SQL Server内存
背景
最近一个客户找到我说是所有的SQL Server 服务器的内存都被用光了,然后截图给我看了一台服务器的任务管理器。如图
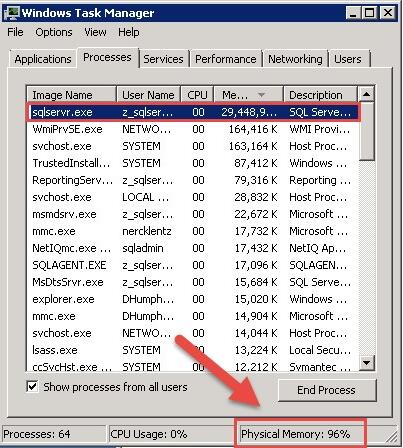
这里要说明一下任务管理器不会完整的告诉真的内存或者CPU的使用情况,也就是说这里只能得到非精确的信息,有可能就是一个假警报。
为了让我的客户放心,我检查了服务器并且查看了很多性能指标。我所看到的就是CPU和硬盘使用都是很低的只有内存是高的,这恰恰是我们期望的SQLServer 服务器的状态。SQL Server会尽可能的使用内存,通过缓存尽可能多的磁盘来改善性能。当然如果OS需要它也会立即释放资源回来。
SQL Server 对内存是“贪得无厌”的,它会持有所有分配给它的内存,不论是否使用。而这也是我们想要它去做的。因为它会存储数据和执行计划在缓存中,然后当使用完这些内存时,它不会释放这些内存,缓存到内存中,除非两种情况才会释放缓存的数据内存:1) SQL Server 重启或者内存不足 2) 操作系统需要内存
默认的内存设定就是使用所有内存(安装时设置),当操作系统需要内存时,它也会大量释放内存。然后等到有内存时在重新大量持有。但是这种不是最佳实践,最好还是设定一个最大内存限制,这样操作系统就会保证一定量的内存永远为SQL Server 使用。
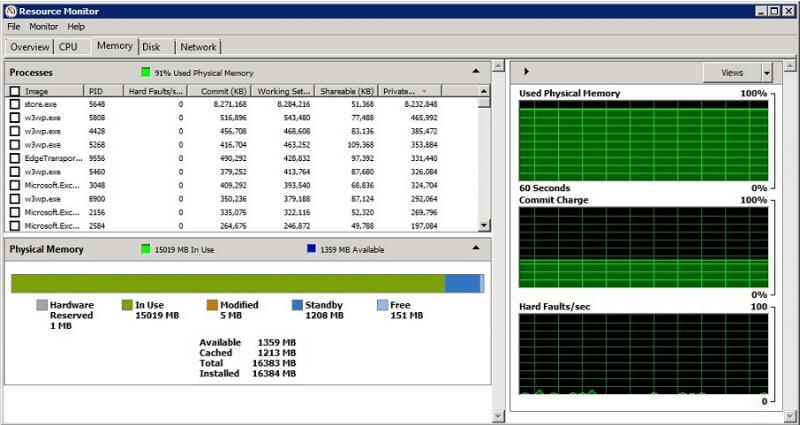
当看到资源管理器,Available MB 的内存有两部分组成Standby--备用和Free--可用,这Standby 的空间系统已经把它缓存了,而Free的内存意味着没有被使用。它们都叫做可利用内存。因此针对一开始那个客户担忧我们大可不必太担心。当然我们还需要健康其他的性能计数器,查明是否存在内存影响性能的隐患。需要关注的指标如下:
- Page Life Expectancy
- Available Bytes
- Buffer Cache Hit Ratio
- Target & Total Server Memory
- Memory Grants Pending
- Pages/sec (Hard Page Faults)
- Batch Requests/sec & Compilations/sec
介绍下这些性能参数:
Page Life Expectancy (PLE)
这个性能计数器记录了数据页(非锁定)在缓冲池中的平均时间。在生产高峰这个数值可能比较低,但是一般要保持这个数据在300s以上,数据待在缓冲中时间越长,那么SQL的IO操作越少。
如果长期这个数值在300s以下,可以考虑增加内存,当然由于现在内存越来越大,这个值也变得不那么重要了,但是对于中小系统依然可以作为一个标准阈值。
由于这个阈值基于32位系统的4G内存,那么标准算法可以大致可以推算:内存大小(GB)/4*300。
也可以使用下面的语句来查询该计数器:
SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%Buffer Manager%' AND [counter_name] = 'Page life expectancy'
Available MBytes
该计数器监测还有多少可用内存,是否操作系统存在内存压力。一般我们调查是否这个计数器持续在500MB以下,这说明内存过低。如果持续低于500则说明你需要增加更多的内存。
这个计数器不能通过T-SQL查询,只能通过性能监视器观察。
Buffer Cache Hit Ratio
缓冲命中率,这个计数器记录平均多少频率从缓冲池中取得数据。我们在OLTP数据库中一般这个比率是90%-95%(该数值经由@MSSQL123 指出发现是错误的,再次进行修改)。由于sqlserver 把预读也作为缓冲比例,所以导致该值很高,所以该计数器只做理解,不能作为真实性能瓶颈参考了。如果该计数器持续低于90%,则需要增加内存。
