用GAN生成二维样本的小例子
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/27343585
本文完整代码地址:Generative Adversarial Networks (GANs) with 2D Samples
50行GAN代码的问题
Dev Nag写的50行代码的GAN,大概是网上流传最广的,关于GAN最简单的小例子。这是一份用一维均匀样本作为特征空间(latent space)样本,经过生成网络变换后,生成高斯分布样本的代码。结构非常清晰,却有一个奇怪的问题,就是判别器(Discriminator)的输入不是2维样本,而是把整个mini-batch整体作为一个维度是batch size(代码中batch size等于cardinality)那么大的样本。也就是说判别网络要判别的不是一个一维的目标分布,而是batch size那么大维度的分布:
...
d_input_size = 100 # Minibatch size - cardinality of distributions
...
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Discriminator, self).__init__()
self.map1 = nn.Linear(input_size, hidden_size)
self.map2 = nn.Linear(hidden_size, hidden_size)
self.map3 = nn.Linear(hidden_size, output_size) def forward(self, x):
x = F.elu(self.map1(x))
x = F.elu(self.map2(x))
return F.sigmoid(self.map3(x))
...
D = Discriminator(input_size=d_input_func(d_input_size), hidden_size=d_hidden_size, output_size=d_output_size)
...
for epoch in range(num_epochs):
for d_index in range(d_steps):
# 1. Train D on real+fake
D.zero_grad() # 1A: Train D on real
d_real_data = Variable(d_sampler(d_input_size))
d_real_decision = D(preprocess(d_real_data))
d_real_error = criterion(d_real_decision, Variable(torch.ones(1))) # ones = true
d_real_error.backward() # compute/store gradients, but don't change params # 1B: Train D on fake
d_gen_input = Variable(gi_sampler(minibatch_size, g_input_size))
d_fake_data = G(d_gen_input).detach() # detach to avoid training G on these labels
d_fake_decision = D(preprocess(d_fake_data.t()))
d_fake_error = criterion(d_fake_decision, Variable(torch.zeros(1))) # zeros = fake
d_fake_error.backward()
d_optimizer.step() # Only optimizes D's parameters; changes based on stored gradients from backward() for g_index in range(g_steps):
