hadoop家族学习路线图之hadoop产品大全
大数据这个词也许几年前你听着还会觉得陌生,但我相信你现在听到hadoop这个词的时候你应该都会觉得“熟悉”!越来越发现身边从事hadoop开发或者是正在学习hadoop的人变多了。作为一个hadoop入门级的新手,你会觉得哪些地方很难呢?运行环境的搭建恐怕就已经足够让新手头疼。如果每一个发行版hadoop都可以做到像大快DKHadoop那样把各种环境搭建集成到一起,一次安装搞定所有,那对于新手来说将是件多么美妙的事情!
闲话扯得稍微多了点,回归整体。这篇准备给大家hadoop新入门的朋友分享一些hadoop的基础知识——hadoop家族产品。通过对hadoop家族产品的认识,进一步帮助大家学习好hadoop!同时,也欢迎大家提出宝贵意见!
一、Hadoop定义
Hadoop是一个大家族,是一个开源的生态系统,是一个分布式运行系统,是基于Java编程语言的架构。不过它最高明的技术还是HDFS和MapReduce,使得它可以分布式处理海量数据。
二、Hadoop产品
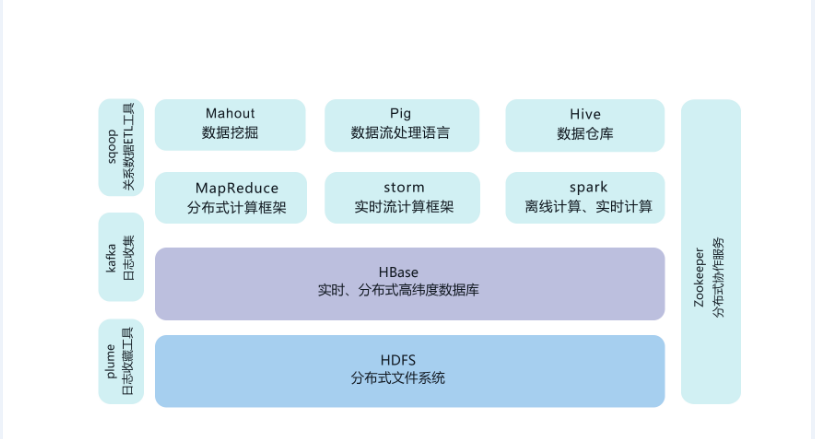
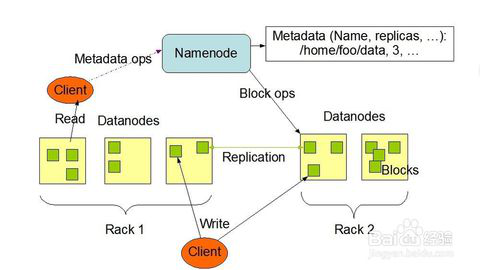
HDFS(分布式文件系统):
它与现存的文件系统不同的特性有很多,比如高度容错(即使中途出错,也能继续运行),支持多媒体数据和流媒体数据访问,高效率访问大型数据集合,数据保持严谨一致,部署成本降低,部署效率提高等,如图是HDFS的基础架构。
MapReduce/Spark/Storm(并行计算架构):
1、数据处理方式来说分离线计算和在线计算:
|
角色 |
描述 |
|
MapReduce |
MapReduce常用于离线的复杂的大数据计算 |
|
Storm |
Storm用于在线的实时的大数据计算,Storm的实时主要是一条一条数据处理; |
|
Spark |
可以用于离线的也可用于在线的实时的大数据计算,Spark的实时主要是处理一个个时间区域的数据,所以说Spark比较灵活。 |
2、数据存储位置来说分磁盘计算和内存计算:
|
角色 |
描述 |
|
MapReduce |
数据存在磁盘中 |
|
Spark和Strom |
数据存在内存中 |
Pig/Hive(Hadoop编程):
|
角色 |
描述 |
|
Pig |
是一种高级编程语言,在处理半结构化数据上拥有非常高的性能,可以帮助我们缩短开发周期。 |
|
Hive |
是数据分析查询工具,尤其在使用类SQL查询分析时显示出极高的性能。可以在分分钟完成ETL要一晚上才能完成的事情,这就是优势,占了先机! |
HBase/Sqoop/Flume(数据导入与导出):
|
角色 |
描述 |
|
HBase |
是运行在HDFS架构上的列存储数据库,并且已经与Pig/Hive很好地集成。通过Java API可以近无缝地使用HBase。 |
|
Sqoop |
设计的目的是方便从传统数据库导入数据到Hadoop数据集合(HDFS/Hive)。 |
|
Flume |
设计的目的是便捷地从日志文件系统直接把数据导入到Hadoop数据集合(HDFS)中。 |
以上这些数据转移工具都极大地方便了使用的人,提高了工作效率,把精力专注在业务分析上。
ZooKeeper/Oozie(系统管理架构):
|
角色 |
描述 |
|
ZooKeeper |
是一个系统管理协调架构,用于管理分布式架构的基本配置。它提供了很多接口,使得配置管理任务简单化。 |
|
Oozie |
Oozie服务是用于管理工作流。用于调度不同工作流,使得每个工作都有始有终。这些架构帮助我们轻量化地管理大数据分布式计算架构。 |
Ambari/Whirr(系统部署管理):
|
角色 |
描述 |
|
Ambari |
帮助相关人员快捷地部署搭建整个大数据分析架构,并且实时监控系统的运行状况。 |
|
Whirr |
Whirr的主要作用是帮助快速地进行云计算开发。 |
Mahout(机器学习):
Mahout旨在帮助我们快速地完成高智商的系统。其中已经实现了部分机器学习的逻辑。这个架构可以让我们快速地集成更多机器学习的智能。
hadoop家族学习路线图之hadoop产品大全的更多相关文章
- Hadoop家族学习路线图--转载
原文地址:http://blog.fens.me/hadoop-family-roadmap/ Sep 6, 2013 Tags: Hadoophadoop familyroadmap Comment ...