在可以使用下面的T-SQL语句查询:
SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%Buffer Manager%' AND [counter_name] = 'Buffer cache hit ratio'
Target & Total Server Memory
服务器当前总内存(buffer)以及目标内存,在缓冲池初始化增加内存的时候,总内存会比目标内存稍低一点。这个比例会逐渐接近1,如果总内存没有增长很快,就会显著低于目标内存,这就表示如下两点:
1) 你可以分配尽可能多的内存,SQL能缓存整个数据库到内存中,然后如果数据库小于机器内存,内存不会完全用光,在这种情况下,总内存将永远小于目标内存。
2) SQL不能增加缓冲池,比如系统内存有压力。如果这种情况你需要增加最大服务器内存,或者增加内存来改善性能。
SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%Memory Manager%' AND [counter_name] IN ('Total Server Memory (KB)','Target Server Memory (KB)')
Memory Grants Pending
这个计数器测量等待内存授予的SQL的进程数量。一般推荐阈值为1或者更少。如果大于1这说明内存不足按顺序等待内存释放再操作SQL。
一般工作中出现这种等待可能是由于糟糕的查询,缺失索引,排序或者哈希引起的。为了查明原因可以查询DMV --sys.dm_exec_query_memory_grants 这个视图,将会展示哪一个查询需要内存授予执行。
如果不是以上原因引起的内存等待,则需要增加内存来解决这个问题。此时就有理由增加硬件了。查询的T-SQL语句如下:
SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%Memory Manager%' AND [counter_name] = 'Memory Grants Pending'
Pages/sec (Hard Page Faults)
这里也使用数据库级别计数器:当需要读取或写入的页不在内存中,需要到磁盘中读取时计数。这个计数器是一个记录读和写的总和并且不能直接在内存中获取只能从因盘中读取(导致resulting in hard page faults),这个问题是由于操作系统必须交换文件在磁盘上,当访问内存时,内存不足则需要交换文件到磁盘上,由于磁盘读写速度远低于内存,性能就会受到严重影响。
对于这个计数器,推荐阈值为<50(或者某个稳定值),如果看到高于这个值,不过需要注意,只要这个值能够稳定在一个较低的水平,没有持续性的大批量数据的写入(磁盘)于读取(从磁盘载入内存),都可以接受。相反,如果长期在一个高位水平,并且观察到PLE不能稳定在参考值范围内,说明内存可能存在瓶颈。当然,如果数据库备份或者还原,包括导出、导入数据以及内存中映射文件等等这些也会导致性能计数器超出某个稳定值。
Batch Request & Compilations
该计数器包含两个检查
- SQL Server: SQL Statistics – Batch Request/Sec. 传入查询的数量(批处理数量)
- SQL Server: SQL Statistics - Compilations/Sec. 新建立的执行计划数量
如果Compilations/sec是25%或者相对Batch Requests/sec更高,则执行计划将被放到缓存中,但是永远不会重用执行计划。宝贵的内存就被浪费了,而不是缓存数据。这是糟糕的实践,我们要做的就是阻止这种情况,
