目标检测网络之 YOLOv2
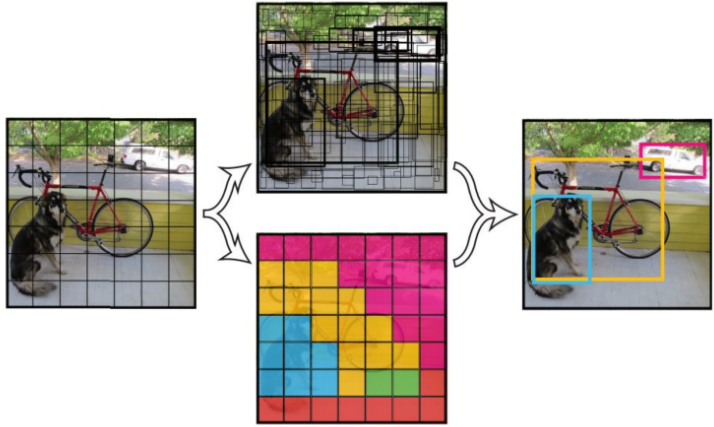
YOLOv1基本思想
YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。

每个格子预测B个bounding box及其置信度(confidence score),以及C个类别概率。bbox信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化.置信度反映是否包含物体以及包含物体情况下位置的准确性,定义为\(Pr(Object) \times IOU^{truth}_{pred}, 其中Pr(Object)\in\{0,1\}\).
网络结构
YOLOv1网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLOv1网络在最后使用全连接层进行类别输出,因此全连接层的输出维度是 \(S × S × (B × 5 + C)\)。
YOLOv1网络比VGG16快(浮点数少于VGG的1/3),准确率稍差。
缺馅:
输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成改分辨率.
占比较小的目标检测效果不好.虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
损失函数
YOLO全部使用了均方和误差作为loss函数.由三部分组成:坐标误差、IOU误差和分类误差。
\[
\text{loss=$\sum_{i=0}^{s^2}$coordErr+iouErr+clsErr}
\]
简单相加时还要考虑每种loss的贡献率,YOLO给coordErr设置权重\(\lambda_{coord}=5\).在计算IOU误差时,包含物体的格子与不包含物体的格子,二者的IOU误差对网络loss的贡献值是不同的。若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用\(\lambda _{noobj} =0.5\)修正iouErr。(此处的‘包含’是指存在一个物体,它的中心坐标落入到格子内)。对于相等的误差值,大物体误差对检测的影响应小于小物体误差对检测的影响。这是因为,相同的位置偏差占大物体的比例远小于同等偏差占小物体的比例。YOLO将物体大小的信息项(w和h)进行求平方根来改进这个问题,但并不能完全解决这个问题。
综上,YOLO在训练过程中Loss计算如下式所示:

其中有宝盖帽子符号(\(\hat x,\hat y,\hat w,\hat h,\hat C,\hat p\))为预测值,无帽子的为训练标记值。\(\mathbb 1_{ij}^{obj}\)表示物体落入格子i的第j个bbox内.如果某个单元格中没有目标,则不对分类误差进行反向传播;B个bbox中与GT具有最高IoU的一个进行坐标误差的反向传播,其余不进行.
训练过程
1)预训练。使用 ImageNet 1000 类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
2)用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用 VOC 20 类标注数据进行YOLO模型训练。检测通常需要有细密纹理的视觉信息,所以为提高图像精度,在训练检测模型时,将输入图像分辨率从224 × 224 resize到448x448。
训练时B个bbox的ground truth设置成一样的.
