芝麻HTTP:Python爬虫入门之Urllib库的基本使用
1.分分钟扒一个网页下来
怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS、CSS,如果把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。所以最重要的部分是存在于HTML中的,下面我们就写个例子来扒一个网页下来。
import urllib2
response = urllib2.urlopen("http://www.baidu.com")
print response.read()
是的你没看错,真正的程序就两行,把它保存成 demo.py,进入该文件的目录,执行如下命令查看运行结果,感受一下。
python demo.py
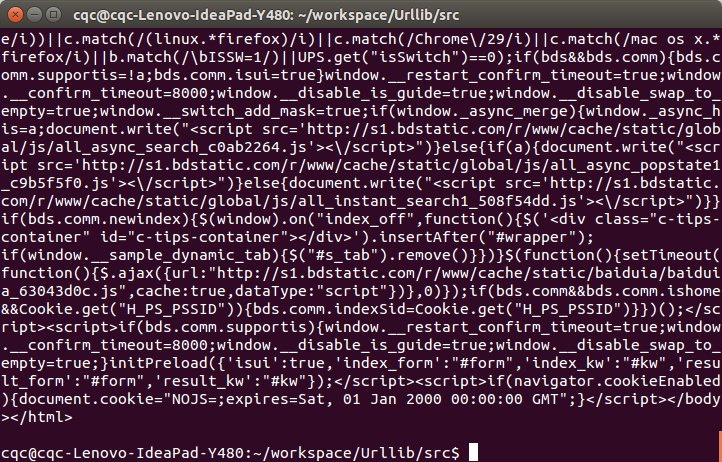
看,这个网页的源码已经被我们扒下来了,是不是很酸爽?
2.分析扒网页的方法
那么我们来分析这两行代码,第一行
response = urllib2.urlopen("http://www.baidu.com")
首先我们调用的是urllib2库里面的urlopen方法,传入一个URL,这个网址是百度首页,协议是HTTP协议,当然你也可以把HTTP换做FTP,FILE,HTTPS 等等,只是代表了一种访问控制协议,urlopen一般接受三个参数,它的参数如下:
urlopen(url, data, timeout)
第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。
第二三个参数是可以不传送的,data默认为空None,timeout默认为 socket._GLOBAL_DEFAULT_TIMEOUT
第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
print response.read()
response对象有一个read方法,可以返回获取到的网页内容。
如果不加read直接打印会是什么?答案如下:
<addinfourl at whose fp = <socket._fileobject object at 0x7f1513fb3ad0>>
直接打印出了该对象的描述,所以记得一定要加read方法,否则它不出来内容可就不怪我咯!
3.构造Request
其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容。比如上面的两行代码,我们可以这么改写
import urllib2
request = urllib2.Request("http://www.baidu.com")
response = urllib2.urlopen(request)
print response.read()
运行结果是完全一样的,只不过中间多了一个request对象,推荐大家这么写,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确。
4.POST和GET数据传送
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。所以,在访问时,我们需要传递数据给它。最常见的情况是什么?对了,就是登录注册的时候呀。
把数据用户名和密码传送到一个URL,然后你得到服务器处理之后的响应,这个该怎么办?下面让我来为小伙伴们揭晓吧!
数据传送分为POST和GET两种方式,两种方式有什么区别呢?
