MapRedece(多表关联)
多表关联:
准备数据
********************************************
工厂表:
| Factory | Addressed |
| BeijingRedStar | 1 |
| ShenzhenThunder | 3 |
| GongzhouHonDa | 2 |
| BeijingRising | 1 |
| GuangzhouDevelopmentBank | 2 |
| Tencent | 3 |
************************************** ****
地址表:
| Address | AddressName |
| 1 | Beijing |
| 2 | Guangzhou |
| 3 | ShenZhen |
| 4 | Xian |
******************************************
工厂-地址表:(中间的数据在结果中不显示)
| Factory | Addressed | AddressName |
| BeijingRedStar | 1 | Beijing |
| ShenzhenThunder | 3 | ShenZhen |
| GongzhouHonDa | 2 | Guangzhou |
| BeijingRising | 1 | Beijing |
| GuangzhouDevelopmentBank | 2 | Guangzhou |
| Tencent | 3 | ShenZhen |
解决思路:根据工厂表中的工厂地址ID和地址表的工厂ID相关,组合成工厂-地址表,可以达到多表关联。
步骤:
- map识别出输入的行属于哪个表之后,对其进行分割,将连接的列值保存在key中,另一列和左右表标识保存在value中,然后输出。
- reduce解析map输出的结果,解析value内容,根据标志将左右表内容分开存放,然后求笛卡尔积,最后直接输出。
(1)自定义Mapper任务
private static class MyMapper extends Mapper<Object, Text, Text, Text> {
Text k2= new Text();
Text v2= new Text();
@Override
protected void map(Object k1, Text v1,
Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String line = v1.toString();//每行文件
String relationType = new String();
//首行数据不处理
if (line.contains("factoryname")==true||line.contains("addressed")==true) {
return;
}
//处理其他行的数据
StringTokenizer item = new StringTokenizer(line);
String mapkey = new String();
String mapvalue = new String();
int i=0;
while (item.hasMoreTokens()) {
String tokenString=item.nextToken();//读取一个单词
//判断输出行所属表,并进行分割
if (tokenString.charAt(0)>='0'&&tokenString.charAt(0)<='9') {
mapkey = tokenString;
if (i>0) {
relationType="1";
}else {
relationType="2";
}
continue;
}
mapvalue+=tokenString+" ";//存储工厂名,以空格隔开
i++;
}
k2 = new Text(mapkey);
v2 =new Text(relationType+"+"+mapvalue);
context.write(k2,v2);//输出左右表
}
}
(2)自定义Reduce任务
private static class MyReducer extends Reducer<Text, Text, Text, Text> {
Text k3 = new Text();
Text v3 = new Text();
@Override
protected void reduce(Text k2, Iterable<Text> v2s,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (0 == time) {
context.write(new Text("factoryname"), new Text("addressed"));
time++;
}
int factoryNum=0;
String [] factory=new String[10];
int addressNum=0;
String [] address = new String[10];
Iterator item=v2s.iterator();
while (item.hasNext()) {
String record = item.next().toString();
int len =record.length();
int i=2;
if (len==0) {
continue;
}
//取得左右表标识
char relationType =record.charAt(0);
//左表
if ('1' == relationType) {
factory[factoryNum]=record.substring(i);
factoryNum++;
}
//右表
if ('2'==relationType) {
address[addressNum]=record.substring(i);
addressNum++;
}
}
// factoryNum和addressNum数组求笛卡尔积
if (0 != factoryNum && 0 != addressNum) {
for (int i = 0; i < factoryNum; i++) {
for (int j = 0; j < addressNum; j++) {
k3 = new Text(factory[i]);
v3 = new Text(address[j]);
context.write(k3, v3);
}
}
}
}
}
(3)主函数
public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=MultiTableLink.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName);
//*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(MultiTableLink.class);
//3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path(args[0]));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//7分区(默认1个),排序,分组,规约 采用 默认
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
}
完整的源代码--多表链接
package Mapreduce; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import com.sun.jdi.Value; public class MultiTableLink {
