Linux云计算运维-MySQL
0、建初心
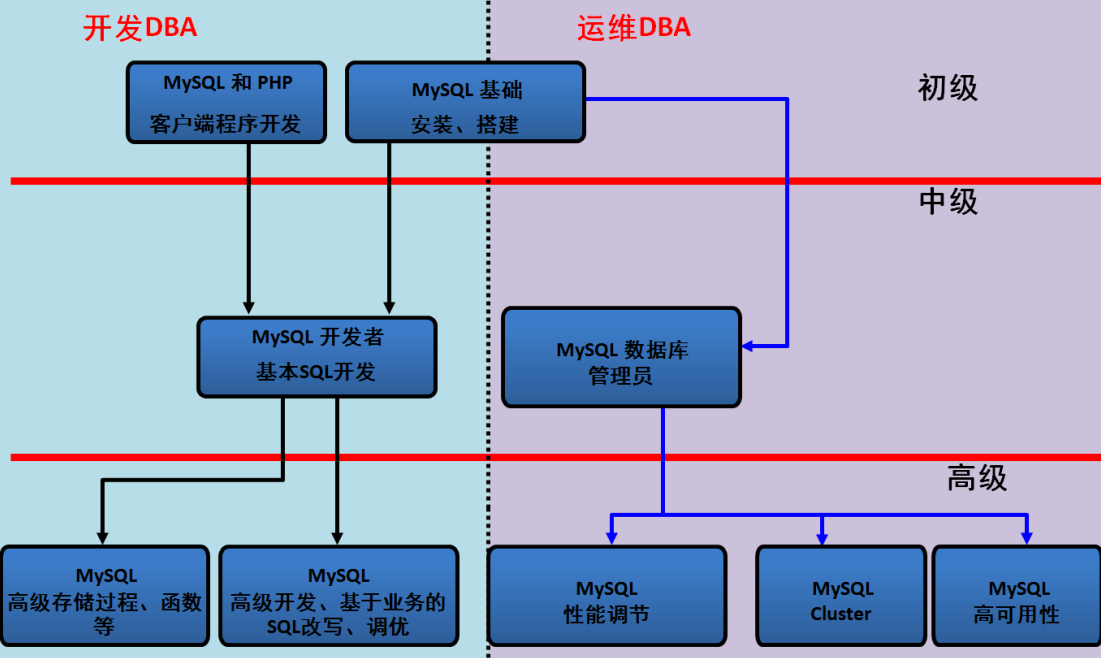
优秀DBA的素质
1、人品,不做某些事情
2、严谨,运行命令前深思熟虑,三思而后行,即使是依据select
3、细心,严格按照步骤一步一步执行,减少出错
4、心态,遇到灾难,首先要稳住,不慌张,不要受到旁人的影响
5、熟悉操作系统,Linux系统的工具和命令
6、熟悉业务(开发),编程语言
7、熟悉行业
8、喜欢数据库
• 什么是数据?
数据是指对客观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合。它是可识别的、抽象的符号。
• 什么是数据库管理系统?
将大量的数据规范的管理在一起的软件
• 数据库管理系统种类
关系型和非关系型

• 关系型数据库的特点
– 二维表
– 典型产品 Oracle传统企业, MySQL是互联网企业
– 数据存取是通过SQL
– 最大特点,数据安全性方面强(ACID)
• NoSQL:非关系型数据库(Not only SQL)
– 不是否定关系型数据库,做关系型数据库的的补充。
– 想做老大,先学会做老二。 RDBMS与NoSQL对比
• web1.0时代
企业提供内容,用户浏览,所以关系型数据库够用,并发并不高,所以不需要NoSQL。
• web2.0时代
核心是企业提供平台,用户参与提供内容。这时关系型数据库无法满足需求了。
• NoSQL出现
memcached诞生,关注的点是性能,而安全性关注比较低。随着安全性需求不断提升,所以有了redis。
• redis特点
– 依然高性能该并发,
– 数据持久化的功能
– 支持多数据类型,主从复制和集群
– 管理不再使用SQL了
• NoSQL特性总览
– 不是否定关系型数据库,而是作为补充,现在也有部分替代的趋势。
– 关注高性能,高并发,灵活性,忽略和上述无关的功能。
– 现在也在提升安全性和使用功能。
– 典型产品: Redis(持久化缓存,两个半天)、 MongoDB(最接近关系型数据的NoSQL)、 Memcached。
– 管理不适用SQL管理,而是用一些特殊的 API 或 数据接口。
• NoSQL的分类、特点、典型产品
– 键值(KV)存储: Memcached、 Redis
– 列存储(column-oriented): HBASE(新浪, )、 Cassandra(200台服务器集群)
– 文档数据库(document-oriented): MongoDB(最接近关系型数据库的NoSQL)
– 图形存储(Graph): Neo4j
常见数据库企业及其产品
• Oracle数据库版本介绍
– 7--8i--9i--10g—11g--12c--18c(?)
• Oracle的市场应用
– 市场份额第一,趋势递减
– 市场空间,传统企业
– 传统企业也在互联网化
• MySQL数据库版本介绍
– 5.0--5.1--5.5--5.6--5.7--8.0
5.0和5.1已经不能用了,5.6和5.7是现在的主流,8.0暂时还没有稳定的版本
• MySQL的市场应用
– 中、大型互联网公司
– 市场空间:互联网领域第一
– 趋势明显
– 同源产品: MariaDB、 perconaDB 其他公司产品介绍
• 微软: SQL Server
– 微软和sysbase合作开发的产品,后来自己开发,windows平台
– 3,4线小公司,传统行业在用
• IBM : DB2
– 市场占有量小
– 目前只有:国有银行(人行、中国银行、工商银行等)、中国移动应用。
• PostgreSQL
• MongoDB
• Redis
后三者广泛应用在大型互联网公司。
MySQL发展史
• 1979年,报表工具Unireg出现。
• 1985 年,以瑞典David Axmark 为首,成立了一家公司(AB前身), IASM引擎出现。
• 1990年,提供SQL支持。
• 1999-2000年, MySQL AB公司成立,并公布源码,开源化。
• 2000年4月BDB引擎出现,支持事务。
• 2008年1月16号 MySQL被Sun公司收购。
• 2009年04月20日Oracle收购Sun公司, MySQL 转入Oracle 门下。
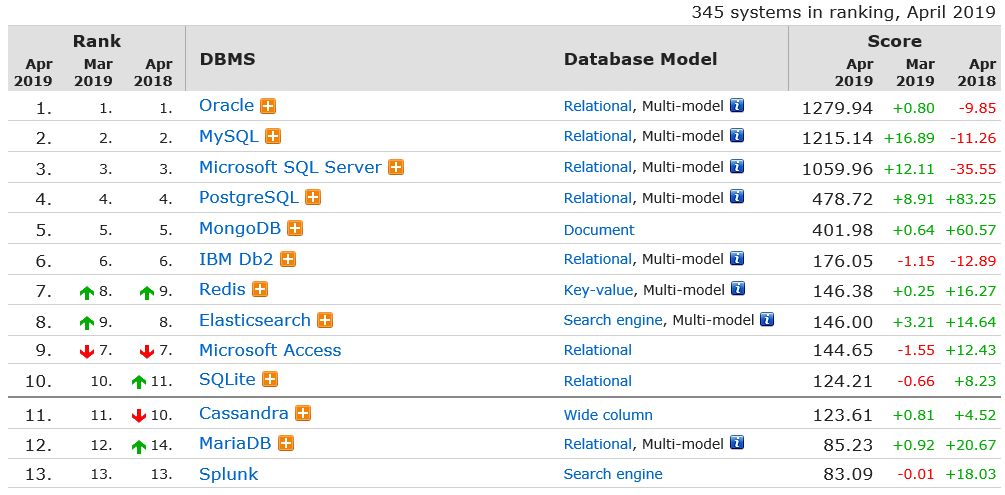
https://db-engines.com/en/ranking 点击查看各种数据度广度排名
1、MySQL的安装和配置
一、MySQL5..36安装前准备 ()克隆一个模板机器(使用centos6),克隆完做快照
()IP 10.0.0.52 主机名db02
()iptables selinux 关闭
()下载好5.6.36
官网下载 ftp://ftp.jaist.ac.jp/pub/mysql/Downloads/MySQL-5.6/ 下载完成最好比对一下md5
()安装依赖包
yum install -y ncurses-devel libaio-devel
()安装cmake
yum install cmake –y
()创建用户
useradd -s /sbin/nologin -M mysql
id mysql 二、MySQL下载安装 ()创建软件下载目录:
mkdir -p /server/tools
cd /server/tools/
()下载并上传到/server/tools
将下载的MySQL上传到服务器文件
社区版MySQL Community Server
5.6 5.6.3x 5.6. 5.6. 5.6.
发布超过6-12余额的版本
5.7 5.7.17以后
()解压:
cd /server/tools
tar xf mysql-5.6..tar.gz
()安装:注意修改自己下载的版本号,我这里是5.6.36,版本号输入错误会导致安装失败
cd mysql-5.6. cmake . -DCMAKE_INSTALL_PREFIX=/application/mysql-5.6. \
-DMYSQL_DATADIR=/application/mysql-5.6./data \
-DMYSQL_UNIX_ADDR=/application/mysql-5.6./tmp/mysql.sock \
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_EXTRA_CHARSETS=all \
-DWITH_INNOBASE_STORAGE_ENGINE= \
-DWITH_FEDERATED_STORAGE_ENGINE= \
-DWITH_BLACKHOLE_STORAGE_ENGINE= \
-DWITHOUT_EXAMPLE_STORAGE_ENGINE= \
-DWITH_ZLIB=bundled \
-DWITH_SSL=bundled \
-DENABLED_LOCAL_INFILE= \
-DWITH_EMBEDDED_SERVER= \
-DENABLE_DOWNLOADS= \
-DWITH_DEBUG=
执行到这里也许会抱一个错误,导致安装失败
CMake Error: your CXX compiler: "CMAKE_CXX_COMPILER-NOTFOUND" was not found. Pleaet CMAKE_CXX_COMPILER to a valid compiler path or name.
这是因为系统缺少C++编译器
yum install gcc-c++ -y
make && make install 太慢了... 三、配置并启动 ()制作软连接:
ln -s /application/mysql-5.6./ /application/mysql ()拷贝配置文件到/etc:覆盖原文件
cp support-files/my*.cnf /etc/my.cnf ()初始化数据库:创建元数据,系统数据库
/application/mysql/scripts/mysql_install_db --basedir=/application/mysql/ --datadir=/application/mysql/data --user=mysql ()创建关键目录并设置权限:
mkdir -p /application/mysql/tmp
chown -R mysql.mysql /application/mysql/ ()复制启动脚本到/etc/init.d/mysqld
cp support-files/mysql.server /etc/init.d/mysqld ()启动数据库
chkconfig mysqld on
/etc/init.d/mysqld start
netstat -lntup|grep ()配置环境变量
echo 'PATH=/application/mysql/bin/:$PATH' >>/etc/profile
tail - /etc/profile
source /etc/profile
echo $PATH
mysql select user,host,password from mysql.user; 排错:
1、输出
2、错误日志
tail -100 /application/mysql/data/db02.err
设置密码:
mysqladmin -u root password 'pizza123'
mysql -uroot -pizza123
清理用户及无用数据库(基本优化)
select user,host from mysql.user;
drop user ''@'db02';
drop user ''@'localhost';
drop user 'root'@'db02';
drop user 'root'@'::1';
select user,host from mysql.user;
drop database test;
show databases;
作业
、请列举你了解到的数据库典型产品 、请说明企业中选择数据库版本的规则 、请简述MySQL数据库支持的安装方式 、编译安装自己的一套MySQL数据库 、简述mysql_install_db命令的常用参数 、简述5.7版本安装过程中与5.6的区别(自己扩展学习)
2、MySQL 体系结构
客户端与服务器端模型
1、cs之间通过TCP/IP链接

2、cs之间通过socket链接
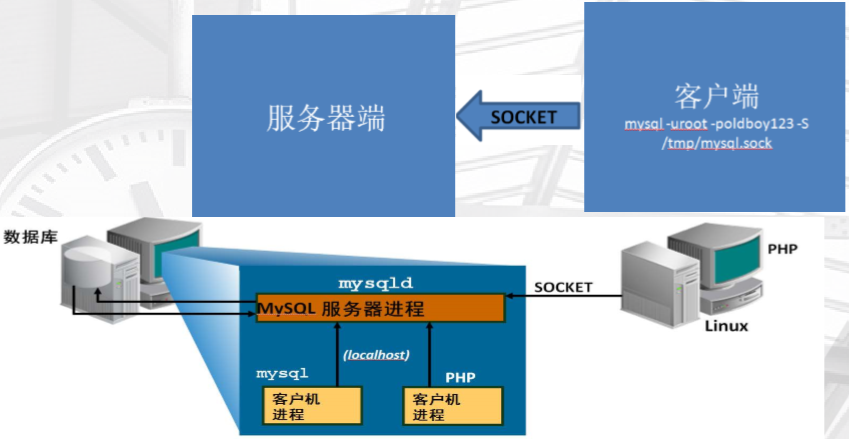
所以,对应两种链接到数据库的方法
• 通过网络连接串
mysql -uroot -poldboy123 -h 10.0.0.200
• 通过套接字文件
mysql -uroot -poldboy123 -S /tmp/mysql.sock
• 思考: mysql - uroot - poldboy123 使用的是什么方式登录的?
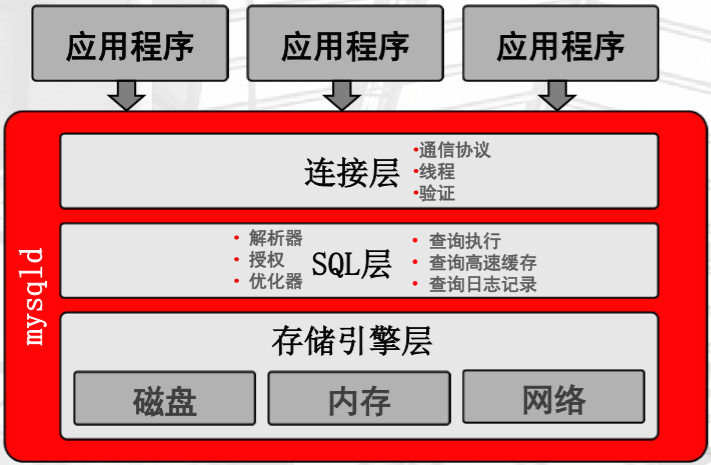
MySQL体系结构-实例、连接层、SQL层详解
• MySQL在启动过程
– 启动后台守护进程,并生成工作线程
– 预分配内存结构供MySQL处理数据使用
• 实例是什么?
MySQL的后台进程+线程+预分配的内存结构。
mysqld服务器程序的构成
show processlist;可以查看链接到MySQL的信息
SQL处理流程
在SQL层中,语句交给解析器,转换成执行计划,交给查询执行
当有多种执行计划时,交给优化器,确认执行计划,交给查询执行
得到的结果(获取数据的方式,即位置)交给存储引擎层,
、接收到连接层送过过来的“SQL”
、由专门的模块,会判断SQL语法、语义(SQL语句的类型:DDL、DCL、DML)
、将不同类型的语句,送到专门的处理接口(解析器)
、解析器,将SQL解析成执行计划
、优化器,会选择“它”最优的执行计划交给执行器
、执行器,执行 执行计划,得出如何去“磁盘”获取数据的方法
、专门线程将获取数据的方法,送给下层(存储引擎层)继续处理。
、验证授权,当前用户对 库或表对象有没有操作的权限。
、查询高速缓存query_cache。
、记录修改操作日志binlog。

存储引擎层
真正接触数据,和数据打交道的,接受SQL层执行计划的结果,去指定的位置取指定的数据,或者将数据存储在哪个位置

存储引擎是充当不同表类型的处理程序的服务器组件。
• 存储引擎用于:
– 存储数据
– 检索数据
– 通过索引查找数据
• 双层处理
– 上层包括SQL解析器和优化器
– 下层包含一组存储引擎
• SQL 层不依赖于存储引擎:
– 引擎不影响SQL处理
– 有一些例外,
依赖于存储引擎的功能
• 存储介质
• 事务功能
• 锁定
• 备份和恢复
• 优化
• 特殊功能:
– 全文搜索
– 引用完整性
– 空间数据处理
简述MySQL的整个处理过程
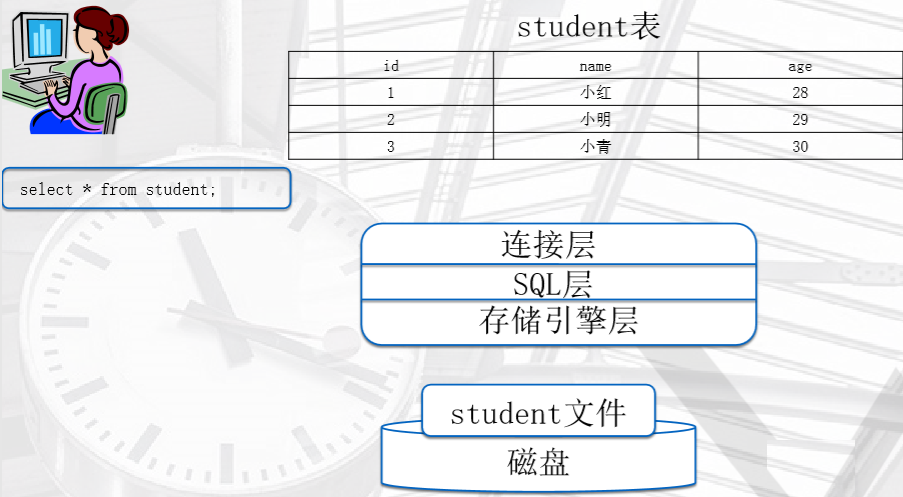
首先,在磁盘中存储的数据肯定不是这个表的形式,在命令运行之后,经过一系列的操作,表格才展现在我们眼前
1、连接层
通信协议---验证---授权---提供链接线程---接收SQL语句,并交给SQL层
2、SQL层
见上面的流程,验证语法、语义(查询or插入)---query_cache---解析---优化---
3、存储引擎层
去指定位置取指定的数据---返回给SQL层---处理---连接层交给用户展现
数据库的逻辑结构
列、数据行、表、库 就是这些抽象出来的结构
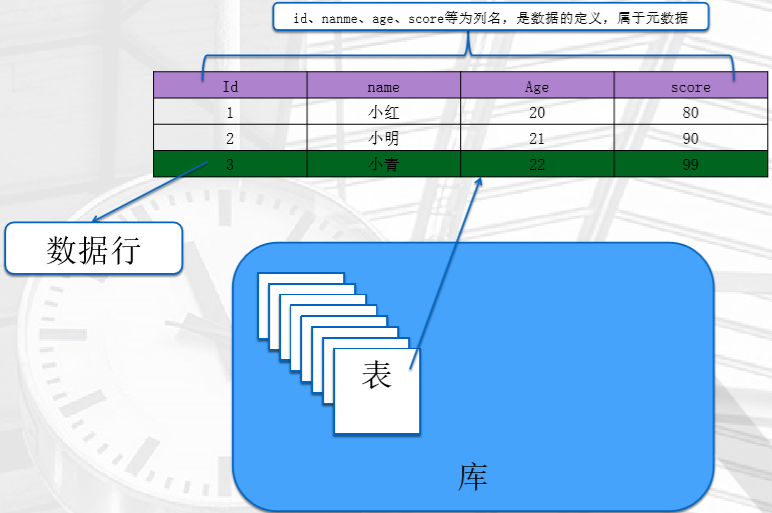
在物理层,是怎么存储到磁盘的呢?见下图,MySQL对磁盘的使用
注:我们只研究到文件系统层

程序文件随数据目录一起存储在服务器安装目录下。执行各种客户机程序、管理程序 和实用程序时将创建程序可执行文件和日志文件。
首要使用磁盘空间的是数据目录。
• 服务器日志文件和状态文件: 包含有关服务器处理的语句的信息。日志可用于进行故障排除、监视、复制和恢复。
• InnoDB 日志文件: (适用于所有数据库)驻留在数据目录级别。
• InnoDB 系统表空间:
包含数据字典、撤消日志和缓冲区。
每个数据库在数据目录下均具有单一目录(无论在数据库中创建何种类型的表)。
数据库目录存储以下内容:
- 数据文件: 特定于存储引擎的数据文件。这些文件也可能包含元数据或索引信息,具体取决于所使用的存储引擎。
- 格式文件 (.frm): 包含每个表和/或视图结构的说明,位于相应的数据库目录中。
- 触发器: 与某个表关联并在该表发生特定事件时激活的命名数据库对象。
数据目录的位置取决于配置、操作系统、安装包和分发。
典型位置是 /var/lib/mysql。 MySQL在磁盘上存储系统数据库 (mysql)。
mysql 包含诸如用户、特权、插件、 帮助列表、事件、时区实现和存储例程之类的信息。
页(默认是16k):是mysql数据库存储的最小单元
区:连续的多个页组成,是一系列练习的数据行
段:一个表(分区表)就是一个段,包含了多个区
3、MySQL的基本管理
• MySQL的连接管理
mysql命令 -u 用户名
-p 密码 例子:
mysql -uroot -pizza123 -h ip
例子:
mysql -uroot -pizza123 -h 10.0.0.52 -P
例子:
mysql -uroot -pizza123 -h 10.0.0.52 -P -S /tmp/mysql.sock 套接字目录
例子:
mysql -uroot -pizza123 -S /application/mysql/tmp/mysql.sock -e "show variables like 'server_id';" 免交互式执行SQL命令,直接获得结果
例子:
mysql -uroot -pizza123 -e "show variables like 'server_id';" mysqladmin
mysqladmin -uroot -p password pizza123
• MySQL用户管理及权限基本管理
用户权限由用户名+主机范围构成
对比一下Linux用户和MySQL用户
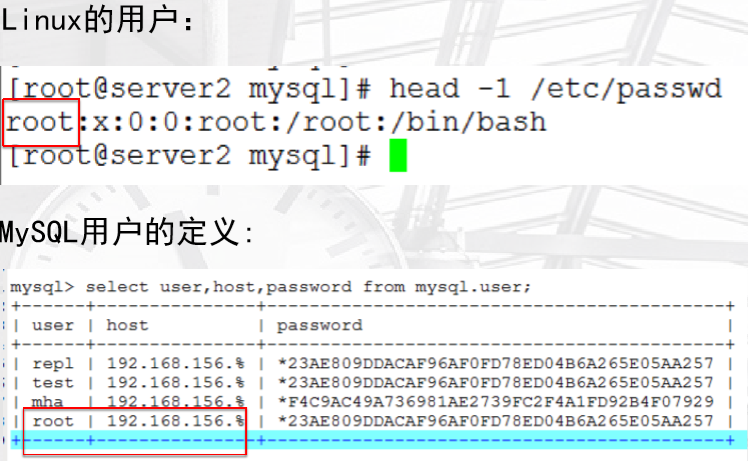
user:表示使用哪个用户登陆
host:表示从哪些地址访问这个数据库
• 用户的作用:
– 、用户登录
– 、用于管理数据库及数据
• 权限: 针对不同用户设置不同对象管理能力
– 对数据库的读、写等操作
– (insert update、select等)
• 角色:
– 数据库定义好的一组权限的定义
– (all privileges、replication slave等)
• 权限范围:
– 全库级别: *.*
– 单库级别:oldboy.*
– 单表级别:oldboy.t1
超级管理(管理)用户:root ,当前如果要进行授权操作只能用root进行
也不用再去创建了,当然也可以根据不同的地址,主机域去设置不同的密码和操作
mysqladmin -uroot -p password pizza123 这条命令,执行的是root@localhost,即只在本地生效的权限范围
普通用户(开发)的权限包括:select update delete insert drop ...用的比较多的
用户操作命令
• 查看当前用户:
select user,host from mysql.user;
• 创建用户
CREATE USER '用户'@'主机' IDENTIFIED BY '密码';
create user 'pizza'@'localhost' identified by 'pizza123';
#只有连接权限 企业里创建用户一般是授权一个内网网段登录,最常见的网段写法有两种。
方法1:172.16.1.%(%为通配符,匹配所有内容)。
方法2:172.16.1.0/255.255.255.0,但是不能使用172.16.1.0/24,是个小遗憾。
# 远程登录,带参数-h
mysql> create user web01@'10.0.0.%' identified by '123';
[root@web01 mysql-5.6.43]# mysql -uweb01 -p123 -h10.0.0.7
登陆后的普通用户,权限很低 标准的建用户方法:
create user 'web'@'172.16.1.%' identified by 'web123';
• 查看用户对应的权限
show grants for oldboy@localhost\G
• 删除用户
drop user 'user'@'主机域' 或者 drop user root@'127.0.0.1';
用户优化:只保留 有密码和有用户名的
| root | 127.0.0.1 |
| root | localhost |
特殊的删除方法:
mysql> delete from mysql.user where user='pizza' and host='localhost';
Query OK, row affected (0.00 sec) mysql> flush privileges; • 给用户授权
create user 'pizza'@'localhost' identified by 'pizza123';
select user,host from mysql.user;
GRANT ALL ON *.* TO 'pizza'@'localhost';
SHOW GRANTS FOR 'pizza'@'localhost'\G
• 创建用户的同时授权
grant all on *.* to pizza@'172.16.1.%' identified by 'pizzal123';
flush privileges; #<==可以不用。
create user 'pizza'@'localhost' identified by 'pizza123';
GRANT ALL ON *.* TO 'pizza'@'localhost';
• 授权和root一样的权限
grant all on *.* to system@'localhost' identified by 'pizzal123' with grant option;
• 收回权限
REVOKE INSERT ON *.* FROM pizza@localhost;
• 可以授权的用户权限
INSERT,SELECT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN, PROCESS, FILE,
REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES,
LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW,
SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER,
CREATE TABLESPACE
• 开发用户 拥有的基本权限
INSERT,SELECT, UPDATE, DELETE, CREATE, DROP
grant INSERT,SELECT, UPDATE, DELETE, CREATE, DROP on testdb.* to web01@‘10.0.0.%’;
• 工作博客授权:
grant select,insert,update,delete,create,drop on blog.* to 'blog'@'172.16.1.%' identified by 'blog123';
revoke create,drop on blog.* from 'blog'@'172.16.1.%';
最多:select,insert,update,delete
• 注意: 思考一下如果在oldboy.*,设置了select,insert,update,delete 在oldboy.t1设置了select,
那么用户在t1表的最终权限应该是什么。 回收权限的时候又该怎么做?
实验后的结论:
如果对于某个用户在不同数据库级别都设置了权限,最终权限相叠加,以加起来的最大权限为准。
建议:不要多范围授权
• MySQL的启动和关闭(启动脚本介绍)
数据库的启动流程介绍