最重要的区别是GET方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。POST则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
POST方式:
上面我们说了data参数是干嘛的?对了,它就是用在这里的,我们传送的数据就是这个参数data,下面演示一下POST方式。
import urllib
import urllib2
values = {"username":"1016903103@qq.com","password":"XXXX"}
data = urllib.urlencode(values)
url = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
我们引入了urllib库,现在我们模拟登陆CSDN,当然上述代码可能登陆不进去,因为CSDN还有个流水号的字段,没有设置全,比较复杂在这里就不写上去了,在此只是说明登录的原理。一般的登录网站一般是这种写法。
我们需要定义一个字典,名字为values,参数我设置了username和password,下面利用urllib的urlencode方法将字典编码,命名为data,构建request时传入两个参数,url和data,运行程序,返回的便是POST后呈现的页面内容。
注意上面字典的定义方式还有一种,下面的写法是等价的
import urllib
import urllib2
values = {}
values['username'] = "1016903103@qq.com"
values['password'] = "XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
以上方法便实现了POST方式的传送
GET方式:
至于GET方式我们可以直接把参数写到网址上面,直接构建一个带参数的URL出来即可。
import urllib
import urllib2
values={}
values['username'] = "1016903103@qq.com"
values['password']="XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
你可以print geturl,打印输出一下url,发现其实就是原来的url加?然后加编码后的参数
http://passport.csdn.net/account/login?username=1016903103%40qq.com&password=XXXX
和我们平常GET访问方式一模一样,这样就实现了数据的GET方式传送。
芝麻HTTP:Python爬虫入门之Urllib库的基本使用的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- Python爬虫入门:Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门:Urllib库的高级使用
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
- 爬虫入门之urllib库(一)
1 爬虫概述 (1)互联网爬虫 一个程序,根据Url进行爬取网页,获取有用信息 (2)核心任务 爬取网页 解析数据 难点 :爬虫和反爬虫之间的博弈 (3)爬虫语言 php 多进程和多线程支持不好 ja ...
- Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习 如有侵权,请联系删除 获取url参数 urlparse 和 parse_qs ParseRes ...
- PYTHON 爬虫笔记二:Urllib库基本使用
知识点一:urllib的详解及基本使用方法 一.基本介绍 urllib是python的一个获取url(Uniform Resource Locators,统一资源定址器)了,我们可以利用它来抓取远程的 ...
随机推荐
- fiddler2请求参数乱码
win7 1.windows按钮+R 2.输入regedit +回车+是 3.HKEY_CURRENT_USER\Software\Microsoft\Fiddler2 4.右键新建,选字符串值 加上 ...
- bzoj 4872: [Shoi2017]分手是祝愿 [期望DP]
4872: [Shoi2017]分手是祝愿 题意:n个灯开关游戏,按i后i的约数都改变状态.随机选择一个灯,如果当前最优策略\(\le k\)直接用最优策略.问期望步数\(\cdot n! \mod ...
- 《深入理解Java虚拟机》——Java内存区域与内存溢出异常
程序计数器(Program Counter Register):一块较小的内存空间,可看作是当前线程所执行的字节码的行号指示器.字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令 ...
- 使用log4net日志组件经验分享
常见步骤: 第一:在项目中引用log4net组件. 第二:配置log4net,一般都写在web.config中. 第三:调用部分. 具体怎么配置,大家可以参考博客其它博友写的,这里我只写我 ...
- My97DatePicker选择两个日期范围不超过30天的demo
需求 ExtJs下使用My97DatePicker对时间范围不超过30天进行选择. 关键点 使用全局变量. 对选择完的第一个日期进行逻辑判断.(我的逻辑能力还有待加强啊) 因为当选择了第一个框范围在超 ...
- qt的编译
cp qt-everywhere-opensource-src-5.5.0.tar.gz /opt/qt/2.1 解压qt源码 sudo tar xzf qt-everywhere-opensourc ...
- QT开发应用程序的欢迎界面
主界面启动太慢,通常要10秒以上,所以想加个欢迎界面,等程序加载好再显示主界面. 主界面(类名为MainWindow)启动慢的原因是构造函数需要执行大量初始化的工作. 创建了Welcome类作为欢迎界 ...
- mac攻略(2) -- apache站点配置
[http://www.cnblogs.com/redirect/p/6112164.html] Mac OS X 中默认有两个目录可以直接运行你的 Web 程序, 一个是系统级的 Web 根目录:/ ...
- 广告中的AdNetwork、AdExchange、DSP、SSP、RTB和DMP是什么?
[https://www.douban.com/note/557732418/?type=rec] AdNetwork.AdExchange.DSP.SSP.RTB.DMP这些模式之间存在着内在的关系 ...
- Docker Centos6 下建立 Docker 桥接网络
cd /etc/sysconfig/network-scripts/; cp ifcfg-eth0 ifcfg-br0 vi ifcfg-eth0 //增加BRIDGE=br0,删除IPADDR,N ...