# 2. Train G on D's response (but DO NOT train D on these labels)
G.zero_grad() gen_input = Variable(gi_sampler(minibatch_size, g_input_size))
g_fake_data = G(gen_input)
dg_fake_decision = D(preprocess(g_fake_data.t()))
g_error = criterion(dg_fake_decision, Variable(torch.ones(1))) # we want to fool, so pretend it's all genuine g_error.backward()
g_optimizer.step() # Only optimizes G's parameters ...
不知作者是疏忽了还是有意为之,总之这么做的结果就是如此简单的例子收敛都好。可能作者自己也察觉了收敛问题,就想把方差信息也放进来,于是又写了个预处理函数(decorate_with_diffs)计算出每个样本距离一批样本中心的距离平方,作为给判别网络的额外输入,其实这样还增加了输入维度。结果当然是加不加这个方差信息都能勉强收敛,但是都不稳定。甚至作者自己贴出来的生成样本分布(下图)都不令人满意:
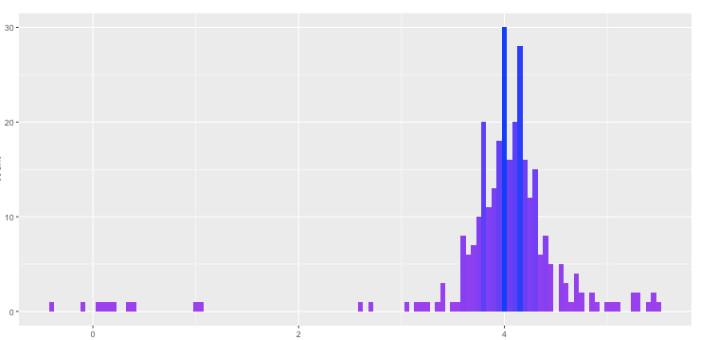
如果直接把这份代码改成二维的,就会发现除了简单的对称分布以外,其他分布基本都无法生成。
理论上讲神经网络作为一种通用的近似函数,只要capacity够,学习多少维分布都不成问题,但是这样写法显然极大增加了收敛难度。更自然的做法应该是:判别网络只接受单个二维样本,通过batch size或是多步迭代学习分布信息。
另:这份代码其实有130行。
从自定义的二维分布采样
不管怎样Dev Nag的代码还是提供了一个用于理解和试验GAN的很好的框架,做一些修改就可以得到一份更适合直观演示,且更容易收敛的代码,也就是本文的例子。
从可视化的角度二维显然比一维更直观,所以我们采用二维样本。第一步,当然是要设定一个目标分布,作为二维的例子,分布的定义方式应该尽量自由,这个例子中我们的思路是通过灰度图像定义的概率密度,进而来产生样本,比如下面这样:
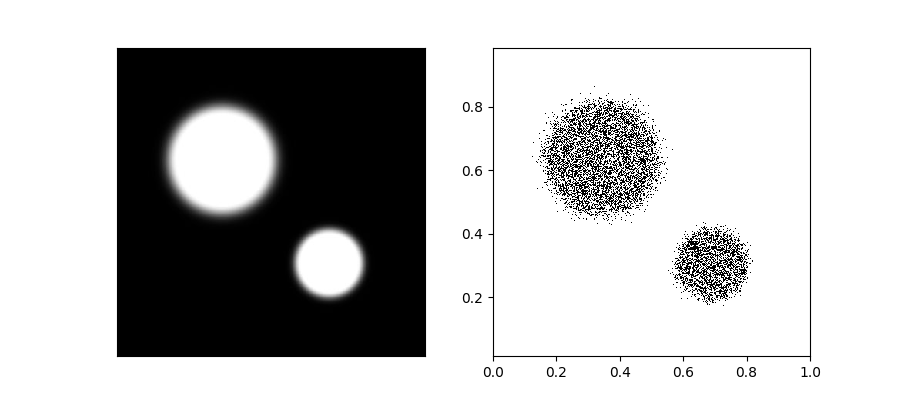
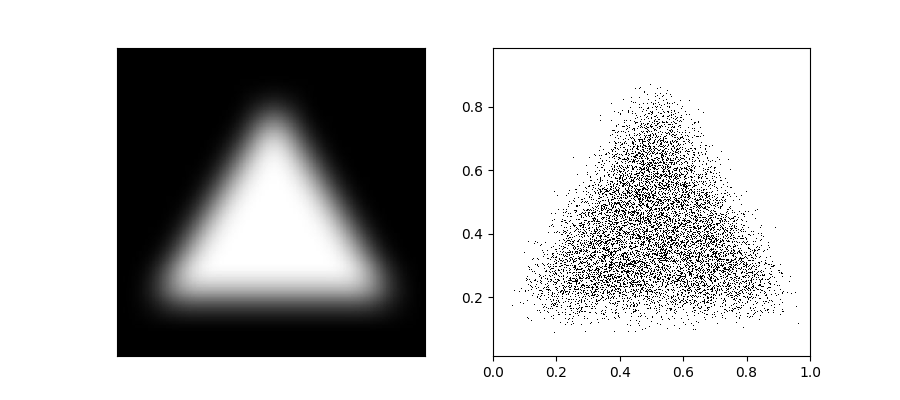
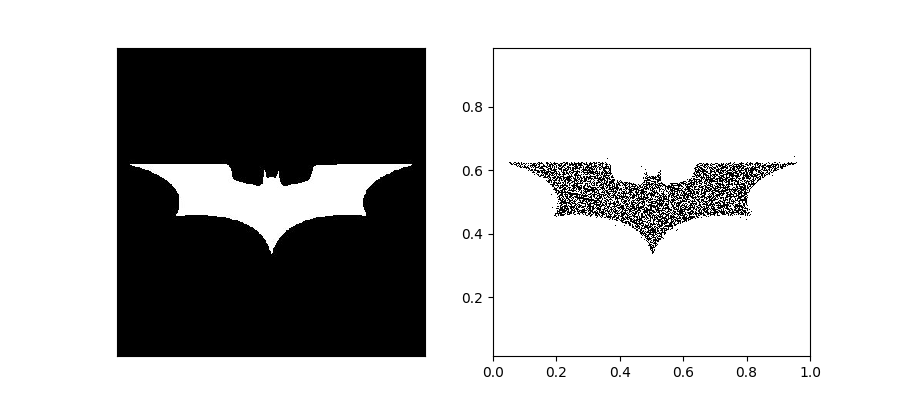
二维情况下,这种采样的一个实现方法是:求一个维度上的边缘(marginal)概率+另一维度上近似的条件概率。比如把图像中白色像素的值作为概率密度的相对大小,然后沿着x求和,然后在y轴上求出marginal probability density,接着再根据y的位置,近似得到对应x关于y的条件概率。采样的时候先采y的值,再采x的值就能近似得到符合图像描述的分布的样本。具体细节就不展开讲解了,看代码:
from functools import partial
import numpy
from skimage import transform EPS = 1e-6
RESOLUTION = 0.001
num_grids = int(1/RESOLUTION+0.5) def generate_lut(img):
"""
linear approximation of CDF & marginal
:param density_img:
:return: lut_y, lut_x
"""
density_img = transform.resize(img, (num_grids, num_grids))
x_accumlation = numpy.sum(density_img, axis=1)
sum_xy = numpy.sum(x_accumlation)
y_cdf_of_accumulated_x = [[0., 0.]]
