使用Markup解析xml文件
1:怎么获取Markup.cpp 和 Markup.h
首先到http://www.firstobject.com/dn_markup.htm链接下,下载Release 11.5 zip (579k)C++ source code for Linux, Mac, Windows,解压后里面是一个Test文件夹和Markup.cpp和Markup.h文件,将Markup.h和Markup .cpp拷贝并添加到工程中,第一次编译可能会出现预编译错误,解决的方法在Markup.cpp最前面include "stdafx.h",或者关闭预编译。
这是工程的大致结构
markup.h
- // Markup.h: interface for the CMarkup class.
- //
- // Markup Release 11.5
- // Copyright (C) 2011 First Objective Software, Inc. All rights reserved
- // Go to www.firstobject.com for the latest CMarkup and EDOM documentation
- // Use in commercial applications requires written permission
- // This software is provided "as is", with no warranty.
- #if !defined(_MARKUP_H_INCLUDED_)
- #define _MARKUP_H_INCLUDED_
- #include <stdlib.h>
- #include <string.h> // memcpy, memset, strcmp...
- // Major build options
- // MARKUP_WCHAR wide char (2-byte UTF-16 on Windows, 4-byte UTF-32 on Linux and OS X)
- // MARKUP_MBCS ANSI/double-byte strings on Windows
- // MARKUP_STL (default except VC++) use STL strings instead of MFC strings
- // MARKUP_SAFESTR to use string _s functions in VC++ 2005 (_MSC_VER >= 1400)
- // MARKUP_WINCONV (default for VC++) for Windows API character conversion
- // MARKUP_ICONV (default for GNU) for character conversion on Linux and OS X and other platforms
- // MARKUP_STDCONV to use neither WINCONV or ICONV, falls back to setlocale based conversion for ANSI
- //
- #if ! defined(MARKUP_WINDOWS)
- #if defined(_WIN32) || defined(WIN32)
- #define MARKUP_WINDOWS
- #endif // WIN32 or _WIN32
- #endif // not MARKUP_WINDOWS
- #if _MSC_VER > 1000 // VC++
- #pragma once
- #if ! defined(MARKUP_SAFESTR) // not VC++ safe strings
- #pragma warning(disable:4996) // VC++ 2005 deprecated function warnings
- #endif // not VC++ safe strings
- #if defined(MARKUP_STL) && _MSC_VER < 1400 // STL pre VC++ 2005
- #pragma warning(disable:4786) // std::string long names
- #endif // VC++ 2005 STL
- #else // not VC++
- #if ! defined(MARKUP_STL)
- #define MARKUP_STL
- #endif // not STL
- #if defined(__GNUC__) && ! defined(MARKUP_ICONV) && ! defined(MARKUP_STDCONV) && ! defined(MARKUP_WINCONV)
- #if ! defined(MARKUP_WINDOWS)
- #define MARKUP_ICONV
- #endif // not Windows
- #endif // GNUC and not ICONV not STDCONV not WINCONV
- #endif // not VC++
- #if (defined(_UNICODE) || defined(UNICODE)) && ! defined(MARKUP_WCHAR)
- #define MARKUP_WCHAR
- #endif // _UNICODE or UNICODE
- #if (defined(_MBCS) || defined(MBCS)) && ! defined(MARKUP_MBCS)
- #define MARKUP_MBCS
- #endif // _MBCS and not MBCS
- #if ! defined(MARKUP_SIZEOFWCHAR)
- #if __SIZEOF_WCHAR_T__ == 4 || __WCHAR_MAX__ > 0x10000
- #define MARKUP_SIZEOFWCHAR 4
- #else // sizeof(wchar_t) != 4
- #define MARKUP_SIZEOFWCHAR 2
- #endif // sizeof(wchar_t) != 4
- #endif // not MARKUP_SIZEOFWCHAR
- #if ! defined(MARKUP_WINCONV) && ! defined(MARKUP_STDCONV) && ! defined(MARKUP_ICONV)
- #define MARKUP_WINCONV
- #endif // not WINCONV not STDCONV not ICONV
- #if ! defined(MARKUP_FILEBLOCKSIZE)
- #define MARKUP_FILEBLOCKSIZE 16384
- #endif
- // Text type and function defines (compiler and build-option dependent)
- //
- #define MCD_ACP 0
- #define MCD_UTF8 65001
- #define MCD_UTF16 1200
- #define MCD_UTF32 65005
- #if defined(MARKUP_WCHAR)
- #define MCD_CHAR wchar_t
- #define MCD_PCSZ const wchar_t*
- #define MCD_PSZLEN (int)wcslen
- #define MCD_PSZCHR wcschr
- #define MCD_PSZSTR wcsstr
- #define MCD_PSZTOL wcstol
- #if defined(MARKUP_SAFESTR) // VC++ safe strings
- #define MCD_SSZ(sz) sz,(sizeof(sz)/sizeof(MCD_CHAR))
- #define MCD_PSZCPY(sz,p) wcscpy_s(MCD_SSZ(sz),p)
- #define MCD_PSZNCPY(sz,p,n) wcsncpy_s(MCD_SSZ(sz),p,n)
- #define MCD_SPRINTF swprintf_s
- #define MCD_FOPEN(f,n,m) {if(_wfopen_s(&f,n,m)!=0)f=NULL;}
- #else // not VC++ safe strings
- #if defined(__GNUC__) && ! defined(MARKUP_WINDOWS) // non-Windows GNUC
- #define MCD_SSZ(sz) sz,(sizeof(sz)/sizeof(MCD_CHAR))
- #else // not non-Windows GNUC
- #define MCD_SSZ(sz) sz
- #endif // not non-Windows GNUC
- #define MCD_PSZCPY wcscpy
- #define MCD_PSZNCPY wcsncpy
- #define MCD_SPRINTF swprintf
- #define MCD_FOPEN(f,n,m) f=_wfopen(n,m)
- #endif // not VC++ safe strings
- #define MCD_T(s) L ## s
- #if MARKUP_SIZEOFWCHAR == 4 // sizeof(wchar_t) == 4
- #define MCD_ENC MCD_T("UTF-32")
- #else // sizeof(wchar_t) == 2
- #define MCD_ENC MCD_T("UTF-16")
- #endif
- #define MCD_CLEN(p) 1
- #else // not MARKUP_WCHAR
- #define MCD_CHAR char
- #define MCD_PCSZ const char*
- #define MCD_PSZLEN (int)strlen
- #define MCD_PSZCHR strchr
- #define MCD_PSZSTR strstr
- #define MCD_PSZTOL strtol
- #if defined(MARKUP_SAFESTR) // VC++ safe strings
- #define MCD_SSZ(sz) sz,(sizeof(sz)/sizeof(MCD_CHAR))
- #define MCD_PSZCPY(sz,p) strcpy_s(MCD_SSZ(sz),p)
- #define MCD_PSZNCPY(sz,p,n) strncpy_s(MCD_SSZ(sz),p,n)
- #define MCD_SPRINTF sprintf_s
- #define MCD_FOPEN(f,n,m) {if(fopen_s(&f,n,m)!=0)f=NULL;}
- #else // not VC++ safe strings
- #define MCD_SSZ(sz) sz
- #define MCD_PSZCPY strcpy
- #define MCD_PSZNCPY strncpy
- #define MCD_SPRINTF sprintf
- #define MCD_FOPEN(f,n,m) f=fopen(n,m)
- #endif // not VC++ safe strings
- #define MCD_T(s) s
- #if defined(MARKUP_MBCS) // MBCS/double byte
- #define MCD_ENC MCD_T("")
- #if defined(MARKUP_WINCONV)
- #define MCD_CLEN(p) (int)_mbclen((const unsigned char*)p)
- #else // not WINCONV
- #define MCD_CLEN(p) (int)mblen(p,MB_CUR_MAX)
- #endif // not WINCONV
- #else // not MBCS/double byte
- #define MCD_ENC MCD_T("UTF-8")
- #define MCD_CLEN(p) 1
- #endif // not MBCS/double byte
- #endif // not MARKUP_WCHAR
- #if _MSC_VER < 1000 // not VC++
- #define MCD_STRERROR strerror(errno)
- #endif // not VC++
- // String type and function defines (compiler and build-option dependent)
- // Define MARKUP_STL to use STL strings
- //
- #if defined(MARKUP_STL) // STL
- #include <string>
- #if defined(MARKUP_WCHAR)
- #define MCD_STR std::wstring
- #else // not MARKUP_WCHAR
- #define MCD_STR std::string
- #endif // not MARKUP_WCHAR
- #define MCD_2PCSZ(s) s.c_str()
- #define MCD_STRLENGTH(s) (int)s.size()
- #define MCD_STRCLEAR(s) s.erase()
- #define MCD_STRCLEARSIZE(s) MCD_STR t; s.swap(t)
- #define MCD_STRISEMPTY(s) s.empty()
- #define MCD_STRMID(s,n,l) s.substr(n,l)
- #define MCD_STRASSIGN(s,p,n) s.assign(p,n)
- #define MCD_STRCAPACITY(s) (int)s.capacity()
- #define MCD_STRINSERTREPLACE(d,i,r,s) d.replace(i,r,s)
- #define MCD_GETBUFFER(s,n) new MCD_CHAR[n+1]; if ((int)s.capacity()<(int)n) s.reserve(n)
- #define MCD_RELEASEBUFFER(s,p,n) s.replace(0,s.size(),p,n); delete[]p
- #define MCD_BLDRESERVE(s,n) s.reserve(n)
- #define MCD_BLDCHECK(s,n,d) ;
- #define MCD_BLDRELEASE(s) ;
- #define MCD_BLDAPPENDN(s,p,n) s.append(p,n)
- #define MCD_BLDAPPEND(s,p) s.append(p)
- #define MCD_BLDAPPEND1(s,c) s+=(MCD_CHAR)(c)
- #define MCD_BLDLEN(s) (int)s.size()
- #define MCD_BLDTRUNC(s,n) s.resize(n)
- #else // not STL, i.e. MFC
- // afx.h provides CString, to avoid "WINVER not defined" #include stdafh.x in Markup.cpp
- #include <afx.h>
- #define MCD_STR CString
- #define MCD_2PCSZ(s) ((MCD_PCSZ)s)
- #define MCD_STRLENGTH(s) s.GetLength()
- #define MCD_STRCLEAR(s) s.Empty()
- #define MCD_STRCLEARSIZE(s) s=MCD_STR()
- #define MCD_STRISEMPTY(s) s.IsEmpty()
- #define MCD_STRMID(s,n,l) s.Mid(n,l)
- #define MCD_STRASSIGN(s,p,n) memcpy(s.GetBuffer(n),p,(n)*sizeof(MCD_CHAR));s.ReleaseBuffer(n);
- #define MCD_STRCAPACITY(s) (((CStringData*)((MCD_PCSZ)s)-1)->nAllocLength)
- #define MCD_GETBUFFER(s,n) s.GetBuffer(n)
- #define MCD_RELEASEBUFFER(s,p,n) s.ReleaseBuffer(n)
- #define MCD_BLDRESERVE(s,n) MCD_CHAR*pD=s.GetBuffer(n); int nL=0
- #define MCD_BLDCHECK(s,n,d) if(nL+(int)(d)>n){s.ReleaseBuffer(nL);n<<=2;pD=s.GetBuffer(n);}
- #define MCD_BLDRELEASE(s) s.ReleaseBuffer(nL)
- #define MCD_BLDAPPENDN(s,p,n) MCD_PSZNCPY(&pD[nL],p,n);nL+=n
- #define MCD_BLDAPPEND(s,p) MCD_PSZCPY(&pD[nL],p);nL+=MCD_PSZLEN(p)
- #define MCD_BLDAPPEND1(s,c) pD[nL++]=(MCD_CHAR)(c)
- #define MCD_BLDLEN(s) nL
- #define MCD_BLDTRUNC(s,n) nL=n
- #endif // not STL
- #define MCD_STRTOINT(s) MCD_PSZTOL(MCD_2PCSZ(s),NULL,10)
- // Allow function args to accept string objects as constant string pointers
- struct MCD_CSTR
- {
- MCD_CSTR() { pcsz=NULL; };
- MCD_CSTR( MCD_PCSZ p ) { pcsz=p; };
- MCD_CSTR( const MCD_STR& s ) { pcsz = MCD_2PCSZ(s); };
- operator MCD_PCSZ() const { return pcsz; };
- MCD_PCSZ pcsz;
- };
- // On Linux and OS X, filenames are not specified in wchar_t
- #if defined(MARKUP_WCHAR) && defined(__GNUC__)
- #undef MCD_FOPEN
- #define MCD_FOPEN(f,n,m) f=fopen(n,m)
- #define MCD_T_FILENAME(s) s
- #define MCD_PCSZ_FILENAME const char*
- struct MCD_CSTR_FILENAME
- {
- MCD_CSTR_FILENAME() { pcsz=NULL; };
- MCD_CSTR_FILENAME( MCD_PCSZ_FILENAME p ) { pcsz=p; };
- MCD_CSTR_FILENAME( const std::string& s ) { pcsz = s.c_str(); };
- operator MCD_PCSZ_FILENAME() const { return pcsz; };
- MCD_PCSZ_FILENAME pcsz;
- };
- #else // not WCHAR GNUC
- #define MCD_CSTR_FILENAME MCD_CSTR
- #define MCD_T_FILENAME MCD_T
- #define MCD_PCSZ_FILENAME MCD_PCSZ
- #endif // not WCHAR GNUC
- // File fseek, ftell and offset type
- #if defined(__GNUC__) && ! defined(MARKUP_WINDOWS) // non-Windows GNUC
- #define MCD_FSEEK fseeko
- #define MCD_FTELL ftello
- #define MCD_INTFILEOFFSET off_t
- #elif _MSC_VER >= 1000 && defined(MARKUP_HUGEFILE) // VC++ HUGEFILE
- #if _MSC_VER < 1400 // before VC++ 2005
- extern "C" int __cdecl _fseeki64(FILE *, __int64, int);
- extern "C" __int64 __cdecl _ftelli64(FILE *);
- #endif // before VC++ 2005
- #define MCD_FSEEK _fseeki64
- #define MCD_FTELL _ftelli64
- #define MCD_INTFILEOFFSET __int64
- #else // not non-Windows GNUC or VC++ HUGEFILE
- #define MCD_FSEEK fseek
- #define MCD_FTELL ftell
- #define MCD_INTFILEOFFSET long
- #endif // not non-Windows GNUC or VC++ HUGEFILE
- // End of line choices: none, return, newline, or CRLF
- #if defined(MARKUP_EOL_NONE)
- #define MCD_EOL MCD_T("")
- #elif defined(MARKUP_EOL_RETURN) // rare; only used on some old operating systems
- #define MCD_EOL MCD_T("\r")
- #elif defined(MARKUP_EOL_NEWLINE) // Unix standard
- #define MCD_EOL MCD_T("\n")
- #elif defined(MARKUP_EOL_CRLF) || defined(MARKUP_WINDOWS) // Windows standard
- #define MCD_EOL MCD_T("\r\n")
- #else // not Windows and not otherwise specified
- #define MCD_EOL MCD_T("\n")
- #endif // not Windows and not otherwise specified
- #define MCD_EOLLEN (sizeof(MCD_EOL)/sizeof(MCD_CHAR)-1) // string length of MCD_EOL
- struct FilePos;
- struct TokenPos;
- struct NodePos;
- struct PathPos;
- struct SavedPosMapArray;
- struct ElemPosTree;
- class CMarkup
- {
- public:
- CMarkup() { x_InitMarkup(); SetDoc( NULL ); };
- CMarkup( MCD_CSTR szDoc ) { x_InitMarkup(); SetDoc( szDoc ); };
- CMarkup( int nFlags ) { x_InitMarkup(); SetDoc( NULL ); m_nDocFlags = nFlags; };
- CMarkup( const CMarkup& markup ) { x_InitMarkup(); *this = markup; };
- void operator=( const CMarkup& markup );
- ~CMarkup();
- // Navigate
- bool Load( MCD_CSTR_FILENAME szFileName );
- bool SetDoc( MCD_PCSZ pDoc );
- bool SetDoc( const MCD_STR& strDoc );
- bool IsWellFormed();
- bool FindElem( MCD_CSTR szName=NULL );
- bool FindChildElem( MCD_CSTR szName=NULL );
- bool IntoElem();
- bool OutOfElem();
- void ResetChildPos() { x_SetPos(m_iPosParent,m_iPos,); };
- void ResetMainPos() { x_SetPos(m_iPosParent,,); };
- void ResetPos() { x_SetPos(,,); };
- MCD_STR GetTagName() const;
- MCD_STR GetChildTagName() const { return x_GetTagName(m_iPosChild); };
- MCD_STR GetData() { return x_GetData(m_iPos); };
- MCD_STR GetChildData() { return x_GetData(m_iPosChild); };
- MCD_STR GetElemContent() const { return x_GetElemContent(m_iPos); };
- MCD_STR GetAttrib( MCD_CSTR szAttrib ) const { return x_GetAttrib(m_iPos,szAttrib); };
- MCD_STR GetChildAttrib( MCD_CSTR szAttrib ) const { return x_GetAttrib(m_iPosChild,szAttrib); };
- bool GetNthAttrib( int n, MCD_STR& strAttrib, MCD_STR& strValue ) const;
- MCD_STR GetAttribName( int n ) const;
- int FindNode( int nType= );
- int GetNodeType() { return m_nNodeType; };
- bool SavePos( MCD_CSTR szPosName=MCD_T(""), int nMap = );
- bool RestorePos( MCD_CSTR szPosName=MCD_T(""), int nMap = );
- bool SetMapSize( int nSize, int nMap = );
- MCD_STR GetError() const;
- const MCD_STR& GetResult() const { return m_strResult; };
- int GetDocFlags() const { return m_nDocFlags; };
- void SetDocFlags( int nFlags ) { m_nDocFlags = (nFlags & ~(MDF_READFILE|MDF_WRITEFILE|MDF_APPENDFILE)); };
- enum MarkupDocFlags
- {
- MDF_UTF16LEFILE = ,
- MDF_UTF8PREAMBLE = ,
- MDF_IGNORECASE = ,
- MDF_READFILE = ,
- MDF_WRITEFILE = ,
- MDF_APPENDFILE = ,
- MDF_UTF16BEFILE = ,
- MDF_TRIMWHITESPACE = ,
- MDF_COLLAPSEWHITESPACE =
- };
- enum MarkupNodeFlags
- {
- MNF_WITHCDATA = 0x01,
- MNF_WITHNOLINES = 0x02,
- MNF_WITHXHTMLSPACE = 0x04,
- MNF_WITHREFS = 0x08,
- MNF_WITHNOEND = 0x10,
- MNF_ESCAPEQUOTES = 0x100,
- MNF_NONENDED = 0x100000,
- MNF_ILLDATA = 0x200000
- };
- enum MarkupNodeType
- {
- MNT_ELEMENT = , // 0x0001
- MNT_TEXT = , // 0x0002
- MNT_WHITESPACE = , // 0x0004
- MNT_TEXT_AND_WHITESPACE = , // 0x0006
- MNT_CDATA_SECTION = , // 0x0008
- MNT_PROCESSING_INSTRUCTION = , // 0x0010
- MNT_COMMENT = , // 0x0020
- MNT_DOCUMENT_TYPE = , // 0x0040
- MNT_EXCLUDE_WHITESPACE = , // 0x007b
- MNT_LONE_END_TAG = , // 0x0080
- MNT_NODE_ERROR = // 0x8000
- };
- // Create
- bool Save( MCD_CSTR_FILENAME szFileName );
- const MCD_STR& GetDoc() const { return m_strDoc; };
- bool AddElem( MCD_CSTR szName, MCD_CSTR szData=NULL, int nFlags= ) { return x_AddElem(szName,szData,nFlags); };
- bool InsertElem( MCD_CSTR szName, MCD_CSTR szData=NULL, int nFlags= ) { return x_AddElem(szName,szData,nFlags|MNF_INSERT); };
- bool AddChildElem( MCD_CSTR szName, MCD_CSTR szData=NULL, int nFlags= ) { return x_AddElem(szName,szData,nFlags|MNF_CHILD); };
- bool InsertChildElem( MCD_CSTR szName, MCD_CSTR szData=NULL, int nFlags= ) { return x_AddElem(szName,szData,nFlags|MNF_INSERT|MNF_CHILD); };
- bool AddElem( MCD_CSTR szName, int nValue, int nFlags= ) { return x_AddElem(szName,nValue,nFlags); };
- bool InsertElem( MCD_CSTR szName, int nValue, int nFlags= ) { return x_AddElem(szName,nValue,nFlags|MNF_INSERT); };
- bool AddChildElem( MCD_CSTR szName, int nValue, int nFlags= ) { return x_AddElem(szName,nValue,nFlags|MNF_CHILD); };
- bool InsertChildElem( MCD_CSTR szName, int nValue, int nFlags= ) { return x_AddElem(szName,nValue,nFlags|MNF_INSERT|MNF_CHILD); };
- bool AddAttrib( MCD_CSTR szAttrib, MCD_CSTR szValue ) { return x_SetAttrib(m_iPos,szAttrib,szValue); };
- bool AddChildAttrib( MCD_CSTR szAttrib, MCD_CSTR szValue ) { return x_SetAttrib(m_iPosChild,szAttrib,szValue); };
- bool AddAttrib( MCD_CSTR szAttrib, int nValue ) { return x_SetAttrib(m_iPos,szAttrib,nValue); };
- bool AddChildAttrib( MCD_CSTR szAttrib, int nValue ) { return x_SetAttrib(m_iPosChild,szAttrib,nValue); };
- bool AddSubDoc( MCD_CSTR szSubDoc ) { return x_AddSubDoc(szSubDoc,); };
- bool InsertSubDoc( MCD_CSTR szSubDoc ) { return x_AddSubDoc(szSubDoc,MNF_INSERT); };
- MCD_STR GetSubDoc() { return x_GetSubDoc(m_iPos); };
- bool AddChildSubDoc( MCD_CSTR szSubDoc ) { return x_AddSubDoc(szSubDoc,MNF_CHILD); };
- bool InsertChildSubDoc( MCD_CSTR szSubDoc ) { return x_AddSubDoc(szSubDoc,MNF_CHILD|MNF_INSERT); };
- MCD_STR GetChildSubDoc() { return x_GetSubDoc(m_iPosChild); };
- bool AddNode( int nType, MCD_CSTR szText ) { return x_AddNode(nType,szText,); };
- bool InsertNode( int nType, MCD_CSTR szText ) { return x_AddNode(nType,szText,MNF_INSERT); };
- // Modify
- bool RemoveElem();
- bool RemoveChildElem();
- bool RemoveNode();
- bool SetAttrib( MCD_CSTR szAttrib, MCD_CSTR szValue, int nFlags= ) { return x_SetAttrib(m_iPos,szAttrib,szValue,nFlags); };
- bool SetChildAttrib( MCD_CSTR szAttrib, MCD_CSTR szValue, int nFlags= ) { return x_SetAttrib(m_iPosChild,szAttrib,szValue,nFlags); };
- bool SetAttrib( MCD_CSTR szAttrib, int nValue, int nFlags= ) { return x_SetAttrib(m_iPos,szAttrib,nValue,nFlags); };
- bool SetChildAttrib( MCD_CSTR szAttrib, int nValue, int nFlags= ) { return x_SetAttrib(m_iPosChild,szAttrib,nValue,nFlags); };
- bool SetData( MCD_CSTR szData, int nFlags= ) { return x_SetData(m_iPos,szData,nFlags); };
- bool SetChildData( MCD_CSTR szData, int nFlags= ) { return x_SetData(m_iPosChild,szData,nFlags); };
- bool SetData( int nValue ) { return x_SetData(m_iPos,nValue); };
- bool SetChildData( int nValue ) { return x_SetData(m_iPosChild,nValue); };
- bool SetElemContent( MCD_CSTR szContent ) { return x_SetElemContent(szContent); };
- // Utility
- static bool ReadTextFile( MCD_CSTR_FILENAME szFileName, MCD_STR& strDoc, MCD_STR* pstrResult=NULL, int* pnDocFlags=NULL, MCD_STR* pstrEncoding=NULL );
- static bool WriteTextFile( MCD_CSTR_FILENAME szFileName, const MCD_STR& strDoc, MCD_STR* pstrResult=NULL, int* pnDocFlags=NULL, MCD_STR* pstrEncoding=NULL );
- static MCD_STR EscapeText( MCD_CSTR szText, int nFlags = );
- static MCD_STR UnescapeText( MCD_CSTR szText, int nTextLength = -, int nFlags = );
- static int UTF16To8( char *pszUTF8, const unsigned short* pwszUTF16, int nUTF8Count );
- static int UTF8To16( unsigned short* pwszUTF16, const char* pszUTF8, int nUTF8Count );
- static MCD_STR UTF8ToA( MCD_CSTR pszUTF8, int* pnFailed = NULL );
- static MCD_STR AToUTF8( MCD_CSTR pszANSI );
- static void EncodeCharUTF8( int nUChar, char* pszUTF8, int& nUTF8Len );
- static int DecodeCharUTF8( const char*& pszUTF8, const char* pszUTF8End = NULL );
- static void EncodeCharUTF16( int nUChar, unsigned short* pwszUTF16, int& nUTF16Len );
- static int DecodeCharUTF16( const unsigned short*& pwszUTF16, const unsigned short* pszUTF16End = NULL );
- static bool DetectUTF8( const char* pText, int nTextLen, int* pnNonASCII = NULL, bool* bErrorAtEnd = NULL );
- static MCD_STR GetDeclaredEncoding( MCD_CSTR szDoc );
- static int GetEncodingCodePage( MCD_CSTR pszEncoding );
- protected:
- #if defined(_DEBUG)
- MCD_PCSZ m_pDebugCur;
- MCD_PCSZ m_pDebugPos;
- #endif // DEBUG
- MCD_STR m_strDoc;
- MCD_STR m_strResult;
- int m_iPosParent;
- int m_iPos;
- int m_iPosChild;
- int m_iPosFree;
- int m_iPosDeleted;
- int m_nNodeType;
- int m_nNodeOffset;
- int m_nNodeLength;
- int m_nDocFlags;
- FilePos* m_pFilePos;
- SavedPosMapArray* m_pSavedPosMaps;
- ElemPosTree* m_pElemPosTree;
- enum MarkupNodeFlagsInternal
- {
- MNF_INSERT = 0x002000,
- MNF_CHILD = 0x004000
- };
- #if defined(_DEBUG) // DEBUG
- void x_SetDebugState();
- #define MARKUP_SETDEBUGSTATE x_SetDebugState()
- #else // not DEBUG
- #define MARKUP_SETDEBUGSTATE
- #endif // not DEBUG
- void x_InitMarkup();
- void x_SetPos( int iPosParent, int iPos, int iPosChild );
- int x_GetFreePos();
- bool x_AllocElemPos( int nNewSize = );
- int x_GetParent( int i );
- bool x_ParseDoc();
- int x_ParseElem( int iPos, TokenPos& token );
- int x_FindElem( int iPosParent, int iPos, PathPos& path ) const;
- MCD_STR x_GetPath( int iPos ) const;
- MCD_STR x_GetTagName( int iPos ) const;
- MCD_STR x_GetData( int iPos );
- MCD_STR x_GetAttrib( int iPos, MCD_PCSZ pAttrib ) const;
- static MCD_STR x_EncodeCDATASection( MCD_PCSZ szData );
- bool x_AddElem( MCD_PCSZ pName, MCD_PCSZ pValue, int nFlags );
- bool x_AddElem( MCD_PCSZ pName, int nValue, int nFlags );
- MCD_STR x_GetSubDoc( int iPos );
- bool x_AddSubDoc( MCD_PCSZ pSubDoc, int nFlags );
- bool x_SetAttrib( int iPos, MCD_PCSZ pAttrib, MCD_PCSZ pValue, int nFlags= );
- bool x_SetAttrib( int iPos, MCD_PCSZ pAttrib, int nValue, int nFlags= );
- bool x_AddNode( int nNodeType, MCD_PCSZ pText, int nNodeFlags );
- void x_RemoveNode( int iPosParent, int& iPos, int& nNodeType, int& nNodeOffset, int& nNodeLength );
- static bool x_CreateNode( MCD_STR& strNode, int nNodeType, MCD_PCSZ pText );
- int x_InsertNew( int iPosParent, int& iPosRel, NodePos& node );
- void x_AdjustForNode( int iPosParent, int iPos, int nShift );
- void x_Adjust( int iPos, int nShift, bool bAfterPos = false );
- void x_LinkElem( int iPosParent, int iPosBefore, int iPos );
- int x_UnlinkElem( int iPos );
- int x_UnlinkPrevElem( int iPosParent, int iPosBefore, int iPos );
- int x_ReleaseSubDoc( int iPos );
- int x_ReleasePos( int iPos );
- void x_CheckSavedPos();
- bool x_SetData( int iPos, MCD_PCSZ szData, int nFlags );
- bool x_SetData( int iPos, int nValue );
- int x_RemoveElem( int iPos );
- MCD_STR x_GetElemContent( int iPos ) const;
- bool x_SetElemContent( MCD_PCSZ szContent );
- void x_DocChange( int nLeft, int nReplace, const MCD_STR& strInsert );
- };
- #endif // !defined(_MARKUP_H_INCLUDED_)
markup.cpp
- // Markup.cpp: implementation of the CMarkup class.
- //
- // Markup Release 11.5
- // Copyright (C) 2011 First Objective Software, Inc. All rights reserved
- // Go to www.firstobject.com for the latest CMarkup and EDOM documentation
- // Use in commercial applications requires written permission
- // This software is provided "as is", with no warranty.
