手把手视频:万能开源Hawk抓取动态网站
Hawk是沙漠之鹰历时五年开发的开源免费网页抓取工具(爬虫),无需编程,全部可视化。
自从上次发布Hawk 2.0过了小半年,可是还是有不少朋友通过邮件或者微信的方式询问如何使用。看文档还是不如视频教学方便,沙漠君决定录播几段视频来帮助大家~
软件最新的下载地址(或点击原文)

下面是视频内容,在腾讯视频可以开启高清,实测清晰度尚可,当然你也可以在百度云盘中下载以下全部视频。
http://pan.baidu.com/s/1dE5D40h
1. 使用Hawk抓取百度百家新闻
这是抓取百度百家新闻(http://baijia.baidu.com/)完整的例子,你可以了解到:
- 如何抓取动态页面和超级模式
- 如何获取网页正文信息
- 如何导出抓取的数据
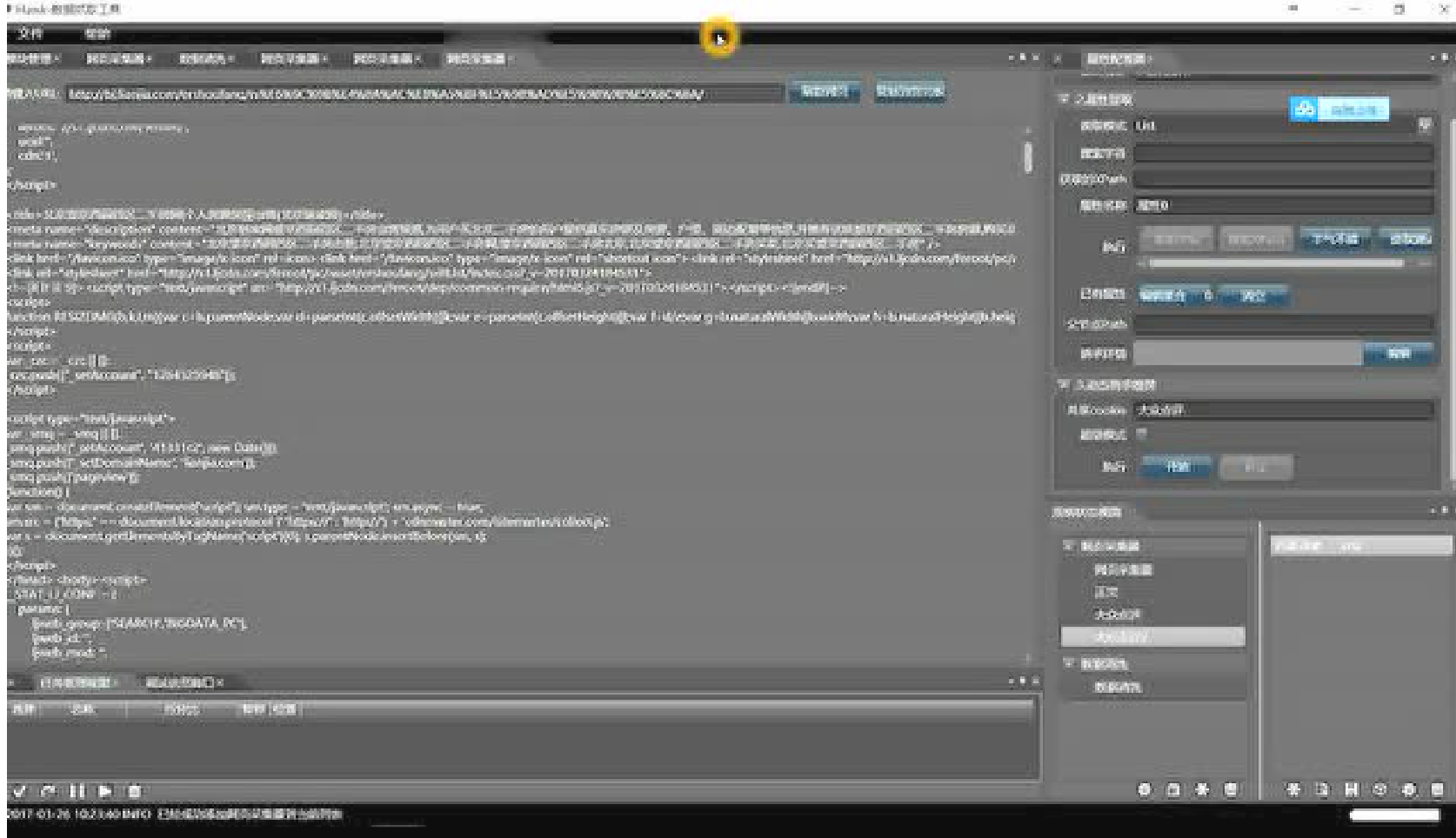
内置的播放器无法调节清晰度。可在PC访问:
2. Hawk答疑
这是一个综述,对大家感兴趣的话题答疑解惑,包括:
- 如何使用手气不错(相比1.0版本优化很多)
- 文档在哪里?
