LinkedHashMap基本原理和用法&使用实现简单缓存(转)
一. 基本用法
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持两种顺序插入顺序 、 访问顺序
1:插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
2:访问顺序:所谓访问指的是get/put操作,对一个键执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
LinkedHashMap 继承了HashMap,实现了Map接口
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap一共提供了五个构造方法:
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
从构造方法中可以看出,默认都采用插入顺序来维持取出键值对的次序。所有构造方法都是通过调用父类的构造方法来创建对象的。
举个例子:键是按照:“c”, “d”,"a"的顺序插入的,修改d不会修改顺序
@Test
public void test2(){
Map<String, Integer> seqMap = new LinkedHashMap<>();
seqMap.put("c",100);
seqMap.put("d",200);
seqMap.put("a",500);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
System.out.println("---------------");
seqMap.put("d",300);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
console输出:
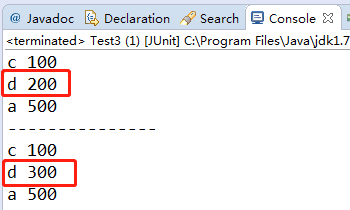
按访问顺序:
@Test
public void test2(){
Map<String, Integer> seqMap = new LinkedHashMap<>(16,0.75f,true);
seqMap.put("c",100);
seqMap.put("d",200);
seqMap.put("a",500);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
System.out.println("---------------");
seqMap.put("d",300);
for(Entry<String,Integer> entry:seqMap.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
console输出:
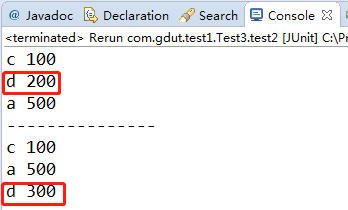
二:HashMap与LinkedHashMap的结构对比
LinkedHashMap其实就是可以看成HashMap的基础上,多了一个双向链表来维持顺序。
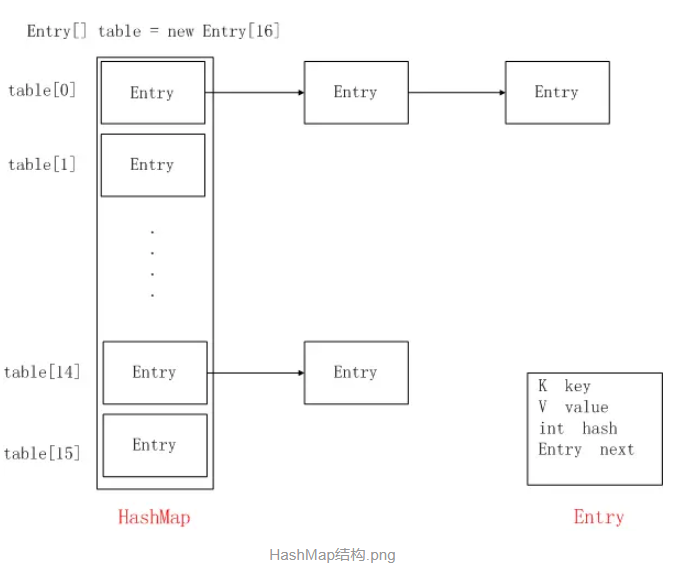
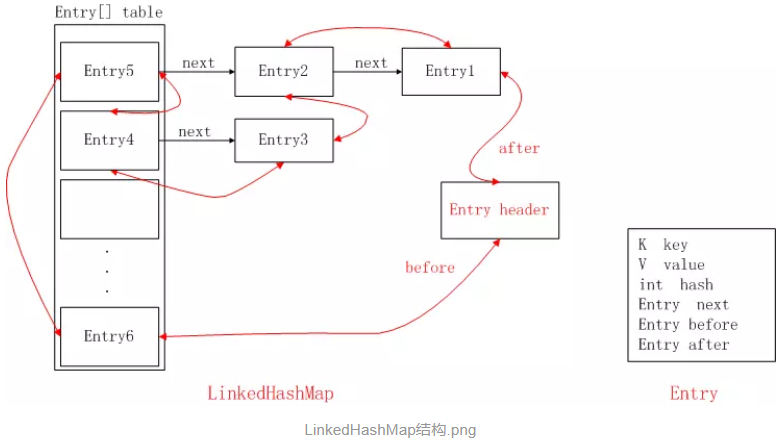
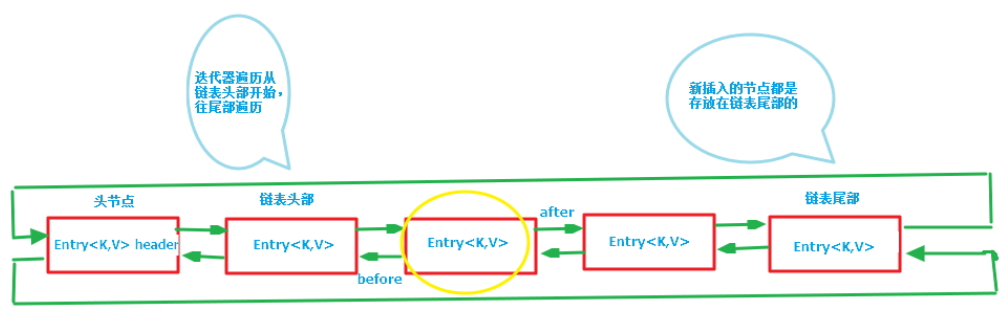
注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
三:借用 LinkedHashMap实现最近被使用(LRU)缓存
最近最少使用缓存的回收
为了实现缓存回收,我们需要很容易做到:
- 查询出最近最晚使用的项
- 给最近使用的项做一个标记
链表可以实现这两个操作。检测最近最少使用的项只需要返回链表的尾部。标记一项为最近使用的项只需要从当前位置移除,然后将该项放置到头部。比较困难的事情是怎么快速的在链表中找到该项。
对于使用链表这种方法,put 和 get 都需要遍历链表查找数据是否存在,所以时间复杂度为 O(n)。空间复杂度为 O(1)。
空间换时间
在实际的应用中,当我们要去读取一个数据的时候,会先判断该数据是否存在于缓存器中,如果存在,则返回,如果不存在,则去别的地方查找该数据(例如磁盘),找到后再把该数据存放于缓存器中,再返回。
所以在实际的应用中,put 操作一般伴随着 get 操作,也就是说,get 操作的次数是比较多的,而且命中率也是相对比较高的,进而 put 操作的次数是比较少的,我们我们是可以考虑采用空间换时间的方式来加快我们的 get 的操作的。
例如我们可以用一个额外哈希表(例如HashMap)来存放 key-value,这样的话,我们的 get 操作就可以在 O(1) 的时间内寻找到目标节点,并且把 value 返回了。
然而,大家想一下,用了哈希表之后,get 操作真的能够在 O(1) 时间内完成吗?