- //
- #include "stdafx.h"
- #include <stdio.h>
- #include "Markup.h"
- #if defined(MCD_STRERROR) // C error routine
- #include <errno.h>
- #endif // C error routine
- #if defined (MARKUP_ICONV)
- #include <iconv.h>
- #endif
- #define x_ATTRIBQUOTE '\"' // can be double or single quote
- #if defined(MARKUP_STL) && ( defined(MARKUP_WINCONV) || (! defined(MCD_STRERROR)))
- #include <windows.h> // for MultiByteToWideChar, WideCharToMultiByte, FormatMessage
- #endif // need windows.h when STL and (not setlocale or not strerror), MFC afx.h includes it already
- #if defined(MARKUP_MBCS) // MBCS/double byte
- #pragma message( "Note: MBCS build (not UTF-8)" )
- // For UTF-8, remove MBCS from project settings C/C++ preprocessor definitions
- #if defined (MARKUP_WINCONV)
- #include <mbstring.h> // for VC++ _mbclen
- #endif // WINCONV
- #endif // MBCS/double byte
- #if defined(_DEBUG) && _MSC_VER > 1000 // VC++ DEBUG
- #undef THIS_FILE
- static char THIS_FILE[]=__FILE__;
- #if defined(DEBUG_NEW)
- #define new DEBUG_NEW
- #endif // DEBUG_NEW
- #endif // VC++ DEBUG
- // Disable "while ( 1 )" warning in VC++ 2002
- #if _MSC_VER >= 1300 // VC++ 2002 (7.0)
- #pragma warning(disable:4127)
- #endif // VC++ 2002 (7.0)
- //////////////////////////////////////////////////////////////////////
- // Internal static utility functions
- //
- void x_StrInsertReplace( MCD_STR& str, int nLeft, int nReplace, const MCD_STR& strInsert )
- {
- // Insert strInsert into str at nLeft replacing nReplace chars
- // Reduce reallocs on growing string by reserving string space
- // If realloc needed, allow for 1.5 times the new length
- //
- int nStrLength = MCD_STRLENGTH(str);
- int nInsLength = MCD_STRLENGTH(strInsert);
- int nNewLength = nInsLength + nStrLength - nReplace;
- int nAllocLen = MCD_STRCAPACITY(str);
- #if defined(MCD_STRINSERTREPLACE) // STL, replace method
- if ( nNewLength > nAllocLen )
- MCD_BLDRESERVE( str, (nNewLength + nNewLength/ + ) );
- MCD_STRINSERTREPLACE( str, nLeft, nReplace, strInsert );
- #else // MFC, no replace method
- int nBufferLen = nNewLength;
- if ( nNewLength > nAllocLen )
- nBufferLen += nBufferLen/ + ;
- MCD_CHAR* pDoc = MCD_GETBUFFER( str, nBufferLen );
- if ( nInsLength != nReplace && nLeft+nReplace < nStrLength )
- memmove( &pDoc[nLeft+nInsLength], &pDoc[nLeft+nReplace], (nStrLength-nLeft-nReplace)*sizeof(MCD_CHAR) );
- if ( nInsLength )
- memcpy( &pDoc[nLeft], strInsert, nInsLength*sizeof(MCD_CHAR) );
- MCD_RELEASEBUFFER( str, pDoc, nNewLength );
- #endif // MFC, no replace method
- }
- int x_Hash( MCD_PCSZ p, int nSize )
- {
- unsigned int n=;
- while (*p)
- n += (unsigned int)(*p++);
- return n % nSize;
- }
- MCD_STR x_IntToStr( int n )
- {
- MCD_CHAR sz[];
- MCD_SPRINTF(MCD_SSZ(sz),MCD_T("%d"),n);
- MCD_STR s=sz;
- return s;
- }
- int x_StrNCmp( MCD_PCSZ p1, MCD_PCSZ p2, int n, int bIgnoreCase = )
- {
- // Fast string compare to determine equality
- if ( bIgnoreCase )
- {
- bool bNonAsciiFound = false;
- MCD_CHAR c1, c2;
- while ( n-- )
- {
- c1 = *p1++;
- c2 = *p2++;
- if ( c1 != c2 )
- {
- if ( bNonAsciiFound )
- return c1 - c2;
- if ( c1 >= 'a' && c1 <= 'z' )
- c1 = (MCD_CHAR)( c1 - ('a'-'A') );
- if ( c2 >= 'a' && c2 <= 'z' )
- c2 = (MCD_CHAR)( c2 - ('a'-'A') );
- if ( c1 != c2 )
- return c1 - c2;
- }
- else if ( (unsigned int)c1 > )
- bNonAsciiFound = true;
- }
- }
- else
- {
- while ( n-- )
- {
- if ( *p1 != *p2 )
- return *p1 - *p2;
- p1++;
- p2++;
- }
- }
- return ;
- }
- enum MarkupResultCode
- {
- MRC_COUNT = ,
- MRC_TYPE = ,
- MRC_NUMBER = ,
- MRC_ENCODING = ,
- MRC_LENGTH = ,
- MRC_MODIFY = ,
- MRC_MSG =
- };
- void x_AddResult( MCD_STR& strResult, MCD_CSTR pszID, MCD_CSTR pszVal = NULL, int nResultCode = , int n = -, int n2 = - )
- {
- // Call this to append an error result to strResult, discard if accumulating too large
- if ( MCD_STRLENGTH(strResult) < )
- {
- // Use a temporary CMarkup object but keep strResult in a string to minimize memory footprint
- CMarkup mResult( strResult );
- if ( nResultCode & MRC_MODIFY )
- mResult.FindElem( pszID );
- else
- mResult.AddElem( pszID, MCD_T(""), CMarkup::MNF_WITHNOLINES );
- if ( pszVal.pcsz )
- {
- if ( nResultCode & MRC_TYPE )
- mResult.SetAttrib( MCD_T("type"), pszVal );
- else if ( nResultCode & MRC_ENCODING )
- mResult.SetAttrib( MCD_T("encoding"), pszVal );
- else if ( nResultCode & MRC_MSG )
- mResult.SetAttrib( MCD_T("msg"), pszVal );
- else
- mResult.SetAttrib( MCD_T("tagname"), pszVal );
- }
- if ( nResultCode & MRC_NUMBER )
- mResult.SetAttrib( MCD_T("n"), n );
- else if ( nResultCode & MRC_COUNT )
- mResult.SetAttrib( MCD_T("count"), n );
- else if ( nResultCode & MRC_LENGTH )
- mResult.SetAttrib( MCD_T("length"), n );
- else if ( n != - )
- mResult.SetAttrib( MCD_T("offset"), n );
- if ( n2 != - )
- mResult.SetAttrib( MCD_T("offset2"), n2 );
- strResult = mResult.GetDoc();
- }
- }
- //////////////////////////////////////////////////////////////////////
- // Encoding conversion struct and methods
- //
- struct TextEncoding
- {
- TextEncoding( MCD_CSTR pszFromEncoding, const void* pFromBuffer, int nFromBufferLen )
- {
- m_strFromEncoding = pszFromEncoding;
- m_pFrom = pFromBuffer;
- m_nFromLen = nFromBufferLen;
- m_nFailedChars = ;
- m_nToCount = ;
- };
- int PerformConversion( void* pTo, MCD_CSTR pszToEncoding = NULL );
- bool FindRaggedEnd( int& nTruncBeforeBytes );
- #if defined(MARKUP_ICONV)
- static const char* IConvName( char* szEncoding, MCD_CSTR pszEncoding );
- int IConv( void* pTo, int nToCharSize, int nFromCharSize );
- #endif // ICONV
- #if ! defined(MARKUP_WCHAR)
- static bool CanConvert( MCD_CSTR pszToEncoding, MCD_CSTR pszFromEncoding );
- #endif // WCHAR
- MCD_STR m_strToEncoding;
- MCD_STR m_strFromEncoding;
- const void* m_pFrom;
- int m_nFromLen;
- int m_nToCount;
- int m_nFailedChars;
- };
- // Encoding names
- // This is a precompiled ASCII hash table for speed and minimum memory requirement
- // Each entry consists of a 2 digit name length, 5 digit code page, and the encoding name
- // Each table slot can have multiple entries, table size 155 was chosen for even distribution
- //
- MCD_PCSZ EncodingNameTable[] =
- {
- MCD_T("0800949ksc_5601"),MCD_T("1920932cseucpkdfmtjapanese0920003x-cp20003"),
- MCD_T("1250221_iso-2022-jp0228591l10920004x-cp20004"),
- MCD_T("0228592l20920005x-cp20005"),
- MCD_T("0228593l30600850ibm8501000858ccsid00858"),
- MCD_T("0228594l40600437ibm4370701201ucs-2be0600860ibm860"),
- MCD_T("0600852ibm8520501250ms-ee0600861ibm8610228599l50751932cp51932"),
- MCD_T("0600862ibm8620620127ibm3670700858cp008581010021x-mac-thai0920261x-cp20261"),
- MCD_T("0600737ibm7370500869cp-gr1057003x-iscii-be0600863ibm863"),
- MCD_T("0750221ms502210628591ibm8190600855ibm8550600864ibm864"),
- MCD_T("0600775ibm7751057002x-iscii-de0300949uhc0228605l91028591iso-ir-1000600865ibm865"),
- MCD_T("1028594iso-ir-1101028592iso-ir-1010600866ibm8660500861cp-is0600857ibm857"),
- MCD_T("0950227x-cp50227"),
- MCD_T("0320866koi1628598csisolatinhebrew1057008x-iscii-ka"),
- MCD_T("1000950big5-hkscs1220106x-ia5-german0600869ibm869"),
- MCD_T("1057009x-iscii-ma0701200ucs-2le0712001utf32be0920269x-cp20269"),
- MCD_T("0800708asmo-7080500437cspc81765000unicode-1-1-utf-70612000utf-320920936x-cp20936"),
- MCD_T("1200775ebcdic-cp-be0628598hebrew0701201utf16be1765001unicode-1-1-utf-81765001unicode-2-0-utf-80551932x-euc"),
- MCD_T("1028595iso-ir-1441028597iso-ir-1260728605latin-90601200utf-161057011x-iscii-pa"),
- MCD_T("1028596iso-ir-1271028593iso-ir-1090751932ms51932"),
- MCD_T("0801253ms-greek0600949korean1050225iso2022-kr1128605iso_8859-150920949x-cp20949"),
- MCD_T("1200775ebcdic-cp-ch1028598iso-ir-1381057006x-iscii-as1450221iso-2022-jp-ms"),
- MCD_T("1057004x-iscii-ta1028599iso-ir-148"),
- MCD_T("1000949iso-ir-1490820127us-ascii"),MCD_T(""),
- MCD_T("1000936gb_2312-801900850cspc850multilingual0712000utf32le"),
- MCD_T("1057005x-iscii-te1300949csksc560119871965000x-unicode-2-0-utf-7"),
- MCD_T("0701200utf16le1965001x-unicode-2-0-utf-80928591iso8859-1"),
- MCD_T("0928592iso8859-21420002x_chinese-eten0520866koi8r1000932x-ms-cp932"),
- MCD_T("1320000x-chinese-cns1138598iso8859-8-i1057010x-iscii-gu0928593iso8859-3"),
- MCD_T("0928594iso8859-4"),MCD_T("0928595iso8859-51150221csiso2022jp"),
- MCD_T("0928596iso8859-60900154csptcp154"),
- MCD_T("0928597iso8859-70900932shift_jis1400154cyrillic-asian"),
- MCD_T("0928598iso8859-81057007x-iscii-or1150225csiso2022kr"),
- MCD_T("0721866koi8-ru0928599iso8859-9"),MCD_T("0910000macintosh"),MCD_T(""),
- MCD_T(""),MCD_T(""),
- MCD_T("1210004x-mac-arabic0800936gb2312800628598visual1520108x-ia5-norwegian"),
- MCD_T(""),MCD_T("0829001x-europa"),MCD_T(""),MCD_T("1510079x-mac-icelandic"),
- MCD_T("0800932sjis-win1128591csisolatin1"),MCD_T("1128592csisolatin2"),
- MCD_T("1400949ks_c_5601-19871128593csisolatin3"),MCD_T("1128594csisolatin4"),
- MCD_T("0400950big51128595csisolatin51400949ks_c_5601-1989"),
- MCD_T("0500775cp5001565000csunicode11utf7"),MCD_T("0501361johab"),
- MCD_T("1100932windows-9321100437codepage437"),
- MCD_T("1800862cspc862latinhebrew1310081x-mac-turkish"),MCD_T(""),
- MCD_T("0701256ms-arab0800775csibm5000500154cp154"),
- MCD_T("1100936windows-9360520127ascii"),
- MCD_T("1528597csisolatingreek1100874windows-874"),MCD_T("0500850cp850"),
- MCD_T("0700720dos-7200500950cp9500500932cp9320500437cp4370500860cp8601650222_iso-2022-jp$sio"),
- MCD_T("0500852cp8520500861cp8610700949ksc56010812001utf-32be"),
- MCD_T("0528597greek0500862cp8620520127cp3670500853cp853"),
- MCD_T("0500737cp7371150220iso-2022-jp0801201utf-16be0500863cp863"),
- MCD_T("0500936cp9360528591cp8194520932extended_unix_code_packed_format_for_japanese0500855cp8550500864cp864"),
- MCD_T("0500775cp7750500874cp8740800860csibm8600500865cp865"),
- MCD_T("0500866cp8660800861csibm8611150225iso-2022-kr0500857cp8571101201unicodefffe"),
- MCD_T("0700862dos-8620701255ms-hebr0500858cp858"),
- MCD_T("1210005x-mac-hebrew0500949cp9490800863csibm863"),
- MCD_T("0500869cp8691600437cspc8codepage4370700874tis-6200800855csibm8550800864csibm864"),
- MCD_T("0800950x-x-big50420866koi80800932ms_kanji0700874dos-8740800865csibm865"),
- MCD_T("0800866csibm8661210003x-mac-korean0800857csibm8570812000utf-32le"),
- MCD_T(""),MCD_T("0500932ms9320801200utf-16le1028591iso-8859-10500154pt154"),
- MCD_T("1028592iso-8859-20620866koi8-r0800869csibm869"),
- MCD_T("1500936csiso58gb2312800828597elot_9281238598iso-8859-8-i1028593iso-8859-30820127iso-ir-6"),
- MCD_T("1028594iso-8859-4"),
- MCD_T("0800852cspcp8520500936ms9361028595iso-8859-50621866koi8-u0701252ms-ansi"),
- MCD_T("1028596iso-8859-60220127us2400858pc-multilingual-850+euro"),
- MCD_T("1028597iso-8859-71028603iso8859-13"),
- MCD_T("1320000x-chinese_cns1028598iso-8859-8"),
- MCD_T("1828595csisolatincyrillic1028605iso8859-151028599iso-8859-9"),
- MCD_T("0465001utf8"),MCD_T("1510017x-mac-ukrainian"),MCD_T(""),
- MCD_T("0828595cyrillic"),MCD_T("0900936gb2312-80"),MCD_T(""),
- MCD_T("0720866cskoi8r1528591iso_8859-1:1987"),MCD_T("1528592iso_8859-2:1987"),
- MCD_T("1354936iso-4873:1986"),MCD_T("0700932sjis-ms1528593iso_8859-3:1988"),
- MCD_T("1528594iso_8859-4:19880600936gb23120701251ms-cyrl"),
- MCD_T("1528596iso_8859-6:19871528595iso_8859-5:1988"),
- MCD_T("1528597iso_8859-7:1987"),
- MCD_T("1201250windows-12501300932shifft_jis-ms"),
- MCD_T("0810029x-mac-ce1201251windows-12511528598iso_8859-8:19880900949ks_c_56011110000csmacintosh"),
- MCD_T("0601200cp12001201252windows-1252"),
- MCD_T("1052936hz-gb-23121201253windows-12531400949ks_c_5601_19871528599iso_8859-9:19890601201cp1201"),
- MCD_T("1201254windows-1254"),MCD_T("1000936csgb2312801201255windows-1255"),
- MCD_T("1201256windows-12561100932windows-31j"),
- MCD_T("1201257windows-12570601250cp12500601133cp1133"),
- MCD_T("0601251cp12511201258windows-12580601125cp1125"),
- MCD_T("0701254ms-turk0601252cp1252"),MCD_T("0601253cp12530601361cp1361"),
- MCD_T("0800949ks-c56010601254cp1254"),MCD_T("0651936euc-cn0601255cp1255"),
- MCD_T("0601256cp1256"),MCD_T("0601257cp12570600950csbig50800858ibm00858"),
- MCD_T("0601258cp1258"),MCD_T("0520105x-ia5"),
- MCD_T("0801250x-cp12501110006x-mac-greek0738598logical"),
- MCD_T("0801251x-cp1251"),MCD_T(""),
- MCD_T("1410001x-mac-japanese1200932cswindows31j"),
- MCD_T("0700936chinese0720127csascii0620932euc-jp"),
- MCD_T("0851936x-euc-cn0501200ucs-2"),MCD_T("0628597greek8"),
- MCD_T("0651949euc-kr"),MCD_T(""),MCD_T("0628591latin1"),
- MCD_T("0628592latin21100874iso-8859-11"),
- MCD_T("0628593latin31420127ansi_x3.4-19681420127ansi_x3.4-19861028591iso_8859-1"),
- MCD_T("0628594latin41028592iso_8859-20701200unicode1128603iso-8859-13"),
- MCD_T("1028593iso_8859-30628599latin51410082x-mac-croatian"),
- MCD_T("1028594iso_8859-41128605iso-8859-150565000utf-70851932x-euc-jp"),
- MCD_T("1300775cspc775baltic1028595iso_8859-50565001utf-80512000utf32"),
- MCD_T("1028596iso_8859-61710002x-mac-chinesetrad0601252x-ansi"),
- MCD_T("1028597iso_8859-70628605latin90501200utf160700154ptcp1541410010x-mac-romanian"),
- MCD_T("0900936iso-ir-581028598iso_8859-8"),MCD_T("1028599iso_8859-9"),
- MCD_T("1350221iso2022-jp-ms0400932sjis"),MCD_T("0751949cseuckr"),
- MCD_T("1420002x-chinese-eten"),MCD_T("1410007x-mac-cyrillic"),
- MCD_T("1000932shifft_jis"),MCD_T("0828596ecma-114"),MCD_T(""),
- MCD_T("0900932shift-jis"),MCD_T("0701256cp1256 1320107x-ia5-swedish"),
- MCD_T("0828597ecma-118"),
- MCD_T("1628596csisolatinarabic1710008x-mac-chinesesimp0600932x-sjis"),MCD_T(""),
- MCD_T("0754936gb18030"),MCD_T("1350221windows-502210712000cp12000"),
- MCD_T("0628596arabic0500936cn-gb0900932sjis-open0712001cp12001"),MCD_T(""),
- MCD_T(""),MCD_T("0700950cn-big50920127iso646-us1001133ibm-cp1133"),MCD_T(""),
- MCD_T("0800936csgb23120900949ks-c-56010310000mac"),
- MCD_T("1001257winbaltrim0750221cp502211020127iso-ir-6us"),
- MCD_T("1000932csshiftjis"),MCD_T("0300936gbk0765001cp65001"),
- MCD_T("1620127iso_646.irv:19911351932windows-519320920001x-cp20001")
- };
- int x_GetEncodingCodePage( MCD_CSTR pszEncoding )
- {
- // redo for completeness, the iconv set, UTF-32, and uppercase
- // Lookup strEncoding in EncodingNameTable and return Windows code page
- int nCodePage = -;
- int nEncLen = MCD_PSZLEN( pszEncoding );
- if ( ! nEncLen )
- nCodePage = MCD_ACP;
- else if ( x_StrNCmp(pszEncoding,MCD_T("UTF-32"),) == )
- nCodePage = MCD_UTF32;
- else if ( nEncLen < )
- {
- MCD_CHAR szEncodingLower[];
- for ( int nEncChar=; nEncChar<nEncLen; ++nEncChar )
- {
- MCD_CHAR cEncChar = pszEncoding[nEncChar];
- szEncodingLower[nEncChar] = (cEncChar>='A' && cEncChar<='Z')? (MCD_CHAR)(cEncChar+('a'-'A')) : cEncChar;
- }
- szEncodingLower[nEncLen] = '\0';
- MCD_PCSZ pEntry = EncodingNameTable[x_Hash(szEncodingLower,sizeof(EncodingNameTable)/sizeof(MCD_PCSZ))];
- while ( *pEntry )
- {
- // e.g. entry: 0565001utf-8 means length 05, code page 65001, encoding name utf-8
- int nEntryLen = (*pEntry - '') * ;
- ++pEntry;
- nEntryLen += (*pEntry - '');
- ++pEntry;
- MCD_PCSZ pCodePage = pEntry;
- pEntry += ;
- if ( nEntryLen == nEncLen && x_StrNCmp(szEncodingLower,pEntry,nEntryLen) == )
- {
- // Convert digits to integer up to code name which always starts with alpha
- nCodePage = MCD_PSZTOL( pCodePage, NULL, );
- break;
- }
- pEntry += nEntryLen;
- }
- }
- return nCodePage;
- }
- #if ! defined(MARKUP_WCHAR)
- bool TextEncoding::CanConvert( MCD_CSTR pszToEncoding, MCD_CSTR pszFromEncoding )
- {
- // Return true if MB to MB conversion is possible
- #if defined(MARKUP_ICONV)
- // iconv_open should fail if either encoding not supported or one is alias for other
- char szTo[], szFrom[];
- iconv_t cd = iconv_open( IConvName(szTo,pszToEncoding), IConvName(szFrom,pszFromEncoding) );
- if ( cd == (iconv_t)- )
- return false;
- iconv_close(cd);
- #else
- int nToCP = x_GetEncodingCodePage( pszToEncoding );
- int nFromCP = x_GetEncodingCodePage( pszFromEncoding );
- if ( nToCP == - || nFromCP == - )
- return false;
- #if defined(MARKUP_WINCONV)
- if ( nToCP == MCD_ACP || nFromCP == MCD_ACP ) // either ACP ANSI?
- {
- int nACP = GetACP();
- if ( nToCP == MCD_ACP )
- nToCP = nACP;
- if ( nFromCP == MCD_ACP )
- nFromCP = nACP;
- }
- #else // no conversion API, but we can do AToUTF8 and UTF8ToA
- if ( nToCP != MCD_UTF8 && nFromCP != MCD_UTF8 ) // either UTF-8?
- return false;
- #endif // no conversion API
- if ( nToCP == nFromCP )
- return false;
- #endif // not ICONV
- return true;
- }
- #endif // not WCHAR
- #if defined(MARKUP_ICONV)
- const char* TextEncoding::IConvName( char* szEncoding, MCD_CSTR pszEncoding )
- {
- // Make upper case char-based name from strEncoding which consists only of characters in the ASCII range
- int nEncChar = ;
- while ( pszEncoding[nEncChar] )
- {
- char cEncChar = (char)pszEncoding[nEncChar];
- szEncoding[nEncChar] = (cEncChar>='a' && cEncChar<='z')? (cEncChar-('a'-'A')) : cEncChar;
- ++nEncChar;
- }
- if ( nEncChar == && x_StrNCmp(szEncoding,"UTF-16",) == )
- {
- szEncoding[nEncChar++] = 'B';
- szEncoding[nEncChar++] = 'E';
- }
- szEncoding[nEncChar] = '\0';
- return szEncoding;
- }
- int TextEncoding::IConv( void* pTo, int nToCharSize, int nFromCharSize )
- {
- // Converts from m_pFrom to pTo
- char szTo[], szFrom[];
- iconv_t cd = iconv_open( IConvName(szTo,m_strToEncoding), IConvName(szFrom,m_strFromEncoding) );
- int nToLenBytes = ;
- if ( cd != (iconv_t)- )
- {
- size_t nFromLenRemaining = (size_t)m_nFromLen * nFromCharSize;
- size_t nToCountRemaining = (size_t)m_nToCount * nToCharSize;
- size_t nToCountRemainingBefore;
- char* pToChar = (char*)pTo;
- char* pFromChar = (char*)m_pFrom;
- char* pToTempBuffer = NULL;
- const size_t nTempBufferSize = ;
- size_t nResult;
- if ( ! pTo )
- {
- pToTempBuffer = new char[nTempBufferSize];
- pToChar = pToTempBuffer;
- nToCountRemaining = nTempBufferSize;
- }
- while ( nFromLenRemaining )
- {
- nToCountRemainingBefore = nToCountRemaining;
- nResult = iconv( cd, &pFromChar, &nFromLenRemaining, &pToChar, &nToCountRemaining );
- nToLenBytes += (int)(nToCountRemainingBefore - nToCountRemaining);
- if ( nResult == (size_t)- )
- {
- int nErrno = errno;
- if ( nErrno == EILSEQ )
- {
- // Bypass bad char, question mark denotes problem in source string
- pFromChar += nFromCharSize;
- nFromLenRemaining -= nFromCharSize;
- if ( nToCharSize == )
- *pToChar = '?';
- else if ( nToCharSize == )
- *((unsigned short*)pToChar) = (unsigned short)'?';
- else if ( nToCharSize == )
- *((unsigned int*)pToChar) = (unsigned int)'?';
- pToChar += nToCharSize;
- nToCountRemaining -= nToCharSize;
- nToLenBytes += nToCharSize;
- size_t nInitFromLen = , nInitToCount = ;
- iconv(cd, NULL, &nInitFromLen ,NULL, &nInitToCount );
- }
- else if ( nErrno == EINVAL )
- break; // incomplete character or shift sequence at end of input
- else if ( nErrno == E2BIG && !pToTempBuffer )
- break; // output buffer full should only happen when using a temp buffer
- }
- else
- m_nFailedChars += nResult;
- if ( pToTempBuffer && nToCountRemaining < )
- {
- nToCountRemaining = nTempBufferSize;
- pToChar = pToTempBuffer;
- }
- }
- if ( pToTempBuffer )
- delete[] pToTempBuffer;
- iconv_close(cd);
- }
- return nToLenBytes / nToCharSize;
- }
- #endif
- #if defined(MARKUP_WINCONV)
- bool x_NoDefaultChar( int nCP )
- {
- // WideCharToMultiByte fails if lpUsedDefaultChar is non-NULL for these code pages:
- return (bool)(nCP == || nCP == || nCP == || nCP == || nCP == || nCP == ||
- nCP == || nCP == || nCP == || nCP == || (nCP >= && nCP <= ) );
- }
- #endif
- int TextEncoding::PerformConversion( void* pTo, MCD_CSTR pszToEncoding/*=NULL*/ )
- {
- // If pTo is not NULL, it must be large enough to hold result, length of result is returned
- // m_nFailedChars will be set to >0 if characters not supported in strToEncoding
- int nToLen = ;
- if ( pszToEncoding.pcsz )
- m_strToEncoding = pszToEncoding;
- int nToCP = x_GetEncodingCodePage( m_strToEncoding );
- if ( nToCP == - )
- nToCP = MCD_ACP;
- int nFromCP = x_GetEncodingCodePage( m_strFromEncoding );
- if ( nFromCP == - )
- nFromCP = MCD_ACP;
- m_nFailedChars = ;
- #if ! defined(MARKUP_WINCONV) && ! defined(MARKUP_ICONV)
- // Only non-Unicode encoding supported is locale charset, must call setlocale
- if ( nToCP != MCD_UTF8 && nToCP != MCD_UTF16 && nToCP != MCD_UTF32 )
- nToCP = MCD_ACP;
- if ( nFromCP != MCD_UTF8 && nFromCP != MCD_UTF16 && nFromCP != MCD_UTF32 )
- nFromCP = MCD_ACP;
- if ( nFromCP == MCD_ACP )
- {
- const char* pA = (const char*)m_pFrom;
- int nALenRemaining = m_nFromLen;
- int nCharLen;
- wchar_t wcChar;
- char* pU = (char*)pTo;
- while ( nALenRemaining )
- {
- nCharLen = mbtowc( &wcChar, pA, nALenRemaining );
- if ( nCharLen < )
- {
- wcChar = (wchar_t)'?';
- nCharLen = ;
- }
- pA += nCharLen;
- nALenRemaining -= nCharLen;
- if ( nToCP == MCD_UTF8 )
- CMarkup::EncodeCharUTF8( (int)wcChar, pU, nToLen );
- else if ( nToCP == MCD_UTF16 )
- CMarkup::EncodeCharUTF16( (int)wcChar, (unsigned short*)pU, nToLen );
- else // UTF32
- {
- if ( pU )
- ((unsigned int*)pU)[nToLen] = (unsigned int)wcChar;
- ++nToLen;
- }
- }
- }
- else if ( nToCP == MCD_ACP )
- {
- union pUnicodeUnion { const char* p8; const unsigned short* p16; const unsigned int* p32; } pU;
- pU.p8 = (const char*)m_pFrom;
- const char* pUEnd = pU.p8 + m_nFromLen;
- if ( nFromCP == MCD_UTF16 )
- pUEnd = (char*)( pU.p16 + m_nFromLen );
- else if ( nFromCP == MCD_UTF32 )
- pUEnd = (char*)( pU.p32 + m_nFromLen );
- int nCharLen;
- char* pA = (char*)pTo;
- char szA[];
- int nUChar;
- while ( pU.p8 != pUEnd )
- {
- if ( nFromCP == MCD_UTF8 )
- nUChar = CMarkup::DecodeCharUTF8( pU.p8, pUEnd );
- else if ( nFromCP == MCD_UTF16 )
- nUChar = CMarkup::DecodeCharUTF16( pU.p16, (const unsigned short*)pUEnd );
- else // UTF32
- nUChar = *(pU.p32)++;
- if ( nUChar == - )
- nCharLen = -;
- else if ( nUChar & ~0xffff )
- nCharLen = -;
- else
- nCharLen = wctomb( pA?pA:szA, (wchar_t)nUChar );
- if ( nCharLen < )
- {
- if ( nCharLen == - )
- ++m_nFailedChars;
- nCharLen = ;
- if ( pA )
- *pA = '?';
- }
- if ( pA )
- pA += nCharLen;
- nToLen += nCharLen;
- }
- }
- #endif // not WINCONV and not ICONV
- if ( nFromCP == MCD_UTF32 )
- {
- const unsigned int* p32 = (const unsigned int*)m_pFrom;
- const unsigned int* p32End = p32 + m_nFromLen;
- if ( nToCP == MCD_UTF8 )
- {
- char* p8 = (char*)pTo;
- while ( p32 != p32End )
- CMarkup::EncodeCharUTF8( *p32++, p8, nToLen );
- }
- else if ( nToCP == MCD_UTF16 )
- {
- unsigned short* p16 = (unsigned short*)pTo;
- while ( p32 != p32End )
- CMarkup::EncodeCharUTF16( (int)*p32++, p16, nToLen );
- }
- else // to ANSI
- {
- // WINCONV not supported for 32To8, since only used for sizeof(wchar_t) == 4
- #if defined(MARKUP_ICONV)
- nToLen = IConv( pTo, , );
- #endif // ICONV
- }
- }
- else if ( nFromCP == MCD_UTF16 )
- {
- // UTF16To8 will be deprecated since weird output buffer size sensitivity not worth implementing here
- const unsigned short* p16 = (const unsigned short*)m_pFrom;
- const unsigned short* p16End = p16 + m_nFromLen;
- int nUChar;
- if ( nToCP == MCD_UTF32 )
- {
- unsigned int* p32 = (unsigned int*)pTo;
- while ( p16 != p16End )
- {
- nUChar = CMarkup::DecodeCharUTF16( p16, p16End );
- if ( nUChar == - )
- nUChar = '?';
- if ( p32 )
- p32[nToLen] = (unsigned int)nUChar;
- ++nToLen;
- }
- }
- #if defined(MARKUP_WINCONV)
- else // to UTF-8 or other multi-byte
- {
- nToLen = WideCharToMultiByte(nToCP,,(const wchar_t*)m_pFrom,m_nFromLen,(char*)pTo,
- m_nToCount?m_nToCount+:,NULL,x_NoDefaultChar(nToCP)?NULL:&m_nFailedChars);
- }
- #else // not WINCONV
- else if ( nToCP == MCD_UTF8 )
- {
- char* p8 = (char*)pTo;
- while ( p16 != p16End )
- {
- nUChar = CMarkup::DecodeCharUTF16( p16, p16End );
- if ( nUChar == - )
- nUChar = '?';
- CMarkup::EncodeCharUTF8( nUChar, p8, nToLen );
- }
- }
- else // to ANSI
- {
- #if defined(MARKUP_ICONV)
- nToLen = IConv( pTo, , );
- #endif // ICONV
- }
- #endif // not WINCONV
- }
- else if ( nToCP == MCD_UTF16 ) // to UTF-16 from UTF-8/ANSI
- {
- #if defined(MARKUP_WINCONV)
- nToLen = MultiByteToWideChar(nFromCP,,(const char*)m_pFrom,m_nFromLen,(wchar_t*)pTo,m_nToCount);
- #else // not WINCONV
- if ( nFromCP == MCD_UTF8 )
- {
- const char* p8 = (const char*)m_pFrom;
- const char* p8End = p8 + m_nFromLen;
- int nUChar;
- unsigned short* p16 = (unsigned short*)pTo;
- while ( p8 != p8End )
- {
- nUChar = CMarkup::DecodeCharUTF8( p8, p8End );
- if ( nUChar == - )
- nUChar = '?';
- if ( p16 )
- p16[nToLen] = (unsigned short)nUChar;
- ++nToLen;
- }
- }
- else // from ANSI
- {
- #if defined(MARKUP_ICONV)
- nToLen = IConv( pTo, , );
- #endif // ICONV
- }
- #endif // not WINCONV
- }
- else if ( nToCP == MCD_UTF32 ) // to UTF-32 from UTF-8/ANSI
- {
- if ( nFromCP == MCD_UTF8 )
- {
- const char* p8 = (const char*)m_pFrom;
- const char* p8End = p8 + m_nFromLen;
- int nUChar;
- unsigned int* p32 = (unsigned int*)pTo;
- while ( p8 != p8End )
- {
- nUChar = CMarkup::DecodeCharUTF8( p8, p8End );
- if ( nUChar == - )
- nUChar = '?';
- if ( p32 )
- p32[nToLen] = (unsigned int)nUChar;
- ++nToLen;
- }
- }
- else // from ANSI
- {
- // WINCONV not supported for ATo32, since only used for sizeof(wchar_t) == 4
- #if defined(MARKUP_ICONV)
- // nToLen = IConv( pTo, 4, 1 );
- // Linux: had trouble getting IConv to leave the BOM off of the UTF-32 output stream
- // So converting via UTF-16 with native endianness
- unsigned short* pwszUTF16 = new unsigned short[m_nFromLen];
- MCD_STR strToEncoding = m_strToEncoding;
- m_strToEncoding = MCD_T("UTF-16BE");
- short nEndianTest = ;
- if ( ((char*)&nEndianTest)[] ) // Little-endian?
- m_strToEncoding = MCD_T("UTF-16LE");
- m_nToCount = m_nFromLen;
- int nUTF16Len = IConv( pwszUTF16, , );
- m_strToEncoding = strToEncoding;
- const unsigned short* p16 = (const unsigned short*)pwszUTF16;
- const unsigned short* p16End = p16 + nUTF16Len;
- int nUChar;
- unsigned int* p32 = (unsigned int*)pTo;
- while ( p16 != p16End )
- {
- nUChar = CMarkup::DecodeCharUTF16( p16, p16End );
- if ( nUChar == - )
- nUChar = '?';
- if ( p32 )
- *p32++ = (unsigned int)nUChar;
- ++nToLen;
- }
- delete[] pwszUTF16;
- #endif // ICONV
- }
- }
- else
- {
- #if defined(MARKUP_ICONV)
- nToLen = IConv( pTo, , );
- #elif defined(MARKUP_WINCONV)
- wchar_t* pwszUTF16 = new wchar_t[m_nFromLen];
- int nUTF16Len = MultiByteToWideChar(nFromCP,,(const char*)m_pFrom,m_nFromLen,pwszUTF16,m_nFromLen);
- nToLen = WideCharToMultiByte(nToCP,,pwszUTF16,nUTF16Len,(char*)pTo,m_nToCount,NULL,
- x_NoDefaultChar(nToCP)?NULL:&m_nFailedChars);
- delete[] pwszUTF16;
- #endif // WINCONV
- }
- // Store the length in case this is called again after allocating output buffer to fit
- m_nToCount = nToLen;
- return nToLen;
- }
- bool TextEncoding::FindRaggedEnd( int& nTruncBeforeBytes )
- {
- // Check for ragged end UTF-16 or multi-byte according to m_strToEncoding, expects at least 40 bytes to work with
- bool bSuccess = true;
- nTruncBeforeBytes = ;
- int nCP = x_GetEncodingCodePage( m_strFromEncoding );
- if ( nCP == MCD_UTF16 )
- {
- unsigned short* pUTF16Buffer = (unsigned short*)m_pFrom;
- const unsigned short* pUTF16Last = &pUTF16Buffer[m_nFromLen-];
- if ( CMarkup::DecodeCharUTF16(pUTF16Last,&pUTF16Buffer[m_nFromLen]) == - )
- nTruncBeforeBytes = ;
- }
- else // UTF-8, SBCS DBCS
- {
- if ( nCP == MCD_UTF8 )
- {
- char* pUTF8Buffer = (char*)m_pFrom;
- char* pUTF8End = &pUTF8Buffer[m_nFromLen];
- int nLast = m_nFromLen - ;
- const char* pUTF8Last = &pUTF8Buffer[nLast];
- while ( nLast > && CMarkup::DecodeCharUTF8(pUTF8Last,pUTF8End) == - )
- pUTF8Last = &pUTF8Buffer[--nLast];
- nTruncBeforeBytes = (int)(pUTF8End - pUTF8Last);
- }
- else
- {
- // Do a conversion-based test unless we can determine it is not multi-byte
- // If m_strEncoding="" default code page then GetACP can tell us the code page, otherwise just do the test
- #if defined(MARKUP_WINCONV)
- if ( nCP == )
- nCP = GetACP();
- #endif
- int nMultibyteCharsToTest = ;
- switch ( nCP )
- {
- case :
- nMultibyteCharsToTest = ;
- case : case : case : case : case : case : case : // Japanese
- case : case : case : case : case : case : // Korean
- case : case : case : case : case : // Taiwan
- case : case : case : case : case : case : case : // EBCDIC
- case : case : case : case : // Chinese
- case : case : case : case : case : case : // Chinese
- nCP = ;
- break;
- }
- if ( nMultibyteCharsToTest > m_nFromLen )
- nMultibyteCharsToTest = m_nFromLen;
- if ( nCP == && nMultibyteCharsToTest )
- {
- /*
- 1. convert the piece to Unicode with MultiByteToWideChar
- 2. Identify at least two Unicode code point boundaries at the end of
- the converted piece by stepping backwards from the end and re-
- converting the final 2 bytes, 3 bytes, 4 bytes etc, comparing the
- converted end string to the end of the entire converted piece to find
- a valid code point boundary.