mysql最终启动的是mysqld进程,通过他提供的启动脚本,不能直接启动mysqld
数据库的关闭
• mysqladmin shutdown
• servive mysqld stop
• kill - ? 慎用
• 第三种为利用系统进程管理命令关闭MySQL。
– kill pid #<==这里的pid为数据库服务对应的进程号。
– killall mysqld #<==这里的mysqld是数据库服务对应的进程名字。
– pkill mysqld #<==这里的mysqld是数据库服务对应的进程名字。
可通过如下地址查看生产高并发环境野蛮粗鲁杀死数据库导致故障企业案例:
http://oldboy.blog.51cto.com/2561410/1431161
http://oldboy.blog.51cto.com/2561410/1431172
MySQL启动报错
停数据库----去mysql/data目录下--随便改一个文件(目录下的一个文件权限改成root)---启动数据库
报错
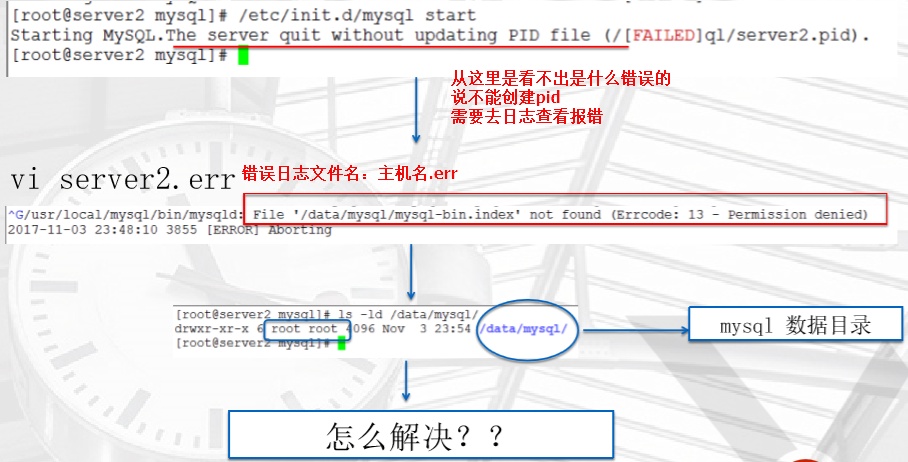
常规的报错代码整理 http://oldboy.blog.51cto.com/2561410/1728380
• MySQL数据库配置文件详解
启动之前都做了什么?
1、程序在哪
2、启动后去哪里找数据
3、启动之后分配多大内存
...
n、还有许许多多的问题
MySQL的初始化配置文件
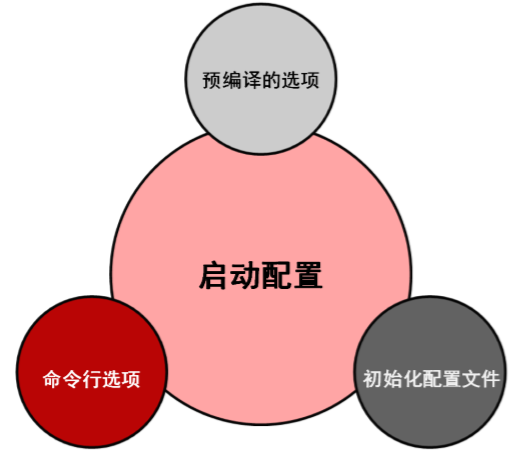
预编译配置项,即在使用cmake时,硬编码设置的参数,指定了如安装目录、数据目录、sock目录
命令行设置,在命令行上配置参数
/application/mysql/bin/mysqld_safe 用来启动mysql,因为设置过环境变量,可以直接运行
mysqld_safe --socket=/tmp/mysql.sock --port=3307 &
链接,不能用老的方式了
mysql -uroot -ppizza -S /tmp/mysql.sock
初始化配置文件,/etc/my.cof
标签的种类和影响的程序
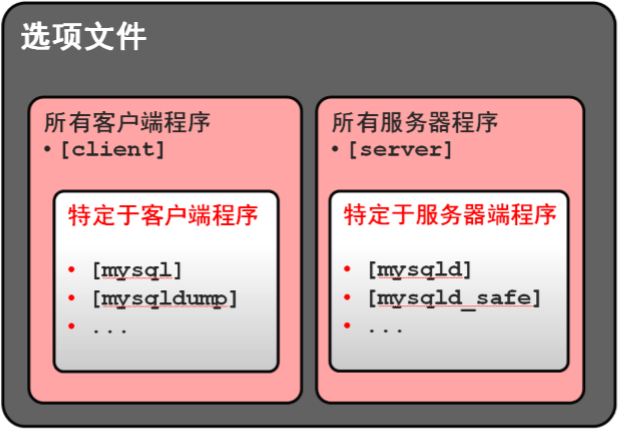
选项文件示例
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
socket=/application/mysql/tmp/mysql.sock
port=3306
server_id=10
log-error=/var/log/mysql.log
log-bin=/application/mysql/data/mysql-bin
binlog_format=row
skip_name_resolve [mysql]
socket=/application/mysql/tmp/mysql.sock
- 数据库的启动(客户端)
- 启动文件的启动选项包括
- 共享内存
- 日志记录
- 系统变量
- 默认存储引擎
- 命名管道链接
- 启动文件的启动选项包括
- 数据库的链接(服务器)
优先级
mysql 启动参数设置
、预编译时候设置参数,参数会硬编码到程序中
、命令行方式设定启动参数
、初始化的配置文件
>>
MySQL为我们配置了很多配置文件,配置文件读取顺序如下
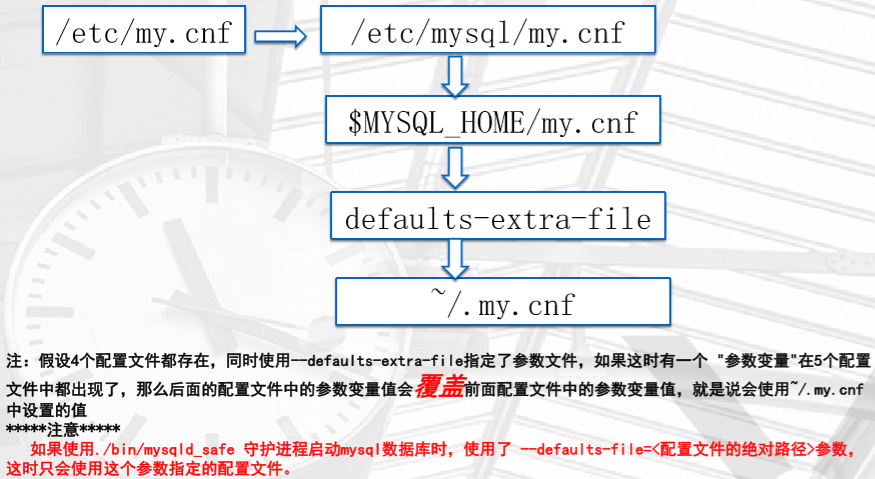
自定义配置文件位置,系统自己是找不到的
vim /tmp/aa.txt
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
port=
socket=/tmp/mysql.sock
使用自定义的配置文件
/etc/init.d/mysqld stop
mysqld_safe --defaults-file=/tmp/aa.txt &
• 多实例简介及配置
一个MySQL实例就是一个进程,多个线程,一定量预分配的内存空间
多实例就是,多个这样的实例管理不同的数据,和一些日志
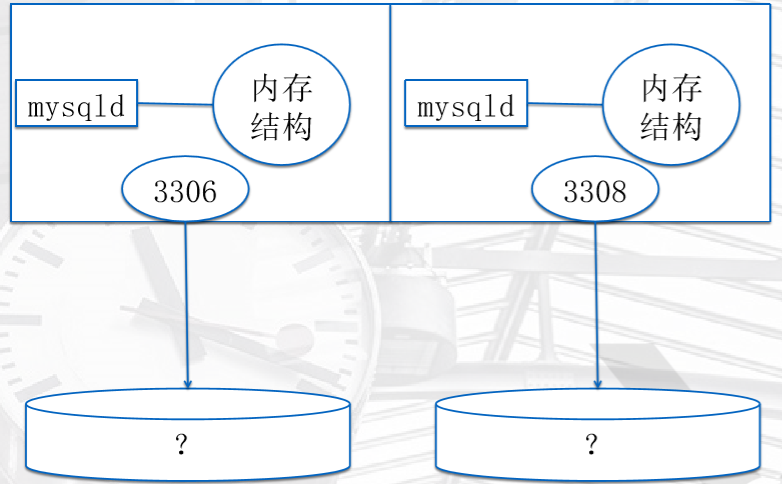
思路
、启动多个mysqld进程
、规划多套数据
、规划多个端口
、规划多套日志路径
多实例配置
、创建多套目录
mkdir -p /data/{,,}
、准备多套配置文件
vim /data//my.cnf
[mysqld]
basedir=/application/mysql
datadir=/data/
server-id=
port=
log-bin=/data//mysql-bin
socket=/data//mysql.sock
log-error=/data//mysql.log
vim /data//my.cnf
[mysqld]
basedir=/application/mysql
datadir=/data/
server-id=
port=
log-bin=/data//mysql-bin
socket=/data//mysql.sock
log-error=/data//mysql.log
vim /data//my.cnf
[mysqld]
basedir=/application/mysql
datadir=/data/
server-id=
port=
log-bin=/data//mysql-bin
socket=/data//mysql.sock
log-error=/data//mysql.log
、初始化多套数据
/application/mysql/scripts/mysql_install_db --basedir=/application/mysql/ --datadir=/data/ --user=mysql
/application/mysql/scripts/mysql_install_db --basedir=/application/mysql/ --datadir=/data/ --user=mysql
/application/mysql/scripts/mysql_install_db --basedir=/application/mysql/ --datadir=/data/ --user=mysql
、启动多个实例
mysqld_safe --defaults-file=/data//my.cnf &
mysqld_safe --defaults-file=/data//my.cnf &
mysqld_safe --defaults-file=/data//my.cnf &
、查看启动端口
netstat -lnp |grep
、分别连接测试
mysql -S /data//mysql.sock -e "show variables like 'server_id';"
mysql -S /data//mysql.sock -e "show variables like 'server_id';"
mysql -S /data//mysql.sock -e "show variables like 'server_id';"
作业
、列出MySQL在Linux下的两种连接方式 、简述mysql修改密码方法 、简述实例的构成 、结合MySQL体系结构,说明一条SQL语句的执行过程 、mysql的默认日志文件在什么位置 、简述MySQL的启动方式 、简述MySQL配置文件读取顺序 、配置MySQL多实例,端口分别为3307 、请介绍mysql连接命令的常用参数,并说明功能 、请简述MySQL的逻辑构成
• 数据库对象管理——SQL(库、表、行记录)
4、MySQL客户端工具及SQL入门
• MySQL 客户端命令
mysql命令
• mysql:
– 用于数据库连接管理
– 前面章节已经使用过(略。)
– 命令接口自带命令
• 1、\h 或 help 或 ?
• 2、\G 键值对的方式排列
• 3、\T 或 tee 记录到日志
• 4、\c 或 CTRL+c 结束上一条命令
• 5、\s 或 status 查看数据库基本状态信息
• 6、\. 或 source 调用外部SQL脚本
• 7、\u 或use
– 将 用户SQL 语句发送到服务器,管理数据库
结构化查询语言,MySQL接口程序只负责接受SQL,传送给SQL层
– DDL:数据库(对象)定义语言
– DCL:数据控制语言(grant、revoke)
– DML:数据(行)操作语言(update、delete、insert)
- DQL:数据查询语言(show、select)
• mysqladmin:
– 命令行管理工具
• mysqldump:
– 备份数据库和表的内容
source命令使用
• 在 mysql 中处理输入文件:
• 如果这些文件包含 SQL 语句,则称为:
– “脚本文件”
– “批处理文件”
• 使用 SOURCE 命令:
mysql> SOURCE /data/mysql/world.sql
或者使用非交互式:
mysql</data/mysql/world.sql
mysqladmin命令
• DBA的命令行客户端工具
• 多项功能:
– “强制回应 (Ping)”服务器。
– 关闭服务器。
– 创建和删除数据库。
– 显示服务器和版本信息。
– 显示或重置服务器状态变量。
– 设置口令
– 重新刷新授权表。
– 刷新日志文件和高速缓存
– 启动和停止复制
– 显示客户机信息
• 命令帮助及基本语法:
mysqladmin --help
mysqladmin -u<name> -p<password> commands
• 例子:
mysqladmin version
mysqladmin status
mysqladmin ping
mysqladmin processlist
mysqladmin shutdown
mysqladmin variables
…
mysqldump命令简介
• 数据库备份工具。
• 命令帮助及基本语法:
mysqldump –help
Usage: mysqldump [OPTIONS] database [tables]
OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...]
OR mysqldump [OPTIONS] --all-databases [OPTIONS]
数据库对象:库、表
库的名字,库的基本属性 create database blog;
• MySQL 获取帮助的方法
help命令的使用
• 查看完整的 SQL 类别列表:
mysql> HELP CONTENTS
...
Account Management
Administration
Compound Statements
Data Definition
Data Manipulation Data Types
...
• 有关特定 SQL 类别或语句的帮助:
mysql> HELP Data Manipulation
mysql> HELP JOIN
• 有关与状态相关的 SQL 语句的帮助:
mysql> HELP STATUS
• DDL操作简介
DDL操作:
对象:
库:
定义什么?
、库名字
、库的基本属性
如何定义?
create database lufei;
create schema lf;
show databases;
create database llf CHARACTER SET utf8 ;
show create database llf;
drop database llf;
help create database;
字符集: CHARACTER SET [=] charset_name
排序规则:COLLATE [=] collation_name 改库的字符集:
ALTER DATABASE [db_name] CHARACTER SET charset_name COLLATE collation_name
mysql> alter database lf charset utf8mb4;
mysql> show create database lf; 表:
表数据:数据行
表属性(元数据):表名、列名字、列定义(数据类型、约束、特殊列属性)、表的索引信息
定义什么?
定义表的属性。
use lufei;
创建:
create table t1 (id int ,name varchar());
查询:
show tables;
show create table t1;
desc
删除
drop table t1;
修改:
()在表中添加一列
alter table t1 add age int;
()添加多列
alter table t1 add bridate datetime, add gender enum('M','F');
()在指定列后添加一列,没有before(,这是一个可有可无的选项,降低开发需求)
alter table t1 add stu_id int after id;
()在表中最前添加一列
alter table t1 add sid int first;
()删除列
alter table t1 drop sid;
()修改列名
alter table t1 change name stu_name varchar();
()修改列属性
alter table t1 modify stu_id varchar();
()修改表名
rename table t1 to student;
alter table student rename to stu;
• DDL 语句之管理数据库
• 查看数据库
show databases;
show databases like '%old%';
• 获取命令帮助
? contents
?Administration
? show database
• 创建数据库
CREATE DATABASE oldboy; #字符集和编译指定相同.
• 获取命令帮助
? contents
?Data Definition
? create database
• 查看建库的语句
show create database oldboy\G
• 指定字符集建库
CREATE DATABASE db_name CHARACTER SET
charset_name COLLATE collation_name
CREATE DATABASE oldgirl CHARACTER SET gbk COLLATE
gbk_chinese_ci;
show character set;#找字符集和校对规则.
• 改库的字符集:
ALTER DATABASE [db_name] CHARACTER SET charset_name COLLATE collation_name
ALTER DATABASE oldgirl CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
• 删库 drop database oldboy;
• 切库 use oldboy;
• 查看当前所在的库 select database(); select user();
• 查看库里的表 show tables;
• DDL语句之管理用户(上面已说过)
• 用户:
‘user’@‘主机域’
• 帮助:
? Account Management
• 常用命令:
.查看当前用户
.创建用户
.查看用户对应的权限
.删除用户
.给用户授权
.收回权限
.工作博客授权
• DDL 语句之管理表 与 案例介绍
建表、查看变结构、查看建表语句、改表名
• 表的属性:
– 字段、数据类型、索引
– 默认:字符集、引擎
• 建立表
create table <表名> (<字段名1> <类型1> , …<字段名n> <类型n>);
• 获取帮助
help create table;
• 查看表结构:
desc student;
• 查看建表语句:
show create table student\G
• 更改表名
rename table student to test;
alter table test rename to student;
修改表结构
• 原表:
CREATE TABLE `test` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` char() NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
• 先添加性别列,长度为4,内容非空
alter table test add sex char() NOT NULL;
• 指定添加年龄列到name列后面的位置,示例如下:
alter table test add age int() after name;
• 通过下面的命令在第一列添加qq字段。
alter table test add qq varchar() first;
• 若要删除字段,可采用如下命令。
alter table test drop qq;
• 若要同时添加两个字段,可采用如下命令。
alter table test add age tinyint() first,add qq varchar();
• 修改字段类型的命令如下:
alter table test modify age char() after name;
Query OK, rows affected (0.00 sec)
Records: Duplicates: Warnings:
• 修改字段名称的命令如下:
alter table test change age oldboyage char() after name; 添加表字段
alter table table1 add transactor varchar(10) not Null;
alter table table1 add id int unsigned not Null auto_increment primary key 修改某个表的字段类型及指定为空或非空
alter table 表名称 change 字段名称 字段名称 字段类型 [是否允许非空]; alter table 表名称 modify 字段名称 字段类型 [是否允许非空]; alter table 表名称 modify 字段名称 字段类型 [是否允许非空]; 修改某个表的字段名称及指定为空或非空
alter table 表名称 change 字段原名称 字段新名称 字段类型 [是否允许非空] 删除某一字段
ALTER TABLE mytable DROP 字段 名; 添加唯一键
ALTER TABLE `test2` ADD UNIQUE ( `userid`) 修改主键 ALTER TABLE `test2` DROP PRIMARY KEY ,ADD PRIMARY KEY ( `id` ) 增加索引 ALTER TABLE `test2` ADD INDEX ( `id` ) ALTER TABLE `category ` MODIFY COLUMN `id` int(11) NOT NULL AUTO_INCREMENT FIRST ,ADD PRIMARY KEY (`id`); 第一步:给 id 增加auto_increment 属性
alter table test modify id int(11) auto_increment;
第二步:给自增值设置初始值
alter table test auto_increment=0;
思考:change和modify该如何选择? 修改主键的sql语句块如下:
mailbox 表新增字段 DROP PROCEDURE IF EXISTS mailbox_column_update;
CREATE PROCEDURE mailbox_column_update() BEGIN
-- 新增删除标志列
IF NOT EXISTS(SELECT 1 FROM information_schema.COLUMNS WHERE TABLE_SCHEMA='cbs' AND table_name='mailbox' AND COLUMN_NAME='delete_flag') THEN
ALTER TABLE mailbox ADD delete_flag int DEFAULT 2 NOT NULL;
END IF;
-- 新增删除日期列
IF NOT EXISTS(SELECT 1 FROM information_schema.COLUMNS WHERE TABLE_SCHEMA='cbs' AND table_name='mailbox' AND COLUMN_NAME='delete_date') THEN
ALTER TABLE mailbox ADD delete_date int DEFAULT 0 NOT NULL;
END IF;
-- 如果存在字段account_mail,则修改字段长度
IF EXISTS(SELECT 1 FROM information_schema.COLUMNS WHERE TABLE_SCHEMA='cbs' AND table_name='mailbox' AND COLUMN_NAME='email_account')
THEN
alter table mailbox modify column email_account varchar(320);
END IF;
-- 如果不存在主键列,则设置双主键
IF ((SELECT count(*) FROM information_schema.KEY_COLUMN_USAGE WHERE TABLE_SCHEMA ='cbs' AND table_name='mailbox' AND CONSTRAINT_NAME ='PRIMARY' AND (COLUMN_NAME ='email_account' OR COLUMN_NAME = 'company_id'))=0)THEN
ALTER TABLE mailbox ADD primary key (company_id,email_account);
-- 如果只存在一个主键列
ELSEIF ((SELECT count(*) FROM information_schema.KEY_COLUMN_USAGE WHERE TABLE_SCHEMA ='cbs' AND table_name='mailbox' AND CONSTRAINT_NAME ='PRIMARY' AND (COLUMN_NAME ='email_account' OR COLUMN_NAME = 'company_id'))<2)THEN
ALTER TABLE mailbox DROP PRIMARY KEY,ADD primary key (company_id,email_account);
END IF;
• DML 语句之管理表中的数据
• 备份数据备用
mysqldump以SQL语句形式将数据导出来。
mysqldump -B --compact oldboy >/opt/bak.sql
• insert 插入数据
use lufei;
create table t1 (id int ,name varchar(20));
# 要根据 表结构 插入
insert into t1 values(1,'zhang3');
select * from t1;
insert into t1 values (2,'li4'),(3,'wang5'),(4,'ma6');
# 向指定列 插入
insert into t1(name) values ('xyz');
• 修改数据
update t1 set name='zhang33' ; --会更新表中所有行的name字段,比较危险。
update t1 set name='zhang55' where id=1;
--update在使用时一般都会有where条件去限制。
update test set id= where name='kaka';
练习:把ID为2的名字改为bingbing.
• 防止不加条件误删:
mysql -U
update test set name='lanlan';
ERROR (HY000): You are using safe update mode
and you tried to update a table without a WHERE that uses a KEY column
至于防止误操作导致上述数据库故障案例的方法之一,
请参见http://oldboy.blog.51cto.com/2561410/1321061
• 删除(delete)
delete from test; #逻辑删除,一行一行删。 删除所有
delete from t1 where id=2; 删除指定数据
truncate table test; #物理删除,pages(block),效率高。 DDL操作
• 案例:不删除,而是伪删除。添加字段state,改变字段的值实现伪删除
alter table test add state tinyint() not null default ;
update test set state=;
正常显示:
select * from test where id=;
update test set state= where name='oldboy';
• DQL
开发环境准备
- 导入world.sql
- 应用脚本
登陆mysql
mysql> source /server/tools/world.sql
show databases;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| world |
+--------------------+
4 rows in set (0.00 sec)
- 创建用户(能远程链接的用户),使用sqlyog(有联想功能)登陆数据库
- create user root@'10.0.0.%' identified '123';
- grant all on *.* to 'root'@'10.0.0.%'
select 的基本格式
• 查询表中的数据
命令语法:select <字段1,字段2,...> from < 表名 > where < 表达式 > and < 表达式 >。
其中,select、from、where是不能随便改的,是关键字,支持大小写。
select <字段1,字段2,...> from < 表名 > where < 表达式 >
select user,host,password from mysql.user;
select * from oldboy.test;
select id,name from oldboy.test;
select id,name from test where id=;
select id,name from test where name='oldgirl';
select id,name from test where id>;
select id,name from test where id> and id<;
select id,name from test where id> or id<;
select id,name from test;
select id,name from test order by id asc;
select id,name from test order by id desc;
select id,name from test limit ,; help select;
查询select语法详解
• 基本语法
SELECT *|{[DISTINCT] column|select_expr [alias], ...]}
[FROM [database.]table]
[WHERE conditions];
• WHERE条件又叫做过滤条件,它从FROM子句的中间结果中去掉所有
条件conditions不为TRUE(而为FALSE或者NULL)的行
• WHERE子句跟在FROM子句后面
• 不能在WHERE子句中使用列别名
• 例1:where字句的基本使用
SELECT * FROM world.`city` WHERE CountryCode='CHN';
or
SELECT * FROM world.`city` WHERE CountryCode='chn';
注意: WHERE中出现的字符串和日期字面量必须使用引号括起来
这里,字符串字面量写成大写或小写结果都一样,即不区分大小写进行查询。
这和ORACLE不同,ORACLE中WHERE条件中的字面量是区分大小写的
• 例2:where字句中的逻辑操作符:
SELECT * FROM world.`city` WHERE CountryCode='chn' AND district = 'anhui';
• 逻辑操作符介绍:
– and 逻辑与。只有当所有的子条件都为true时,and才返回true。否则返回false或null
– or 逻辑或。只要有一个子条件为true,or就返回true。否则返回false或null
– not 逻辑非。如果子条件为true,则返回false;如果子条件为false,则返回true
– xor 逻辑异或。当一个子条件为true而另一个子条件为false时,其结果为true;
当两个条件都为true或都为false时,结果为false。否则,结果为null
• 例3 :where字句中的范围比较:
SELECT * FROM world.`city` WHERE population BETWEEN AND ;
• 例4:where字句中的IN
SELECT * FROM city WHERE countrycode IN ('CHN','JPN');
• 例5:where字句中的like
– 语法:
like ‘匹配模式字符串’
– 实现模式匹配查询或者模糊查询:
测试一个列值是否匹配给出的模式
– 在‘匹配模式字符串’中,可以有两个具有特殊含义的通配字符:
%:表示0个或者任意多个字符
_:只表示一个任意字符
SELECT * FROM city WHERE countrycode LIKE 'ch%';
• ORDER BY子句用来排序行
• 如果SELECT语句中没有ORDER BY子句,
那么结果集中行的顺序是 不可预料的
• 语法: SELECT expr
FROM table
[WHERE condition(s)]
[ORDER BY {column, expr, numeric_position} [Asc|DEsc]];
• 其中:
– Asc:执行升序排序。默认值
– DEsc:执行降序排序
– ORDER BY子句一般在SELECT语句的最后面
• 例1: 基本使用
SELECT * FROM city ORDER BY population;
• 例2:多个排序条件
SELECT * FROM city ORDER BY population,countrycode;
• 例3:以select字句列编号排序
SELECT * FROM city ORDER BY ;
• 例4:desc asc
SELECT * FROM city ORDER BY desc;
• 例5:NULL值的排序 在MySQL中,把NULL值当做一列值中的最小值对待。
因此,升序排序时,它出现在最前面
LIMIT
• MySQL特有的子句。
• 它是SELECT语句中的最后一个子句(在order by后面)。
• 它用来表示从结果集中选取最前面或最后面的几行。
• 偏移量offset的最小值为0。
• 语法: limit <获取的行数> [OFFSET <跳过的行数>]
或者 limit [<跳过的行数>,] <获取的行数>
SELECT * FROM city ORDER BY DEsc LIMIT ;
注:先按照人口数量进行降序排序,然后使用 limit 从中挑出最前面的 行。
如果没有 order by 子句,返回的 行就是不可预料的。
• 传统的连接写法(使用where)
SELECT NAME,ci.countrycode ,cl.language ,ci.population
FROM city ci , countrylanguage cl WHERE ci.`CountryCode`=cl.countrycode;
注意:一旦给表定义了别名,那么原始的表名就不能在出现在该语句 的其它子句中了
• NATURAL JOIN子句
• 自动到两张表中查找所有同名同类型的列拿来做连接列,进行相等
连接 SELECT NAME,countrycode ,LANGUAGE ,population
FROM city NATURAL JOIN countrylanguage WHERE population >
ORDER BY population;
注意:在 select 子句只能出现一个连接列
• 使用using子句
SELECT NAME,countrycode ,LANGUAGE ,population
FROM city JOIN countrylanguage USING(countrycode);
• UNION [DISTINCT]
• UNION ALL
• 语法:
SELECT ...
UNION [ALL | DISTINCT]
SELECT ...
[UNION [ALL | DISTINCT]
SELECT ...]
• UNION用于把两个或者多个select查询的结果集合并成一个
• 进行合并的两个查询,其SELECT列表必须在数量和对应列的数据类型上保持一致
• 默认会去掉两个查询结果集中的重复行
• 默认结果集不排序
• 最终结果集的列名来自于第一个查询的SELECT列表
• “Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,
所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个 “小区域”进行数据处理。
• Having与Where的区别
– where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,
即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
– having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,
条件中经常包含聚 组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
• 子查询定义
– 在一个表表达中可以调用另一个表表达式,这个被调用的表表达式叫做子查询( subquery),
我么也称作子选择(subselect)或内嵌选择(inner select)。
子查询 的结果传递给调用它的表表达式继续处理。
– 子查询(inner query)先执行,然后执行主查询(outer query)
– 子查询按对返回结果集的调用方法,可分为:where型子查询,from型子查询及exists 型子查询。
• 使用子查询原则
– 一个子查询必须放在圆括号中。
– 将子查询放在比较条件的右边以增加可读性。
子查询不包含 ORDER BY 子句。对一个 SELECT 语句只能用一个 ORDER BY 子句,并且
如果指定了它就必须放在主 SELECT 语句的最后。
– 在子查询中可以使用两种比较条件:
单行运算符(>, =, >=, <, <>, <=) 和多行运算符 (IN, ANY, ALL)。
查询select案例详解
查询之前,先看一下表的结构
DESC world.city
SELECT id ,NAME FROM world.city;
SELECT * FROM world.`city`;
-- select 条件查询 where
注意: WHERE中出现的字符串和日期字面量必须使用引号括起来
这里,字符串字面量写成大写或小写结果都一样,即不区分大小写进行查询。
这和ORACLE不同,ORACLE中WHERE条件中的字面量是区分大小写的
---- 、查询中国(CHN)所有的城市信息
SELECT * FROM world.`city` WHERE countrycode='CHN';
---- 、查询中国(CHN)安徽省所有的城市信息。 AND
SELECT * FROM world.`city`
WHERE countrycode='CHN'
AND
district='anhui'; ---- 、查询世界上人口数量在10w-20w城市信息 BETWEEN AND
SELECT * FROM world.`city`
WHERE
population BETWEEN AND ; ---- 、中国或者日本的所有城市信息 IN
where字句中的IN
SELECT * FROM world.city
WHERE countrycode IN ('CHN','JPN'); ---- 、模糊查询 LIKE
SELECT * FROM world.city
WHERE countrycode LIKE 'ch%'; -- select 排序并限制 ORDER BY
---- 按照人口数量排序输出中国的城市信息(ASC\DESC)
ASC 升序 DESC 降序
order by 字句一般在select语句的后面
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population ASC;
SELECT * FROM world.`city` WHERE countrycode='CHN' ORDER BY population DESC; ---- 按照多列排序人口+省排序
SELECT * FROM world.`city` WHERE countrycode='CHN'
ORDER BY Population,District DESC; 多个条件用,分割,
---出现的效果是,按照最后一个排序,但有时候也不是按照最后一个,会出现意想不到的效果
---一般排序时,最好还是使用单列
SELECT * FROM world.`city` WHERE countrycode='CHN'
ORDER BY id DESC ;
---安装列所在位置,排序
SELECT * FROM city
ORDER BY DESC ; ---就是按照第5列population
--- NULL值的排序,在MySQL中,把NULL值当做一列的最小值
-10 LIMIT
SELECT * FROM world.`city` WHERE countrycode='CHN'
ORDER BY DESC LIMIT ; -
SELECT * FROM world.`city` WHERE countrycode='CHN'
ORDER BY DESC LIMIT , ;
--相当于
SELECT * FROM world.`city` WHERE countrycode='CHN'
ORDER BY DESC LIMIT OFFSET ;
-- 表连接查询 DESC city
DESC countrylanguage 传统的连接写法(使用where)
---- 中国所有城市信息+使用语言(city+countrylanguage)
--1、从city中显示城市名
SELECT NAME ,countrycode ,population FROM city WHERE countrycode ='CHN'
--2、从countrycode中显示语言
SELECT countrycode ,LANGUAGE FROM countrylanguage;
--3、连表
SELECT ci.NAME ,ci.countrycode ,ci.population,cl.language
FROM
city AS ci , countrylanguage AS cl
WHERE ci.countrycode ='CHN'
AND
ci.CountryCode=cl.CountryCode;
-- name 可以直接使用,
SELECT NAME,ci.countrycode ,cl.language ,ci.population
FROM city ci , countrylanguage cl
WHERE
ci.countrycode='chn' AND
ci.`CountryCode`=cl.countrycode;
-- 使用NATURAL JOIN
SELECT NAME,countrycode ,LANGUAGE ,population
FROM city NATURAL JOIN countrylanguage
WHERE population >
ORDER BY population;
-- 使用JOIN USING
SELECT NAME,countrycode ,LANGUAGE ,population
FROM city JOIN countrylanguage
USING(countrycode);
NATURAL JOIN 和 JOIN USING 都不常用
---- 查询青岛这个城市,所在的国家具体叫什么名字 使用 JOIN ON
DESC city
DESC country
--1、查看青岛
SELECT NAME,countrycode FROM city WHERE NAME='qingdao';
--2、查看中国城市名
SELECT NAME FROM country WHERE CODE='CHN';
--3、连表
--------------------------------
SELECT ci.name ,ci.countrycode,ci.population ,co.name
FROM city AS ci
JOIN
country AS co
ON ci.countrycode=co.code
AND
ci.name='qingdao';
---------------------------------
group by +聚合函数(avg()、max()、min()、sum()) SELECT countrycode ,SUM(population) FROM city
WHERE countrycode = 'chn'
GROUP BY countrycode; union 用来替换 or 、in() 性能更好些 SELECT * FROM world.city
WHERE countrycode IN ('CHN','JPN');
改写为:
SELECT * FROM world.city
WHERE countrycode ='CHN'
union
SELECT * FROM world.city
WHERE countrycode ='JPN'; 两个SQL需要是相同的结
5、SQL字符集
尤其是在进行数据库迁移的时候,一定要注意字符集
• 字符集(Charset):
是一个系统支持的所有抽象字符的集合。
字符是各种文字和符号的总称, 包括各国家文字、标点符号、图形符号、数字等。

