R及Rstuio下载及配置,及基本使用介绍
1、R和Rstudio下载地址
https://cran.rstudio.com/a
2、Rstudio 的配置
外观、代码显示比例配置
选中tools
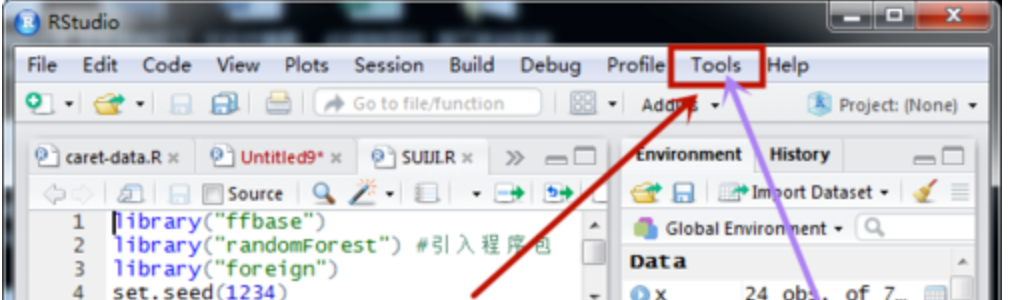
选中globle options
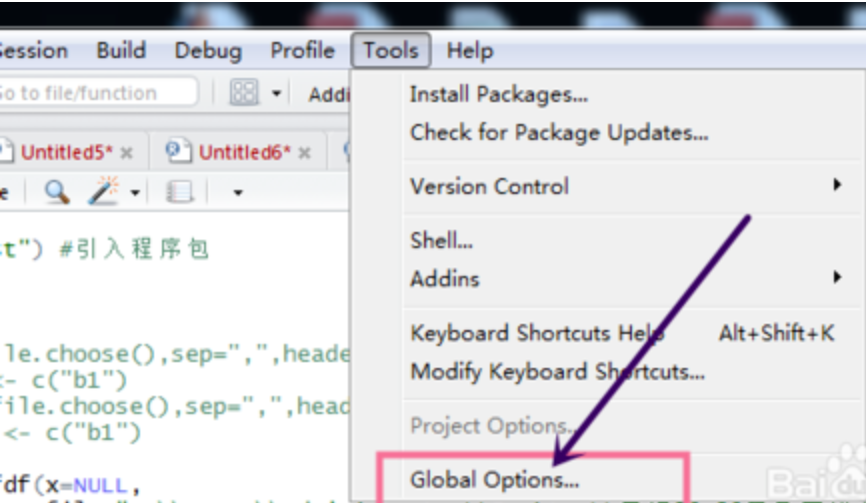
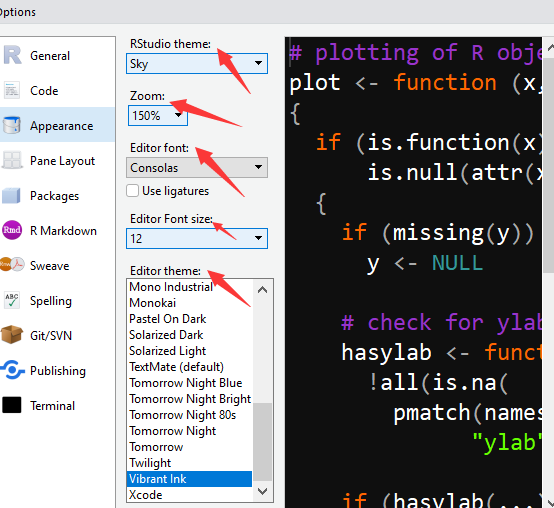
选中appearance