- 3. Upon finding a code point boundary, I still want to make sure it
- will convert the same separately on either side of the divide as it
- does together, so separately convert the first byte and the remaining
- bytes and see if the result together is the same as the whole end, if
- not try the first two bytes and the remaining bytes. etc., until I
- find a useable dividing point. If none found, go back to step 2 and
- get a longer end string to try.
- */
- m_strToEncoding = MCD_T("UTF-16");
- m_nToCount = m_nFromLen*;
- unsigned short* pUTF16Buffer = new unsigned short[m_nToCount];
- int nUTF16Len = PerformConversion( (void*)pUTF16Buffer );
- int nOriginalByteLen = m_nFromLen;
- // Guaranteed to have at least MARKUP_FILEBLOCKSIZE/2 bytes to work with
- const int nMaxBytesToTry = ;
- unsigned short wsz16End[nMaxBytesToTry*];
- unsigned short wsz16EndDivided[nMaxBytesToTry*];
- const char* pszOriginalBytes = (const char*)m_pFrom;
- int nBoundariesFound = ;
- bSuccess = false;
- while ( nTruncBeforeBytes < nMaxBytesToTry && ! bSuccess )
- {
- ++nTruncBeforeBytes;
- m_pFrom = &pszOriginalBytes[nOriginalByteLen-nTruncBeforeBytes];
- m_nFromLen = nTruncBeforeBytes;
- m_nToCount = nMaxBytesToTry*;
- int nEndUTF16Len = PerformConversion( (void*)wsz16End );
- if ( nEndUTF16Len && memcmp(wsz16End,&pUTF16Buffer[nUTF16Len-nEndUTF16Len],nEndUTF16Len*) == )
- {
- ++nBoundariesFound;
- if ( nBoundariesFound > )
- {
- int nDivideAt = ;
- while ( nDivideAt < nTruncBeforeBytes )
- {
- m_pFrom = &pszOriginalBytes[nOriginalByteLen-nTruncBeforeBytes];
- m_nFromLen = nDivideAt;
- m_nToCount = nMaxBytesToTry*;
- int nDividedUTF16Len = PerformConversion( (void*)wsz16EndDivided );
- if ( nDividedUTF16Len )
- {
- m_pFrom = &pszOriginalBytes[nOriginalByteLen-nTruncBeforeBytes+nDivideAt];
- m_nFromLen = nTruncBeforeBytes-nDivideAt;
- m_nToCount = nMaxBytesToTry*-nDividedUTF16Len;
- nDividedUTF16Len += PerformConversion( (void*)&wsz16EndDivided[nDividedUTF16Len] );
- if ( m_nToCount && nEndUTF16Len == nDividedUTF16Len && memcmp(wsz16End,wsz16EndDivided,nEndUTF16Len) == )
- {
- nTruncBeforeBytes -= nDivideAt;
- bSuccess = true;
- break;
- }
- }
- ++nDivideAt;
- }
- }
- }
- }
- delete [] pUTF16Buffer;
- }
- }
- }
- return bSuccess;
- }
- bool x_EndianSwapRequired( int nDocFlags )
- {
- short nWord = ;
- char cFirstByte = ((char*)&nWord)[];
- if ( cFirstByte ) // LE
- {
- if ( nDocFlags & CMarkup::MDF_UTF16BEFILE )
- return true;
- }
- else if ( nDocFlags & CMarkup::MDF_UTF16LEFILE )
- return true;
- return false;
- }
- void x_EndianSwapUTF16( unsigned short* pBuffer, int nCharLen )
- {
- unsigned short cChar;
- while ( nCharLen-- )
- {
- cChar = pBuffer[nCharLen];
- pBuffer[nCharLen] = (unsigned short)((cChar<<) | (cChar>>));
- }
- }
- //////////////////////////////////////////////////////////////////////
- // Element position indexes
- // This is the primary means of storing the layout of the document
- //
- struct ElemPos
- {
- ElemPos() {};
- ElemPos( const ElemPos& pos ) { *this = pos; };
- int StartTagLen() const { return nStartTagLen; };
- void SetStartTagLen( int n ) { nStartTagLen = n; };
- void AdjustStartTagLen( int n ) { nStartTagLen += n; };
- int EndTagLen() const { return nEndTagLen; };
- void SetEndTagLen( int n ) { nEndTagLen = n; };
- bool IsEmptyElement() { return (StartTagLen()==nLength)?true:false; };
- int StartContent() const { return nStart + StartTagLen(); };
- int ContentLen() const { return nLength - StartTagLen() - EndTagLen(); };
- int StartAfter() const { return nStart + nLength; };
- int Level() const { return nFlags & 0xffff; };
- void SetLevel( int nLev ) { nFlags = (nFlags & ~0xffff) | nLev; };
- void ClearVirtualParent() { memset(this,,sizeof(ElemPos)); };
- void SetEndTagLenUnparsed() { SetEndTagLen(); };
- bool IsUnparsed() { return EndTagLen() == ; };
- // Memory size: 8 32-bit integers == 32 bytes
- int nStart;
- int nLength;
- unsigned int nStartTagLen : ; // 4MB limit for start tag
- unsigned int nEndTagLen : ; // 1K limit for end tag
- int nFlags; // 16 bits flags, 16 bits level 65536 depth limit
- int iElemParent;
- int iElemChild; // first child
- int iElemNext; // next sibling
- int iElemPrev; // if this is first, iElemPrev points to last
- };
- enum MarkupNodeFlagsInternal2
- {
- MNF_REPLACE = 0x001000,
- MNF_QUOTED = 0x008000,
- MNF_EMPTY = 0x010000,
- MNF_DELETED = 0x020000,
- MNF_FIRST = 0x080000,
- MNF_PUBLIC = 0x300000,
- MNF_ILLFORMED = 0x800000,
- MNF_USER = 0xf000000
- };
- struct ElemPosTree
- {
- ElemPosTree() { Clear(); };
- ~ElemPosTree() { Release(); };
- enum { PA_SEGBITS = , PA_SEGMASK = 0xffff };
- void ReleaseElemPosTree() { Release(); Clear(); };
- void Release() { for (int n=;n<SegsUsed();++n) delete[] (char*)m_pSegs[n]; if (m_pSegs) delete[] (char*)m_pSegs; };
- void Clear() { m_nSegs=; m_nSize=; m_pSegs=NULL; };
- int GetSize() const { return m_nSize; };
- int SegsUsed() const { return ((m_nSize-)>>PA_SEGBITS) + ; };
- ElemPos& GetRefElemPosAt(int i) const { return m_pSegs[i>>PA_SEGBITS][i&PA_SEGMASK]; };
- void CopyElemPosTree( ElemPosTree* pOtherTree, int n );
- void GrowElemPosTree( int nNewSize );
- private:
- ElemPos** m_pSegs;
- int m_nSize;
- int m_nSegs;
- };
- void ElemPosTree::CopyElemPosTree( ElemPosTree* pOtherTree, int n )
- {
- ReleaseElemPosTree();
- m_nSize = n;
- if ( m_nSize < )
- m_nSize = ;
- m_nSegs = SegsUsed();
- if ( m_nSegs )
- {
- m_pSegs = (ElemPos**)(new char[m_nSegs*sizeof(char*)]);
- int nSegSize = << PA_SEGBITS;
- for ( int nSeg=; nSeg < m_nSegs; ++nSeg )
- {
- if ( nSeg + == m_nSegs )
- nSegSize = m_nSize - (nSeg << PA_SEGBITS);
- m_pSegs[nSeg] = (ElemPos*)(new char[nSegSize*sizeof(ElemPos)]);
- memcpy( m_pSegs[nSeg], pOtherTree->m_pSegs[nSeg], nSegSize*sizeof(ElemPos) );
- }
- }
- }
- void ElemPosTree::GrowElemPosTree( int nNewSize )
- {
- // Called by x_AllocElemPos when the document is created or the array is filled
- // The ElemPosTree class is implemented using segments to reduce contiguous memory requirements
- // It reduces reallocations (copying of memory) since this only occurs within one segment
- // The "Grow By" algorithm ensures there are no reallocations after 2 segments
- //
- // Grow By: new size can be at most one more complete segment
- int nSeg = (m_nSize?m_nSize-:) >> PA_SEGBITS;
- int nNewSeg = (nNewSize-) >> PA_SEGBITS;
- if ( nNewSeg > nSeg + )
- {
- nNewSeg = nSeg + ;
- nNewSize = (nNewSeg+) << PA_SEGBITS;
- }
- // Allocate array of segments
- if ( m_nSegs <= nNewSeg )
- {
- int nNewSegments = + nNewSeg * ;
- char* pNewSegments = new char[nNewSegments*sizeof(char*)];
- if ( SegsUsed() )
- memcpy( pNewSegments, m_pSegs, SegsUsed()*sizeof(char*) );
- if ( m_pSegs )
- delete[] (char*)m_pSegs;
- m_pSegs = (ElemPos**)pNewSegments;
- m_nSegs = nNewSegments;
- }
- // Calculate segment sizes
- int nSegSize = m_nSize - (nSeg << PA_SEGBITS);
- int nNewSegSize = nNewSize - (nNewSeg << PA_SEGBITS);
- // Complete first segment
- int nFullSegSize = << PA_SEGBITS;
- if ( nSeg < nNewSeg && nSegSize < nFullSegSize )
- {
- char* pNewFirstSeg = new char[ nFullSegSize * sizeof(ElemPos) ];
- if ( nSegSize )
- {
- // Reallocate
- memcpy( pNewFirstSeg, m_pSegs[nSeg], nSegSize * sizeof(ElemPos) );
- delete[] (char*)m_pSegs[nSeg];
- }
- m_pSegs[nSeg] = (ElemPos*)pNewFirstSeg;
- }
- // New segment
- char* pNewSeg = new char[ nNewSegSize * sizeof(ElemPos) ];
- if ( nNewSeg == nSeg && nSegSize )
- {
- // Reallocate
- memcpy( pNewSeg, m_pSegs[nSeg], nSegSize * sizeof(ElemPos) );
- delete[] (char*)m_pSegs[nSeg];
- }
- m_pSegs[nNewSeg] = (ElemPos*)pNewSeg;
- m_nSize = nNewSize;
- }
- #define ELEM(i) m_pElemPosTree->GetRefElemPosAt(i)
- //////////////////////////////////////////////////////////////////////
- // NodePos stores information about an element or node during document creation and parsing
- //
- struct NodePos
- {
- NodePos() {};
- NodePos( int n ) { nNodeFlags=n; nNodeType=; nStart=; nLength=; };
- int nNodeType;
- int nStart;
- int nLength;
- int nNodeFlags;
- MCD_STR strMeta;
- };
- //////////////////////////////////////////////////////////////////////
- // "Is Char" defines
- // Quickly determine if a character matches a limited set
- //
- #define x_ISONEOF(c,f,l,s) ((c>=f&&c<=l)?(int)(s[c-f]):0)
- // classic whitespace " \t\n\r"
- #define x_ISWHITESPACE(c) x_ISONEOF(c,9,32,"\2\3\0\0\4\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1")
- // end of word in a path " =/[]"
- #define x_ISENDPATHWORD(c) x_ISONEOF(c,32,93,"\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\3\0\0\0\0\0\0\0\0\0\0\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\4\0\5")
- // end of a name " \t\n\r/>"
- #define x_ISENDNAME(c) x_ISONEOF(c,9,62,"\2\3\0\0\4\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\5\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1")
- // a small set of chars cannot be second last in attribute value " \t\n\r\"\'"
- #define x_ISNOTSECONDLASTINVAL(c) x_ISONEOF(c,9,39,"\2\3\0\0\4\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\5\0\0\0\0\1")
- // first char of doc type tag name "EAN"
- #define x_ISDOCTYPESTART(c) x_ISONEOF(c,65,78,"\2\0\0\0\1\0\0\0\0\0\0\0\0\3")
- // attrib special char "<&>\"\'"
- #define x_ISATTRIBSPECIAL(c) x_ISONEOF(c,34,62,"\4\0\0\0\2\5\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\3")
- // parsed text special char "<&>"
- #define x_ISSPECIAL(c) x_ISONEOF(c,38,62,"\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\3")
- // end of any name " \t\n\r<>=\\/?!\"';"
- #define x_ISENDANYNAME(c) x_ISONEOF(c,9,92,"\2\3\0\0\4\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\1\1\0\0\0\0\1\0\0\0\0\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\1\5\1\1\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1")
- // end of unquoted attrib value " \t\n\r>"
- #define x_ISENDUNQUOTED(c) x_ISONEOF(c,9,62,"\2\3\0\0\4\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\5")
- // end of attrib name "= \t\n\r>/?"
- #define x_ISENDATTRIBNAME(c) x_ISONEOF(c,9,63,"\3\4\0\0\5\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\1\1\1")
- // start of entity reference "A-Za-Z#_:"
- #define x_ISSTARTENTREF(c) x_ISONEOF(c,35,122,"\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\0\0\0\0\0\1\2\3\4\5\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\0\0\0\1\0\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1")
- // within entity reference "A-Za-Z0-9_:-."
- #define x_ISINENTREF(c) x_ISONEOF(c,45,122,"\1\1\0\1\1\1\1\1\1\1\1\1\1\1\0\0\0\0\0\0\1\2\3\4\5\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\0\0\0\1\0\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1")
- //////////////////////////////////////////////////////////////////////
- // Token struct and tokenizing functions
- // TokenPos handles parsing operations on a constant text pointer
- //
- struct TokenPos
- {
- TokenPos( MCD_CSTR sz, int n, FilePos* p=NULL ) { Clear(); m_pDocText=sz; m_nTokenFlags=n; m_pReaderFilePos=p; };
- void Clear() { m_nL=; m_nR=-; m_nNext=; };
- int Length() const { return m_nR - m_nL + ; };
- MCD_PCSZ GetTokenPtr() const { return &m_pDocText[m_nL]; };
- MCD_STR GetTokenText() const { return MCD_STR( GetTokenPtr(), Length() ); };
- MCD_CHAR NextChar() { m_nNext += MCD_CLEN(&m_pDocText[m_nNext]); return m_pDocText[m_nNext]; };
- int WhitespaceToTag( int n ) { m_nNext = n; if (FindAny()&&m_pDocText[m_nNext]!='<') { m_nNext=n; m_nR=n-; } return m_nNext; };
- bool FindAny()
- {
- // Go to non-whitespace or end
- MCD_CHAR cNext = m_pDocText[m_nNext];
- while ( cNext && x_ISWHITESPACE(cNext) )
- cNext = m_pDocText[++m_nNext];
- m_nL = m_nNext;
- m_nR = m_nNext-;
- return m_pDocText[m_nNext]!='\0';
- };
- bool FindName()
- {
- if ( ! FindAny() ) // go to first non-whitespace
- return false;
- MCD_CHAR cNext = m_pDocText[m_nNext];
- while ( cNext && ! x_ISENDANYNAME(cNext) )
- cNext = NextChar();
- if ( m_nNext == m_nL )
- ++m_nNext; // it is a special char
- m_nR = m_nNext - ;
- return true;
- }
- bool Match( MCD_CSTR szName )
- {
- int nLen = Length();
- return ( (x_StrNCmp( GetTokenPtr(), szName, nLen, m_nTokenFlags & CMarkup::MDF_IGNORECASE ) == )
- && ( szName[nLen] == '\0' || x_ISENDPATHWORD(szName[nLen]) ) );
- };
- bool FindAttrib( MCD_PCSZ pAttrib, int n = , MCD_STR* pstrAttrib = NULL );
- int ParseNode( NodePos& node );
- int m_nL;
- int m_nR;
- int m_nNext;
- MCD_PCSZ m_pDocText;
- int m_nTokenFlags;
- int m_nPreSpaceStart;
- int m_nPreSpaceLength;
- FilePos* m_pReaderFilePos;
- };
- bool TokenPos::FindAttrib( MCD_PCSZ pAttrib, int n/*=0*/, MCD_STR* pstrAttrib/*=NULL*/ )
- {
- // Return true if found, otherwise false and token.m_nNext is new insertion point
- // If pAttrib is NULL find attrib n and leave token at attrib name
- // If pAttrib is given, find matching attrib and leave token at value
- // support non-well-formed attributes e.g. href=/advanced_search?hl=en, nowrap
- // token also holds start and length of preceeding whitespace to support remove
- //
- int nTempPreSpaceStart;
- int nTempPreSpaceLength;
- MCD_CHAR cFirstChar, cNext;
- int nAttrib = -; // starts at tag name
- int nFoundAttribNameR = ;
- bool bAfterEqual = false;
- while ( )
- {
- // Starting at m_nNext, bypass whitespace and find the next token
- nTempPreSpaceStart = m_nNext;
- if ( ! FindAny() )
- break;
- nTempPreSpaceLength = m_nNext - nTempPreSpaceStart;
- // Is it an opening quote?
- cFirstChar = m_pDocText[m_nNext];
- if ( cFirstChar == '\"' || cFirstChar == '\'' )
- {
- m_nTokenFlags |= MNF_QUOTED;
- // Move past opening quote
- ++m_nNext;
- m_nL = m_nNext;
- // Look for closing quote
- cNext = m_pDocText[m_nNext];
- while ( cNext && cNext != cFirstChar )
- cNext = NextChar();
- // Set right to before closing quote
- m_nR = m_nNext - ;
- // Set m_nNext past closing quote unless at end of document
- if ( cNext )
- ++m_nNext;
- }
- else
- {
- m_nTokenFlags &= ~MNF_QUOTED;
- // Go until special char or whitespace
- m_nL = m_nNext;
- cNext = m_pDocText[m_nNext];
- if ( bAfterEqual )
- {
- while ( cNext && ! x_ISENDUNQUOTED(cNext) )
- cNext = NextChar();
- }
- else
- {
- while ( cNext && ! x_ISENDATTRIBNAME(cNext) )
- cNext = NextChar();
- }
- // Adjust end position if it is one special char
- if ( m_nNext == m_nL )
- ++m_nNext; // it is a special char
- m_nR = m_nNext - ;
- }
- if ( ! bAfterEqual && ! (m_nTokenFlags&MNF_QUOTED) )
- {
- // Is it an equal sign?
- MCD_CHAR cChar = m_pDocText[m_nL];
- if ( cChar == '=' )
- {
- bAfterEqual = true;
- continue;
- }
- // Is it the end of the tag?
- if ( cChar == '>' || cChar == '/' || cChar == '?' )
- {
- m_nNext = nTempPreSpaceStart;
- break; // attrib not found
- }
- if ( nFoundAttribNameR )
- break;
- // Attribute name
- if ( nAttrib != - )
- {
- if ( ! pAttrib )
- {
- if ( nAttrib == n )
- {
- // found by number
- if ( pstrAttrib )
- {
- *pstrAttrib = GetTokenText();
- nFoundAttribNameR = m_nR;
- }
- else
- return true;
- }
- }
- else if ( Match(pAttrib) )
- {
- // Matched attrib name, go forward to value
- nFoundAttribNameR = m_nR;
- }
- if ( nFoundAttribNameR ) // either by n or name match
- {
- m_nPreSpaceStart = nTempPreSpaceStart;
- m_nPreSpaceLength = nTempPreSpaceLength;
- }
- }
- ++nAttrib;
- }
- else if ( nFoundAttribNameR )
- break;
- bAfterEqual = false;
- }
- if ( nFoundAttribNameR )
- {
- if ( ! bAfterEqual )
- {
- // when attribute has no value the value is the attribute name
- m_nL = m_nPreSpaceStart + m_nPreSpaceLength;
- m_nR = nFoundAttribNameR;
- m_nNext = nFoundAttribNameR + ;
- }
- return true; // found by name
- }
- return false; // not found
- }
- //////////////////////////////////////////////////////////////////////
- // Element tag stack: an array of TagPos structs to track nested elements
- // This is used during parsing to match end tags with corresponding start tags
- // For x_ParseElem only ElemStack::iTop is used with PushIntoLevel, PopOutOfLevel, and Current
- // For file mode then the full capabilities are used to track counts of sibling tag names for path support
- //
- struct TagPos
- {
- TagPos() { Init(); };
- void SetTagName( MCD_PCSZ pName, int n ) { MCD_STRASSIGN(strTagName,pName,n); };
- void Init( int i=, int n= ) { nCount=; nTagNames=n; iNext=i; iPrev=; nSlot=-; iSlotPrev=; iSlotNext=; };
- void IncCount() { if (nCount) ++nCount; };
- MCD_STR strTagName;
- int nCount;
- int nTagNames;
- int iParent;
- int iNext;
- int iPrev;
- int nSlot;
- int iSlotNext;
- int iSlotPrev;
- };
- struct ElemStack
- {
- enum { LS_TABLESIZE = };
- ElemStack() { iTop=; iUsed=; iPar=; nLevel=; nSize=; pL=NULL; Alloc(); pL[].Init(); InitTable(); };
- ~ElemStack() { if (pL) delete [] pL; };
- TagPos& Current() { return pL[iTop]; };
- void InitTable() { memset(anTable,,sizeof(int)*LS_TABLESIZE); };
- TagPos& NextParent( int& i ) { int iCur=i; i=pL[i].iParent; return pL[iCur]; };
- TagPos& GetRefTagPosAt( int i ) { return pL[i]; };
- void Push( MCD_PCSZ pName, int n ) { ++iUsed; if (iUsed==nSize) Alloc(nSize*); pL[iUsed].SetTagName(pName,n); pL[iUsed].iParent=iPar; iTop=iUsed; };
- void IntoLevel() { iPar = iTop; ++nLevel; };
- void OutOfLevel() { if (iPar!=iTop) Pop(); iPar = pL[iTop].iParent; --nLevel; };
- void PushIntoLevel( MCD_PCSZ pName, int n ) { ++iTop; if (iTop==nSize) Alloc(nSize*); pL[iTop].SetTagName(pName,n); };
- void PopOutOfLevel() { --iTop; };
- void Pop() { iTop = iPar; while (iUsed && pL[iUsed].iParent==iPar) { if (pL[iUsed].nSlot!=-) Unslot(pL[iUsed]); --iUsed; } };
- void Slot( int n ) { pL[iUsed].nSlot=n; int i=anTable[n]; anTable[n]=iUsed; pL[iUsed].iSlotNext=i; if (i) pL[i].iSlotPrev=iUsed; };
- void Unslot( TagPos& lp ) { int n=lp.iSlotNext,p=lp.iSlotPrev; if (n) pL[n].iSlotPrev=p; if (p) pL[p].iSlotNext=n; else anTable[lp.nSlot]=n; };
- static int CalcSlot( MCD_PCSZ pName, int n, bool bIC );
- void PushTagAndCount( TokenPos& token );
- int iTop;
- int nLevel;
- int iPar;
- protected:
- void Alloc( int nNewSize ) { TagPos* pLNew = new TagPos[nNewSize]; Copy(pLNew); nSize=nNewSize; };
- void Copy( TagPos* pLNew ) { for(int n=;n<nSize;++n) pLNew[n]=pL[n]; if (pL) delete [] pL; pL=pLNew; };
- TagPos* pL;
- int iUsed;
- int nSize;
- int anTable[LS_TABLESIZE];
- };
- int ElemStack::CalcSlot( MCD_PCSZ pName, int n, bool bIC )
- {
- // If bIC (ASCII ignore case) then return an ASCII case insensitive hash
- unsigned int nHash = ;
- MCD_PCSZ pEnd = pName + n;
- while ( pName != pEnd )
- {
- nHash += (unsigned int)(*pName);
- if ( bIC && *pName >= 'A' && *pName <= 'Z' )
- nHash += ('a'-'A');
- ++pName;
- }
- return nHash%LS_TABLESIZE;
- }
- void ElemStack::PushTagAndCount( TokenPos& token )
- {
- // Check for a matching tag name at the top level and set current if found or add new one
- // Calculate hash of tag name, support ignore ASCII case for MDF_IGNORECASE
- int nSlot = -;
- int iNext = ;
- MCD_PCSZ pTagName = token.GetTokenPtr();
- if ( iTop != iPar )
- {
- // See if tag name is already used, first try previous sibling (almost always)
- iNext = iTop;
- if ( token.Match(Current().strTagName) )
- {
- iNext = -;
- Current().IncCount();
- }
- else
- {
- nSlot = CalcSlot( pTagName, token.Length(), (token.m_nTokenFlags & CMarkup::MDF_IGNORECASE)?true:false );
- int iLookup = anTable[nSlot];
- while ( iLookup )
- {
- TagPos& tag = pL[iLookup];
- if ( tag.iParent == iPar && token.Match(tag.strTagName) )
- {
- pL[tag.iPrev].iNext = tag.iNext;
- if ( tag.iNext )
- pL[tag.iNext].iPrev = tag.iPrev;
- tag.nTagNames = Current().nTagNames;
- tag.iNext = iTop;
- tag.IncCount();
- iTop = iLookup;
- iNext = -;
- break;
- }
- iLookup = tag.iSlotNext;
- }
- }
- }
- if ( iNext != - )
- {
- // Turn off in the rare case where a document uses unique tag names like record1, record2, etc, more than 256
- int nTagNames = ;
- if ( iNext )
- nTagNames = Current().nTagNames;
- if ( nTagNames == )
- {
- MCD_STRASSIGN( (Current().strTagName), pTagName, (token.Length()) );
- Current().nCount = ;
- Unslot( Current() );
- }
- else
- {
- Push( pTagName, token.Length() );
- Current().Init( iNext, nTagNames+ );
- }
- if ( nSlot == - )
- nSlot = CalcSlot( pTagName, token.Length(), (token.m_nTokenFlags & CMarkup::MDF_IGNORECASE)?true:false );
- Slot( nSlot );
- }
- }
- //////////////////////////////////////////////////////////////////////
- // FilePos is created for a file while it is open
- // In file mode the file stays open between CMarkup calls and is stored in m_pFilePos
- //
- struct FilePos
- {
- FilePos()
- {
- m_fp=NULL; m_nDocFlags=; m_nFileByteLen=; m_nFileByteOffset=; m_nOpFileByteLen=; m_nBlockSizeBasis=MARKUP_FILEBLOCKSIZE;
- m_nFileCharUnitSize=; m_nOpFileTextLen=; m_pstrBuffer=NULL; m_nReadBufferStart=; m_nReadBufferRemoved=; m_nReadGatherStart=-;
- };
- bool FileOpen( MCD_CSTR_FILENAME szFileName );
- bool FileRead( void* pBuffer );
- bool FileReadText( MCD_STR& strDoc );
- bool FileCheckRaggedEnd( void* pBuffer );
- bool FileReadNextBuffer();
- void FileGatherStart( int nStart );
- int FileGatherEnd( MCD_STR& strSubDoc );
- bool FileWrite( void* pBuffer, const void* pConstBuffer = NULL );
- bool FileWriteText( const MCD_STR& strDoc, int nWriteStrLen = - );
- bool FileFlush( MCD_STR& strBuffer, int nWriteStrLen = -, bool bFflush = false );
- bool FileClose();
- void FileSpecifyEncoding( MCD_STR* pstrEncoding );
- bool FileAtTop();
- bool FileErrorAddResult();
- FILE* m_fp;
- int m_nDocFlags;
- int m_nOpFileByteLen;
- int m_nBlockSizeBasis;
- MCD_INTFILEOFFSET m_nFileByteLen;
- MCD_INTFILEOFFSET m_nFileByteOffset;
- int m_nFileCharUnitSize;
- int m_nOpFileTextLen;
- MCD_STR m_strIOResult;
- MCD_STR m_strEncoding;
- MCD_STR* m_pstrBuffer;
- ElemStack m_elemstack;
- int m_nReadBufferStart;
- int m_nReadBufferRemoved;
- int m_nReadGatherStart;
- MCD_STR m_strReadGatherMarkup;
- };
- struct BomTableStruct { const char* pszBom; int nBomLen; MCD_PCSZ pszBomEnc; int nBomFlag; } BomTable[] =
- {
- { "\xef\xbb\xbf", , MCD_T("UTF-8"), CMarkup::MDF_UTF8PREAMBLE },
- { "\xff\xfe", , MCD_T("UTF-16LE"), CMarkup::MDF_UTF16LEFILE },
- { "\xfe\xff", , MCD_T("UTF-16BE"), CMarkup::MDF_UTF16BEFILE },
- { NULL,,NULL, }
- };
- bool FilePos::FileErrorAddResult()
- {
- // strerror has difficulties cross-platform
- // VC++ leaves MCD_STRERROR undefined and uses FormatMessage
- // Non-VC++ use strerror (even for MARKUP_WCHAR and convert)
- // additional notes:
- // _WIN32_WCE (Windows CE) has no strerror (Embedded VC++ uses FormatMessage)
- // _MSC_VER >= 1310 (VC++ 2003/7.1) has _wcserror (but not used)
- //
- const int nErrorBufferSize = ;
- int nErr = ;
- MCD_CHAR szError[nErrorBufferSize+];
- #if defined(MCD_STRERROR) // C error routine
- nErr = (int)errno;
- #if defined(MARKUP_WCHAR)
- char szMBError[nErrorBufferSize+];
- strncpy( szMBError, MCD_STRERROR, nErrorBufferSize );
- szMBError[nErrorBufferSize] = '\0';
- TextEncoding textencoding( MCD_T(""), (const void*)szMBError, strlen(szMBError) );
- textencoding.m_nToCount = nErrorBufferSize;
- int nWideLen = textencoding.PerformConversion( (void*)szError, MCD_ENC );
- szError[nWideLen] = '\0';
- #else
- MCD_PSZNCPY( szError, MCD_STRERROR, nErrorBufferSize );
- szError[nErrorBufferSize] = '\0';
- #endif
- #else // no C error routine, use Windows API
- DWORD dwErr = ::GetLastError();
- if ( ::FormatMessage(0x1200,,dwErr,,szError,nErrorBufferSize,) < )
- szError[] = '\0';
- nErr = (int)dwErr;
- #endif // no C error routine
- MCD_STR strError = szError;
- for ( int nChar=; nChar<MCD_STRLENGTH(strError); ++nChar )
- if ( strError[nChar] == '\r' || strError[nChar] == '\n' )
- {
- strError = MCD_STRMID( strError, , nChar ); // no trailing newline
- break;
- }
- x_AddResult( m_strIOResult, MCD_T("file_error"), strError, MRC_MSG|MRC_NUMBER, nErr );
- return false;
- }
- void FilePos::FileSpecifyEncoding( MCD_STR* pstrEncoding )
- {
- // In ReadTextFile, WriteTextFile and Open, the pstrEncoding argument can override or return the detected encoding
- if ( pstrEncoding && m_strEncoding != *pstrEncoding )
- {
- if ( m_nFileCharUnitSize == && *pstrEncoding != MCD_T("") )
- m_strEncoding = *pstrEncoding; // override the encoding
- else // just report the encoding
- *pstrEncoding = m_strEncoding;
- }
- }
- bool FilePos::FileAtTop()
- {
- // Return true if in the first block of file mode, max BOM < 5 bytes
- if ( ((m_nDocFlags & CMarkup::MDF_READFILE) && m_nFileByteOffset < (MCD_INTFILEOFFSET)m_nOpFileByteLen + )
- || ((m_nDocFlags & CMarkup::MDF_WRITEFILE) && m_nFileByteOffset < ) )
- return true;
- return false;
- }
- bool FilePos::FileOpen( MCD_CSTR_FILENAME szFileName )
- {
- MCD_STRCLEAR( m_strIOResult );
- // Open file
- MCD_PCSZ_FILENAME pMode = MCD_T_FILENAME("rb");
- if ( m_nDocFlags & CMarkup::MDF_APPENDFILE )
- pMode = MCD_T_FILENAME("ab");
- else if ( m_nDocFlags & CMarkup::MDF_WRITEFILE )
- pMode = MCD_T_FILENAME("wb");
- m_fp = NULL;
- MCD_FOPEN( m_fp, szFileName, pMode );
- if ( ! m_fp )
- return FileErrorAddResult();
- // Prepare file
- bool bSuccess = true;
- int nBomLen = ;
- m_nFileCharUnitSize = ; // unless UTF-16 BOM
- if ( m_nDocFlags & CMarkup::MDF_READFILE )
- {
- // Get file length
- MCD_FSEEK( m_fp, , SEEK_END );
- m_nFileByteLen = MCD_FTELL( m_fp );
- MCD_FSEEK( m_fp, , SEEK_SET );
- // Read the top of the file to check BOM and encoding
- int nReadTop = ;
- if ( m_nFileByteLen < nReadTop )
- nReadTop = (int)m_nFileByteLen;
- if ( nReadTop )
- {
- char* pFileTop = new char[nReadTop];
- if ( nReadTop )
- bSuccess = ( fread( pFileTop, nReadTop, , m_fp ) == );
- if ( bSuccess )
- {
- // Check for Byte Order Mark (preamble)
- int nBomCheck = ;
- m_nDocFlags &= ~( CMarkup::MDF_UTF16LEFILE | CMarkup::MDF_UTF8PREAMBLE );
- while ( BomTable[nBomCheck].pszBom )
- {
- while ( nBomLen < BomTable[nBomCheck].nBomLen )
- {
- if ( nBomLen >= nReadTop || pFileTop[nBomLen] != BomTable[nBomCheck].pszBom[nBomLen] )
- break;
- ++nBomLen;
- }
- if ( nBomLen == BomTable[nBomCheck].nBomLen )
- {
- m_nDocFlags |= BomTable[nBomCheck].nBomFlag;
- if ( nBomLen == )
- m_nFileCharUnitSize = ;
- m_strEncoding = BomTable[nBomCheck].pszBomEnc;
- break;
- }
- ++nBomCheck;
- nBomLen = ;
- }
- if ( nReadTop > nBomLen )
- MCD_FSEEK( m_fp, nBomLen, SEEK_SET );
