基于 HTTP 请求拦截,快速解决跨域和代理 Mock
近几年,随着 Web 开发逐渐成熟,前后端分离的架构设计越来越被众多开发者认可,使得前端和后端可以专注各自的职能,降低沟通成本,提高开发效率。
在前后端分离的开发模式下,前端和后端工程师得以并行工作。当遇到前端界面展示需要的数据,而后端对应的接口还没有完成开发的情况时,需要一个数据源来保证前端工作的顺利进行。
今天这篇文章,我们会介绍几种常见的方法和其中存在的问题,并提出如何基于HTTP 请求拦截,快速解决跨域和代理 mock 问题的方案。
常见方法及问题
请求 mock 服务器
最常规的做法是维护一个提供静态数据的 mock 服务器(它提供的数据称为 mock 数据),前端请求 mock 服务器获取数据即可,但这种静态数据维护不便。
请求 AMP
更好的做法是有一个根据接口定义来自动生成数据的 mock 服务器,我们称为AMP(接口管理平台,API Manage Platform),前端请求该服务器获取数据。
在这种场景下,如果有些接口已经完成开发,前端需要手动修改代码去设置不同接口的请求地址。当接口数量较多时,这种方法会变得非常低效。因此, AMP 一般也会同时提供代理功能,也就是指前端仍请求 AMP,AMP 会根据接口完成情况来决定返回 mock 数据,还是将请求再次代理到真实的业务服务器获取数据后返回。
但是这种方案的问题在于当涉及到需要角色权限验证的接口时,登录输入用户信息后在浏览器中会缓存 cookie,当访问与登录时同域名的接口时,浏览器会自动携带 cookie,由服务器解析 cookie 并鉴权后获取对应权限的接口数据。前端一般是在本地启动服务器进行开发,当业务服务器的接口完成开发,这时再采用请求 AMP 的方法切换接口数据,就会出现跨域的情况。
由于浏览器的安全机制决定跨域访问时无法携带 cookie,并且无法通过代码读取 cookie,因此通过代码传递 cookie 跨域不可行,而现有的解决方案也不完美:
如果在 AMP 额外增加模拟登陆的功能,会因为所有接口的权限固定不变,无法适配一个接口对不同角色有不同权限而返回相应的数据;而且一旦鉴权的接口功能变更、失效等情况发生,都需要重写修改 AMP 的代理功能,代价较大。
如果利用浏览器插件保存登陆信息、提供代理,则需要兼容不同浏览器,成本太高。
针对上述技术问题,本文提出了一种可跨浏览器,并在前端实现的不侵入业务代码的代理方法。
基于 HTTP 请求拦截
实现前端接口代理
基于 HTTP 请求拦截实现前端接口的方式,从更底层的角度实现了接口开发完成前后的 mock 数据,及业务服务器真实数据之间的切换,并且解决了现有技术中由 HTTP 请求通过 AMP 代理到业务服务器产生跨域无法携带权限信息,导致无法按照角色权限返回请求数据的技术问题。
主要创新点
在更底层基于 XMLHttpRequest 和 Fetch API 实现拦截代理,不需要考虑主流浏览器类型,和 JavaScript 依赖的工具库;
在前端实现代理,保留了登陆信息,无需额外处理鉴权问题;
提供一种可以快速实现且可插拔的使用方式。
总的来说,这个方案提供了一种可快速实现,运行在前端浏览器中,且不依赖浏览器类型的请求代理方法。
设计思路
Web 前端开发一般使用 JavaScript 语言,浏览器环境的 HTTP 请求都是基于 Fetch API 或 XMLHttpRequest API 来实现的(基于前者的请求记做 xhr,后者记做 fetch),主流的 Javascript 开源工具库如 Axios、Request 也是这样。所以,我们的方案就是要通过在底层拦截 xhr 或 fetch,根据一定的判断逻辑来实现前端代理功能。
实现方式
首先,重新封装浏览器环境中原生的 XMLHttpRequest API 和 Fetch API。基本思路是将这两个原生的 API 保存起来,添加到各自重新封装的同名 API 中(记作新 API),为新 API 写入与原生 API 中同名的方法和属性,在携带请求参数的同名方法(比如下文中的 open 和 send)里加入拦截请求和代理的逻辑 ApiProxy,对外开放一个可配置该拦截逻辑的接口,用于配置针对不同的 HTTP 请求格式所请求数据的拦截和代理逻辑。

图1:代理与AMP和终端业务的交互流程
ApiProxy 在这个过程中的主要作用和工作流程可以归纳为:
注册拦截器。接收并拦截 HTTP 请求,解析该请求中的参数,这里的参数是指能在 AMP 中唯一标识该接口的参数,比如域名+请求方法(如 GET、POST 等)+路径(如 https://service.com/user 中的/user)。
根据该参数生成发送 AMP 的请求。AMP 实时维护了 mock 服务器上存储的接口以及业务服务器上存储的真实接口的相关信息,包括接口的定义、域名、属性、开发状态等。
