.listen(self.requestQueueSize) self.servrName = "localhost"
self.serverPort = serverAddress[1] def serveForever(self):
'循环运行web服务器,等待客户端的链接并为客户端服务'
while True:
#等待新客户端到来
self.clientSocket, client_address = self.listenSocket.accept() #方法2,多进程服务器,并发服务器于多个客户端
newClientProcess = Process(target = self.handleRequest)
newClientProcess.start() #因为创建的新进程中,会对这个套接字+1,所以需要在主进程中减去依次,即调用一次close
self.clientSocket.close() def setApp(self, application):
'设置此WSGI服务器调用的应用程序入口函数'
self.application = application def handleRequest(self):
'用一个新的进程,为一个客户端进行服务'
self.recvData = self.clientSocket.recv(2014)
requestHeaderLines = self.recvData.splitlines()
for line in requestHeaderLines:
print(line) httpRequestMethodLine = requestHeaderLines[0]
getFileName = re.match("[^/]+(/[^ ]*)", httpRequestMethodLine).group(1)
print("file name is ===>%s"%getFileName) #for test if getFileName[-3:] != ".py": if getFileName == '/':
getFileName = documentRoot + "/index.html"
else:
getFileName = documentRoot + getFileName print("file name is ===2>%s"%getFileName) #for test try:
f = open(getFileName)
except IOError:
responseHeaderLines = "HTTP/1.1 404 not found\r\n"
responseHeaderLines += "\r\n"
responseBody = "====sorry ,file not found===="
else:
responseHeaderLines = "HTTP/1.1 200 OK\r\n"
responseHeaderLines += "\r\n"
responseBody = f.read()
f.close()
finally:
response = responseHeaderLines + responseBody
self.clientSocket.send(response)
self.clientSocket.close()
else:
#处理接收到的请求头
self.parseRequest() #根据接收到的请求头构造环境变量字典
env = self.getEnviron() #调用应用的相应方法,完成动态数据的获取
bodyContent = self.application(env, self.startResponse) #组织数据发送给客户端
self.finishResponse(bodyContent) def parseRequest(self):
'提取出客户端发送的request'
requestLine = self.recvData.splitlines()[0]
requestLine = requestLine.rstrip('\r\n')
self.requestMethod, self.path, self.requestVersion = requestLine.split(" ") def getEnviron(self):
env = {}
env['wsgi.version'] = (1, 0)
env['wsgi.input'] = self.recvData
env['REQUEST_METHOD'] = self.requestMethod # GET
env['PATH_INFO'] = self.path # /index.html
return env def startResponse(self, status, response_headers, exc_info=None):
serverHeaders = [
('Date', 'Tue, 31 Mar 2016 10:11:12 GMT'),
('Server', 'WSGIServer 0.2'),
]
self.headers_set = [status, response_headers + serverHeaders] def finishResponse(self, bodyContent):
try:
status, response_headers = self.headers_set
#response的第一行
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
#response的其他头信息
for header in response_headers:
response += '{0}: {1}\r\n'.format(*header)
#添加一个换行,用来和body进行分开
response += '\r\n'
#添加发送的数据
for data in bodyContent:
response += data self.clientSocket.send(response)
finally:
self.clientSocket.close() #设定服务器的端口
serverAddr = (HOST, PORT) = '', 8888
#设置服务器静态资源的路径
documentRoot = './html'
#设置服务器动态资源的路径
pythonRoot = './wsgiPy' def makeServer(serverAddr, application):
server = WSGIServer(serverAddr)
server.setApp(application)
return server def main(): if len(sys.argv) < 2:
sys.exit('请按照要求,指定模块名称:应用名称,例如 module:callable') #获取module:callable
appPath = sys.argv[1]
#根据冒号切割为module和callable
module, application = appPath.split(':')
#添加路径套sys.path
sys.path.insert(0, pythonRoot)
#动态导入module变量中指定的模块
module = __import__(module)
#获取module变量中制定的模块的application变量指定的属性
application = getattr(module, application)
httpd = makeServer(serverAddr, application)
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
httpd.serveForever() if __name__ == '__main__':
main()
python之Web服务器案例的更多相关文章
- Python基础Web服务器案例
一.WSGI 1.PythonWeb服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI) 是Python应用程序或框架和Web服务器之间的一种接口, ...
