在Spark程序中使用压缩
当大片连续区域进行数据存储并且存储区域中数据重复性高的状况下,数据适合进行压缩。数组或者对象序列化后的数据块可以考虑压缩。所以序列化后的数据可以压缩,使数据紧缩,减少空间开销。
1. Spark对压缩方式的选择
压缩采用了两种算法:Snappy和LZF,底层分别采用了两个第三方库实现,同时可以自定义其他压缩库对Spark进行扩展。Snappy提供了更高的压缩速度,LZF提供了更高的压缩比,用户可以根据具体需求选择压缩方式。
压缩格式及解编码器如下。
·LZF:org.apache.spark.io.LZFCompressionCodec。
·Snappy:org.apache.spark.io.SnappyCompressionCodec。
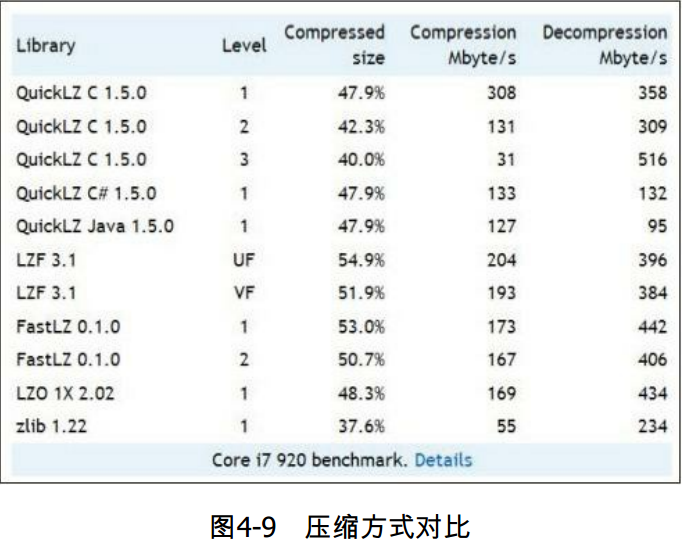
压缩算法的对比,如图4-9所示。
(1)Ning-Compress
Ning-compress是一个对数据进行LZF格式压缩和解压缩的库,这个库是TatuSaloranta(tatu.saloranta@iki .fi)书写的。用户可以在Github地址:https://github.com/ning/compress下载,进行学习和研究。
(2)snappy-java
Snappy算法的前身是Zippy,被Google用于MapReduce、BigTable等许多内部项目。snappy-java由谷歌开发,是以C++开发的Snappy压缩解压缩库的Java分支。Github地址为:https://github.com/xerial /snappy-java。
Snappy的目标是在合理的压缩量情况下,提供高压缩速度的库。因此Snappy的压缩比和LZF差不多,并不是很高。根据数据集的不同,压缩比能达到20%~100%。有兴趣的读者可以看一个压缩算法Benchmark,它对基于JVM运行语言的压缩库进行对比。这个Benchmark对snappy-java和其他压缩工具LZO-java/LZF/Qui ckLZ/Gzip/Bzip2进行了比较。地址为Github:https://github.com/ning/jvm-compressor-benchmark/wiki。这个Benchmark是由Tatu Saloranta@cotowncoder开发的。Snappy通常在达到相当压缩的情况下,要比同类的LZO、LZF、FastLZ和Qui ckLZ等快速的压缩算法快。它对纯文本的压缩比大概是1.5~1.7x,对HTML网页是2~4x,对图片等二进制数据基本没有压缩,为1x。Snappy分别对64位和32位处理器进行了优化,不论是32位处理,还是64位处理器,都能达到很高的效率。据官方介绍,Snappy经过PB级别的大数据的考验,稳定性方面没有问题,Google的map reduce、rpc等很多框架都用到了Snappy压缩算法。
压缩是在时间和空间上的一种权衡。更长的压缩和解压缩时间会节省更多的空间。而空间占用少意味着可以缓存更多的数据,节省I/O时间和网络传输时间。不同的压缩算法是在不同情境的一种权衡,而且对不同数据类型文件进行压缩又会产生差异。可以参考图4-9,对不同算法的使用进行权衡。
2. 在Spark程序中使用压缩
用户可以通过下面两种方式配置压缩。
(1)在Spark-env.sh文件中配置
用户可以在启动前配置文件spark-env.sh设定压缩配置的参数。
export SPARK_JAVA_OPTS="-Dspark.broadcast.compress"
(2)在应用程序中配置
sc是SparkContext对象,conf是SparkConf对象。
val conf=sc.getConf
1)获取压缩的配置。
conf.getBoolean("spark.broadcast.compress",true)
2)压缩的配置。
conf.set("spark.broadcast.compress",true)
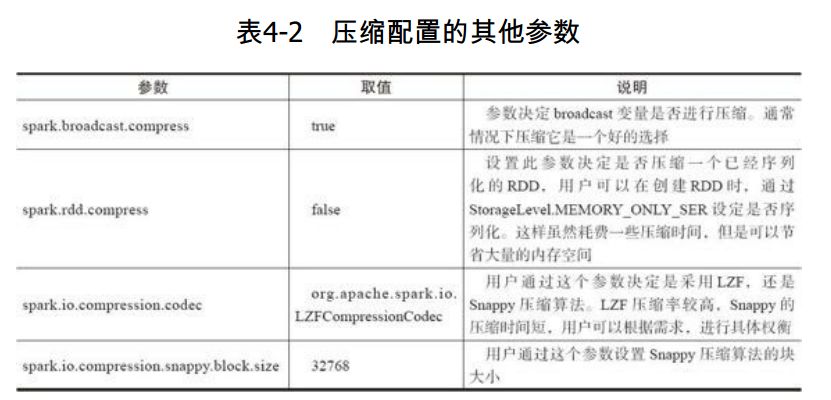
其他参数如表4-2所示:
在分布式计算中,序列化和压缩是两个重要的手段。Spark通过序列化将链式分布的数据转化为连续分布的数据,这样就能够进行分布式的进程间数据通信,或者在内存进行数据压缩等操作,提升Spark的应用性能。通过压缩,能够减少数据的内存占用,以及IO和网络数据传输开销。
在Spark程序中使用压缩的更多相关文章
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified M ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- 程序中使用7-zip(7z)压缩文件