AMP 根据请求查询接口定义数据,如果接口存在且状态是开发中,则返回根据接口定义生成的 mock 数据,否则返回特定响应标志,如图 1 中的「{code:』200302』}」。
Apiproxy 收到 AMP 的响应后判断是否有特殊标志,没有直接返回 mock 数据到原请求,有则表示后端接口开发完成,继续发送原 HTTP 请求到后端服务器请求后端服务器存储的真实数据,相当于没有对原请求做任何处理。
和传统的将 HTTP 请求发送给 AMP 不同的是 ,AMP 根据接口状态判断是根据请求直接返回 mock 数据,还是开启代理将 HTTP 请求再发送给业务服务器(此时跨域访问会丢失原始 HTTP 请求中浏览器携带的 cookie),不直接将 HTTP 请求发送给 AMP,而是对请求正式发出之前进行拦截,并解析其中的参数发送给 AMP,由 AMP 反馈接口状态,若开发完成则将 HTTP 请求正式发送给业务服务器。因为没有修改该请求,只是延迟发送,这样就保持了原请求与业务服务器之间的所有鉴权等相关信息,由此解决了跨域访问无法携带 cookie 的问题。
不同请求方式下 ApiProxy 的实现
由于不同请求方式的底层设计不同,我们相应的具体封装手段也不同。
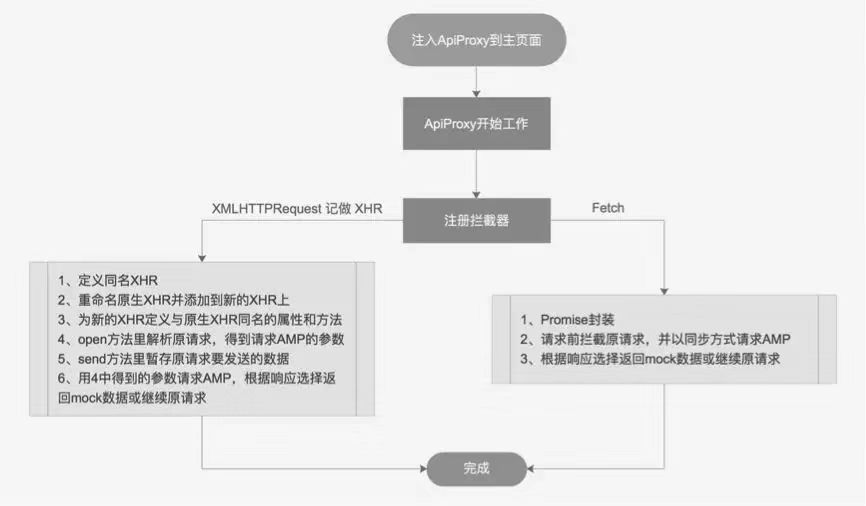
图2:代理核心工作原理
XMLHttpRequest
对于 XMLHttpRequest 请求,在其 open 方法中解析请求,访问 AMP 根据响应结果判断是否需要继续发送原请求到后台服务器,一个 xhr 只有在其 send 方法被调用时才会真正的发起 HTTP 请求,而在 open 方法中无法获取到 send 方法传递的数据,所以拦截发生在 send 方法中。首先单独存储 send 方法中发送请求时的参数,然后直接返回,确保先不调用真正的 XMLHttpRequest 的 send 方法,将单独存储的参数生成对 AMP 的请求,执行上述 AMP 中的判断。
实例
1、定义与原生 XMLHttpRequest API 同名的接口,称为新的 XHR 接口;
2、重命名原生 XMLHttpRequest API 并添加到新的 XHR 接口;
3、在新的 XHR 接口中定义与原生 XMLHttpRequest API 同名的属性和方法;
4、在同名的 open 方法中解析 HTTP 请求,得到用来在 AMP 查询接口状态的参数(比如域名+请求方法+路径);
5、拦截将要发送的原请求,在同名的 send 方法中暂存原请求要发送的数据,暂停原请求的发送;
6、用 4 中的参数请求 AMP,查询接口状态,如果接口不存在或是已完成状态,则返回特殊标志,ApiProxy 取出 5 中暂存的数据,传递给原请求,并继续原请求的发送;否则,AMP 返回 mock 数据,ApiProxy 直接将该数据返回给原请求。
Fetch API
对于 Fetch API 而言,因为它是基于 Promise 实现的,拦截比较容易,只需要在 Fetch API 外层封装一个 Promise 入口,在其发起 fetch 请求前,先暂停原请求,解析数据请求 AMP,并等待响应,判断响应是否有特殊响应码,如果有则继续原请求,否则跳过原请求,直接返回 mock 数据。
启动前端代理功能
在前端实际开发中,可以借助打包工具,比如 webpack,自定义一个可配置的插件,开启后在开发环境中自动将代理拦截代码插入到主页面里,从而启动前端代理功能。
小结
本文提出的前端代理方法通过将代理职责下沉到前端,减少了 mock 服务器(或者接口管理平台)请求真实业务服务器步骤,同时将角色权限保持在前端请求中,进一步减少了代理所需要承担的工作量,从底层拦截 HTTP 请求的方法,绕过了利用浏览器插件做代理带来的浏览器兼容的问题。最后提供的利用打包工具(如 webpack)封装这种代理方法,实现快速插拔的前端代理。
本文作者:邓仲哲,马蜂窝社区研发团队前端开发工程师,主要负责社区管理后台,接口管理平台开发等工作。
关注马蜂窝技术,找到更多你需要的内容

附:参考资料
关于跨域:
https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
关于XMLHTTPRequest:
https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest
关于Fetch:
https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API
基于 HTTP 请求拦截,快速解决跨域和代理 Mock的更多相关文章
- 前后端分离djangorestframework——解决跨域请求
跨域 什么是跨域 比如一个链接:http://www.baidu.com(端口默认是80端口), 如果再来一个链接是这样:http://api.baidu.com,这个就算是跨域了(因为域名不同) 再 ...