升级版 YOLO v2
为提高物体定位精准性和召回率,YOLO作者提出了 《YOLO9000: Better, Faster, Stronger》 (Joseph Redmon, Ali Farhadi, CVPR 2017, Best Paper Honorable Mention),相比v1提高了训练图像的分辨率;引入了faster rcnn中anchor box的思想,对网络结构的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,联合使用coco物体检测标注数据和imagenet物体分类标注数据训练物体检测模型。相比YOLO,YOLO9000在识别种类、精度、速度、和定位准确性等方面都有大大提升。
YOLOv2 改进之处
YOLO与Fast R-CNN相比有较大的定位误差,与基于region proposal的方法相比具有较低的召回率。因此YOLO v2主要改进是提高召回率和定位能力。下面是改进之处:
Batch Normalization: v1中也大量用了Batch Normalization,同时在定位层后边用了dropout,v2中取消了dropout,在卷积层全部使用Batch Normalization。
高分辨率分类器:v1中使用224 × 224训练分类器网络,扩大到448用于检测网络。v2将ImageNet以448×448 的分辨率微调最初的分类网络,迭代10 epochs。
Anchor Boxes:v1中直接在卷积层之后使用全连接层预测bbox的坐标。v2借鉴Faster R-CNN的思想预测bbox的偏移.移除了全连接层,并且删掉了一个pooling层使特征的分辨率更大一些.另外调整了网络的输入(448->416)以使得位置坐标是奇数只有一个中心点(yolo使用pooling来下采样,有5个size=2,stride=2的max pooling,而卷积层没有降低大小,因此最后的特征是416/(2^5)=13).v1中每张图片预测7x7x2=98个box,而v2加上Anchor Boxes能预测超过1000个.检测结果从69.5mAP,81% recall变为69.2 mAP,88% recall.
YOLO v2对Faster R-CNN的手选先验框方法做了改进,采样k-means在训练集bbox上进行聚类产生合适的先验框.由于使用欧氏距离会使较大的bbox比小的bbox产生更大的误差,而IOU与bbox尺寸无关,因此使用IOU参与距离计算,使得通过这些anchor boxes获得好的IOU分值。距离公式:
\[
D\text{(box,centroid)} = 1 − IOU\text{(box,centroid)}
\]
使用聚类进行选择的优势是达到相同的IOU结果时所需的anchor box数量更少,使得模型的表示能力更强,任务更容易学习.k-means算法代码实现参考:k_means_yolo.py.算法过程是:将每个bbox的宽和高相对整张图片的比例(wr,hr)进行聚类,得到k个anchor box,由于darknet代码需要配置文件中region层的anchors参数是绝对值大小,因此需要将这个比例值乘上卷积层的输出特征的大小.如输入是416x416,那么最后卷积层的特征是13x13.
细粒度特征(fine grain features):在Faster R-CNN 和 SSD 均使用了不同的feature map以适应不同尺度大小的目标.YOLOv2使用了一种不同的方法,简单添加一个 pass through layer,把浅层特征图(26x26)连接到深层特征图(连接到新加入的三个卷积核尺寸为3 * 3的卷积层最后一层的输入)。 通过叠加浅层特征图相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mapping。这个方法把26x26x512的特征图叠加成13x13x2048的特征图,与原生的深层特征图相连接,使模型有了细粒度特征。此方法使得模型的性能获得了1%的提升。
Multi-Scale Training: 和YOLOv1训练时网络输入的图像尺寸固定不变不同,YOLOv2(在cfg文件中random=1时)每隔几次迭代后就会微调网络的输入尺寸。训练时每迭代10次,就会随机选择新的输入图像尺寸。因为YOLOv2的网络使用的downsamples倍率为32,所以使用32的倍数调整输入图像尺寸{320,352,…,608}。训练使用的最小的图像尺寸为320 x 320,最大的图像尺寸为608 x 608。 这使得网络可以适应多种不同尺度的输入.
YOLOv2网络结构
YOLOv2对v1的基础网络做了更改.
分类网络
YOLOv2提出了一种新的分类模型Darknet-19.借鉴了很多其它网络的设计概念.主要使用3x3卷积并在pooling之后channel数加倍(VGG);global average pooling替代全连接做预测分类,并在3x3卷积之间使用1x1卷积压缩特征表示(Network in Network);使用 batch normalization 来提高稳定性,加速收敛,对模型正则化.