accumulated = 0
for ir, i in enumerate(range(num_grids-1, -1, -1)):
accumulated += x_accumlation[i]
if accumulated == 0:
y_cdf_of_accumulated_x[0][0] = float(ir+1)/float(num_grids)
elif EPS < accumulated < sum_xy - EPS:
y_cdf_of_accumulated_x.append([float(ir+1)/float(num_grids), accumulated/sum_xy])
else:
break
y_cdf_of_accumulated_x.append([float(ir+1)/float(num_grids), 1.])
y_cdf_of_accumulated_x = numpy.array(y_cdf_of_accumulated_x) x_cdfs = []
for j in range(num_grids):
x_freq = density_img[num_grids-j-1]
sum_x = numpy.sum(x_freq)
x_cdf = [[0., 0.]]
accumulated = 0
for i in range(num_grids):
accumulated += x_freq[i]
if accumulated == 0:
x_cdf[0][0] = float(i+1) / float(num_grids)
elif EPS < accumulated < sum_xy - EPS:
x_cdf.append([float(i+1)/float(num_grids), accumulated/sum_x])
else:
break
x_cdf.append([float(i+1)/float(num_grids), 1.])
if accumulated > EPS:
x_cdf = numpy.array(x_cdf)
x_cdfs.append(x_cdf)
else:
x_cdfs.append(None) y_lut = partial(numpy.interp, xp=y_cdf_of_accumulated_x[:, 1], fp=y_cdf_of_accumulated_x[:, 0])
x_luts = [partial(numpy.interp, xp=x_cdfs[i][:, 1], fp=x_cdfs[i][:, 0]) if x_cdfs[i] is not None else None for i in range(num_grids)] return y_lut, x_luts def sample_2d(lut, N):
y_lut, x_luts = lut
u_rv = numpy.random.random((N, 2))
samples = numpy.zeros(u_rv.shape)
for i, (x, y) in enumerate(u_rv):
ys = y_lut(y)
x_bin = int(ys/RESOLUTION)