- 如何连接数据库
- 其他一些使用上的问题
可在PC访问:
3. 历史视频
这些视频都是针对1.0在2016年上半年录制的,由于网站改版,或增加了防爬虫(如链家),因此在使用上会有较大区别,仅供各位用户参考。
抓取链家(目前链家防爬虫非常严格,视频仅供参考)
大众点评(没想到播放量高达8.3W)
获取最近地铁站(Hawk的功能可不局限于爬虫)
4. 如何下载工程案例
Hawk本身提供了一系列例子(虽然基本都是2016年上半年的),不少已经过期了。
有些朋友直接用“右键另存为”下载,这样保存的是html页面,有两种方法可以下载:
如果你会用git, 在shell里直接执行
git clone git@github.com:ferventdesert/Hawk-Projects.git
手动下载整个文件夹: 在首页上Download ZIP
4. 欢迎共同改进Hawk
为什么要重提再度改进Hawk呢?
- 高不成低不就: 因为如果一件好用的工具分数是0.8的话,Hawk正好在0.74,因为一些其实很简单的问题,用户就卡在那里无从下手。
- 可用性/UI设计急需提高: 特别需要懂产品/UI的朋友一起协助
- 软件依然有不少bugs
- etlpy(Python版本的Hawk)开发虽完成,但有相当陡峭的学习曲线
万里长征走了9500里,却在最后的一段路上止步不前,给世人留下一个半吊子,终究是不好的。所以2017年一个重要的任务便是进一步完善它,走完剩下的500里。
因此,如果你对Hawk,爬虫或是软件设计感兴趣的话,可以考虑和沙漠君一起改进它。只要你有任何靠谱的建议,都可以告诉我,我会集中起来一起改进。也许你可能获得不了什么经济上的补偿(沙漠君也没有),但总比网络上各种野路子收费软件强很多。我们做了一件能帮助几十万甚至百万人的事情。
虽然工作非常忙,因此各种回复不及时,不过有任何问题依然可以给我发邮件:
最后祝使用Hawk愉快!
手把手视频:万能开源Hawk抓取动态网站的更多相关文章
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- 使用scrapy-selenium, chrome-headless抓取动态网页
在使用scrapy抓取网页时, 如果遇到使用js动态渲染的页面, 将无法提取到在浏览器中看到的内容. 针对这个问题scrapy官方给出的方案是scrapy-selenium, 这是一个把sel ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- java抓取动态生成的网页
最近在做项目的时候有一个需求:从网页面抓取数据,要求是首先抓取整个网页的html源码(后期更新要使用到).刚开始一看这个简单,然后就稀里哗啦的敲起了代码(在这之前使用过Hadoop平台的分布式爬虫框架 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- 用php实现一个简单的爬虫,抓取电影网站的视频下载地址
昨天没什么事,先看一下电影,就用php写了一个爬虫在视频网站上进行视频下载地址的抓取,这里总结一下抓取过程中遇到的问题 1:通过访问浏览器来执行php脚本这种访问方式其实并不适合用来爬网页,因为要受到 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- Scrapy笔记12- 抓取动态网站
Scrapy笔记12- 抓取动态网站 前面我们介绍的都是去抓取静态的网站页面,也就是说我们打开某个链接,它的内容全部呈现出来. 但是如今的互联网大部分的web页面都是动态的,经常逛的网站例如京东.淘宝 ...
随机推荐
- php调去存储过程
第一步,mysql端建存储过程 DELIMITER $$create procedure mintime()beginselect min(year(htime)) as minnian,max(ye ...
- java线程学习(二)
多个线程并发抢占资源是,就会存在线程并发问题,造成实际资源与预期不符合的情况.这个时候需要设置"资源互斥". 1.创建资源,这个地方我创建了一个资源对象threadResource ...
- SpringBoot之旅 -- SpringBoot 项目健康检查与监控
前言 You build it,You run it, 当我们编写的项目上线后,为了能第一时间知晓该项目是否出现问题,常常对项目进行健康检查及一些指标进行监控. Spring Boot-Actuato ...
- 模态Model视图Push下一个视图(混合跳转)
来自: http://www.cnblogs.com/dingding3w/p/6222626.html 如果没有UINavigationController导航栏页面之间切换是不能实现Push操作的 ...
- AVFoundation自定义录制视频
#import <AVFoundation/AVFoundation.h> #import <AssetsLibrary/AssetsLibrary.h> @interface ...
- oracle xe 数据库用户操作
在system账号登录获得system权限,然后对用户进行操作 --创建表空间create tablespace tablespace_name datafile 'D:\tablespace_nam ...
- python 的正则表达式 贪婪模式与懒惰模式
正则表达式中用于表示匹配数量的元字符如下: ? 重复0次或1次,等同于{0,1} * 重复0次或更多次,等同于{0,} + 重复1次或更多次,等同于{1,} {n,} 重复n次及以上 上面的表示匹配次 ...
- mybatis基础学习1---(配置文件和sql语句)
1:配置文件(主要配置文件) 2:配置文件(引入) 3:sql语句解析: <mapper namespace="/"> <!-- 1 -->根据id查对象 ...
- 【iOS】7.4 定位服务->2.1.3.2 定位 - 官方框架CoreLocation 功能2:地理编码和反地理编码
本文并非最终版本,如果想要关注更新或更正的内容请关注文集,联系方式详见文末,如有疏忽和遗漏,欢迎指正. 本文相关目录: ================== 所属文集:[iOS]07 设备工具 === ...
- MVC不用302跳转Action,内部跳转
原理,在一个Action里面return 另一个Action出去. public class HomeController : Controller { // GET: Home public Act ...