- // Encoding check
- if ( ! nBomLen )
- {
- MCD_STR strDeclCheck;
- #if defined(MARKUP_WCHAR) // WCHAR
- TextEncoding textencoding( MCD_T("UTF-8"), (const void*)pFileTop, nReadTop );
- MCD_CHAR* pWideBuffer = MCD_GETBUFFER(strDeclCheck,nReadTop);
- textencoding.m_nToCount = nReadTop;
- int nDeclWideLen = textencoding.PerformConversion( (void*)pWideBuffer, MCD_ENC );
- MCD_RELEASEBUFFER(strDeclCheck,pWideBuffer,nDeclWideLen);
- #else // not WCHAR
- MCD_STRASSIGN(strDeclCheck,pFileTop,nReadTop);
- #endif // not WCHAR
- m_strEncoding = CMarkup::GetDeclaredEncoding( strDeclCheck );
- }
- // Assume markup files starting with < sign are UTF-8 if otherwise unknown
- if ( MCD_STRISEMPTY(m_strEncoding) && pFileTop[] == '<' )
- m_strEncoding = MCD_T("UTF-8");
- }
- delete [] pFileTop;
- }
- }
- else if ( m_nDocFlags & CMarkup::MDF_WRITEFILE )
- {
- if ( m_nDocFlags & CMarkup::MDF_APPENDFILE )
- {
- // fopen for append does not move the file pointer to the end until first I/O operation
- MCD_FSEEK( m_fp, , SEEK_END );
- m_nFileByteLen = MCD_FTELL( m_fp );
- }
- int nBomCheck = ;
- while ( BomTable[nBomCheck].pszBom )
- {
- if ( m_nDocFlags & BomTable[nBomCheck].nBomFlag )
- {
- nBomLen = BomTable[nBomCheck].nBomLen;
- if ( nBomLen == )
- m_nFileCharUnitSize = ;
- m_strEncoding = BomTable[nBomCheck].pszBomEnc;
- if ( m_nFileByteLen ) // append
- nBomLen = ;
- else // write BOM
- bSuccess = ( fwrite(BomTable[nBomCheck].pszBom,nBomLen,,m_fp) == );
- break;
- }
- ++nBomCheck;
- }
- }
- if ( ! bSuccess )
- return FileErrorAddResult();
- if ( m_nDocFlags & CMarkup::MDF_APPENDFILE )
- m_nFileByteOffset = m_nFileByteLen;
- else
- m_nFileByteOffset = (MCD_INTFILEOFFSET)nBomLen;
- if ( nBomLen )
- x_AddResult( m_strIOResult, MCD_T("bom") );
- return bSuccess;
- }
- bool FilePos::FileRead( void* pBuffer )
- {
- bool bSuccess = ( fread( pBuffer,m_nOpFileByteLen,,m_fp) == );
- m_nOpFileTextLen = m_nOpFileByteLen / m_nFileCharUnitSize;
- if ( bSuccess )
- {
- m_nFileByteOffset += m_nOpFileByteLen;
- x_AddResult( m_strIOResult, MCD_T("read"), m_strEncoding, MRC_ENCODING|MRC_LENGTH, m_nOpFileTextLen );
- // Microsoft components can produce apparently valid docs with some nulls at ends of values
- int nNullCount = ;
- int nNullCheckCharsRemaining = m_nOpFileTextLen;
- char* pAfterNull = NULL;
- char* pNullScan = (char*)pBuffer;
- bool bSingleByteChar = m_nFileCharUnitSize == ;
- while ( nNullCheckCharsRemaining-- )
- {
- if ( bSingleByteChar? (! *pNullScan) : (! (*(unsigned short*)pNullScan)) )
- {
- if ( pAfterNull && pNullScan != pAfterNull )
- memmove( pAfterNull - (nNullCount*m_nFileCharUnitSize), pAfterNull, pNullScan - pAfterNull );
- pAfterNull = pNullScan + m_nFileCharUnitSize;
- ++nNullCount;
- }
- pNullScan += m_nFileCharUnitSize;
- }
- if ( pAfterNull && pNullScan != pAfterNull )
- memmove( pAfterNull - (nNullCount*m_nFileCharUnitSize), pAfterNull, pNullScan - pAfterNull );
- if ( nNullCount )
- {
- x_AddResult( m_strIOResult, MCD_T("nulls_removed"), NULL, MRC_COUNT, nNullCount );
- m_nOpFileTextLen -= nNullCount;
- }
- // Big endian/little endian conversion
- if ( m_nFileCharUnitSize > && x_EndianSwapRequired(m_nDocFlags) )
- {
- x_EndianSwapUTF16( (unsigned short*)pBuffer, m_nOpFileTextLen );
- x_AddResult( m_strIOResult, MCD_T("endian_swap") );
- }
- }
- if ( ! bSuccess )
- FileErrorAddResult();
- return bSuccess;
- }
- bool FilePos::FileCheckRaggedEnd( void* pBuffer )
- {
- // In file read mode, piece of file text in memory must end on a character boundary
- // This check must happen after the encoding has been decided, so after UTF-8 autodetection
- // If ragged, adjust file position, m_nOpFileTextLen and m_nOpFileByteLen
- int nTruncBeforeBytes = ;
- TextEncoding textencoding( m_strEncoding, pBuffer, m_nOpFileTextLen );
- if ( ! textencoding.FindRaggedEnd(nTruncBeforeBytes) )
- {
- // Input must be garbled? decoding error before potentially ragged end, add error result and continue
- MCD_STR strEncoding = m_strEncoding;
- if ( MCD_STRISEMPTY(strEncoding) )
- strEncoding = MCD_T("ANSI");
- x_AddResult( m_strIOResult, MCD_T("truncation_error"), strEncoding, MRC_ENCODING );
- }
- else if ( nTruncBeforeBytes )
- {
- nTruncBeforeBytes *= -;
- m_nFileByteOffset += nTruncBeforeBytes;
- MCD_FSEEK( m_fp, m_nFileByteOffset, SEEK_SET );
- m_nOpFileByteLen += nTruncBeforeBytes;
- m_nOpFileTextLen += nTruncBeforeBytes / m_nFileCharUnitSize;
- x_AddResult( m_strIOResult, MCD_T("read"), NULL, MRC_MODIFY|MRC_LENGTH, m_nOpFileTextLen );
- }
- return true;
- }
- bool FilePos::FileReadText( MCD_STR& strDoc )
- {
- bool bSuccess = true;
- MCD_STRCLEAR( m_strIOResult );
- if ( ! m_nOpFileByteLen )
- {
- x_AddResult( m_strIOResult, MCD_T("read"), m_strEncoding, MRC_ENCODING|MRC_LENGTH, );
- return bSuccess;
- }
- // Only read up to end of file (a single read byte length cannot be over the capacity of int)
- bool bCheckRaggedEnd = true;
- MCD_INTFILEOFFSET nBytesRemaining = m_nFileByteLen - m_nFileByteOffset;
- if ( (MCD_INTFILEOFFSET)m_nOpFileByteLen >= nBytesRemaining )
- {
- m_nOpFileByteLen = (int)nBytesRemaining;
- bCheckRaggedEnd = false;
- }
- if ( m_nDocFlags & (CMarkup::MDF_UTF16LEFILE | CMarkup::MDF_UTF16BEFILE) )
- {
- int nUTF16Len = m_nOpFileByteLen / ;
- #if defined(MARKUP_WCHAR) // WCHAR
- int nBufferSizeForGrow = nUTF16Len + nUTF16Len/; // extra 1%
- #if MARKUP_SIZEOFWCHAR == 4 // sizeof(wchar_t) == 4
- unsigned short* pUTF16Buffer = new unsigned short[nUTF16Len+];
- bSuccess = FileRead( pUTF16Buffer );
- if ( bSuccess )
- {
- if ( bCheckRaggedEnd )
- FileCheckRaggedEnd( (void*)pUTF16Buffer );
- TextEncoding textencoding( MCD_T("UTF-16"), (const void*)pUTF16Buffer, m_nOpFileTextLen );
- textencoding.m_nToCount = nBufferSizeForGrow;
- MCD_CHAR* pUTF32Buffer = MCD_GETBUFFER(strDoc,nBufferSizeForGrow);
- int nUTF32Len = textencoding.PerformConversion( (void*)pUTF32Buffer, MCD_T("UTF-32") );
- MCD_RELEASEBUFFER(strDoc,pUTF32Buffer,nUTF32Len);
- x_AddResult( m_strIOResult, MCD_T("converted_to"), MCD_T("UTF-32"), MRC_ENCODING|MRC_LENGTH, nUTF32Len );
- }
- #else // sizeof(wchar_t) == 2
- MCD_CHAR* pUTF16Buffer = MCD_GETBUFFER(strDoc,nBufferSizeForGrow);
- bSuccess = FileRead( pUTF16Buffer );
- if ( bSuccess && bCheckRaggedEnd )
- FileCheckRaggedEnd( (void*)pUTF16Buffer );
- MCD_RELEASEBUFFER(strDoc,pUTF16Buffer,m_nOpFileTextLen);
- #endif // sizeof(wchar_t) == 2
- #else // not WCHAR
- // Convert file from UTF-16; it needs to be in memory as UTF-8 or MBCS
- unsigned short* pUTF16Buffer = new unsigned short[nUTF16Len+];
- bSuccess = FileRead( pUTF16Buffer );
- if ( bSuccess && bCheckRaggedEnd )
- FileCheckRaggedEnd( (void*)pUTF16Buffer );
- TextEncoding textencoding( MCD_T("UTF-16"), (const void*)pUTF16Buffer, m_nOpFileTextLen );
- int nMBLen = textencoding.PerformConversion( NULL, MCD_ENC );
- int nBufferSizeForGrow = nMBLen + nMBLen/; // extra 1%
- MCD_CHAR* pMBBuffer = MCD_GETBUFFER(strDoc,nBufferSizeForGrow);
- textencoding.PerformConversion( (void*)pMBBuffer );
- delete [] pUTF16Buffer;
- MCD_RELEASEBUFFER(strDoc,pMBBuffer,nMBLen);
- x_AddResult( m_strIOResult, MCD_T("converted_to"), MCD_ENC, MRC_ENCODING|MRC_LENGTH, nMBLen );
- if ( textencoding.m_nFailedChars )
- x_AddResult( m_strIOResult, MCD_T("conversion_loss") );
- #endif // not WCHAR
- }
- else // single or multibyte file (i.e. not UTF-16)
- {
- #if defined(MARKUP_WCHAR) // WCHAR
- char* pBuffer = new char[m_nOpFileByteLen];
- bSuccess = FileRead( pBuffer );
- if ( MCD_STRISEMPTY(m_strEncoding) )
- {
- int nNonASCII;
- bool bErrorAtEnd;
- if ( CMarkup::DetectUTF8(pBuffer,m_nOpFileByteLen,&nNonASCII,&bErrorAtEnd) || (bCheckRaggedEnd && bErrorAtEnd) )
- {
- m_strEncoding = MCD_T("UTF-8");
- x_AddResult( m_strIOResult, MCD_T("read"), m_strEncoding, MRC_MODIFY|MRC_ENCODING );
- }
- x_AddResult( m_strIOResult, MCD_T("utf8_detection") );
- }
- if ( bSuccess && bCheckRaggedEnd )
- FileCheckRaggedEnd( (void*)pBuffer );
- TextEncoding textencoding( m_strEncoding, (const void*)pBuffer, m_nOpFileTextLen );
- int nWideLen = textencoding.PerformConversion( NULL, MCD_ENC );
- int nBufferSizeForGrow = nWideLen + nWideLen/; // extra 1%
- MCD_CHAR* pWideBuffer = MCD_GETBUFFER(strDoc,nBufferSizeForGrow);
- textencoding.PerformConversion( (void*)pWideBuffer );
- MCD_RELEASEBUFFER( strDoc, pWideBuffer, nWideLen );
- delete [] pBuffer;
- x_AddResult( m_strIOResult, MCD_T("converted_to"), MCD_ENC, MRC_ENCODING|MRC_LENGTH, nWideLen );
- #else // not WCHAR
- // After loading a file with unknown multi-byte encoding
- bool bAssumeUnknownIsNative = false;
- if ( MCD_STRISEMPTY(m_strEncoding) )
- {
- bAssumeUnknownIsNative = true;
- m_strEncoding = MCD_ENC;
- }
- if ( TextEncoding::CanConvert(MCD_ENC,m_strEncoding) )
- {
- char* pBuffer = new char[m_nOpFileByteLen];
- bSuccess = FileRead( pBuffer );
- if ( bSuccess && bCheckRaggedEnd )
- FileCheckRaggedEnd( (void*)pBuffer );
- TextEncoding textencoding( m_strEncoding, (const void*)pBuffer, m_nOpFileTextLen );
- int nMBLen = textencoding.PerformConversion( NULL, MCD_ENC );
- int nBufferSizeForGrow = nMBLen + nMBLen/; // extra 1%
- MCD_CHAR* pMBBuffer = MCD_GETBUFFER(strDoc,nBufferSizeForGrow);
- textencoding.PerformConversion( (void*)pMBBuffer );
- MCD_RELEASEBUFFER( strDoc, pMBBuffer, nMBLen );
- delete [] pBuffer;
- x_AddResult( m_strIOResult, MCD_T("converted_to"), MCD_ENC, MRC_ENCODING|MRC_LENGTH, nMBLen );
- if ( textencoding.m_nFailedChars )
- x_AddResult( m_strIOResult, MCD_T("conversion_loss") );
- }
- else // load directly into string
- {
- int nBufferSizeForGrow = m_nOpFileByteLen + m_nOpFileByteLen/; // extra 1%
- MCD_CHAR* pBuffer = MCD_GETBUFFER(strDoc,nBufferSizeForGrow);
- bSuccess = FileRead( pBuffer );
- bool bConvertMB = false;
- if ( bAssumeUnknownIsNative )
- {
- // Might need additional conversion if we assumed an encoding
- int nNonASCII;
- bool bErrorAtEnd;
- bool bIsUTF8 = CMarkup::DetectUTF8( pBuffer, m_nOpFileByteLen, &nNonASCII, &bErrorAtEnd ) || (bCheckRaggedEnd && bErrorAtEnd);
- MCD_STR strDetectedEncoding = bIsUTF8? MCD_T("UTF-8"): MCD_T("");
- if ( nNonASCII && m_strEncoding != strDetectedEncoding ) // only need to convert non-ASCII
- bConvertMB = true;
- m_strEncoding = strDetectedEncoding;
- if ( bIsUTF8 )
- x_AddResult( m_strIOResult, MCD_T("read"), m_strEncoding, MRC_MODIFY|MRC_ENCODING );
- }
- if ( bSuccess && bCheckRaggedEnd )
- FileCheckRaggedEnd( (void*)pBuffer );
- MCD_RELEASEBUFFER( strDoc, pBuffer, m_nOpFileTextLen );
- if ( bConvertMB )
- {
- TextEncoding textencoding( m_strEncoding, MCD_2PCSZ(strDoc), m_nOpFileTextLen );
- int nMBLen = textencoding.PerformConversion( NULL, MCD_ENC );
- nBufferSizeForGrow = nMBLen + nMBLen/; // extra 1%
- MCD_STR strConvDoc;
- pBuffer = MCD_GETBUFFER(strConvDoc,nBufferSizeForGrow);
- textencoding.PerformConversion( (void*)pBuffer );
- MCD_RELEASEBUFFER( strConvDoc, pBuffer, nMBLen );
- strDoc = strConvDoc;
- x_AddResult( m_strIOResult, MCD_T("converted_to"), MCD_ENC, MRC_ENCODING|MRC_LENGTH, nMBLen );
- if ( textencoding.m_nFailedChars )
- x_AddResult( m_strIOResult, MCD_T("conversion_loss") );
- }
- if ( bAssumeUnknownIsNative )
- x_AddResult( m_strIOResult, MCD_T("utf8_detection") );
- }
- #endif // not WCHAR
- }
- return bSuccess;
- }
- bool FilePos::FileWrite( void* pBuffer, const void* pConstBuffer /*=NULL*/ )
- {
- m_nOpFileByteLen = m_nOpFileTextLen * m_nFileCharUnitSize;
- if ( ! pConstBuffer )
- pConstBuffer = pBuffer;
- unsigned short* pTempEndianBuffer = NULL;
- if ( x_EndianSwapRequired(m_nDocFlags) )
- {
- if ( ! pBuffer )
- {
- pTempEndianBuffer = new unsigned short[m_nOpFileTextLen];
- memcpy( pTempEndianBuffer, pConstBuffer, m_nOpFileTextLen * );
- pBuffer = pTempEndianBuffer;
- pConstBuffer = pTempEndianBuffer;
- }
- x_EndianSwapUTF16( (unsigned short*)pBuffer, m_nOpFileTextLen );
- x_AddResult( m_strIOResult, MCD_T("endian_swap") );
- }
- bool bSuccess = ( fwrite( pConstBuffer, m_nOpFileByteLen, , m_fp ) == );
- if ( pTempEndianBuffer )
- delete [] pTempEndianBuffer;
- if ( bSuccess )
- {
- m_nFileByteOffset += m_nOpFileByteLen;
- x_AddResult( m_strIOResult, MCD_T("write"), m_strEncoding, MRC_ENCODING|MRC_LENGTH, m_nOpFileTextLen );
- }
- else
- FileErrorAddResult();
- return bSuccess;
- }
- bool FilePos::FileWriteText( const MCD_STR& strDoc, int nWriteStrLen/*=-1*/ )
- {
- bool bSuccess = true;
- MCD_STRCLEAR( m_strIOResult );
- MCD_PCSZ pDoc = MCD_2PCSZ(strDoc);
- if ( nWriteStrLen == - )
- nWriteStrLen = MCD_STRLENGTH(strDoc);
- if ( ! nWriteStrLen )
- {
- x_AddResult( m_strIOResult, MCD_T("write"), m_strEncoding, MRC_ENCODING|MRC_LENGTH, );
- return bSuccess;
- }
- if ( m_nDocFlags & (CMarkup::MDF_UTF16LEFILE | CMarkup::MDF_UTF16BEFILE) )
- {
- #if defined(MARKUP_WCHAR) // WCHAR
- #if MARKUP_SIZEOFWCHAR == 4 // sizeof(wchar_t) == 4
- TextEncoding textencoding( MCD_T("UTF-32"), (const void*)pDoc, nWriteStrLen );
- m_nOpFileTextLen = textencoding.PerformConversion( NULL, MCD_T("UTF-16") );
- unsigned short* pUTF16Buffer = new unsigned short[m_nOpFileTextLen];
- textencoding.PerformConversion( (void*)pUTF16Buffer );
- x_AddResult( m_strIOResult, MCD_T("converted_from"), MCD_T("UTF-32"), MRC_ENCODING|MRC_LENGTH, nWriteStrLen );
- bSuccess = FileWrite( pUTF16Buffer );
- delete [] pUTF16Buffer;
- #else // sizeof(wchar_t) == 2
- m_nOpFileTextLen = nWriteStrLen;
- bSuccess = FileWrite( NULL, pDoc );
- #endif
- #else // not WCHAR
- TextEncoding textencoding( MCD_ENC, (const void*)pDoc, nWriteStrLen );
- m_nOpFileTextLen = textencoding.PerformConversion( NULL, MCD_T("UTF-16") );
- unsigned short* pUTF16Buffer = new unsigned short[m_nOpFileTextLen];
- textencoding.PerformConversion( (void*)pUTF16Buffer );
- x_AddResult( m_strIOResult, MCD_T("converted_from"), MCD_ENC, MRC_ENCODING|MRC_LENGTH, nWriteStrLen );
- bSuccess = FileWrite( pUTF16Buffer );
- delete [] pUTF16Buffer;
- #endif // not WCHAR
- }
- else // single or multibyte file (i.e. not UTF-16)
- {
- #if ! defined(MARKUP_WCHAR) // not WCHAR
- if ( ! TextEncoding::CanConvert(m_strEncoding,MCD_ENC) )
- {
- // Same or unsupported multi-byte to multi-byte, so save directly from string
- m_nOpFileTextLen = nWriteStrLen;
- bSuccess = FileWrite( NULL, pDoc );
- return bSuccess;
- }
- #endif // not WCHAR
- TextEncoding textencoding( MCD_ENC, (const void*)pDoc, nWriteStrLen );
- m_nOpFileTextLen = textencoding.PerformConversion( NULL, m_strEncoding );
- char* pMBBuffer = new char[m_nOpFileTextLen];
- textencoding.PerformConversion( (void*)pMBBuffer );
- x_AddResult( m_strIOResult, MCD_T("converted_from"), MCD_ENC, MRC_ENCODING|MRC_LENGTH, nWriteStrLen );
- if ( textencoding.m_nFailedChars )
- x_AddResult( m_strIOResult, MCD_T("conversion_loss") );
- bSuccess = FileWrite( pMBBuffer );
- delete [] pMBBuffer;
- }
- return bSuccess;
- }
- bool FilePos::FileClose()
- {
- if ( m_fp )
- {
- if ( fclose(m_fp) )
- FileErrorAddResult();
- m_fp = NULL;
- m_nDocFlags &= ~(CMarkup::MDF_WRITEFILE|CMarkup::MDF_READFILE|CMarkup::MDF_APPENDFILE);
- return true;
- }
- return false;
- }
- bool FilePos::FileReadNextBuffer()
- {
- // If not end of file, returns amount to subtract from offsets
- if ( m_nFileByteOffset < m_nFileByteLen )
- {
- // Prepare to put this node at beginning
- MCD_STR& str = *m_pstrBuffer;
- int nDocLength = MCD_STRLENGTH( str );
- int nRemove = m_nReadBufferStart;
- m_nReadBufferRemoved = nRemove;
- // Gather
- if ( m_nReadGatherStart != - )
- {
- if ( m_nReadBufferStart > m_nReadGatherStart )
- {
- // In case it is a large subdoc, reduce reallocs by using x_StrInsertReplace
- MCD_STR strAppend = MCD_STRMID( str, m_nReadGatherStart, m_nReadBufferStart - m_nReadGatherStart );
- x_StrInsertReplace( m_strReadGatherMarkup, MCD_STRLENGTH(m_strReadGatherMarkup), , strAppend );
- }
- m_nReadGatherStart = ;
- }
- // Increase capacity if keeping more than half of nDocLength
- int nKeepLength = nDocLength - nRemove;
- if ( nKeepLength > nDocLength / )
- m_nBlockSizeBasis *= ;
- if ( nRemove )
- x_StrInsertReplace( str, , nRemove, MCD_STR() );
- MCD_STR strRead;
- m_nOpFileByteLen = m_nBlockSizeBasis - nKeepLength;
- m_nOpFileByteLen += - m_nOpFileByteLen % ; // round up to 4-byte offset
- FileReadText( strRead );
- x_StrInsertReplace( str, nKeepLength, , strRead );
- m_nReadBufferStart = ; // next time just elongate/increase capacity
- return true;
- }
- return false;
- }
- void FilePos::FileGatherStart( int nStart )
- {
- m_nReadGatherStart = nStart;
- }
- int FilePos::FileGatherEnd( MCD_STR& strMarkup )
- {
- int nStart = m_nReadGatherStart;
- m_nReadGatherStart = -;
- strMarkup = m_strReadGatherMarkup;
- MCD_STRCLEAR( m_strReadGatherMarkup );
- return nStart;
- }
- bool FilePos::FileFlush( MCD_STR& strBuffer, int nWriteStrLen/*=-1*/, bool bFflush/*=false*/ )
- {
- bool bSuccess = true;
- MCD_STRCLEAR( m_strIOResult );
- if ( nWriteStrLen == - )
- nWriteStrLen = MCD_STRLENGTH( strBuffer );
- if ( nWriteStrLen )
- {
- if ( (! m_nFileByteOffset) && MCD_STRISEMPTY(m_strEncoding) && ! MCD_STRISEMPTY(strBuffer) )
- {
- m_strEncoding = CMarkup::GetDeclaredEncoding( strBuffer );
- if ( MCD_STRISEMPTY(m_strEncoding) )
- m_strEncoding = MCD_T("UTF-8");
- }
- bSuccess = FileWriteText( strBuffer, nWriteStrLen );
- if ( bSuccess )
- x_StrInsertReplace( strBuffer, , nWriteStrLen, MCD_STR() );
- }
- if ( bFflush && bSuccess )
- {
- if ( fflush(m_fp) )
- bSuccess = FileErrorAddResult();
- }
- return bSuccess;
- }
- //////////////////////////////////////////////////////////////////////
- // PathPos encapsulates parsing of the path string used in Find methods
- //
- struct PathPos
- {
- PathPos( MCD_PCSZ pszPath, bool b ) { p=pszPath; bReader=b; i=; iPathAttribName=; iSave=; nPathType=; if (!ParsePath()) nPathType=-; };
- int GetTypeAndInc() { i=-; if (p) { if (p[]=='/') { if (p[]=='/') i=; else i=; } else if (p[]) i=; } nPathType=i+; return nPathType; };
- int GetNumAndInc() { int n=; while (p[i]>=''&&p[i]<='') n=n*+(int)p[i++]-(int)''; return n; };
- MCD_PCSZ GetValAndInc() { ++i; MCD_CHAR cEnd=']'; if (p[i]=='\''||p[i]=='\"') cEnd=p[i++]; int iVal=i; IncWord(cEnd); nLen=i-iVal; if (cEnd!=']') ++i; return &p[iVal]; };
- int GetValOrWordLen() { return nLen; };
- MCD_CHAR GetChar() { return p[i]; };
- bool IsAtPathEnd() { return ((!p[i])||(iPathAttribName&&i+>=iPathAttribName))?true:false; };
- MCD_PCSZ GetPtr() { return &p[i]; };
- void SaveOffset() { iSave=i; };
- void RevertOffset() { i=iSave; };
- void RevertOffsetAsName() { i=iSave; nPathType=; };
- MCD_PCSZ GetWordAndInc() { int iWord=i; IncWord(); nLen=i-iWord; return &p[iWord]; };
- void IncWord() { while (p[i]&&!x_ISENDPATHWORD(p[i])) i+=MCD_CLEN(&p[i]); };
- void IncWord( MCD_CHAR c ) { while (p[i]&&p[i]!=c) i+=MCD_CLEN(&p[i]); };
- void IncChar() { ++i; };
- void Inc( int n ) { i+=n; };
- bool IsAnywherePath() { return nPathType == ; };
- bool IsAbsolutePath() { return nPathType == ; };
- bool IsPath() { return nPathType > ; };
- bool ValidPath() { return nPathType != -; };
- MCD_PCSZ GetPathAttribName() { if (iPathAttribName) return &p[iPathAttribName]; return NULL; };
- bool AttribPredicateMatch( TokenPos& token );
- private:
- bool ParsePath();
- int nPathType; // -1 invalid, 0 empty, 1 name, 2 absolute path, 3 anywhere path
- bool bReader;
- MCD_PCSZ p;
- int i;
- int iPathAttribName;
- int iSave;
- int nLen;
- };
- bool PathPos::ParsePath()
- {
- // Determine if the path seems to be in a valid format before attempting to find
- if ( GetTypeAndInc() )
- {
- SaveOffset();
- while ( )
- {
- if ( ! GetChar() )
- return false;
- IncWord(); // Tag name
- if ( GetChar() == '[' ) // predicate
- {
- IncChar(); // [
- if ( GetChar() >= '' && GetChar() <= '' )
- GetNumAndInc();
- else // attrib or child tag name
- {
- if ( GetChar() == '@' )
- {
- IncChar(); // @
- IncWord(); // attrib name
- if ( GetChar() == '=' )
- GetValAndInc();
- }
- else
- {
- if ( bReader )
- return false;
- IncWord();
- }
- }
- if ( GetChar() != ']' )
- return false;
- IncChar(); // ]
- }
- // Another level of path
- if ( GetChar() == '/' )
- {
- if ( IsAnywherePath() )
- return false; // multiple levels not supported for // path
- IncChar();
- if ( GetChar() == '@' )
- {
- // FindGetData and FindSetData support paths ending in attribute
- IncChar(); // @
- iPathAttribName = i;
- IncWord(); // attrib name
- if ( GetChar() )
- return false; // it should have ended with attribute name
- break;
- }
- }
- else
- {
- if ( GetChar() )
- return false; // not a slash, so it should have ended here
- break;
- }
- }
- RevertOffset();
- }
- return true;
- }
- bool PathPos::AttribPredicateMatch( TokenPos& token )
- {
- // Support attribute predicate matching in regular and file read mode
- // token.m_nNext must already be set to node.nStart + 1 or ELEM(i).nStart + 1
- IncChar(); // @
- if ( token.FindAttrib(GetPtr()) )
- {
- IncWord();
- if ( GetChar() == '=' )
- {
- MCD_PCSZ pszVal = GetValAndInc();
- MCD_STR strPathValue = CMarkup::UnescapeText( pszVal, GetValOrWordLen() );
- MCD_STR strAttribValue = CMarkup::UnescapeText( token.GetTokenPtr(), token.Length(), token.m_nTokenFlags );
- if ( strPathValue != strAttribValue )
- return false;
- }
- return true;
- }
- return false;
- }
- //////////////////////////////////////////////////////////////////////
- // A map is a table of SavedPos structs
- //
- struct SavedPos
- {
- // SavedPos is an entry in the SavedPosMap hash table
- SavedPos() { nSavedPosFlags=; iPos=; };
- MCD_STR strName;
- int iPos;
- enum { SPM_MAIN = , SPM_CHILD = , SPM_USED = , SPM_LAST = };
- int nSavedPosFlags;
- };
- struct SavedPosMap
- {
- // SavedPosMap is only created if SavePos/RestorePos are used
- SavedPosMap( int nSize ) { nMapSize=nSize; pTable = new SavedPos*[nSize]; memset(pTable,,nSize*sizeof(SavedPos*)); };
- ~SavedPosMap() { if (pTable) { for (int n=;n<nMapSize;++n) if (pTable[n]) delete[] pTable[n]; delete[] pTable; } };
- SavedPos** pTable;
- int nMapSize;
- };
- struct SavedPosMapArray
- {
- // SavedPosMapArray keeps pointers to SavedPosMap instances
- SavedPosMapArray() { m_pMaps = NULL; };
- ~SavedPosMapArray() { ReleaseMaps(); };
- void ReleaseMaps() { SavedPosMap**p = m_pMaps; if (p) { while (*p) delete *p++; delete[] m_pMaps; m_pMaps=NULL; } };
- bool GetMap( SavedPosMap*& pMap, int nMap, int nMapSize = );
- void CopySavedPosMaps( SavedPosMapArray* pOtherMaps );
- SavedPosMap** m_pMaps; // NULL terminated array
- };
- bool SavedPosMapArray::GetMap( SavedPosMap*& pMap, int nMap, int nMapSize /*=7*/ )
- {
- // Find or create map, returns true if map(s) created
- SavedPosMap** pMapsExisting = m_pMaps;
- int nMapIndex = ;
- if ( pMapsExisting )
- {
- // Length of array is unknown, so loop through maps
- while ( nMapIndex <= nMap )
- {
- pMap = pMapsExisting[nMapIndex];
- if ( ! pMap )
- break;
- if ( nMapIndex == nMap )
- return false; // not created
- ++nMapIndex;
- }
- nMapIndex = ;
- }
- // Create map(s)
- // If you access map 1 before map 0 created, then 2 maps will be created
- m_pMaps = new SavedPosMap*[nMap+];
- if ( pMapsExisting )
- {
- while ( pMapsExisting[nMapIndex] )
- {
- m_pMaps[nMapIndex] = pMapsExisting[nMapIndex];
- ++nMapIndex;
- }
- delete[] pMapsExisting;
- }
- while ( nMapIndex <= nMap )
- {
- m_pMaps[nMapIndex] = new SavedPosMap( nMapSize );
- ++nMapIndex;
- }
- m_pMaps[nMapIndex] = NULL;
- pMap = m_pMaps[nMap];
- return true; // map(s) created
- }
- void SavedPosMapArray::CopySavedPosMaps( SavedPosMapArray* pOtherMaps )
- {
- ReleaseMaps();
- if ( pOtherMaps->m_pMaps )
- {
- int nMap = ;
- SavedPosMap* pMap = NULL;
- while ( pOtherMaps->m_pMaps[nMap] )
- {
- SavedPosMap* pMapSrc = pOtherMaps->m_pMaps[nMap];
- GetMap( pMap, nMap, pMapSrc->nMapSize );
- for ( int nSlot=; nSlot < pMap->nMapSize; ++nSlot )
- {
- SavedPos* pCopySavedPos = pMapSrc->pTable[nSlot];
- if ( pCopySavedPos )
- {
- int nCount = ;
- while ( pCopySavedPos[nCount].nSavedPosFlags & SavedPos::SPM_USED )
- {
- ++nCount;
- if ( pCopySavedPos[nCount-].nSavedPosFlags & SavedPos::SPM_LAST )
- break;
- }
- if ( nCount )
- {
- SavedPos* pNewSavedPos = new SavedPos[nCount];
- for ( int nCopy=; nCopy<nCount; ++nCopy )
- pNewSavedPos[nCopy] = pCopySavedPos[nCopy];
- pNewSavedPos[nCount-].nSavedPosFlags |= SavedPos::SPM_LAST;
- pMap->pTable[nSlot] = pNewSavedPos;
- }
- }
- }
- ++nMap;
- }
- }
- }
- //////////////////////////////////////////////////////////////////////
- // Core parser function
- //
- int TokenPos::ParseNode( NodePos& node )
- {
- // Call this with m_nNext set to the start of the node or tag
- // Upon return m_nNext points to the char after the node or tag
- // m_nL and m_nR are set to name location if it is a tag with a name
- // node members set to node location, strMeta used for parse error
- //
- // <!--...--> comment
- // <!DOCTYPE ...> dtd
- // <?target ...?> processing instruction
- // <![CDATA[...]]> cdata section
- // <NAME ...> element start tag
- // </NAME ...> element end tag
- //
- // returns the nodetype or
- // 0 for end tag
- // -1 for bad node
- // -2 for end of document
- //
- enum ParseBits
- {
- PD_OPENTAG = ,
- PD_BANG = ,
- PD_DASH = ,
- PD_BRACKET = ,
- PD_TEXTORWS = ,
- PD_DOCTYPE = ,
- PD_INQUOTE_S = ,
- PD_INQUOTE_D = ,
- PD_EQUALS = ,
- PD_NOQUOTEVAL =
- };
- int nParseFlags = ;
- MCD_PCSZ pFindEnd = NULL;
- int nNodeType = -;
- int nEndLen = ;
- int nName = ;
- int nNameLen = ;
- unsigned int cDminus1 = , cDminus2 = ;
- #define FINDNODETYPE(e,t) { pFindEnd=e; nEndLen=(sizeof(e)-1)/sizeof(MCD_CHAR); nNodeType=t; }
- #define FINDNODETYPENAME(e,t,n) { FINDNODETYPE(e,t) nName=(int)(pD-m_pDocText)+n; }
- #define FINDNODEBAD(e) { pFindEnd=MCD_T(">"); nEndLen=1; x_AddResult(node.strMeta,e,NULL,0,m_nNext); nNodeType=-1; }
- node.nStart = m_nNext;
- node.nNodeFlags = ;
- MCD_PCSZ pD = &m_pDocText[m_nNext];
- unsigned int cD;
- while ( )
- {
- cD = (unsigned int)*pD;
- if ( ! cD )
- {
- m_nNext = (int)(pD - m_pDocText);
- if ( m_pReaderFilePos ) // read file mode
- {
- // Read buffer may only be removed on the first FileReadNextBuffer in this node
- int nRemovedAlready = m_pReaderFilePos->m_nReadBufferRemoved;
- if ( m_pReaderFilePos->FileReadNextBuffer() ) // more text in file?
