MongoDB聚合(count、distinct、group、MapReduce)
1. count:返回集合中文档的数量。
db.friend.count()
db.friend.count({'age':24})
增加查询条件会使count查询变慢。
2. distinct:找出给定键的所有不同的值。
使用时必须指定集合和键:
db.runCommand({'distinct':'friend','key':'age'})
3. group:分组统计。
示例:找出相同年龄(age)中,积分(score)最高的人。

参数说明:
ns:指定要进行分组的集合。
key:指定文档分组依据的键,键值相同的所有文档分为一组。
initial:每一组reduce函数调用时作为第二个参数传递给reduce函数的初始文档,每一组的所有成员都会
使用这个累加器,所以改变会被保留住。
$reduce:每个文档都对应一次这个调用,两个参数分别是当前文档和累加器文档(本组当前的结果)。
每一组都有一个独立的累加器存储本分组的结果。
condition:只处理满足条件的文档。
finalize:函数,完成器,在每组结果传递到客户端之前被调用一次,用以精简从数据库传到用户的数据。
例如,在上面的例子中可以在group中加入finalize参数来去除结果中的’age’键:
‘finalize’: function(prev) {
delete prev.age;
}
(参数prev是每个分组结果文档)
$keyf:将函数作为键使用,用作分组依据。当分组依据变得复杂,不再只是一个简单的键值那么简单的时候,
’key’参数已经无法满足需求,此时可以使用’$keyf’参数,它可以依据各种复杂的条件进行分组。
使用场景之一:依据分组键值进行分组,但忽略大小写。
‘$keyf’: function(x) {
return {‘name’:x.name.toLowerCase()};
}
(参数x表示当前文档对象,返回值一定要是一个对象,对象的键即是分组键。group中不能同时包含key参数和$keyf参数)
注意:分组依据键不存在的文档会被分到一组,并显示键值为null,可以在condition参数中加入{‘$exists’:true}来去掉这一组。
4. MapReduce:
使用MapReduce的代价就是速度慢,不能用在“实时”环境中。要作为后台任务来运行MapReduce,创建一个
保存结果的集合,然后对这个集合进行实时查询。
示例:找出集合中的所有键。
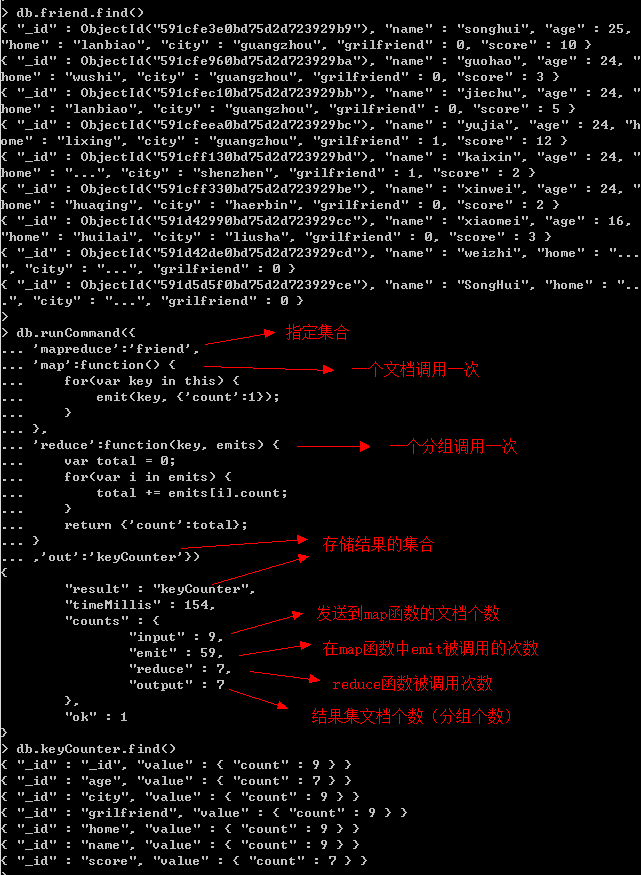
参数说明:
mapreduce:字符串,指定需要进行MapReduce操作的集合的名称。
map:函数,分组函数,将集合中的文档根据某个键的值进行分组(一个文档调用一次)。