- 后端CORS解决跨域问题
一 . 为什么会有跨域问题 是因为浏览器的同源策略是对ajax请求进行阻拦了,但是不是所有的请求都给做跨域,像是一般的href 属性,a标签什么的都不拦截. 二 . 解决跨域的方法 解决跨域有两种方法 ...
- VUE 使用axios请求第三方接口数据跨域问题解决
VUE是基于node.js,所以解决跨域问题,设置一下反向代理即可. 我这里要调用的第三方接口地址为 http://v.juhe.cn/toutiao/index?type=top&key=1 ...
- 如何用Nginx解决跨域问题
一. 产生跨域的原因 1.浏览器限制 2.跨域 3.XHR(XMLHttpRequest)请求 二. 解决思路 解决跨域有多重,在这里主要讲用nginx解决跨域 1.JSONP 2.nginx代理 3 ...
- Nginx解决跨域问题No 'Access-Control-Allow-Origin'
使用nginx在server块下的location块下为请求添加请求头来解决跨域 add_header 'Access-Control-Allow-Origin' '*'; add_header 'A ...
- SpringBoot解决跨域请求拦截
前言 同源策略:判断是否是同源的,主要看这三点,协议,ip,端口. 同源策略就是浏览器出于网站安全性的考虑,限制不同源之间的资源相互访问的一种政策. 比如在域名https://www.baidu.co ...
- Vue使用Axios实现http请求以及解决跨域问题
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中.Axios的中文文档以及github地址如下: 中文:https://www.kancloud.cn/y ...
- Django框架深入了解_05 (Django中的缓存、Django解决跨域流程(非简单请求,简单请求)、自动生成接口文档)
一.Django中的缓存: 前戏: 在动态网站中,用户所有的请求,服务器都会去数据库中进行相应的增,删,查,改,渲染模板,执行业务逻辑,最后生成用户看到的页面. 当一个网站的用户访问量很大的时候,每一 ...
- 【手摸手,带你搭建前后端分离商城系统】02 VUE-CLI 脚手架生成基本项目,axios配置请求、解决跨域问题
[手摸手,带你搭建前后端分离商城系统]02 VUE-CLI 脚手架生成基本项目,axios配置请求.解决跨域问题. 回顾一下上一节我们学习到的内容.已经将一个 usm_admin 后台用户 表的基本增 ...
随机推荐
- 分享一下 常用的转换方法(例如:数字转金钱,文本与html互转等)
public sealed class SAFCFormater { /// <summary> /// 文本格式到HTML /// </summary> /// <pa ...
- 用一张表里的记录更新自己(或另一张表)里的记录(exists使用)
update jqhdzt set shid=(select shid from v_plat_userjqinfo t where jqhdzt.jqbh=t.JQBH and jqhdzt.shi ...
- Hession集成Spring + maven依赖通讯comm项目 + 解决@ResponseBody中文乱码
hessian结合spring的demo hessian的maven依赖: <!-- hessian --> <dependency> < ...
- 初探Margin负值(转)
相对而言,margin 负值的使用机率在布局中似乎很少,但是我相信一旦你开始掌握就会着迷,接下来我们看看关于margin负值的一些资料: 它是一个有效的属性,至少w3c中明确描述如下:”Negativ ...
- shiro 权限管理配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- 杨老师课堂_Java核心技术下之控制台模拟记事本案例
预览效果图: 背景介绍: 编写一个模拟记事本的程序通过在控制台输入指令,实现在本地新建文件打开文件和修改文件等功能. 要求在程序中: 用户输入指令1代表"新建文件",此时可以从控制 ...
- element-ui bug及解决方案
1.element-ui 使用MessageBox后弹窗显示异常 解决方案:去掉Vue.use(MessageBox); 2.element-ui 分页切换后若改变总数会导致请求两次 解决方案:< ...
- spring+jotm+ibatis+mysql实现JTA分布式事务
1 环境 1.1 软件环境 spring-framework-2.5.6.SEC01-with-dependencies.zip ibatis-2.3.4 ow2-jotm-dist-2.1.4-b ...
- sql server 高可用故障转移(上)
群集准备工作 个人电脑 内存12G,处理器 AMD A6-3650CPU主频2.6GHz 虚拟机 VMware Workstation 12 数据库 sql server 2008 r2 三台虚拟服 ...
- How to set spring boot active profiles with maven profiles
In the previous post you could read about separate Spring Boot builds for a local development machin ...