xs = x_luts[x_bin](x)
samples[i][0] = xs
samples[i][1] = ys return samples if __name__ == '__main__':
from skimage import io
density_img = io.imread('batman.jpg', True)
lut_2d = generate_lut(density_img)
samples = sample_2d(lut_2d, 10000) from matplotlib import pyplot
fig, (ax0, ax1) = pyplot.subplots(ncols=2, figsize=(9, 4))
fig.canvas.set_window_title('Test 2D Sampling')
ax0.imshow(density_img, cmap='gray')
ax0.xaxis.set_major_locator(pyplot.NullLocator())
ax0.yaxis.set_major_locator(pyplot.NullLocator()) ax1.axis('equal')
ax1.axis([0, 1, 0, 1])
ax1.plot(samples[:, 0], samples[:, 1], 'k,')
pyplot.show()
二维GAN的小例子
虽然网上到处都有,这里还是贴一下GAN的公式:
就是一个你追我赶的零和博弈,这在Dev Nag的代码里体现得很清晰:判别网络训一拨,然后生成网络训一拨,不断往复。按照上节所述,本文例子在Dev Nag代码的基础上,把判别网络每次接受一个batch作为输入的方式变成了:每次接受一个二维样本,通过每个batch的多个样本计算loss。GAN部分的训练代码如下:
DIMENSION = 2 ... generator = SimpleMLP(input_size=z_dim, hidden_size=args.g_hidden_size, output_size=DIMENSION)
discriminator = SimpleMLP(input_size=DIMENSION, hidden_size=args.d_hidden_size, output_size=1) ... for train_iter in range(args.iterations):
for d_index in range(args.d_steps):
# 1. Train D on real+fake
discriminator.zero_grad() # 1A: Train D on real
real_samples = sample_2d(lut_2d, bs)
d_real_data = Variable(torch.Tensor(real_samples))
d_real_decision = discriminator(d_real_data)
labels = Variable(torch.ones(bs))
d_real_loss = criterion(d_real_decision, labels) # ones = true # 1B: Train D on fake