用了哈希表之后,虽然我们能够在 O(1) 时间内找到目标元素,可以,我们还需要删除该元素,并且把该元素插入到链表头部啊,删除一个元素,我们是需要定位到这个元素的前驱的,然而定位到这个元素的前驱,是需要 O(n) 时间复杂度的。
最后的结果是,用了哈希表时候,最坏时间复杂度还是 O(1),而空间复杂度也变为了 O(n)。
双向链表+哈希表
我们都已经能够在 O(1) 时间复杂度找到要删除的节点了,之所以还得花 O(n) 时间复杂度才能删除,主要是时间是花在了节点前驱的查找上,为了解决这个问题,其实,我们可以把单链表换成双链表,这样的话,我们就可以很好着解决这个问题了,而且,换成双链表之后,你会发现,它要比单链表的操作简单多了。
所以我们最后的方案是:双链表 + 哈希表,采用这两种数据结构的组合,我们的 get 操作就可以在 O(1) 时间复杂度内完成了。由于 put 操作我们要删除的节点一般是尾部节点,所以我们可以用一个变量 tai 时刻记录尾部节点的位置,这样的话,我们的 put 操作也可以在 O(1) 时间内完成了。
Java已经为我们提供了这种形式的数据结构 LinkedHashMap!它甚至提供可覆盖回收策略的方法(见removeEldestEntry文档)。唯一需要我们注意的事情是,改链表的顺序是插入的顺序,而不是访问的顺序。但是,有一个构造函数提供了一个选项,可以使用访问的顺序
import java.util.LinkedHashMap;
import java.util.Map; public LRUCache<K, V> extends LinkedHashMap<K, V> {
private int cacheSize; public LRUCache(int cacheSize) {
super(16, 0.75, true);
this.cacheSize = cacheSize;
}
//LinkedHashMap有一个removeEldestEntry(Map.Entry eldest)方法,通过覆盖这个方法,加入一定的条件,满足条件返回true。当put进新的值方法返回true时,便移除该map中最老的键和值。
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() >= cacheSize;
}
}
注:在LinkedHashMap添加元素后,会调用removeEldestEntry防范,传递的参数时最久没有被访问的键值对,如果方法返回true,这个最久的键值对就会被删除。LinkedHashMap中的实现总返回false,该子类重写后即可实现对容量的控制
自己通过HashMap+双向链表实现LRU缓存算法
import java.util.HashMap;
public class LRUCache<K, V> {
private int currentCacheSize; // 当前缓存的容量
private int CacheCapcity; // 缓存容量最大值
private HashMap<K,CacheNode> caches; //HashMap
private CacheNode first; //链表头
private CacheNode last; //链表尾
public LRUCache(int size) {
this.currentCacheSize = 0;
this.CacheCapcity = size;
caches = new HashMap<K, CacheNode>(size);
}
public void put(K k,V v){
CacheNode node = caches.get(k);
if(node == null) { //缓存中没有该key
if(caches.size() >= CacheCapcity) { //缓存容量已经达到最大值了,不能装了
caches.remove(last.key); //删除HashMap中的Node
removeLast(); //删除双向链表中的尾结点Node
}
node = new CacheNode();
node.key = k;
}
node.value = v;
moveToFirst(node);
caches.put(k, node);
}
public Object get(K k){
CacheNode node = caches.get(k);
if(node == null) {
return null;
}
moveToFirst(node);
return node.value;
}
public Object remove(K k) {
CacheNode node = caches.get(k);
if(node != null) {
if(node.pre != null){
node.pre.next=node.next;
}