如果Compilation/sec 很高比如100,表示有大量的即席查询正在运行。这时可以启用“optimize for ad hoc”把执行计划缓存,但是只有在第二次查询时才能被使用。
使用如下T-SQL可以得到相应的指标:
SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%SQL Statistics%' AND [counter_name] = 'Batch Requests/sec'; SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%SQL Statistics%' AND [counter_name] = 'SQL Compilations/sec';
同样可以获得比率:
SELECT ROUND (100.0 * (SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%SQL Statistics%' AND [counter_name] = 'SQL Compilations/sec') / (SELECT [cntr_value] FROM sys.dm_os_performance_counters WHERE [object_name] LIKE '%SQL Statistics%' AND [counter_name] = 'Batch Requests/sec') ,) as [Ratio]
关于如何设定数据库可用的内存最大值,如图所示:

推荐阈值:一般来说,我都是采用10%用于操作系统其它90%分配给数据库。当然如果内存很大可以调整这个比例小于1/9,对于内存较小的通常我都预留4-6G左右给操作系统。
我们看一下实际例子:
在性能监视器中看一下这个计数器,我们可以看到这个服务器处于健康状态下,有11GB的可用空间,没有PageFaults(I/O只从缓存中没有交换到磁盘),缓冲的比率为100%,PLE超过20000s,没有内存等待,充足的总内存和较低的编译比率(编译数/查询数).
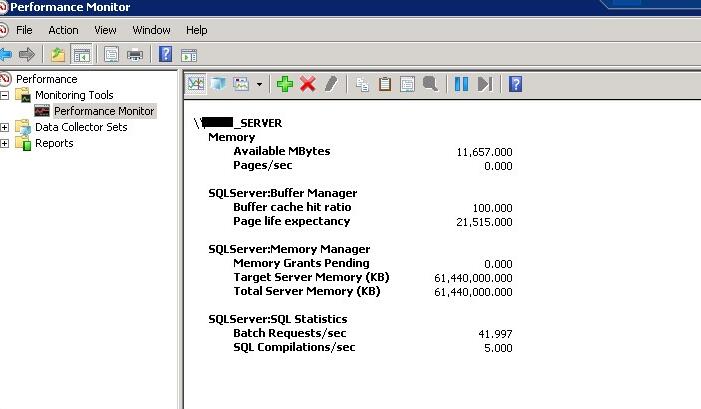
这个测量数据很容易理解,这要比任务管理器更具有作用,能依据此做出判断是否有足够的内存在这台SQL Server服务器上。
总结
如果只根据任务管理器来做出判断,我们很容易出现错误决定。因为不管系统多少内存,SQL Server 会尽可能的使用占用内存,这不是bug。缓存数据在内存中有很好的效果,意味着服务器是健康的,也为用户提供了更好的执行效率。在实际数据库环境中,一般突然遇到的性能问题多半是因为T-SQL语句引起的,就如我前面提到糟糕的查询(缺失索引、排序、哈希等等),这个时候通过语句优化可以很好的解决突发问题,这里就不详解了。如果服务器普遍存在文章中出现的内存性能计数器问题,那就写报告提交内存增加需求吧。
SQL Server内存的更多相关文章
- SQL Server内存遭遇操作系统进程压榨案例
场景: 最近一台DB服务器偶尔出现CPU报警,我的邮件报警阈(请读yù)值设置的是15%,开始时没当回事,以为是有什么统计类的查询,后来越来越频繁. 探索: 我决定来查一下,究竟是什么在作怪,我排查的 ...
- Sql Server 内存相关计数器以及内存压力诊断
在数据库服务器中,内存是数据库对外提供服务最重要的资源之一, 不仅仅是Sql Server,包括其他数据库,比如Oracle,MySQL等,都是一类非常喜欢内存的应用. 在Sql Server服务器中 ...
- SQL SERVER 内存学习系列(二)-DMV查看内存信息
内存管理在SQL Server中有一个三级结构.底部是内存节点,这是最低级的分配器,用于SQL Server的内存.第二个层次是由内存Clerk组成,这是用来访问内存节点和缓存存储,缓存存储则用于缓存 ...
