python之路8-内置模块介绍
time & datetime模块
1 #_*_coding:utf-8_*_
2 __author__ = 'Alex Li'
3
4 import time
5
6
7 # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
8 # print(time.altzone) #返回与utc时间的时间差,以秒计算\
9 # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
10 # print(time.localtime()) #返回本地时间 的struct time对象格式
11 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式
12
13 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
14 #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
15
16
17
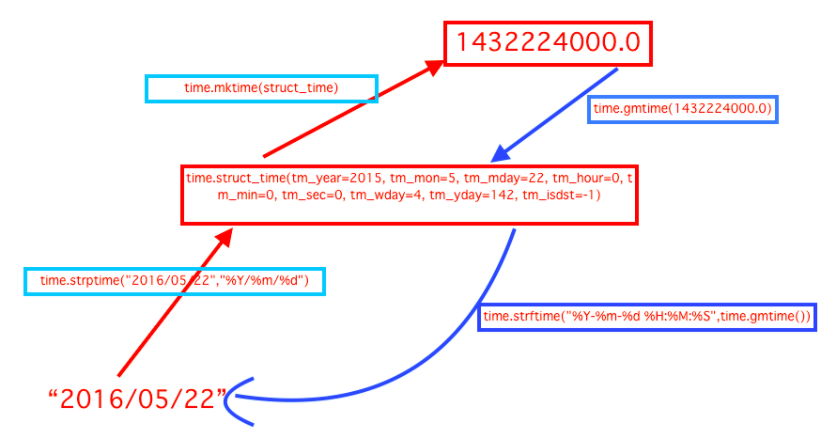
18 # 日期字符串 转成 时间戳
19 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
20 # print(string_2_struct)
21 # #
22 # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
23 # print(struct_2_stamp)
24
25
26
27 #将时间戳转为字符串格式
28 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
29 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
30
31
32
33
34
35 #时间加减
36 import datetime
37
38 # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
39 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
40 # print(datetime.datetime.now() )
41 # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
42 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
43 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
44 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
45
46
47 #
48 # c_time = datetime.datetime.now()
49 # print(c_time.replace(minute=3,hour=2)) #时间替换
random模块——随机数
mport random
print random.random()
print random.randint(1,2)
print random.randrange(1,10)
#生成随机验证码
1 import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print checkcode
OS模块——提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
json & pickle 模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle
import datetime
account = {
"id":6225353234,
"credit": 15000, #credit card
"balance": 8000,
"expire_date": "2020-5-21",
"password": "sdfsf",
"register_date":datetime.datetime.now()
} names = ["alex","jack"] f = open("account.db","wb")
print(pickle.dumps(account))
f.write(pickle.dumps(account))
f.write(pickle.dumps(names))
#pickle.dump(account,f) f.close()
shelve 模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
d = shelve.open('shelve_test') #打开一个文件
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ["alex","rain","test"]
d["test"] = name #持久化列表
d["t1"] = t #持久化类
d["t2"] = t2
d.close()
xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档内容
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
自己创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = ''
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = ''
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
PyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
ConfigParser模块
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port = 50022
ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '',
'Compression': 'yes',
'CompressionLevel': ''} config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
写完了还可以再读出来哈。
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
''
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
configparser增删改查语法
[section1]
k1 = v1
k2:v2 [section2]
k1 = v1 import ConfigParser config = ConfigParser.ConfigParser()
config.read('i.cfg') # ########## 读 ##########
#secs = config.sections()
#print secs
#options = config.options('group2')
#print options #item_list = config.items('group2')
#print item_list #val = config.get('group1','key')
#val = config.getint('group1','key') # ########## 改写 ##########
#sec = config.remove_section('group1')
#config.write(open('i.cfg', "w")) #sec = config.has_section('wupeiqi')
#sec = config.add_section('wupeiqi')
#config.write(open('i.cfg', "w")) #config.set('group2','k1',11111)
#config.write(open('i.cfg', "w")) #config.remove_option('group2','age')
#config.write(open('i.cfg', "w"))
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...") print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass '''
import hashlib # ######## md5 ######## hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hmac
h = hmac.new(b'天王盖地虎', b'宝塔镇河妖')
print h.hexdigest()
更多关于md5,sha1,sha256等介绍的文章看这里https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
最简单用法
import logging
logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down")
#输出
WARNING:root:user [alex] attempted wrong password more than 3 times
CRITICAL:root:server is down

如果想把日志写到文件里,也很简单
import logging logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
logging.basicConfig(filename='example.log',level=logging.INFO)
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.') #输出
12/12/2010 11:46:36 AM is when this event was logged.