reduce:函数,每个分组的处理函数(一个分组调用一次)。
在以上例子中,执行完map函数之后,传递给reduce函数的参数格式类似:key为’age’,
emits为[{‘count’:1},{‘count’:1},{‘count’:1}...]。
最终产生的结果集中”_id”键值为分组key的键值,”value”则是reduce函数返回的内容,目前reduce函数
不支持返回数组,会报错:multiple not supported yet。
finalize:函数,处理reduce调用之后产生的结果,MapReduce的最后一步(一般用于清除多余信息)。
keeptemp:布尔,连接关闭时临时结果集合是否保存。
out:字符串,结果集名称,设置该项则隐含着keeptemp:true。
不指定’out’参数会报错:’out’ has to be a string or an object。
query:文档,发往map函数前先使用指定条件过滤文档。
sort:文档,发往map函数前先给文档排序。
limit:整数,发往map函数的文档数量的上限。
scope:文档,JavaScript代码中要用到的变量。
scope是MapReduce的作用域键,可以使用“变量名:值”这样的普通文档来设置该选项,然后在map、reduce和
finalize函数中就能使用了。
verbose:布尔,是否产生更加详细的服务器日志。(查看MapReduce的运行过程,也可以用print把map、reduce、
finalize过程中的信息输出到服务器日志上。)
每个传递给map函数的文档都要事先反序列化,从BSON转换成JavaScript对象,这个过程非常耗资源。要是事先能
确定只对集合的一部分文档执行MapReduce,使用query、sort、limit来增加一层过滤层会极大地提高速度。
可以在MapReduce操作产生的结果集合上再进行MapReduce操作!
Group的结果集有4MB的大小限制,MapReduce则没有这个限制。
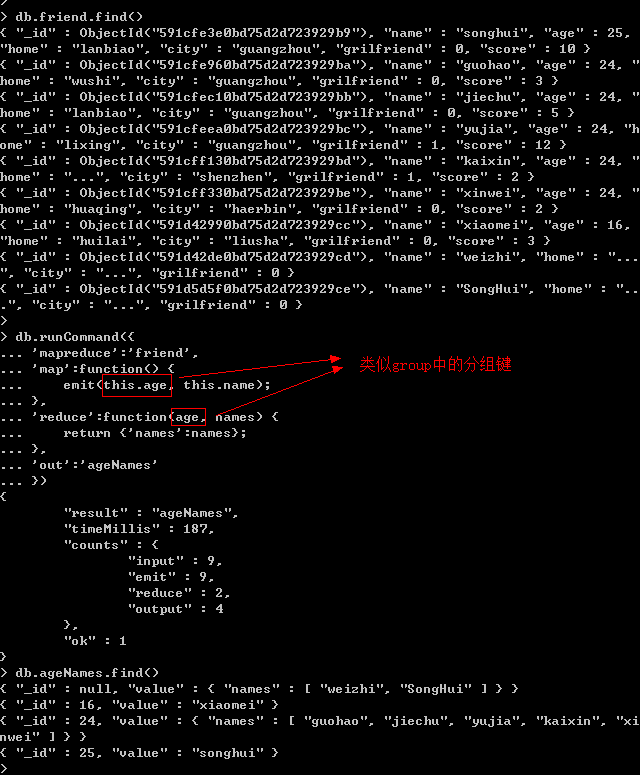
group和MapReduce对比示例:查询相同年龄人的名字。
(1)group:

(2)MapReduce:
MongoDB聚合(count、distinct、group、MapReduce)的更多相关文章
- MongoDB count distinct group by JavaAPI查询
import java.net.UnknownHostException; import com.mongodb.BasicDBList; import com.mongodb.BasicDBObje ...
