PYTHON HTML.PARSER库学习小结--转载
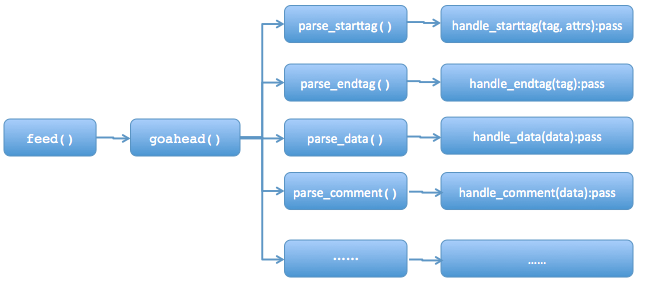
- feed(data):主要用于接受带html标签的str,当调用这个方法时并提供相应的data时,整个实例(instance)开始执行,结束执行close()。
- handle_starttag(tag, attrs): 这个方法接收Parse_starttag返回的tag和attrs,并进行处理,处理方式通常由使用者进行覆盖,本身为空。例如,连接的start tag是<a>,那么对应的参数tag=’a’(小写)。attrs是start tag <>中的属性,以元组形式(name, value)返回(所有这些内容都是小写)。例如,对于<A HREF="http://www.baidu.com“>,那么内部调用形式为:handle_starttag(’a’,[(‘href’,’http://www.baidu.com)]).
- handle_endtag(tag):跟上述一样,只是处理的是结束标签,也就是以</开头的标签。
- handle_data(data):处理的是网页的数据,也就是开始标签和结束标签之间的内容。例如:<script>...</script>的省略号内容
- reset():将实例重置,包括作为参数输入的数据进行清空。
</h3>
<p class="tb-subtitle">
【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【金冠信誉+顺丰包邮+全国联保---多重保障】
</p>
<div id="J_TEditItem" class="tb-editor-menu"></div>
【现货增强/标准】MIUI/小米 红米手机2红米2移动联通电信4G双卡
</h3>
<p class="tb-subtitle">
[红米手机2代颜色版本较多,请亲们阅读购买说明按需选购---感谢光临] 【金皇冠信誉小米手机集市销量第一】【购买套餐送高清钢化膜+线控通话耳机+ 剪卡器(含还原卡托)+ 防辐射贴+专用高清贴膜+ 擦机布+ 耳机绕线器+手机电影支架+ 一年延保服务+ 默认享受顺丰包邮 !
</p>
<div id="J_TEditItem" class="tb-editor-menu"></div>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#定义一个MyParser继承自HTMLParserclass MyParser(HTMLParser): re=[]#放置结果 flg=0#标志,用以标记是否找到我们需要的标签 def handle_starttag(self, tag, attrs): if tag=='h3':#目标标签 for attr in attrs: if attr[0]=='class' and attr[1]=='tb-main-title':#目标标签具有的属性 self.flg=1#符合条件则将标志设置为1 break else: pass def handle_data(self, data): if self.flg==1: self.re.append(data.strip())#如果标志为我们需要的标志,则将数据添加到列表中 self.flg=0#重置标志,进行下次迭代 else: passmy=MyParser()my.feed(html) |

PYTHON HTML.PARSER库学习小结--转载的更多相关文章
- Python html.parser库学习小结
分类路径:/Datazen/DataMining/Crawler/ 前段时间,一朋友让我做个小脚本,抓一下某C2C商城上竞争对手的销售/价格数据,好让他可以实时调整自己的营销策略.自己之前也有过写 ...
- python爬虫解析库学习
一.xpath库使用: 1.基本规则: 2.将文件转为HTML对象: html = etree.parse('./test.html', etree.HTMLParser()) result = et ...
- Python之matplotlib库学习
matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中. 它的文档相当完备, ...
- python 之Requests库学习笔记
1. Requests库安装 Windows平台安装说明: 直接以管理员身份打开cmd运行界面,使用pip管理工具进行requests库的安装. 具体安装命令如下: >pip instal ...
- Python之matplotlib库学习:实现数据可视化
1. 安装和文档 pip install matplotlib 官方文档 为了方便显示图像,还使用了ipython qtconsole方便显示.具体怎么弄网上搜一下就很多教程了. pyplot模块是提 ...
- 基于Windows平台的Python多线程及多进程学习小结
python多线程及多进程对于不同平台有不同的工具(platform-specific tools),如os.fork仅在Unix上可用,而windows不可用,该文仅针对windows平台可用的工具 ...
- Python之Pandas库学习(二):数据读写
1. I/O API工具 读取函数 写入函数 read_csv to_csv read_excel to_excel read_hdf to_hdf read_sql to_sql read_json ...
- Python之Pandas库学习(一):简介
官方文档 1. 安装Pandas windos下cmd:pip install pandas 导入pandas包:import pandas as pd 2. Series对象 带索引的一维数组 创建 ...
- python的pandas库学习笔记
导入: import pandas as pd from pandas import Series,DataFrame 1.两个主要数据结构:Series和DataFrame (1)Series是一种 ...
随机推荐
- 深入理解Fabric环境搭建的详细过程(转)
前面的准备工作我就不用多说了,也就是各种软件和开发环境的安装,安装好以后,我们git clone下来最新的代码,并切换到v1.0.0,并且下载好我们需要使用的docker镜像,也就是到步骤6,接下来我 ...
- [LeetCode] 53. Maximum Subarray_Easy tag: Dynamic Programming
Given an integer array nums, find the contiguous subarray (containing at least one number) which has ...
- [LeetCode] 176. Second Highest Salary_Easy tag: SQL
Write a SQL query to get the second highest salary from the Employee table. +----+--------+ | Id | S ...
- web前端面试小结(1)
两天大概面试了4家,有电面也有F2F,现将面试中的问题大概汇总下,一方面了解自己的不足,一方面用来勉励自己后面面试加油! 答案网上都有,就不一一写在这里了,后面有时间会把下面的问题分别拉出来详述. 1 ...
- linux服务后台管理
把进程放到后台有两种方法 1.cmmand & 2.ctrl+z 暂停到后台 查看后台服务 jobs 把后台进程移到前台 fg %2 工作号 恢复到前台 后台服务继续执行 bg ...
- lnmp1.4 安装php fileinfo扩展 方法
第一步:在lnmp1.4找到php安装的版本 使用命令 tar -jxvf php-7.1.7.tar.bz2 解压 第二步: 在解压的php-7.1.7文件夹里找到fileinfo文件夹,然 ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON AngleLl
zw版[转发·台湾nvp系列Delphi例程]HALCON AngleLl procedure TForm1.Button1Click(Sender: TObject);var Row1, Row2 ...
- mysql事务(二)——控制语句使用
事务控制 一般来说,mysql默认开启了事务自动提交功能,每条sql执行都会提交事务.可以使用如下语句关闭事务自动提交功能. show session variables like 'autocomm ...
- python 模拟windows键盘按键的封装
代码:在执行的时候,把光标放在指定的地方,在此例中,点击运行后把光标放到结果区域,粘贴的时候是粘贴到光标所在的问题,如过是运行脚本在web元素输入框中输入的话,不能移动光标到其他位置 #encodin ...
- P3501 [POI2010]ANT-Antisymmetry
P3501 [POI2010]ANT-Antisymmetry 二分+hash 注意:答案超出int范围 ------------ 先拿一个反对称串来做栗子:010101 我们可以发现 0101(左边 ...