- {
- int nNodeLength = m_nNext - node.nStart;
- int nRemove = m_pReaderFilePos->m_nReadBufferRemoved;
- if ( nRemove )
- {
- node.nStart -= nRemove;
- if ( nName )
- nName -= nRemove;
- else if ( nNameLen )
- {
- m_nL -= nRemove;
- m_nR -= nRemove;
- }
- m_nNext -= nRemove;
- }
- int nNewOffset = node.nStart + nNodeLength;
- MCD_STR& str = *m_pReaderFilePos->m_pstrBuffer;
- m_pDocText = MCD_2PCSZ( str );
- pD = &m_pDocText[nNewOffset];
- cD = (unsigned int)*pD; // loaded char replaces null terminator
- }
- if (nRemovedAlready) // preserve m_nReadBufferRemoved for caller of ParseNode
- m_pReaderFilePos->m_nReadBufferRemoved = nRemovedAlready;
- }
- if ( ! cD )
- {
- if ( m_nNext == node.nStart )
- {
- node.nLength = ;
- node.nNodeType = ;
- return -; // end of document
- }
- if ( nNodeType != CMarkup::MNT_WHITESPACE && nNodeType != CMarkup::MNT_TEXT )
- {
- MCD_PCSZ pType = MCD_T("tag");
- if ( (nParseFlags & PD_DOCTYPE) || nNodeType == CMarkup::MNT_DOCUMENT_TYPE )
- pType = MCD_T("document_type");
- else if ( nNodeType == CMarkup::MNT_ELEMENT )
- pType = MCD_T("start_tag");
- else if ( nNodeType == )
- pType = MCD_T("end_tag");
- else if ( nNodeType == CMarkup::MNT_CDATA_SECTION )
- pType = MCD_T("cdata_section");
- else if ( nNodeType == CMarkup::MNT_PROCESSING_INSTRUCTION )
- pType = MCD_T("processing_instruction");
- else if ( nNodeType == CMarkup::MNT_COMMENT )
- pType = MCD_T("comment");
- nNodeType = -;
- x_AddResult(node.strMeta,MCD_T("unterminated_tag_syntax"),pType,MRC_TYPE,node.nStart);
- }
- break;
- }
- }
- if ( nName )
- {
- if ( x_ISENDNAME(cD) )
- {
- nNameLen = (int)(pD - m_pDocText) - nName;
- m_nL = nName;
- m_nR = nName + nNameLen - ;
- nName = ;
- cDminus2 = ;
- cDminus1 = ;
- }
- else
- {
- pD += MCD_CLEN( pD );
- continue;
- }
- }
- if ( pFindEnd )
- {
- if ( cD == '>' && ! (nParseFlags & (PD_INQUOTE_S|PD_INQUOTE_D)) )
- {
- m_nNext = (int)(pD - m_pDocText) + ;
- if ( nEndLen == )
- {
- pFindEnd = NULL;
- if ( nNodeType == CMarkup::MNT_ELEMENT && cDminus1 == '/' )
- {
- if ( (! cDminus2) || (!(nParseFlags&PD_NOQUOTEVAL)) || x_ISNOTSECONDLASTINVAL(cDminus2) )
- node.nNodeFlags |= MNF_EMPTY;
- }
- }
- else if ( m_nNext - > nEndLen )
- {
- // Test for end of PI or comment
- MCD_PCSZ pEnd = pD - nEndLen + ;
- MCD_PCSZ pInFindEnd = pFindEnd;
- int nLen = nEndLen;
- while ( --nLen && *pEnd++ == *pInFindEnd++ );
- if ( nLen == )
- pFindEnd = NULL;
- }
- nParseFlags &= ~PD_NOQUOTEVAL; // make sure PD_NOQUOTEVAL is off
- if ( ! pFindEnd && ! (nParseFlags & PD_DOCTYPE) )
- break;
- }
- else if ( cD == '<' && (nNodeType == CMarkup::MNT_TEXT || nNodeType == -) )
- {
- m_nNext = (int)(pD - m_pDocText);
- break;
- }
- else if ( nNodeType & CMarkup::MNT_ELEMENT )
- {
- if ( (nParseFlags & (PD_INQUOTE_S|PD_INQUOTE_D|PD_NOQUOTEVAL)) )
- {
- if ( cD == '\"' && (nParseFlags&PD_INQUOTE_D) )
- nParseFlags ^= PD_INQUOTE_D; // off
- else if ( cD == '\'' && (nParseFlags&PD_INQUOTE_S) )
- nParseFlags ^= PD_INQUOTE_S; // off
- else if ( (nParseFlags&PD_NOQUOTEVAL) && x_ISWHITESPACE(cD) )
- nParseFlags ^= PD_NOQUOTEVAL; // off
- }
- else // not in attrib value
- {
- // Only set INQUOTE status when preceeded by equal sign
- if ( cD == '\"' && (nParseFlags&PD_EQUALS) )
- nParseFlags ^= PD_INQUOTE_D|PD_EQUALS; // D on, equals off
- else if ( cD == '\'' && (nParseFlags&PD_EQUALS) )
- nParseFlags ^= PD_INQUOTE_S|PD_EQUALS; // S on, equals off
- else if ( cD == '=' && cDminus1 != '=' && ! (nParseFlags&PD_EQUALS) )
- nParseFlags ^= PD_EQUALS; // on
- else if ( (nParseFlags&PD_EQUALS) && ! x_ISWHITESPACE(cD) )
- nParseFlags ^= PD_NOQUOTEVAL|PD_EQUALS; // no quote val on, equals off
- }
- cDminus2 = cDminus1;
- cDminus1 = cD;
- }
- else if ( nNodeType & CMarkup::MNT_DOCUMENT_TYPE )
- {
- if ( cD == '\"' && ! (nParseFlags&PD_INQUOTE_S) )
- nParseFlags ^= PD_INQUOTE_D; // toggle
- else if ( cD == '\'' && ! (nParseFlags&PD_INQUOTE_D) )
- nParseFlags ^= PD_INQUOTE_S; // toggle
- }
- }
- else if ( nParseFlags )
- {
- if ( nParseFlags & PD_TEXTORWS )
- {
- if ( cD == '<' )
- {
- m_nNext = (int)(pD - m_pDocText);
- nNodeType = CMarkup::MNT_WHITESPACE;
- break;
- }
- else if ( ! x_ISWHITESPACE(cD) )
- {
- nParseFlags ^= PD_TEXTORWS;
- FINDNODETYPE( MCD_T("<"), CMarkup::MNT_TEXT )
- }
- }
- else if ( nParseFlags & PD_OPENTAG )
- {
- nParseFlags ^= PD_OPENTAG;
- if ( cD > 0x60 || ( cD > 0x40 && cD < 0x5b ) || cD == 0x5f || cD == 0x3a )
- FINDNODETYPENAME( MCD_T(">"), CMarkup::MNT_ELEMENT, )
- else if ( cD == '/' )
- FINDNODETYPENAME( MCD_T(">"), , )
- else if ( cD == '!' )
- nParseFlags |= PD_BANG;
- else if ( cD == '?' )
- FINDNODETYPENAME( MCD_T("?>"), CMarkup::MNT_PROCESSING_INSTRUCTION, )
- else
- FINDNODEBAD( MCD_T("first_tag_syntax") )
- }
- else if ( nParseFlags & PD_BANG )
- {
- nParseFlags ^= PD_BANG;
- if ( cD == '-' )
- nParseFlags |= PD_DASH;
- else if ( nParseFlags & PD_DOCTYPE )
- {
- if ( x_ISDOCTYPESTART(cD) ) // <!ELEMENT ATTLIST ENTITY NOTATION
- FINDNODETYPE( MCD_T(">"), CMarkup::MNT_DOCUMENT_TYPE )
- else
- FINDNODEBAD( MCD_T("doctype_tag_syntax") )
- }
- else
- {
- if ( cD == '[' )
- nParseFlags |= PD_BRACKET;
- else if ( cD == 'D' )
- nParseFlags |= PD_DOCTYPE;
- else
- FINDNODEBAD( MCD_T("exclamation_tag_syntax") )
- }
- }
- else if ( nParseFlags & PD_DASH )
- {
- nParseFlags ^= PD_DASH;
- if ( cD == '-' )
- FINDNODETYPE( MCD_T("-->"), CMarkup::MNT_COMMENT )
- else
- FINDNODEBAD( MCD_T("comment_tag_syntax") )
- }
- else if ( nParseFlags & PD_BRACKET )
- {
- nParseFlags ^= PD_BRACKET;
- if ( cD == 'C' )
- FINDNODETYPE( MCD_T("]]>"), CMarkup::MNT_CDATA_SECTION )
- else
- FINDNODEBAD( MCD_T("cdata_section_syntax") )
- }
- else if ( nParseFlags & PD_DOCTYPE )
- {
- if ( cD == '<' )
- nParseFlags |= PD_OPENTAG;
- else if ( cD == '>' )
- {
- m_nNext = (int)(pD - m_pDocText) + ;
- nNodeType = CMarkup::MNT_DOCUMENT_TYPE;
- break;
- }
- }
- }
- else if ( cD == '<' )
- {
- nParseFlags |= PD_OPENTAG;
- }
- else
- {
- nNodeType = CMarkup::MNT_WHITESPACE;
- if ( x_ISWHITESPACE(cD) )
- nParseFlags |= PD_TEXTORWS;
- else
- FINDNODETYPE( MCD_T("<"), CMarkup::MNT_TEXT )
- }
- pD += MCD_CLEN( pD );
- }
- node.nLength = m_nNext - node.nStart;
- node.nNodeType = nNodeType;
- return nNodeType;
- }
- //////////////////////////////////////////////////////////////////////
- // CMarkup public methods
- //
- CMarkup::~CMarkup()
- {
- delete m_pSavedPosMaps;
- delete m_pElemPosTree;
- }
- void CMarkup::operator=( const CMarkup& markup )
- {
- // Copying not supported during file mode because of file pointer
- if ( (m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE)) || (markup.m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE)) )
- return;
- m_iPosParent = markup.m_iPosParent;
- m_iPos = markup.m_iPos;
- m_iPosChild = markup.m_iPosChild;
- m_iPosFree = markup.m_iPosFree;
- m_iPosDeleted = markup.m_iPosDeleted;
- m_nNodeType = markup.m_nNodeType;
- m_nNodeOffset = markup.m_nNodeOffset;
- m_nNodeLength = markup.m_nNodeLength;
- m_strDoc = markup.m_strDoc;
- m_strResult = markup.m_strResult;
- m_nDocFlags = markup.m_nDocFlags;
- m_pElemPosTree->CopyElemPosTree( markup.m_pElemPosTree, m_iPosFree );
- m_pSavedPosMaps->CopySavedPosMaps( markup.m_pSavedPosMaps );
- MARKUP_SETDEBUGSTATE;
- }
- bool CMarkup::SetDoc( MCD_PCSZ pDoc )
- {
- // pDoc is markup text, not a filename!
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Set document text
- if ( pDoc )
- m_strDoc = pDoc;
- else
- {
- MCD_STRCLEARSIZE( m_strDoc );
- m_pElemPosTree->ReleaseElemPosTree();
- }
- MCD_STRCLEAR(m_strResult);
- return x_ParseDoc();
- }
- bool CMarkup::SetDoc( const MCD_STR& strDoc )
- {
- // strDoc is markup text, not a filename!
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- m_strDoc = strDoc;
- MCD_STRCLEAR(m_strResult);
- return x_ParseDoc();
- }
- bool CMarkup::IsWellFormed()
- {
- if ( m_nDocFlags & MDF_WRITEFILE )
- return true;
- if ( m_nDocFlags & MDF_READFILE )
- {
- if ( ! (ELEM().nFlags & MNF_ILLFORMED) )
- return true;
- }
- else if ( m_pElemPosTree->GetSize()
- && ! (ELEM().nFlags & MNF_ILLFORMED)
- && ELEM().iElemChild
- && ! ELEM(ELEM().iElemChild).iElemNext )
- return true;
- return false;
- }
- MCD_STR CMarkup::GetError() const
- {
- // For backwards compatibility, return a readable English string built from m_strResult
- // In release 11.0 you can use GetResult and examine result in XML format
- CMarkup mResult( m_strResult );
- MCD_STR strError;
- int nSyntaxErrors = ;
- while ( mResult.FindElem() )
- {
- MCD_STR strItem;
- MCD_STR strID = mResult.GetTagName();
- // Parse result
- if ( strID == MCD_T("root_has_sibling") )
- strItem = MCD_T("root element has sibling");
- else if ( strID == MCD_T("no_root_element") )
- strItem = MCD_T("no root element");
- else if ( strID == MCD_T("lone_end_tag") )
- strItem = MCD_T("lone end tag '") + mResult.GetAttrib(MCD_T("tagname")) + MCD_T("' at offset ")
- + mResult.GetAttrib(MCD_T("offset"));
- else if ( strID == MCD_T("unended_start_tag") )
- strItem = MCD_T("start tag '") + mResult.GetAttrib(MCD_T("tagname")) + MCD_T("' at offset ")
- + mResult.GetAttrib(MCD_T("offset")) + MCD_T(" expecting end tag at offset ") + mResult.GetAttrib(MCD_T("offset2"));
- else if ( strID == MCD_T("first_tag_syntax") )
- strItem = MCD_T("tag syntax error at offset ") + mResult.GetAttrib(MCD_T("offset"))
- + MCD_T(" expecting tag name / ! or ?");
- else if ( strID == MCD_T("exclamation_tag_syntax") )
- strItem = MCD_T("tag syntax error at offset ") + mResult.GetAttrib(MCD_T("offset"))
- + MCD_T(" expecting 'DOCTYPE' [ or -");
- else if ( strID == MCD_T("doctype_tag_syntax") )
- strItem = MCD_T("tag syntax error at offset ") + mResult.GetAttrib(MCD_T("offset"))
- + MCD_T(" expecting markup declaration"); // ELEMENT ATTLIST ENTITY NOTATION
- else if ( strID == MCD_T("comment_tag_syntax") )
- strItem = MCD_T("tag syntax error at offset ") + mResult.GetAttrib(MCD_T("offset"))
- + MCD_T(" expecting - to begin comment");
- else if ( strID == MCD_T("cdata_section_syntax") )
- strItem = MCD_T("tag syntax error at offset ") + mResult.GetAttrib(MCD_T("offset"))
- + MCD_T(" expecting 'CDATA'");
- else if ( strID == MCD_T("unterminated_tag_syntax") )
- strItem = MCD_T("unterminated tag at offset ") + mResult.GetAttrib(MCD_T("offset"));
- // Report only the first syntax or well-formedness error
- if ( ! MCD_STRISEMPTY(strItem) )
- {
- ++nSyntaxErrors;
- if ( nSyntaxErrors > )
- continue;
- }
- // I/O results
- if ( strID == MCD_T("file_error") )
- strItem = mResult.GetAttrib(MCD_T("msg"));
- else if ( strID == MCD_T("bom") )
- strItem = MCD_T("BOM +");
- else if ( strID == MCD_T("read") || strID == MCD_T("write") || strID == MCD_T("converted_to") || strID == MCD_T("converted_from") )
- {
- if ( strID == MCD_T("converted_to") )
- strItem = MCD_T("to ");
- MCD_STR strEncoding = mResult.GetAttrib( MCD_T("encoding") );
- if ( ! MCD_STRISEMPTY(strEncoding) )
- strItem += strEncoding + MCD_T(" ");
- strItem += MCD_T("length ") + mResult.GetAttrib(MCD_T("length"));
- if ( strID == MCD_T("converted_from") )
- strItem += MCD_T(" to");
- }
- else if ( strID == MCD_T("nulls_removed") )
- strItem = MCD_T("removed ") + mResult.GetAttrib(MCD_T("count")) + MCD_T(" nulls");
- else if ( strID == MCD_T("conversion_loss") )
- strItem = MCD_T("(chars lost in conversion!)");
- else if ( strID == MCD_T("utf8_detection") )
- strItem = MCD_T("(used UTF-8 detection)");
- else if ( strID == MCD_T("endian_swap") )
- strItem = MCD_T("endian swap");
- else if ( strID == MCD_T("truncation_error") )
- strItem = MCD_T("encoding ") + mResult.GetAttrib(MCD_T("encoding")) + MCD_T(" adjustment error");
- // Concatenate result item to error string
- if ( ! MCD_STRISEMPTY(strItem) )
- {
- if ( ! MCD_STRISEMPTY(strError) )
- strError += MCD_T(" ");
- strError += strItem;
- }
- }
- return strError;
- }
- bool CMarkup::Load( MCD_CSTR_FILENAME szFileName )
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- if ( ! ReadTextFile(szFileName, m_strDoc, &m_strResult, &m_nDocFlags) )
- return false;
- return x_ParseDoc();
- }
- bool CMarkup::ReadTextFile( MCD_CSTR_FILENAME szFileName, MCD_STR& strDoc, MCD_STR* pstrResult, int* pnDocFlags, MCD_STR* pstrEncoding )
- {
- // Static utility method to load text file into strDoc
- //
- FilePos file;
- file.m_nDocFlags = (pnDocFlags?*pnDocFlags:) | MDF_READFILE;
- bool bSuccess = file.FileOpen( szFileName );
- if ( pstrResult )
- *pstrResult = file.m_strIOResult;
- MCD_STRCLEAR(strDoc);
- if ( bSuccess )
- {
- file.FileSpecifyEncoding( pstrEncoding );
- file.m_nOpFileByteLen = (int)((MCD_INTFILEOFFSET)(file.m_nFileByteLen - file.m_nFileByteOffset));
- bSuccess = file.FileReadText( strDoc );
- file.FileClose();
- if ( pstrResult )
- *pstrResult += file.m_strIOResult;
- if ( pnDocFlags )
- *pnDocFlags = file.m_nDocFlags;
- }
- return bSuccess;
- }
- bool CMarkup::Save( MCD_CSTR_FILENAME szFileName )
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- return WriteTextFile( szFileName, m_strDoc, &m_strResult, &m_nDocFlags );
- }
- bool CMarkup::WriteTextFile( MCD_CSTR_FILENAME szFileName, const MCD_STR& strDoc, MCD_STR* pstrResult, int* pnDocFlags, MCD_STR* pstrEncoding )
- {
- // Static utility method to save strDoc to text file
- //
- FilePos file;
- file.m_nDocFlags = (pnDocFlags?*pnDocFlags:) | MDF_WRITEFILE;
- bool bSuccess = file.FileOpen( szFileName );
- if ( pstrResult )
- *pstrResult = file.m_strIOResult;
- if ( bSuccess )
- {
- if ( MCD_STRISEMPTY(file.m_strEncoding) && ! MCD_STRISEMPTY(strDoc) )
- {
- file.m_strEncoding = GetDeclaredEncoding( strDoc );
- if ( MCD_STRISEMPTY(file.m_strEncoding) )
- file.m_strEncoding = MCD_T("UTF-8"); // to do: MDF_ANSIFILE
- }
- file.FileSpecifyEncoding( pstrEncoding );
- bSuccess = file.FileWriteText( strDoc );
- file.FileClose();
- if ( pstrResult )
- *pstrResult += file.m_strIOResult;
- if ( pnDocFlags )
- *pnDocFlags = file.m_nDocFlags;
- }
- return bSuccess;
- }
- bool CMarkup::FindElem( MCD_CSTR szName )
- {
- if ( m_nDocFlags & MDF_WRITEFILE )
- return false;
- if ( m_pElemPosTree->GetSize() )
- {
- // Change current position only if found
- PathPos path( szName, false );
- int iPos = x_FindElem( m_iPosParent, m_iPos, path );
- if ( iPos )
- {
- // Assign new position
- x_SetPos( ELEM(iPos).iElemParent, iPos, );
- return true;
- }
- }
- return false;
- }
- bool CMarkup::FindChildElem( MCD_CSTR szName )
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Shorthand: if no current main position, find first child under parent element
- if ( ! m_iPos )
- FindElem();
- // Change current child position only if found
- PathPos path( szName, false );
- int iPosChild = x_FindElem( m_iPos, m_iPosChild, path );
- if ( iPosChild )
- {
- // Assign new position
- int iPos = ELEM(iPosChild).iElemParent;
- x_SetPos( ELEM(iPos).iElemParent, iPos, iPosChild );
- return true;
- }
- return false;
- }
- MCD_STR CMarkup::EscapeText( MCD_CSTR szText, int nFlags )
- {
- // Convert text as seen outside XML document to XML friendly
- // replacing special characters with ampersand escape codes
- // E.g. convert "6>7" to "6>7"
- //
- // < less than
- // & ampersand
- // > greater than
- //
- // and for attributes:
- //
- // ' apostrophe or single quote
- // " double quote
- //
- static MCD_PCSZ apReplace[] = { NULL,MCD_T("<"),MCD_T("&"),MCD_T(">"),MCD_T("""),MCD_T("'") };
- MCD_STR strText;
- MCD_PCSZ pSource = szText;
- int nDestSize = MCD_PSZLEN(pSource);
- nDestSize += nDestSize / + ;
- MCD_BLDRESERVE(strText,nDestSize);
- MCD_CHAR cSource = *pSource;
- int nFound;
- int nCharLen;
- while ( cSource )
- {
- MCD_BLDCHECK(strText,nDestSize,);
- nFound = ((nFlags&MNF_ESCAPEQUOTES)?x_ISATTRIBSPECIAL(cSource):x_ISSPECIAL(cSource));
- if ( nFound )
- {
- bool bIgnoreAmpersand = false;
- if ( (nFlags&MNF_WITHREFS) && cSource == '&' )
- {
- // Do not replace ampersand if it is start of any entity reference
- // &[#_:A-Za-zU][_:-.A-Za-z0-9U]*; where U is > 0x7f
- MCD_PCSZ pCheckEntity = pSource;
- ++pCheckEntity;
- MCD_CHAR c = *pCheckEntity;
- if ( x_ISSTARTENTREF(c) || ((unsigned int)c)>0x7f )
- {
- while ( )
- {
- pCheckEntity += MCD_CLEN( pCheckEntity );
- c = *pCheckEntity;
- if ( c == ';' )
- {
- int nEntityLen = (int)(pCheckEntity - pSource) + ;
- MCD_BLDAPPENDN(strText,pSource,nEntityLen);
- pSource = pCheckEntity;
- bIgnoreAmpersand = true;
- }
- else if ( x_ISINENTREF(c) || ((unsigned int)c)>0x7f )
- continue;
- break;
- }
- }
- }
- if ( ! bIgnoreAmpersand )
- {
- MCD_BLDAPPEND(strText,apReplace[nFound]);
- }
- ++pSource; // ASCII, so 1 byte
- }
- else
- {
- nCharLen = MCD_CLEN( pSource );
- MCD_BLDAPPENDN(strText,pSource,nCharLen);
- pSource += nCharLen;
- }
- cSource = *pSource;
- }
- MCD_BLDRELEASE(strText);
- return strText;
- }
- // Predefined character entities
- // By default UnescapeText will decode standard HTML entities as well as the 5 in XML
- // To unescape only the 5 standard XML entities, use this short table instead:
- // MCD_PCSZ PredefEntityTable[4] =
- // { MCD_T("20060lt"),MCD_T("40034quot"),MCD_T("30038amp"),MCD_T("20062gt40039apos") };
- //
- // This is a precompiled ASCII hash table for speed and minimum memory requirement
- // Each entry consists of a 1 digit code name length, 4 digit code point, and the code name
- // Each table slot can have multiple entries, table size 130 was chosen for even distribution
- //
- MCD_PCSZ PredefEntityTable[] =
- {
- MCD_T("60216oslash60217ugrave60248oslash60249ugrave"),
- MCD_T("50937omega60221yacute58968lceil50969omega60253yacute"),
- MCD_T("50916delta50206icirc50948delta50238icirc68472weierp"),MCD_T("40185sup1"),
- MCD_T("68970lfloor40178sup2"),
- MCD_T("50922kappa60164curren50954kappa58212mdash40179sup3"),
- MCD_T("59830diams58211ndash"),MCD_T("68855otimes58969rceil"),
- MCD_T("50338oelig50212ocirc50244ocirc50339oelig58482trade"),
- MCD_T("50197aring50931sigma50229aring50963sigma"),
- MCD_T("50180acute68971rfloor50732tilde"),MCD_T("68249lsaquo"),
- MCD_T("58734infin68201thinsp"),MCD_T("50161iexcl"),
- MCD_T("50920theta50219ucirc50952theta50251ucirc"),MCD_T("58254oline"),
- MCD_T("58260frasl68727lowast"),MCD_T("59827clubs60191iquest68250rsaquo"),
- MCD_T("58629crarr50181micro"),MCD_T("58222bdquo"),MCD_T(""),
- MCD_T("58243prime60177plusmn58242prime"),MCD_T("40914beta40946beta"),MCD_T(""),
- MCD_T(""),MCD_T(""),MCD_T("50171laquo50215times"),MCD_T("40710circ"),
- MCD_T("49001lang"),MCD_T("58220ldquo40175macr"),
- MCD_T("40182para50163pound48476real"),MCD_T(""),MCD_T("58713notin50187raquo"),
- MCD_T("48773cong50223szlig50978upsih"),
- MCD_T("58776asymp58801equiv49002rang58218sbquo"),
- MCD_T("50222thorn48659darr48595darr40402fnof58221rdquo50254thorn"),
- MCD_T("40162cent58722minus"),MCD_T("58707exist40170ordf"),MCD_T(""),
- MCD_T("40921iota58709empty48660harr48596harr40953iota"),MCD_T(""),
- MCD_T("40196auml40228auml48226bull40167sect48838sube"),MCD_T(""),
- MCD_T("48656larr48592larr58853oplus"),MCD_T("30176deg58216lsquo40186ordm"),
- MCD_T("40203euml40039apos40235euml48712isin40160nbsp"),
- MCD_T("40918zeta40950zeta"),MCD_T("38743and48195emsp48719prod"),
- MCD_T("30935chi38745cap30967chi48194ensp"),
- MCD_T("40207iuml40239iuml48706part48869perp48658rarr48594rarr"),
- MCD_T("38736ang48836nsub58217rsquo"),MCD_T(""),
- MCD_T("48901sdot48657uarr48593uarr"),MCD_T("40169copy48364euro"),
- MCD_T("30919eta30951eta"),MCD_T("40214ouml40246ouml48839supe"),MCD_T(""),
- MCD_T(""),MCD_T("30038amp30174reg"),MCD_T("48733prop"),MCD_T(""),
- MCD_T("30208eth30934phi40220uuml30240eth30966phi40252uuml"),MCD_T(""),MCD_T(""),
- MCD_T(""),MCD_T("40376yuml40255yuml"),MCD_T(""),MCD_T("40034quot48204zwnj"),
- MCD_T("38746cup68756there4"),MCD_T("30929rho30961rho38764sim"),
- MCD_T("30932tau38834sub30964tau"),MCD_T("38747int38206lrm38207rlm"),
- MCD_T("30936psi30968psi30165yen"),MCD_T(""),MCD_T("28805ge30168uml"),
- MCD_T("30982piv"),MCD_T(""),MCD_T("30172not"),MCD_T(""),MCD_T("28804le"),
- MCD_T("30173shy"),MCD_T("39674loz28800ne38721sum"),MCD_T(""),MCD_T(""),
- MCD_T("38835sup"),MCD_T("28715ni"),MCD_T(""),MCD_T("20928pi20960pi38205zwj"),
- MCD_T(""),MCD_T("60923lambda20062gt60955lambda"),MCD_T(""),MCD_T(""),
- MCD_T("60199ccedil60231ccedil"),MCD_T(""),MCD_T("20060lt"),
- MCD_T("20926xi28744or20958xi"),MCD_T("20924mu20956mu"),MCD_T("20925nu20957nu"),
- MCD_T("68225dagger68224dagger"),MCD_T("80977thetasym"),MCD_T(""),MCD_T(""),
- MCD_T(""),MCD_T("78501alefsym"),MCD_T(""),MCD_T(""),MCD_T(""),
- MCD_T("60193aacute60195atilde60225aacute60227atilde"),MCD_T(""),
- MCD_T("70927omicron60247divide70959omicron"),MCD_T("60192agrave60224agrave"),
- MCD_T("60201eacute60233eacute60962sigmaf"),MCD_T("70917epsilon70949epsilon"),
- MCD_T(""),MCD_T("60200egrave60232egrave"),MCD_T("60205iacute60237iacute"),
- MCD_T(""),MCD_T(""),MCD_T("60204igrave68230hellip60236igrave"),
- MCD_T("60166brvbar"),
- MCD_T("60209ntilde68704forall58711nabla60241ntilde69824spades"),
- MCD_T("60211oacute60213otilde60189frac1260183middot60243oacute60245otilde"),
- MCD_T(""),MCD_T("50184cedil60188frac14"),
- MCD_T("50198aelig50194acirc60210ograve50226acirc50230aelig60242ograve"),
- MCD_T("50915gamma60190frac3450947gamma58465image58730radic"),
- MCD_T("60352scaron60353scaron"),MCD_T("60218uacute69829hearts60250uacute"),
- MCD_T("50913alpha50202ecirc70933upsilon50945alpha50234ecirc70965upsilon"),
- MCD_T("68240permil")
- };
- MCD_STR CMarkup::UnescapeText( MCD_CSTR szText, int nTextLength /*=-1*/, int nFlags /*=0*/ )
- {
- // Convert XML friendly text to text as seen outside XML document
- // ampersand escape codes replaced with special characters e.g. convert "6>7" to "6>7"
- // ampersand numeric codes replaced with character e.g. convert < to <
- // Conveniently the result is always the same or shorter in byte length
- //
- MCD_STR strText;
- MCD_PCSZ pSource = szText;
- if ( nTextLength == - )
- nTextLength = MCD_PSZLEN(szText);
- MCD_BLDRESERVE(strText,nTextLength);
- MCD_CHAR szCodeName[];
- bool bAlterWhitespace = (nFlags & (MDF_TRIMWHITESPACE|MDF_COLLAPSEWHITESPACE))?true:false;
- bool bCollapseWhitespace = (nFlags & MDF_COLLAPSEWHITESPACE)?true:false;
- int nCharWhitespace = -; // start of string
- int nCharLen;
- int nChar = ;
- while ( nChar < nTextLength )
- {
- if ( pSource[nChar] == '&' )
- {
- if ( bAlterWhitespace )
- nCharWhitespace = ;
- // Get corresponding unicode code point
- int nUnicode = ;
- // Look for terminating semi-colon within 9 ASCII characters
- int nCodeLen = ;
- MCD_CHAR cCodeChar = pSource[nChar+];
- while ( nCodeLen < && ((unsigned int)cCodeChar) < && cCodeChar != ';' )
- {
- if ( cCodeChar >= 'A' && cCodeChar <= 'Z') // upper case?
