Hadoop 新生报道(四) WordCount
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//accept
String line = value.toString();
//split
String[] words = line.split(" ");
//loop
for(String w : words){
//send
context.write(new Text(w), new LongWritable(1));
}
}
}
Mapper这里继承的时候泛型限定了4个类型<LongWritable, Text, Text, LongWritable>,分别是输入的key,value,输出的key,value的类型,LongWritable是hadoop中long的序列化类,Text是String的序列化类。
map函数中,Mapper从文档中得到偏移量(本程序不用,不管他)在key中,每行的值在value中,然后从value中用空格分开得到每个词,然后现在得到的每个词都是一次的,所以给content中添加<单词,1>,保存在content中,传给reduce。
Reduce的代码:
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
//define a counter
long counter = 0;
//loop
for(LongWritable l : values){
counter += l.get();
}
//write
context.write(key, new LongWritable(counter));
}
}
Reduce继承的时候,限定的<Text, LongWritable, Text, LongWritable>是输入的<key,value>和输出的<key,value>,输入必须和Mapper的输出一样,输出自己定义,我们定义的是输出单词和它的次数。
Mapper的输出传到Reduce的时候,中间会有一个过程(框架自动干的活,这就是框架的好处了),他会把Mapper输出的键值对中key相同的键值对合并,比如<hadoop,1>和<hadoop,1>会因为key都是hadoop二合并变成<hadoop,[1,1]>,如果再有一个<hadoop,1>,就会合并成<hadoop,[1,1,1]>。
所以在reduce函数中,对每一个key对应的value迭代,每次得到一个次数(我们都设定的1),累加起来就是这个单词的次数了。
然后,每个MapReduce程序都是一个job,需要开启。
运行类(都有注释就不解释了):
public class WCRun {
public static void main(String[] args) {
try {
//下边4行代码设置job的基础信息,setJarByClass就是设置当前运行的main所在的class文件
Configuration conf = new Configuration();
Job job =Job.getInstance(conf);
job.setJarByClass(WCRun.class);
job.setJobName("wordcount");
//设置Mapper和Reduce的class文件是哪个
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//设置输出的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入也就是从文件中得到键值对的方法,也就是我们之所以得到的是偏移量和一行文本,就是这个决定的
job.setInputFormatClass(TextInputFormat.class);
//设置输出的格式,同输入,不过内容是我们自己定义的
job.setOutputFormatClass(TextOutputFormat.class);
//得到输入路径和输出路径,这里用参数,注意输出目录不能存在
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//启动job并等待运行结果
job.waitForCompletion(true);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
!!!再次提醒,输出目录不能存在!!!
运行的话,可以配置本地模式,可以集群运行,我们用集群跑一跑。
首先吧整个程序打包成jar包,项目-->export-->java,jar
然后把jar文件上传到我们的集群上。
在hdfs里建一个输入文件夹,找一个文档放进去,输出的目录一定不要建(重要的事说三遍)。

然后运行, 指令是 hadoop jar 你的程序的jar包 程序的main在的类 输入文件夹 输出文件夹
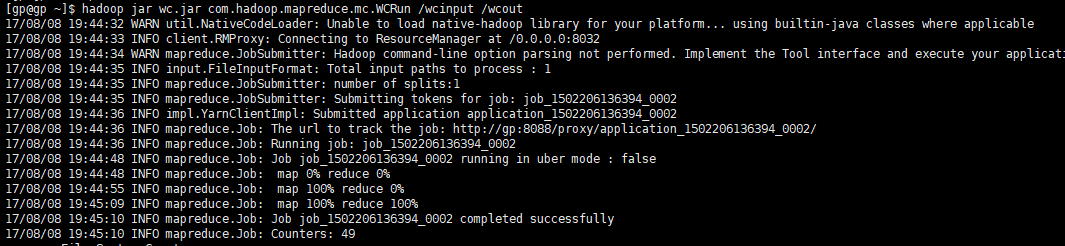
程序运行成功,进入wcout看一看

有两个文件,第一个表示我们成功了,第二个就是结果文件,吧第二个文件get到本地打开看一看
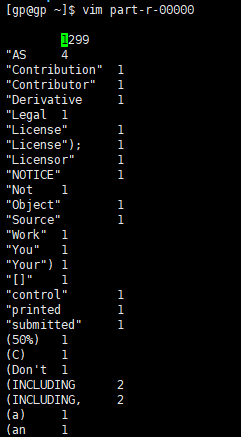
统计的结果,大功告成。
ps:都是学hadoop的新手,欢迎评论留言交流,一起进步。
Hadoop 新生报道(四) WordCount的更多相关文章
- Hadoop 新生报道(三) hadoop基础概念
一.NameNode,SeconderyNamenode,DataNode NameNode,DataNode,SeconderyNamenode都是进程,运行在节点上. 1.NameNode:had ...
- Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置
本次基于Hadoop2.6版本进行分布式配置,Linux系统是基于CentOS6.5 64位的版本.在此设置一个主节点和两个从节点. 准备3台虚拟机,分别为: 主机名 IP地址 master 192. ...
- hadoop自带例子wordcount的具体运行步骤
1.在hadoop所在目录“usr/local”下创建一个文件夹input root@ubuntu:/usr/local# mkdir input 2.在文件夹input中创建两个文本文件file1. ...
- HADOOP :: java.lang.ClassNotFoundException: WordCount
I am using eclipse to export the jar file of a map-reduce program. When i am run the jar using comma ...
- Hadoop版Helloworld之wordcount运行示例
1.编写一个统计单词数量的java程序,并命名为wordcount.java,代码如下: import java.io.IOException; import java.util.StringToke ...
- Hadoop最基本的wordcount(统计词频)
package com.uniclick.dapa.dstest; import java.io.IOException; import java.net.URI; import org.apache ...
- 执行hadoop自带的WordCount实例
hadoop 自带的WordCount实例可以统计一批文本文件中各单词出现的次数.下面介绍如何执行WordCount实例. 1.启动hadoop [root@hadoop ~]# start-all. ...
- Hadoop环境搭建及wordcount程序
目的: 前期学习了一些机器学习基本算法,实际企业应用中算法是核心,运行的环境和数据处理的平台是基础. 手段: 搭建简易hadoop集群(由于机器限制在自己的笔记本上通过虚拟机搭建) 一.基础环境介绍 ...
- hadoop第一个例子WordCount
hadoop查看自己空间 http://127.0.0.1:50070/dfshealth.jsp import java.io.IOException; import java.util.Strin ...
随机推荐
- http请求HttpClient短信接口
项目中安全设置找回密码的功能,需要通过发送短信验证绑定手机,通过绑定的手机号验证并重新设置密码. 因为项目是通过maven管理的,所以需要在pom.xml文件中引入jar包, maven引入的jar包 ...
- 杭电1513Palindrome
Palindrome Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- SpringMVC+Mybatis架构中的问题记录
2014/08/16 记录 今天遇到个问题.折腾了我大约4个小时,好坑啊由于之前没遇到过 我的包是这么分的:com.project名.模块名.service.impl 在spring 配置这个 ...
- vim各种编码设置问题
vim各种编码设置问题 vim中主要有四个编码相关的设置,详细是~/.vimrc中: 下面是我的设置: set fileencodings=gb18030,utf-8,gb2312,gbk: set ...
- C#:CsvReader读取.CSV文件并转换成DataTable
原文引用:https://www.codeproject.com/Articles/9258/A-Fast-CSV-Reader using LumenWorks.Framework.IO.Csv; ...
- 使用angularjs实现注册表单
本文是在学习angularjs过程中做的相应的练习 github地址 https://github.com/2016Messi/angularjs1.6-form 演示地址 https://2016m ...
- 数据分析与展示——Matplotlib库入门
Matplotlib库入门 Matplotlib库介绍 Matliotlib库是Python优秀的数据可视化第三方库. Matliotlib库的效果见:http://matplotlib.org/ga ...
- Struts2学习---result结果集
这一章节主要介绍如何配置结果集,分为以下几个知识点: 结果集类型(result type) 全局结果集(global types) 动态结果集(dynamic type) 带有参数的结果集(type ...
- 使用Python Shapefile Library创建和编辑Shapefile文件
介绍 shapefile是GIS中非常重要的一种数据类型,在ArcGIS中被称为要素类(Feature Classes),主要包括点(point).线(polyline)和多边形(polygon).P ...
- Structural Inference of Hierarchies in Networks(网络层次结构推断)
Structural Inference of Hierarchies in Networks(网络层次结构推断) 1. 问题 层次结构是一种重要的复杂网络性质.这篇文章给出了层次结构的精确定义,给出 ...