- python网络-动态Web服务器案例(30)
一.浏览器请求HTML页面的过程 了解了HTTP协议和HTML文档,其实就明白了一个Web应用的本质就是: 浏览器发送一个HTTP请求: 服务器收到请求,生成一个HTML文档: 服务器把HTML文档作 ...
- python网络-静态Web服务器案例(29)
一.静态Web服务器案例代码static_web_server.py # coding:utf-8 # 导入socket模块 import socket # 导入正则表达式模块 import re # ...
- Python搭建Web服务器,与Ajax交互,接收处理Get和Post请求的简易结构
用python搭建web服务器,与ajax交互,接收处理Get和Post请求:简单实用,没有用框架,适用于简单需求,更多功能可进行扩展. python有自带模块BaseHTTPServer.CGIHT ...
- python写web服务器
#coding = utf-8 from http.server import BaseHTTPRequestHandler, HTTPServer class RequestHandler(Base ...
- (转)Python的web服务器
1.浏览器请求动态页面过程 2.WSGI Python Web Server Gateway Interface (或简称 WSGI,读作“wizgy”). WSGI允许开发者将选择web框架和web ...
- Python的web服务器
1.浏览器请求动态页面过程 2.WSGI Python Web Server Gateway Interface (或简称 WSGI,读作“wizgy”). WSGI允许开发者将选择web框架和web ...
- Python——轻量级web服务器flask的学习
前言: 根据工程需要,开始上手另一个python服务器---flask,flask是一个轻量级的python服务器,简单易用.将我的学习过程记录下来,有新的知识会及时补充. 记录只为更好的分享~ 正文 ...
- python对web服务器做压力测试并做出图形直观显示
压力测试有很多工具啊.apache的,还有jmeter, 还有loadrunner,都比较常用. 其实你自己用python写的,也足够用. 压力测试过程中要统计时间. 比如每秒的并发数,每秒的最大响应 ...
随机推荐
- Unity3D安卓程序中提示窗与常用静态方法封装
Unity3D/安卓封装SDK常用方法 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) 1 IO -- - ...
- centos安装redis +RedisDesktopManager连接redis
1.先到Redis官网(redis.io)下载redis安装包 wget http://download.redis.io/releases/redis-5.0.4.tar.gztar xzf red ...
- 【分形】【洛谷P1498】
https://www.luogu.org/problemnew/show/P1498 题目描述 自从到了南蛮之地,孔明不仅把孟获收拾的服服帖帖,而且还发现了不少少数民族的智慧,他发现少数民族的图腾往 ...
- Mybatis的mapper文件中$和#的用法及区别详解
https://www.2cto.com/database/201806/752139.html用了一段时间的Mybatis了,对于$和#的用法老是很迷糊,特此记下加深记忆. 简单来说 #{} 会在将 ...
- 【JVM】jvm的jps命令
jps -- Java Virtual Machine Process Status Tool 可以列出本机所有java进程的pid jps [ options ] [ hostid ] 选项 -q ...
- Eclipse+Spring学习(一)环境搭建(转)
最近由于投了一家公司实习,他要java工程师,而我大学3年的精力都花到了ASP.NET和前端上面,到找工作的时候才发现大公司不要.NET的,所以马上转型java...由于网上的高手都不屑于写这类文章, ...
- tiny4412-Uboot启动分析
一.从本质上将,引导转载程序至少应提供以下功能 (1)设置和初始化RAM (2)初始化一个串口 (3)检测机器类型(machine type) (4)设置内核标签列表(tag list) (5)调用内 ...
- 针对 FastAdmin 2018-01-19 号的升级 SQL (废)
FastAdmin 在 2018-01-19 升级增加了以下功能. 新增前台会员模块和API会员模块 新增后台会员管理.会员规则和会员分组管理 新增短信发送的行为事件 新增前台Token.短信.日志模 ...
- .csv 和 .xls 的区别
.csv 和 .xls 的区别 .csv .xls 较为通用,易导入至各式表格.资料库等 Microsoft excel的专用档案 文本档案,用记事本就可以打开 二进位档案,只有用excel才能打开 ...
- PHP安全相关的配置(2)
php用越来越多!安全问题更为重要!这里讲解如果安全配置php.ini 安全配置一 (1) 打开php的安全模式 php的安全模式是个非常重要的内嵌的安全机制,能够控制一些php中的函数,比如syst ...