- cCodeChar += ('a' - 'A'); // make lower case
- szCodeName[nCodeLen] = cCodeChar;
- ++nCodeLen;
- cCodeChar = pSource[nChar++nCodeLen];
- }
- if ( cCodeChar == ';' ) // found semi-colon?
- {
- // Decode szCodeName
- szCodeName[nCodeLen] = '\0';
- if ( *szCodeName == '#' ) // numeric character reference?
- {
- // Is it a hex number?
- int nBase = ; // decimal
- int nNumberOffset = ; // after #
- if ( szCodeName[] == 'x' )
- {
- nNumberOffset = ; // after #x
- nBase = ; // hex
- }
- nUnicode = MCD_PSZTOL( &szCodeName[nNumberOffset], NULL, nBase );
- }
- else // does not start with #
- {
- // Look for matching code name in PredefEntityTable
- MCD_PCSZ pEntry = PredefEntityTable[x_Hash(szCodeName,sizeof(PredefEntityTable)/sizeof(MCD_PCSZ))];
- while ( *pEntry )
- {
- // e.g. entry: 40039apos means length 4, code point 0039, code name apos
- int nEntryLen = (*pEntry - '');
- ++pEntry;
- MCD_PCSZ pCodePoint = pEntry;
- pEntry += ;
- if ( nEntryLen == nCodeLen && x_StrNCmp(szCodeName,pEntry,nEntryLen) == )
- {
- // Convert digits to integer up to code name which always starts with alpha
- nUnicode = MCD_PSZTOL( pCodePoint, NULL, );
- break;
- }
- pEntry += nEntryLen;
- }
- }
- }
- // If a code point found, encode it into text
- if ( nUnicode )
- {
- MCD_CHAR szChar[];
- nCharLen = ;
- #if defined(MARKUP_WCHAR) // WCHAR
- #if MARKUP_SIZEOFWCHAR == 4 // sizeof(wchar_t) == 4
- szChar[] = (MCD_CHAR)nUnicode;
- nCharLen = ;
- #else // sizeof(wchar_t) == 2
- EncodeCharUTF16( nUnicode, (unsigned short*)szChar, nCharLen );
- #endif
- #elif defined(MARKUP_MBCS) // MBCS/double byte
- #if defined(MARKUP_WINCONV)
- int nUsedDefaultChar = ;
- wchar_t wszUTF16[];
- EncodeCharUTF16( nUnicode, (unsigned short*)wszUTF16, nCharLen );
- nCharLen = WideCharToMultiByte( CP_ACP, , wszUTF16, nCharLen, szChar, , NULL, &nUsedDefaultChar );
- if ( nUsedDefaultChar || nCharLen <= )
- nUnicode = ;
- #else // not WINCONV
- wchar_t wcUnicode = (wchar_t)nUnicode;
- nCharLen = wctomb( szChar, wcUnicode );
- if ( nCharLen <= )
- nUnicode = ;
- #endif // not WINCONV
- #else // not WCHAR and not MBCS/double byte
- EncodeCharUTF8( nUnicode, szChar, nCharLen );
- #endif // not WCHAR and not MBCS/double byte
- // Increment index past ampersand semi-colon
- if ( nUnicode ) // must check since MBCS case can clear it
- {
- MCD_BLDAPPENDN(strText,szChar,nCharLen);
- nChar += nCodeLen + ;
- }
- }
- if ( ! nUnicode )
- {
- // If the code is not converted, leave it as is
- MCD_BLDAPPEND1(strText,'&');
- ++nChar;
- }
- }
- else if ( bAlterWhitespace && x_ISWHITESPACE(pSource[nChar]) )
- {
- if ( nCharWhitespace == && bCollapseWhitespace )
- {
- nCharWhitespace = MCD_BLDLEN(strText);
- MCD_BLDAPPEND1(strText,' ');
- }
- else if ( nCharWhitespace != - && ! bCollapseWhitespace )
- {
- if ( nCharWhitespace == )
- nCharWhitespace = MCD_BLDLEN(strText);
- MCD_BLDAPPEND1(strText,pSource[nChar]);
- }
- ++nChar;
- }
- else // not &
- {
- if ( bAlterWhitespace )
- nCharWhitespace = ;
- nCharLen = MCD_CLEN(&pSource[nChar]);
- MCD_BLDAPPENDN(strText,&pSource[nChar],nCharLen);
- nChar += nCharLen;
- }
- }
- if ( bAlterWhitespace && nCharWhitespace > )
- {
- MCD_BLDTRUNC(strText,nCharWhitespace);
- }
- MCD_BLDRELEASE(strText);
- return strText;
- }
- bool CMarkup::DetectUTF8( const char* pText, int nTextLen, int* pnNonASCII/*=NULL*/, bool* bErrorAtEnd/*=NULL*/ )
- {
- // return true if ASCII or all non-ASCII byte sequences are valid UTF-8 pattern:
- // ASCII 0xxxxxxx
- // 2-byte 110xxxxx 10xxxxxx
- // 3-byte 1110xxxx 10xxxxxx 10xxxxxx
- // 4-byte 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- // *pnNonASCII is set (if pnNonASCII is not NULL) to the number of non-ASCII UTF-8 sequences
- // or if an invalid UTF-8 sequence is found, to 1 + the valid non-ASCII sequences up to the invalid sequence
- // *bErrorAtEnd is set (if bErrorAtEnd is not NULL) to true if the UTF-8 was cut off at the end in mid valid sequence
- int nUChar;
- if ( pnNonASCII )
- *pnNonASCII = ;
- const char* pTextEnd = pText + nTextLen;
- while ( *pText && pText != pTextEnd )
- {
- if ( (unsigned char)(*pText) & 0x80 )
- {
- if ( pnNonASCII )
- ++(*pnNonASCII);
- nUChar = DecodeCharUTF8( pText, pTextEnd );
- if ( nUChar == - )
- {
- if ( bErrorAtEnd )
- *bErrorAtEnd = (pTextEnd == pText)? true:false;
- return false;
- }
- }
- else
- ++pText;
- }
- if ( bErrorAtEnd )
- *bErrorAtEnd = false;
- return true;
- }
- int CMarkup::DecodeCharUTF8( const char*& pszUTF8, const char* pszUTF8End/*=NULL*/ )
- {
- // Return Unicode code point and increment pszUTF8 past 1-4 bytes
- // pszUTF8End can be NULL if pszUTF8 is null terminated
- int nUChar = (unsigned char)*pszUTF8;
- ++pszUTF8;
- if ( nUChar & 0x80 )
- {
- int nExtraChars;
- if ( ! (nUChar & 0x20) )
- {
- nExtraChars = ;
- nUChar &= 0x1f;
- }
- else if ( ! (nUChar & 0x10) )
- {
- nExtraChars = ;
- nUChar &= 0x0f;
- }
- else if ( ! (nUChar & 0x08) )
- {
- nExtraChars = ;
- nUChar &= 0x07;
- }
- else
- return -;
- while ( nExtraChars-- )
- {
- if ( pszUTF8 == pszUTF8End || ! (*pszUTF8 & 0x80) )
- return -;
- nUChar = nUChar<<;
- nUChar |= *pszUTF8 & 0x3f;
- ++pszUTF8;
- }
- }
- return nUChar;
- }
- void CMarkup::EncodeCharUTF16( int nUChar, unsigned short* pwszUTF16, int& nUTF16Len )
- {
- // Write UTF-16 sequence to pwszUTF16 for Unicode code point nUChar and update nUTF16Len
- // Be sure pwszUTF16 has room for up to 2 wide chars
- if ( nUChar & ~0xffff )
- {
- if ( pwszUTF16 )
- {
- // Surrogate pair
- nUChar -= 0x10000;
- pwszUTF16[nUTF16Len++] = (unsigned short)(((nUChar>>) & 0x3ff) | 0xd800); // W1
- pwszUTF16[nUTF16Len++] = (unsigned short)((nUChar & 0x3ff) | 0xdc00); // W2
- }
- else
- nUTF16Len += ;
- }
- else
- {
- if ( pwszUTF16 )
- pwszUTF16[nUTF16Len++] = (unsigned short)nUChar;
- else
- ++nUTF16Len;
- }
- }
- int CMarkup::DecodeCharUTF16( const unsigned short*& pwszUTF16, const unsigned short* pszUTF16End/*=NULL*/ )
- {
- // Return Unicode code point and increment pwszUTF16 past 1 or 2 (if surrogrates) UTF-16 code points
- // pszUTF16End can be NULL if pszUTF16 is zero terminated
- int nUChar = *pwszUTF16;
- ++pwszUTF16;
- if ( (nUChar & ~0x000007ff) == 0xd800 ) // W1
- {
- if ( pwszUTF16 == pszUTF16End || ! (*pwszUTF16) ) // W2
- return -; // incorrect UTF-16
- nUChar = (((nUChar & 0x3ff) << ) | (*pwszUTF16 & 0x3ff)) + 0x10000;
- ++pwszUTF16;
- }
- return nUChar;
- }
- void CMarkup::EncodeCharUTF8( int nUChar, char* pszUTF8, int& nUTF8Len )
- {
- // Write UTF-8 sequence to pszUTF8 for Unicode code point nUChar and update nUTF8Len
- // Be sure pszUTF8 has room for up to 4 bytes
- if ( ! (nUChar & ~0x0000007f) ) // < 0x80
- {
- if ( pszUTF8 )
- pszUTF8[nUTF8Len++] = (char)nUChar;
- else
- ++nUTF8Len;
- }
- else if ( ! (nUChar & ~0x000007ff) ) // < 0x800
- {
- if ( pszUTF8 )
- {
- pszUTF8[nUTF8Len++] = (char)(((nUChar&0x7c0)>>)|0xc0);
- pszUTF8[nUTF8Len++] = (char)((nUChar&0x3f)|0x80);
- }
- else
- nUTF8Len += ;
- }
- else if ( ! (nUChar & ~0x0000ffff) ) // < 0x10000
- {
- if ( pszUTF8 )
- {
- pszUTF8[nUTF8Len++] = (char)(((nUChar&0xf000)>>)|0xe0);
- pszUTF8[nUTF8Len++] = (char)(((nUChar&0xfc0)>>)|0x80);
- pszUTF8[nUTF8Len++] = (char)((nUChar&0x3f)|0x80);
- }
- else
- nUTF8Len += ;
- }
- else // < 0x110000
- {
- if ( pszUTF8 )
- {
- pszUTF8[nUTF8Len++] = (char)(((nUChar&0x1c0000)>>)|0xf0);
- pszUTF8[nUTF8Len++] = (char)(((nUChar&0x3f000)>>)|0x80);
- pszUTF8[nUTF8Len++] = (char)(((nUChar&0xfc0)>>)|0x80);
- pszUTF8[nUTF8Len++] = (char)((nUChar&0x3f)|0x80);
- }
- else
- nUTF8Len += ;
- }
- }
- int CMarkup::UTF16To8( char* pszUTF8, const unsigned short* pwszUTF16, int nUTF8Count )
- {
- // Supports the same arguments as wcstombs
- // the pwszUTF16 source must be a NULL-terminated UTF-16 string
- // if pszUTF8 is NULL, the number of bytes required is returned and nUTF8Count is ignored
- // otherwise pszUTF8 is filled with the result string and NULL-terminated if nUTF8Count allows
- // nUTF8Count is the byte size of pszUTF8 and must be large enough for the NULL if NULL desired
- // and the number of bytes (excluding NULL) is returned
- //
- int nUChar, nUTF8Len = ;
- while ( *pwszUTF16 )
- {
- // Decode UTF-16
- nUChar = DecodeCharUTF16( pwszUTF16, NULL );
- if ( nUChar == - )
- nUChar = '?';
- // Encode UTF-8
- if ( pszUTF8 && nUTF8Len + > nUTF8Count )
- {
- int nUTF8LenSoFar = nUTF8Len;
- EncodeCharUTF8( nUChar, NULL, nUTF8Len );
- if ( nUTF8Len > nUTF8Count )
- return nUTF8LenSoFar;
- nUTF8Len = nUTF8LenSoFar;
- }
- EncodeCharUTF8( nUChar, pszUTF8, nUTF8Len );
- }
- if ( pszUTF8 && nUTF8Len < nUTF8Count )
- pszUTF8[nUTF8Len] = ;
- return nUTF8Len;
- }
- int CMarkup::UTF8To16( unsigned short* pwszUTF16, const char* pszUTF8, int nUTF8Count )
- {
- // Supports the same arguments as mbstowcs
- // the pszUTF8 source must be a UTF-8 string which will be processed up to NULL-terminator or nUTF8Count
- // if pwszUTF16 is NULL, the number of UTF-16 chars required is returned
- // nUTF8Count is maximum UTF-8 bytes to convert and should include NULL if NULL desired in result
- // if pwszUTF16 is not NULL it is filled with the result string and it must be large enough
- // result will be NULL-terminated if NULL encountered in pszUTF8 before nUTF8Count
- // and the number of UTF-8 bytes converted is returned
- //
- const char* pszPosUTF8 = pszUTF8;
- const char* pszUTF8End = pszUTF8 + nUTF8Count;
- int nUChar, nUTF8Len = , nUTF16Len = ;
- while ( pszPosUTF8 != pszUTF8End )
- {
- nUChar = DecodeCharUTF8( pszPosUTF8, pszUTF8End );
- if ( ! nUChar )
- {
- if ( pwszUTF16 )
- pwszUTF16[nUTF16Len] = ;
- break;
- }
- else if ( nUChar == - )
- nUChar = '?';
- // Encode UTF-16
- EncodeCharUTF16( nUChar, pwszUTF16, nUTF16Len );
- }
- nUTF8Len = (int)(pszPosUTF8 - pszUTF8);
- if ( ! pwszUTF16 )
- return nUTF16Len;
- return nUTF8Len;
- }
- #if ! defined(MARKUP_WCHAR) // not WCHAR
- MCD_STR CMarkup::UTF8ToA( MCD_CSTR pszUTF8, int* pnFailed/*=NULL*/ )
- {
- // Converts from UTF-8 to locale ANSI charset
- MCD_STR strANSI;
- int nMBLen = (int)MCD_PSZLEN( pszUTF8 );
- if ( pnFailed )
- *pnFailed = ;
- if ( nMBLen )
- {
- TextEncoding textencoding( MCD_T("UTF-8"), (const void*)pszUTF8, nMBLen );
- textencoding.m_nToCount = nMBLen;
- MCD_CHAR* pANSIBuffer = MCD_GETBUFFER(strANSI,textencoding.m_nToCount);
- nMBLen = textencoding.PerformConversion( (void*)pANSIBuffer );
- MCD_RELEASEBUFFER(strANSI,pANSIBuffer,nMBLen);
- if ( pnFailed )
- *pnFailed = textencoding.m_nFailedChars;
- }
- return strANSI;
- }
- MCD_STR CMarkup::AToUTF8( MCD_CSTR pszANSI )
- {
- // Converts locale ANSI charset to UTF-8
- MCD_STR strUTF8;
- int nMBLen = (int)MCD_PSZLEN( pszANSI );
- if ( nMBLen )
- {
- TextEncoding textencoding( MCD_T(""), (const void*)pszANSI, nMBLen );
- textencoding.m_nToCount = nMBLen * ;
- MCD_CHAR* pUTF8Buffer = MCD_GETBUFFER(strUTF8,textencoding.m_nToCount);
- nMBLen = textencoding.PerformConversion( (void*)pUTF8Buffer, MCD_T("UTF-8") );
- MCD_RELEASEBUFFER(strUTF8,pUTF8Buffer,nMBLen);
- }
- return strUTF8;
- }
- #endif // not WCHAR
- MCD_STR CMarkup::GetDeclaredEncoding( MCD_CSTR szDoc )
- {
- // Extract encoding attribute from XML Declaration, or HTML meta charset
- MCD_STR strEncoding;
- TokenPos token( szDoc, MDF_IGNORECASE );
- NodePos node;
- bool bHtml = false;
- int nTypeFound = ;
- while ( nTypeFound >= )
- {
- nTypeFound = token.ParseNode( node );
- int nNext = token.m_nNext;
- if ( nTypeFound == MNT_PROCESSING_INSTRUCTION && node.nStart == )
- {
- token.m_nNext = node.nStart + ; // after <?
- if ( token.FindName() && token.Match(MCD_T("xml")) )
- {
- // e.g. <?xml version="1.0" encoding="UTF-8"?>
- if ( token.FindAttrib(MCD_T("encoding")) )
- strEncoding = token.GetTokenText();
- break;
- }
- }
- else if ( nTypeFound == ) // end tag
- {
- // Check for end of HTML head
- token.m_nNext = node.nStart + ; // after </
- if ( token.FindName() && token.Match(MCD_T("head")) )
- break;
- }
- else if ( nTypeFound == MNT_ELEMENT )
- {
- token.m_nNext = node.nStart + ; // after <
- token.FindName();
- if ( ! bHtml )
- {
- if ( ! token.Match(MCD_T("html")) )
- break;
- bHtml = true;
- }
- else if ( token.Match(MCD_T("meta")) )
- {
- // e.g. <META http-equiv=Content-Type content="text/html; charset=UTF-8">
- int nAttribOffset = node.nStart + ;
- token.m_nNext = nAttribOffset;
- if ( token.FindAttrib(MCD_T("http-equiv")) && token.Match(MCD_T("Content-Type")) )
- {
- token.m_nNext = nAttribOffset;
- if ( token.FindAttrib(MCD_T("content")) )
- {
- int nContentEndOffset = token.m_nNext;
- token.m_nNext = token.m_nL;
- while ( token.m_nNext < nContentEndOffset && token.FindName() )
- {
- if ( token.Match(MCD_T("charset")) && token.FindName() && token.Match(MCD_T("=")) )
- {
- token.FindName();
- strEncoding = token.GetTokenText();
- break;
- }
- }
- }
- break;
- }
- }
- }
- token.m_nNext = nNext;
- }
- return strEncoding;
- }
- int CMarkup::GetEncodingCodePage( MCD_CSTR pszEncoding )
- {
- return x_GetEncodingCodePage( pszEncoding );
- }
- int CMarkup::FindNode( int nType )
- {
- // Change current node position only if a node is found
- // If nType is 0 find any node, otherwise find node of type nType
- // Return type of node or 0 if not found
- // Determine where in document to start scanning for node
- int nNodeOffset = m_nNodeOffset;
- if ( m_nNodeType > MNT_ELEMENT )
- {
- // By-pass current node
- nNodeOffset += m_nNodeLength;
- }
- else // element or no current main position
- {
- // Set position to begin looking for node
- if ( m_iPos )
- {
- // After element
- nNodeOffset = ELEM(m_iPos).StartAfter();
- }
- else if ( m_iPosParent )
- {
- // Immediately after start tag of parent
- if ( ELEM(m_iPosParent).IsEmptyElement() )
- return ;
- else
- nNodeOffset = ELEM(m_iPosParent).StartContent();
- }
- }
- // Get nodes until we find what we're looking for
- int nTypeFound = ;
- int iPosNew = m_iPos;
- TokenPos token( m_strDoc, m_nDocFlags );
- NodePos node;
- token.m_nNext = nNodeOffset;
- do
- {
- nNodeOffset = token.m_nNext;
- nTypeFound = token.ParseNode( node );
- if ( nTypeFound == )
- {
- // Check if we have reached the end of the parent element
- if ( m_iPosParent && nNodeOffset == ELEM(m_iPosParent).StartContent()
- + ELEM(m_iPosParent).ContentLen() )
- return ;
- nTypeFound = MNT_LONE_END_TAG; // otherwise it is a lone end tag
- }
- else if ( nTypeFound < )
- {
- if ( nTypeFound == - ) // end of document
- return ;
- // -1 is node error
- nTypeFound = MNT_NODE_ERROR;
- }
- else if ( nTypeFound == MNT_ELEMENT )
- {
- if ( iPosNew )
- iPosNew = ELEM(iPosNew).iElemNext;
- else
- iPosNew = ELEM(m_iPosParent).iElemChild;
- if ( ! iPosNew )
- return ;
- if ( ! nType || (nType & nTypeFound) )
- {
- // Found element node, move position to this element
- x_SetPos( m_iPosParent, iPosNew, );
- return m_nNodeType;
- }
- token.m_nNext = ELEM(iPosNew).StartAfter();
- }
- }
- while ( nType && ! (nType & nTypeFound) );
- m_iPos = iPosNew;
- m_iPosChild = ;
- m_nNodeOffset = node.nStart;
- m_nNodeLength = node.nLength;
- m_nNodeType = nTypeFound;
- MARKUP_SETDEBUGSTATE;
- return m_nNodeType;
- }
- bool CMarkup::RemoveNode()
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- if ( m_iPos || m_nNodeLength )
- {
- x_RemoveNode( m_iPosParent, m_iPos, m_nNodeType, m_nNodeOffset, m_nNodeLength );
- m_iPosChild = ;
- MARKUP_SETDEBUGSTATE;
- return true;
- }
- return false;
- }
- MCD_STR CMarkup::GetTagName() const
- {
- // Return the tag name at the current main position
- MCD_STR strTagName;
- // This method is primarily for elements, however
- // it does return something for certain other nodes
- if ( m_nNodeLength )
- {
- switch ( m_nNodeType )
- {
- case MNT_PROCESSING_INSTRUCTION:
- case MNT_LONE_END_TAG:
- {
- // <?target or </tagname
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nNext = m_nNodeOffset + ;
- if ( token.FindName() )
- strTagName = token.GetTokenText();
- }
- break;
- case MNT_COMMENT:
- strTagName = MCD_T("#comment");
- break;
- case MNT_CDATA_SECTION:
- strTagName = MCD_T("#cdata-section");
- break;
- case MNT_DOCUMENT_TYPE:
- {
- // <!DOCTYPE name
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nNext = m_nNodeOffset + ;
- if ( token.FindName() && token.FindName() )
- strTagName = token.GetTokenText();
- }
- break;
- case MNT_TEXT:
- case MNT_WHITESPACE:
- strTagName = MCD_T("#text");
- break;
- }
- return strTagName;
- }
- if ( m_iPos )
- strTagName = x_GetTagName( m_iPos );
- return strTagName;
- }
- bool CMarkup::IntoElem()
- {
- // Make current element the parent
- if ( m_iPos && m_nNodeType == MNT_ELEMENT )
- {
- x_SetPos( m_iPos, m_iPosChild, );
- return true;
- }
- return false;
- }
- bool CMarkup::OutOfElem()
- {
- // Go to parent element
- if ( m_iPosParent )
- {
- x_SetPos( ELEM(m_iPosParent).iElemParent, m_iPosParent, m_iPos );
- return true;
- }
- return false;
- }
- bool CMarkup::GetNthAttrib( int n, MCD_STR& strAttrib, MCD_STR& strValue ) const
- {
- // Return nth attribute name and value from main position
- TokenPos token( m_strDoc, m_nDocFlags );
- if ( m_iPos && m_nNodeType == MNT_ELEMENT )
- token.m_nNext = ELEM(m_iPos).nStart + ;
- else if ( m_nNodeLength && m_nNodeType == MNT_PROCESSING_INSTRUCTION )
- token.m_nNext = m_nNodeOffset + ;
- else
- return false;
- if ( token.FindAttrib(NULL,n,&strAttrib) )
- {
- strValue = UnescapeText( token.GetTokenPtr(), token.Length(), m_nDocFlags );
- return true;
- }
- return false;
- }
- MCD_STR CMarkup::GetAttribName( int n ) const
- {
- // Return nth attribute name of main position
- TokenPos token( m_strDoc, m_nDocFlags );
- if ( m_iPos && m_nNodeType == MNT_ELEMENT )
- token.m_nNext = ELEM(m_iPos).nStart + ;
- else if ( m_nNodeLength && m_nNodeType == MNT_PROCESSING_INSTRUCTION )
- token.m_nNext = m_nNodeOffset + ;
- else
- return MCD_T("");
- if ( token.FindAttrib(NULL,n) )
- return token.GetTokenText();
- return MCD_T("");
- }
- bool CMarkup::SavePos( MCD_CSTR szPosName /*=""*/, int nMap /*=0*/ )
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Save current element position in saved position map
- if ( szPosName )
- {
- SavedPosMap* pMap;
- m_pSavedPosMaps->GetMap( pMap, nMap );
- SavedPos savedpos;
- if ( szPosName )
- savedpos.strName = szPosName;
- if ( m_iPosChild )
- {
- savedpos.iPos = m_iPosChild;
- savedpos.nSavedPosFlags |= SavedPos::SPM_CHILD;
- }
- else if ( m_iPos )
- {
- savedpos.iPos = m_iPos;
- savedpos.nSavedPosFlags |= SavedPos::SPM_MAIN;
- }
- else
- {
- savedpos.iPos = m_iPosParent;
- }
- savedpos.nSavedPosFlags |= SavedPos::SPM_USED;
- int nSlot = x_Hash( szPosName, pMap->nMapSize);
- SavedPos* pSavedPos = pMap->pTable[nSlot];
- int nOffset = ;
- if ( ! pSavedPos )
- {
- pSavedPos = new SavedPos[];
- pSavedPos[].nSavedPosFlags = SavedPos::SPM_LAST;
- pMap->pTable[nSlot] = pSavedPos;
- }
- else
- {
- while ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_USED )
- {
- if ( pSavedPos[nOffset].strName == (MCD_PCSZ)szPosName )
- break;
- if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_LAST )
- {
- int nNewSize = (nOffset + ) * ;
- SavedPos* pNewSavedPos = new SavedPos[nNewSize];
- for ( int nCopy=; nCopy<=nOffset; ++nCopy )
- pNewSavedPos[nCopy] = pSavedPos[nCopy];
- pNewSavedPos[nOffset].nSavedPosFlags ^= SavedPos::SPM_LAST;
- pNewSavedPos[nNewSize-].nSavedPosFlags = SavedPos::SPM_LAST;
- delete [] pSavedPos;
- pSavedPos = pNewSavedPos;
- pMap->pTable[nSlot] = pSavedPos;
- ++nOffset;
- break;
- }
- ++nOffset;
- }
- }
- if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_LAST )
- savedpos.nSavedPosFlags |= SavedPos::SPM_LAST;
- pSavedPos[nOffset] = savedpos;
- /*
- // To review hash table balance, uncomment and watch strBalance
- MCD_STR strBalance, strSlot;
- for ( nSlot=0; nSlot < pMap->nMapSize; ++nSlot )
- {
- pSavedPos = pMap->pTable[nSlot];
- int nCount = 0;
- while ( pSavedPos && pSavedPos->nSavedPosFlags & SavedPos::SPM_USED )
- {
- ++nCount;
- if ( pSavedPos->nSavedPosFlags & SavedPos::SPM_LAST )
- break;
- ++pSavedPos;
- }
- strSlot.Format( MCD_T("%d "), nCount );
- strBalance += strSlot;
- }
- */
- return true;
- }
- return false;
- }
- bool CMarkup::RestorePos( MCD_CSTR szPosName /*=""*/, int nMap /*=0*/ )
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Restore element position if found in saved position map
- if ( szPosName )
- {
- SavedPosMap* pMap;
- m_pSavedPosMaps->GetMap( pMap, nMap );
- int nSlot = x_Hash( szPosName, pMap->nMapSize );
- SavedPos* pSavedPos = pMap->pTable[nSlot];
- if ( pSavedPos )
- {
- int nOffset = ;
- while ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_USED )
- {
- if ( pSavedPos[nOffset].strName == (MCD_PCSZ)szPosName )
- {
- int i = pSavedPos[nOffset].iPos;
- if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_CHILD )
- x_SetPos( ELEM(ELEM(i).iElemParent).iElemParent, ELEM(i).iElemParent, i );
- else if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_MAIN )
- x_SetPos( ELEM(i).iElemParent, i, );
- else
- x_SetPos( i, , );
- return true;
- }
- if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_LAST )
- break;
- ++nOffset;
- }
- }
- }
- return false;
- }
- bool CMarkup::SetMapSize( int nSize, int nMap /*=0*/ )
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Set saved position map hash table size before using it
- // Returns false if map already exists
- // Some prime numbers: 53, 101, 211, 503, 1009, 2003, 10007, 20011, 50021, 100003, 200003, 500009
- SavedPosMap* pNewMap;
- return m_pSavedPosMaps->GetMap( pNewMap, nMap, nSize );
- }
- bool CMarkup::RemoveElem()
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Remove current main position element
- if ( m_iPos && m_nNodeType == MNT_ELEMENT )
- {
- int iPos = x_RemoveElem( m_iPos );
- x_SetPos( m_iPosParent, iPos, );
- return true;
- }
- return false;
- }
- bool CMarkup::RemoveChildElem()
- {
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Remove current child position element
- if ( m_iPosChild )
- {
- int iPosChild = x_RemoveElem( m_iPosChild );
- x_SetPos( m_iPosParent, m_iPos, iPosChild );
- return true;
- }
- return false;
- }
- //////////////////////////////////////////////////////////////////////
- // CMarkup private methods
- //
- void CMarkup::x_InitMarkup()
- {
- // Only called from CMarkup constructors
- m_pFilePos = NULL;
- m_pSavedPosMaps = new SavedPosMapArray;
- m_pElemPosTree = new ElemPosTree;
- // To always ignore case, define MARKUP_IGNORECASE
- #if defined(MARKUP_IGNORECASE) // ignore case
- m_nDocFlags = MDF_IGNORECASE;
- #else // not ignore case
- m_nDocFlags = ;
- #endif // not ignore case
- }
- int CMarkup::x_GetParent( int i )
- {
- return ELEM(i).iElemParent;
- }
- void CMarkup::x_SetPos( int iPosParent, int iPos, int iPosChild )
- {
- m_iPosParent = iPosParent;
- m_iPos = iPos;
- m_iPosChild = iPosChild;
- m_nNodeOffset = ;
- m_nNodeLength = ;