- Hadoop家族学习路线图
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- Hadoop家族学习路线图v
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- [转]Hadoop家族学习路线图
Hadoop家族学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, ...
- Hadoop家族学习路线图-张丹老师
前言 使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了.Hadoop在大数据领域的成功,更引发了它本身的加速发展.现 ...
- Hadoop家族学习路线、实践案例
作者:Han Hsiao链接:https://www.zhihu.com/question/19795366/answer/24524910来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- Hadoop家族 路线图(转)
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- Hadoop家族
现在Hadoop家族产品,已经达到20个了之多. 有必要对自己的知识做一个整理了,把产品和技术都串起来.不仅能加深印象,更可以对以后的技术方向,技术选型做好基础准备. 本文为"Hadoop家 ...
- Hadoop生态系统学习路线
主要介绍Hadoop家族产品,经常使用的项目包含Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa.新添加 ...
随机推荐
- html页面展示Json样式
一般有些做后台数据查询,要把后台返回json数据展示到页面上,如果需要展示样式更清晰.直观.一目了然,就要用到html+css+js实现这个小功能 一.css代码 pre {outline: 1px ...
- BZOJ1197 [HNOI2006]花仙子的魔法
其实是一道奇怪的DP题,蒟蒻又不会做... 看了Vfk的题解才算弄明白是怎么一回事: 令f[i, j]表示i维有j个球时最大切割部分,则 f[i, j] = f[i, j - 1] + f[i - 1 ...
- storage路径问题
1 概念总述 android开发中,关于存储路径,我们经常听到以下几个概念:内存.内部存储和外部存储,现在我们就来详细说说这三者区别与联系. 内存:英文中记为memory,即RAM 内部存储:英文记为 ...
- H5技术干货
H5技术干货 meta标签相关知识 H5页面窗口自动调整到设备宽度,并禁止用户缩放页面 <meta name="viewport" content="width=d ...
- python面试知识总结
1. 先做自我介绍 2. 做Python几年了?为什么选择Python?3. 学历?大学什么专业?4. 除了Python以外对其他语言有没有了解?5. 你对Python这门语言的看法?6. 在学习Py ...
- 你应该关注的几个Eclipse超酷插件
来自非营利性Eclipse基金会的Eclipse IDE以其插件生态系统著称.Eclipse市场拥有海量插件可供下载,你可以通过插件定制自己的Eclipse. 最近我在Eclipse Marketpl ...
- 在 windows 开发 reactNative 的环境 搭建过程 react-native-android
安装的东西挺多的, 从 jdk 到c++环境 到node , python, 各种模拟器 http://bbs.reactnative.cn/topic/10/%E5%9C%A8windows%E4% ...
- 利用nexus5伪造一张门禁卡
0×00 前言 我租住的杭州一个老小区一年前出现了所谓的“出租房杀人事件”,事件过后民警叔叔们给小区的每个单元都装上了门禁,所有住户都需要在物业处登记,物业的工作人员会让你提供身份证或者公交卡用来注册 ...
- 一款经典的 jQuery Lightbox 灯箱效果
一个灯箱效果的图片展示插件. 版本: jQuery v1.2.3+ jQuery Lightbox v2.7.1 github 实例预览 使用方法 载入 CSS 文件 <link rel=&qu ...
- Swift中WebView的应用
WebView控件是做网络应用开发中使用最多的控件,直接在WebView内部指定一个网页地址就可以访问网页了,同时也可以实现UIWebViewDelegate协议实现相应的方法去控制内容的加载和处理. ...