• MySQL数据库的字符集:
– 字符集(CHARACTER)
– 校对规则(COLLATION)
• MySQL中常见的字符集:
– UTF8 ,utf8mb4
– LATIN1 编译默认的,开发者的母语
– GBK
• 常见校对规则: 即排序规则
– ci:大小写不敏感 aA-zZ
– cs或bin:大小写敏感 a-z A-Z
• 我们可以使用以下命令查看:
– show charset;
– show collation;
字符集的级别
• 操作系统级别
控制的是系统相关的显示,和一些依赖于操作系统的应用
source /etc/sysconfig/i18n
[root@db02 logs]# echo $LANG
zh_CN.UTF-8
• 操作系统客户端级别(SSH)
控制的是用户的输入和展示
• 服务端字符集
控制的是,存到mysql中时,字符集控制
• MySQL实例级别
– 方法1:在编译安装时候就指定如下服务器端字符集。
cmake .
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci \
-DWITH_EXTRA_CHARSETS=all \
– 方法2:
[mysqld] character-set-server=utf8 • 数据库中的库级别
CREATE DATABASE `oldboy` /*!40100 DEFAULT CHARACTER SET utf8 */
create database oldboy DEFAULT CHARACTER SET UTF8 DEFAULT COLLATE
= utf8_general_ci;
• 获取帮助并查询
help create database;
show character set;
• 表级别(含字段级别)
CREATE TABLE `test` (
`id` int(4) NOT NULL AUTO_INCREMENT,
`name` char(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8
• MySQL客户端级别(连接及返回结果)
方法1:临时生效单条命令法。
mysql> set names utf8;
Query OK, 0 rows affected (0.00 sec)
方法2:通过修改my.cnf实现修改mysql客户端的字符集,配置方法如下。
[client]
default-character-set=utf8
• 程序代码级别
• 生产环境更改数据库(含数据)字符集的方法
alter database oldboy CHARACTER SET utf8 collate
utf8_general_ci;
alter table t1 CHARACTER SET latin1;
注意:更改字符集时,一定要保证由小往大改,后者必须是前者的严格超集。
6、数据类型介绍
• 数据类型介绍
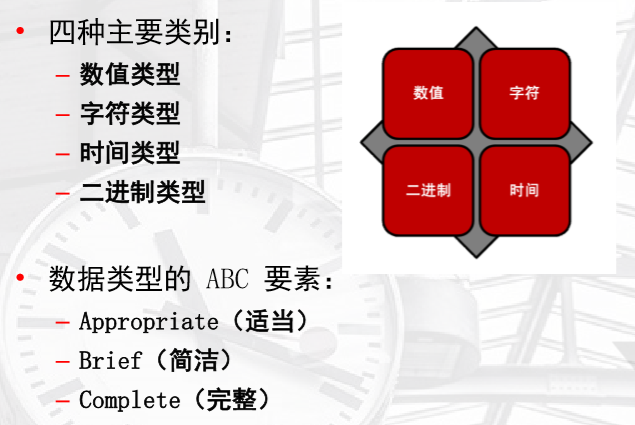
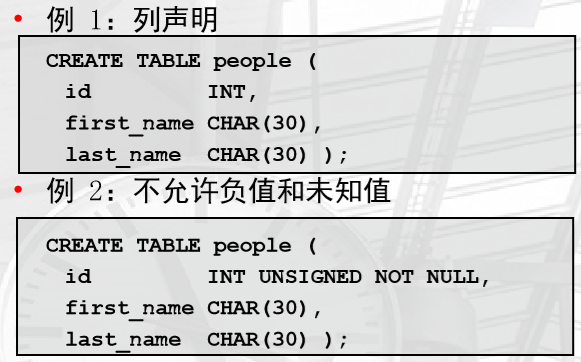
• 数据类型设置
创建带有数据类型的表
数值数据类型
注意事项:
- 数据类型所表示的值的范围
- 列值所需的空间量
- 列精度和范围(浮点数和定点数)
种类:
- 整数:整数
- 浮点数:小数
- 定点数:精确值数值
- BIT:位字段值

字符串数据类型
- 表示给定字符集中的一个字母数字字符序列
- 用于存储文本或二进制数据
- 几乎在每种编程语言中都有实现
- 支持字符集和整理
- 属于以下其中一类
- 文本:真实的非结构化字符串数据类型
- 整数:结构化字符串类型
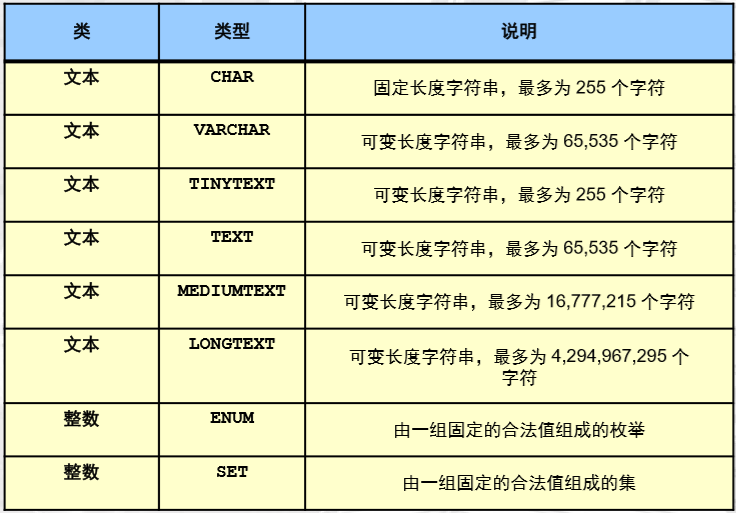
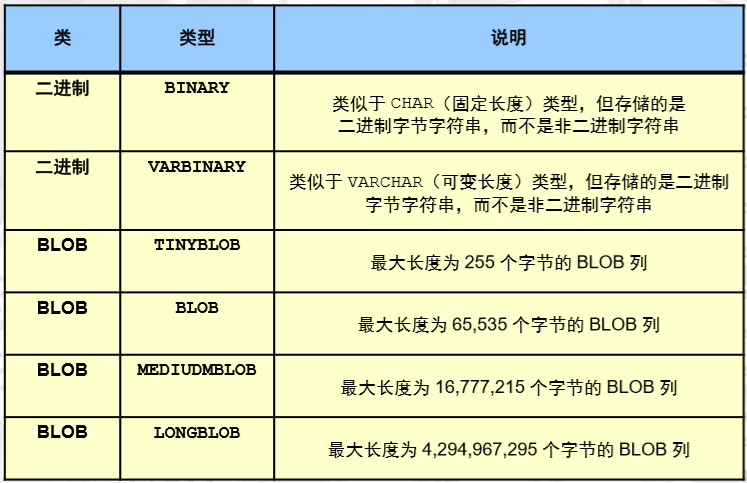
二进制字符串数据类型
- 字节序列
- 二进制位按八位分组
- 存储二进制值,例如:
- 编译的计算机程序和应用程序
- 图像和声音文件
- 字符二进制数据类型的类:
- 二进制:固定长度和可变长度的二进制字符串
- – BLOB:二进制数据的可变长度非结构化集合
时间数据类型

常用的是datetime和timestamp
• 列属性
列属性的类别:
- 数值:适用于数值数据类型(BIT 除外)
- 字符串:适用于非二进制字符串数据类型
- 常规:适用于所有数据类型

primary key:主键:非空、唯一
unique:唯一
• 数据类型的字符集用法
• 选择适当的数据类型
• 考虑哪些数据类型和字符集可以最大限度地减少存储和磁盘 I/O。
• 使用固定长度数据类型:
– 如果存储的所有字符串值的长度相同
• 使用可变长度数据类型:
– 如果存储的字符串值不同
– 对于多字节字符集
• 对于频繁使用的字符,使用占用空间较少的多字节字符集。
– 使用基本多文种平面 (Basic Multilingual Plane, BMP) 之外的其他 Unicode 字符集
7、元数据获取-INFORMATION_SCHEMA数据库介绍
INFORMATION_SCHEMA,通过这个库提供的一些视图,我们可以非常轻松的去获取
对于数据库的,统计信息。我们也把这些叫做元数据
对于数据库,两个信息
- 数据行:我们使用DDL、DCL、DQL操作的数据
- 元数据:定义数据的数据
- 库的名字、属性
- 表名、属性
- 库状态,表状态...
• 元数据访问方式介绍
• 查询 INFORMATION_SCHEMA 数据库表。
– 其中包含 MySQL 数据库服务器所管理的所有对象的相关数据
• 使用 SHOW 语句。
– 用于获取数据库和表信息的 MySQL 专用语句
• 使用 DESCRIBE(或 DESC)语句。
– 用于检查表结构和列属性的快捷方式
• 使用 mysqlshow 客户端程序。
– SHOW 语法的命令行程序
• INFORMATION_SCHEMA 数据库的结构
• 充当数据库元数据的中央系统信息库
– 模式和模式对象
– 服务器统计信息(状态变量、设置、连接)
• 采用表格式以实现灵活访问
– 使用任意 SELECT 语句
• 是“虚拟数据库”
– 表并非“真实”表(基表),而是“系统视图”
– 根据当前用户的特权动态填充表
INFORMATION_SCHEMA 表
列出 INFORMATION_SCHEMA 数据库中所有的表:
mysql> use information_schema
mysql> show tables;
| CHARACTER_SETS |
| COLLATIONS |
| COLLATION_CHARACTER_SET_APPLICABILITY |
| COLUMNS |
| COLUMN_PRIVILEGES |
...
| USER_PRIVILEGES |
| VIEWS
查看数据库一共有多少张表
查看元数据中的表的元数据
mysql> desc tables;
+-----------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+---------------------+------+-----+---------+-------+
| TABLE_CATALOG | varchar() | NO | | | |
| TABLE_SCHEMA | varchar() | NO | | | |
| TABLE_NAME | varchar() | NO | | | |
| TABLE_TYPE | varchar() | NO | | | |
| ENGINE | varchar() | YES | | NULL | |
| VERSION | bigint() unsigned | YES | | NULL | |
| ROW_FORMAT | varchar() | YES | | NULL | |
| TABLE_ROWS | bigint() unsigned | YES | | NULL | |
| AVG_ROW_LENGTH | bigint() unsigned | YES | | NULL | |
| DATA_LENGTH | bigint() unsigned | YES | | NULL | |
| MAX_DATA_LENGTH | bigint() unsigned | YES | | NULL | |
| INDEX_LENGTH | bigint() unsigned | YES | | NULL | |
| DATA_FREE | bigint() unsigned | YES | | NULL | |
| AUTO_INCREMENT | bigint() unsigned | YES | | NULL | |
| CREATE_TIME | datetime | YES | | NULL | |
| UPDATE_TIME | datetime | YES | | NULL | |
| CHECK_TIME | datetime | YES | | NULL | |
| TABLE_COLLATION | varchar() | YES | | NULL | |
| CHECKSUM | bigint() unsigned | YES | | NULL | |
| CREATE_OPTIONS | varchar() | YES | | NULL | |
| TABLE_COMMENT | varchar() | NO | | | |
+-----------------+---------------------+------+-----+---------+-------+
rows in set (0.00 sec)
查看数据库一共有多少张表
mysql> select count(TABLE_NAME) from tables;
+-------------------+
| count(TABLE_NAME) |
+-------------------+
| |
+-------------------+
row in set (0.01 sec)
• 使用可用命令查看元数据
对 INFORMATION_SCHEMA 使用 SELECT
• 指定要检索哪个表和哪些列。
• 通过使用 WHERE 子句,可仅检索特定条件。
• 对结果分组或排序。
• 使用 JOIN、UNION 和子查询。
• 将结果检索到其他表中。
• 基于 INFORMATION_SCHEMA 表创建视图
例子:
查看world库下的所有表的表名,引擎
mysql> SELECT TABLE_NAME, ENGINE
-> FROM INFORMATION_SCHEMA.TABLES
-> WHERE TABLE_SCHEMA = 'world';
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME
-> FROM INFORMATION_SCHEMA.COLUMNS
-> WHERE DATA_TYPE = 'set';
mysql> SELECT CHARACTER_SET_NAME, COLLATION_NAME
-> FROM INFORMATION_SCHEMA.COLLATIONS
-> WHERE IS_DEFAULT = 'Yes';
每个库下面的表数量的统计
mysql> SELECT TABLE_SCHEMA, COUNT(*)
-> FROM INFORMATION_SCHEMA.TABLES
-> GROUP BY TABLE_SCHEMA;
只能查询
mysql> DELETE FROM INFORMATION_SCHEMA.VIEWS;
ERROR (): Access denied for user
'root'@'localhost' to database 'information_schema'
• SHOW 语句和 INFORMATION_SCHEMA 表之间的区别
show是基于information_schema表提前做好的视图函数
show语句
• SOHW databases:列出所有数据库
• SHOW TABLES:列出默认数据库中的表
• SHOW TABLES FROM <database_name>:列出指定数据库中的表
• SHOW COLUMNS FROM <table_name>:显示表的列结构
• SHOW INDEX FROM <table_name>:显示表中有关索引和索引列的信息
• SHOW CHARACTER SET:显示可用的字符集及其默认整理
• SHOW COLLATION:显示每个字符集的整理
• SHOW STATUS:列出当前数据库状态
• SHOW VARIABLES:列出数据库中的参数定义值
上面的命令重点掌握
配合模糊查询得到我们需要的信息
mysql> show status like '%lock%';
+------------------------------------------+-------+
| Variable_name | Value |
+------------------------------------------+-------+
| Com_lock_tables | |
| Com_unlock_tables | |
| Handler_external_lock | |
| Innodb_row_lock_current_waits | |
| Innodb_row_lock_time | |
| Innodb_row_lock_time_avg | |
| Innodb_row_lock_time_max | |
| Innodb_row_lock_waits | |
| Key_blocks_not_flushed | |
| Key_blocks_unused | |
| Key_blocks_used | |
| Performance_schema_locker_lost | |
| Performance_schema_rwlock_classes_lost | |
| Performance_schema_rwlock_instances_lost | |
| Qcache_free_blocks | |
| Qcache_total_blocks | |
| Table_locks_immediate | |
| Table_locks_waited | |
+------------------------------------------+-------+
rows in set (0.00 sec)
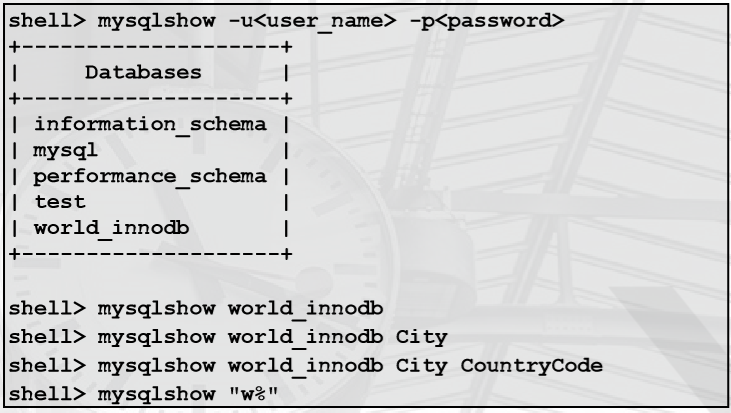
• mysqlshow 客户端工具使用
显示有关数据库和表的结构的信息
– 与 SHOW 语句相似
一般语法:
shell> mysqlshow [options] [db_name [table_name [column_name]]]
选项可以是标准连接参数。
显示所有数据库或特定数据库、表和/或列的相关信息:
• 使用 INFORMATION_SCHEMA 表创建 shell 命令和 SQL 语句
使用 INFORMATION_SCHEMA 表创建 SQL 语句