- m_nNodeType = iPos?MNT_ELEMENT:;
- MARKUP_SETDEBUGSTATE;
- }
- #if defined(_DEBUG) // DEBUG
- void CMarkup::x_SetDebugState()
- {
- // Set m_pDebugCur and m_pDebugPos to point into document
- MCD_PCSZ pD = MCD_2PCSZ(m_strDoc);
- // Node (non-element) position is determined differently in file mode
- if ( m_nNodeLength || (m_nNodeOffset && !m_pFilePos)
- || (m_pFilePos && (!m_iPos) && (!m_iPosParent) && ! m_pFilePos->FileAtTop()) )
- {
- if ( ! m_nNodeLength )
- m_pDebugCur = MCD_T("main position offset"); // file mode only
- else
- m_pDebugCur = MCD_T("main position node");
- m_pDebugPos = &pD[m_nNodeOffset];
- }
- else
- {
- if ( m_iPosChild )
- {
- m_pDebugCur = MCD_T("child position element");
- m_pDebugPos = &pD[ELEM(m_iPosChild).nStart];
- }
- else if ( m_iPos )
- {
- m_pDebugCur = MCD_T("main position element");
- m_pDebugPos = &pD[ELEM(m_iPos).nStart];
- }
- else if ( m_iPosParent )
- {
- m_pDebugCur = MCD_T("parent position element");
- m_pDebugPos = &pD[ELEM(m_iPosParent).nStart];
- }
- else
- {
- m_pDebugCur = MCD_T("top of document");
- m_pDebugPos = pD;
- }
- }
- }
- #endif // DEBUG
- int CMarkup::x_GetFreePos()
- {
- if ( m_iPosFree == m_pElemPosTree->GetSize() )
- x_AllocElemPos();
- return m_iPosFree++;
- }
- bool CMarkup::x_AllocElemPos( int nNewSize /*=0*/ )
- {
- // Resize m_aPos when the document is created or the array is filled
- if ( ! nNewSize )
- nNewSize = m_iPosFree + (m_iPosFree>>); // Grow By: multiply size by 1.5
- if ( m_pElemPosTree->GetSize() < nNewSize )
- m_pElemPosTree->GrowElemPosTree( nNewSize );
- return true;
- }
- bool CMarkup::x_ParseDoc()
- {
- // Reset indexes
- ResetPos();
- m_pSavedPosMaps->ReleaseMaps();
- // Starting size of position array: 1 element per 64 bytes of document
- // Tight fit when parsing small doc, only 0 to 2 reallocs when parsing large doc
- // Start at 8 when creating new document
- int nDocLen = MCD_STRLENGTH(m_strDoc);
- m_iPosFree = ;
- x_AllocElemPos( nDocLen / + );
- m_iPosDeleted = ;
- // Parse document
- ELEM().ClearVirtualParent();
- if ( nDocLen )
- {
- TokenPos token( m_strDoc, m_nDocFlags );
- int iPos = x_ParseElem( , token );
- ELEM().nLength = nDocLen;
- if ( iPos > )
- {
- ELEM().iElemChild = iPos;
- if ( ELEM(iPos).iElemNext )
- x_AddResult( m_strResult, MCD_T("root_has_sibling") );
- }
- else
- x_AddResult( m_strResult, MCD_T("no_root_element") );
- }
- ResetPos();
- return IsWellFormed();
- }
- int CMarkup::x_ParseElem( int iPosParent, TokenPos& token )
- {
- // This is either called by x_ParseDoc or x_AddSubDoc or x_SetElemContent
- // Returns index of the first element encountered or zero if no elements
- //
- int iPosRoot = ;
- int iPos = iPosParent;
- int iVirtualParent = iPosParent;
- int nRootDepth = ELEM(iPos).Level();
- int nMatchLevel;
- int iPosMatch;
- int iTag;
- int nTypeFound;
- int iPosFirst;
- int iPosLast;
- ElemPos* pElem;
- ElemPos* pElemParent;
- ElemPos* pElemChild;
- // Loop through the nodes of the document
- ElemStack elemstack;
- NodePos node;
- token.m_nNext = ;
- while ( )
- {
- nTypeFound = token.ParseNode( node );
- nMatchLevel = ;
- if ( nTypeFound == MNT_ELEMENT ) // start tag
- {
- iPos = x_GetFreePos();
- if ( ! iPosRoot )
- iPosRoot = iPos;
- pElem = &ELEM(iPos);
- pElem->iElemParent = iPosParent;
- pElem->iElemNext = ;
- pElemParent = &ELEM(iPosParent);
- if ( pElemParent->iElemChild )
- {
- iPosFirst = pElemParent->iElemChild;
- pElemChild = &ELEM(iPosFirst);
- iPosLast = pElemChild->iElemPrev;
- ELEM(iPosLast).iElemNext = iPos;
- pElem->iElemPrev = iPosLast;
- pElemChild->iElemPrev = iPos;
- pElem->nFlags = ;
- }
- else
- {
- pElemParent->iElemChild = iPos;
- pElem->iElemPrev = iPos;
- pElem->nFlags = MNF_FIRST;
- }
- pElem->SetLevel( nRootDepth + elemstack.iTop );
- pElem->iElemChild = ;
- pElem->nStart = node.nStart;
- pElem->SetStartTagLen( node.nLength );
- if ( node.nNodeFlags & MNF_EMPTY )
- {
- iPos = iPosParent;
- pElem->SetEndTagLen( );
- pElem->nLength = node.nLength;
- }
- else
- {
- iPosParent = iPos;
- elemstack.PushIntoLevel( token.GetTokenPtr(), token.Length() );
- }
- }
- else if ( nTypeFound == ) // end tag
- {
- iPosMatch = iPos;
- iTag = elemstack.iTop;
- nMatchLevel = iTag;
- while ( nMatchLevel && ! token.Match(elemstack.GetRefTagPosAt(iTag--).strTagName) )
- {
- --nMatchLevel;
- iPosMatch = ELEM(iPosMatch).iElemParent;
- }
- if ( nMatchLevel == )
- {
- // Not matched at all, it is a lone end tag, a non-element node
- ELEM(iVirtualParent).nFlags |= MNF_ILLFORMED;
- ELEM(iPos).nFlags |= MNF_ILLDATA;
- x_AddResult( m_strResult, MCD_T("lone_end_tag"), token.GetTokenText(), , node.nStart );
- }
- else
- {
- pElem = &ELEM(iPosMatch);
- pElem->nLength = node.nStart - pElem->nStart + node.nLength;
- pElem->SetEndTagLen( node.nLength );
- }
- }
- else if ( nTypeFound == - )
- {
- ELEM(iVirtualParent).nFlags |= MNF_ILLFORMED;
- ELEM(iPos).nFlags |= MNF_ILLDATA;
- m_strResult += node.strMeta;
- }
- // Matched end tag, or end of document
- if ( nMatchLevel || nTypeFound == - )
- {
- if ( elemstack.iTop > nMatchLevel )
- ELEM(iVirtualParent).nFlags |= MNF_ILLFORMED;
- // Process any non-ended elements
- while ( elemstack.iTop > nMatchLevel )
- {
- // Element with no end tag
- pElem = &ELEM(iPos);
- int iPosChild = pElem->iElemChild;
- iPosParent = pElem->iElemParent;
- pElem->SetEndTagLen( );
- pElem->nFlags |= MNF_NONENDED;
- pElem->iElemChild = ;
- pElem->nLength = pElem->StartTagLen();
- if ( pElem->nFlags & MNF_ILLDATA )
- {
- pElem->nFlags ^= MNF_ILLDATA;
- ELEM(iPosParent).nFlags |= MNF_ILLDATA;
- }
- while ( iPosChild )
- {
- ELEM(iPosChild).iElemParent = iPosParent;
- ELEM(iPosChild).iElemPrev = iPos;
- ELEM(iPos).iElemNext = iPosChild;
- iPos = iPosChild;
- iPosChild = ELEM(iPosChild).iElemNext;
- }
- // If end tag did not match, top node is end tag that did not match pElem
- // if end of document, any nodes below top have no end tag
- // second offset represents location where end tag was expected but end of document or other end tag was found
- // end tag that was found is token.GetTokenText() but not reported in error
- int nOffset2 = (nTypeFound==)? token.m_nL-: MCD_STRLENGTH(m_strDoc);
- x_AddResult( m_strResult, MCD_T("unended_start_tag"), elemstack.Current().strTagName, , pElem->nStart, nOffset2 );
- iPos = iPosParent;
- elemstack.PopOutOfLevel();
- }
- if ( nTypeFound == - )
- break;
- iPosParent = ELEM(iPos).iElemParent;
- iPos = iPosParent;
- elemstack.PopOutOfLevel();
- }
- }
- return iPosRoot;
- }
- int CMarkup::x_FindElem( int iPosParent, int iPos, PathPos& path ) const
- {
- // If pPath is NULL or empty, go to next sibling element
- // Otherwise go to next sibling element with matching path
- //
- if ( ! path.ValidPath() )
- return ;
- // Paths other than simple tag name are only supported in the developer version
- if ( path.IsAnywherePath() || path.IsAbsolutePath() )
- return ;
- if ( iPos )
- iPos = ELEM(iPos).iElemNext;
- else
- iPos = ELEM(iPosParent).iElemChild;
- // Finished here if pPath not specified
- if ( ! path.IsPath() )
- return iPos;
- // Search
- TokenPos token( m_strDoc, m_nDocFlags );
- while ( iPos )
- {
- // Compare tag name
- token.m_nNext = ELEM(iPos).nStart + ;
- token.FindName(); // Locate tag name
- if ( token.Match(path.GetPtr()) )
- return iPos;
- iPos = ELEM(iPos).iElemNext;
- }
- return ;
- }
- MCD_STR CMarkup::x_GetPath( int iPos ) const
- {
- // In file mode, iPos is an index into m_pFilePos->m_elemstack or zero
- MCD_STR strPath;
- while ( iPos )
- {
- MCD_STR strTagName;
- int iPosParent;
- int nCount = ;
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- {
- TagPos& tag = m_pFilePos->m_elemstack.GetRefTagPosAt(iPos);
- strTagName = tag.strTagName;
- nCount = tag.nCount;
- iPosParent = tag.iParent;
- }
- else
- {
- strTagName = x_GetTagName( iPos );
- PathPos path( MCD_2PCSZ(strTagName), false );
- iPosParent = ELEM(iPos).iElemParent;
- int iPosSib = ;
- while ( iPosSib != iPos )
- {
- path.RevertOffset();
- iPosSib = x_FindElem( iPosParent, iPosSib, path );
- ++nCount;
- }
- }
- if ( nCount == )
- strPath = MCD_T("/") + strTagName + strPath;
- else
- {
- MCD_CHAR szPred[];
- MCD_SPRINTF( MCD_SSZ(szPred), MCD_T("[%d]"), nCount );
- strPath = MCD_T("/") + strTagName + szPred + strPath;
- }
- iPos = iPosParent;
- }
- return strPath;
- }
- MCD_STR CMarkup::x_GetTagName( int iPos ) const
- {
- // Return the tag name at specified element
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nNext = ELEM(iPos).nStart + ;
- if ( ! iPos || ! token.FindName() )
- return MCD_T("");
- // Return substring of document
- return token.GetTokenText();
- }
- MCD_STR CMarkup::x_GetAttrib( int iPos, MCD_PCSZ pAttrib ) const
- {
- // Return the value of the attrib
- TokenPos token( m_strDoc, m_nDocFlags );
- if ( iPos && m_nNodeType == MNT_ELEMENT )
- token.m_nNext = ELEM(iPos).nStart + ;
- else if ( iPos == m_iPos && m_nNodeLength && m_nNodeType == MNT_PROCESSING_INSTRUCTION )
- token.m_nNext = m_nNodeOffset + ;
- else
- return MCD_T("");
- if ( pAttrib && token.FindAttrib(pAttrib) )
- return UnescapeText( token.GetTokenPtr(), token.Length(), m_nDocFlags );
- return MCD_T("");
- }
- bool CMarkup::x_SetAttrib( int iPos, MCD_PCSZ pAttrib, int nValue, int nFlags /*=0*/ )
- {
- // Convert integer to string
- MCD_CHAR szVal[];
- MCD_SPRINTF( MCD_SSZ(szVal), MCD_T("%d"), nValue );
- return x_SetAttrib( iPos, pAttrib, szVal, nFlags );
- }
- bool CMarkup::x_SetAttrib( int iPos, MCD_PCSZ pAttrib, MCD_PCSZ pValue, int nFlags /*=0*/ )
- {
- if ( m_nDocFlags & MDF_READFILE )
- return false;
- int nNodeStart = ;
- if ( iPos && m_nNodeType == MNT_ELEMENT )
- nNodeStart = ELEM(iPos).nStart;
- else if ( iPos == m_iPos && m_nNodeLength && m_nNodeType == MNT_PROCESSING_INSTRUCTION )
- nNodeStart = m_nNodeOffset;
- else
- return false;
- // Create insertion text depending on whether attribute already exists
- // Decision: for empty value leaving attrib="" instead of removing attrib
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nNext = nNodeStart + ((m_nNodeType == MNT_ELEMENT)?:);
- int nReplace = ;
- int nInsertAt;
- MCD_STR strEscapedValue = EscapeText( pValue, MNF_ESCAPEQUOTES|nFlags );
- int nEscapedValueLen = MCD_STRLENGTH( strEscapedValue );
- MCD_STR strInsert;
- if ( token.FindAttrib(pAttrib) )
- {
- // Replace value
- MCD_BLDRESERVE( strInsert, nEscapedValueLen + );
- MCD_BLDAPPEND1( strInsert, x_ATTRIBQUOTE );
- MCD_BLDAPPENDN( strInsert, MCD_2PCSZ(strEscapedValue), nEscapedValueLen );
- MCD_BLDAPPEND1( strInsert, x_ATTRIBQUOTE );
- MCD_BLDRELEASE( strInsert );
- nInsertAt = token.m_nL - ((token.m_nTokenFlags&MNF_QUOTED)?:);
- nReplace = token.Length() + ((token.m_nTokenFlags&MNF_QUOTED)?:);
- }
- else
- {
- // Insert string name value pair
- int nAttribNameLen = MCD_PSZLEN( pAttrib );
- MCD_BLDRESERVE( strInsert, nAttribNameLen + nEscapedValueLen + );
- MCD_BLDAPPEND1( strInsert, ' ' );
- MCD_BLDAPPENDN( strInsert, pAttrib, nAttribNameLen );
- MCD_BLDAPPEND1( strInsert, '=' );
- MCD_BLDAPPEND1( strInsert, x_ATTRIBQUOTE );
- MCD_BLDAPPENDN( strInsert, MCD_2PCSZ(strEscapedValue), nEscapedValueLen );
- MCD_BLDAPPEND1( strInsert, x_ATTRIBQUOTE );
- MCD_BLDRELEASE( strInsert );
- nInsertAt = token.m_nNext;
- }
- int nAdjust = MCD_STRLENGTH(strInsert) - nReplace;
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- int nNewDocLength = MCD_STRLENGTH(m_strDoc) + nAdjust;
- MCD_STRCLEAR( m_strResult );
- if ( nNodeStart && nNewDocLength > m_pFilePos->m_nBlockSizeBasis )
- {
- int nDocCapacity = MCD_STRCAPACITY(m_strDoc);
- if ( nNewDocLength > nDocCapacity )
- {
- m_pFilePos->FileFlush( *m_pFilePos->m_pstrBuffer, nNodeStart );
- m_strResult = m_pFilePos->m_strIOResult;
- nInsertAt -= nNodeStart;
- m_nNodeOffset = ;
- if ( m_nNodeType == MNT_ELEMENT )
- ELEM(iPos).nStart = ;
- }
- }
- }
- x_DocChange( nInsertAt, nReplace, strInsert );
- if ( m_nNodeType == MNT_PROCESSING_INSTRUCTION )
- {
- x_AdjustForNode( m_iPosParent, m_iPos, nAdjust );
- m_nNodeLength += nAdjust;
- }
- else
- {
- ELEM(iPos).AdjustStartTagLen( nAdjust );
- ELEM(iPos).nLength += nAdjust;
- x_Adjust( iPos, nAdjust );
- }
- MARKUP_SETDEBUGSTATE;
- return true;
- }
- bool CMarkup::x_CreateNode( MCD_STR& strNode, int nNodeType, MCD_PCSZ pText )
- {
- // Set strNode based on nNodeType and szData
- // Return false if szData would jeopardize well-formed document
- //
- switch ( nNodeType )
- {
- case MNT_PROCESSING_INSTRUCTION:
- strNode = MCD_T("<?");
- strNode += pText;
- strNode += MCD_T("?>");
- break;
- case MNT_COMMENT:
- strNode = MCD_T("<!--");
- strNode += pText;
- strNode += MCD_T("-->");
- break;
- case MNT_ELEMENT:
- strNode = MCD_T("<");
- strNode += pText;
- strNode += MCD_T("/>");
- break;
- case MNT_TEXT:
- case MNT_WHITESPACE:
- strNode = EscapeText( pText );
- break;
- case MNT_DOCUMENT_TYPE:
- strNode = pText;
- break;
- case MNT_LONE_END_TAG:
- strNode = MCD_T("</");
- strNode += pText;
- strNode += MCD_T(">");
- break;
- case MNT_CDATA_SECTION:
- if ( MCD_PSZSTR(pText,MCD_T("]]>")) != NULL )
- return false;
- strNode = MCD_T("<![CDATA[");
- strNode += pText;
- strNode += MCD_T("]]>");
- break;
- }
- return true;
- }
- MCD_STR CMarkup::x_EncodeCDATASection( MCD_PCSZ szData )
- {
- // Split CDATA Sections if there are any end delimiters
- MCD_STR strData = MCD_T("<![CDATA[");
- MCD_PCSZ pszNextStart = szData;
- MCD_PCSZ pszEnd = MCD_PSZSTR( szData, MCD_T("]]>") );
- while ( pszEnd )
- {
- strData += MCD_STR( pszNextStart, (int)(pszEnd - pszNextStart) );
- strData += MCD_T("]]]]><![CDATA[>");
- pszNextStart = pszEnd + ;
- pszEnd = MCD_PSZSTR( pszNextStart, MCD_T("]]>") );
- }
- strData += pszNextStart;
- strData += MCD_T("]]>");
- return strData;
- }
- bool CMarkup::x_SetData( int iPos, int nValue )
- {
- // Convert integer to string
- MCD_CHAR szVal[];
- MCD_SPRINTF( MCD_SSZ(szVal), MCD_T("%d"), nValue );
- return x_SetData( iPos, szVal, );
- }
- bool CMarkup::x_SetData( int iPos, MCD_PCSZ szData, int nFlags )
- {
- if ( m_nDocFlags & MDF_READFILE )
- return false;
- MCD_STR strInsert;
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- if ( ! iPos || m_nNodeType != || ! ELEM(iPos).IsEmptyElement() )
- return false; // only set data on current empty element (no other kinds of nodes)
- }
- if ( iPos == m_iPos && m_nNodeLength )
- {
- // Not an element
- if ( ! x_CreateNode(strInsert, m_nNodeType, szData) )
- return false;
- x_DocChange( m_nNodeOffset, m_nNodeLength, strInsert );
- x_AdjustForNode( m_iPosParent, iPos, MCD_STRLENGTH(strInsert) - m_nNodeLength );
- m_nNodeLength = MCD_STRLENGTH(strInsert);
- MARKUP_SETDEBUGSTATE;
- return true;
- }
- // Set data in iPos element
- if ( ! iPos || ELEM(iPos).iElemChild )
- return false;
- // Build strInsert from szData based on nFlags
- if ( nFlags & MNF_WITHCDATA )
- strInsert = x_EncodeCDATASection( szData );
- else
- strInsert = EscapeText( szData, nFlags );
- // Insert
- NodePos node( MNF_WITHNOLINES|MNF_REPLACE );
- node.strMeta = strInsert;
- int iPosBefore = ;
- int nReplace = x_InsertNew( iPos, iPosBefore, node );
- int nAdjust = MCD_STRLENGTH(node.strMeta) - nReplace;
- x_Adjust( iPos, nAdjust );
- ELEM(iPos).nLength += nAdjust;
- if ( ELEM(iPos).nFlags & MNF_ILLDATA )
- ELEM(iPos).nFlags &= ~MNF_ILLDATA;
- MARKUP_SETDEBUGSTATE;
- return true;
- }
- MCD_STR CMarkup::x_GetData( int iPos )
- {
- if ( iPos == m_iPos && m_nNodeLength )
- {
- if ( m_nNodeType == MNT_COMMENT )
- return MCD_STRMID( m_strDoc, m_nNodeOffset+, m_nNodeLength- );
- else if ( m_nNodeType == MNT_PROCESSING_INSTRUCTION )
- return MCD_STRMID( m_strDoc, m_nNodeOffset+, m_nNodeLength- );
- else if ( m_nNodeType == MNT_CDATA_SECTION )
- return MCD_STRMID( m_strDoc, m_nNodeOffset+, m_nNodeLength- );
- else if ( m_nNodeType == MNT_TEXT )
- return UnescapeText( &(MCD_2PCSZ(m_strDoc))[m_nNodeOffset], m_nNodeLength, m_nDocFlags );
- else if ( m_nNodeType == MNT_LONE_END_TAG )
- return MCD_STRMID( m_strDoc, m_nNodeOffset+, m_nNodeLength- );
- return MCD_STRMID( m_strDoc, m_nNodeOffset, m_nNodeLength );
- }
- // Return a string representing data between start and end tag
- // Return empty string if there are any children elements
- MCD_STR strData;
- if ( iPos && ! ELEM(iPos).IsEmptyElement() )
- {
- ElemPos* pElem = &ELEM(iPos);
- int nStartContent = pElem->StartContent();
- if ( pElem->IsUnparsed() )
- {
- TokenPos token( m_strDoc, m_nDocFlags, m_pFilePos );
- token.m_nNext = nStartContent;
- NodePos node;
- m_pFilePos->m_nReadBufferStart = pElem->nStart;
- while ( )
- {
- m_pFilePos->m_nReadBufferRemoved = ; // will be non-zero after ParseNode if read buffer shifted
- token.ParseNode( node );
- if ( m_pFilePos->m_nReadBufferRemoved )
- {
- pElem->nStart = ;
- MARKUP_SETDEBUGSTATE;
- }
- if ( node.nNodeType == MNT_TEXT )
- strData += UnescapeText( &token.m_pDocText[node.nStart], node.nLength, m_nDocFlags );
- else if ( node.nNodeType == MNT_CDATA_SECTION )
- strData += MCD_STRMID( m_strDoc, node.nStart+, node.nLength- );
- else if ( node.nNodeType == MNT_ELEMENT )
- {
- MCD_STRCLEAR(strData);
- break;
- }
- else if ( node.nNodeType == )
- {
- if ( token.Match(m_pFilePos->m_elemstack.Current().strTagName) )
- {
- pElem->SetEndTagLen( node.nLength );
- pElem->nLength = node.nStart + node.nLength - pElem->nStart;
- m_pFilePos->m_elemstack.OutOfLevel();
- }
- else
- {
- MCD_STRCLEAR(strData);
- }
- break;
- }
- }
- }
- else if ( ! pElem->iElemChild )
- {
- // Quick scan for any tags inside content
- int nContentLen = pElem->ContentLen();
- MCD_PCSZ pszContent = &(MCD_2PCSZ(m_strDoc))[nStartContent];
- MCD_PCSZ pszTag = MCD_PSZCHR( pszContent, '<' );
- if ( pszTag && ((int)(pszTag-pszContent) < nContentLen) )
- {
- // Concatenate all CDATA Sections and text nodes, ignore other nodes
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nNext = nStartContent;
- NodePos node;
- while ( token.m_nNext < nStartContent + nContentLen )
- {
- token.ParseNode( node );
- if ( node.nNodeType == MNT_TEXT )
- strData += UnescapeText( &token.m_pDocText[node.nStart], node.nLength, m_nDocFlags );
- else if ( node.nNodeType == MNT_CDATA_SECTION )
- strData += MCD_STRMID( m_strDoc, node.nStart+, node.nLength- );
- }
- }
- else // no tags
- strData = UnescapeText( &(MCD_2PCSZ(m_strDoc))[nStartContent], nContentLen, m_nDocFlags );
- }
- }
- return strData;
- }
- MCD_STR CMarkup::x_GetElemContent( int iPos ) const
- {
- if ( ! (m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE)) )
- {
- ElemPos* pElem = &ELEM(iPos);
- if ( iPos && pElem->ContentLen() )
- return MCD_STRMID( m_strDoc, pElem->StartContent(), pElem->ContentLen() );
- }
- return MCD_T("");
- }
- bool CMarkup::x_SetElemContent( MCD_PCSZ szContent )
- {
- MCD_STRCLEAR(m_strResult);
- if ( m_nDocFlags & (MDF_READFILE|MDF_WRITEFILE) )
- return false;
- // Set data in iPos element only
- if ( ! m_iPos )
- return false;
- if ( m_nNodeLength )
- return false; // not an element
- // Unlink all children
- int iPos = m_iPos;
- int iPosChild = ELEM(iPos).iElemChild;
- bool bHadChild = (iPosChild != );
- while ( iPosChild )
- iPosChild = x_ReleaseSubDoc( iPosChild );
- if ( bHadChild )
- x_CheckSavedPos();
- // Parse content
- bool bWellFormed = true;
- TokenPos token( szContent, m_nDocFlags );
- int iPosVirtual = x_GetFreePos();
- ELEM(iPosVirtual).ClearVirtualParent();
- ELEM(iPosVirtual).SetLevel( ELEM(iPos).Level() + );
- iPosChild = x_ParseElem( iPosVirtual, token );
- if ( ELEM(iPosVirtual).nFlags & MNF_ILLFORMED )
- bWellFormed = false;
- ELEM(iPos).nFlags = (ELEM(iPos).nFlags & ~MNF_ILLDATA) | (ELEM(iPosVirtual).nFlags & MNF_ILLDATA);
- // Prepare insert and adjust offsets
- NodePos node( MNF_WITHNOLINES|MNF_REPLACE );
- node.strMeta = szContent;
- int iPosBefore = ;
- int nReplace = x_InsertNew( iPos, iPosBefore, node );
- // Adjust and link in the inserted elements
- x_Adjust( iPosChild, node.nStart );
- ELEM(iPosChild).nStart += node.nStart;
- ELEM(iPos).iElemChild = iPosChild;
- while ( iPosChild )
- {
- ELEM(iPosChild).iElemParent = iPos;
- iPosChild = ELEM(iPosChild).iElemNext;
- }
- x_ReleasePos( iPosVirtual );
- int nAdjust = MCD_STRLENGTH(node.strMeta) - nReplace;
- x_Adjust( iPos, nAdjust, true );
- ELEM(iPos).nLength += nAdjust;
- x_SetPos( m_iPosParent, m_iPos, );
- return bWellFormed;
- }
- void CMarkup::x_DocChange( int nLeft, int nReplace, const MCD_STR& strInsert )
- {
- x_StrInsertReplace( m_strDoc, nLeft, nReplace, strInsert );
- }
- void CMarkup::x_Adjust( int iPos, int nShift, bool bAfterPos /*=false*/ )
- {
- // Loop through affected elements and adjust indexes
- // Algorithm:
- // 1. update children unless bAfterPos
- // (if no children or bAfterPos is true, length of iPos not affected)
- // 2. update starts of next siblings and their children
- // 3. go up until there is a next sibling of a parent and update starts
- // 4. step 2
- int iPosTop = ELEM(iPos).iElemParent;
- bool bPosFirst = bAfterPos; // mark as first to skip its children
- // Stop when we've reached the virtual parent (which has no tags)
- while ( ELEM(iPos).StartTagLen() )
- {
- // Were we at containing parent of affected position?
- bool bPosTop = false;
- if ( iPos == iPosTop )
- {
- // Move iPosTop up one towards root
- iPosTop = ELEM(iPos).iElemParent;
- bPosTop = true;
- }
- // Traverse to the next update position
- if ( ! bPosTop && ! bPosFirst && ELEM(iPos).iElemChild )
- {
- // Depth first
- iPos = ELEM(iPos).iElemChild;
- }
- else if ( ELEM(iPos).iElemNext )
- {
- iPos = ELEM(iPos).iElemNext;
- }
- else
- {
- // Look for next sibling of a parent of iPos
- // When going back up, parents have already been done except iPosTop
- while ( )
- {
- iPos = ELEM(iPos).iElemParent;
- if ( iPos == iPosTop )
- break;
- if ( ELEM(iPos).iElemNext )
- {
- iPos = ELEM(iPos).iElemNext;
- break;
- }
- }
- }
- bPosFirst = false;
- // Shift indexes at iPos
- if ( iPos != iPosTop )
- ELEM(iPos).nStart += nShift;
- else
- ELEM(iPos).nLength += nShift;
- }
- }
- int CMarkup::x_InsertNew( int iPosParent, int& iPosRel, NodePos& node )
- {
- // Parent empty tag or tags with no content?
- bool bEmptyParentTag = iPosParent && ELEM(iPosParent).IsEmptyElement();
- bool bNoContentParentTags = iPosParent && ! ELEM(iPosParent).ContentLen();
- if ( iPosRel && ! node.nLength ) // current position element?
- {
- node.nStart = ELEM(iPosRel).nStart;
- if ( ! (node.nNodeFlags & MNF_INSERT) ) // follow iPosRel
- node.nStart += ELEM(iPosRel).nLength;
- }
- else if ( bEmptyParentTag ) // parent has no separate end tag?
- {
- // Split empty parent element
- if ( ELEM(iPosParent).nFlags & MNF_NONENDED )
- node.nStart = ELEM(iPosParent).StartContent();
- else
- node.nStart = ELEM(iPosParent).StartContent() - ;
- }
- else if ( node.nLength || (m_nDocFlags&MDF_WRITEFILE) ) // non-element node or a file mode zero length position?