选择主题、缩放比例、字体、字体大小
---------------------------------------------华丽丽的分割线----------------------------------------------------
3、R简介
执行特定功能最基本的是R包,在使用前必须先从一些库(repository)中下载,并载入。两个最流行的R库是CRAN和Bioconductor(主要用于处理高通量测序数据)。默认情况下,R从CRAN抓取包,但根据需要你可以更换库,比如Biocondutor,,去获取其它CRAN库中没有的包。更换库不等于更换镜像,镜像是指同一个库(repository) at a different location,一个库可以含有许多镜像。
4、基本使用简介
4.0) 工作环境
>getwd() # 当前工作目录
>setwd('path/to/directory') #更换工作目录
4.1) 安装包
>install.packages('packagesname',dependency=TRUE)
>install.packages('path/to/packages.tar.gz',repos=NULL,type='source') ##从本地文件安装4.2)查看包
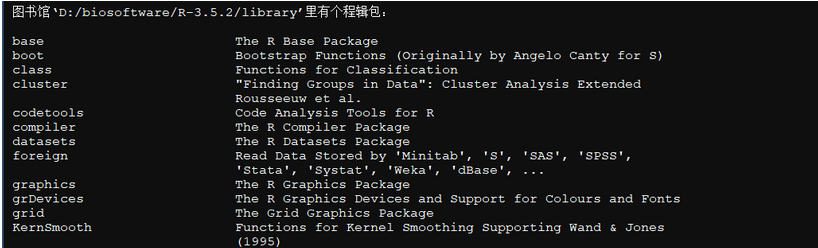
查看所有的包
>library()
查看默认包
>getOption('defaultPackages')
查看当前环境中所含有的包
print(.packages())
查看包里面所有的函数
>ls("package:GenomicFeatures")
4.3) 帮助文档
help(sum) 或者 ?sum
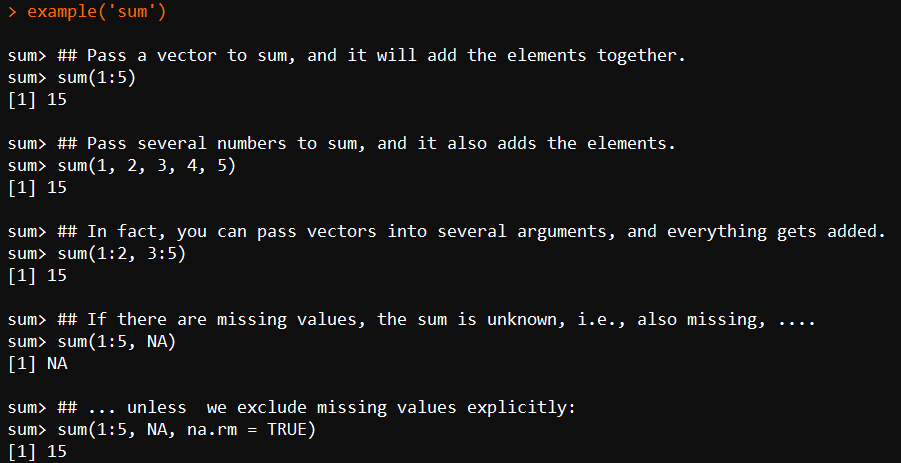
用例子来展示函数:
example(sum)
利用关键字搜素帮助文档:
>help.search('sum')
通过包名收索帮助文档:
>help(package='base')
4.4) 退出
q()
5)读取数据
5.1)对于R内置数据
>data(iris)
>load(file='mydata.RData') #载入数据对象
5.2)读取外部文件
>Mydata <- read.table('file',header='True',sep='\t',rowname=1)
>Mydata <- read.csv('file.csv')
5.3)读取excel文件
>install.packages('xlsx',dependeces=TRUE)
>library(gdata)
>mydata <- read.xlsx('mydata.xlsx')
5.4)数据探索
>class(iris)
>dim(iris)
>head(iris)
>tail(iris)
6) 保存数据
>wirte.table(x,file='myexcel.xls',append=false,quote=true,sep=' ') ##保存为table文件
>write.csv(x,col.names=NA,sep=',') ##保存为csv文件
>save(D,file='mydata.RData') ##保存为数据对象
--------------------------------------------------------------华丽丽的分割线----------------------------------------
7、R中索引方式
在R中,索引体系是[rows, columns]。
数据框$数据框名 :表示该数据框中该列所有的数据。
These functions use R indexing with named columns (the $ sign) or index numbers. The $ sign placed after the data followed by the column name specifies the data in that column. The R indexing system for data frames is very simple, just like other scripting languages, and is represented as [rows, columns].You can represent several indices for rows and columns using the c operator . A minus(减号) sign on the indices for rows/columns removes these parts of the data. The rbind function used earlier combines the data along the rows (row-wise,行向), whereas cbind does the same along the columns (column-wise,列向).
7.1)下面举例来说,首先载入数据
- data(iris) ##载入数据
- str(iris) ##观察数据结构