latent_samples = torch.randn(bs, z_dim)
d_gen_input = Variable(latent_samples)
d_fake_data = generator(d_gen_input).detach() # detach to avoid training G on these labels
d_fake_decision = discriminator(d_fake_data)
labels = Variable(torch.zeros(bs))
d_fake_loss = criterion(d_fake_decision, labels) # zeros = fake d_loss = d_real_loss + d_fake_loss
d_loss.backward() d_optimizer.step() # Only optimizes D's parameters; changes based on stored gradients from backward() for g_index in range(args.g_steps):
# 2. Train G on D's response (but DO NOT train D on these labels)
generator.zero_grad() latent_samples = torch.randn(bs, z_dim)
g_gen_input = Variable(latent_samples)
g_fake_data = generator(g_gen_input)
g_fake_decision = discriminator(g_fake_data)
labels = Variable(torch.ones(bs))
g_loss = criterion(g_fake_decision, labels) # we want to fool, so pretend it's all genuine g_loss.backward()
g_optimizer.step() # Only optimizes G's parameters ... ...
和Dev Nag的版本比起来除了上面提到的判别网络,和样本维度的修改,还加了可视化方便直观演示和理解,比如用一个二维高斯分布产生一个折线形状的分布,执行:
python gan_demo.py inputs/zig.jpg
训练过程的可视化如下:
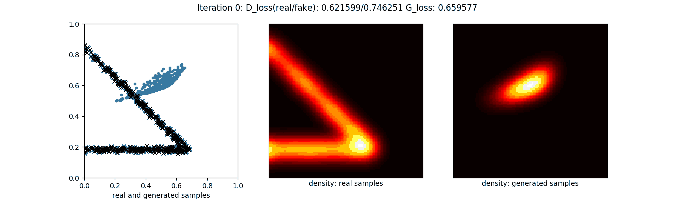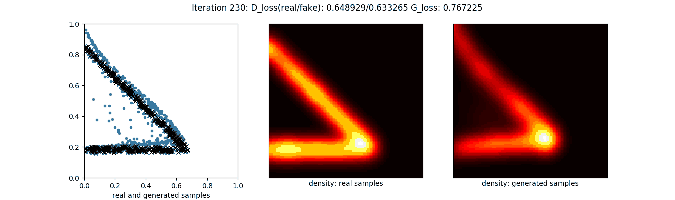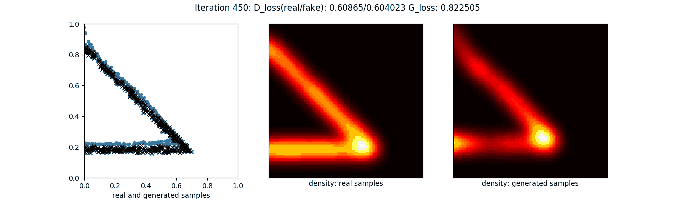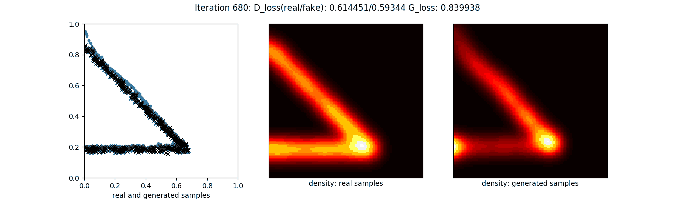
更多可视化例子可以参考这里。
Conditional GAN
对于一些复杂的分布,原始的GAN就会很吃力,比如用一个二维高斯分布产生两坨圆形的分布:

因为latent space的分布就是一坨二维的样本,所以即使模型有很强的非线性,也难以把这个分布“切开”并变换成两个很好的圆形分布。因此在上面的动图里能看到生成的两坨样本中间总是有一些残存的样本,像是两个天体在交换物质。要改进这种情况,比较直接的想法是增加模型复杂度,或是提高latent space维度。也许模型可以学习到用其中部分维度产生一个圆形,用另一部分维度产生另一个圆形。不过我自己试了下,效果都不好。
其实这个例子人眼一看就知道是两个分布在一个图里,假设我们已经知道这个信息,那么生成依据的就是个条件概率。把这个条件加到GAN里,就是Conditional GAN,公式如下:
示意图如下:
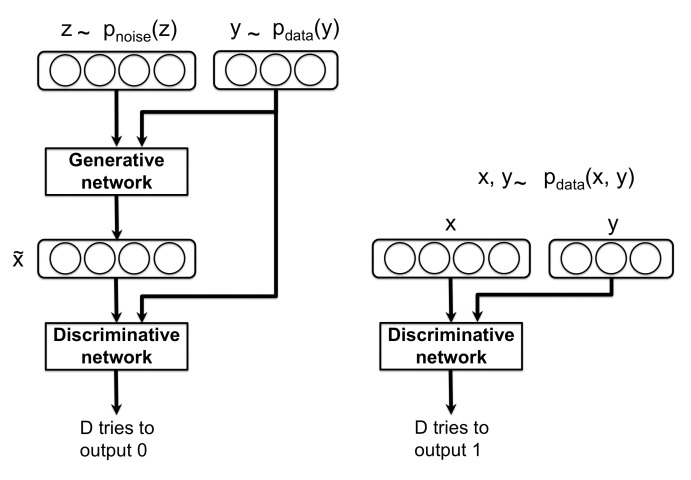
条件信息变相降低了生成样本的难度,生成的样本效果好很多。
在网络中加入条件的方式没有固定的原则,这里我们采用的是可能最常见的方法:用one-hot方式将条件编码成一个向量,然后和原始的输入拼一下。注意对于判别网络和生成网络都要这么做,所以上面公式和C-GAN原文简化过度的公式比起来多了两个y,避免造成迷惑。
C-GAN的代码实现就是GAN的版本基础上,利用pytorch的torch.cat()对条件和输入进行拼接。其中条件的输入就是多张图片,每张定义一部分分布的PDF。比如对于上面两坨分布的例子,就拆成两张图像来定义PDF:
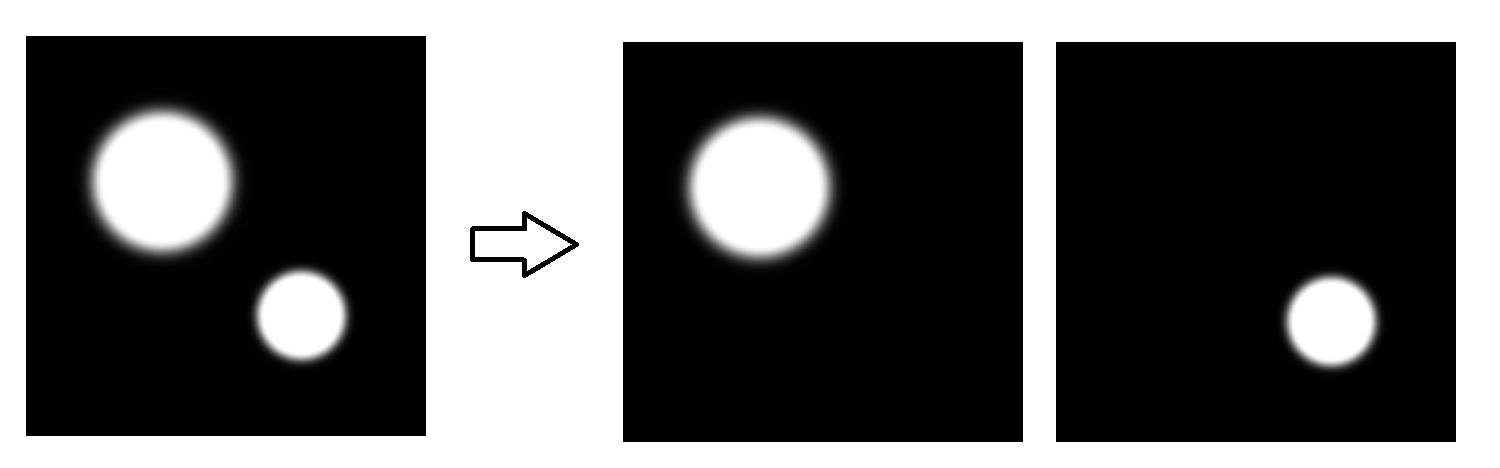
具体实现就不贴这里了,参考本文的Github页面。加入条件信息后,两坨分布的生成就轻松搞定了,执行:
python cgan_demo.py inputs/binary
得到下面的训练过程可视化:
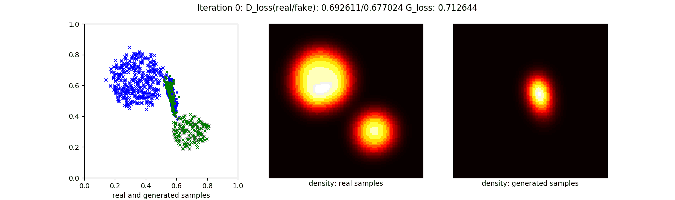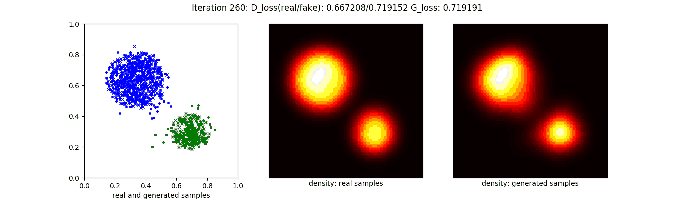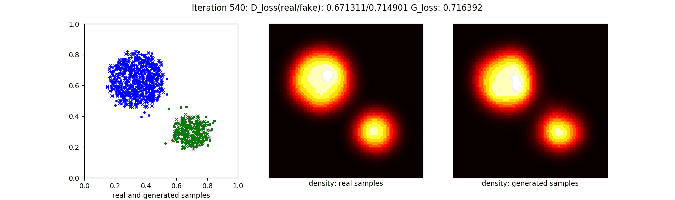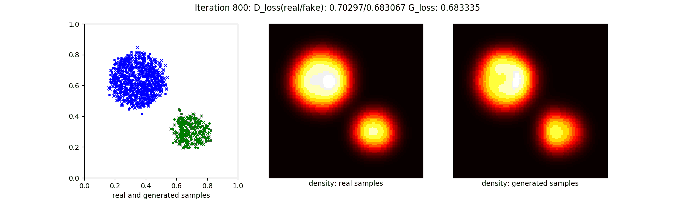
对于一些更复杂的分布也不在话下,比如:

这两个图案对应的原始GAN和C-GAN的训练可视化对比可以在这里看到。
下期预告
其实现在能见到的基于GAN的有意思应用基本都是Conditional GAN,下篇打算介绍基于C-GAN的一个实(dan)用(teng)例子:
1) 利用GAN去除(爱情)动作片中的码赛克。
用GAN生成二维样本的小例子的更多相关文章
- 【C#/WPF】.Net生成二维码QRCode的工具
先马 http://qrcodenet.codeplex.com/ 使用该工具WPF生成二维码的简单例子: 前台XAML准备一个Image控件显示二维码. string qrcodeStr = &qu ...
- 微信小程序开发——使用第三方插件生成二维码
需求场景: 小程序中指定页面需要根据列表数据生成多张二维码. 实现方案: 鉴于需要生成多张二维码,可以将生成二维码的功能封装到组件中,直接在页面列表循环中调用就好了.也可以给组件添加slot,在页面调 ...
- 微信小程序之生成二维码
最近项目中涉及到小程序的生成二维码,很是头疼,经过多次摸索,整理出了自己的一些思想方法,如有不足,欢迎指正. 首先完全按照小程序的结构依次填坑. pages--index.wxml <view ...
