闲聊cassandra
原创,转载请注明出处
今天聊聊cassandra,里面用了不少分布式系统设计的经典算法比如consistent hashing, bloom filter, merkle tree, sstable, CAP trade off, replication, etc.(笔者已然泪流满面) 总之就是经典中的经典,我只能是仰视一下巨人的设计理念和应用。
cassandra起源于Facebook,据说是dynamo的设计师跑到了Facebook写的(其实也借鉴了谷歌的bigtable)。所以可以知道亚麻的dynamo真的是革命性的突破。dynamo应该是当代流行的布式数据库的开山鼻祖。不过后来Facebook自己不用了。。。但是在硅谷的其它公司可是火到不行。另一个相关数据库是riak,是一波程序员读了dynamo的paper用erlang搞出来的open source。笔者安装过riak, 貌似它能每次query都能设定R,W的值(不过时间有点久,印象有点模糊,反正当时我就惊了)后来发现Cassandra也是每次query可以设consistency level我才明白原来都这样。后来bisho(维护riak的公司,于riak应该就像datastax和Cassandra,confluent和kafka的关系差不多)的CTO走了,不知道riak前景如何,我是觉得懂erlang的人太少(当然不能否认erlang并发的牛逼),所以大家如果学习了Cassandra,就不用了解riak了。
本文内容是基于Cassandra 3 btw 。
Tables
用cql shell写table,让人有一种操控relational database的感觉有木有。然并卵,原理完全不同呀亲。它的shape应该说是瘦高个,宽度会较窄,长度会任意长(horizontally scale,想要更多行,加机器就行)。没有join。没有foreign key。需要有keyspace,keyspace相当于是tables的container, 相当于relational database里的database, 会定义replication strategy, replication factor。在keyspace里面就可以create table了。
table里面有primary key, 用来识别row,primary key 由(paritition key) 和 clustering key组成。对于partition key,相同key的row会存在同一台物理机器上。clustering key则可以用在where后面用来与threshold啥的做比较或者排个序啥的。
Data Types
- text, int, bigint, float, double, boolean
- decimal, varint
- uuid, timeuuid(sorted by time, 牛逼)
- inet
- tuple
- timestamp
- counter (distributed counter, 除了key之外,如果有一个column是counter,其它column都要是counter,初始为0)
- set (unique set)
- list
- map (k/v pair, k is unique)
Secondary Index
在relational database中,相当于加index给其它column。加了有减慢写的速度的可能性。Cassandra在设计的时候会避免一切减慢scalable的可能性。SASI(SSTable Attached Secondary Index)是Cassandra的实现。可以通过以下方式添加SASI:
- create custom index XXX on X_table(XXX) using "org.apache.cassandra.index.sasi.SASIIndex" with options = {'mode' : 'CONTAINS'};
另外两种mode分别是(prefix和sparse),prefix就是“prefix%”如果这就是唯一的pattern,那么效率比contains要高。
SASI在下文中有详细的介绍: http://www.doanduyhai.com/blog/?p=2058
Secondary index怎么用?可以应用于非常大的partition(同一个node)来加速rows filter。应用的时候注意使用相同的partition key,也就意味着在同一个node。当然它也支持多node,也就是不同的partition key,不过要小心出问题。
Query First Modeling
这里要注意Cassandra的table设计理念是de-normalize,(恰好和relational database的normalize相反)。Entity model(domain) still the same, 比如movies。 知道你的program要干什么,需要什么query,然后设计table。table的创建是由query的需求决定的。当然也会因为新query的需求而要进行schema revolution,这个在relational database中也是常见的无法避免的问题,毕竟没有完美的schema,是一个动态平衡的问题。所以只能通过create new talbes, migration old data to new table来满足新的query。
更多信息参见:https://academy.datastax.com/resources/ds220-data-modeling
基本的理念就是现想都有哪几个query需要解决,然后根据query想partition key和clustering key,最后计算partition大小不能超过2 billion cells,大概就是(num_of_column - partition_key) * num_of_rows。如果parititon过大,要么加新的cluster key减少partition size,要么用materiel view替代query.