private static int time = 0; public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=MultiTableLink.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName); //*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(MultiTableLink.class); //3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path(args[0]));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//7分区(默认1个),排序,分组,规约 采用 默认 //接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); //12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
} private static class MyMapper extends Mapper<Object, Text, Text, Text> {
Text k2= new Text();
Text v2= new Text();
@Override
protected void map(Object k1, Text v1,
Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String line = v1.toString();//每行文件
String relationType = new String();
//首行数据不处理
if (line.contains("factoryname")==true||line.contains("addressed")==true) {
return;
}
//处理其他行的数据
StringTokenizer item = new StringTokenizer(line);
String mapkey = new String();
String mapvalue = new String(); int i=0;
while (item.hasMoreTokens()) {
String tokenString=item.nextToken();//读取一个单词
//判断输出行所属表,并进行分割
if (tokenString.charAt(0)>='0'&&tokenString.charAt(0)<='9') {
mapkey = tokenString;
if (i>0) {
relationType="1";
}else {
relationType="2";
}
continue;
}
mapvalue+=tokenString+" ";//存储工厂名,以空格隔开
i++;
}
k2 = new Text(mapkey);
v2 =new Text(relationType+"+"+mapvalue);
context.write(k2,v2);//输出左右表 }
}
private static class MyReducer extends Reducer<Text, Text, Text, Text> {
Text k3 = new Text();
Text v3 = new Text(); @Override
protected void reduce(Text k2, Iterable<Text> v2s,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (0 == time) {
context.write(new Text("factoryname"), new Text("addressed"));
time++;
}
int factoryNum=0;
String [] factory=new String[10];
int addressNum=0;
String [] address = new String[10];
Iterator item=v2s.iterator();
while (item.hasNext()) {
String record = item.next().toString();
int len =record.length();
int i=2;
if (len==0) {
continue;
}
//取得左右表标识
char relationType =record.charAt(0);
//左表
if ('1' == relationType) {
factory[factoryNum]=record.substring(i);
factoryNum++;
}
//右表
if ('2'==relationType) {
address[addressNum]=record.substring(i);
addressNum++;
}
}
// factoryNum和addressNum数组求笛卡尔积
if (0 != factoryNum && 0 != addressNum) {
for (int i = 0; i < factoryNum; i++) {
for (int j = 0; j < addressNum; j++) {
k3 = new Text(factory[i]);
v3 = new Text(address[j]);
context.write(k3, v3);
}
}
}
}
}
}
多表链接
程序运行结果
(1) 数据准备:新建文件夹,并在文件夹内新建factory文件和address文件
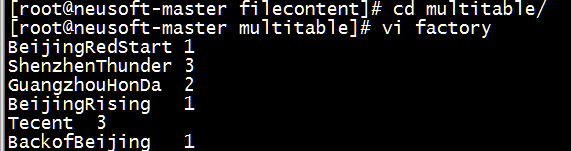
[root@neusoft-master multitable]# vi factory
BeijingRedStart 1
ShenzhenThunder 3
GuangzhouHonDa 2
BeijingRising 1
Tecent 3
BackofBeijing 1
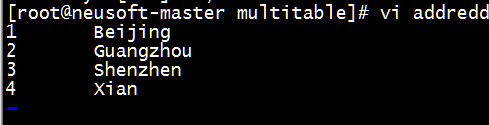
[root@neusoft-master multitable]# vi addredd
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
(2)将文件夹上传到HDFS中
[root@neusoft-master filecontent]# hadoop dfs -put multitable/ /neusoft/
(3)打成jar包并指定主类,提交至Linux中
[root@neusoft-master filecontent]# hadoop jar MultiTableLink.jar /neusoft/multitable /out14

(4)查看结果
[root@neusoft-master filecontent]# hadoop dfs -cat /out14/part-r-00000
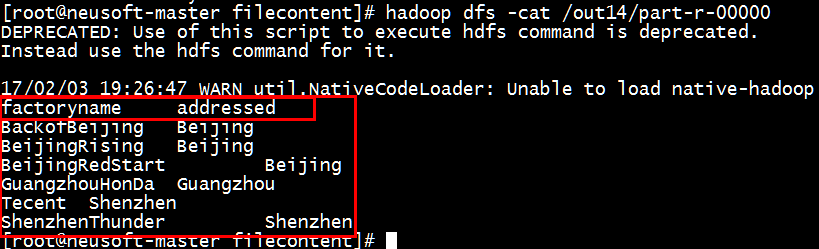
End~
MapRedece(多表关联)的更多相关文章
- MapRedece(单表关联)
源数据:Child--Parent表 Tom Lucy Tom Jack Jone Lucy Jone Jack Lucy Marry Lucy Ben Jack Alice Jack Jesse T ...
- EF里单个实体的增查改删以及主从表关联数据的各种增删 改查
本文目录 EF对单个实体的增查改删 增加单个实体 查询单个实体 修改单个实体 删除单个实体 EF里主从表关联数据的各种增删改查 增加(增加从表数据.增加主从表数据) 查询(根据主表找从表数据.根据从表 ...