Darknet-19的结构如下表:
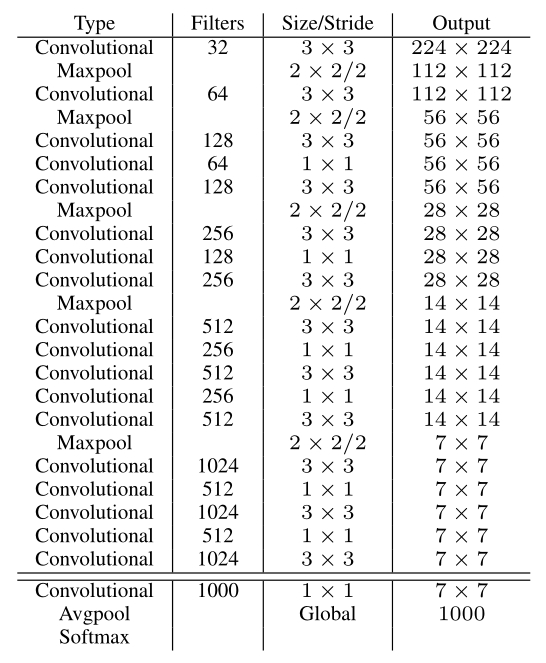
包含 19 conv + 5 maxpooling.
训练:使用Darknet框架在ImageNet 1000类上训练160 epochs,学习率初始为0.1,以4级多项式衰减.weight decay=0.0005 , momentum=0.9.使用标准的数据增广方法:random crops, rotations, (hue, saturation), exposure shifts.
之后将输入从224放大至448,学习率调整为0.001,迭代10 epochs.结果达到top-1 accuracy 76.5% , top-5 accuracy 93.3%.
检测网络
在分类网络中移除最后一个1x1的层,在最后添加3个3x3x1024的卷积层,再接上输出是类别个数的1x1卷积.
对于输入图像尺寸为Si x Si,最终3x3卷积层输出的feature map是Oi x Oi(Oi=Si/(2^5)),对应输入图像的Oi x Oi个栅格,每个栅格预测#anchors种boxes大小,每个box包含4个坐标值,1个置信度和#classes个条件类别概率,所以输出维度是Oi x Oi x #anchors x (5 + #classes)。
添加跨层跳跃连接(借鉴ResNet等思想),融合粗细粒度的特征:将前面最后一个3x3x512卷积的特征图,对于416x416的输入,该层输出26x26x512,直接连接到最后新加的三个3x3卷积层的最后一个的前边.将26x26x512变形为13x13x1024与后边的13x13x1024特征按channel堆起来得到13x13x3072.从yolo-voc.cfg文件可以看到,第25层为route层,逆向9层拿到第16层26 * 26 * 512的输出,并由第26层的reorg层把26 * 26 * 512 变形为13 * 13 * 2048,再有第27层的route层连接24层和26层的输出,堆叠为13 * 13 * 3072,由最后一个卷积核为3 * 3的卷积层进行跨通道的信息融合并把通道降维为1024。
训练:作者在VOC07+12以及COCO2014数据集上迭代了160 epochs,初始学习率0.001,在60和90 epochs分别减小为0.1倍.