if(node.next != null){
node.next.pre=node.pre;
}
if(node == first){
first = node.next;
}
if(node == last){
last = node.pre;
}
}
return null;
}
public void clear(){
first = null;
last = null;
caches.clear();
}
private void removeLast(){
if(last != null) {
last = last.pre;
if(last == null) {
first = null;
}else {
last.next = null;
}
}
}
/**
* @param node 插入的结点</br>
* put数据,将新数据放到链表头部,这样链表头部就是最新的数据,尾部就是最少访问的数据
*/
private void moveToFirst(CacheNode node) {
if(first == node){
return;
}
if(node.next != null){
node.next.pre = node.pre;
}
if(node.pre != null){
node.pre.next = node.next;
}
if(node == last){
last= last.pre;
}
if(first == null || last == null){
first = last = node;
return;
}
node.next=first;
first.pre = node;
first = node;
first.pre=null;
}
@Override
public String toString(){
StringBuilder sb = new StringBuilder();
CacheNode node = first;
while(node != null){
sb.append(String.format("%s:%s ", node.key,node.value));
node = node.next;
}
return sb.toString();
}
public static void main(String[] args) {
LRUCache<Integer,String> lru = new LRUCache<Integer,String>(3);
lru.put(1, "a"); // 1:a
System.out.println(lru.toString());
lru.put(2, "b"); // 2:b 1:a
System.out.println(lru.toString());
lru.put(3, "c"); // 3:c 2:b 1:a
System.out.println(lru.toString());
lru.put(4, "d"); // 4:d 3:c 2:b
System.out.println(lru.toString());
lru.put(1, "aa"); // 1:aa 4:d 3:c
System.out.println(lru.toString());
lru.put(2, "bb"); // 2:bb 1:aa 4:d
System.out.println(lru.toString());
lru.put(5, "e"); // 5:e 2:bb 1:aa
System.out.println(lru.toString());
lru.get(1); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(11); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(1); //5:e 2:bb
System.out.println(lru.toString());
lru.put(1, "aaa"); //1:aaa 5:e 2:bb
System.out.println(lru.toString());
}
}
LinkedHashMap基本原理和用法&使用实现简单缓存(转)的更多相关文章
- 【转】asp.net mvc3 简单缓存实现sql依赖
asp.net mvc3 简单缓存实现sql依赖 议题 随 着网站的发展,大量用户访问流行内容和动态内容,这两个方面的因素会增加平均的载入时间,给Web服务器和数据库服务器造成大量的请求压力.而大 ...
- Learning ReactNative (一) : JavaScript模块基本原理与用法
在使用ReactNative进行开发的时候,我们的工程是模块化进行组织的.在npmjs.com几十万个库中,大部分都是遵循着CommonJS规则的.在ES6中引入了class的概念,从此JavaScr ...