Email:longsu2010 at yeah dot net 工作中难免遇到需要压缩文件的情况,比如有一千万个小文件,每个文件约100k,如果使用7-zip压缩后可能十几k,可以节省很多磁盘空间. ...
- IntelliJ IDEA在Local模式下Spark程序消除日志中INFO输出
在使用Intellij IDEA,local模式下运行Spark程序时,会在Run窗口打印出很多INFO信息,辅助信息太多可能会将有用的信息掩盖掉.如下所示 要解决这个问题,主要是要正确设置好log4 ...
- 在编译器中调试spark程序处理
在IDEA中调试spark程序会报错 18/05/16 07:33:51 WARN NativeCodeLoader: Unable to load native-hadoop library for ...
- Guava com.google.common.base.Stopwatch Spark程序在yarn中 MethodNotFound
今天在公司提交一个Spark 读取hive中的数据,写入JanusGraph 的app,自己本地调试没有问题,放入环境中提交到yarn 中时,发现app 跑不起. yarn 中日志,也比较明显,app ...
- 在IntelliJ IDEA中创建和运行java/scala/spark程序
本文将分两部分来介绍如何在IntelliJ IDEA中运行Java/Scala/Spark程序: 基本概念介绍 在IntelliJ IDEA中创建和运行java/scala/spark程序 基本概念介 ...
随机推荐
- JavaScript中的数据类型总结
Javascript是一种弱类型语言,没有明确的类型分类:网上分类的方式比较多,个人感觉不比去特别的追究细分是什么什么类型,若是能够明确的分出类型的话,javascript就不是弱类型语言,又由于大家 ...
- DotNetOpenAuth实践之WebApi资源服务器
系列目录: DotNetOpenAuth实践系列(源码在这里) 上篇我们讲到WCF服务作为资源服务器接口提供数据服务,那么这篇我们介绍WebApi作为资源服务器,下面开始: 一.环境搭建 1.新建We ...
- Deepin 2015 安装惠普打印机驱动
参考:https://bbs.deepin.org/forum.php?mod=viewthread&tid=34749&extra= 1.安装新立得包管理器:sudo apt-get ...
- CentOS7 logstash配置部署
(1)logstash介绍 `Logstash是一个开源的数据收集引擎,可以水平伸缩,而且logstash是整个ELK当中拥有最多插件的一个组件,其可以接收来自不同源的数据并统一输入到指定的且可以是不 ...
- elementUI 学习入门之 inputNumber 计数器
InputNumber 计数器 基础用法 <el-input-number v-model="num2"></el-input-number> v-mode ...
- 转:php防止sql注入的一点心得
转:http://blog.csdn.net/sky_zhe/article/details/9702489 转:http://zhangxugg-163-com.iteye.com/blog/183 ...
- 【JAVAWEB学习笔记】网上商城实战1:环境搭建和完成用户模块
今日任务 完成用户模块的功能 1.1 网上商城的实战: 1.1.1 演示网上商城的功能: 1.1.2 制作目的: 灵活运用所学知识完成商城实战. 1.1.3 数据库分析和设 ...
- 零配置文件搭建SpringMvc
零配置文件搭建SpringMvc SpringMvc 流程原理 (1)用户发送请求至前端控制器DispatcherServlet:(2) DispatcherServlet收到请求后,调用Handle ...
- [转]JSONObject,JSONArray使用手册
您的评价: 收藏该经验 这两个是官网的API JSONObject API JSONArray API 里面有这两个类的所有方法,是不可多得的好材料哦~ 配合上面的API ...
- [转]android.support.v4.app.Fragment和android.app.Fragment区别
1.最低支持版本不同 android.app.Fragment 兼容的最低版本是android:minSdkVersion="11" 即3.0版 android.support ...