使用 INFORMATION_SCHEMA 表创建 Shell 命令
备份的普通写法:mysqldump -uroot -ppizza123 world country >> /backup/world.bak.sql
如果有100条,要写100次
可以在NFORMATION_SCHEMA中查到world下的所有表
select table_schema,country from tables where table schema='world';
请按照下面的例子,按照需求拼接上面的命令并输出到文件

注意:空格也是要标识出来的
8、索引管理及执行计划
索引类型介绍
- BTREE:B+树索引 ------>重点和常用
- HASH:HASH索引
- FULLTEXT:全文索引
- RTREE:R树索引
索引管理
- 索引建立在表的列上(字段)的。
- 在where后面的列建立索引才会加快查询速度。
- pages<---索引(属性)<----查数据。
- 索引分类:
- 主键索引 开发前就决定了
- 普通索引*****
- 唯一索引 开发前就决定了
- 添加索引:
- alter table test add index index_name(name);
- create index index_name on test(name);
查询索引信息
mysql> desc test;
+-------+------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | char(20) | NO | MUL | NULL | |
| state | tinyint(2) | NO | | 1 | |
+-------+------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
删除索引
mysql> alter table test drop index index_name;
Query OK, rows affected (0.20 sec)
Records: Duplicates: Warnings: mysql> desc test;
+-------+------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+----------------+
| id | int() | NO | PRI | NULL | auto_increment |
| name | char() | NO | | NULL | |
| state | tinyint() | NO | | | |
+-------+------------+------+-----+---------+----------------+
rows in set (0.00 sec)
或者drop index index_name on test;
查询
desc test;
或
show index from test\G
MySQL中的约束索引
、主键索引:只能有一个主键。
主键索引:列的内容是唯一值,高中学号.
表创建的时候至少要有一个主键索引,最好和业务无关。
走主键索引的查询效率是最高的
、普通索引
加快查询速度,工作中优化数据库的关键。
在合适的列上建立索引,让数据查询更高效。
create index index_name on test(name);
alter table test add index index_name(name);
用了索引,查一堆内容。
在where条件关键字后面的列建立索引才会加快查询速度.
select id,name from test where state= order by id group by name;
、唯一索引
内容唯一,但不是主键。
create unique index index_name on test(name);
创建主键索引
.建立表时
CREATE TABLE `test` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` char() NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8; .建立表后增加
CREATE TABLE `test` (
`id` int() NOT NULL,
`name` char() NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
增加自增主键
alter table test change id id int() primary key not null auto_increment;
使用字段前缀创建索引及联合索引
.前缀索引:根据字段的前N个字符建立索引
create index index_name on test(name());
.联合索引:多个字段建立一个索引。
where a女生 and b身高165 and c身材好
index(a,b,c)
特点:前缀生效特性。
a,ab,abc 可以走索引。
b ac bc c 不走索引。
原则:把最常用来作为条件查询的列放在前面。 实例:
alter table test add sex char(4) not null;
create index ind_name_sex on test(name,sex);
explain select id,name from test where name='oldboy'\G
explain select id,name from test where sex='nv'\G
explain select id,name from test where name='oldgirl' and sex='nv'\G 联合主键是联合索引的特殊形式:
PRIMARY KEY (`Host`,`User`)
alter table test add sex char(4) not null;
create index ind_name_sex on test(name,sex);
前缀加联合索引
create index index_name on test(name(8),sex(2));
用expain查看SQL的执行计划
没有索引
mysql> explain select id,name from test where name='pizza'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ALL 表示MySQL在表中找到所需行的方式,又称“访问类型”
possible_keys: NULL
key: NULL
key_len: NULL 越小越好
ref: NULL
rows: 1
Extra: Using where
1 row in set (0.08 sec)
常见的type
ALL、index、range、ref、eq_ref、const、system、null
从左到右,性能从最差到最好
mysql> alter table test add index index_name(name);
Query OK, 0 rows affected (0.14 sec)
Records: 0 Duplicates: 0 Warnings: 0
有索引
mysql> explain select id,name from test where name='pizza'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
type: ref
possible_keys: index_name
key: index_name
key_len: 60
ref: const
rows: 1
Extra: Using where; Using index
1 row in set (0.00 sec)
explain select SQL_NO_CACHE * from test where name='oldboy'\G
SQL_NO_CACHE的作用是禁止缓存查询结果。
explain中各type类型的详解
ALL:
Full Table Scan, MySQL将遍历全表以找到匹配的行 如果显示ALL,说明:
查询没有走索引:
1、语句本身的问题
2、索引的问题,没建立索引 index:
Full Index Scan,index与ALL区别为index类型只遍历索引树
例子:
explain select count(*) from stu ; range:
索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。
显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。
where 条件中有范围查询或模糊查询时
> < >= <= between and in () or
like 'xx%'
当mysql使用索引去查找一系列值时,例如IN()和OR列表,也会显示range(范围扫描)
当然性能上面是有差异的。 ref:
使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行
where stu_name='xiaoming'
explain select * from stu where stu_name='aa'; eq_ref:
类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,
就是多表连接中使用primary key或者 unique key作为关联条件
join条件使用的是primary key或者 unique key const、system:
当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
如将主键置于where列表中,MySQL就能将该查询转换为一个常量
explain select * from city where id=1; NULL:
MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,
例如从一个索引列里选取最小值可以通过单独索引查找完成。
或者走的缓存中已经存在的
explain中的Extra
避免出现
Using temporary
Using filesort
Using join buffer
出现的原因是:
排序 order by ,group by ,distinct,排序条件上没有索引
explain select * from city where countrycode='CHN' order by population;
解决办法:
在join 的条件列上没有建立索引
将前一个结果保存为视图,再排序
数据库索引的设计原则
为了使索引的使用效率更高,在创建索引时
必须考虑在哪些字段上创建索引和创建什么类型的索引。
那么索引设计原则又是怎样的? .选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。 主键索引和唯一键索引,在查询中使用是效率最高的 .为经常需要排序、分组和联合操作的字段建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。
如果为其建立索引,可以有效地避免排序操作。 .为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,
为这样的字段建立索引,可以提高整个表的查询速度。
但是,是不是真的适合去做索引,还要去统计一下这个列,去重之后的数量
和总行数对比,占的数量太小,比如性别,就不合适作为索引列
select count(DISTINCT population ) from city;
select count(*) from city; .尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索
会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。 ------------------------以上的是重点关注的,以下是能保证则保证的--------------------
.限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。 .尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。例如,对一个CHAR()类型的字段进行全文
检索需要的时间肯定要比对CHAR()类型的字段需要的时间要多。 .删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。 ------------------------------二、开发规范----------------------------------------- 不走索引的情况:
重点关注:
) 没有查询条件,或者查询条件没有建立索引 select * from tab; 全表扫描。
select * from tab where =; 在业务数据库中,特别是数据量比较大的表。
是没有全表扫描这种需求。 、对用户查看是非常痛苦的。
、对服务器来讲毁灭性的。 ()select * from tab;
SQL改写成以下语句:
selec * from tab order by price limit 需要在price列上建立索引
()
select * from tab where name='zhangsan' name列没有索引 改:
、换成有索引的列作为查询条件
、将name列建立索引 ) 查询结果集是原表中的大部分数据,应该是30%以上。 查询的结果集,超过了总数行数30%,优化器觉得就没有必要走索引了。
假如:tab表 id,name id:-100w ,id列有索引
select * from tab where id>; 如果业务允许,可以使用limit控制。
怎么改写 ?
结合业务判断,有没有更好的方式。如果没有更好的改写方案
尽量不要在mysql存放这个数据了。放到redis里面。 ) 索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。 ) 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例子:
错误的例子:select * from test where id-=;
正确的例子:select * from test where id=; )隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
由于表的字段tu_mdn定义为varchar2(),但在查询时把该字段作为number类型以where条件传给数据库,
这样会导致索引失效. 错误的例子:select * from test where tu_mdn=;
正确的例子:select * from test where tu_mdn='';
------------------------
mysql> alter table tab add index inx_tel(telnum);
Query OK, rows affected (0.03 sec)
Records: Duplicates: Warnings:
mysql>
mysql> desc tab;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int() | YES | | NULL | |
| name | varchar() | YES | | NULL | |
| telnum | varchar() | YES | MUL | NULL | |
+--------+-------------+------+-----+---------+-------+
rows in set (0.01 sec) mysql> select * from tab where telnum='';
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| | a | |
+------+------+---------+
row in set (0.00 sec) mysql> select * from tab where telnum=;
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| | a | |
+------+------+---------+
row in set (0.00 sec) mysql> explain select * from tab where telnum='';
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| | SIMPLE | tab | ref | inx_tel | inx_tel | | const | | Using index condition |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
row in set (0.00 sec) mysql> explain select * from tab where telnum=;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
row in set (0.00 sec) mysql> explain select * from tab where telnum=;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
row in set (0.00 sec) mysql> explain select * from tab where telnum='';
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| | SIMPLE | tab | ref | inx_tel | inx_tel | | const | | Using index condition |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
row in set (0.00 sec) mysql> ------------------------ )
<> ,not in 不走索引 EXPLAIN SELECT * FROM teltab WHERE telnum <> '';
EXPLAIN SELECT * FROM teltab WHERE telnum NOT IN ('','');
------------
mysql> select * from tab where telnum <> '';
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| | a | |
+------+------+---------+
row in set (0.00 sec) mysql> explain select * from tab where telnum <> '';
-----
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit
or或in 尽量改成union EXPLAIN SELECT * FROM teltab WHERE telnum IN ('','');
改写成: EXPLAIN SELECT * FROM teltab WHERE telnum=''
UNION ALL
SELECT * FROM teltab WHERE telnum='' -----------------------------------
) like "%_" 百分号在最前面不走 EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%' 走range索引扫描
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110' 不走索引
%linux%类的搜索需求,可以使用elasticsearch
%linux培训% ) 单独引用复合索引里非第一位置的索引列.
列子:
复合索引: DROP TABLE t1
CREATE TABLE t1 (id INT,NAME VARCHAR(),age INT ,sex ENUM('m','f'),money INT); ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex);
DESC t1
SHOW INDEX FROM t1
走索引的情况测试:
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money= AND age= AND sex='m';
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money= AND age= ;
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money= AND sex='m'; ----->部分走索引
不走索引的:
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age= AND sex='m';
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex='m'; ------------------------------------------------
索引的企业应用场景
企业SQL优化思路:
、把一个大的不使用索引的SQL语句按照功能进行拆分
、长的SQL语句无法使用索引,能不能变成2条短的SQL语句让它分别使用上索引。
、对SQL语句功能的拆分和修改
、减少“烂”SQL
由运维(DBA)和开发交流(确认),共同确定如何改,最终由DBA执行
、制定开发流程 不适合走索引的场景:
、唯一值少的列上不适合建立索引或者建立索引效率低。例如:性别列
、小表可以不建立索引,100条记录。
、对于数据仓库,大量全表扫描的情况,建索引反而会慢 查看表的唯一值数量:
select count(distinct user) from mysql.user;
select count(distinct user,host) from mysql.user; 建索引流程:
、找到慢SQL。
show processlist;
记录慢查询日志。
、explain select句,条件列多。
、查看表的唯一值数量:
select count(distinct user) from mysql.user;
select count(distinct user,host) from mysql.user;
条件列多。可以考虑建立联合索引。
、建立索引(流量低谷)
force index
、拆开语句(和开发)。
、like '%%'不用mysql
9、MySQL的存储引擎
1、存储引擎的介绍
文件系统:
- 操作系统组织和存取数据的一种机制。
- 文件系统是一种软件。
类型:ext2 ,xfs 数据
- 不管使用什么文件系统,数据内容不会变化
- 不同的是,存储空间、大小、速度。
MySQL引擎:
- 可以理解为,MySQL的“文件系统”,只不过功能更加强大。
MySQL引擎功能:
- 除了可以提供基本的存取功能,还有更多功能事务功能、锁定、备份和恢复、优化以及特殊功能。
2、MySQL中的存储引擎分类
MySQL 提供以下存储引擎:
- InnoDB
- MyISAM
InnoDB 和 MyISAM最常用
- MEMORY
- ARCHIVE
- FEDERATED
- EXAMPLE
- BLACKHOLE
- MERGE
- NDBCLUSTER
- CSV
还可以使用第三方存储引擎(TokuDB)。用于zabbix和爬虫的存储,inno操作很有效,压缩性
Innodb功能总览
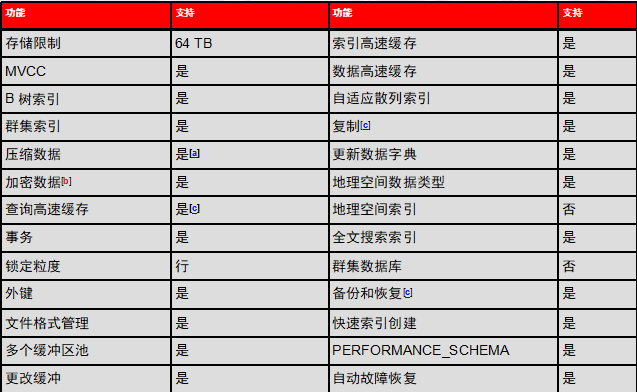
重点理解:事务、锁定粒度(行)、备份和恢复、自动故障恢复
3、MySQL存储引擎设置
查看
、使用 SELECT 确认会话存储引擎:
SELECT @@default_storage_engine;
查看所有的存储引擎
show engines;
、使用 SHOW 确认每个表的存储引擎:
SHOW CREATE TABLE City\G
SHOW TABLE STATUS LIKE 'CountryLanguage'\G
、使用 INFORMATION_SCHEMA 确认每个表的存储引擎:
SELECT TABLE_NAME, ENGINE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'world'
AND TABLE_SCHEMA = 'world';
+-----------------+--------+
| TABLE_NAME | ENGINE |
+-----------------+--------+
| city | InnoDB |
| country | InnoDB |
| countrylanguage | InnoDB |
| test | InnoDB |
+-----------------+--------+
4、mysql> show variables like '%engine%';
+----------------------------+--------+
| Variable_name | Value |
+----------------------------+--------+
| default_storage_engine | InnoDB |
| default_tmp_storage_engine | InnoDB |
| storage_engine | InnoDB |
+----------------------------+--------+
3 rows in set (0.00 sec) 下列查询语句都对应查询了什么?
show engines;
show create table city;
show table status like 'city'\G
select table_schema,table_name,engine from information_schema.tables where table_schema='world';
select table_schema,table_name,engine from information_schema.tables where table_schema='mysql';
select table_schema,table_name,engine from information_schema.tables where engine='csv';
设置
0、在编译的时候也可以设置
1、在启动配置文件中设置服务器存储引擎:
vim /etc/my.cnf
[mysqld]
default-storage-engine=<Storage Engine>
、使用 SET 命令为当前客户机会话设置:
SET @@storage_engine=<Storage Engine>;
、在 CREATE TABLE 语句指定:
CREATE TABLE t (i INT) ENGINE = <Storage Engine>;
4、MySQL Innodb引擎存储结构
表空间的概念由orcle引入
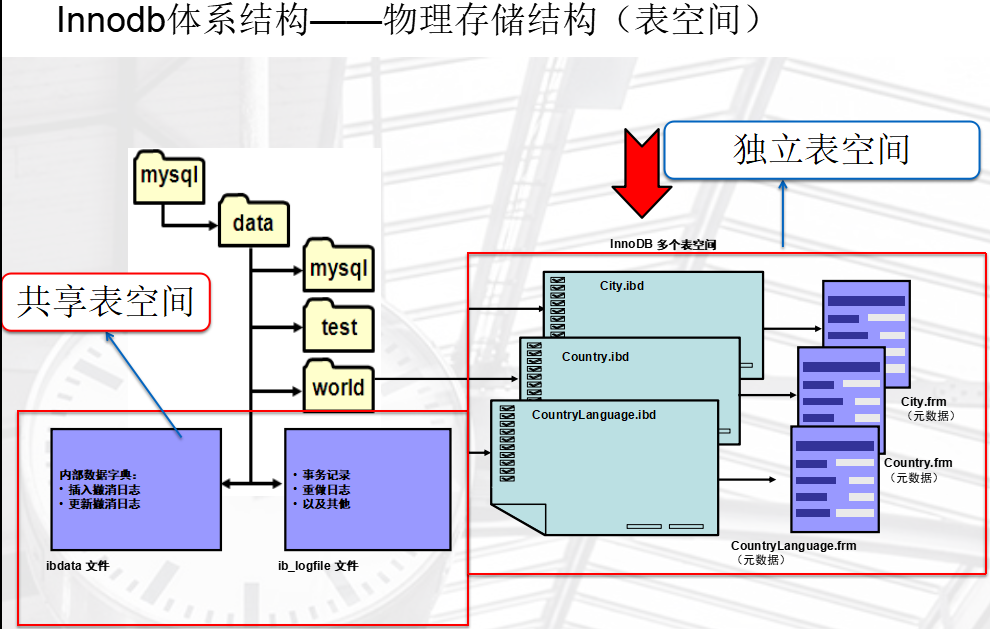
系统共享表空间
InnoDB 系统表空间
- 默认情况下,InnoDB 元数据、撤消日志和缓冲区存储在系统“表空间”中。
- 这是单个逻辑存储区域,可以包含一个或多个文件。
- 每个文件可以是常规文件或原始分区。
- 最后的文件可以自动扩展。
现在已经不用于生产数据的存储了,只用于存系统文件。
共享表空间设置
通过添加数据文件增加表空间大小。
在 my.cnf 文件中使用 innodb_data_file_path 选项。
[mysqld]
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
配置示例:创建一个表空间,
其中包含一个名为 ibdata1 且大小为 MB(固定)的数据文件和
一个名为 ibdata2 且大小为 MB(自动扩展)的数据文件:
[mysqld]
innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
默认情况下将文件放置在 data 目录中。
如果需要,显式指定文件位置。
innodb_data_file_path=ibdata1:12M;ibdata2:50M:autoextend ----错误的配置XXX
innodb_data_file_path=ibdata1:76M;ibdata2:50M:autoextend ----正确的配置,看实际而定
查看表空间设置
修改之前:
mysql> show variables like '%data%';
+-------------------------------+---------------------------------+
| Variable_name | Value |
+-------------------------------+---------------------------------+
| character_set_database | utf8 |
| collation_database | utf8_general_ci |
| datadir | /application/mysql-5.6.43/data/ |
| innodb_data_file_path | ibdata1:12M:autoextend |
修改之前先看一下,文件的大小,否则就是错误的修改,将导致数据库启动时报错,无法启动 [root@web01 data]# du -h ibdata1
12M ibdata1
这第一个的大小,不能大也不能小
innodb_data_file_path=ibdata1:12M;ibdata2:50M:autoextend
修改后,重启,再次查看
mysql> show variables like '%data%';
+-------------------------------+------------------------------------+
| Variable_name | Value |
+-------------------------------+------------------------------------+
| character_set_database | utf8 |
| collation_database | utf8_general_ci |
| datadir | /application/mysql-5.6.43/data/ |
| innodb_data_file_path | ibdata1:12M;ibdata2:50M:autoextend |
已经改变了! 最好在装完软件后就设置好
数据独立表空间
除了系统表空间之外,InnoDB 还在数据库目录中创建另外的表空间,用于每个 InnoDB 表的 .ibd 文件。
InnoDB 创建的每个新表在数据库目录中设置一个 .ibd 文件来搭配表的 .frm 文件。
当然,也会想系统空间存放元数据信息(存在哪个库,空间占用是多少,索引信息)
可以使用 innodb_file_per_table 选项控制此设置,
更改该设置仅会更改已创建的新表的默认值。 注:在mysql5.6开始,默认的配置为:
| innodb_file_per_table | ON | 在mysql内部有专门删除或者导入ibd的功能
alter table test discard tablespace;
5、MySQL中的事务
简介
一组数据操作执行步骤,这些步骤被视为一个工作单元
- 用于对多个语句进行分组
- 可以在多个客户机并发访问同一个表中的数据时使用
所有步骤都成功或都失败
- 如果所有步骤正常,则执行
- 如果步骤出现错误或不完整,则取消
事务的特性-ACID
Atomic(原子性)
所有语句作为一个单元全部成功执行或全部取消。
Consistent(一致性)
如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态。
Isolated(隔离性)
事务之间不相互影响。
Durable(持久性)
事务成功完成后,所做的所有更改都会准确地记录在数据库中。所做的更改不会丢失。
Innodb存储引擎--事务处理流程举例
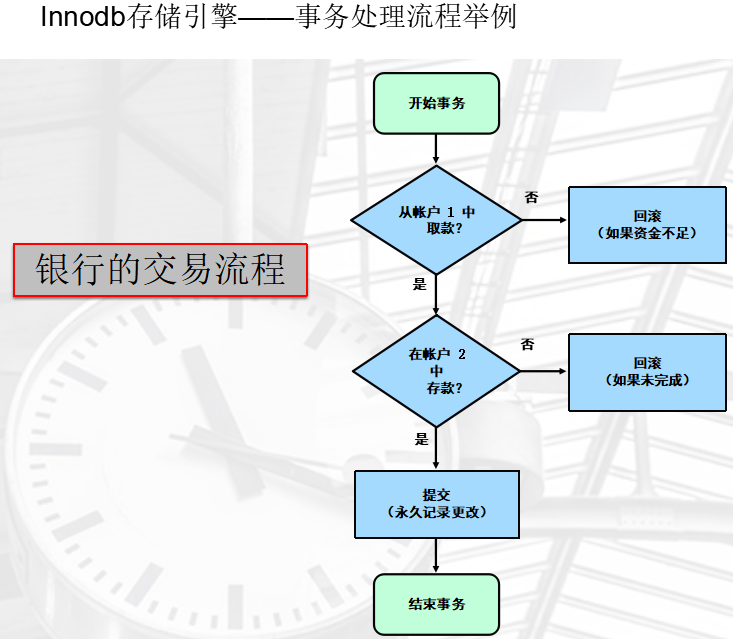
标准的事务语句,就只是DML语句,insert、update、delete
只要看到有DML标准语句,系统不需要begin就开始事务了,这是5.6后的新特性
START TRANSACTION(或 BEGIN):显式开始一个新事务
SAVEPOINT:分配事务过程中的一个位置,以供将来引用
COMMIT:永久记录当前事务所做的更改,说明事务要提交,要完成了
ROLLBACK:取消当前事务所做的更改
ROLLBACK TO SAVEPOINT:取消在 savepoint 之后执行的更改
RELEASE SAVEPOINT:删除 savepoint 标识符
SET AUTOCOMMIT:为当前连接禁用或启用默认 autocommit 模式 查看autocommit的状态
mysql> show variables like '%autocommit%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
在事务性的应用场景下,要改成OFF,避免写一句就提交,写一句就提交
查看全局的
show global variables like '%autocommit%';
Autocommit 模式设置
在MySQL5.5开始,开启事务时不再需要begin或者start transaction语句。
并且,默认是开启了Autocommit模式,作为一个事务隐式提交每个语句。
在有些业务繁忙企业场景下,这种配置可能会对性能产生很大影响,但对于安全性上有很大提高。
将来,我们需要去权衡我们的业务需求去调整是否自动提交。
我们可以通过以下命令进行修改关闭(0是关闭,1是开启):
SET GLOBAL AUTOCOMMIT=; - 所有新建会话
SET SESSION AUTOCOMMIT=; - 当前会话
SELECT @@AUTOCOMMIT; - 查看设置结果
我们也可以修改配置文件让其永久生效:
vim /etc/my.cnf
[mysqld]
AUTOCOMMIT=
其他触发隐式commit的情况
用于隐式提交的 SQL 语句:
START TRANSACTION,也就是之前有一个Begin或者START TRANSACTION
SET AUTOCOMMIT =
导致提交的非事务语句:
DDL语句: (ALTER、CREATE 和 DROP)
DCL语句: (GRANT、REVOKE 和 SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
导致隐式提交的语句示例:
TRUNCATE TABLE
LOAD DATA INFILE
SELECT FOR UPDATE
事务日志redo
Redo是什么?
redo,顾名思义“重做日志”,是事务日志的一种。
作用是什么?
在事务ACID过程中,实现的是“D”持久化的作用。
记录数据页的变化
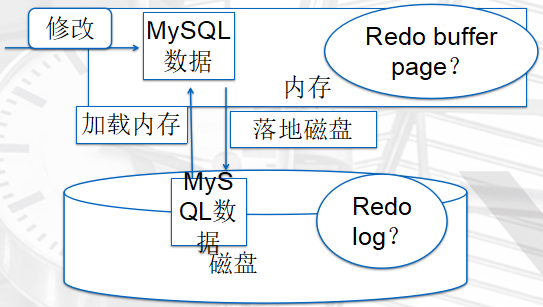
每次都提交,过多的IO操作会影响性能,所以有了Redo
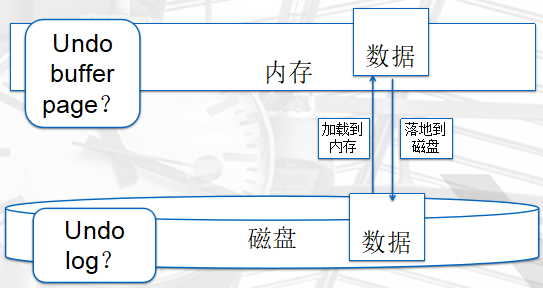
事务日志undo
undo是什么?
undo,顾名思义“回滚日志”,是事务日志的一种。
作用是什么?
在事务ACID过程中,实现的是“A、C”原子性和一致性的作用。
6、MySQL中的锁
什么是“锁”?
“锁”顾名思义就是锁定的意思。
“锁”的作用是什么?
在事务ACID过程中,“锁”和“隔离级别”一起来实现“I”隔离性的作用。
避免争抢资源
锁的粒度:
1、MyIasm:低并发锁——表级锁
2、Innodb:高并发锁——行级锁
四种隔离级别
READ UNCOMMITTED
允许事务查看其他事务所进行的未提交更改
READ COMMITTED
允许事务查看其他事务所进行的已提交更改
REPEATABLE READ******
确保每个事务的 SELECT 输出一致
InnoDB 的默认级别
SERIALIZABLE
将一个事务的结果与其他事务完全隔离 mysql> show variables like '%iso%';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | REPEATABLE-READ |
+---------------+-----------------+
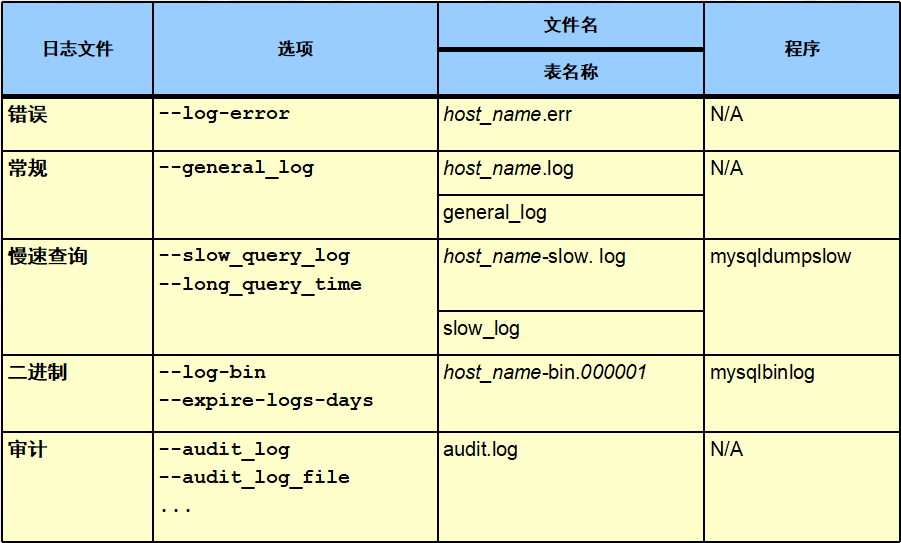
10、MySQL日志管理
1、MySQL日志类型简介
2、MySQL错误日志配置及查看
配置方法:
[mysqld]
log-error=/data/mysql/mysql.log
查看配置方式:
mysql> show variables like '%log%error%';
mysql> show variables like '%log_error%';
+---------------------+--------------+
| Variable_name | Value |
+---------------------+--------------+
| binlog_error_action | IGNORE_ERROR |
| log_error | ./web01.err |
+---------------------+--------------+
2 rows in set (0.00 sec)
不进行设置,默认在上面的目录
作用:
记录mysql数据库的一般状态信息及报错信息,是我们对于数据库常规报错处理的常用日志。
一般查询日志
配置方法:
[mysqld]
general_log=on
general_log_file=/data/mysql/server2.log
查看配置方式:
show variables like '%gen%';
作用:
记录mysql所有执行成功的SQL语句信息,可以做审计用,但是我们很少开启
3、MySQL binlog介绍及管理实战