Materialized Views
如果有几个denormalized table,有相同的信息,现在需要加入新的信息,听起来好像要插入好几个table,由于没有transaction,会出现一个table update了,剩下的还没动静的问题,感觉好像会有race condition存在而且好像无法避免。笔者的理解是materialized view正是要来解决这个问题,有一个比较wide的table,然后通过定义material view来回答query,这样当这个table被update了,casandra 会guarantee view也就被update了,问题就解决了。否则application端要相办法加transaction。
Nodes and Clusters
如果你的问题可以用一台电脑解决,用postgres就好了,不要用Cassandra,cassandra就是要解决一台电脑搞不定的问题。每一个Node都是peer, 没有master/controller,cluster是ring structure,去中心化结构。Parition key is hashed to go to a particlar machine. 基本上就是应用了consistent hashing。
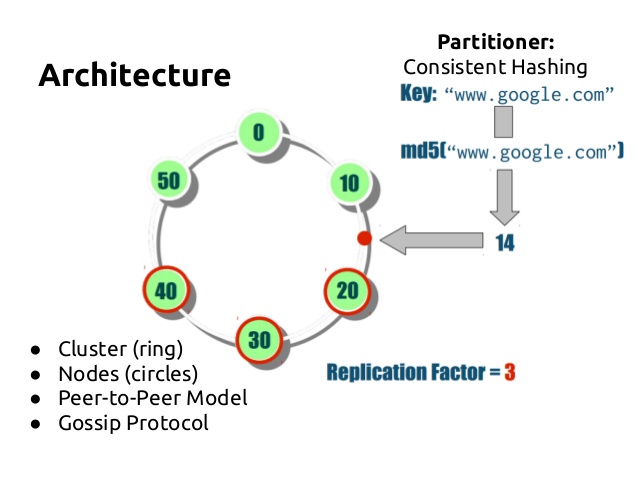
Replication
replication factor决定了每次写复制几次,比如如果是3(通常production会选择3个,当然我也见过一共7台机器就把copy定义为7的),就意味着写的结果会存3个copy。replication strategy会决定怎么找到copy。在keyspace会定义这两个parameter。
Consistency
通常有3种选择,all/quorum/one,tunable at every query level(of course also at table level), 假设replication factor是3,那么quorum写就是2,quorum读也是2,all写/读是3,one写/读是1。 每个node都有coordinator的角色,能够帮助redirect找到真正的node。client往coordinator写的时候,block多久取决于consistency level,如果是quorum,那么两个成功写入就会返回了。
R+W > N,决定了strong consistency, E.g. 2+2 > 3。读总是能读到最新写的内容。
Multiple Data Center
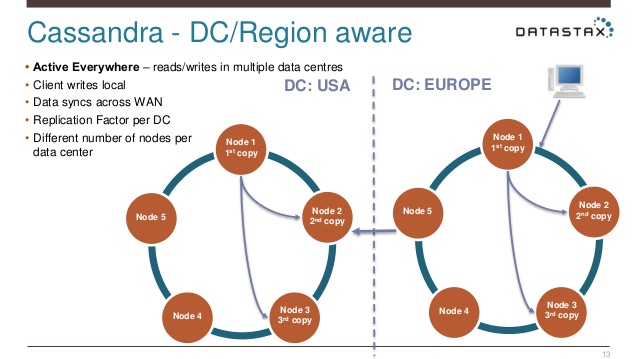
client端何时返回取决于each_quorum还是local_quorum,如果是local_quorum,那么另一个data center就是asyncrhonous, 效率比较高。each_quorum由于牵扯WAN latency会很高。
multiple data center同时适用于支持both transaction heavy job和analytical job。transaction heavy job比较容易caching,因为总会有一些hot data去某几个server。而analytical job是每个row都要读所以不适合caching,这样这两种job就不适合运行在同一台machine。所以可以一个data center进行transsaction job,另一个data center运行analysis job。
