SQL Server-聚焦ROW_NUMBER VS TOP N性能
前言
抱歉各位,从八月份开始一直在着手写EntityFramework 6.x和EntityFramework Core 2.0的书籍写作,所以最近一直遗漏了对博客的管理,后面会着手于写SQL Server、EntityFramework Core和.NET Core方面的博客。我们知道如果需要查询前N行数据,除了可以利用TOP N进行查询外,同样也可以利用ROW_NUMBER来达到同样的效果,那么二者使用哪个性能会更好呢?下面我们来比较下。
ROW_NUMBER VS TOP N
我们利用AdventureWorks2012示例库中的Production.Product表来进行演示,如下:
DBCC DROPCLEANBUFFERS()
DBCC FREEPROCCACHE()
GO --ROW_NUMBER QUERY
SELECT ProductID
FROM (
SELECT ProductID, ROW_NUMBER() OVER (ORDER BY ProductID) AS RN
FROM Production.Product
) AS T
WHERE T.RN <= 100
GO -- TOP N QUERY
SELECT
TOP 100 ProductID
FROM Production.Product
ORDER BY ProductID
GO
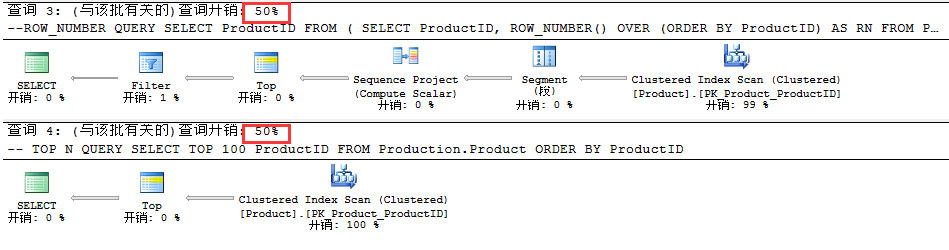
如上图所知,对于这两个查询计划的成本是一样的,都为50%。 如果我们要检查在两个聚集索引扫描操作符中读取的估计行数,那么我们会注意到两者都显示相同的值,即100。可以说聚集索引扫描的估计和实际行数是相同的都是100,如下。
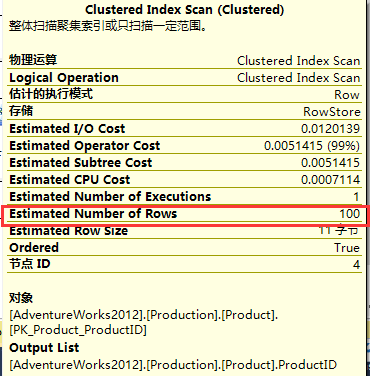
是不是就以此说明二者性能是一样的呢?稍等片刻,接下来我们将查询基数再设置大一点看看,比如1000而不再是100,如下:
DBCC DROPCLEANBUFFERS()
DBCC FREEPROCCACHE()
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
--ROW_NUMBER QUERY
SELECT ProductID
FROM (
SELECT ProductID, ROW_NUMBER() OVER (ORDER BY ProductID) AS RN
FROM Production.Product
) AS T
WHERE T.RN <= 1000
GO -- TOP N QUERY
SELECT
TOP 1000 ProductID
FROM Production.Product
ORDER BY ProductID
GO

从如上截图可以看出,使用ROW_NUMBER进行查询的速度要明显快于TOP N,即29%和71%。 但是,我们还需要在等一下,因为我们在这里看到的成本只是估计成本。 如果操作的估算不准确,那么查询计划估算成本也将不准确。 接下来我们检查两个计划中的聚集索引扫描的属性:

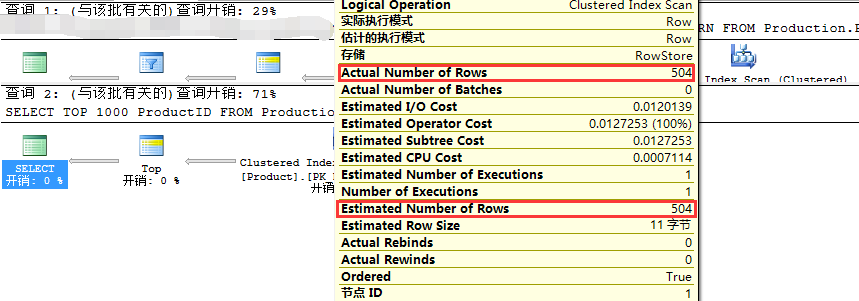
我们可以看到,使用ROW_NUMBER查询的估计行数为100,而实际数量为504,查询计划的估计成本是基于估计的行数所计算得来,即100。我们还是不能够相信估计的计划成本。 我们再来看看统计数据:

经过上面的统计,我们可以根据统计数据而做出最终决定,而不是比较执行计划的估计成本。TOP N的查询性能优于ROW_NUMBER。
总结
从上比较TOP N和ROW_NUMBER的查询得知,查询计划所得到的成本并不是判断性能的最终依据,只是基础性的判断,我们最终还得集合IO和TIME等来综合判断性能差异。
SQL Server-聚焦ROW_NUMBER VS TOP N性能的更多相关文章
- SQL Server 分组后取Top N
SQL Server 分组后取Top N(转) 近日,工作中突遇一需求:将一数据表分组,而后取出每组内按一定规则排列的前N条数据.乍想来,这本是寻常查询,无甚难处.可提笔写来,终究是困住了笔者好一会儿 ...
- SQL Server数据库ROW_NUMBER()函数使用详解
SQL Server数据库ROW_NUMBER()函数使用详解 摘自:http://database.51cto.com/art/201108/283399.htm SQL Server数据库ROW_ ...
- SQL Server调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server 中ROW_NUMBER() OVER基本用法
1.不能排序法 * FROM table1 WHERE id NOT IN ( SELECT TOP 开始的位置 id FROM table1 ) 2.SQL 2000 临时表法 DECLARE @S ...
- SQL Server 调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server 2008内存及I/O性能监控
来源: it168 发布时间: 2011-04-12 11:04 阅读: 10820 次 推荐: 1 原文链接 [收藏] 以下均是针对Window 32位系统环境下,64位的不在下面 ...
- SQL Server分页的存储过程写法以及性能比较
------创建数据库data_Test ----- create database data_Test GO use data_Test GO create table tb_TestTable - ...
- SQL Server中使用Check约束提升性能
在SQL Server中,SQL语句的执行是依赖查询优化器生成的执行计划,而执行计划的好坏直接关乎执行性能. 在查询优化器生成执行计划过程中,需要参考元数据来尽可能生成高效的执行计划, ...
- SQL Server中一个隐性的IO性能杀手-Forwarded record
简介 最近在一个客户那里注意到一个计数器很高(Forwarded Records/Sec),伴随着间歇性的磁盘等待队列的波动.本篇文章分享什么是forwarded record,并从原理上谈一 ...
随机推荐
- 华南师大 2017 年 ACM 程序设计竞赛新生初赛题解
题解 被你们虐了千百遍的题目和 OJ 也很累的,也想要休息,所以你们别想了,行行好放过它们,我们来看题解吧... A. 诡异的计数法 Description cgy 太喜欢质数了以至于他计数也需要用质 ...
- 了解python,利用python来制作日常猜拳,猜价小游戏
初次接触python,便被它简洁优美的语言所吸引,正所谓人生苦短,python当歌.python之所以在最近几年越发的炽手可热,离不开它的一些特点: 1.易于学习:Python有相对较少的关键字,结构 ...
- 【JDK1.8】JDK1.8集合源码阅读——TreeMap(二)
一.前言 在前一篇博客中,我们对TreeMap的继承关系进行了分析,在这一篇里,我们将分析TreeMap的数据结构,深入理解它的排序能力是如何实现的.这一节要有一定的数据结构基础,在阅读下面的之前,推 ...
- TP框架中内置查询IP函数
系统内置了get_client_ip方法用于获取客户端的IP地址,使用示例: $ip = get_client_ip(); 如果要支持IP定位功能,需要使用扩展类库Org\Net\IpLocation ...
- C语言之二分猜数字游戏
#include <stdio.h>#include <windows.h>#include<string.h>int main() { int oldprice, ...
- 友元函数 C++
#include<iostream> #include<vector> using namespace std; class Text{ public: Text():a(){ ...
- HDU3790-最短路径问题
最短路径问题 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- Linux磁盘分区(二):删除
***********************************************声明************************************************ 原创 ...
- post 与get 区别
刷新/后退按钮 GET后退按钮/刷新无害,POST数据会被重新提交(浏览器应该告知用户数据会被重新提交). 书签 GET书签可收藏,POST为书签不可收藏. 缓存 GET能被缓存 缓存是针对URL来进 ...
- 最好用的MongoDB GUI - LivingMongo
LivingMongo是一个mongodb数据库的GUI操作系统,支持对数据字段的修改.数据搜索.集合的分类.索引管理.空间统计.慢查询等 demo地址 : http://living-mongo.k ...