、二进制日志都记录了什么?
已提交的数据记录,以event的形式记录到二进制文件中
只记录增删改
、二进制记录格式有哪些?
row:行模式,即数据行的变化过程,上图中Age=19修改成Age=20的过程事件。
行模式相比语句模式,臃肿,它要记录每一行的变化
statement:语句模式,上图中将update语句进行记录。
记录函数类的操作,不是特别的准确,比如插入了一个时间函数now()
mixed:以上两者的混合模式。
、三种模式有什么优缺点?
、binlog的作用
备份恢复、复制
查看模式的设置
mysql> show variables like '%binlog_format%';
+---------------+-----------+
| Variable_name | Value |
+---------------+-----------+
| binlog_format | STATEMENT |
+---------------+-----------+
1 row in set (0.00 sec)
二进制日志是否开启的查看
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF | 关闭的
+---------------+-------+
1 row in set (0.00 sec
二进制日志管理
、开启二进制日志
set sql_log_bin= 在会话级别修改为临时关闭
vi /etc/my.cnf
log-bin=/data/mysql/mysql-bin 在全局打开binlog 、设置二进制日志记录格式(建议是ROW):
配置文件中修改:
binlog-format=ROW
命令行修改
mysql> SET GLOBAL binlog_format = 'STATEMENT';
mysql> SET GLOBAL binlog_format = 'ROW';
mysql> SET GLOBAL binlog_format = 'MIXED';
、查看binlog设置
show variables like '%binlog%';
+-----------------------------------------+----------------------+
| Variable_name | Value |
+-----------------------------------------+----------------------+
| binlog_cache_size | 32768 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_error_action | IGNORE_ERROR |
| binlog_format | STATEMENT |
| binlog_gtid_simple_recovery | OFF |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_row_image | FULL |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
| binlogging_impossible_mode | IGNORE_ERROR |
| innodb_api_enable_binlog | OFF |
| innodb_locks_unsafe_for_binlog | OFF |
| max_binlog_cache_size | 18446744073709547520 |
| max_binlog_size | 1073741824 |
| max_binlog_stmt_cache_size | 18446744073709547520 |
| simplified_binlog_gtid_recovery | OFF |
| sync_binlog | 0 |什么时候写入到磁盘上
设置为1 ,每次事务提交commit就binlog cache刷新,0就是达到内存大小才写入
+-----------------------------------------+----------------------+
19 rows in set (0.00 sec)
设置文件中的内容
cat /etc/my.cnf
-------------------------------------------
[mysqld]
basedir=/appliacation/mysql
datadir=/application/mysql/data
soket=/appliacation/mysql/tmp/mysql.sock
port=3306
server_id=10
log-error=/var/log/mysql.log
log-bin=/application/mysql/data/mysql-bin
binlog_format=row
skip_name_resolve
innodb_data_file_path=ibdata1:76M;abdata2:50M:autoexend
default_storage_engine=innodb
character-set-server=utf8
antocommit=0
sync_binlog=1
[mysql]
socket=/application/mysql/tmp/mysql.sock
default-character-set=utf8
--------------------------------------------
查询二进制日志文件
ls -l /data/mysql/mysql-bin*
或者在mysql中使用命令
mysql> SHOW BINARY LOGS;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000015 | 724935 |
| binlog.000016 | 733481 |
查看当前在使用的binlog
mysql> SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+---------------+----------+--------------+------------------+
| binlog.000016 | 733481 | world_innodb | manual,mysql 刷新二进制日志
flush logs
截取二进制日志
mysqlbinlog --start-position= --stop-position= >a.sql
删除二进制:
默认情况下,不会删除旧的日志文件。
根据存在时间删除日志:
SET GLOBAL expire_logs_days = 7;
…或者…
PURGE BINARY LOGS BEFORE now() - INTERVAL 3 day; 删除3天之前的,手工
根据文件名删除日志:
PURGE BINARY LOGS TO 'mysql-bin.000010'; 删除到那个文件
help purge binary logs 查看帮助
reset master 重第一个开始重新开始记录,之前都删除了 问题:
1、什么是事件?
2、什么是position?
获取二进制日志的内容及事件,在一系列sql操作后,并commit后,可以看到日志内容
shell中使用mysqlbinlog /data/mysql/mysql-bin.000016
或者
sql中使用show binlog events in ‘mysql-bin.000016
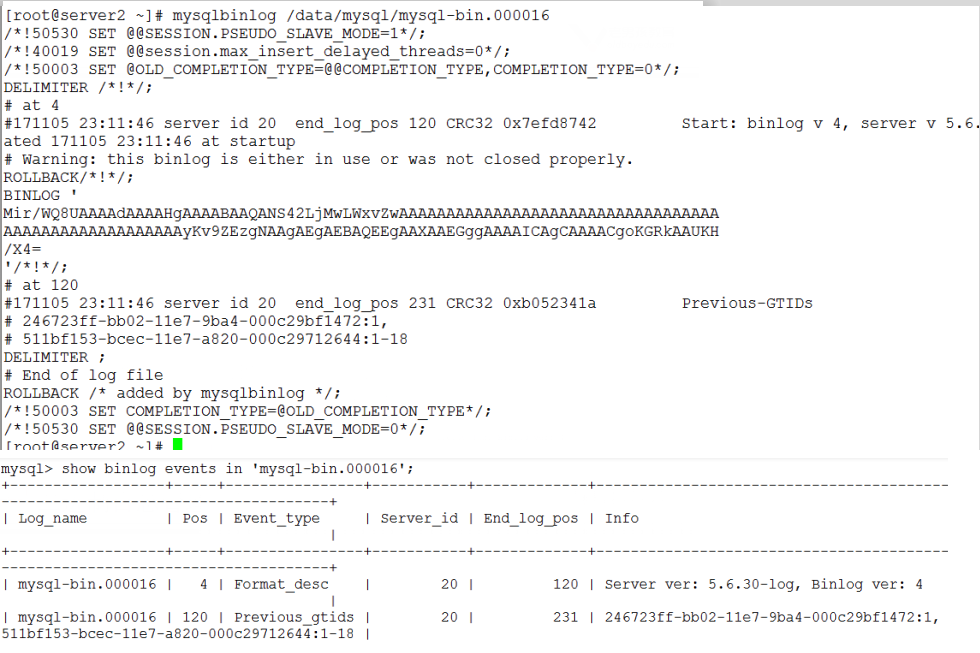
但是看不到DML详细的命令,可以使用参数(mysqlbinlog --help|more)--base64-output=decode-rows 改变输出
mysqlbinlog --base64-output=decode-rows -v /data/mysql/mysql-bin.000016
命令小结
show binary logs; 查询二进制日志文件
show binlog events in 'my-bin.000002' 查看日志中的事件
show master status; 查看当前在使用的binlog mysqlbinlog --base64-output=decode-rows -v my-bin.000002 查看日志转码后的 详细结果,有DML语句的执行过程
mysqlbinlog --start-position= --stop-position= my-bin.000002 截取
mysqlbinlog --start-position= --stop-position= my-bin. >/tmp/binlog.sql
二进制日志管理实战
、通过截取binlog恢复损坏数据
set sql_log_bin=0 临时关闭二进制日志记录,不记录恢复语句
commit
source //tmp/binlog.sql
2、如果我们没有提前去备份binlog,将来在误操作之后,有如何恢复呢?
去截取到误操作之前的所有操作,没有开始标记了
mysqlbinlog --stop-position=721 my-bin.000002 >/tmp/binlog.sql
、二进制日志翻转实现闪回数据(扩展)
一年多的二进制文件,极大,极多,如何快速恢复
4、MySQL 慢查询日志设置及管理实战
慢查询日志
是将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件
通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。
慢日志设置
long_query_time : 设定慢查询的阀值,超出次设定值的SQL即被记录到慢查询日志,缺省值为10s
slow_query_log : 指定是否开启慢查询日志
slow_query_log_file : 指定慢日志文件存放位置,可以为空,系统会给一个缺省的文件host_name-slow.log
min_examined_row_limit:查询检查返回少于该参数指定行的SQL不被记录到慢查询日志
log_queries_not_using_indexes: 不使用索引的慢查询日志是否记录到索引
配置例子
slow_query_log=1
slow_query_log_file=/data/slow/slow.log (必须要有这个文件,且有权限
long_query_time=0.5 (单位是s,)
log_queries_not_using_indexes
加入到/etc/my.cnf
# min_examined_row_limit=100 (少于100行,认为他没问题,尽量不用,如果查询半小时,返回少于100)
mysql中查看配置
mysql> show variables like '%slow%';
+---------------------------+---------------------+
| Variable_name | Value |
+---------------------------+---------------------+
| log_slow_admin_statements | OFF |
| log_slow_slave_statements | OFF |
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | /data/slow/slow.log |
+---------------------------+---------------------+
5 rows in set (0.00 sec)
查看慢查询超时时间
mysql> show variables like '%long_que%';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 0.500000 |
+-----------------+----------+
1 row in set (0.00 sec)
查看 不使用 索引 是否记录的设置
mysql> show variables like '%indexes%';
+----------------------------------------+-------+
| Variable_name | Value |
+----------------------------------------+-------+
| log_queries_not_using_indexes | ON |
| log_throttle_queries_not_using_indexes | 0 |
+----------------------------------------+-------+
2 rows in set (0.00 sec)
mysqldumpslow 如何处理慢日志
记录到慢日志中的日志是没有顺序的,它是追加的模式
mysqldumpslow命令
mysqldumpslow -s c -t /data/slow/slow.log 次数
mysqldumpslow -s at -t 10 /data/slow/slow.log 时间
这会输出记录次数最多的10条SQL语句,其中:
-s
是表示按照何种方式排序,
c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,
ac、at、al、ar,表示相应的倒叙;
-t
是top n的意思,即为返回前面多少条的数据;
----扩展工具---
pt-query-diagest 自动做判断,先优化哪一个 percona-toolkit 里面的
mysqlsla
重要的是先找到,哪条语句最慢,而且执行次数最多
11、MySQL备份与恢复
理论情况下,只要有二进制日志文件在,我就可以将数据库恢复到任意时刻
但是,有一个前提,必须是全量
而且,二进制文件只适合短期的恢复
1、备份的原因
运维工作的核心简单概括就两件事:
- 第一个是保护公司的数据.
- 第二个是让网站能7*24小时提供服务(用户体验)。
2、备份的方式
备份的类型
- 热备份:在线备份,不影响业务正常运行,避开业务高峰
- 冷备份:关闭数据,停止业务
- 温备份:加锁备份,避开业务高峰
备份方式
逻辑备份(文本表示:SQL 语句)
()mysqldump---->建库、建表、数据插入
()基于二进制日志:数据库的所有变化类的操作
()基于复制的备份:将二进制日志实时传送到另一台机器并且恢复
物理备份(数据文件的二进制副本)
()xtrabackup进行物理备份
()拷贝数据文件(冷备)
增量备份(刷新二进制日志)
基于复制的备份
3、备份工具
1、mysqldump
mysql原生自带很好用的逻辑备份工具
2、mysqlbinlog
实现binlog备份的原生态命令
3、xtrabackup
precona公司开发的性能很高的物理备份工具
4、mysqldump备份工具详解
优点:逻辑备份工具,都是SQL语句,都是文本格式,便于查看和编辑,更便于压缩
缺点:备份效率慢
mysqldump常用参数 -u -p -h -S -P 首先是链接到数据库
-A, --all-databases 全库备份
例子:mysqldump -uroot -p123 -A >/backup/full.sql
-B,单库备份
- 例子:
mysqldump -uroot -p123 -B lufei >/backup/lufei.sql
mysqldump -uroot -p123 lufei >/backup/lufei1.sql
- 区别:
加-B,增加建库(create)及“use库”的语句,在将来恢复时,不需要手工进行建库和use
不加-B,需要恢复时,先创建库,use到库下再进行恢复
- 另外,-B选项还可以实现,同时备份多个库,备份到同一个文件中
mysqldump -uroot -p123 -B lufei oldboy>/backup/lufei_oldboy.sql
不加-B,去备份,他的功能是备份路飞数据库下的oldboy表
mysqldump -uroot -p123 lufei oldboy>/backup/lufei_oldboy.sql
mysqldump 库1 表1 表2 表3 >库1.sql
生产环境下,也要加的额外参数
-R, --routines 备份存储过程和函数数据
--triggers 备份触发器数据
mysqldump -uroot -p123 -A -R --triggers >/backup/full.sql 备份多个表:
mysqldump 库1 表1 表2 表3 >库1.sql
mysqldump 库2 表1 表2 表3 >库2.sql -F, --flush-logs 备份时刷新binlog日志(回顾binlog),为了方便将来二进制截取时的起点
每天晚上0点备份数据库
mysqldump -A -B -F >/opt/$(date +%F).sql
提示:每个库都会刷新一次.
即,-F会根据有多少个库,刷新出多少个二进制文件
[root@db02 ~]# ll /application/mysql/logs/
-rw-rw---- mysql mysql Jun : oldboy-bin.
-rw-rw---- mysql mysql Jun : oldboy-bin.
-rw-rw---- mysql mysql Jun : oldboy-bin.index
一个解决每个库都会刷新的参数
--master-data={|} 告诉你备份时刻的binlog位置,一般我们选择使用2,以注释的方式记录二进制日志位置
注释
非注释,要执行(主从复制)
mysqldump -uroot -p123 -A --master-data= >/backup/full.sql
看一下记录:
[root@db02 logs]# sed -n '22p' /opt/t.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='oldboy-bin.000005', MASTER_LOG_POS=;
[root@db02 logs]# mysqldump -B --master-data= oldboy >/opt/t.sql 锁表:适合所有引擎(myisam,innodb) (温备份)
-x, --lock-all-tables
-l, --lock-tables
mysqldump -B -x oldboy >/opt/t.sql
有了--master-data 就不用锁表参数了
基于事务引擎:不用锁表就可以获得一致性的备份.
生产中99% 使用innodb事务引擎.
ACID四大特性中的隔离性
--single-transaction 对innodb引擎进行热备
mysqldump -uroot -p123 -A -R --triggers --master-data=2 --single-transaction >/backup/full.sql
这是比较合适的备份方式
热备,就是不需要锁表,它是以快照的方式实现热备
举例子:查人数,把教室的学员照个相,在相片上点数 压缩备份:压缩比很高
mysqldump -B --master-data= oldboy|gzip >/opt/t.sql.gz
解压:
zcat t.sql.gz >t1.sql
gzip -d t.sql.gz #删压缩包 适合多引擎混合(例如:myisam与innodb混合)的备份命令如下:
mysqldump -A -R --triggers --master-data= --single-transaction |gzip >/opt/all_$(date +%F).sql.gz 使用source命令进行恢复:
mysql>set sql_log_bin=0; 临时不向二进制文件记录
mysql> source /opt/xxx.sql;
5、mysqldump+mysqlbinlog实现增量备份
6、企业级备份策略及恢复案例
背景环境:
正在运行的网站系统,mysql数据库,数据量25G,日业务增量10-15M。
备份方式:
每天23:00点,计划任务调用mysqldump执行全备脚本
故障时间点:
上午10点,误删除了一个表 如何恢复?
思路:
、断开业务,防止对数据库二次伤害,挂出维护页面
、搭建备用库,恢复全备
、截取昨天晚上23:00之后到上午10点误删除操作之前的二进制日志
、恢复到备用库,验证数据可用性和完整性
、两种方案恢复前端应用
5.1 备用库导出误删除的表,导入到生产库,开启业务
5.2 直接将应用切割到备用库,替代生产库,开启业务
------------------
模拟故障并恢复:
0、为了模拟 二进制全清除,
mysql>reset master;
删除原库数据
cd /application/mysql/data
\rm -rf *
pkill mysqld
初始化
/application/mysql/script/mysql_install_db --basedir=/application/mysql --datadir=/application/data --user=mysql
启动
/etc/init.d/mysqld start
mysql
、插入原始数据:
mysql> create database oldboy;
mysql> use oldboy
mysql> create table t1 (id int,name varchar());
mysql> insert into t1 values (,'zhang3');
mysql> insert into t1 values (,'li4');
mysql> insert into t1 values (,'wang5');
mysql> commit;
、模拟前一天晚上23:00全备
mysqldump -A -R --triggers --master-data= --single-transaction |gzip >/backup/all_$(date +%F).sql.gz 、模拟白天(:-:)业务对数据的修改
mysql> insert into t1 values (,'zhang33');
mysql> insert into t1 values (,'li44');
mysql> insert into t1 values (,'wang54');
mysql> commit;
、模拟故障
drop table t1; 、恢复
()准备全备,并获取到备份文件中的binlog的截取起点 gunzip all_2018--.sql.gz
-- CHANGE MASTER TO MASTER_LOG_FILE='my-bin.000004', MASTER_LOG_POS=;
()截取二进制日志
查看删库前的日志
mysql>show binlog events in 'my-bin.000004',找到删除之前的位置
mysqlbinlog --start-position= --stop-position= /data/binlog/my-bin. >/backup/binlog.sql -----
show binlog events in 'my-bin.000004'; ----》drop之前的position为1126
-----
()恢复全备+binlog
set sql_log_Bin=;
source /backup/all_2018--.sql;
source /backup/binlog.sql
7、Xtrabackup备份恢复实战
Xtrabackup介绍
percona公司的备份工具,性能比较高。物理备份工具。
特点:
物理备份工具,在同级数据量基础上,都要比逻辑备份性能要好的多。
特别是在数据量比较大的时候,体现的更加明显。
备份方式:
、拷贝数据文件
、拷贝数据页
备份原理(innodb):
、对于innodb表,可以实现热备
()在数据还有修改操作的时刻,直接将数据文件中的数据页备份
此时,备份走的数据对于当前mysql来讲是不一致。
()将备份过程中的redo和undo一并备走。
()为了恢复的时候,只要保证备份出来的数据页LSN 能和redo LSN匹配,
将来恢复的就是一致的数据。redo应用和undo的应用。
、对与myisam表,实现自动锁表拷贝文件。
Xtrabackup安装
、安装
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/6/x86_64/percona-xtrabackup-24-2.4.4-1.el6.x86_64.rpm
yum -y install percona-xtrabackup--2.4.-.el6.x86_64.rpm 备份命令:
xtrabackup
innobackupex ******
依赖配置文件,需要配置好
Xtrabackup全备份及恢复实战
创建备份目录
mkdir /server/backup -p
全备完整命令
innobackupex --user=root --password=oldboy123
--socket=/application/mysql-5.6./tmp/mysql.sock
--no-timestamp /server/backup/full 因为是新库,且配置文件中指定可sock简单的命令
innobackupex /server/backup/
默认是备份到以时间戳作为目录名的目录中,加参数后,备份到指定目录
innobackupex --no-timestamp /server/backup/full 全备的回复例子:
1、恢复数据前的准备(合并xtabackup_log_file和备份的物理文件),因为备份时把redo和undo也备走了
-use-memory:恢复的时候,单独指定一个内存,属于优化的细节
--apply-log:做操作-->恢复数据前的准备(合并xtabackup_log_file和备份的物理文件)
innobackupex --apply-log --use-memory=32M /server/backup/full/
2、模拟故障
停库:
Kill - pid
lsof -i :
破坏数据:
cd /application/mysql/data
mv data /opt/ 或者 \rm -rf *
3、恢复
cp -a /server/backup/full/ /application/mysql/data
或者