- java小技术之生成二维码
把我们需要的链接或者内容生成二维码其实是一件非常容易的事情,有很多办法可以实现,这里我们采用JS方法生成. <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTM ...
- 小程序canvas生成二维码图片踩的坑
1:生成临时图片,保证画布被加载以及渲染(即本身不可以 hidden 或是 上级元素不可以 hidden 或是 wx:if 隐藏等) == > 建议:因为 canvas 的组件层级(z-inde ...
- uniapp 微信小程序 生成二维码
使用 tki-qrcode组件 生成二维码(https://www.npmjs.com/package/tki-qrcode) 1.引入 tki-qrcode 下载组件后引入 import tkiQr ...
- 深度学习实践-物体检测-faster-RCNN(原理和部分代码说明) 1.tf.image.resize_and_crop(根据比例取出特征层,进行维度变化) 2.tf.slice(数据切片) 3.x.argsort()(对数据进行排列,返回索引值) 4.np.empty(生成空矩阵) 5.np.meshgrid(生成二维数据) 6.np.where(符合条件的索引) 7.tf.gather取值
1. tf.image.resize_and_crop(net, bbox, 256, [14, 14], name) # 根据bbox的y1,x1,y2,x2获得net中的位置,将其转换为14*1 ...
- Javascript生成二维码(QR)
网络上已经有非常多的二维码编码和解码工具和代码,很多都是服务器端的,也就是说需要一台服务器才能提供二维码的生成.本着对服务器性能的考虑,这种小事情都让服务器去做,感觉对不住服务器,尤其是对于大流量的网 ...
- Python 创建本地服务器环境生成二维码
一. 需求 公司要做一个H5手机端适配页面,因技术问题所以H5是外包的,每次前端给我们源码,我们把源码传到服务器让其他人访问看是否存在bug,这个不是很麻烦吗?有人说,可以让前端在他们的服务器上先托管 ...
随机推荐
- [.NET] 《Effective C#》读书笔记(二)- .NET 资源托管
<Effective C#>读书笔记(二)- .NET 资源托管 简介 续 <Effective C#>读书笔记(一)- C# 语言习惯. .NET 中,GC 会帮助我们管理内 ...
- DirectFB学习笔记二
本篇目的,画一个方框,在方框上画一串字符. 实现步骤:首先创建IDirectFB接口,通过它再创建要显示的表面surface,同时创建字体font,绘制字符必须要设置绘制的字体,否则绘制不成功.然后清 ...
- 大数据及hadoop相关知识介绍
一.大数据的基本概念 1.1什么是大数据 互联网企业是最早收集大数据的行业,最典型的代表就是Google和百度,这两个公司是做搜索引擎的,数量都非常庞大,每天都要去把互联网上的各种各样的网页信息抓取下 ...
- FrameBuffer系列 之 相关结构与结构体
在linux中,fb设备驱动的源码主要在Fb.h (linux2.6.28\include\linux)和Fbmem.c(linux2.6.28\drivers\video)两个文件中,它们是fb设备 ...
- PHP die() 函数
die() 函数输出一条消息,并退出当前脚本. 该函数是 exit() 函数的别名.
- 亲测可用!!!golang如何在idea中保存时自动进行代码格式化
亲测可用,golang在idea中的代码自动格式化 1.ctrl+alt+s打开设置界面,选择[Plugins] -> [Install JetBrains plugin...] -> 搜 ...
- 设计模式的征途—5.原型(Prototype)模式
相信大多数的人都看过<西游记>,对孙悟空拔毛变出小猴子的故事情节应该都很熟悉.孙悟空可以用猴毛根据自己的形象复制出很多跟自己一模一样的小猴兵出来,其实在设计模式中也有一个类似的模式,我们可 ...
- 记录——excel导出lua工具(python实现)
项目需要一个从excel导出lua配置表的工具,之前的工具是主程写的,效率极差,i7 CPU 一次全部导出要花掉1个多小时.匪夷所思的是,这么渣的效率,居然用了整整一年.当 然,中途有人反映效率差,主 ...
- dp
1. 将原问题分解为子问题 2. 确定状态 3. 确定一些初始状态(边界状态)的值 4. 确定状态转移方程 1) 问题具有最优子结构性质.如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具 ...
- POJ 1007
DNA Sorting Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 83069 Accepted: 33428 Descrip ...