Gossip
想象一下coordinator redirect的时候需要知道哪些node up or down或者哪台机器latency最低,所以每隔一段时间比如每秒钟,random node就会把自己知道的other nodes status/metadata随机发送出去,information could propagate pretty efficiently。每个node就通过这种方式维持每个成员的metadata。
Write Path

首先,data会先写入commit log,append only,每个node有一个global commit log,每个table都是望着里面写。然后会写入memtable,memtable是每个table会有自己的memtable。写完之后write就可以返回给coordinator了。memtable写到一定程度会flush到SSTable(sorted string table)。cassandra的write是非常efficient,可能比读还快。对于update,只是会重新写一个新的,不会改旧的,读的时候会读最新的。delete的时候是写新row加tombstone。SSTable合并的时候会把这个row删除掉。
Read Path
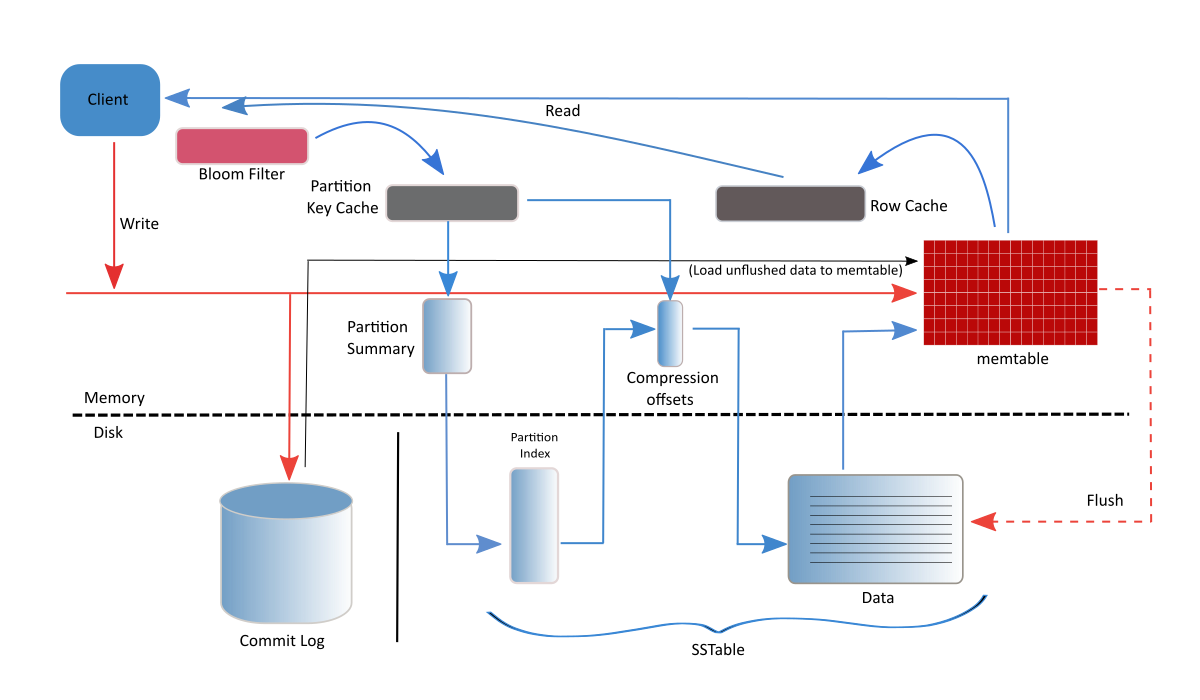
读的时候先读memtable,如果没有的话找SSTable,通过bloomfilter来加速查询,如果bloomfilter说没有,那就真没有,如果bloomfilter说有,就继续查。file will be sorted by partition key。在bloom filter之后还会有一个key cache,如果key cache里有就可以直接读了,没有再从index/file去找,找到后把location/path放到key cache,不用cache具体的内容,操作系统的cache比如page cache会更高效。
Compaction

因为SSTable是sorted by partition key,所以合并的时候value in new partition 会overwrite value in old partition,tombstone的会被删除掉。
compaction也有不同的strategy可供选择,比如write heavy和read heavy的strategy就不一样。这里就不详细解读了。
cassandra支持很多种不同语言的driver,比如java,python,c++。方便developer选择最适合自己的。今天就先聊到这,happy cassandra!
闲聊cassandra的更多相关文章
- 与HBase对比,Cassandra的优势特性是什么?
在1月9日Cassandra中文社区开年活动开始之前的闲聊时间,活动的四位嘉宾就"HBase和Cassandra的对比"这一话题展开了讨论. 总的来说,HBase和Cassan ...