innobackupex --copy-back /server/backup/full/
注意:恢复时,要确认数据路径是空的,并且数据库是停掉的
chown -R mysql.mysql /application/mysql/data
启动:
/etc/init.d/mysqld start
mysql -e "select * from oldboy.test"
注:我们还可以使用—copy-back参数进行恢复
Xtrabackup实现增量备份与恢复实战
、全备:
innobackupex --user=root --password= --no-timestamp /backup/full/
、模拟数据变化
、第一增量:
innobackupex --user=root --password= --incremental --no-timestamp --incremental-basedir=/backup/full/ /backup/inc1
、模拟数据变化
、第二次增量:
innobackupex --user=root --password= --incremental --no-timestamp --incremental-basedir=/backup/inc1 /backup/inc2
、模拟数据损坏
、恢复数据:
innobackupex --apply-log --redo-only /backup/full
无法直接恢复,要依赖全备,合并
innobackupex --apply-log --redo-only --incremental-dir=/backup/inc1 /backup/full
innobackupex --apply-log --incremental-dir=/backup/inc2 /backup/full
innobackupex --apply-log /backup/full
--redo-only:只把已提交的事务合并,不合并undo。除了最后一次增量,都要加上这个参数
把原有的数据删掉,必须是空的
cd /application/mysql/data
\rm -rf *
停库
pkill mysqld
innobackupex --copy-back /backup/full/
Xtrabackup企业级增量备份实战
背景:
某大型网站,mysql数据库,数据量500G,每日更新量100M-200M
备份策略:
xtrabackup,每周日0:00进行全备,周一到周六00:00进行增量备份。
故障场景:
周三上午10点出现数据库意外删除表操作。
如何恢复?
思路:
1、停业务,挂维护页
2、找备用库
3、合并full+inc1+inc2
4、截取周二晚上inc2备份后到周三上午10点,t1表删除之前的binlog日志
5、将合并后的full+截取的binlog恢复到备用库
6、验证数据可用性和完整性
7、使用备用库替代生产库使用 或者 将t1表导出并导入回生产库
8、业务恢复 -----------------
-----------------
思考:以上恢复策略是否可以优化?
为了恢复1G表,需要将整个全备恢复,有必要吗?有什么好的解决办法? drop table t1;
create table t1 (id int,name varchar(20)); 创建表结构,和原来的表结构一模一样
alter table t1 discard tablespace; 在数据库内部删除 cd /application/mysql/data/oldboy
cp /backup/full/oldboy/t1.ibd ./ 将备份中的.ibd文件拷贝到新建的表下面 chown -R mysql.mysql * 修改文件的权限归属
alter table t1 import tablespace; 导入数据
12、MySQL主从复制
1、主从复制简介
复制能为我们做什么?
- 辅助备份
- 高可用
- 分担负载
复制是 MySQL 的一项功能,允许服务器将更改从一个实例复制到另一个实例。
- 主服务器将所有数据和结构更改记录到二进制日志中。
- 从属服务器从主服务器请求该二进制日志并在本地应用其内容。
2、主从复制原理
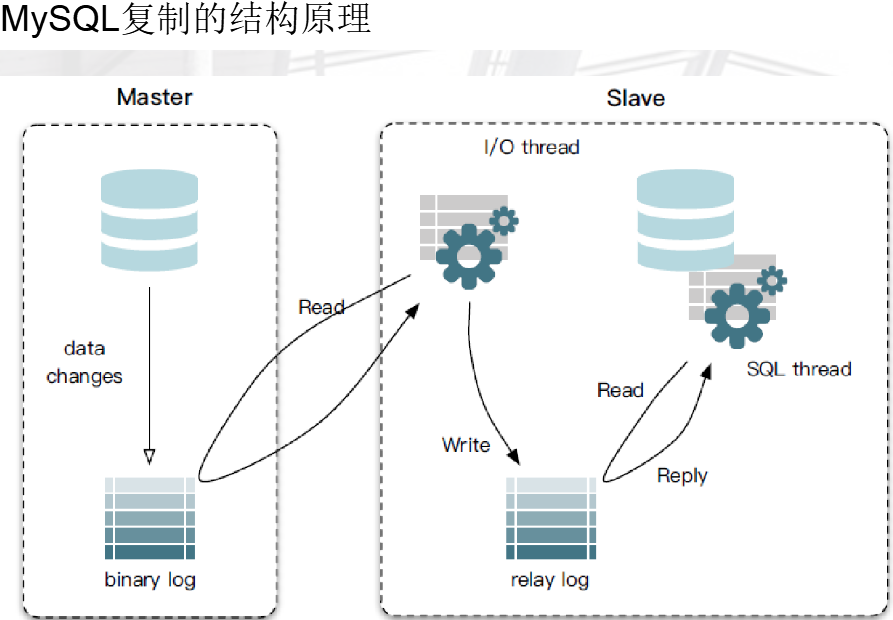
主从复制的前提
1.1 两台以上mysql实例
多台物理机
多个mysql实例
1.2 主库要开启二进制日志 1.3 主库要提供复制相关的用户
replication slave,一个比较特殊的权限
grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
1.4 从库需要将和主库相差的数据,进行追加
一般情况下可以人为备份主库数据,恢复到从库上
1.5 从应该从恢复之后的时间点,开始自动从主库获取新的二进制日志开始应用
我们需要人为告诉从库,从哪开始自动开始复制二进制日志(file+position),另外还需要告诉从库user,passwd,port,ip
change master to 命令根据mster.info中的参数 来连接主库
复制中的线程
、主库
Dump thread:在复制过程中,主库发送二进制日志的线程
、从库
IO thread:向主库请求二进制日志,并且接受二进制日志的线程
SQL thread:执行请求过来的二进制线程
复制中的文件
、主库
binlog:主库的二进制文件
、从库
Relay-log:中继日志,存储请求过来的二进制日志
Relay-index:
Master.info:
1、从库连接主库的重要参数(user,passwd,ip,port)
2、上次获取过的主库二进制日志的位置
Relay-log.info:存储从库SQL线程已经执行过的relaylog日志位置
主从复制的工作原理
3.1 从库,IO线程,读取master.info中的信息,
获取到连接参数(user\passwd\ip\port)+上次请求过的主库的binlog的位置(例子:mysql-bin.,position=)
3.2 IO线程使用链接到主库,拿着位置信息(mysql-bin.,position=),问主库有没有比这个更新的二进制日志。
3.3 主库查询二进制日志,并对比从库发送过来的位置信息(mysql-bin.,position=),如果有新的二进制日志,会通过
dump thread发送给从库。
3.4 从库通过IO线程,接受主库发来的二进制日志,存储到TCP/IP缓存中,并且返回“ACK”确认给主库,这时主库收到ACK后,
就认为复制完成了,可以继续其他工作了。
3.5 从库更新master.info,二进制日志位置更新为新的位置信息。
3.6 从库IO线程会将TCP/IP缓存中的日志,存储到relay-log中继日志文件中。
3.7 从库SQL线程,读取relay-log.info,获取到上次执行到的relaylog日志位置,以这个位置信息作为起点,往后继续执行中继日志。
3.8 SQL线程执行完成所有relay之后,会更新relay-log.info信息为新位置信息。 到此为止,一次完整的复制过程就完成了。
3、主从复制搭建实践
思路:
、两个节点
、主库binlog开启,从库开启relay-log
、server-id不同
、主库创建复制账户
、主库备份并记录二进制文件和position
、从库change master to连接主库
、启动从库复制
、验证主从
详细配置过程,请看配置文档。
配置步骤
主从复制搭建实战: 、准备环境
思路:
、两个以上节点(多实例)
:master
:slave1
:slave2
、主库binlog开启,从库开启relay-log(默认在数据目录下生成)
vim /data//my.cnf
log-bin=/data//mysql-bin
binlog_format=row 、server-id不同
[root@db02 data]# cat /data//my.cnf |grep server-id
server-id=
[root@db02 data]# cat /data//my.cnf |grep server-id
server-id=
[root@db02 data]# cat /data//my.cnf |grep server-id
server-id=
、关闭数据库的自动域名解析
每个节点都加入以下配置:vim /data/3307{8|9}/my.cnf
skip-name-resolve
、启动多实例
mysqld_safe --defaults-file=/data//my.cnf &
mysqld_safe --defaults-file=/data//my.cnf &
mysqld_safe --defaults-file=/data//my.cnf & 、主库创建复制账户
连接到主库:
mysql -S /data//mysql.sock
grant replication slave on *.* to repl@'10.0.0.%' identified by ''; 、从库数据的追加
()不需要追加的情况
主和从同时搭建的新环境,就不需要备份主库数据,恢复到从库了,直接从第一个binlog(mysql-bin.)的开头位置()
()如果主库已经工作了很长时间了,我们一般需要备份主库数据,恢复到从库,然后从库从备份的时间点起自动进行复制
重点针对第二种情况进行演示:
备份主库:
mysqldump -S /data//mysql.sock -A -R --triggers --master-data= --single-transaction >/tmp/full.sql
sed -n '22p' /tmp/full.sql 下面需要用到这个信息
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=
恢复到从库:
mysql -S /data//mysql.sock
mysql> set sql_log_bin=;
mysql> source /tmp/full.sql 、从库开启主从复制:
mysql -S /data//mysql.sock help change master to
执行命令:
CHANGE MASTER TO
MASTER_HOST='10.0.0.52',
MASTER_USER='repl',
MASTER_PASSWORD='',
MASTER_PORT=,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=; 开启主从(开启IO和SQL线程):
start slave; 、查看主从状态: show slave status\G Slave_IO_Running: Yes
Slave_SQL_Running: Yes
--------------
、主从重要状态信息介绍 show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno:
Last_IO_Error:
Last_SQL_Errno:
Last_SQL_Error:
4、主从复制状态监控
mysql> show slave status\G
***************** . row *********************
Slave_IO_State: Queueing master event to the relay log
...
Master_Log_File: mysql-bin.
Read_Master_Log_Pos:
Relay_Log_File: slave-relay-bin.
Relay_Log_Pos:
Relay_Master_Log_File: mysql-bin.
Slave_IO_Running: Yes 主要看这两
Slave_SQL_Running: Yes 主要看这两
...
Exec_Master_Log_Pos:
...
Seconds_Behind_Master:
5、主从复制基本故障处理
主从复制故障及解决
stop slave; #<==临时停止同步开关。
set global sql_slave_skip_counter = ; #<==将同步指针向下移动一个,如果多次不同步,可以重复操作。
start slave;
/etc/my.cnf
slave-skip-errors = ,,
如何避免:从库只读 read_only IO线程故障:
1、主库连接不上
user、password、port、ip 错误
解决方案:
stop slave;
reset slave all; 清理master.info。重新开始
change master to
start slave;
防火墙
网络不通
skip-name-resolve
stop slave;
start slave;
2、主库二进制日志丢失或损坏
解决方案:
stop slave;
reset slave all;
重新备份恢复
change master to
start slave;
SQL线程故障:
查看状态,发现SQL线程被关闭,且出现下面的问题
执行relaylog日志新事件
1、删除、修改对象的操作时,没有这个对象
2、创建对象时,对象已存在
3、主键冲突
从库做写入操作,会导致以上问题出现 处理方法:
stop slave;
set global sql_slave_skip_counter = 1; 跳过错误
start slave; /etc/my.cnf
slave-skip-errors = 1032,1062,1007 跳过指定代号代表的错误 但是,以上操作有时是有风险的,最安全的做法就是重新构建主从。
怎么预防以上问题?
从库加入配置文件
设置成只读库
set global read_only=1;
vim /etc/my.cnf
read_only=1 ---->只能控制普通用户,控制不了管理员,从库设置成只读库
------------------
主从异常——主从延时过长
show slave status \G 查看状态
Seconds_Behind_Master:0 主从延时为0 默认的主从复制机制是异步的一个过程。 主库原因:
1、主库做修改操作之后,才会记录二进制日志。
sync_binlog=0/1
官方文档
If the value of this variable is greater than 0,
the MySQL server synchronizes its binary log to disk (using fdatasync())
after sync_binlog commit groups are written to the binary log.
The default value of sync_binlog is 0, which does no synchronizing to disk—in this case,
the server relies on the operating system to flush the binary log's contents from time to time as for any other file.
A value of 1 is the safest choice because in the event of a crash you lose at most one commit group from the binary log.
However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast)
---------------------总结成两句话
1:表示:每次事务commit,刷新binlog到磁盘
0:系统决定binlog什时候刷新到磁盘
2、主库的压力特别大(大事务、多事务)
3、从库数量多,导致dump线程繁忙
-------------------
从库原因:
1、relay-log写入慢
2、SQL线程慢(主从硬件差异比较大)
-----------------------------
尽可能的避免主从延时
1、sync_binlog=1
2、大事务拆成小事务,多事务进行分离
3、使用多级主从,分库分表架构
4、将binlog放到ssd或者flash上,高性能存储 5、将relay放到ssd或者flash上
6、尽量选择和主库一致硬件和配置
6、主从复制高级功能
、延时复制
、SQL多线程
、复制过滤
、半同步复制
、GTID复制
详细
- 主从复制高级功能——半同步复制
出发点:保证主从数据一致性的问题,安全的考虑
5.5出现的概念,但是不建议使用,性能太差,和之前不同的是ack返回的时间点晚了一步,必须在二进制文件写入relay后 .6以后出现group commit 组提交功能,来提升开启版同步复制的性能 5.7增强半同步复制的新特性:after sync; ------
加载插件
主:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
从:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
查看是否加载成功:
show plugins; 启动:
主:
SET GLOBAL rpl_semi_sync_master_enabled = ;
从:
SET GLOBAL rpl_semi_sync_slave_enabled = ; 重启从库上的IO线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD; 查看是否在运行
主:
show status like 'Rpl_semi_sync_master_status';
从:
show status like 'Rpl_semi_sync_slave_status';
----- 补充:
rpl_semi_sync_master_timeout |
默认情况,到达10秒钟还没有ack,主从关系自动切换为普通复制
如果是1主多从的半同步复制,只要有一台落地relaylog,返回ack,这次半同步就完成了。 --------------------------------------
- 主从复制高级功能——延时从库
会专门找一个节点,配置成延时节点,尽可能防止逻辑损坏,一般情况下这个节点会被用备份
我们配置的是SQL_thread的延时,一般会设置到3-6小时
mysql>stop slave;
mysql>CHANGE MASTER TO MASTER_DELAY = ;
mysql>start slave;
mysql> show slave status \G
SQL_Delay: 取消延时:
mysql> stop slave;
mysql> CHANGE MASTER TO MASTER_DELAY = ;
mysql> start slave;
-----------------------
- 主从复制高级功能——复制过滤
挑着复制,只想复制某些内容
主库方面控制(不建议使用):有分风险
show master status;
白名单:只记录白名单中列出的库的二进制日志
binlog-do-db
黑名单:不记录黑名单列出的库的二进制日志
binlog-ignore-db 从库方面控制:
show slave status\G 查看信息
白名单:只执行白名单中列出的库或者表的中继日志
--replicate-do-db=test 库
--replicate-do-table=test.t1 库下的表
--replicate-wild-do-table=test.x* 模糊
黑名单:不执行黑名单中列出的库或者表的中继日志
--replicate-ignore-db
--replicate-ignore-table
--replicate-wild-ignore-table 只复制world数据库的数据
主:只记录world的二进制日志,但是风险大
从:写入配置文件/data/3308/my.cnf
replicate-do-db=world
--------------
主从复制新特性——GTID复制
之前说的是基于 二进制日志的文件号 + 二进制日志position号 来实现的复制
叫做传统复制结构classic GTID 是新的复制结构
好处:简化了复制的难度,主从切换的时候更有优势 .6新特性
GTID(Global Transaction ID全局事务ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。
它的官方定义如下:
GTID = source_id :transaction_id
7E11FA47-31CA-19E1-9E56-C43AA21293967:
每一台mysql实例中,都会有一个唯一的uuid(128位随机数),标识实例的唯一性
auto.cnf,存放在数据目录下 重要参数:
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates= gtid-mode=on --启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true --强制GTID的一致性
log-slave-updates= --slave更新是否记入日志
----------------- 构建1主2从的GTID复制环境:
3台虚拟机,
db02 克隆两台虚拟机环境,分别命名为db01、db03,在生产中准备3台真实的物理机,不用多实例 要求:
、IP地址、主机名
db01:10.0.0.51/
db03:10.0.0.53/
、清理所有之前3306的相关数据,只留软件
db01:
cd /application/mysql/data/
\rm -rf *
cd /data/binlog/
\rm -rf * db02:
cd /application/mysql/data/
\rm -rf *
cd /data/binlog/
\rm -rf * db03:
cd /application/mysql/data/
\rm -rf *
cd /data/binlog/
\rm -rf * 、准备配置文件
规划:
主库: 10.0.0.51/
从库1: 10.0.0.52/
从库2:10.0.0.53/ 主库:
加入以下配置信息
db01:10.0.0.51/ vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
socket=/tmp/mysql.sock
log-error=/var/log/mysql.log
log_bin=/data/binlog/mysql-bin
binlog_format=row
skip-name-resolve
server-id=
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=
[client]
socket=/tmp/mysql.sock slave1:
db02:10.0.0.52/ vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
socket=/tmp/mysql.sock
log-error=/var/log/mysql.log
log_bin=/data/binlog/mysql-bin
binlog_format=row
skip-name-resolve
server-id=
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=
[client]
socket=/tmp/mysql.sock slave2:
db02:10.0.0.53/ vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
socket=/tmp/mysql.sock
log-error=/var/log/mysql.log
log_bin=/data/binlog/mysql-bin
binlog_format=row
skip-name-resolve
server-id=
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=
[client]
socket=/tmp/mysql.sock
-----------------
三台节点分别初始化数据:
/application/mysql/scripts/mysql_install_db --user=mysql --basedir=/application/mysql --datadir=/application/mysql/data/ 分别启动三个节点mysql:
/etc/init.d/mysqld start 测试启动情况:
mysql -e "show variables like 'server_id'" master:
slave:, :
grant replication slave on *.* to repl@'10.0.0.%' identified by ''; \:
change master to master_host='10.0.0.51',master_user='repl',master_password='' ,MASTER_AUTO_POSITION=;
# 参数MASTER_AUTO_POSITION=1 自动判断哪些事务有,哪些食物没有,不用像之前那样设置起点位置 start slave;
-------------
show master status \G
show slave status \G 查看状态
正常情况Retrieved_Gtid_Set(记录的事务数) 和 Executed_gtid_Set(已执行的事务数) 的事务数是一样的
除了这两个标识,其他的变化不大
13、MHA高可用
普通主从复制方案不足
高可用---业务不间断的工作---用户的体验
普通主从环境,存在的问题:
、监控的问题:APP应用程序,并不具备监控数据库的功能,没有责任监控数据库是否能连接。
、选主的问题:选替代者,没有选主的功能
、failover:VIP漂移,将IP落到新的主上,对于应用透明
、数据补偿:数据不全
宕机后的架构形态的改变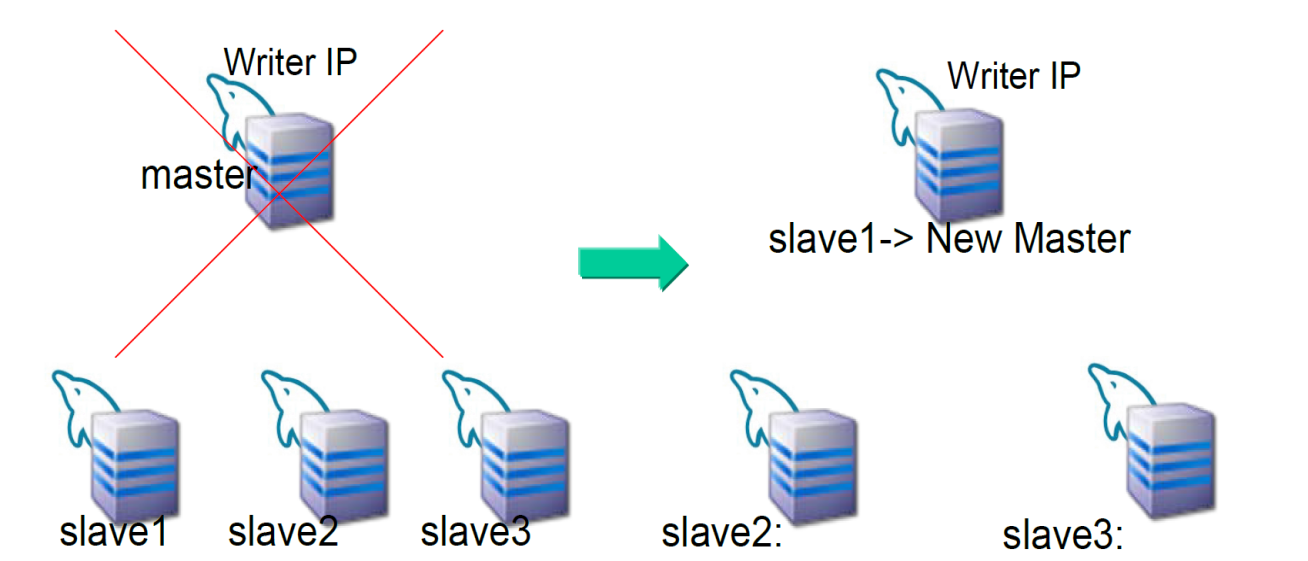
普通主从复制架构思路主库宕机场景(1)
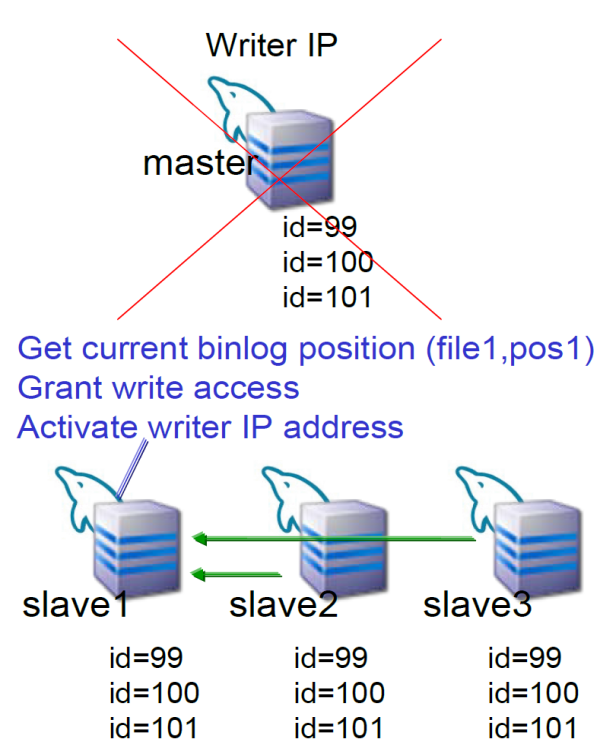
普通主从复制架构思路主库宕机场景(2)
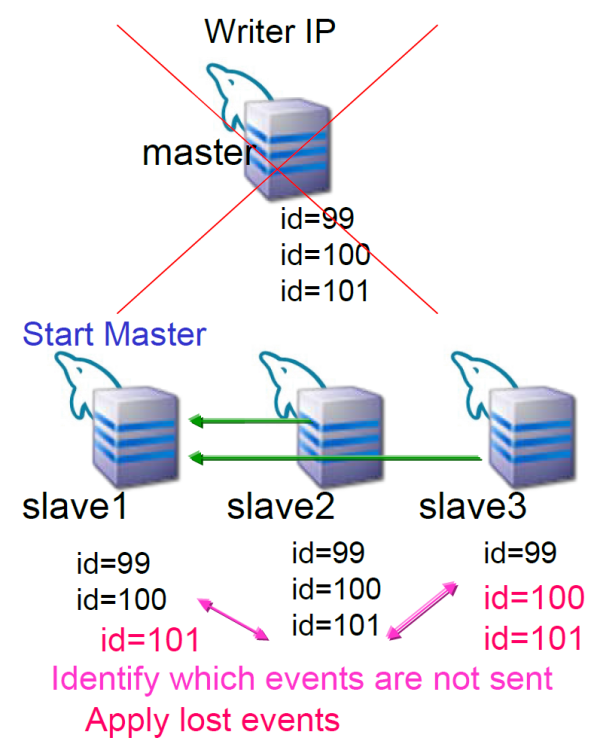
普通主从复制架构思路主库宕机场景(3)

