无需看到你的脸就能认出你——实现Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
今年年初Facebook AI Research发布了一篇名为Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues的人物识别的文章。
正好公司mentor想搞一个类似的东西看看能不能做一个智能相册出来(有点像iphoto和新版的lightroom里面那个根据人的id来分子相册),于是就实现了一下。
如果只想要代码的话就不用往下看了,请直接点击:https://github.com/sciencefans/Beyond-Frontal-Faces
由于使用了定制的caffe的matlab接口,所以想要跑通需要根据你自己的接口来改一下,还是需要折腾的~
其中feature文件夹下给出了我跑出来的test集上有脸的所有图片的特征向量和labels,可以直接训练svm或者knn跑跑看。
在我的试验中1nn(最邻近)算法居然比svm搞了快10个点。。。
转载请说明转自http://www.cnblogs.com/sciencefans/
整篇文章噱头满满,总结一下有以下贡献:
1.作者从flickr上收集了一个叫People In Photo Albums (PIPA)的数据库,其中:1)标注了人的头的位置,注意是头的位置不是脸的位置;2)有一半的人都是没有脸的;3)包含60000张图,2000多个人;4)数据库分成了三个子库,train,valid和test,互不相交。
具体的一些例子如下:

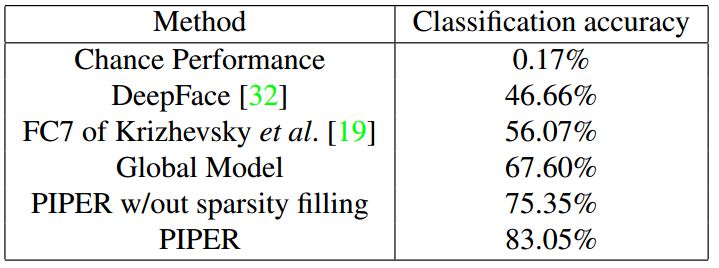
2.文章提出了一个叫Pose Invariant PErson Recognition(PIPER) 的方法,其实就是搞了109个分类器(具体哪109个后面说),用了一个线性分数叠加来做最后的得分,这个model在上述PIPA的test集上得到了83.05%的准确率,如果只看有脸的图片,准确率能够到达93.4%。这个结果超过了deepface(只有89.3%)。
3.想不出有什么别的贡献了。
一句话总结这篇文章就是:提出了一个标注了头部的数据库,想了一种方法线性叠加了109个CNN-SVM模型来获得了一个很好的identify效果。
下面具体来说一说这109个分类器:
109分类器=用人体的107个poselet(详见参考文献2)分别训练出来的107个CNN(这一步是在Imagenet模型上finetune的,并不是直接训练的)+1个global model(用整个身体来训练一个CNN,一样是finetune)+1个基于DeepFace(详见参考文献3)提出的特征的SVM分类器。
这109个分类器都是神经网络的倒数第二层(fc7)作为特征来训练出的SVM。
怎么组合这109个分类器给出的得分呢?首先计算图片的每个poselet的激活程度(得分程度),如果没有激活(得分很低),则使用global model来代替。计算公式如下:
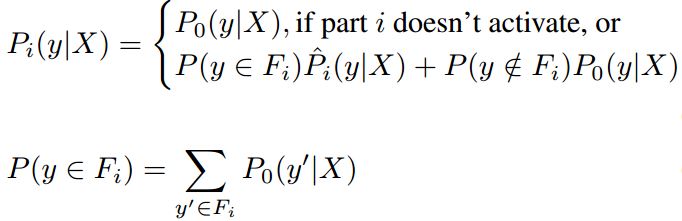
其中Pi就是第i个poselet的svm对X的预测
Fi指的是训练集中拥有第i个poselet的人物的集合,是所有identity的子集。
得到了Pi之后,就可以计算每个分类器的权重w了。
文章使用validation集合来计算得出w,方法还是svm:
对于任意一张图j,它的第i个poselet分类器的得分是

一共有K个poselet分类器的话,一张图就一共有K+1个得分(加上global model)
这样就相当于一个图可以用一个K+1维的向量表示,用这个特征向量和来训练出一个二分类SVM(label是j是否属于y这个人)
最后每个分类器的权重就是最后这个SVM模型的权重w。
接下来就是实验结果:
然后作者又用特征做了一下聚类,得到了如下结果:

论文到这里就结束了,我觉得搞这么多分类器来做得分叠加是一个很简单暴力的想法。
复现的时候我用Zeiler网络训练了脸部和global两个model,基于caffe框架在8颗Tesla K40m上跑了整整两天。
其中global model是纯粹根据头部位置计算出的一个矩形区域,效果只做到了百分之三十多(最新更新,效果以做到69.59%)。但是脸部区域达到了和论文近似的效果——全部test集做cross validation得到了82%(91.68%),只看有脸的图能达到91%(93.90%)。这一复现均超越了原文,我猜原因可能是我们的face feature比较好吧。
=======================
参考文献
[1]Ning Zhang, et al, Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
[2]L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3D human pose annotations. In International Conference on Computer Vision (ICCV), 2009
[3]Y. Taigman, M. Yang, M. Ranzato, and L. Wolf. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Conference on Computer Vision and Pattern Recognition (CVPR), 2014
无需看到你的脸就能认出你——实现Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues的更多相关文章
- [转]无需看到你的脸就能认出你——实现Beyond Frontal Faces: Improving Person Recognition Using Multiple Cues
转自:http://www.cnblogs.com/sciencefans/p/4764395.html
- 使用OpenCV和Python进行人脸识别
介绍 人脸识别是什么?或识别是什么?当你看到一个苹果时,你的大脑会立刻告诉你这是一个苹果.在这个过程中,你的大脑告诉你这是一个苹果水果,用简单的语言来说就是识别.那么什么是人脸识别呢?我肯定你猜对了. ...
- opencv人脸识别提取手机相册内人物充当数据集,身份识别学习(草稿)
未写完 采用C++,opencv+opencv contrib 4.1.0 对手机相册内人物opencv人脸识别,身份识别学习 最近事情多,介绍就先不介绍了 photocut.c #include & ...
- 基于QT和OpenCV的人脸检測识别系统(2)
紧接着上一篇博客的讲 第二步是识别部分 人脸识别 把上一阶段检測处理得到的人脸图像与数据库中的已知 人脸进行比对,判定人脸相应的人是谁(此处以白色文本显示). 人脸预处理 如今你已经得到一张人脸,你能 ...
- 131.008 Unsupervised Learning - Principle component Analysis |PCA | 非监督学习 - 主成分分析
@(131 - Machine Learning | 机器学习) PCA是一种特征选择方法,可将一组相关变量转变成一组基础正交变量 25 PCA的回顾和定义 Demo: when to use PCA ...
- OpenCV人脸识别的原理 .
OpenCV人脸识别的原理 . 在之前讲到的人脸测试后,提取出人脸来,并且保存下来,以供训练或识别是用,提取人脸的代码如下: void GetImageRect(IplImage* orgImage, ...
- 论文翻译_Tracking The Untrackable_Learning To Track Multiple Cues with Long-Term Dependencies_IEEE2017
Tracking The Untrackable: Learning to Track Multiple Cues with Long-Term Dependencies 跟踪不可跟踪:学习跟踪具有长 ...
- Computer Vision_33_SIFT:SAR-SIFT: A SIFT-LIKE ALGORITHM FOR SAR IMAGES——2015
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_2_Active Shape Models:Active Shape Models-Their Training and Application——1995
此为计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面. 1. Active Appearance Models 活动表观模型和活动轮廓模型基本思想来源 Snake,现在 ...
随机推荐
- Mac那些相见恨晚的技巧
Mac那些相见恨晚的技巧 https://mp.weixin.qq.com/mp/homepage?__biz=MzAxNzcwMTA4Ng==&hid=2&sn=4f42926a59 ...
- (剑指Offer)面试题39:二叉树的深度
题目: 输入一棵二叉树,求该树的深度.从根结点到叶结点依次经过的结点(含根.叶结点)形成树的一条路径,最长路径的长度为树的深度. 结点的定义如下: struct TreeNode{ int val; ...
- C#应用视频教程3.3 Halcon+C#测试
接下来我们考虑把Halcon的代码移植到C#程序上,首先找到halcon的dll(.NET类库有1.0,2.0,3.5的,如果你安装了更新版本的halcon则有更新的.NET类库,我们复制最新的dll ...
- ASP.NET找不到类型或命名空间名称怎么办
如图所示,运行之后提示找不到类型或空间名称,右击有波浪线的代码,选择解析,using XXX 随后自动补上了程序集引用
- I/O复用的应用场合
I/O复用(select.poll)典型使用在下列网络应用场合: (1)当客户处理多个描述字(通常是交互式输入和网络套接口)时,必须使用I/O复用. (2)一个客户同时处理多个套接口是可能的,不过比较 ...
- excel 如何为列添加指定内容(字符串)
excel 如何为列添加指定内容(字符串) CreateTime--2018年5月26日17:52:32 Author:Marydon 1.情景展示 D列的值需要获取B列的值并且在后面统一加上12 ...
- chrome打包程序
使用chrome如何打包扩展程序中已经存在的插件及所遇到的问题 CreateTime--2017年7月4日07:41:33 Author:Marydon 一.前言 鉴于本文章的访问量大,特此进行多 ...
- windows 设置定时锁屏
设置间隔指定时间电脑自动锁屏 CreateTime--2017年7月3日10:16:14Author:Marydon 参考地址:电脑爱好者杂志 举例:实现每间隔45分钟,电脑自动锁屏 实现思路: ...
- linux下vi编辑文件
vi 文件名.进入读文件模式 按i进入编辑模式 按g切光标换到第一行,按G光标切换到最后一行. 按Esc退出编辑模式 :q退出 :wq保存退出 以上命名后面加上!表示强制运行
- 【CI3.1】CI框架简单使用方法
CI框架简单使用方法 1.回忆MVC 1.1.M:模型,提供数据,保存数据 1.2.V:视图,只负责显示,表单form 1.3.C:控制器,协调模型和视图 1.4.action:动作,是控制器中的方法 ...