- yii2 ActiveRecord多表关联以及多表关联搜索的实现
作者:白狼 出处:http://www.manks.top/yii2_many_ar_relation_search.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明 ...
- mongodb 3.x 之实用新功能窥看[2] ——使用$lookup做多表关联处理
这篇我们来看mongodb另一个非常有意思的东西,那就是$lookup,我们知道mongodb是一个文档型的数据库,而且它也是最像关系型数据库的 一种nosql,但是呢,既然mongodb是无模式的, ...
- Oracle中如何实现Mysql的两表关联update操作
在看<MySQL 5.1参考手册>的时候,发现MySQL提供了一种两表关联update操作.原文如下: UPDATE items,month SET items.price=month.p ...
- Yii2-多表关联的用法示例
本篇博客是基于<活动记录(Active Record)>中对于AR表关联用法的介绍. 我会构造一个业务场景,主要是测试我比较存疑的各种表关联写法,而非再次介绍基础用法. 构造场景 订单ar ...
- T-Sql(四)表关联和视图(view)
今天讲下T-sql中用于查询的表关联和视图,我们平时做项目的时候会遇到一些复杂的查询操作,比如有班级表,学生表,现在要查询一个学生列表,要求把学生所属班级名称也查询出来,这时候简单的select查询就 ...
- SQL语句分组排序,多表关联排序
SQL语句分组排序,多表关联排序总结几种常见的方法: 案例一: 在查询结果中按人数降序排列,若人数相同,则按课程号升序排列? 分析:单个表内的多个字段排序,一般可以直接用逗号分割实现. select ...
- Spring+MyBatis框架中sql语句的书写,数据集的传递以及多表关联查询
在很多Java EE项目中,Spring+MyBatis框架经常被用到,项目搭建在这里不再赘述,现在要将的是如何在项目中书写,增删改查的语句,如何操作数据库,以及后台如何获取数据,如何进行关联查询,以 ...
随机推荐
- iOS 应用中打开其他应用 (转)
我们来讨论一下,在iOS开发中,如何实现从app1打开app2. 基本的思路就是,可以为app2定义一个URL,在app1中通过打开这个URL来打开app2,在此过程中,可以传送一些参数.下面来讨论一 ...
- SpringMVC由浅入深day01_12.4 pojo绑定_12.5自定义参数绑定实现日期类型绑定_12.6集合类
12.4 pojo绑定 页面中input的name和controller的pojo形参中的属性名称一致,将页面中数据绑定到pojo. 页面定义: controller的pojo形参的定义: 打断点测试 ...
- 爬虫 测试webmagic (一)
目标:统计斗鱼(www.douyu.com)人数 思路: 1. 目录找到douyu播出的所有游戏 http://www.douyutv.com/directory 2. 借助 chrome 定位到每个 ...
- mysql asyn 实战
创建configuration时,发现URLParser找不到,于是只能使用配置文件来,当然使用配置文件比使用URL初始化还要直观些 def configurationWithPassword = n ...
- grid网格的流动定位
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ios开发之--NSNumber的使用
什么是NSNumber? NSArray/NSDictionary中只能存放oc对象,不能存放基本数据类型,如果想把基本数据类型放进去,需要先把基本数据类型转换成OC对象, 代码如下: ; ; flo ...
- TOMCAT可以稳定支持的最大并发用户数
转自:http://blog.sina.com.cn/s/blog_68b7d2f50101ann7.html 服务器配置: 单硬盘,SATA 8MB缓存 测试服务器和loadrunner运行服务 ...
- N76E003的定时器/计数器 0和1
定时器/计数器 0和1N76E003系列定时器/计数器 0和1是2个16位定时器/计数器.每个都是由两个8位的寄存器组成的16位计数寄存器. 对于定时器/计数器0,高8位寄存器是TH0. 低8位寄存器 ...
- 《C++ Primer Plus》第16章 string类和标准模板库 学习笔记
C++提供了一组功能强大的库,这些库提供了很多常见编程问题的解决方案以及简化其他问题的工具string类为将字符串作为对象来处理提供了一种方便的方法.string类提供了自动内存管理动能以及众多处理字 ...
- (转)C语言中长度为0的数组
前面在看Xen的源码时,遇到了一段代码,如下所示: 注意上面最后一行的代码,这里定义了一个长度为的数组,这种用法可以吗?为什么可以使用长度为0 的数组?长度为的数组到底怎么使用?……这篇文章主要针对该 ...