- MongoDB聚合运算之group和aggregate聚集框架简单聚合(10)
聚合运算之group 语法: db.collection.group( { key:{key1:1,key2:1}, cond:{}, reduce: function(curr,result) { ...
- MongoDB 聚合函数
概念 聚合函数是对一组值执行计算并返回单一的值 主要的聚合函数 count distinct Group MapReduce 1.count db.users.count() db.users.cou ...
- ElasticSearch中"distinct","count"和"group by"的实现
最近在业务中需要使用ES来进行数据查询,在某些场景下需要对数据进行去重,以及去重后的统计.为了方便大家理解,特意从SQL角度,方便大家能够理解ES查询语句. 1 - distinct ; { &quo ...
- MongoDB 聚合 (转) 仅限于C++开发
MongoDB除了基本的查询功能,还提供了很多强大的聚合工具,其中简单的可计算集合中的文档个数, 复杂的可利用MapReduce做复杂数据分析. 1.count count返回集合中的文档数量 db. ...
- MongoDB学习笔记——聚合操作之group,distinct,count
单独的聚合命令(group,distinct,count) 单独聚合命令 比aggregate性能低,比Map-reduce灵活度低:但是可以节省几行javascript代码,后面那句话我自己加的,哈 ...
- mongodb MongoDB 聚合 group
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- mongodb MongoDB 聚合 group(转)
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- mongodb聚合 group
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.collection.agg ...
随机推荐
- dbda数据库类
<?phpclass DBDA{ public $host="localhost";//服务器地址 public $uid="root";//用户名 pu ...
- Java: 类继承中 super关键字
super 关键字的作用有两个: 1)在子类中调用超类的构造器,完成实例域参数的初始化,调用构造器的语句只能作为另一个构造器(通常指的是子类构造器)的第一条语句出现, 2)在子类中调用超类的方法,如: ...
- postman: 用于网页调试和发送Http请求的chrome插件
一 简介 Postman 是一款功能超级强大的用于发送 HTTP 请求的 Chrome插件 .做web页面开发和测试的人员应该是无人不晓无人不用!其主要特点 特点: 创建 + 测试:创建和发送任何的H ...
- delphi cxrid设置column靠左显示
1.双击cxgrid控件,选中要设置的column 2.找到properties,将column设置为Textedit,点击左边的加号 3.点击ALignment->Horz选中taleftJu ...
- [01] Java语言的基本认识
0.写在前面的话 我们都知道在计算机的底层,它是识别二进制的,也就是说,计算机只能认识0和1.这主要是因为电路的逻辑只有两种状态,所以只需要0和1两个数字就可以表示低电平和高电平.而计算机是由数不清的 ...
- jQuery基礎知識
jQuery基礎知識 $(function(){}) //jQuery先執行一遍再執行其他函數 $(document).ready(fn) //文檔加載完後觸發 1. 刪除$:jQuery.noCon ...
- ACM学习之路___HDU 5723(kruskal + dfs)
Abandoned country Time Limit: / MS (Java/Others) Memory Limit: / K (Java/Others) Total Submission(s) ...
- 静态页面如何实现 include 引入公用代码
一直以来,我司的前端都是用 php 的 include 函数来实现引入 header .footer 这些公用代码的,就像下面这样: <!-- index.php --> <!DOC ...
- PHP中isset和empty的区别(最后总结)
PHP的isset()函数 一般用来检测变量是否设置 格式:bool isset ( mixed var [, mixed var [, ...]] ) 功能:检测变量是否设置 返回值: 若变量不存在 ...
- util包里的一些类的使用
好几天没有更新我的博客了 .国庆放假出去玩了一趟,这回来应该收心回到我的事业上了,哈哈哈!废话不多说,开始学习吧!首先今天来学习一些例子,这些例子可以回顾假期遗忘的知识,还能提高自己的能力.程序也会相 ...