- Cassandra简介
在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法.而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介 ...
- ASP.NET Core Web API Cassandra CRUD 操作
在本文中,我们将创建一个简单的 Web API 来实现对一个 “todo” 列表的 CRUD 操作,使用 Apache Cassandra 来存储数据,在这里不会创建 UI ,Web API 的测试将 ...
- cassandra写数据CommitLog
cassandra 两种方式: Cassandra-ArchitectureCommitLog Cassandra持久化-Durability 一种是配置commitlog_sync为periodic ...
- 学习Cassandra的开源电子书(中英文版)
学习Cassandra的开源电子书(中英文版)发布啦:http://teddymaef.github.io/learncassandra/ 之前发布了英文版,现在包含中文版了. 学习Cassandra ...
- Solr与Cassandra二级缓存实践
额达到数十亿美元.在Newegg,每天有数以千万计的用户浏览商品,并产生下单交易等后续操作.我们构建的数据系统,必须应对日益增大的数据量,具备健壮性.可靠性.目前,我们采用Cassandra来构建Ne ...
- cassandra.yaml介绍
cluster_name 集群的名字,默认情况下是TestCluster.对于这个属性的配置可以防止某个节点加入到其他集群中去,所以一个集群中的节点必须有相同的cluster_name属性. list ...
- Cassandra数据类型:
Cassandra在CQL语言层面支持多种数据类型[12]. CQL类型 对应Java类型 描述 ascii String ascii字符串 bigint long 64位整数 blob ByteBu ...
- Cassandra 配制 cassandra.yaml
一.设置用户名和密码 修改cassandra.yaml配置文件 把默认的 authenticator: AllowAllAuthenticator 改成 authenticator: Password ...
随机推荐
- mysql commit 和 rollback
转自:http://blog.csdn.net/ying_593254979/article/details/12134629 SQL 语言类型 从功能上划分,SQL 语言可以分为DDL,DML和DC ...
- Windows上最大传输单元MTU值的查看和设置
最近使用ssh工具在VPN环境下连接一个生产环境的Linux主机的时候,发现经常出现输入命令后卡死的情况.最开始以为是Linux主机的问题,问了一些老同事之后发现原来是我自己电脑的最大传输单元MTU和 ...
- 《algorithms Unlocked》读书笔记3——计数排序
<Algorithms Unlocked>是 <算法导论>的合著者之一 Thomas H. Cormen 写的一本算法基础,算是啃CLRS前的开胃菜和辅助教材.如果CLRS的厚 ...
- webapi框架搭建-创建项目(一)
本文只是一些基本的vs操作,供初学者参考,有基础的请查看 创建项目(二) 创建项目(三) 前言 为了从头了解webapi的技术,创建一个为空的项目 步骤 我用的是vs2017,从文件-->新建- ...
- delphi用webservice
delphi的webservice开发. 一.在已有的项目中,调用外部的webservice 1.根据向导建webservice,在项目中引入“WSDL Importer".假设引入后生成的 ...
- VI命令汇总
ia/Ao/Or + ?替换 0:文件当前行的开头$:文件当前行的末尾G:文件的最后一行开头:n :文件中第n行的开头 dd:删除一行3dd:删除3行yy:复制一行3yy:复制3行p:粘贴u:undo ...
- MySQL数据类型转换函数CAST与CONVERT的用法
MySQL 的CAST()和CONVERT()函数可用来获取一个类型的值,并产生另一个类型的值.两者具体的语法如下: 1.CAST(value as type) 就是CAST(xxx AS 类型) 2 ...
- 【转载】Linux下的IO监控与分析
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performance and Tuning G ...
- Core Animation 文档翻译 (第二篇)
Core Animation 文档翻译 (第二篇) 核心动画基础要素 核心动画为我们APP内Views动画和其他可视化元素动画提供了综合性的实现体系.核心动画不是我们APP内Views的替代品,相反, ...
- 一次完整的http的请求过程
一个完整的http的完成请求过程: 输入网址-> 域名解析-> tcp的三次握手-> 建立tcp连接后发起http 请求-> 服务器响应http ,发送数据给浏览器-> ...