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
import logging #create logger
logger = logging.getLogger('TEST-LOG')
logger.setLevel(logging.DEBUG) # create console handler and set level to debug
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # create file handler and set level to warning
fh = logging.FileHandler("access.log")
fh.setLevel(logging.WARNING)
# create formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # add formatter to ch and fh
ch.setFormatter(formatter)
fh.setFormatter(formatter) # add ch and fh to logger
logger.addHandler(ch)
logger.addHandler(fh) # 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
文件自动截断例子
import logging from logging import handlers logger = logging.getLogger(__name__) log_file = "timelog.log"
#fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3)
fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3) formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s') fh.setFormatter(formatter) logger.addHandler(fh) logger.warning("test1")
logger.warning("test12")
logger.warning("test13")
logger.warning("test14")
re模块——常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","").groupdict("city")
结果{'province': '', 'city': '', 'birthday': ''}
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
python之路8-内置模块介绍的更多相关文章
- python之路之简单介绍:
python介绍: a. python 基础 - 基础 - 基本的数据类型 - 函数 - 面向对象 python 安装 python 安装在os上 执行操作: 写一个文件,文件中按照python规则写 ...
- 百万年薪python之路 -- JS基础介绍及数据类型
JS代码的引入 方式1: <script> alert('兽人永不为奴!') </script> 方式2:外部文件引入 src属性值为js文件路径 <script src ...
- python内置模块介绍(一)
本文主要介绍模块列表如下: os sys re time datetime random shutil subprocess os模块 os.getcwd() ...
- python之路(dingo 框架)
Python之路 转载自QIMI老师 Python之路 第一篇:Python基础 PyCharm使用秘籍免费视频教程v3 ... 迭代器生成器 模块和常用内置模块 面向对象 面向对象进阶 网络编程 ...
- Python之路
Python学习之路 第一天 Python之路,Day1 - Python基础1介绍.基本语法.流程控制 第一天作业第二天 Python之路,Day2 - Pytho ...
- python之路 目录
目录 python python_基础总结1 python由来 字符编码 注释 pyc文件 python变量 导入模块 获取用户输入 流程控制if while python 基础2 编码转换 pych ...
- Python之路【第十九篇】:爬虫
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
- Python之路【第十八篇】:Web框架们
Python之路[第十八篇]:Web框架们 Python的WEB框架 Bottle Bottle是一个快速.简洁.轻量级的基于WSIG的微型Web框架,此框架只由一个 .py 文件,除了Pytho ...
- Python之路【第五篇】:面向对象及相关
Python之路[第五篇]:面向对象及相关 面向对象基础 基础内容介绍详见一下两篇博文: 面向对象初级篇 面向对象进阶篇 其他相关 一.isinstance(obj, cls) 检查是否obj是否 ...
- Python之路【第五篇】:面向对象和相关
Python之路[第五篇]:面向对象及相关 面向对象基础 基础内容介绍详见一下两篇博文: 面向对象初级篇 面向对象进阶篇 其他相关 一.isinstance(obj, cls) 检查是否obj是否 ...
随机推荐
- Pycharm2018永久破解的办法
Pycharm2018永久破解的具体步骤: 一.下载pycharm2018专业版 JetBrains官网:https://www.jetbrains.com/pycharm/download/#sec ...
- Asp.Net.Identity认证不依赖Entity Framework实现方式
Asp.Net.Identity为何物请自行搜索,也可转向此文章http://www.cnblogs.com/shanyou/p/3918178.html 本来微软已经帮我们将授权.认证以及数据库存储 ...
- Java使用Aspose组件进行多文档间的转换操作
首先,祝大家新年快乐,2019诸事顺利,很久没有更新博客,今天要给大家说的是 ”Aspose“ 组件,作为2019年第一篇博客,希望大家能够多多支持,2019年要继续加油. 什么是Aspose? As ...
- KVO讲解
最近一直在写swift项目,没有时间更新自己的技术博客,以前在博客里面写过KVO的底层原理,今天我们来看一下KVO的整个使用过程和使用场景(附有demo),大约花大家10-15分钟时间,希望大家看完博 ...
- PHP正则表达式二分法实现mysql盲注脚本
$sUrl = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'; $sPost = 'inject=Inject&injection='; $sCharset = 'AB ...
- 【并发编程】Future模式及JDK中的实现
1.1.Future模式是什么 先简单举个例子介绍,当我们平时写一个函数,函数里的语句一行行同步执行,如果某一行执行很慢,程序就必须等待,直到执行结束才返回结果:但有时我们可能并不急着需要其中某行的执 ...
- 通过JS动态的修改HTML元素的样式和增添标签元素等
一. 通过JS动态的修改HTML元素的样式 1. 要想在js中动态的修改HTML元素的样式,首先需要写document, document我们称之为文档对象,这个对象中保存了当前网页中所有的 ...
- Android为TV端助力:自定义view之太阳
先看效果图 package com.hhzt.iptv.lvb_w8.view; import android.content.Context;import android.graphics.Canv ...
- Centos7 使用 kubeadm 安装Kubernetes 1.13.3
目录 目录 什么是Kubeadm? 什么是容器存储接口(CSI)? 什么是CoreDNS? 1.环境准备 1.1.网络配置 1.2.更改 hostname 1.3.配置 SSH 免密码登录登录 1.4 ...
- kkkK的随笔
自我介绍 学号:211606310 姓名:柯伟敏 爱好:篮球,足球 最爱的菜:4堂的饺子 最想说的话:一切都是最好的安排 初入大学 -------------------- 选择 选择软件工程这个专业 ...