Darknet训练VOC的参数如下:
learning_rate=0.0001
batch=64
max_batches = 45000 # 最大迭代batch数
policy=steps # 学习率衰减策略
steps=100,25000,35000 # 训练到这些batch次数时learning_rate按scale缩放
scales=10,.1,.1 # 与steps对应网络结构如下(输入416,5个类别,5个anchor box):
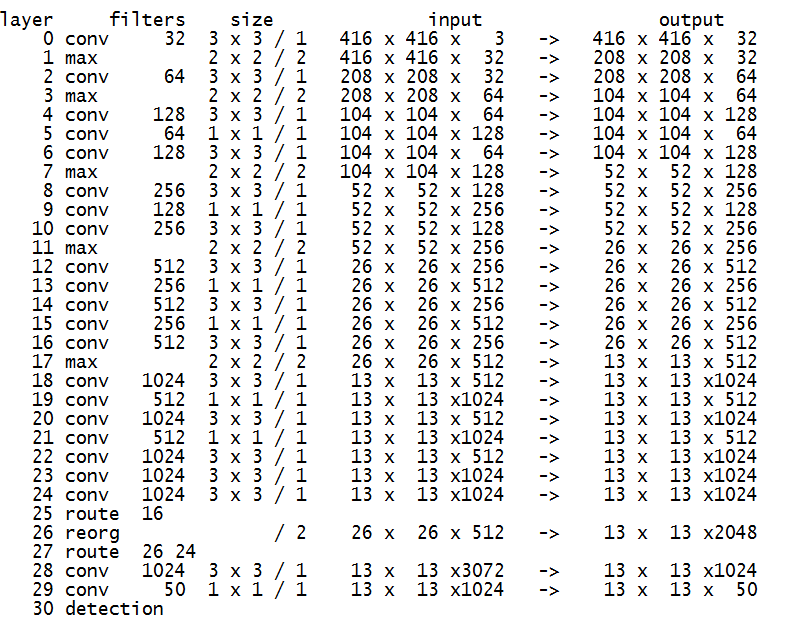
YOLO9000
提出了一种联合训练方法,能够容许同时使用目标检测数据集和分类数据集。使用有标记的检测数据集精确定位,使用分类数据增加类别和鲁棒性。
优缺点
优点
- 快速,pipline简单.
- 背景误检率低。
- 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
但相比RCNN系列物体检测方法,YOLO具有以下缺点:
- 识别物体位置精准性差。
- 召回率低。在每个网格中预测两个bbox这种约束方式减少了对同一目标的多次检测(R-CNN使用的region proposal方式重叠较多),相比R-CNN使用Selective Search产生2000个proposal(RCNN测试时每张超过40秒),yolo仅使用7x7x2个.
YOLO v.s. Faster R-CNN
- 统一网络:
YOLO没有显示求取region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络.
相对于R-CNN系列的"看两眼"(候选框提取与分类,图示如下),YOLO只需要Look Once.
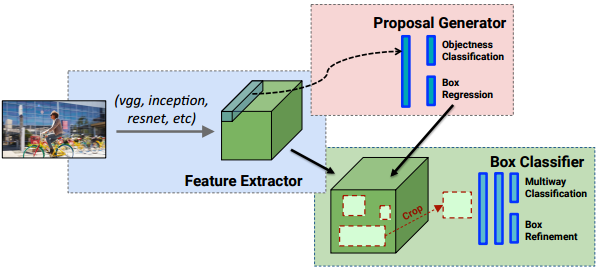
- YOLO统一为一个回归问题
而R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
darknet部分代码解读
region层:参数anchors指定kmeans计算出来的anchor box的长宽的绝对值(与网络输入大小相关),num参数为anchor box的数量(这两个参数由本人简化为一个参数norm_anchors是归一化的),另外还有bias_match,classes,coords等参数.在parser.c代码中的parse_region函数中解析这些参数,并保存在region_layer.num参数保存在l.n变量中;anchors保存在l.biases数组中.region_layer的前向传播中使用for(n = 0; n < l.n; ++n)这样的语句,因此,如果在配置文件中anchors的数量大于num时,仅使用前num个,小于时内存越界.
region层的输入和输出大小与前一层(1x1 conv)的输出大小和网络的输入大小相关.
目标检测网络之 YOLOv2的更多相关文章
- 目标检测网络之 YOLOv3
本文逐步介绍YOLO v1~v3的设计历程. YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这 ...
- 目标检测网络之 Mask R-CNN
Mask R-CNN 论文Mask R-CNN(ICCV 2017, Kaiming He,Georgia Gkioxari,Piotr Dollár,Ross Girshick, arXiv:170 ...