- {
- if ( ! (node.nNodeFlags & MNF_INSERT) )
- node.nStart += node.nLength; // after node or file mode position
- }
- else // no current node
- {
- // Insert relative to parent's content
- if ( node.nNodeFlags & (MNF_INSERT|MNF_REPLACE) )
- node.nStart = ELEM(iPosParent).StartContent(); // beginning of parent's content
- else // in front of parent's end tag
- node.nStart = ELEM(iPosParent).StartAfter() - ELEM(iPosParent).EndTagLen();
- }
- // Go up to start of next node, unless its splitting an empty element
- if ( ! (node.nNodeFlags&(MNF_WITHNOLINES|MNF_REPLACE)) && ! bEmptyParentTag )
- {
- TokenPos token( m_strDoc, m_nDocFlags );
- node.nStart = token.WhitespaceToTag( node.nStart );
- }
- // Is insert relative to element position? (i.e. not other kind of node)
- if ( ! node.nLength )
- {
- // Modify iPosRel to reflect position before
- if ( iPosRel )
- {
- if ( node.nNodeFlags & MNF_INSERT )
- {
- if ( ! (ELEM(iPosRel).nFlags & MNF_FIRST) )
- iPosRel = ELEM(iPosRel).iElemPrev;
- else
- iPosRel = ;
- }
- }
- else if ( ! (node.nNodeFlags & MNF_INSERT) )
- {
- // If parent has a child, add after last child
- if ( ELEM(iPosParent).iElemChild )
- iPosRel = ELEM(ELEM(iPosParent).iElemChild).iElemPrev;
- }
- }
- // Get node length (needed for x_AddNode and x_AddSubDoc in file write mode)
- node.nLength = MCD_STRLENGTH(node.strMeta);
- // Prepare end of lines
- if ( (! (node.nNodeFlags & MNF_WITHNOLINES)) && (bEmptyParentTag || bNoContentParentTags) )
- node.nStart += MCD_EOLLEN;
- if ( ! (node.nNodeFlags & MNF_WITHNOLINES) )
- node.strMeta += MCD_EOL;
- // Calculate insert offset and replace length
- int nReplace = ;
- int nInsertAt = node.nStart;
- if ( bEmptyParentTag )
- {
- MCD_STR strTagName = x_GetTagName( iPosParent );
- MCD_STR strFormat;
- if ( node.nNodeFlags & MNF_WITHNOLINES )
- strFormat = MCD_T(">");
- else
- strFormat = MCD_T(">") MCD_EOL;
- strFormat += node.strMeta;
- strFormat += MCD_T("</");
- strFormat += strTagName;
- node.strMeta = strFormat;
- if ( ELEM(iPosParent).nFlags & MNF_NONENDED )
- {
- nInsertAt = ELEM(iPosParent).StartAfter() - ;
- nReplace = ;
- ELEM(iPosParent).nFlags ^= MNF_NONENDED;
- }
- else
- {
- nInsertAt = ELEM(iPosParent).StartAfter() - ;
- nReplace = ;
- ELEM(iPosParent).AdjustStartTagLen( - );
- }
- ELEM(iPosParent).SetEndTagLen( + MCD_STRLENGTH(strTagName) );
- }
- else
- {
- if ( node.nNodeFlags & MNF_REPLACE )
- {
- nInsertAt = ELEM(iPosParent).StartContent();
- nReplace = ELEM(iPosParent).ContentLen();
- }
- else if ( bNoContentParentTags )
- {
- node.strMeta = MCD_EOL + node.strMeta;
- nInsertAt = ELEM(iPosParent).StartContent();
- }
- }
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- // Check if buffer is full
- int nNewDocLength = MCD_STRLENGTH(m_strDoc) + MCD_STRLENGTH(node.strMeta) - nReplace;
- int nFlushTo = node.nStart;
- MCD_STRCLEAR( m_strResult );
- if ( bEmptyParentTag )
- nFlushTo = ELEM(iPosParent).nStart;
- if ( nFlushTo && nNewDocLength > m_pFilePos->m_nBlockSizeBasis )
- {
- int nDocCapacity = MCD_STRCAPACITY(m_strDoc);
- if ( nNewDocLength > nDocCapacity )
- {
- if ( bEmptyParentTag )
- ELEM(iPosParent).nStart = ;
- node.nStart -= nFlushTo;
- nInsertAt -= nFlushTo;
- m_pFilePos->FileFlush( m_strDoc, nFlushTo );
- m_strResult = m_pFilePos->m_strIOResult;
- }
- }
- }
- x_DocChange( nInsertAt, nReplace, node.strMeta );
- return nReplace;
- }
- bool CMarkup::x_AddElem( MCD_PCSZ pName, int nValue, int nFlags )
- {
- // Convert integer to string
- MCD_CHAR szVal[];
- MCD_SPRINTF( MCD_SSZ(szVal), MCD_T("%d"), nValue );
- return x_AddElem( pName, szVal, nFlags );
- }
- bool CMarkup::x_AddElem( MCD_PCSZ pName, MCD_PCSZ pValue, int nFlags )
- {
- if ( m_nDocFlags & MDF_READFILE )
- return false;
- if ( nFlags & MNF_CHILD )
- {
- // Adding a child element under main position
- if ( ! m_iPos || (m_nDocFlags & MDF_WRITEFILE) )
- return false;
- }
- // Cannot have data in non-ended element
- if ( (nFlags&MNF_WITHNOEND) && pValue && pValue[] )
- return false;
- // Node and element structures
- NodePos node( nFlags );
- int iPosParent = , iPosBefore = ;
- int iPos = x_GetFreePos();
- ElemPos* pElem = &ELEM(iPos);
- // Locate where to add element relative to current node
- if ( nFlags & MNF_CHILD )
- {
- iPosParent = m_iPos;
- iPosBefore = m_iPosChild;
- }
- else
- {
- iPosParent = m_iPosParent;
- iPosBefore = m_iPos;
- node.nStart = m_nNodeOffset;
- node.nLength = m_nNodeLength;
- }
- // Create string for insert
- // If no pValue is specified, an empty element is created
- // i.e. either <NAME>value</NAME> or <NAME/>
- //
- int nLenName = MCD_PSZLEN(pName);
- if ( ! pValue || ! pValue[] )
- {
- // <NAME/> empty element
- MCD_BLDRESERVE( node.strMeta, nLenName + );
- MCD_BLDAPPEND1( node.strMeta, '<' );
- MCD_BLDAPPENDN( node.strMeta, pName, nLenName );
- if ( nFlags & MNF_WITHNOEND )
- {
- MCD_BLDAPPEND1( node.strMeta, '>' );
- }
- else
- {
- if ( nFlags & MNF_WITHXHTMLSPACE )
- {
- MCD_BLDAPPENDN( node.strMeta, MCD_T(" />"), );
- }
- else
- {
- MCD_BLDAPPENDN( node.strMeta, MCD_T("/>"), );
- }
- }
- MCD_BLDRELEASE( node.strMeta );
- pElem->nLength = MCD_STRLENGTH( node.strMeta );
- pElem->SetStartTagLen( pElem->nLength );
- pElem->SetEndTagLen( );
- }
- else
- {
- // <NAME>value</NAME>
- MCD_STR strValue;
- if ( nFlags & MNF_WITHCDATA )
- strValue = x_EncodeCDATASection( pValue );
- else
- strValue = EscapeText( pValue, nFlags );
- int nLenValue = MCD_STRLENGTH(strValue);
- pElem->nLength = nLenName * + nLenValue + ;
- MCD_BLDRESERVE( node.strMeta, pElem->nLength );
- MCD_BLDAPPEND1( node.strMeta, '<' );
- MCD_BLDAPPENDN( node.strMeta, pName, nLenName );
- MCD_BLDAPPEND1( node.strMeta, '>' );
- MCD_BLDAPPENDN( node.strMeta, MCD_2PCSZ(strValue), nLenValue );
- MCD_BLDAPPENDN( node.strMeta, MCD_T("</"), );
- MCD_BLDAPPENDN( node.strMeta, pName, nLenName );
- MCD_BLDAPPEND1( node.strMeta, '>' );
- MCD_BLDRELEASE( node.strMeta );
- pElem->SetEndTagLen( nLenName + );
- pElem->SetStartTagLen( nLenName + );
- }
- // Insert
- int nReplace = x_InsertNew( iPosParent, iPosBefore, node );
- pElem->nStart = node.nStart;
- pElem->iElemChild = ;
- if ( nFlags & MNF_WITHNOEND )
- pElem->nFlags = MNF_NONENDED;
- else
- pElem->nFlags = ;
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- iPosParent = x_UnlinkPrevElem( iPosParent, iPosBefore, iPos );
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nL = pElem->nStart + ;
- token.m_nR = pElem->nStart + nLenName;
- m_pFilePos->m_elemstack.PushTagAndCount( token );
- }
- else
- {
- x_LinkElem( iPosParent, iPosBefore, iPos );
- x_Adjust( iPos, MCD_STRLENGTH(node.strMeta) - nReplace );
- }
- if ( nFlags & MNF_CHILD )
- x_SetPos( m_iPosParent, iPosParent, iPos );
- else
- x_SetPos( iPosParent, iPos, );
- return true;
- }
- MCD_STR CMarkup::x_GetSubDoc( int iPos )
- {
- if ( iPos && ! (m_nDocFlags&MDF_WRITEFILE) )
- {
- if ( ! (m_nDocFlags&MDF_READFILE) )
- {
- TokenPos token( m_strDoc, m_nDocFlags );
- token.WhitespaceToTag( ELEM(iPos).StartAfter() );
- token.m_nL = ELEM(iPos).nStart;
- return token.GetTokenText();
- }
- }
- return MCD_T("");
- }
- bool CMarkup::x_AddSubDoc( MCD_PCSZ pSubDoc, int nFlags )
- {
- if ( m_nDocFlags & MDF_READFILE || ((nFlags & MNF_CHILD) && (m_nDocFlags & MDF_WRITEFILE)) )
- return false;
- MCD_STRCLEAR(m_strResult);
- NodePos node( nFlags );
- int iPosParent, iPosBefore;
- if ( nFlags & MNF_CHILD )
- {
- // Add a subdocument under main position, before or after child
- if ( ! m_iPos )
- return false;
- iPosParent = m_iPos;
- iPosBefore = m_iPosChild;
- }
- else
- {
- // Add a subdocument under parent position, before or after main
- iPosParent = m_iPosParent;
- iPosBefore = m_iPos;
- node.nStart = m_nNodeOffset;
- node.nLength = m_nNodeLength;
- }
- // Parse subdocument, generating indexes based on the subdocument string to be offset later
- bool bWellFormed = true;
- TokenPos token( pSubDoc, m_nDocFlags );
- int iPosVirtual = x_GetFreePos();
- ELEM(iPosVirtual).ClearVirtualParent();
- ELEM(iPosVirtual).SetLevel( ELEM(iPosParent).Level() + );
- int iPos = x_ParseElem( iPosVirtual, token );
- if ( (!iPos) || ELEM(iPosVirtual).nFlags & MNF_ILLFORMED )
- bWellFormed = false;
- if ( ELEM(iPosVirtual).nFlags & MNF_ILLDATA )
- ELEM(iPosParent).nFlags |= MNF_ILLDATA;
- // File write mode handling
- bool bBypassSubDoc = false;
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- // Current position will bypass subdoc unless well-formed single element
- if ( (! bWellFormed) || ELEM(iPos).iElemChild || ELEM(iPos).iElemNext )
- bBypassSubDoc = true;
- // Count tag names of top level elements (usually one) in given markup
- int iPosTop = iPos;
- while ( iPosTop )
- {
- token.m_nNext = ELEM(iPosTop).nStart + ;
- token.FindName();
- m_pFilePos->m_elemstack.PushTagAndCount( token );
- iPosTop = ELEM(iPosTop).iElemNext;
- }
- }
- // Extract subdocument without leading/trailing nodes
- int nExtractStart = ;
- int iPosLast = ELEM(iPos).iElemPrev;
- if ( bWellFormed )
- {
- nExtractStart = ELEM(iPos).nStart;
- int nExtractLength = ELEM(iPos).nLength;
- if ( iPos != iPosLast )
- {
- nExtractLength = ELEM(iPosLast).nStart - nExtractStart + ELEM(iPosLast).nLength;
- bWellFormed = false; // treat as subdoc here, but return not well-formed
- }
- MCD_STRASSIGN(node.strMeta,&pSubDoc[nExtractStart],nExtractLength);
- }
- else
- {
- node.strMeta = pSubDoc;
- node.nNodeFlags |= MNF_WITHNOLINES;
- }
- // Insert
- int nReplace = x_InsertNew( iPosParent, iPosBefore, node );
- // Clean up indexes
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- if ( bBypassSubDoc )
- {
- // Release indexes used in parsing the subdocument
- m_iPosParent = x_UnlinkPrevElem( iPosParent, iPosBefore, );
- m_iPosFree = ;
- m_iPosDeleted = ;
- m_iPos = ;
- m_nNodeOffset = node.nStart + node.nLength;
- m_nNodeLength = ;
- m_nNodeType = ;
- MARKUP_SETDEBUGSTATE;
- return bWellFormed;
- }
- else // single element added
- {
- m_iPos = iPos;
- ElemPos* pElem = &ELEM(iPos);
- pElem->nStart = node.nStart;
- m_iPosParent = x_UnlinkPrevElem( iPosParent, iPosBefore, iPos );
- x_ReleasePos( iPosVirtual );
- }
- }
- else
- {
- // Adjust and link in the inserted elements
- // iPosVirtual will stop it from affecting rest of document
- int nAdjust = node.nStart - nExtractStart;
- if ( iPos && nAdjust )
- {
- x_Adjust( iPos, nAdjust );
- ELEM(iPos).nStart += nAdjust;
- }
- int iPosChild = iPos;
- while ( iPosChild )
- {
- int iPosNext = ELEM(iPosChild).iElemNext;
- x_LinkElem( iPosParent, iPosBefore, iPosChild );
- iPosBefore = iPosChild;
- iPosChild = iPosNext;
- }
- x_ReleasePos( iPosVirtual );
- // Now adjust remainder of document
- x_Adjust( iPosLast, MCD_STRLENGTH(node.strMeta) - nReplace, true );
- }
- // Set position to top element of subdocument
- if ( nFlags & MNF_CHILD )
- x_SetPos( m_iPosParent, iPosParent, iPos );
- else // Main
- x_SetPos( m_iPosParent, iPos, );
- return bWellFormed;
- }
- int CMarkup::x_RemoveElem( int iPos )
- {
- // Determine whether any whitespace up to next tag
- TokenPos token( m_strDoc, m_nDocFlags );
- int nAfterEnd = token.WhitespaceToTag( ELEM(iPos).StartAfter() );
- // Remove from document, adjust affected indexes, and unlink
- int nLen = nAfterEnd - ELEM(iPos).nStart;
- x_DocChange( ELEM(iPos).nStart, nLen, MCD_STR() );
- x_Adjust( iPos, - nLen, true );
- int iPosPrev = x_UnlinkElem( iPos );
- x_CheckSavedPos();
- return iPosPrev; // new position
- }
- void CMarkup::x_LinkElem( int iPosParent, int iPosBefore, int iPos )
- {
- // Update links between elements and initialize nFlags
- ElemPos* pElem = &ELEM(iPos);
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- // In file write mode, only keep virtual parent 0 plus one element
- if ( iPosParent )
- x_ReleasePos( iPosParent );
- else if ( iPosBefore )
- x_ReleasePos( iPosBefore );
- iPosParent = ;
- ELEM(iPosParent).iElemChild = iPos;
- pElem->iElemParent = iPosParent;
- pElem->iElemPrev = iPos;
- pElem->iElemNext = ;
- pElem->nFlags |= MNF_FIRST;
- }
- else
- {
- pElem->iElemParent = iPosParent;
- if ( iPosBefore )
- {
- // Link in after iPosBefore
- pElem->nFlags &= ~MNF_FIRST;
- pElem->iElemNext = ELEM(iPosBefore).iElemNext;
- if ( pElem->iElemNext )
- ELEM(pElem->iElemNext).iElemPrev = iPos;
- else
- ELEM(ELEM(iPosParent).iElemChild).iElemPrev = iPos;
- ELEM(iPosBefore).iElemNext = iPos;
- pElem->iElemPrev = iPosBefore;
- }
- else
- {
- // Link in as first child
- pElem->nFlags |= MNF_FIRST;
- if ( ELEM(iPosParent).iElemChild )
- {
- pElem->iElemNext = ELEM(iPosParent).iElemChild;
- pElem->iElemPrev = ELEM(pElem->iElemNext).iElemPrev;
- ELEM(pElem->iElemNext).iElemPrev = iPos;
- ELEM(pElem->iElemNext).nFlags ^= MNF_FIRST;
- }
- else
- {
- pElem->iElemNext = ;
- pElem->iElemPrev = iPos;
- }
- ELEM(iPosParent).iElemChild = iPos;
- }
- if ( iPosParent )
- pElem->SetLevel( ELEM(iPosParent).Level() + );
- }
- }
- int CMarkup::x_UnlinkElem( int iPos )
- {
- // Fix links to remove element and mark as deleted
- // return previous position or zero if none
- ElemPos* pElem = &ELEM(iPos);
- // Find previous sibling and bypass removed element
- int iPosPrev = ;
- if ( pElem->nFlags & MNF_FIRST )
- {
- if ( pElem->iElemNext ) // set next as first child
- {
- ELEM(pElem->iElemParent).iElemChild = pElem->iElemNext;
- ELEM(pElem->iElemNext).iElemPrev = pElem->iElemPrev;
- ELEM(pElem->iElemNext).nFlags |= MNF_FIRST;
- }
- else // no children remaining
- ELEM(pElem->iElemParent).iElemChild = ;
- }
- else
- {
- iPosPrev = pElem->iElemPrev;
- ELEM(iPosPrev).iElemNext = pElem->iElemNext;
- if ( pElem->iElemNext )
- ELEM(pElem->iElemNext).iElemPrev = iPosPrev;
- else
- ELEM(ELEM(pElem->iElemParent).iElemChild).iElemPrev = iPosPrev;
- }
- x_ReleaseSubDoc( iPos );
- return iPosPrev;
- }
- int CMarkup::x_UnlinkPrevElem( int iPosParent, int iPosBefore, int iPos )
- {
- // In file write mode, only keep virtual parent 0 plus one element if currently at element
- if ( iPosParent )
- {
- x_ReleasePos( iPosParent );
- iPosParent = ;
- }
- else if ( iPosBefore )
- x_ReleasePos( iPosBefore );
- ELEM(iPosParent).iElemChild = iPos;
- ELEM(iPosParent).nLength = MCD_STRLENGTH(m_strDoc);
- if ( iPos )
- {
- ElemPos* pElem = &ELEM(iPos);
- pElem->iElemParent = iPosParent;
- pElem->iElemPrev = iPos;
- pElem->iElemNext = ;
- pElem->nFlags |= MNF_FIRST;
- }
- return iPosParent;
- }
- int CMarkup::x_ReleasePos( int iPos )
- {
- int iPosNext = ELEM(iPos).iElemNext;
- ELEM(iPos).iElemNext = m_iPosDeleted;
- ELEM(iPos).nFlags = MNF_DELETED;
- m_iPosDeleted = iPos;
- return iPosNext;
- }
- int CMarkup::x_ReleaseSubDoc( int iPos )
- {
- // Mark position structures as deleted by depth first traversal
- // Tricky because iElemNext used in traversal is overwritten for linked list of deleted
- // Return value is what iElemNext was before being overwritten
- //
- int iPosNext = , iPosTop = iPos;
- while ( )
- {
- if ( ELEM(iPos).iElemChild )
- iPos = ELEM(iPos).iElemChild;
- else
- {
- while ( )
- {
- iPosNext = x_ReleasePos( iPos );
- if ( iPosNext || iPos == iPosTop )
- break;
- iPos = ELEM(iPos).iElemParent;
- }
- if ( iPos == iPosTop )
- break;
- iPos = iPosNext;
- }
- }
- return iPosNext;
- }
- void CMarkup::x_CheckSavedPos()
- {
- // Remove any saved positions now pointing to deleted elements
- // Must be done as part of element removal before position reassigned
- if ( m_pSavedPosMaps->m_pMaps )
- {
- int nMap = ;
- while ( m_pSavedPosMaps->m_pMaps[nMap] )
- {
- SavedPosMap* pMap = m_pSavedPosMaps->m_pMaps[nMap];
- for ( int nSlot = ; nSlot < pMap->nMapSize; ++nSlot )
- {
- SavedPos* pSavedPos = pMap->pTable[nSlot];
- if ( pSavedPos )
- {
- int nOffset = ;
- int nSavedPosCount = ;
- while ( )
- {
- if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_USED )
- {
- int iPos = pSavedPos[nOffset].iPos;
- if ( ! (ELEM(iPos).nFlags & MNF_DELETED) )
- {
- if ( nSavedPosCount < nOffset )
- {
- pSavedPos[nSavedPosCount] = pSavedPos[nOffset];
- pSavedPos[nSavedPosCount].nSavedPosFlags &= ~SavedPos::SPM_LAST;
- }
- ++nSavedPosCount;
- }
- }
- if ( pSavedPos[nOffset].nSavedPosFlags & SavedPos::SPM_LAST )
- {
- while ( nSavedPosCount <= nOffset )
- pSavedPos[nSavedPosCount++].nSavedPosFlags &= ~SavedPos::SPM_USED;
- break;
- }
- ++nOffset;
- }
- }
- }
- ++nMap;
- }
- }
- }
- void CMarkup::x_AdjustForNode( int iPosParent, int iPos, int nShift )
- {
- // Adjust affected indexes
- bool bAfterPos = true;
- if ( ! iPos )
- {
- // Change happened before or at first element under iPosParent
- // If there are any children of iPosParent, adjust from there
- // otherwise start at parent and adjust from there
- iPos = ELEM(iPosParent).iElemChild;
- if ( iPos )
- {
- ELEM(iPos).nStart += nShift;
- bAfterPos = false;
- }
- else
- {
- iPos = iPosParent;
- ELEM(iPos).nLength += nShift;
- }
- }
- x_Adjust( iPos, nShift, bAfterPos );
- }
- bool CMarkup::x_AddNode( int nNodeType, MCD_PCSZ pText, int nNodeFlags )
- {
- if ( m_nDocFlags & MDF_READFILE )
- return false;
- // Comments, DTDs, and processing instructions are followed by CRLF
- // Other nodes are usually concerned with mixed content, so no CRLF
- if ( ! (nNodeType & (MNT_PROCESSING_INSTRUCTION|MNT_COMMENT|MNT_DOCUMENT_TYPE)) )
- nNodeFlags |= MNF_WITHNOLINES;
- // Add node of nNodeType after current node position
- NodePos node( nNodeFlags );
- if ( ! x_CreateNode(node.strMeta, nNodeType, pText) )
- return false;
- // Insert the new node relative to current node
- node.nStart = m_nNodeOffset;
- node.nLength = m_nNodeLength;
- node.nNodeType = nNodeType;
- int iPosBefore = m_iPos;
- int nReplace = x_InsertNew( m_iPosParent, iPosBefore, node );
- // If its a new element, create an ElemPos
- int iPos = iPosBefore;
- ElemPos* pElem = NULL;
- if ( nNodeType == MNT_ELEMENT )
- {
- // Set indexes
- iPos = x_GetFreePos();
- pElem = &ELEM(iPos);
- pElem->nStart = node.nStart;
- pElem->SetStartTagLen( node.nLength );
- pElem->SetEndTagLen( );
- pElem->nLength = node.nLength;
- node.nStart = ;
- node.nLength = ;
- pElem->iElemChild = ;
- pElem->nFlags = ;
- x_LinkElem( m_iPosParent, iPosBefore, iPos );
- }
- if ( m_nDocFlags & MDF_WRITEFILE )
- {
- m_iPosParent = x_UnlinkPrevElem( m_iPosParent, iPosBefore, iPos );
- if ( nNodeType == MNT_ELEMENT )
- {
- TokenPos token( m_strDoc, m_nDocFlags );
- token.m_nL = pElem->nStart + ;
- token.m_nR = pElem->nStart + pElem->nLength - ;
- m_pFilePos->m_elemstack.PushTagAndCount( token );
- }
- }
- else // need to adjust element positions after iPos
- x_AdjustForNode( m_iPosParent, iPos, MCD_STRLENGTH(node.strMeta) - nReplace );
- // Store current position
- m_iPos = iPos;
- m_iPosChild = ;
- m_nNodeOffset = node.nStart;
- m_nNodeLength = node.nLength;
- m_nNodeType = nNodeType;
- MARKUP_SETDEBUGSTATE;
- return true;
- }
- void CMarkup::x_RemoveNode( int iPosParent, int& iPos, int& nNodeType, int& nNodeOffset, int& nNodeLength )
- {
- int iPosPrev = iPos;
- // Removing an element?
- if ( nNodeType == MNT_ELEMENT )
- {
- nNodeOffset = ELEM(iPos).nStart;
- nNodeLength = ELEM(iPos).nLength;
- iPosPrev = x_UnlinkElem( iPos );
- x_CheckSavedPos();
- }
- // Find previous node type, offset and length
- int nPrevOffset = ;
- if ( iPosPrev )
- nPrevOffset = ELEM(iPosPrev).StartAfter();
- else if ( iPosParent )
- nPrevOffset = ELEM(iPosParent).StartContent();
- TokenPos token( m_strDoc, m_nDocFlags );
- NodePos node;
- token.m_nNext = nPrevOffset;
- int nPrevType = ;
- while ( token.m_nNext < nNodeOffset )
- {
- nPrevOffset = token.m_nNext;
- nPrevType = token.ParseNode( node );
- }
- int nPrevLength = nNodeOffset - nPrevOffset;
- if ( ! nPrevLength )
- {
- // Previous node is iPosPrev element
- nPrevOffset = ;
- if ( iPosPrev )
- nPrevType = MNT_ELEMENT;
- }
- // Remove node from document
- x_DocChange( nNodeOffset, nNodeLength, MCD_STR() );
- x_AdjustForNode( iPosParent, iPosPrev, - nNodeLength );
- // Was removed node a lone end tag?
- if ( nNodeType == MNT_LONE_END_TAG )
- {
- // See if we can unset parent MNF_ILLDATA flag
- token.m_nNext = ELEM(iPosParent).StartContent();
- int nEndOfContent = token.m_nNext + ELEM(iPosParent).ContentLen();
- int iPosChild = ELEM(iPosParent).iElemChild;
- while ( token.m_nNext < nEndOfContent )
- {
- if ( token.ParseNode(node) <= )
- break;
- if ( node.nNodeType == MNT_ELEMENT )
- {
- token.m_nNext = ELEM(iPosChild).StartAfter();
- iPosChild = ELEM(iPosChild).iElemNext;
- }
- }
- if ( token.m_nNext == nEndOfContent )
- ELEM(iPosParent).nFlags &= ~MNF_ILLDATA;
- }
- nNodeType = nPrevType;
- nNodeOffset = nPrevOffset;
- nNodeLength = nPrevLength;
- iPos = iPosPrev;
- }
2:生成Userinfo.xml
- #include "stdafx.h"
- #include<stdlib.h>
- #include<iostream>
- #include<string.h>
- #include"Markup.h"
- using namespace std;
- int main()
- {
- CMarkup xml;
- xml.SetDoc("<?xml version=\"1.0\" encoding=\"UTF-8\"?>\r\n");
- xml.AddElem((MCD_CSTR)"UserInfo"); //在当前主位置元素或最后兄弟位置之后增加一个元素
- xml.IntoElem(); //进入当前主位置的下一级,当前的位置变为父位置。
- xml.AddElem((MCD_CSTR)"UserID",(MCD_CSTR)"Jason");
- xml.AddElem((MCD_CSTR)"UserID",(MCD_CSTR)"evil");
- xml.OutOfElem(); //使当前父位置变成当前位置。
- xml.Save((MCD_CSTR)"UserInfo.xml"); //可指定目录 将XML数据写入文件中
- return ;
- }
运行结果:会在本地程序目录下生成一个UserInfo.xml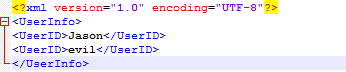
3:浏览特定元素
- #include "stdafx.h"
- #include<stdlib.h>
- #include<iostream>
- #include<string.h>
- #include"Markup.h"
- using namespace std;
- int main()
- {
- CMarkup xml;
- xml.Load((MCD_CSTR)"UserInfo.xml");
- BOOL bFind = true;
- xml.ResetMainPos();//将当前主位置复位为第一个兄弟位置之前
- while (xml.FindChildElem((MCD_CSTR)"UserID")) //定位到下一个子元素,匹配元素名或路径。
- {
- xml.IntoElem();//进入当前主位置的下一级,当前的位置变为父位置
- CString strTagName = _T("");
- CString strData = _T("");
- strTagName = xml.GetTagName(); //得到主位置元素(或正在进行的指令的)标签名称
- strData = xml.GetData(); // 得到当前主位置元素或节点的字符串值
- //以下为了看输出结果把CString 转 char*类型
- int len1 =WideCharToMultiByte(CP_ACP,,strTagName,-,NULL,,NULL,NULL);
- char ptagName[];
- WideCharToMultiByte(CP_ACP,,strTagName,-,ptagName,len1,NULL,NULL );
- int len2 =WideCharToMultiByte(CP_ACP,,strData,-,NULL,,NULL,NULL);
- char pData[];
- WideCharToMultiByte(CP_ACP,,strData,-,pData,len2,NULL,NULL );
- printf("\n-----tagName:%s,Data:%s\n",ptagName,pData);
- xml.OutOfElem();//使当前父位置变成当前位置
- }
- system("pause");
- return ;
- }
输出结果为: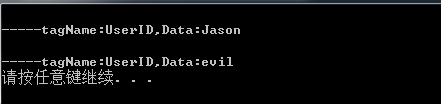
4:修改,把UserID为Jason值的修改snake
- #include "stdafx.h"
- #include<stdlib.h>
- #include<iostream>
- #include<string.h>
- #include"Markup.h"
- using namespace std;
- int main()
- {
- CMarkup xml;
- BOOL bLoadXml = false;
- bLoadXml = xml.Load((MCD_CSTR)"UserInfo.xml");
- if( bLoadXml )
- {
- CString strUserID = _T("");
- xml.ResetMainPos();
- xml.FindElem(); //定位到下一个元素,可能和一个标签名或路径匹配。 也就是定位到UserID;
- xml.IntoElem();
- while (xml.FindElem((MCD_CSTR)"UserID"))
- {
- strUserID = xml.GetData();
- if (strUserID=="Jason")
- {
- xml.SetData(CString("snake"));
- xml.Save((MCD_CSTR)"UserInfo.xml");
- break;
- }
- }
- }
- system("pause");
- return ;
- }
结果为: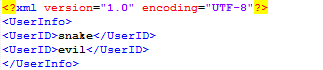
5:添加元素,添加在最后面
- #include "stdafx.h"
- #include<stdlib.h>
- #include<iostream>
- #include<string.h>
- #include"Markup.h"
- using namespace std;
- int main()
- {
- BOOL bLoadXml = false;
- CMarkup xml;
- bLoadXml = xml.Load((MCD_CSTR)"UserInfo.xml");
- if (bLoadXml)
- {
- xml.ResetMainPos();
- xml.FindElem();
- xml.IntoElem();
- xml.AddElem((MCD_CSTR)"UserID",(MCD_CSTR)"Jason");
- xml.OutOfElem();
- xml.Save((MCD_CSTR)"UserInfo.xml");
- }
- system("pause");
- return ;
- }
结果为: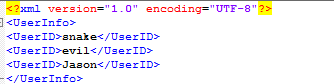
6:添加元素到最前面,使用的InsertElem()函数
- #include "stdafx.h"
- #include<stdlib.h>
- #include<iostream>
- #include<string.h>
- #include"Markup.h"
- using namespace std;
- int main()
- {
- BOOL bLoadXml = false;
- CMarkup xml;
- bLoadXml = xml.Load((MCD_CSTR)"UserInfo.xml");
- if (bLoadXml)
- {
- xml.ResetMainPos();
- xml.FindElem();
- xml.IntoElem();
- xml.InsertElem((MCD_CSTR)"UserID",(MCD_CSTR)"AddUserIDHead");
- xml.OutOfElem();
- xml.Save((MCD_CSTR)"UserInfo.xml");
- }
- system("pause");
- return ;
- }
结果为: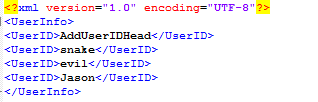
7:删除元素 使用的是RemoveChildElem
- #include "stdafx.h"
- #include<stdlib.h>
- #include<iostream>
- #include<string.h>
- #include"Markup.h"
- using namespace std;
- int main()
- {
- CMarkup xml;
- xml.Load((MCD_CSTR)"UserInfo.xml");
- BOOL bFind = true;
- xml.ResetMainPos();
- while (bFind)
- {
- bFind = xml.FindChildElem((MCD_CSTR)"UserID");
- if (bFind)
- {
- CString strData = _T("");
- strData = xml.GetChildData();
- if (strData==(MCD_CSTR)"snake")
- {
- xml.RemoveChildElem();
- xml.Save((MCD_CSTR)"UserInfo.xml");
- break;
- }
- }
- }
- system("pause");
- return ;
- }
结果为: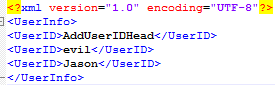
使用Markup解析xml文件的更多相关文章
- 解析xml文件的四种方式
什么是 XML? XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 标签没 ...
- C++生成和解析XML文件
1.xml 指可扩展标记语言(EXtensible Markup Language) 2.xml 是一种标记语言,类似html 3.xml 的设计宗旨是传输数据,而非显示数据 4.xml 标签没有被预 ...
- Java解析XML文件的方式
在项目里,我们往往会把一些配置信息放到xml文件里,或者各部门间会通过xml文件来交换业务数据,所以有时候我们会遇到“解析xml文件”的需求.一般来讲,有基于DOM树和SAX的两种解析xml文件的方式 ...
- Android 解析XML文件和生成XML文件
解析XML文件 public static void initXML(Context context) { //can't create in /data/media/0 because permis ...
- JAVA使用SAX解析XML文件
在我的另一篇文章(http://www.cnblogs.com/anivia/p/5849712.html)中,通过一个例子介绍了使用DOM来解析XML文件,那么本篇文章通过相同的XML文件介绍如何使 ...
- JAVA中使用DOM解析XML文件
XML是一种方便快捷高效的数据保存传输的格式,在JSON广泛使用之前,XML是服务器和客户端之间数据传输的主要方式.因此,需要使用各种方式,解析服务器传送过来的信息,以供使用者查看. JAVA作为一种 ...
- java中采用dom4j解析xml文件
一.前言 在最近的开发中用到了dom4j来解析xml文件,以前听说过来解析xml文件的几种标准方式:但是从来的没有应用过来,所以可以在google中搜索dmo4j解析xml文件的方式,学习一下dom4 ...
- XML:使用DOM技术解析xML文件中的城市,实现select级联选择
中国的城市xml格式:cities.xml <?xml version="1.0" encoding="utf-8"?> <china> ...
- dom4j如何解析XML文件
最近在 一些对xml文件的操作,下面简单写一个dom4j解析xml文件并将其封装到一个javabean中的例子,只是具有针对性的,不是通用的,仅供参考哦~~ 首先说:dom4j是一个java的XML ...
随机推荐
- 关于Unity中如何代码动态修改天空盒
在Unity中动态修改天空盒有两种方法: 一.为每个Texture建立天空盒材质球,需要更换时直接将对应材质球作为天空盒,缺点是建立的材质球太多 private void ChangeSkybox(M ...
- 移动前端的html5 head 头标签
DOCTYPE DOCTYPE(Document Type),该声明位于文档中最前面的位置,处于 html 标签之前,此标签告知浏览器文档使用哪种 HTML 或者 XHTML 规范. 使用 HTML5 ...
- Java基础学习笔记九 Java基础语法之this和super
构造方法 我们对封装已经有了基本的了解,接下来我们来看一个新的问题,依然以Person为例,由于Person中的属性都被private了,外界无法直接访问属性,必须对外提供相应的set和get方法.当 ...
- JavaScript(第二十天)【DOM操作表格及样式】
DOM在操作生成HTML上,还是比较简明的.不过,由于浏览器总是存在兼容和陷阱,导致最终的操作就不是那么简单方便了.本章主要了解一下DOM操作表格和样式的一些知识. 一.操作表格 <table& ...
- 课后练习:C语言实现Linux命令——od
课后练习:C语言实现Linux命令--od --------CONTENTS-------- 题目详情与分析 设计思路 遇到的问题及解决 待实现的设想与思考 学习反思与感悟 附1:myod.c「1.0 ...
- 简单的C语言编译器--语义制导翻译
语法分析是最难写的,而这部分确实最伤脑的.大量的语义动作分析差点把我逼疯. 简而言之,这部分的作用就是在每次归约之后,都进行一些语义动作,最终让我们得到测试程序的三地址码,即中间代码. 1. ...
- 《高级软件测试》11.15.全组完成jira安装,开始任务的部分书写
今日任务完成情况如下: 小段:完成linux环境上jira的安装,并将jira的安装过程录制下来 小费:完成linux环境下jira的安装,开始部分任务的书写 小高:完成了jira的安装,并进一步熟悉 ...
- Scala Option类型
转载自: Scala 初学者指南, 这里有一系列很棒的文章 类型 Option 可能你已经见过它在 Map API 中的使用:在实现自己的提取器时,我们也用过它, 然而,它还需要更多的解释. 你可能会 ...
- django + nginx + uwsgi + websocket
最近使用django框架做了一个简单的聊天机器人demo, 开发的过程中使用了django自带的websocket模块,当使用django框架自带的wsgi服务去启动的话,没有什么问题.如果要使用uw ...
- js实现短暂提示框
业务场景:当鼠标移入某元素时,显示提示框进行介绍.当鼠标移除时,会自动消失.引入ToolTip.js和ToolTip.css 主方法:ToolTip.show(需要提示的元素id, 随意不重复即可, ...