7.2) 获取特定列数据,组成一个数据框,存放到myiris对象中
- myiris <- iris[,c(1,2,5)] #虽然这种方法在实际应用中最好尽量去避免,这种写法。
- View(myiris)
- ls()
- rm(myiris)
- myiris <- iris[,-c(3,4)] #减号表示去除相应的数据,虽然这种方法也行,但在实际应用中最好尽量去避免
- View(myiris)
- ls()
- rm(myiris)
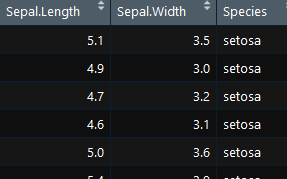
- myiris=data.frame(Sepal.Length=iris$Sepal.Length, Sepal.Width=iris$Sepal.Width,
- Species= iris$Species)#提取指定列,通过datafram函数构建数据框,存放到myiris对象中
- View(myiris)
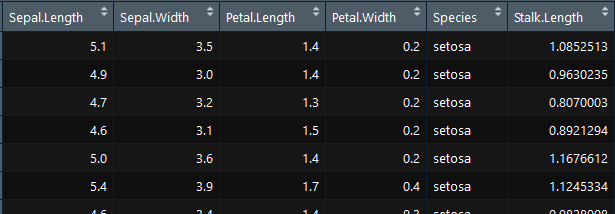
7.3)添加额外列(column)到数据框中
- Stalk.Length <-c(rnorm(30,1,0.1),rnorm(30,1.3,0.1), rnorm(30,1.5,0.1),rnorm(30,1.8,0.1), rnorm(30,2,0.1)) #获取150个数据,
- myiris <- cbind(iris, Stalk.Length) #cbind,将Stalk.Length列合并到iris框中
- dim(myiris)
- colnames(myiris) #获取列名

7.4)添加额外行(raw)到数据框
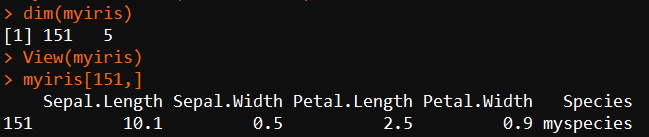
- newdat <- data.frame(Sepal.Length=10.1, Sepal.Width=0.5, Petal.Length=2.5, Petal.Width=0.9, Species="myspecies")
- myiris <- rbind(iris, newdat) #合并行
- dim(myiris)
- myiris[151,] #查看最后加入的行
- rownames(myiris) #这里相当于行号

7.5) 按照一定规则提取数据子集
- mynew.iris <- subset(myiris, Sepal.Length == 5.0) #提取符合Sepal.Length=5.0的数据
- rownames(mynewiris) #注意观察rownames是什么,是符合上述条件的数据所在的行号


也可以不用subset函数,用以下方法:
- rm(mynew.iris)
- mynew.iris <- myiris[myiris$Sepal.Length == 5.0, ]

删除所有数据对象。
- rm(list=ls())
另外一种方法是使用%in%方法
- data(iris)
mylength <- c(4,5,6,7,7,2)- mynew.iris <- iris[iris[,1] %in% mylength,]