- SQL SERVER 内存学习系列(一)
最近帮客户解决发布订阅的问题时,突然遇到这样一个问题发布订阅中报下面的错误,另外执行alter table 操作时也会报错 : 问题很奇怪发布订阅和CLR有什么关系?memtoleave内存是个啥?回 ...
- 人人都是 DBA(IV)SQL Server 内存管理
SQL Server 的内存管理是一个庞大的主题,涉及特别多的概念和技术,例如常见的 Plan Cache.Buffer Pool.Memory Clerks 等.本文仅是管中窥豹,描述常见的内存管理 ...
- SQL Server内存理解的误区
SQL Server内存理解 内存的读写速度要远远大于磁盘,对于数据库而言,会充分利用内存的这种优势,将数据尽可能多地从磁盘缓存到内存中,从而使数据库可以直接从内存中读写数据,减少对机械磁盘的IO请求 ...
- SQL SERVER 内存分配及常见内存问题 DMV查询
内存动态管理视图(DMV): 从sys.dm_os_memory_clerks开始. SELECT [type] , SUM(virtual_memory_reserved_kb) AS [VM R ...
- SQL SERVER 内存分配及常见内存问题 简介
一.问题: 1.SQL Server 所占用内存数量从启动以后就不断地增加: 首先,作为成熟的产品,内存溢出的机会微乎其微.对此要了解SQL SERVER与windows是如何协调.共享内存.并且SQ ...
- SQL Server 内存中OLTP内部机制概述(四)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
随机推荐
- 【html】 a 标签
摘要 嗷呜,发现好多前端细节,基础不扎实啊,喵了个咪 target 属性 在制定框架中打开 <a href="a.html" target="view_frame& ...
- taskctl实现自定义mysql存储过程作业类型调用
TASKCTL支持任意作业类型的扩展,但目前TASKCTL 4.1.3版本中并没有内置mysql存储过程的作业插件.通过介绍使TASKCTL支持调度mysql存储过程作业类型的步骤,一方面解决一些朋友 ...
- Oracle 12C 新特性 - “可插拔数据库”功能
Oracle 12C加入了一个非常有新意的功能"可插拔数据库"特性,实现了数据库(PDB)在"容器"(CDB)上的拔功能,既能提高系统资源的利用率,也简化大面积 ...
- springboot启动时报错No session repository could be auto-configured.....
具体异常提示: Error starting ApplicationContext. To display the auto-configuration report re-run your appl ...
- ES6学习目录
前面的话 ES6是JavaScript语言的下一代标准,已经在 2015 年 6 月正式发布.它的目标,是使得 JavaScript 语言可以用来编写复杂的大型应用程序,成为企业级开发语言 为什么要学 ...
- Codeforces 828B Black Square(简单题)
Codeforces 828B Black Square(简单题) Description Polycarp has a checkered sheet of paper of size n × m. ...
- React Native 系列(五) -- 组件间传值
前言 本系列是基于React Native版本号0.44.3写的.任何一款 App 都有界面之间数据传递的这个步骤的,那么在RN中,组件间是怎么传值的呢?这篇文章将介绍到顺传.逆传已经通过通知传值. ...
- kickstart文件详解
kickstart自动应答文件选项非常多,以下只说明CentOS 6下几个常用的可能用到的选项.另外,CentOS 6和CentOS 7的选项有不小区别,所以请注意使用,可以查看官方安装文档. Cen ...
- box-sizing 属性应用
1.box-sizing属性功能 官方说明文档为:http://www.w3school.com.cn/cssref/pr_box-sizing.asp box-sizing 属性允许您以特定的方式定 ...
- 乐卡上海网点地图制作心得 | 百度地图API使用心得
前言 事情的起因是我的爱人喜欢收集一些美丽的乐卡(明信片的一种,正面是美丽壮阔的风景照).作为一个坚实的后盾自然要支持她!于是我经常借着午休穿梭在大街小巷,凭借乐卡官方提供的乐卡网点地址进行寻找并取卡 ...