- localStorage/cookie 用法分析与简单封装
本地存储是HTML5中提出来的概念,分localStorage和sessionStorage.通过本地存储,web应用程序能够在用户浏览器中对数据进行本地的存储.与 cookie 不同,存储限制要大得 ...
- 关于ExpandableListView用法的一个简单小例子
喜欢显示好友QQ那样的列表,可以展开,可以收起,在android中,以往用的比较多的是listview,虽然可以实现列表的展示,但在某些情况下,我们还是希望用到可以分组并实现收缩的列表,那就要用到an ...
- php简单缓存类
<?phpclass Cache { private $cache_path;//path for the cache private $cache_expire;//seconds ...
- ElasticSearch的基本原理与用法
一.简介 ElasticSearch和Solr都是基于Lucene的搜索引擎,不过ElasticSearch天生支持分布式,而Solr是4.0版本后的SolrCloud才是分布式版本,Solr的分布式 ...
- 写了一个Java的简单缓存模型
缓存操作接口 /** * 缓存操作接口 * * @author xiudong * * @param <T> */ public interface Cache<T> { /* ...
- C++标准 bind函数用法与C#简单实现
在看C++标准程序库书中,看到bind1st,bind2nd及bind的用法,当时就有一种熟悉感,仔细想了下,是F#里提到的柯里化.下面是维基百科的解释:在计算机科学中,柯里化(英语:Currying ...
- Django之django-redis对数据进行简单缓存
最近公司老大抱怨,产品某部分内容访问速度奇慢无比,由于是之前接手的别人的代码,不太清楚业务的具体逻辑,不过,经过查看,内容为无需实时更新的内容,so 直接上缓存. 什么是缓存? 对于后端来说,要做的 ...
随机推荐
- Vue.js-06:第六章 - 按键修饰符的使用
一.前言 上周末的时候,准备试试将 ASP.NET Core 的项目部署到 CentOS 服务器上,结果在一个接一个坑里面跳,最后 Supervisor 守护程序还是有问题,于是,采用重装系统大招, ...
- 《前端之路》之三 数组的属性 && 操作方法(下)
咱们 接着上篇来讲- 7.slice() 从某个已有的数组返回选定的元素 经常用来将类数组转化成数组,这样做一方面可以利用现有的数组方法更加方便的处理,另一方面是处于性能的考虑 var f = fun ...
- Java~命名规范
下面总结以点java命名规范 虽然感觉这些规范比起C#来说有点怪,但还是应该尊重它的命名! 命名规范 项目名全部小写 包名全部小写 类名首字母大写,如果类名由多个单词组成,每个单词的首字母都要大写. ...
- 从零开始搭建一个规范的vue-cli 3.0项目
在这一集我们将讲到如何从安装vue-cli开始,到新建一个本地项目,再到vscode中关于eslint的配置,以及本地项目关联公司远程项目的基本操作. 一,初始化本地项目 1,首先,全局安装vue-c ...
- 事件Event一
事件(Event)例如:最近的视觉中国'黑洞事件'.我们大多数人(订阅者)是通过XX平台(发布者)得知的这一消息,然后订阅者A出售视觉中国的股票(触发的方法),订阅者B买入视觉中国的股票. using ...
- 微信小程序性能优化之一
性能优化 界面和业务逻辑之间事件交互小程序调用nativeNative回调小程序 图片源文件优化 渲染优化 ---------------------------------------------- ...
- Java开发笔记(八十二)注解的基本单元——元注解
Java的注解非但是一种标记,还是一种特殊的类型,并且拥有专门的类型定义.前面介绍的五种内置注解,都可以找到对应的类型定义代码,例如查看注解@Override的源码,发现它的代码定义是下面这样的: @ ...
- 最新阿里Java技术面试题,看这一文就够了!
金三银四跳槽季即将到来,作为 Java 开发者你开始刷面试题了吗?别急,小编整理了阿里技术面试题,看这一文就够了! 阿里面试题目目录 技术一面(基础面试题目) 技术二面(技术深度.技术原理) 项目实战 ...
- vue px 转rem
来自:https://www.cnblogs.com/wangqiao170/p/8652505.html 侵 删 每一个认真生活的人,都值得被认真对待 vue px转换为rem 前端开发中还原设 ...
- .net开源工作流引擎ccflow Pop返回值设置
关键词: 点击字段弹出返回值填充文本框或其他字段 表单自动填充 .net开源工作流 jflow工作流 ccflow 工作流引擎 应用场景 当我们的查询信息比较多我们希望有一个比较 ...