R及Rstuio下载及配置,及基本使用介绍的更多相关文章
- CentOS环境下R语言的安装和配置
最近在看数据统计和分析,想到了R语言,于是就着手在自己的CentOS环境下进行安装和配置.步骤如下: 1.前往R官网下载安装包. 2.解压压缩包:tar xvzf R-3.2.2.tar.gz 3.进 ...
- CentOS 下 SonarQube 6.7 的下载、配置、问题排查
CentOS 下 SonarQube 6.7 的下载.配置.问题排查 系统: CentOS 7 x86_64 SonarQube 版本: 6.7.3 Java 版本: 1.8.0_171 MySQL ...
- JDK下载安装配置教程(详细)
JDK下载安装配置教程(详细) 版权声明:本文为原创文章,转载请附上原文出处链接和本声明.https://www.cnblogs.com/mxxbc/p/11844885.html 因为最近需要在Wi ...
- win10操作系统下oracle11g客户端/服务端的下载安装配置卸载总结
win10操作系统下oracle11g客户端/服务端的下载安装配置卸载总结 一:前提 注意:现在有两种安装的方式 1. oracle11g服务端(64位)+oracle客户端(32位)+plsql(3 ...
- Tomcat的下载和配置
目录结构: // contents structure [-] 下载Tomcat 配置Tomcat 运行Tomcat 参考文章 下载Tomcat 读者可以到apache官网下载Tomcat.笔者下载的 ...
- AgileEAS.NET SOA 中间件平台5.2版本下载、配置学习(四):开源的Silverlight运行容器的编译、配置
一.前言 AgileEAS.NET SOA 中间件平台是一款基于基于敏捷并行开发思想和Microsoft .Net构件(组件)开发技术而构建的一个快速开发应用平台.用于帮助中小型软件企业建立一条适合市 ...
- AgileEAS.NET SOA 中间件平台5.2版本下载、配置学习(三):配置ActiveXForm运行环境
一.前言 AgileEAS.NET SOA 中间件平台是一款基于基于敏捷并行开发思想和Microsoft .Net构件(组件)开发技术而构建的一个快速开发应用平台.用于帮助中小型软件企业建立一条适合市 ...
- AgileEAS.NET SOA 中间件平台5.2版本下载、配置学习(二):配置WinClient分布式运行环境
一.前言 AgileEAS.NET SOA 中间件平台是一款基于基于敏捷并行开发思想和Microsoft .Net构件(组件)开发技术而构建的一个快速开发应用平台.用于帮助中小型软件企业建立一条适合市 ...
- Stm32 SWD 下载 调试配置
找到一篇比较好的 关于stm32 SWD模式 下载 调试 配置文章 整理如下: 我们比较常用的是Jlink下载器 ,这种下载器有一个缺点就是使用的Jtag 20PIN接口,太多的PIN会 ...
随机推荐
- 利用Python玩微信跳一跳
创建python项目jump_weixin,新建python程序jump.py 需要4个辅助文件[adb.exe,AdbWinApi.dll,AdbWinUsbApi.dll,fastboot.exe ...
- form 表单提交浏览器的enctype(编码方式)
1. method 为 get 时 enctype :x-www-form-urlencoded(默认), 把form数据append到对应的url后面: 2. method 为 post 时 Bro ...
- 小峰servlet/jsp(5)jsp自定义标签
一.自定义标签helloworld: 二.自定义有属性的标签: HelloWorldTag.java:继承TagSupport: package com.java1234.tag; import ja ...
- DOM节点的增删改查
在开始展开DOM操作前,首先需要构建一棵DOM树. <!DOCTYPE html> <html lang="en"> <head> <me ...
- Java-Runoob-高级教程-实例-数组:05. Java 实例 – 数组输出
ylbtech-Java-Runoob-高级教程-实例-数组:05. Java 实例 – 数组输出 1.返回顶部 1. Java 实例 - 数组输出 Java 实例 以下实例演示了如何通过循环输出数 ...
- Java5,Java 6,Java 7,Java 8新特性
Java5: 1.泛型 Generics: 引用泛型之后,允许指定集合里元素的类型,免去了强制类型转换,并且能在编译时刻进行类型检查的好处. Parameterized Type作为参数 ...
- 深入理解yield(三):yield与基于Tornado的异步回调
转自:http://beginman.cn/python/2015/04/06/yield-via-Tornado/ 作者:BeginMan 版权声明:本文版权归作者所有,欢迎转载,但未经作者同意必须 ...
- MySQL 查看执行的SQL记录
我们时常会有查看MySQL服务端执行的SQL记录.在MySQL5.1之后提供了支持,通过在启动时加入-l 或者--log选项即可: mysqld -l mysqld --log 在后面的版本(5.1. ...
- 好用的 FTP 软件之 FileZilla 技巧教程
FTP 软件之 FileZilla教程 使用教程参考:http://163.26.161.1/~yilinteacher/wwwict/flash/FileZilla.swf (1)如何设置传输完成后 ...
- 高负载均衡学习haproxy之安装与配置
https://www.cnblogs.com/ilanni/p/4750081.html