- 目标检测网络之 R-FCN
R-FCN 原理 R-FCN作者指出在图片分类网络中具有平移不变性(translation invariance),而目标在图片中的位置也并不影响分类结果;但是检测网络对目标的位置比较敏感.因此Fas ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 使用Caffe完成图像目标检测 和 caffe 全卷积网络
一.[用Python学习Caffe]2. 使用Caffe完成图像目标检测 标签: pythoncaffe深度学习目标检测ssd 2017-06-22 22:08 207人阅读 评论(0) 收藏 举报 ...
- 目标检测之YOLO V2 V3
YOLO V2 YOLO V2是在YOLO的基础上,融合了其他一些网络结构的特性(比如:Faster R-CNN的Anchor,GooLeNet的\(1\times1\)卷积核等),进行的升级.其目的 ...
- 【目标检测】SSD:
slides 讲得是相当清楚了: http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf 配合中文翻译来看: https://www.cnb ...
- 目标检测之YOLO V1
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别.虽然,在Faster R-CNN中利用 ...
- 目标检测之R-CNN系列
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来. 或者是,图像中有那些目标,目标的位置在那.这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫. ...
随机推荐
- 【推荐】免费,19 款仿 Bootstrap 后台管理主题下载
声明: 1. 本篇文章提到的仿 Bootstrap 风格的主题,是基于 jQuery 的 ASP.NET MVC 控件库的主题. 2. FineUIMvc(基础版)完全免费,可以用于商业项目. 目录 ...
- 快了快了,你的 MacBook Pro 和 FineUICore!
着玻璃窗,看到星巴克里那帮人拿着MacBook喝咖啡,你是不是要默念一遍:这帮傻叉,就爱装逼! 不过话说回来,你想不想尝试下这个傻叉的感觉? 是时候了,给自己一个理由,拥有自己的 MacBook Pr ...
- MyBatis框架概述
MyBatis是一个优秀的持久层框架,它对jdbc的操作数据库的过程进行封装,使开发者只需要关注SQL本身,而不需要花费精力去处理例如注册驱动.创建connection.创建statement.手动设 ...
- apache配置,禁止ip访问web站点
由于一台服务器上面部署了好几个应用,对应不同的域名,如果用户知道ip地址的话,直接用户ip地址访问,会显示第一个虚拟主机的页面(更改了虚拟主机的顺序,每次都是显示第一个).这样对用户造成不好的印象,所 ...
- 查看dmp文件
1.查看dmp文件,首先要通过以下的链接地址进行下载 http://msdl.microsoft.com/download/symbols/debuggers/dbg_x86_6.11.1.404.m ...
- vxworks下的串口测试程序
VXWORKS串口设置说明: 一般有这么几步: 打开串口 设置串口raw模式,清空输入输出的缓冲区 设置波特率,数据位,停止位,校验方式 便可以开始读和写 打开串口: fd = open(" ...
- java SpringWeb 接收安卓android传来的图片集合及其他信息入库存储
公司是做APP的,进公司一年了还是第一次做安卓的接口 安卓是使用OkGo.post("").addFileParams("key",File); 通过这种方式传 ...
- RobotFramework自动化测试框架的基础关键字(一)
1.1.1 如何搜索RobotFramework的关键字 有两种方式可以快速的打开RIDE的关键字搜索对话框 1.选择菜单栏Tools->Search Keywords,然后会出现 ...
- 【最新】Power BI混合现实应用Mixed Reality app预览版正式发布
1.介绍 2018年3月13日,Power BI在官方博客和Docs文档发布了Power BI for Mixed Reality应用预览版的消息, 也就是可以以后在更虚拟的世界中来观察你的报表,想象 ...
- 设置mysql密码 Access denied 问题
原文:http://www.upwqy.com/details/31.html 在Mac上安装完mysql以后 在终端执行 /usr/local/mysql/bin/mysql 可以直接进入.但是在设 ...