高可用解决方案简介
企业高可用解决方案:
MMM(过时)
MHA(目前推荐)
PXC、Galera Cluster(出现很多年,企业很少用)
5.7. MGR 、Innodb Cluster(未来的趋势,尽早研究)
MySQL NDB Cluster(出现很多年,仍然不完善)
MyCAT 高可
MHA简介
MHA(Master High Availability),
由日本DeNA公司youshimaton(现就职于Facebook公司)开发。
MHA能做到在10~30秒之内自动完成数据库的Failover,
Failover的过程中,能最大程度上保证数据的一致性。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。
MHA高可用集群,要求一个复制集群中需要有三台数据库服务器,一主二从,不支持多实例。
出于机器成本的考虑,淘宝也在该基础上进行了改造,淘宝TMHA支持一主一从。
注意:必须使用独立的数据库节点,不支持多实例。
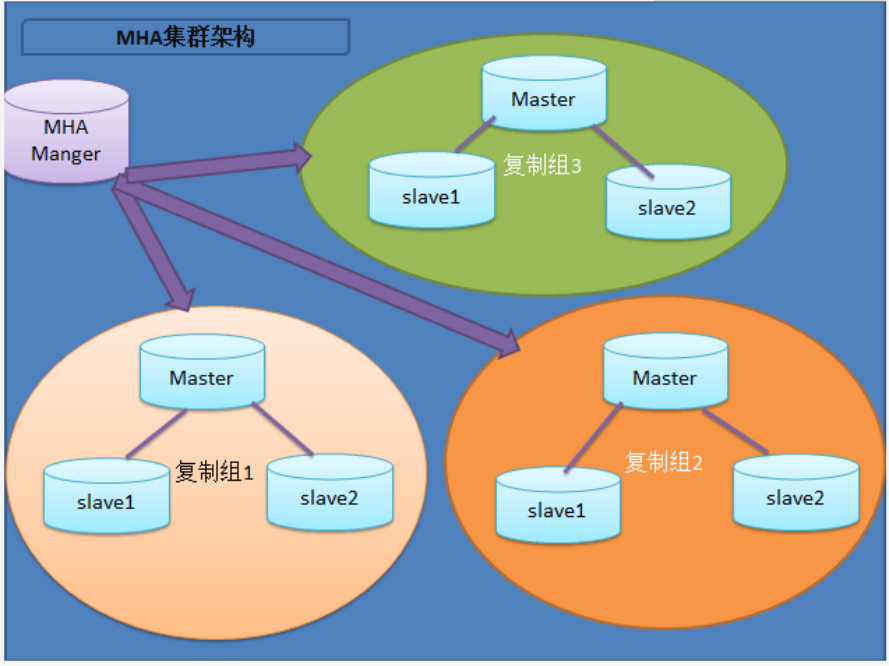
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_conf_host 添加或删除配置的server信息
masterha_master_switch 控制故障转移(自动或者手动)
Node工具包
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs
保存和复制master的二进制日志
apply_diff_relay_logs
识别差异的中继日志事件并将其差异的事件应用于其他的从节点
slave filter_mysqlbinlog
去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs
清除中继日志(不会阻塞SQL线程)
MHA实现原理
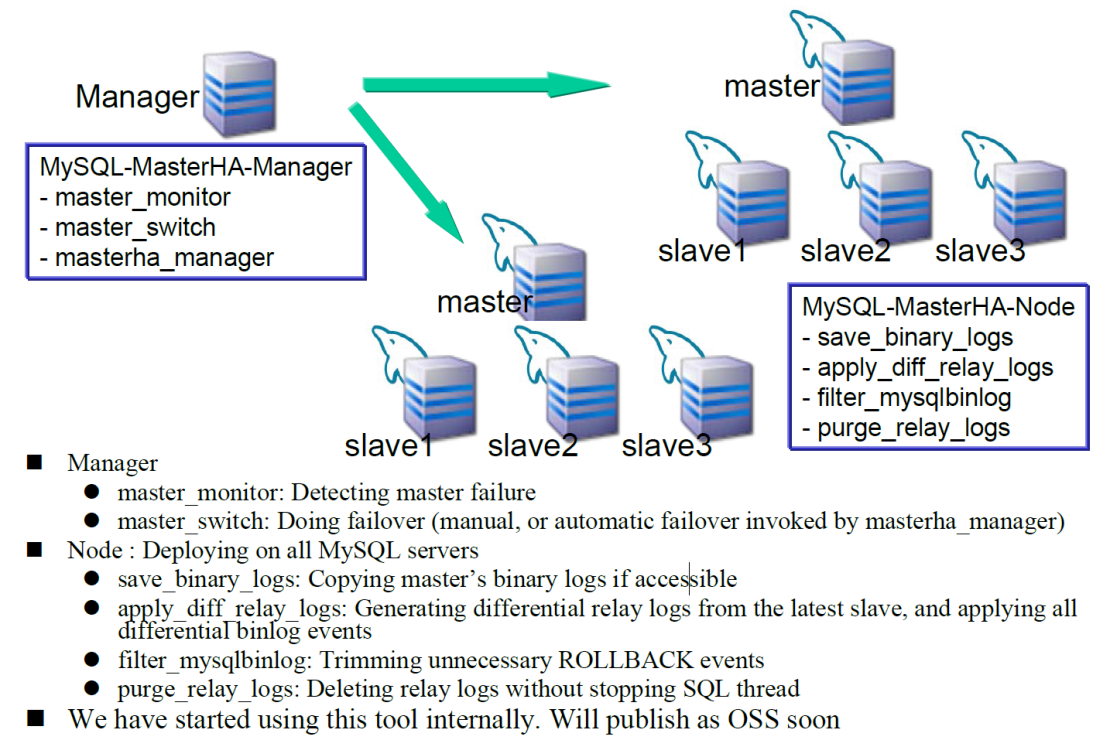
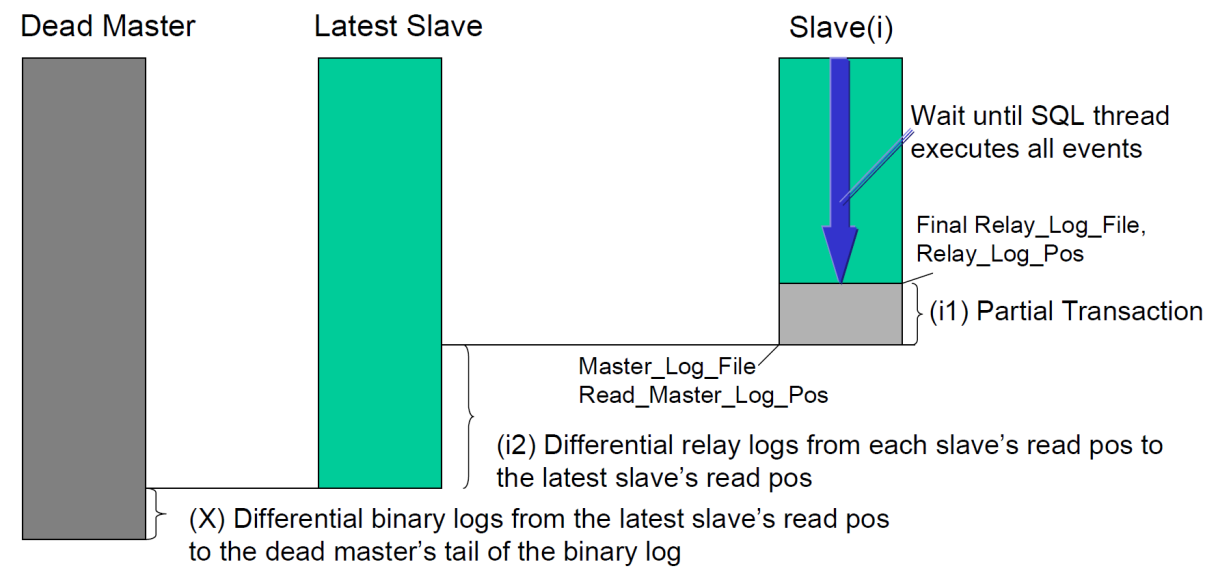
()Manager程序负责监控所有已知Node(1主2从所有节点)
()当主库发生意外宕机
(2.1)mysql实例故障(SSH能够连接到主机)
、监控到主库宕机,选择一个新主(取消从库角色,reset slave),选择标准:数据较新的从库会被选择为新主(show slave status\G)
、从库通过MHA自带脚本程序,立即保存缺失部分的binlog
、二号从库会重新与新主构建主从关系,继续提供服务
、如果VIP机制,将vip从原主库漂移到新主,让应用程序无感知
(2.2)主节点服务器宕机(SSH已经连接不上了)
、监控到主库宕机,尝试SSH连接,尝试失败
、选择一个数据较新的从库成为新主库(取消从库角色 reset slave),判断细节:show slave status\G
、计算从库之间的relay-log的差异,补偿到2号从库
、二号从库会重新与新主构建主从关系,继续提供服务
、如果VIP机制,将vip从原主库漂移到新主,让应用程序无感知
、如果有binlog server机制,会继续讲binlog server中的记录的缺失部分的事务,补偿到新的主库
部署步骤
- 三台MySQL独立节点实例,主机名、IP、防火墙关闭等
- 开启1主2从GTID复制结构--之前做过了
- 关闭各节点relay-log自动删除功能
- relay_log_purge=0
- 记不住show一下:show variables like '%relay%';
- 各节点部署node工具包及依赖包
- 选择其中一个从节点进行部署manager工具包
- 各节点ssh秘钥互信配置
- 配置manager节点配置文件(注意:在数据库中添加mha管理用户和密码)
- 做ssh互信检查和主从状态检查
- 开启MHA功能
MHA高可用解决方案详解
3.1、安装mha node: 依赖包perl-DBD-MySQL ,并在三个节点都安装node软件
rpm包直接
rpm -ivh mha4mysql-node-0.56-.el6.noarch.rpm 3.2、主库中创建mha管理用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';
从库中也要查看是不是有这个账户
3.3、配置软连接 ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /application/mysql/bin/mysql /usr/bin/mysql 3.4、部署manger节点(建议在从节点db03)
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes 3.5、安装 manager软件
rpm -ivh mha4mysql-manager-0.56-.el6.noarch.rpm 3.6、创建Manager必须目录与配置文件
mkdir -p /etc/mha
mkdir -p /var/log/mha/app1 ----》可以管理多套主从复制
创建配置文件 (不需要的配置不要留着,注释没用,切换后会重写)
vim /etc/mha/app1.cnf -----》serverdefault可以独立
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
user=mha
password=mha
ping_interval=
repl_password=
repl_user=repl
ssh_user=root [server1]
hostname=10.0.0.51
port= [server2]
hostname=10.0.0.52
port= [server3]
hostname=10.0.0.53
port= 3.7、配置互信(所有节点)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null >& ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.51
ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.52
ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.53
检测是否成功
ssh 10.0.0.{51..53} date
3.8、检测互信
masterha_check_ssh --conf=/etc/mha/app1.cnf 3.9、检测主从
masterha_check_repl --conf=/etc/mha/app1.cnf 3.10、启动MHA manager
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log >& & 查看日志,
cd /var/log/mha
cd app1/
tail -f manager
故障演练
、宕掉db01主库,停掉数据库
、tail -f /var/log/mha/app1/manager 观察日志变化
、恢复主库运行,重新将db01加入到主从复制关系中
mysql
CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=, MASTER_AUTO_POSITION=, MASTER_USER='repl', MASTER_PASSWORD='';
start slave;
、将配置文件中加入修稿的故障节点(因为当即后,系统会自动清理掉server1)
、启动MHA了manager程序
masterha_check_ssh --conf=/etc/mha/app1.cnf
masterha_check_repl --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log >& & 检测状态
masterha_check_status --conf=/etc/mha/app1.cnf
使用MHA自带脚本实现IP FailOver(vip 漂移,应用透明)
配置步骤
上传准备好的/usr/local/bin/master_ip_failover
vim master_ip_failover
只修改脚本中以下内容
my $vip = '10.0.0.55/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
给脚本添加 执行权限
chown +x
转换格式
dos2unix /usr/local/bin/master_ip_failover 修改配置文件
vim /etc/mha/app1.cnf
添加:
master_ip_failover_script=/usr/local/bin/master_ip_failover 重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log >& & 手工在主库上绑定vip,注意一定要和配置文件中的ethN一致,我的是eth0:(1是key指定的值)
ifconfig eth0: 10.0.0.55/ 切换测试:
停主库,看vip是否漂移
binlogserver配置:
思考:为什么不直接在从slave上左binlogserver?
找一台额外的机器,必须要有5.6以上的版本,支持gtid并开启,我们直接用的第二个slave [binlog1]
no_master=1 不参与主从
hostname=10.0.0.53
master_binlog_dir=/data/mysql/binlog 单独的,不能和主库的binlog一样
提前创建好,这个目录不能和原有的binlog一致
mkdir -p /data/mysql/binlog
chown -R mysql.mysql /data/mysql/*
修改完成后,将主库binlog拉过来(从000001开始拉,之后的binlog会自动按顺序过来)
cd /data/mysql/binlog -----》必须进入到自己创建好的目录 mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
最好,先在主库查看一下,是不是从000001开始的
重启MHA,生效配置:
重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
其他参数说明
manager检测节点存活的间隔时间,总共会探测4次。
ping_interval=
#节点标签下设置
设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
candidate_master=1
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,
因为对于这个slave的恢复需要花费很长时间,
通过设置check_repl_delay=,
MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,
因为这个候选主在切换的过程中一定是新的master
check_repl_delay=
14 、Atlas-MySQL读写分离架构
MHA高可用架构的问题
- 所有的压力都集中在了主上
- 从的资源被大大的浪费,应该想办法让从分担一下主的压力
我们的业务基本都是读多写少,何不分离开来,增加架构的效率
增加中间层,任何的增删改查都走中间层,来分配路由到后端
企业读写分离及分库分表方案介绍
Mysql-proxy(oracle) 已不再开发
Mysql-router(oracle) 重点关注
Atlas (Qihoo 360) 轻量级,简单
Atlas-sharding (Qihoo )
Cobar(是阿里巴巴(B2B)部门开发) 已不再更新
Mycat(基于阿里开源的Cobar产品而研发)
TDDL Smart Client的方式(淘宝)
DRDS 阿里云的产品
Oceanus(58同城数据库中间件)
OneProxy(原支付宝首席架构师楼方鑫开发)
vitess(谷歌开发的数据库中间件)
Heisenberg(百度)
TSharding(蘑菇街白辉)
Xx-dbproxy(金山的Kingshard、当当网的sharding-jdbc )amoeba
Atlas简介
Atlas 是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。
它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。
目前该项目在360公司内部得到了广泛应用,很多MySQL业务已经接入了Atlas平台,每天承载的读写请求数达几十亿条。 源码 Github: https://github.com/Qihoo360/Atlas
你理解的中间层应该能做些啥?
、监控
、对应用透明,有IP,port
、分析语句
、进行语句的路由
、有负载均衡的功能
、平滑上下线节点的能力
、黑名单等
Atlas主要功能介绍
读写分离
从库负载均衡
自动分表
IP过滤
SQL语句黑白名单
DBA可平滑上下线DB
自动摘除宕机的DB
Atlas应用场景介绍
Atlas是一个位于前端应用与后端MySQL数据库之间的中间件,
它使得应用程序员无需再关心读写分离、分表等与MySQL相关的细节,可以专注于编写业务逻辑,
同时使得DBA的运维工作对前端应用透明,上下线DB前端应用无感知。
Atlas安装配置
下载地址:https://github.com/Qihoo360/Atlas/releases 注意:
、Atlas只能安装运行在64位的系统上
、Centos .X安装 Atlas-XX.el5.x86_64.rpm,Centos .X安装Atlas-XX.el6.x86_64.rpm。
、后端mysql版本应大于5.,建议使用Mysql .6以上
安装在了10.0.0.53
安装和配置
、安装软件
rpm -ivh Atlas-2.2..el6.x86_64.rpm 、修改配置
cd /usr/local/mysql-proxy/ vim /usr/local/mysql-proxy/conf/test.cnf # 原本的文件里面有中文的注释,解释每一行的作用
[mysql-proxy]
admin-username = user
admin-password = pwd
proxy-backend-addresses = 10.0.0.55:3306 主库 写操作 vip
proxy-read-only-backend-addresses = 10.0.0.52:,10.0.0.53:3306 按照环境修改从库地址
pwds = repl:3yb5jEku5h4=,mha:O2jBXONX098= 后端数据库账号和密码,需要提前规划好用户和权限
daemon = true
keepalive = true
event-threads =
log-level = message
log-path = /usr/local/mysql-proxy/log
sql-log=ON
proxy-address = 0.0.0.0:33060 允许所有地址,通过端口33060 链接atlas
admin-address = 0.0.0.0:2345 管理atlas的地址
charset=utf8 /usr/local/mysql-proxy/bin/encrypt ---->制作加密密码的命令 、启动atlas
/usr/local/mysql-proxy/bin/mysql-proxyd test start
ps -ef |grep proxy
----------------------
netstat -lntup | grep proxy 看是否两个端口号都生成了
ps -ef |grep proxy 看应用是否起来
、测试
测试读写分离: 读的测试
mysql -uroot -p123 -h10.0.0. -P33060
show variables like 'server_id';可以看到在两个从指间切换 写操作测试:
设置两个从节点只读
set global read_only=; 临时设置为只读库 连接测试
mysql -umha -pmha -h10.0.0. -P33060
create database db1;
Atlas配置文件说明
Atlas基本管理
连接管理接口:
mysql -uuser -ppwd -h127.0.0. -P2345
打印帮助:
mysql> select * from help;查看到所有管理命令
动态添加删除节点:
REMOVE BACKEND ;
添加节点:
ADD SLAVE 10.0.0.53:;
在线改配置,使重启后依然生效
SAVE CONFIG;
atlas自动分表功能
数据条数达到800万后,索引的层次会很深,影响性能
school.stu 1000w
id name
实现拆分
stu_0 stu_1 stu_2 stu_3 stu_4 以上分表方式,存数据非常均匀,取数据不均与,因为要考虑业务需求
如果业务查询热点数据集中在id是1-200w这些数据,那么读取就不均匀
取模分表
n/ 取余数 (,,,,)
()如果是 则分到 stu_0
()如果是 则分到 stu_1
()如果是 则分到 stu_2
()如果是 则分到 stu_3
()如果是 则分到 stu_4 取余数
-------------------------------------
配置文件
vim /usr/local/mysql-proxy/conf/test.cnf
加入
tables = school.stu.id. (主库)手工创建,分表后的库和表,分别为定义的school 和 stu_0 stu_1 stu_2 stu_3 stu_4
mysql -umha -pmha h10.0.0.53 -P33060
create database school;
use school
create table stu_0 (id int,name varchar());
create table stu_1 (id int,name varchar());
create table stu_2 (id int,name varchar());
create table stu_3 (id int,name varchar());
create table stu_4 (id int,name varchar());
重启atlas
测试:
insert into stu values (,'wang5');
insert into stu values (,'li4');
insert into stu values (,'zhang3');
insert into stu values (,'m6');
insert into stu values (,'zou7'); commit; 查询的时候,必须加上where条件,不能做范围查询,只能做等值查询
扩展功能介绍
读写分离
Atlas会透明的将事务语句和写语句发送至主库执行,读语句发送至从库执行。具体以下语句会在主库执行
显式事务中的语句
autocommit=0时的所有语句
含有select GET_LOCK()的语句
除SELECT、SET、USE、SHOW、DESC、EXPLAIN外的 从库负载均衡
proxy-read-only-backend-addresses=ip1:port1@权重,ip2:port2@权重 自动分表(已详细配置过)
使用Atlas的分表功能时,首先需要在配置文件test.cnf设置tables参数。
tables参数设置格式:数据库名.表名.分表字段.子表数量,
比如:
你的数据库名叫school,表名叫stu,分表字段叫id,总共分为2张表,
那么就写为school.stu.id.,如果还有其他的分表,以逗号分隔即可。
用户需要手动建立2张子表(stu_0,stu_1,注意子表序号是从0开始的)。
所有的子表必须在DB的同一个database里。
当通过Atlas执行(SELECT、DELETE、UPDATE、INSERT、REPLACE)操作时,
Atlas会根据分表结果(id%=k),定位到相应的子表(stu_k)。例如,执行select * from stu where id=;,
Atlas会自动从stu_1这张子表返回查询结果。但如果执行SQL语句(select * from stu;)时不带上id,则会提示执行stu 表不存在。
Atlas暂不支持自动建表和跨库分表的功能。
Atlas目前支持分表的语句有SELECT、DELETE、UPDATE、INSERT、REPLACE。
IP过滤:client-ips
该参数用来实现IP过滤功能。
在传统的开发模式中,应用程序直接连接DB,因此DB会对部署应用的机器(比如web服务器)的IP作访问授权。
在引入中间层后,因为连接DB的是Atlas,所以DB改为对部署Atlas的机器的IP作访问授权,
如果任意一台客户端都可以连接Atlas,就会带来潜在的风险。
client-ips参数用来控制连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔写在一行上即可。
如:
client-ips=192.168.1.2, 192.168.,
这就代表192.168.1.2这个IP和192.168.2.*这个段的IP可以连接Atlas,其他IP均不能连接。
如果该参数不设置,则任意IP均可连接Atlas。
如果设置了client-ips参数,且Atlas前面挂有LVS,则必须设置lvs-ips参数,否则可以不设置lvs-ips。 SQL语句黑白名单
Atlas会屏蔽不带where条件的delete和update操作,以及sleep函数。
Atlas-Sharding版本介绍
Sharding的基本思想就是把一个数据表中的数据切分成多个部分, 存放到不同的主机上去(切分的策略有多种),
从而缓解单台机器的性能跟容量的问题. sharding是一种水平切分, 适用于单表数据庞大的情景.
目前atlas支持静态的sharding方案, 暂时不支持数据的自动迁移以及数据组的动态加入.
Atlas以表为单位sharding, 同一个数据库内可以同时共有sharding的表和不sharding的表,
不sharding的表数据存在未sharding的数据库组中.
目前Atlas sharding支持insert, delete, select, update语句, 只支持不跨shard的事务.
所有的写操作如insert, delete, update只能一次命中一个组,
否则会报"ERROR 1105 (HY000):write operation is only allow to one dbgroup!"错误.
由于sharding取替了Atlas的分表功能, 所以在Sharding分支里面, Atlas单机分表的功能已经移除, 配置tables将不会再有效.
Atlas-Sharding架构*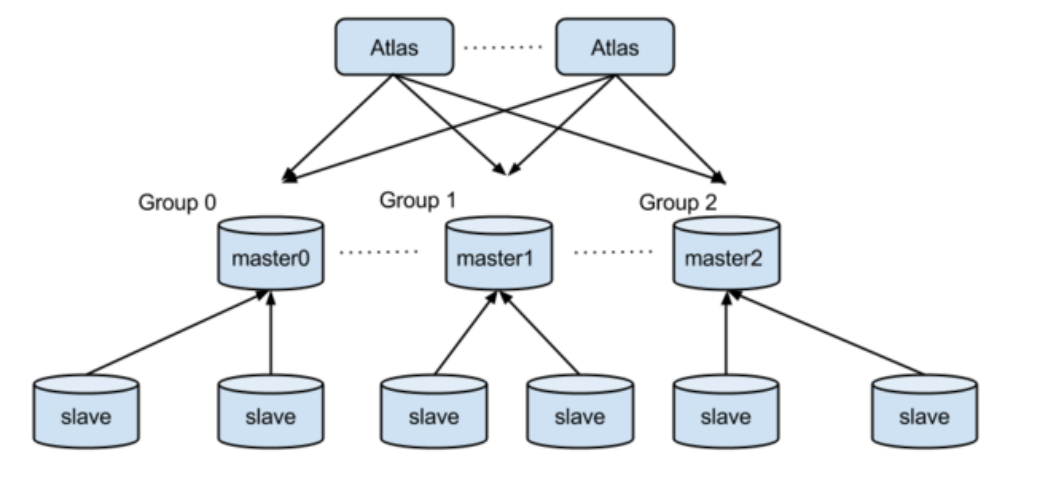
配置示例
Atlas支持非sharding跟sharding的表共存在同一个Atlas中, 2.2.1之前的配置可以直接运行. 之前的配置如
proxy-backend-addresses = 192.168.0.12:
proxy-read-only-backend-addresses = 192.168.0.13:,192.168.0.14: ...
这配置了一个master和两个slave, 这属于非sharding的组, 所有非sharding的表跟语句都会发往这个组内.
所以之前没有Sharding的Atlas的表可以无缝的在新版上使用, 注意: 非Sharding的组只能配置一个, 而sharding的组可以配置多个. 下面的配置, 配置了Sharding的组, 注意与上面的配置区分
[shardrule-]
table = test.sharding_test
#分表名,有数据库+表名组成
type = range
#sharding类型:range 或 hash
shard-key = id
#sharding 字段
groups = :-,:-
#分片的group,如果是range类型的sharding,则groups的格式是:group_id:id范围。
如果是hash类型的sharding,则groups的格式是:group_id。例如groups = ,
[group-]
proxy-backend-addresses=192.168.0.15:
proxy-read-only-backend-addresses=192.168.0.16:
[group-]
proxy-backend-addresses=192.168.0.17:
proxy-read-only-backend-addresses=192.168.0.18:
Sharding测试案例*
创建测试表:
DROP TABLE IF EXISTS `sharding_test`;
CREATE TABLE `sharding_test` ( `id` int() NOT NULL AUTO_INCREMENT, `name` char()
COLLATE utf8_bin NOT NULL, `age` int() DEFAULT NULL, `birthday` date DEFAULT NULL,
`nickname` char() COLLATE utf8_bin DEFAULT NULL, PRIMARY KEY (`id`) ) mysql -h127.0.0. –P33060 -uroot -pmysqltest –c
mysql> use test;
mysql> insert into sharding_test(id, name, age) values(, 'test', );
mysql> insert into sharding_test(id, name, age) values(, 'test', ), (, 'test', );
注意:
以上几条数据都插入到了dbgroup0,
请注意第二条多值插入的语句, 因为50和999都命中了dbgroup0, 所以其执行成功, 但是如果执行以下的语句:
mysql> insert into sharding_test(id, name, age) values(, 'test', ), (, 'test', );
ERROR (HY000): Proxy Warning - write operation is only allow to one dbgroup! 在sharding的表中, 这是不允许的, 因为id为100命中了dbgroup0, 而id为1500 命中了dbgroup1,
由于分布式的多值插入可能导致部分成功, 需要回滚, 这个Atlas暂不支持. update, delete, replace同理.
测试完成分别登陆两个主库进行查看数据。
sharding限制
关于支持的语句
Atlas sharding只对sql语句提供有限的支持, 目前支持基本的Select, insert/replace, delete, update语句,
支持全部的Where语法(SQL-92标准), 不支持DDL(create drop alter)以及一些管理语句,
DDL请直连MYSQL执行, 请只在Atlas上执行Select, insert, delete, update(CRUD)语句.
对于以下语句, 如果语句命中了多台dbgroup, Atlas均未做支持(如果语句只命中了一个dbgroup,
如select count(*) from test where id < , 其中dbgroup0范围是0 - , 那么这些特性都是支持的)
Limit Offset(支持Limit)
Order by
Group by
Join
ON
Count, Max, Min等函数 增加节点
注意: 暂时只支持range方式的节点扩展, hash方式由于需要数据迁移, 暂时未做支持.
扩展节点在保证原来节点的范围不改变的情况下, 如已有dbgroup0为范围0 - , dbgroup1为范围 - ,
这个时候可以增加范围>2000的节点. 如增加一个节点为2000 - , 修改配置文件, 重启Atlas即可.
15、MySQL优化
优化哲学

- 优化不总是对一个单纯的环境进行!还很可能是一个复杂的已投产的系统。
- 优化手段本来就有很大的风险,只不过你没能力意识到和预见到!
- 任何的技术可以解决一个问题,但必然存在带来一个问题的风险!
- 对于优化来说解决问题而带来的问题控制在可接受的范围内才是有成果。
- 保持现状或出现更差的情况都是失败!
- 稳定性和业务可持续性通常比性能更重要!
- 优化不可避免涉及到变更,变更就有风险!不要随意变更生产中的软件参数!
- 优化使性能变好,维持和变差是等概率事件!
- 优化不能只是数据库管理员担当风险,但会所有的人分享优化成果!
- 所以优化工作是由业务需要驱使的!!!
谁参与优化
- 数据库管理员
- 业务部门代表
- 应用程序架构师
- 应用程序设计人员
- 应用程序开发人员
- 硬件及系统管理员
- 存储管理员
优化方向
- 安全优化(业务持续性)
- 性能优化(业务高效性)
优化范围
存储、主机和操作系统:
主机架构稳定性
I/O规划及配置
Swap
OS内核参数和网络问题
应用程序:
应用程序稳定性
SQL语句性能
串行访问资源
性能欠佳会话管理
数据库优化:
内存
数据库结构(物理&逻辑)
实例配置
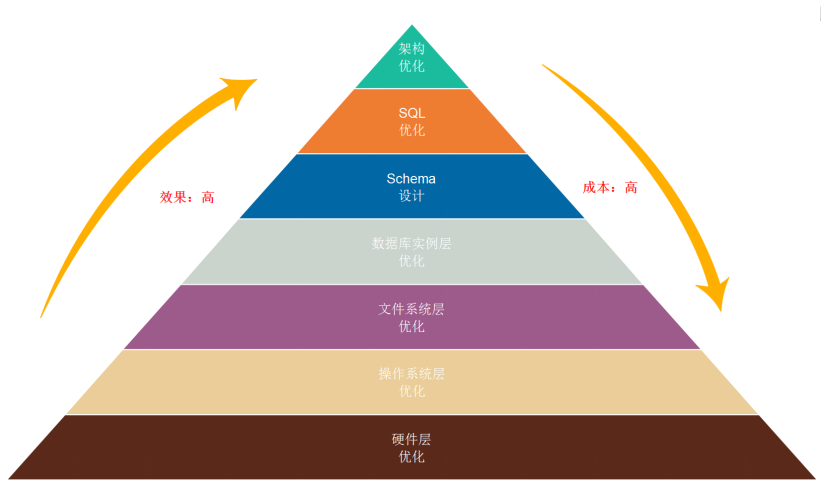
优化成本:由上往下依次增高
优化效果:由下往上依次增高
由以上图示可以看出,我们如果想要深度优化MySQL数据库,需要做的事情不是单方面的,而是要从成本及优化
效果选择最适合当前企业需求的方案。所以本课程针对整个出发点,会从各个维度来让MySQL在运行过程中达到最优的
状态。
优化工具
操作系统
top,
iostat 、
vmstat、
nmon、
dstata
数据库
基础优化命令工具
mysql
SHOW [SESSION | GLOBAL] STATUS
SHOW ENGINE INNODB STATUS
SHOW PROCESSLIST
show index
Information Schema
mysqldumpslow
explain
msyqladmin
mysqlshow
深度优化命令工具(扩展)
mysqlslap
sysbench
mysql profiling
Performance Schema
优化思路
思路:
定位问题:
硬件
系统
应用
数据库
架构(高可用、读写分离、分库分表)
处理问题
明确优化目标
性能和安全的折中
防患未然
工具详细介绍
、系统优化工具
1.1 top
[root@Dao ~]# top
top - 23:52:39 up 14:39, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 67 total, 1 running, 66 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0
KiB Mem : 1014892 total, 668044 free, 62020 used, 284828 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 800696 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3284 root 10 -10 125300 11640 9116 S 0.3 1.1 2:40.03 AliYunDun
()简介:
实时监控当前操作系统的负载情况的,每秒刷新一次状态,通常会关注三大指标(CPU、MEM、IO) ()评判标准
(2.1) 整体的负载情况,判断标准,如果值非常高,只能告诉我们操作系统很繁忙
load average: 0.00, 0.00, 0.00
(2.2)CPU使用情况
Cpu(s): 0.2%us, 0.2%sy, 99.7%id, 0.0%wa
%id: CPU空闲的百分比
问一个问题?你觉得在一个已投产的系统中ID值是高好还是低好呢?
一般情况下我们建议,%以下都算是正常的,但是呢,我们去准备硬件的时候,一般都会预留一部分(3年)
硬件配置
%us:用户程序,占用的CPU时间片的百分比。我们认为us%高是好事,但要在cpu正常能力范围内。
%sy:系统程序(和内核工作有关),资源调配,资源管理,内核其他功能的管理(system call)
对于比较成熟的操作系统,对sy%应该是占比很少的。我们认为越少越好。
如果飙升,可能说明两件事情,,系统bug;,中病毒了
%wa 这个参数越少越好。如果wait高说明了,
,IO很慢(速度慢,全表扫描)
、内存满了OOM(内存小,全表扫描) (2.3)
Mem: 4040596k total, 1692536k used, 2348060k free, 152348k buffers
Swap: 786428k total, 0k used, 786428k free, 620256k cached Mem:
total:总的内存量
used:已经被使用的内存量
free:空闲的内存空间
buffer:专门负责操作系统当中,与文件修改类操作有关的内存缓冲区(专门负责写操作的),
可以被重复利用的内存区域
cached:专门负责操作系统当中,与文件读取有关的缓存区域(专门负责文件读取操作的),
对于操作系统可用内存量=free+buffer+cached
used:used=RSS+anon+buffer+cached 补充:
.Linux操作系统内存划分的三大区域:
RSS:常驻内存集,主要负责程序运行需要的内存区域
Page Cache:页缓存,文件系统缓存(FS cache),主要负责文件有关的缓冲和缓存,buffer+cached
anon page: 匿名页,主要负责程序之间交互时使用到内存区域 .连续的地址位,定义为了page(页),并且进行了量化。
()基于固定大小page分配模式,他的一些不足的地方?
在申请内存时,需要整个内存进行遍历
会有大量的内存碎片,导致程序OOM(out of memory)
()SLAB Allocator内存管理子系统
、将内存逻辑化成chain+chunk模式,内存区域会有多条链。
每条chain下都“挂着”多个等同大小的chunk(2的幂)
、在每条链的头部,都会有一个专门的chunk位图,来更快速的找到需要的空闲chunk,
并且记录每个chunk最后被访问的时间戳。
()buddy system(伙伴系统)
、提供了多种内存实现回收和整理内存碎片算法,最经典的就是LRU算法。
、当内存free空间紧张时,会触发进行整理或释放,不再使用buffer和cached
通过以下命令,手工释放所有buffer和cached
echo > /proc/sys/vm/drop_caches SWAP:交换分区,当内存紧张的时候,会将内存区域当中的数据临时置换到SWAP中。
默认:在内存使用量达到60%
[root@db02 ~]# cat /proc/sys/vm/swappiness 控制参数
60
主要交换有哪些
buffer 中为修改完成的,RSS,anon_page
对于MySQL环境,要尽量避免swap使用
sysctl.conf swappiness=0
临时修改:
[root@db02 ~]# echo >/proc/sys/vm/swappiness 、iostat
测试当前环境IO水平
[root@Dao ~]# iostat 1 10 # 每1秒显示一次,共显示10次
[root@Dao ~]# iostat -dk 1 5 # 以KB为单位,每1秒显示一次,显示5次
mount /dev/sdb /data
iostat -dm /dev/sdb # 以MB为单位,每1s显示一次sdb的情况 ,不停
dd if=/dev/zero of=/data/bigfile 一直写文件 在优化过程中,我们一般会结合CPU和内存的使用情况看IO状态
CPU非常繁忙(MYSQL):
、user 很高
再看IO水平,正常情况下IO也会很高
不正常的情况,user很高,但是IO很低?
在做大量的计算(多表连接查询、排序、分组、子查询很复杂或者很频繁)
、wait 很高
IO很少
()很有可能是全表扫描
()IO有问题(RAID规划或者磁盘IO本身问题)
、vmstat
用法和iostat类似,是一个综合判断的命令
vmstat
[root@Dao ~]# vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 531816 45680 375384 0 0 1 2 90 105 0 0 100 0 0
0 0 0 531792 45680 375384 0 0 0 0 102 258 0 0 100 0 0
0 0 0 531792 45680 375384 0 0 0 0 97 250 0 0 100 0 0
0 0 0 531792 45680 375384 0 0 0 0 100 255 0 0 100 0 0
0 0 0 531792 45680 375384 0 0 0 0 101 253 0 1 99 0 、dstat
需要单独安装 yum install dstat -y
也是一个综合命令,直接使用,比较人性化,自动设置显示的单位,还是彩色的,换页自动显示表头,很cool
显示了cpu、磁盘、网络IO、swap(paging space)、系统相关 、数据库层面优化工具
基础优化命令工具
()mysql
用法举例:
mysql -uroot -p123 -e "show status like '%lock%'"
()SHOW ENGINE INNODB STATUS
mysql> show engine innodb status\G
一般关注比较多的:
内存、线程、锁相关
()show index from table 查看索引情况
()Information Schema 可以直接使用show命令查看里面的内容
()mysql库下的 innodb_table_stats innodb_index_stats
desc innodb_table_stats 看表的使用情况
select * from innodb_table_stats;
select * from innodb_index_stats; 索引的使用情况和跟新状态
() 用的最多的SHOW [SESSION | GLOBAL] STATUS
() SHOW [FULL] PROCESSLIST(应急调优)
() explain 查看执行计划
() mysqldumpslow (pt-query-diagest) 分析慢日志 深度优化命令工具(扩展)
mysqlslap
sysbench
tpcc
以上三个都是压力测试工具
Performance Schema(.7默认开启)-可以重点关注,用于定位数据库问题
-----------------------------------------
企业基础优化实战(压力测试例子)
硬件优化
硬件优化:
主机:
根据数据库类型,主机CPU选择、内存容量选择、磁盘选择
平衡内存和磁盘资源
随机的I/O和顺序的I/O
主机 RAID卡的BBU(Battery Backup Unit)关闭
存储:
根据存储数据种类的不同,选择不同的存储设备
配置合理的RAID级别(raid5、raid10、热备盘)
网络设备:
使用流量支持更高的网络设备(交换机、路由器、网线、网卡、HBA卡)
注意:这些规划应该在初始设计系统时就应该 考虑
--------------------------------------------------------
详细说明
主机:
根据数据库类型
(1)主机CPU选择
IO密集型:可以处理多并发的CPU类型,特点是核心数量较多,主频中等
Intel E系列
CPU密集型:可以处理高性能计算的cpu类型,主频非常高,核心数量中等
Intel I系列的
MySQL的线上业务,处理高并发访问的业务。属于IO密集型的业务,所以选择志强系列的CPU更好一些。
MySQL非线上的业务,数据处理数据分析,算法计算,属于CPU密集型业务,所以选择I系列的CPU。 (2)内存容量选择
一般是选择cpu核心数量的2倍 (3)IO的选择
1、磁盘选择
SATAIII SAS FC SSD pci-e SSD Flash
主机 RAID卡的BBU(Battery Backup Unit)关闭
存储(有条件的公司会选择单独存储设备):
根据存储数据种类的不同,选择不同的存储设备
配置合理的RAID级别(raid5、raid10、热备盘)
raid0 :性能高(条带化),安全性和单盘一样
raid1 :安全性高(条带化功能),性能和单盘一样
raid10 :读写性能都很高(0级别条带化功能),安全性高(1级别,镜像功能),企业如果有条件推荐的一种raid级别
raid5 :较好的安全性(校验),较好的性能(条带化功能,读性能比较高,写性能一般),
对于读多写少的业务可以使用此级别 高端存储:IBM EMC HDS,一般都是raid1(就是raid10) ,自带条带化功能,而且只支持4块盘做一个raid 使用合适raid级别,避免过度条带化 ,条带化增加了IO次数(相同量的数据)
IOPS峰值:对于每一块硬件磁盘来讲,都有一个固定参数IOPS,每秒最多能够进行的IO的次数。 网络设备:
使用流量支持更高的网络设备(交换机、路由器、网线、网卡、HBA卡)
网卡绑定:解决网络传输的可靠性,
bonding 0(负载均衡模式) 1(主备模式)
添加备用网卡,交换机,预防线路故障
交换机:堆叠 0模式的绑定,要进行交换机的之间的绑定(链接成类似一台的状态),如果不做,会发生丢包
系统优化
系统优化
Cpu:
基本不需要调整,在硬件选择方面下功夫即可。
内存:
基本不需要调整,在硬件选择方面下功夫即可。
SWAP:
MySQL尽量避免使用swap。
IO :
raid
no lvm
ext4或xfs
ssd
IO调度策略
--------------------------------------------------------
详细说明
系统层面优化:
1、Swap调整
/proc/sys/vm/swappiness的内容改成0(临时)
echo 0>/proc/sys/vm/swappiness /etc/sysctl.conf上添加vm.swappiness=0(永久)
vim /etc/sysctl.conf
vm.swappiness=0
sysctl -p 这个参数决定了Linux是倾向于使用swap,还是倾向于释放文件系统cache。
在内存紧张的情况下,数值越低越倾向于释放文件系统cache。
当然,这个参数只能减少使用swap的概率,并不能避免Linux使用swap。
注: 修改MySQL的的配置参数innodb_flush_method,并开启O_DIRECT模式。
这种情况下,IonnDB的buffer pool会直接绕过cache来访问磁盘,
但是redo log依旧会使用文件系统的cache。
值得注意的是,Redo log是覆写模式,即使使用了文件系统的cache,也不会占用太多 2、IO调度策略
临时修改:
[root@db02 ~]# cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq] 修改前是cfq(先进先出)
[root@db02 ~]# cat /sys/block/sdb/queue/scheduler
noop anticipatory deadline [cfq]
[root@db02 ~]# echo deadline >/sys/block/sda/queue/scheduler
[root@db02 ~]# echo deadline >/sys/block/sdb/queue/scheduler
[root@db02 ~]# cat /sys/block/sdb/queue/scheduler
noop anticipatory [deadline] cfq 修改后(mysql比较适合dedline)
[root@db02 ~]#
永久修改:
vim /boot/grub.conf 在文件的下面内容中加入参数elevator=deadline,重启后生效
kernel /vmlinuz-2.6.32-696.el6.x86_64 ro root=UUID=40c9133f-6007-485c-be19-4082c8361df3 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8
rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM elevator=deadline rhgb quiet 3、FS:
NO LVM 尽量不要使用LVM
ext4或xfs 文件系统的选择
ssd(binlog relay可能单独存放在ssd上) 4、关闭无用服务
chkconfig --level 23456 acpid off
chkconfig --level 23456 anacron off
chkconfig --level 23456 autofs off
chkconfig --level 23456 avahi-daemon off
chkconfig --level 23456 bluetooth off
chkconfig --level 23456 cups off
chkconfig --level 23456 firstboot off
chkconfig --level 23456 haldaemon off
chkconfig --level 23456 hplip off
chkconfig --level 23456 ip6tables off
chkconfig --level 23456 iptables off
chkconfig --level 23456 isdn off
chkconfig --level 23456 pcscd off
chkconfig --level 23456 sendmail off
chkconfig --level 23456 yum-updatesd off
Linux系统内核参数优化
vm.swappiness=
用户限制参数
/etc/security/limits.conf
* soft nproc
* hard nproc
* soft nofile
* hard nofile
应用优化
业务应用和数据库应用独立
防火墙:iptables selinux
其他(关闭无用服务):
chkconfig --level acpid off
chkconfig --level anacron off
chkconfig --level autofs off
chkconfig --level avahi-daemon off
chkconfig --level bluetooth off
chkconfig --level cups off
chkconfig --level firstboot off
chkconfig --level haldaemon off
chkconfig --level hplip off
chkconfig --level ip6tables off
chkconfig --level iptables off
chkconfig --level isdn off
chkconfig --level pcscd off
chkconfig --level sendmail off
chkconfig --level yum-updatesd off 另外,思考将来我们的业务是否真的需要MySQL,还是使用其他种类的数据库。
以上:硬件优化建议,操作系统优化建议,应该在业务架构搭建初始应该做好。
数据库优化
数据库层面优化:
4.1 参数优化(见参数优化建议.txt)
4.2 数据库索引优化(见索引管理章节)
4.3 锁优化
4.4 数据库架构优化(扩展) 参数调整:
实例整体(高级优化,扩展):
thread_concurrency 并发线程数量个数
sort_buffer_size 排序缓存
read_buffer_size 顺序读取缓存
read_rnd_buffer_size 随机读取缓存
key_buffer_size 索引缓存
thread_cache_size (1G —> , 2G —> , 3G —> , >3G —> )
连接层(基础优化)
设置合理的连接客户和连接方式
max_connections 最大连接数
max_connect_errors 最大错误连接数
connect_timeout 连接超时
max_user_connections 最大用户连接数
skip-name-resolve 跳过域名解析
wait_timeout 等待超时
back_log 可以在堆栈中的连接数量
SQL层(基础优化)
query_cache_size 查询缓存
存储引擎层(innodb基础优化参数)
default-storage-engine
innodb_buffer_pool_size
innodb_file_per_table=(,)
innodb_flush_log_at_trx_commit=(,,)
Innodb_flush_method=(O_DIRECT, fdatasync)
innodb_log_buffer_size
innodb_log_file_size
innodb_log_files_in_group
innodb_max_dirty_pages_pct
log_bin
max_binlog_cache_size
max_binlog_size
innodb_additional_mem_pool_size(于2G内存的机器,推荐值是20M。32G内存的 100M)
transaction_isolation
SQL优化:
执行计划(基础优化)
索引(基础优化)
SQL改写(高级优化)
架构优化(高级优化扩展):
高可用架构
高性能架构
分库分表
-----------------------------------------------
锁优化-减少死锁和处理死锁
锁优化
MyIASM: 表级锁
优点:申请和释放时,需要更少系统资源,减少死锁产生。
缺点:不利于并发处理,在某个事务在对表进行修改操作时,会锁定整个表,其他事务只能等待完成之后,才能操作。
有非常严重的锁等待。 InnoDB:
支持行级锁,行级锁在索引锁。如果表中没有任何索引,那么我们做表数据处理的时候,依然会表级锁。
GAP锁:主要针对范围数据操作时 死锁的处理过程:
、show processlist
、show engine innodb status\G;
LOCK WAIT lock struct(s), heap size , row lock(s)
MySQL thread id , OS thread handle 0x7f37d66f0700, query id localhost root Sending data
select * from t1 where id= for update
Trx read view will not see trx with id >= , sees <
------- TRX HAS BEEN WAITING SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id page no n bits index `GEN_CLUST_INDEX` of table `test`.`t1` trx id lock_mode X waiting
Record lock, heap no PHYSICAL RECORD: n_fields ; compact format; info bits 、kill ; 避免死锁的方法:
()将index lock 转换为table lock
set autocommit=;
lock table t1;
insert to
update
delete
commit
unlock table t1;
()将所有事务处理表数据的顺序尽量保证一致。
作业
1、搭建MHA+Atlas高可用读写分离架构
要求: 画出实验拓扑图,标准清楚IP/hostname/作用
(1)实现1主2从GTID主从复制环境
(2)构建MHA高可用环境
(3)模拟损坏主库,并实现修复
(4)实现应用透明(VIP)
(5)实现外部数据补偿(binlog server)
(6)基于MHA环境实现Atlas读写分离
(7)在线增加删除节点管理Atlas
Linux云计算运维-MySQL的更多相关文章
- 零基础转行Linux云计算运维工程师获得20万年薪的超级学习技巧
云计算概念一旦产生便一发不可收拾,成为移动互联网时代最为火热的行业之一.国内各大互联网公司例如阿里.腾讯.百度.网易等纷纷推出自己的云计算产品,3月10日,腾讯云0.01元投标时间更是让云计算在普罗大 ...
- Linux云计算运维-Redis
Redis简介 Redis是一款开源的,ANSI C语言编写的,高级键值(key-value)缓存和支持永久存储NoSQL数据库产品. Redis采用内存(In-Memory)数据集(DataSet) ...
- Linux 云计算运维之路
搭建中小型网站的架构图 s1-2 Linux 硬件基础 s3-4 linux 基础 文件系统 用户权限 s5-6 Linux 标准输出 系统优化 目录结构 w7 rsync-备份服务器 w8 NFS服 ...
- Linux系统运维工程该具备哪些素质
记得在上高中时,物理老师总是会对我们一句话:"学习是件苦差事."工作后发现,其实做运维也是件苦差事.最为一名运维工程师,深知这一行的艰辛,但和IT行业其他职务一样,那就是付出的越多 ...
- 线上Linux服务器运维安全策略经验分享
线上Linux服务器运维安全策略经验分享 https://mp.weixin.qq.com/s?__biz=MjM5NTU2MTQwNA==&mid=402022683&idx=1&a ...
- Linux系统运维笔记(四),CentOS 6.4安装Nginx
Linux系统运维笔记(四),CentOS 6.4安装Nginx 1,安装编译工具及库文件 yum -y install make zlib zlib-devel gcc-c++ libtool op ...
- 要成为linux网站运维工程师必须要掌握的技能
要成为linux网站运维工程师必须要掌握的技能 2015-07-27 发表 老男孩点评:感谢此文的作者,写的非常到位,值得入门的初学者认真看看 我是一名linux运维工程师,确切的说是网站运维工程师, ...
- 【微学堂】线上Linux服务器运维安全策略经验分享
技术转载:https://mp.weixin.qq.com/s?__biz=MjM5NTU2MTQwNA==&mid=402022683&idx=1&sn=6d403ab4 ...
- Linux系统运维相关的面试题 (问答题)
这里给大家整理了一些Linux系统运维相关的面试题,有些问题没有标准答案,希望要去参加Linux运维面试的朋友,可以先思考下这些问题. 一.Linux操作系统知识 1.常见的Linux发行版本都有 ...
随机推荐
- 一文让你明白Redis主从同步
今天想和大家分享有关 Redis 主从同步(也称「复制」)的内容. 我们知道,当有多台 Redis 服务器时,肯定就有一台主服务器和多台从服务器.一般来说,主服务器进行写操作,从服务器进行读操作. 那 ...
- Java数据结构和算法 - 二叉树
前言 数据结构可划分为线性结构.树型结构和图型结构三大类.前面几篇讨论了数组.栈和队列.链表都是线性结构.树型结构中每个结点只允许有一个直接前驱结点,但允许有一个以上直接后驱结点.树型结构有树和二叉树 ...
- oracle和mysql批量合并对比
orm框架采用mybatis,本博客介绍一下批量合并merge用oracle和mysql来做的区别, oracle merge合并更新函数的详细介绍可以参考我以前的博客:https://blog.cs ...
- RecyclerView实现一个页面有多种item,每个item有多个view,并且可以让任意item的任意view自定义监听,通过接口方法进行触发操作
百度了很多贴子,看着大佬的博客,模仿尝试,最终都是以失败告终,api可能版本不一样, 毕竟博客大佬都是7~8前写的,日期新点的都是好几年前了,多次尝试,还是报出莫名其妙的错. 哎,忧伤. 翻阅各种资料 ...
- 从壹开始微服务 [ DDD ] 之三 ║ 简单说说:领域、子域、限界上下文
前言 哈喽大家好,DDD领域驱动设计系列又开始了,前天周二的那篇入门文章中,也收到了一定的效果(写小说的除外),同时我也是倍感鸭梨,怎么说呢,DDD领域驱动设计已经有十年历史了,甚至更久,但是包括我在 ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Maven常用命令:
Maven库: http://repo2.maven.org/maven2/ Maven依赖查询: http://mvnrepository.com/ 一,Maven常用命令: 1. 创建Maven的 ...
- RabbitMQ在Windows环境下的安装与使用
Windows下安装RabbitMQ 环境配置 部署环境 部署环境:windows server 2008 r2 enterprise 官方安装部署文档:http://www.rabbitmq.com ...
- cocos creator主程入门教程(九)—— 瓦片地图
五邑隐侠,本名关健昌,10年游戏生涯,现隐居五邑.本系列文章以TypeScript为介绍语言. 这一篇介绍瓦片地图,在开发模拟经营类游戏.SLG类游戏.RPG游戏,都会使用到瓦片地图.瓦片地图地面是通 ...